Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
在庫の最適化を実現する SaaSデータ基盤の裏側
Search
Atsushi Yokota
December 12, 2023
Programming
0
240
在庫の最適化を実現する SaaSデータ基盤の裏側
[大阪オフィス現地開催] 目指せ日本の西海岸!関西スタートアップの AWS 活用事例 登壇資料
Atsushi Yokota
December 12, 2023
Tweet
Share
More Decks by Atsushi Yokota
See All by Atsushi Yokota
Athenaで実現する時系列データのパフォーマンス改善
atsuyokota
0
210
Rust on Lambda 大きめCSV生成
atsuyokota
3
1.5k
Other Decks in Programming
See All in Programming
CSC307 Lecture 10
javiergs
PRO
1
660
高速開発のためのコード整理術
sutetotanuki
1
410
AIによる高速開発をどう制御するか? ガードレール設置で開発速度と品質を両立させたチームの事例
tonkotsuboy_com
7
2.4k
AI巻き込み型コードレビューのススメ
nealle
2
1.4k
15年続くIoTサービスの SREエンジニアが挑む 分散トレーシング導入
melonps
2
230
AI Agent の開発と運用を支える Durable Execution #AgentsInProd
izumin5210
7
2.3k
20260127_試行錯誤の結晶を1冊に。著者が解説 先輩データサイエンティストからの指南書 / author's_commentary_ds_instructions_guide
nash_efp
1
990
360° Signals in Angular: Signal Forms with SignalStore & Resources @ngLondon 01/2026
manfredsteyer
PRO
0
140
AI によるインシデント初動調査の自動化を行う AI インシデントコマンダーを作った話
azukiazusa1
1
750
フロントエンド開発の勘所 -複数事業を経験して見えた判断軸の違い-
heimusu
7
2.8k
2026年 エンジニアリング自己学習法
yumechi
0
140
CSC307 Lecture 03
javiergs
PRO
1
490
Featured
See All Featured
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
