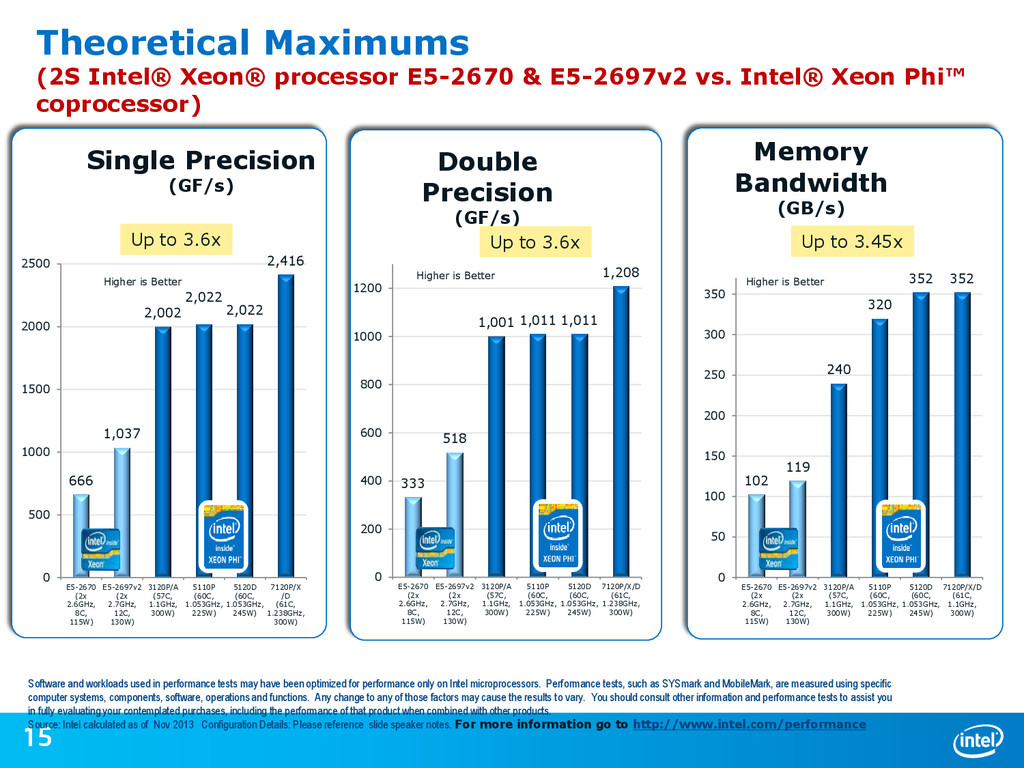
1500 2000 2500 E5-2670 (2x 2.6GHz, 8C, 115W) E5-2697v2 (2x 2.7GHz, 12C, 130W) 3120P/A (57C, 1.1GHz, 300W) 5110P (60C, 1.053GHz, 225W) 5120D (60C, 1.053GHz, 245W) 7120P/X /D (61C, 1.238GHz, 300W) Single Precision (GF/s) Theoretical Maximums (2S Intel® Xeon® processor E5-2670 & E5-2697v2 vs. Intel® Xeon Phi™ coprocessor) Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Source: Intel calculated as of Nov 2013 Configuration Details: Please reference slide speaker notes. For more information go to http://www.intel.com/performance Up to 3.6x 333 518 1,001 1,011 1,011 1,208 0 200 400 600 800 1000 1200 E5-2670 (2x 2.6GHz, 8C, 115W) E5-2697v2 (2x 2.7GHz, 12C, 130W) 3120P/A (57C, 1.1GHz, 300W) 5110P (60C, 1.053GHz, 225W) 5120D (60C, 1.053GHz, 245W) 7120P/X/D (61C, 1.238GHz, 300W) Double Precision (GF/s) 102 119 240 320 352 352 0 50 100 150 200 250 300 350 E5-2670 (2x 2.6GHz, 8C, 115W) E5-2697v2 (2x 2.7GHz, 12C, 130W) 3120P/A (57C, 1.1GHz, 300W) 5110P (60C, 1.053GHz, 225W) 5120D (60C, 1.053GHz, 245W) 7120P/X/D (61C, 1.1GHz, 300W) Memory Bandwidth (GB/s) Up to 3.6x Up to 3.45x Higher is Better Higher is Better Higher is Better
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
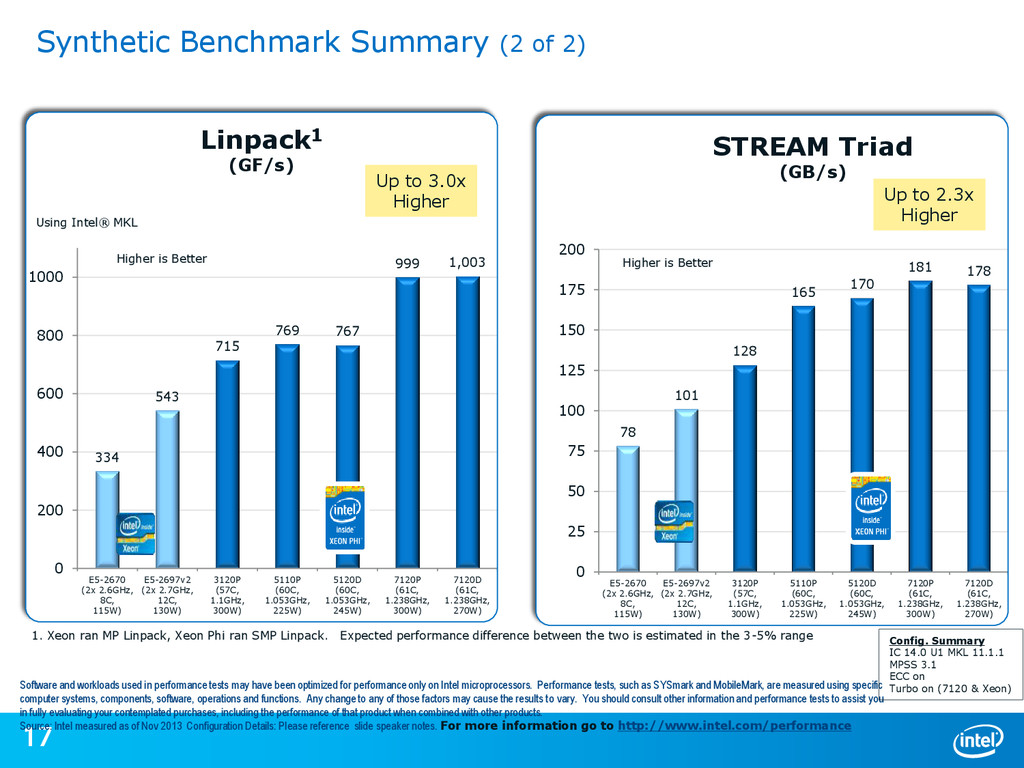{kind=link}