270
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
57
Claude Code のすすめ
schroneko
67
210k
Become a Pro
speakerdeck
PRO
31
5.8k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
350
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
740
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
170
ラッコキーワード サービス紹介資料
rakko
1
2.3M
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
54
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
110
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
0
210
30 Presentation Tips
portentint
PRO
1
220
Transcript
在庫の最適化を実現する SaaSデータ基盤の裏側 フルカイテン株式会社 横田
Atsushi Yokota バックエンドエンジニア 2 • 2020年10月よりフルカイテンに参画。 • FULL KAITEN V3の新規開発に携わり、Rustによる
GraphQLサーバーの構築やデータ基盤の構築を担当 • バックエンドグループマネージャー 自己紹介
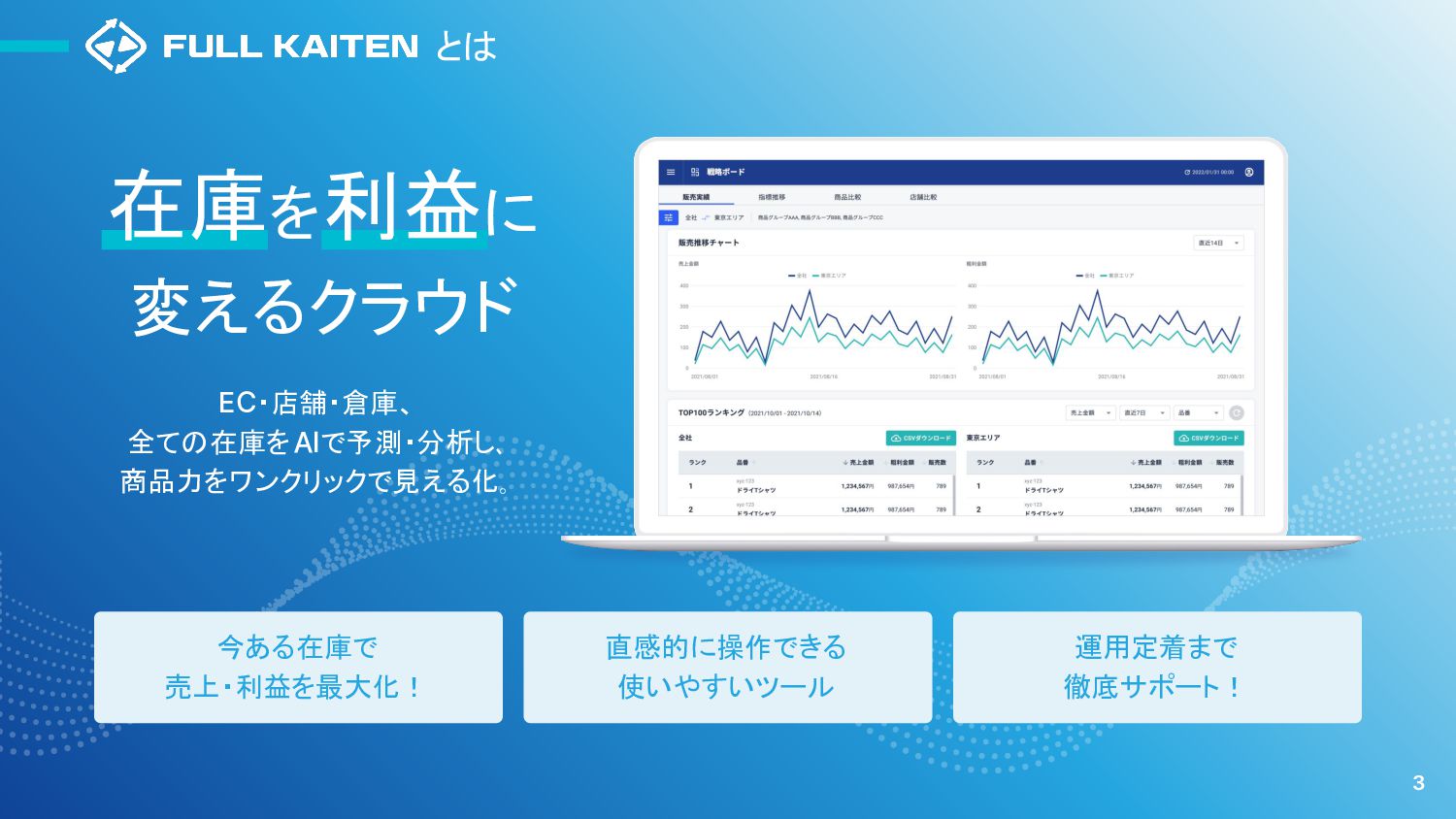
3 在庫を利益に 変えるクラウド 今ある在庫で 売上・利益を最大化! 直感的に操作できる 使いやすいツール 運用定着まで 徹底サポート! EC・店舗・倉庫、
全ての在庫をAIで予測・分析し、 商品力をワンクリックで見える化。 とは
4 導入実績 ※一部抜粋/順不同 ※2023年10月時点
1. データ基盤の重要ポイント 2. リリース当初のアーキテクチャー 3. 刷新後のアーキテクチャー 4. 刷新の結果 5. 今後の展望
Agenda
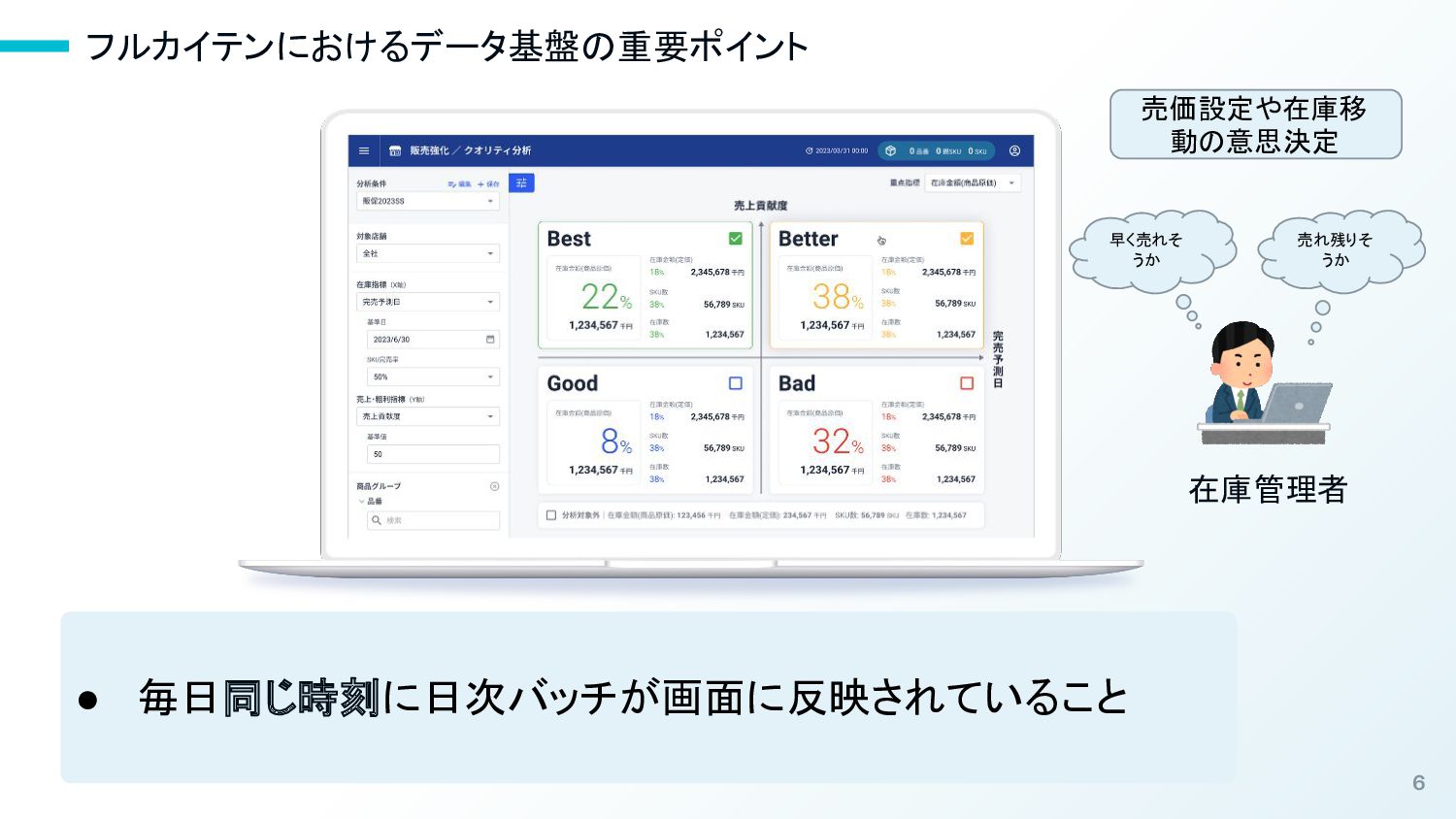
6 フルカイテンにおけるデータ基盤の重要ポイント • 毎日同じ時刻に日次バッチが画面に反映されていること 在庫管理者 売価設定や在庫移 動の意思決定 早く売れそ うか 売れ残りそ
うか
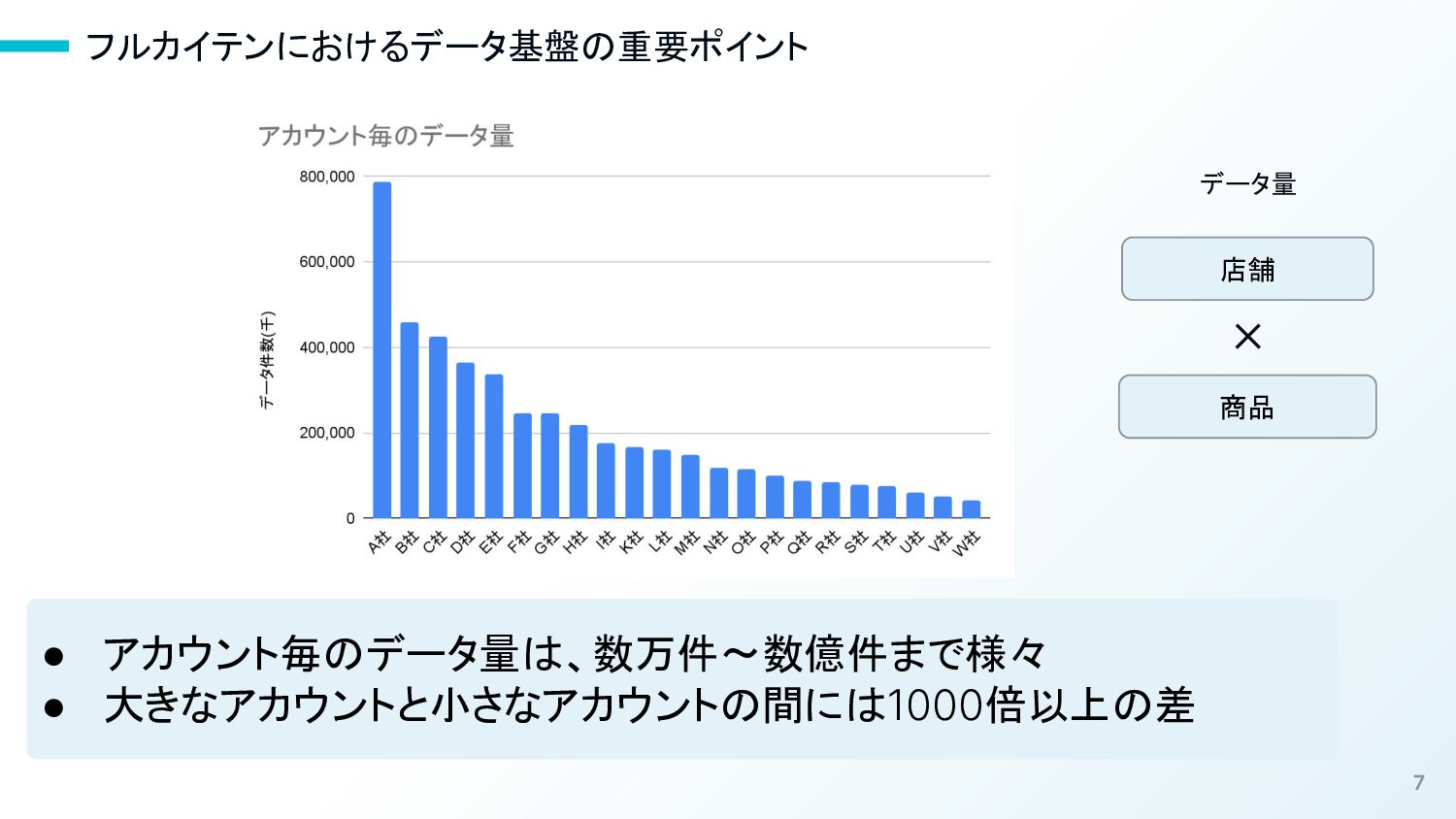
7 フルカイテンにおけるデータ基盤の重要ポイント • アカウント毎のデータ量は、数万件〜数億件まで様々 • 大きなアカウントと小さなアカウントの間には1000倍以上の差 店舗 商品 ✕ データ量
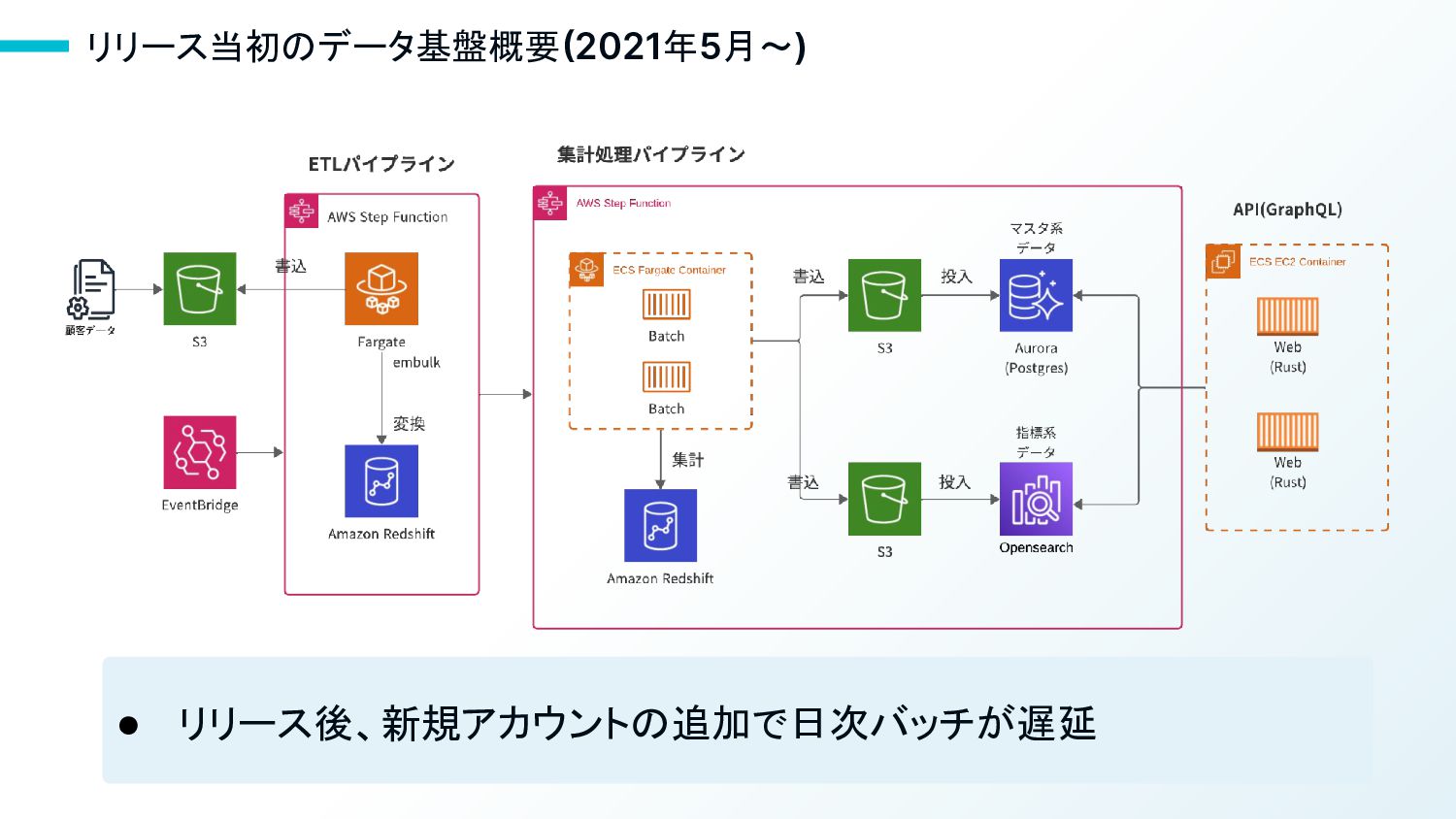
8 リリース当初のデータ基盤概要(2021年5月〜)
リリース当初のデータ基盤概要(2021年5月〜) • リリース後、新規アカウントの追加で日次バッチが遅延
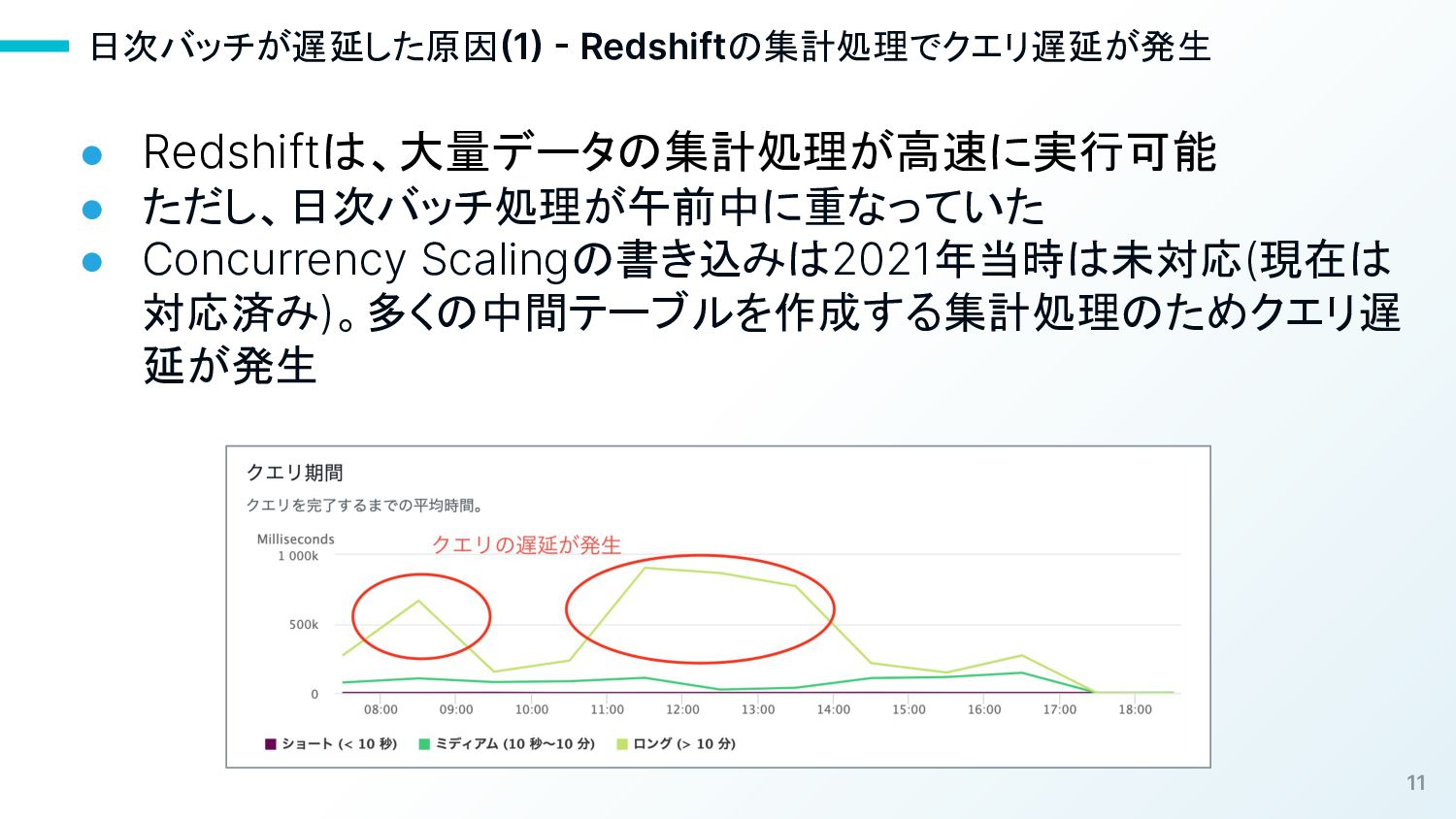
日次バッチが遅延した原因(1) Redshiftの集計処理でクエリ遅延が発生
11 日次バッチが遅延した原因(1) - Redshiftの集計処理でクエリ遅延が発生 • Redshiftは、大量データの集計処理が高速に実行可能 • ただし、日次バッチ処理が午前中に重なっていた • Concurrency
Scalingの書き込みは2021年当時は未対応(現在は 対応済み)。多くの中間テーブルを作成する集計処理のためクエリ遅 延が発生
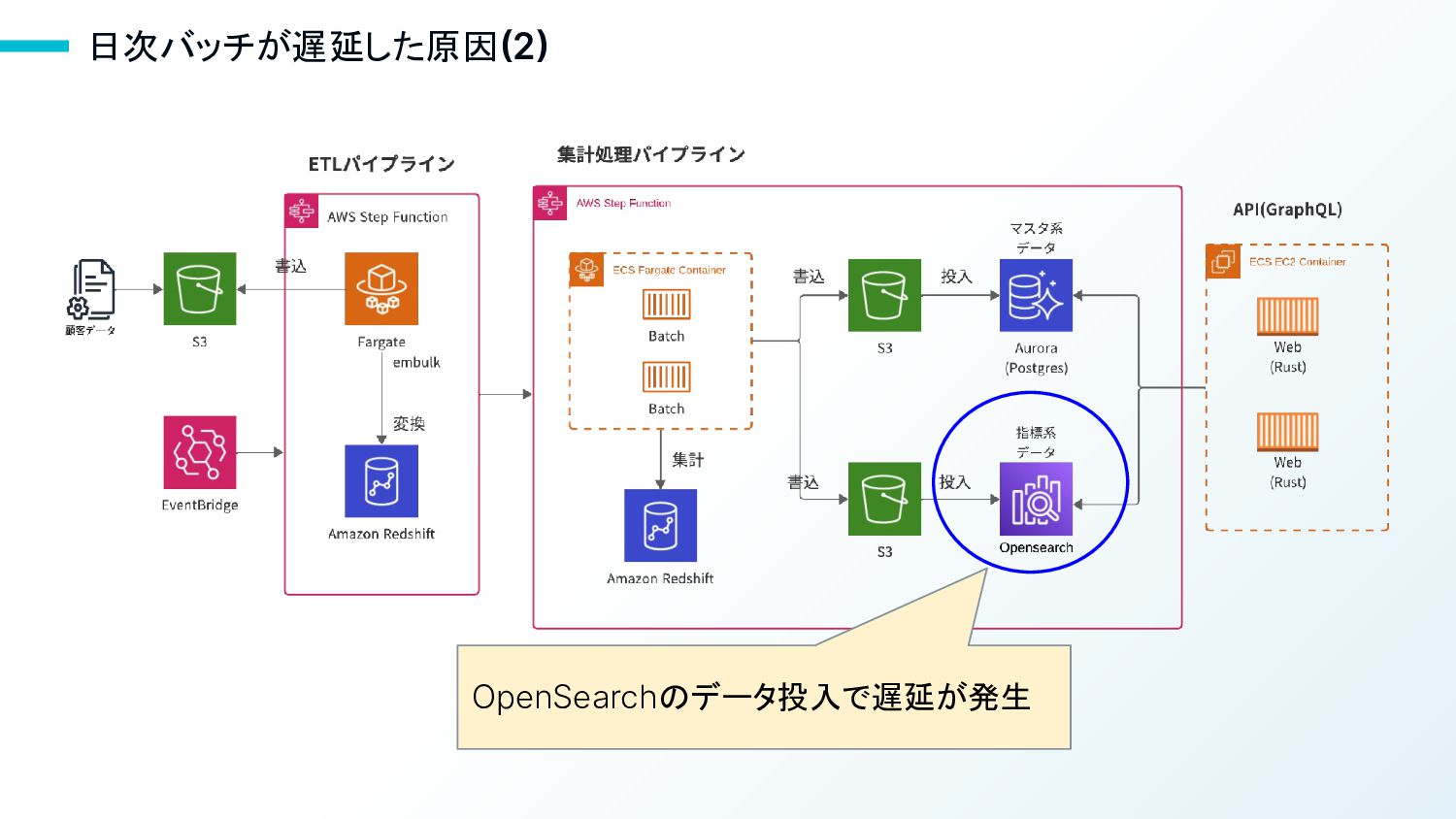
日次バッチが遅延した原因(2) OpenSearchのデータ投入で遅延が発生