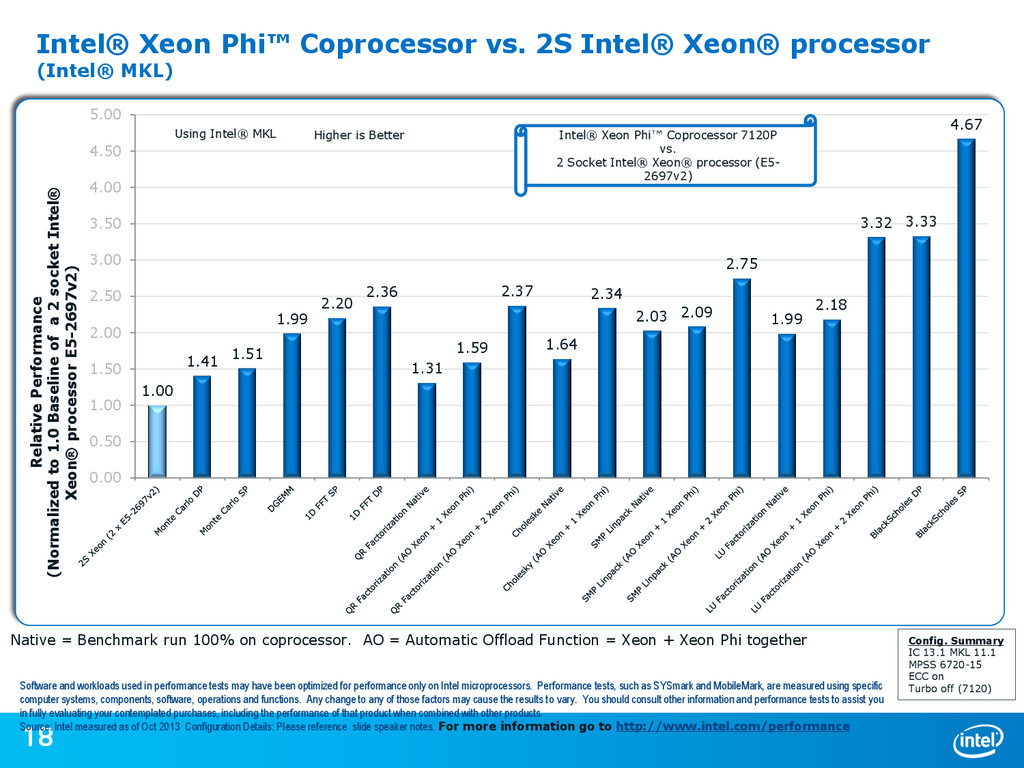{kind=link}
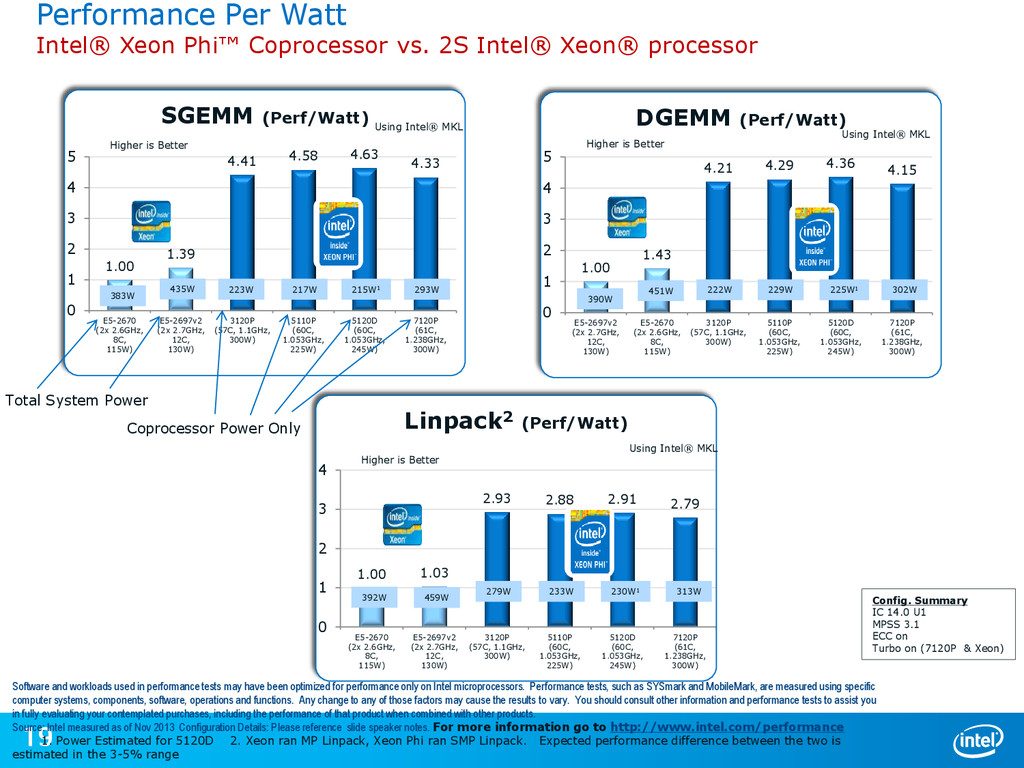{kind=link}
{kind=link}
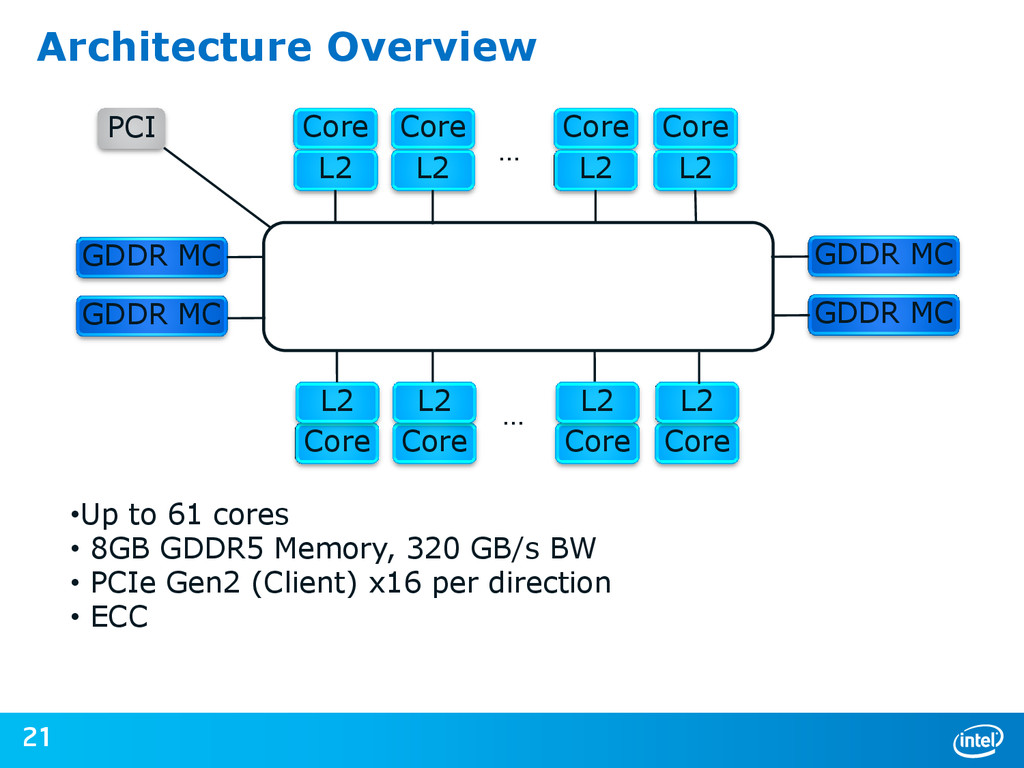{kind=link}
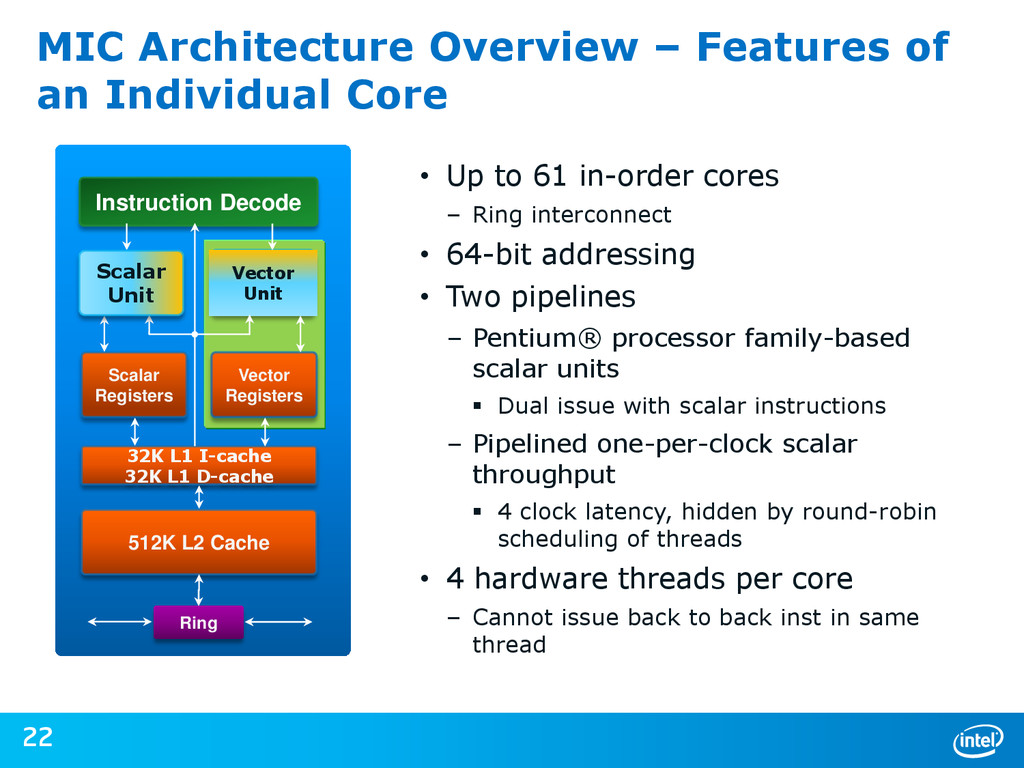{kind=link}
{kind=link}
{kind=link}
{kind=link}