13 日次バッチが遅延した原因(2) - OpenSearchのデータ投入で遅延が発生 • 大量データのソート、フィルタリングは非常に高速 • ただし、インデックス作成に時間がかかり、大量データの投入が重な るとエラーが発生することがある •
結果、データの投入待ち時間が長くなり、日次バッチにかかる時間の 40%を占める状況になった
14 問題点のまとめ • 新規アカウントが増加するにつれて、リソースの奪い合いが発生 • 大きめのアカウント(約3.5億件)で画面反映まで、毎日15時間もかかる 状態 • データ量の小さなお客様もバッチ処理の反映が遅くなるようになっ た。。
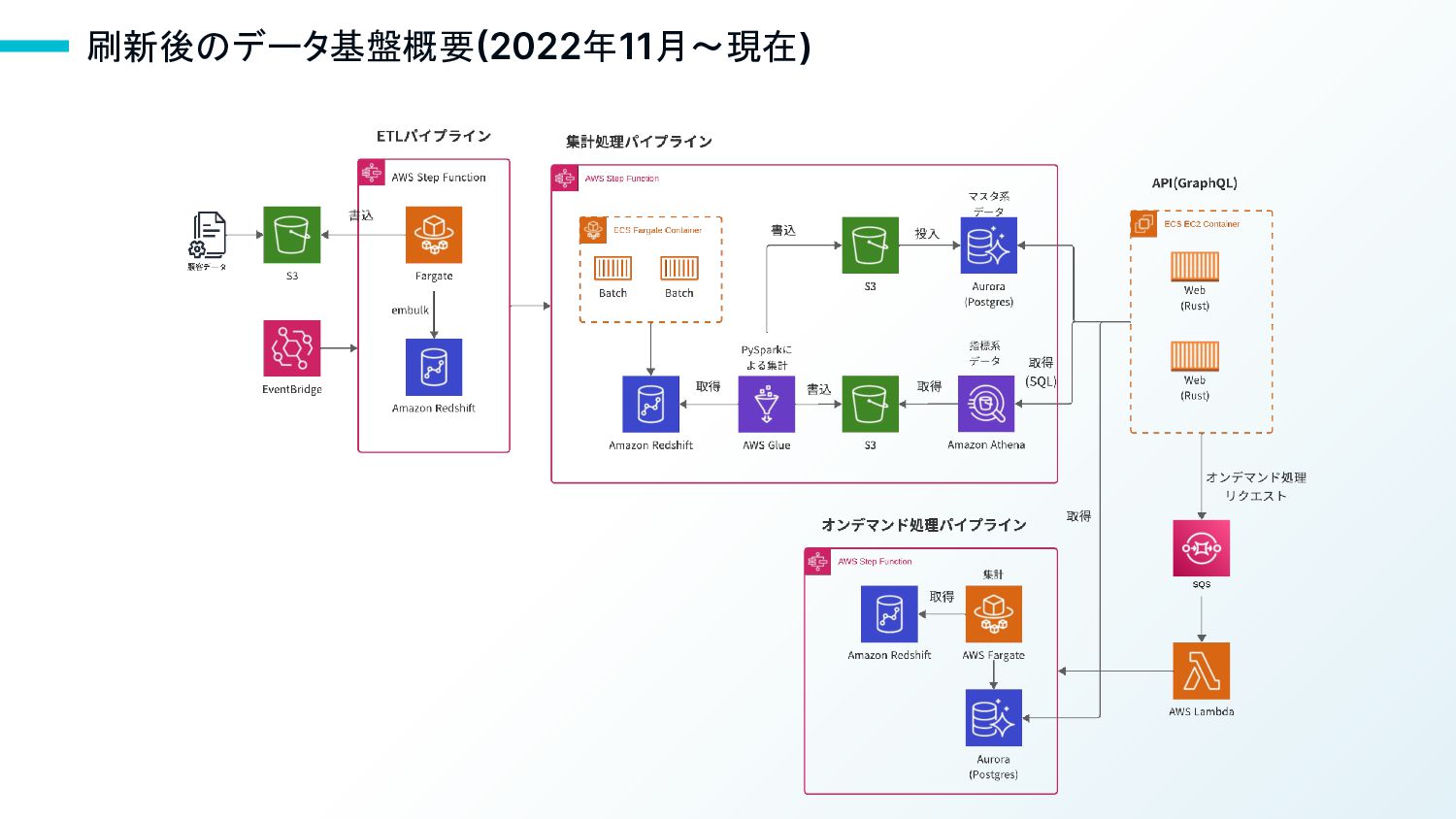
15 刷新後のデータ基盤概要(2022年11月〜現在)
刷新後のデータ基盤概要(2022年11月〜現在)
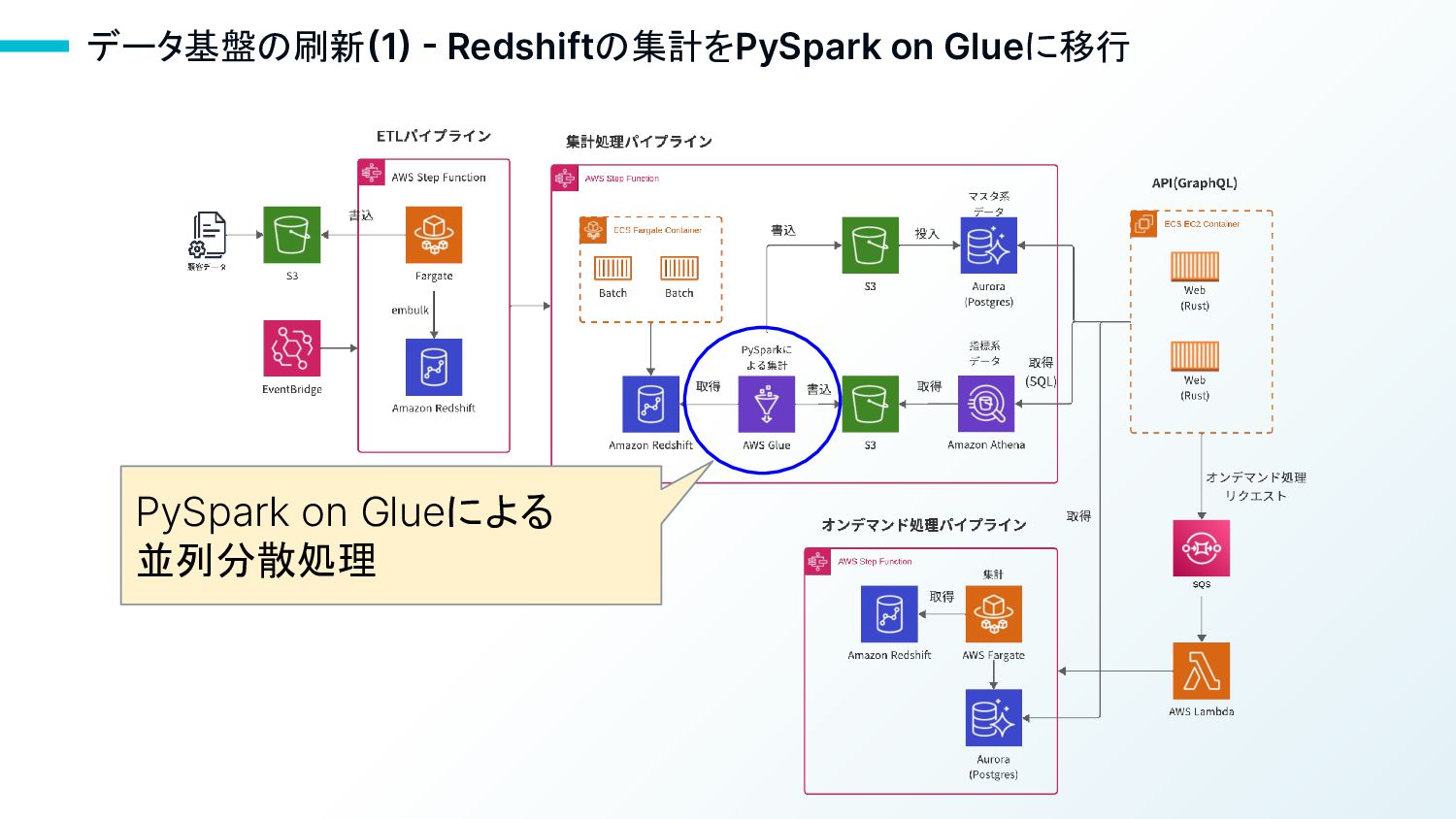
データ基盤の刷新(1) - Redshiftの集計をPySpark on Glueに移行 PySpark on Glueによる 並列分散処理
18 Redshiftの集計をPySpark on Glueに移行した理由 • 複雑な集計処理が多く、中間テーブルの作成が必要であるため、メモ リ上での集計を行うPySpark on Glueの方が処理速度が速い •
サーバレスのGlueを使用することで、他のアカウントの影響を受 けることなく、並列分散処理が可能 • アカウント毎にワーカー数を指定することで、インフラコストを最適化 することが可能
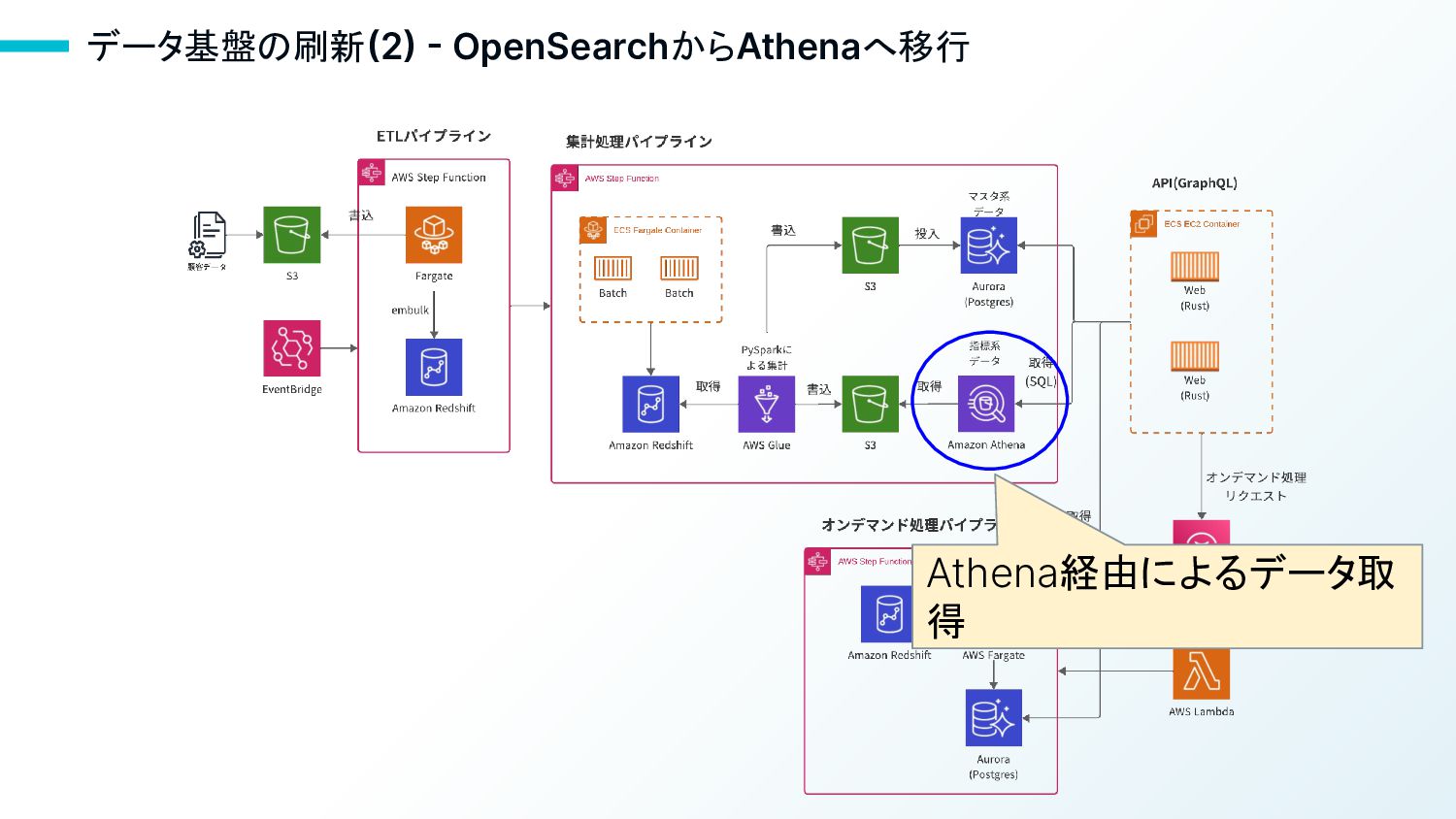
データ基盤の刷新(2) - OpenSearchからAthenaへ移行 Athena経由によるデータ取 得
20 OpenSearchからAthenaへ移行した理由 • S3に格納されたデータを直接SQLでリクエストできるため、データ投入が 不要 • リクエスト毎にリソースが割り当てられるため、重いリクエストも並列で実行す ることが可能 • FederatedQueryを使用することで、Auroraを含む他のデータストアと結合
可能 書込 Parquet ファイル Glue Athena 取得 SQL Aurora
Athena導入の注意点 • ソートやフィルタリング処理は、OpenSearchの方が速いことが多い • 少量のデータに対してもレスポンス時間がかかる ◦ S3のExpress One Zoneで早くなるらしい トレードオフがあるので、
ユースケースに合わせた検討が必要
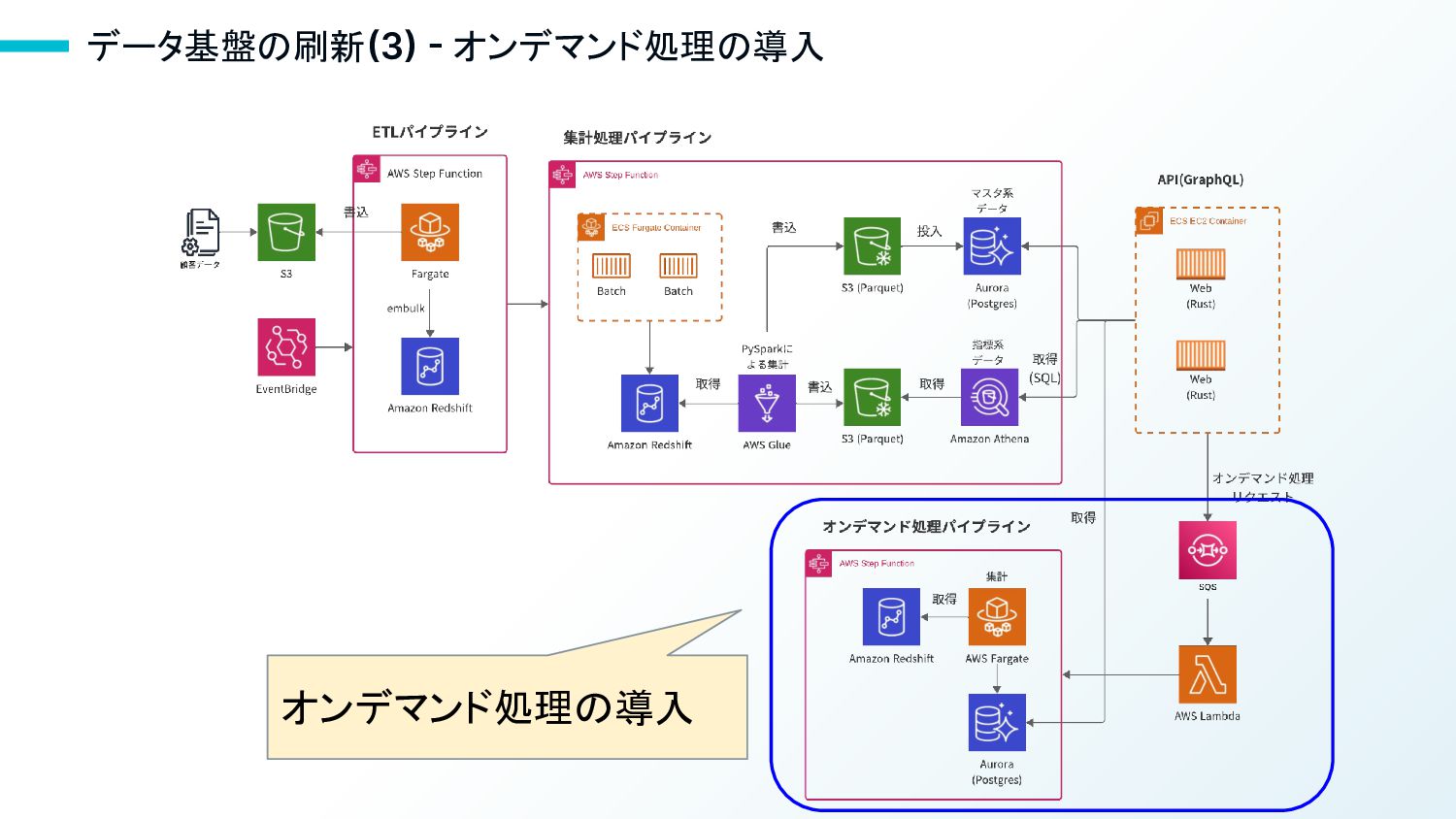
データ基盤の刷新(3) - オンデマンド処理の導入 オンデマンド処理の導入
23 オンデマンド処理の導入理由 • ユーザーからのリクエストに応じて、必要な集計処理を行うオンデマ ンド処理に対応 • 日次バッチを待たずにアドホックな分析が可能になり、ユーザー体験 が向上した • 参照頻度の低い日次集計をオンデマンド処理に移行
• Fargateの最大vCPU16個、メモリ128GiBに大幅拡張(2022年9 月)。これにより、ある程度のデータ量でもPandasで処理できるように なった。
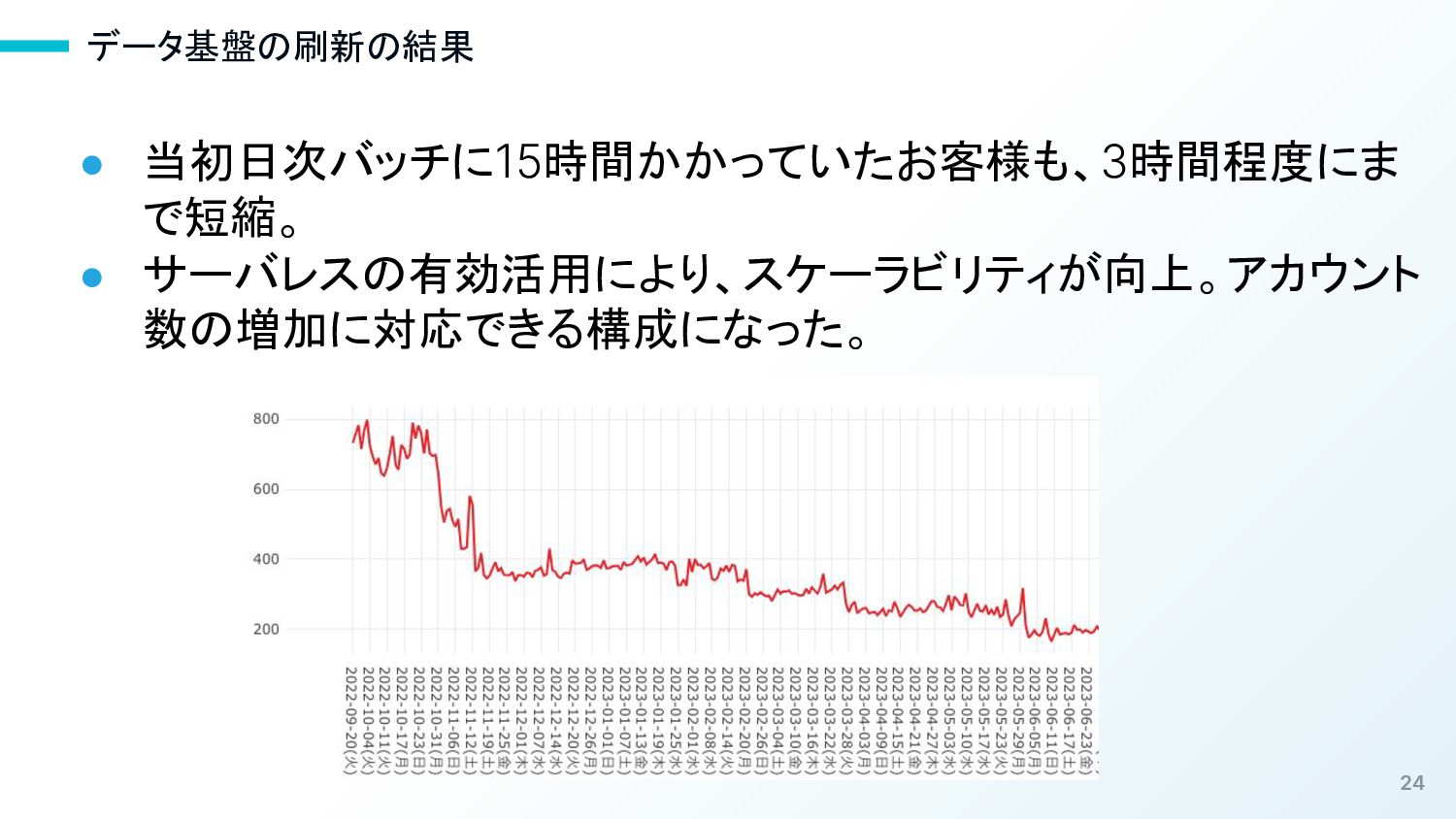
24 データ基盤の刷新の結果 • 当初日次バッチに15時間かかっていたお客様も、3時間程度にま で短縮。 • サーバレスの有効活用により、スケーラビリティが向上。アカウント 数の増加に対応できる構成になった。
25 今後の展望 • アーキテクチャーの再編 ◦ オンデマンド処理への移行 ◦ Glueジョブの分割 • パフォーマンス・チューニング
◦ データ構造の見直し ◦ Glueのworkerの自動設定 • 機械学習のライフサイクル管理 • サービスとして横断的なデータ解析 プロダクトの状況は日々変化する データ基盤の作り替えも積極的に行う
エンジニア募集中! 一緒に世界の大量廃棄問題を解決しましょう! https://note.com/fullkaiten_re フルカイテン公式note
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}