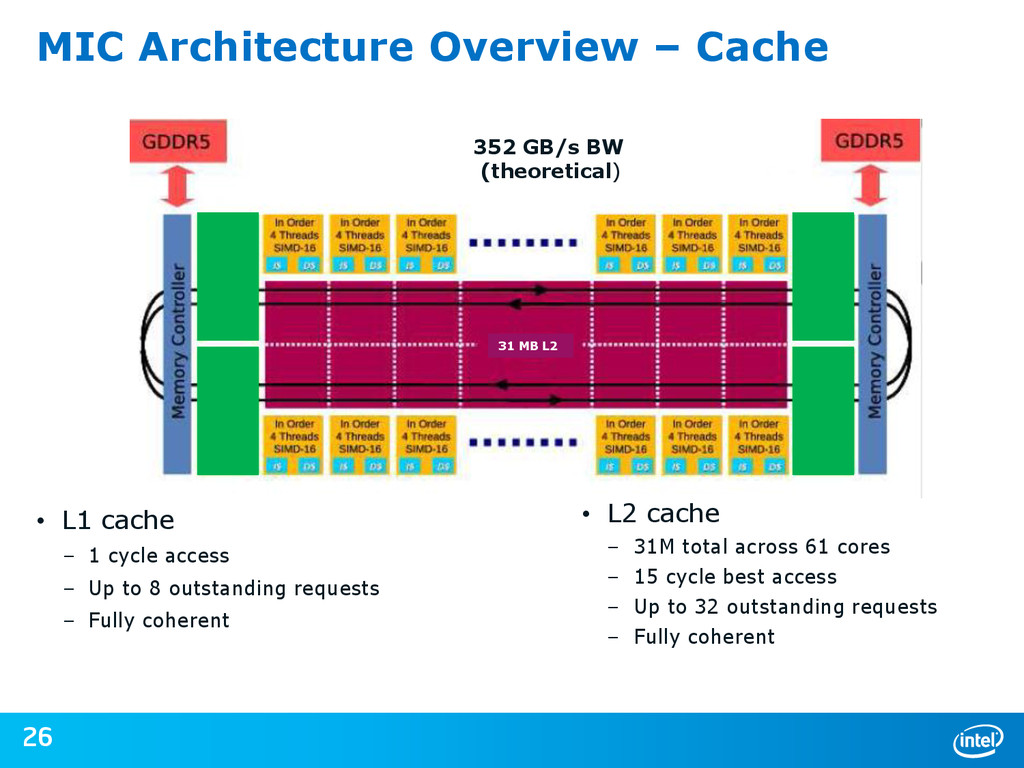{kind=link}
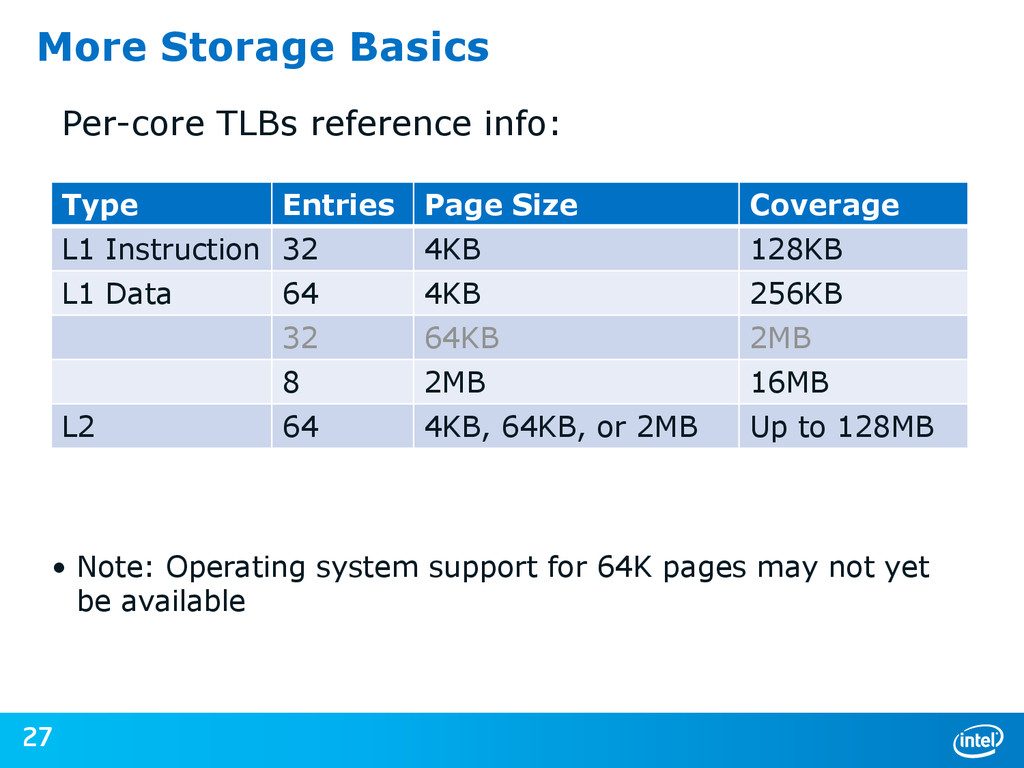{kind=link}
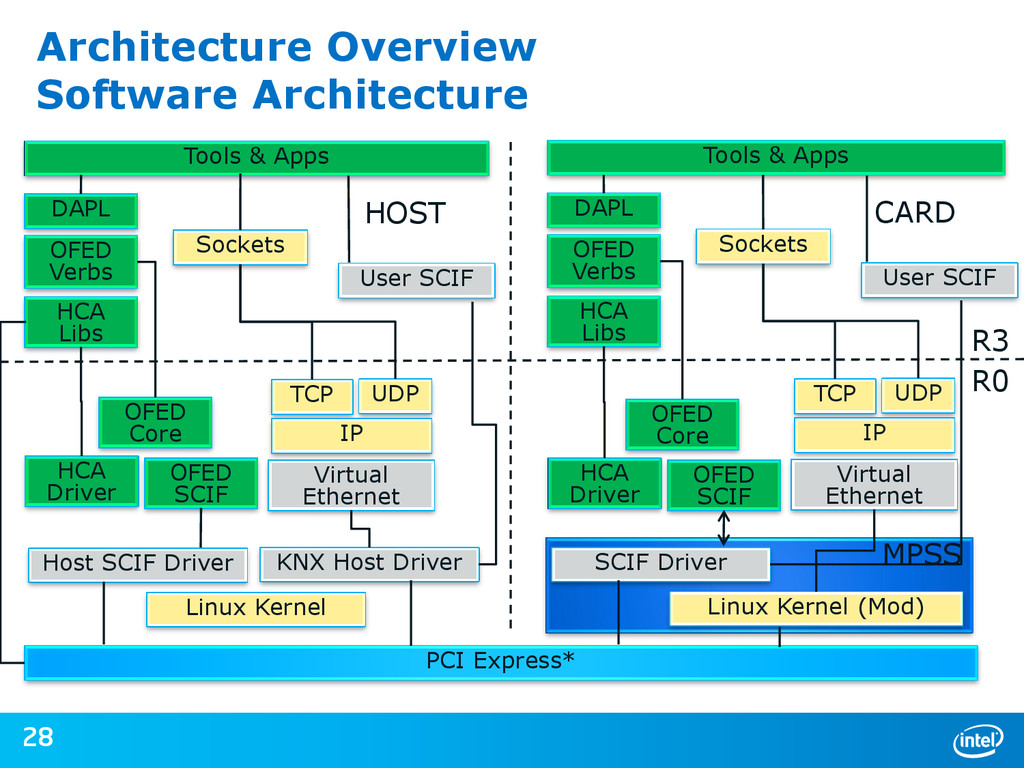{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
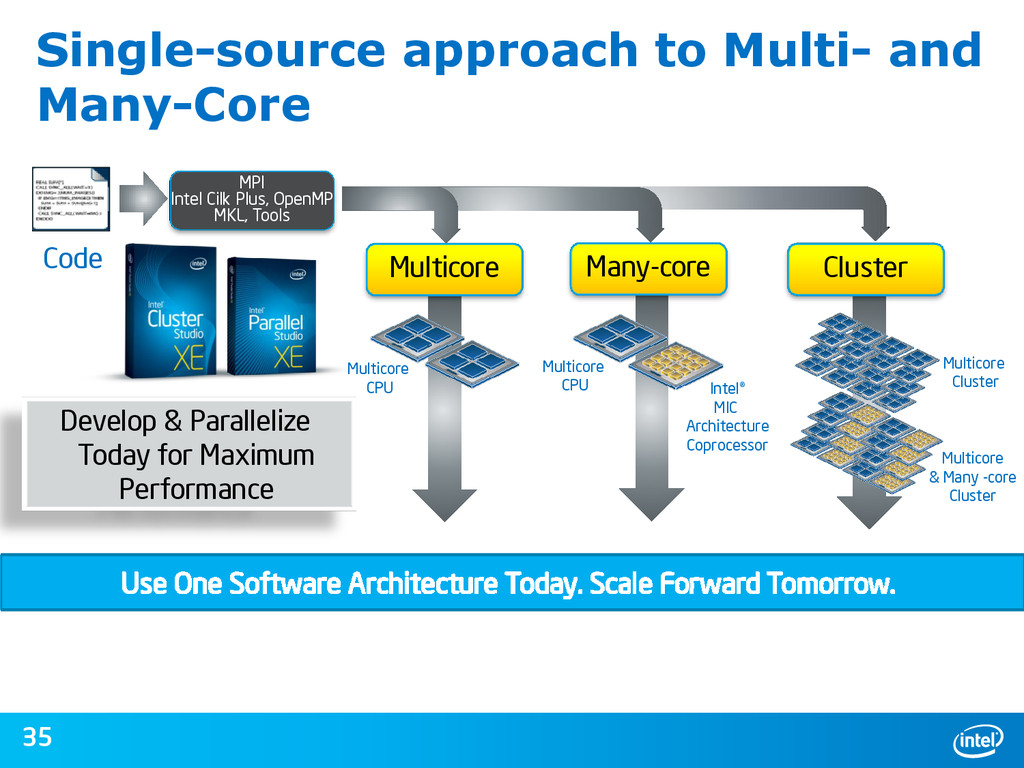{kind=link}
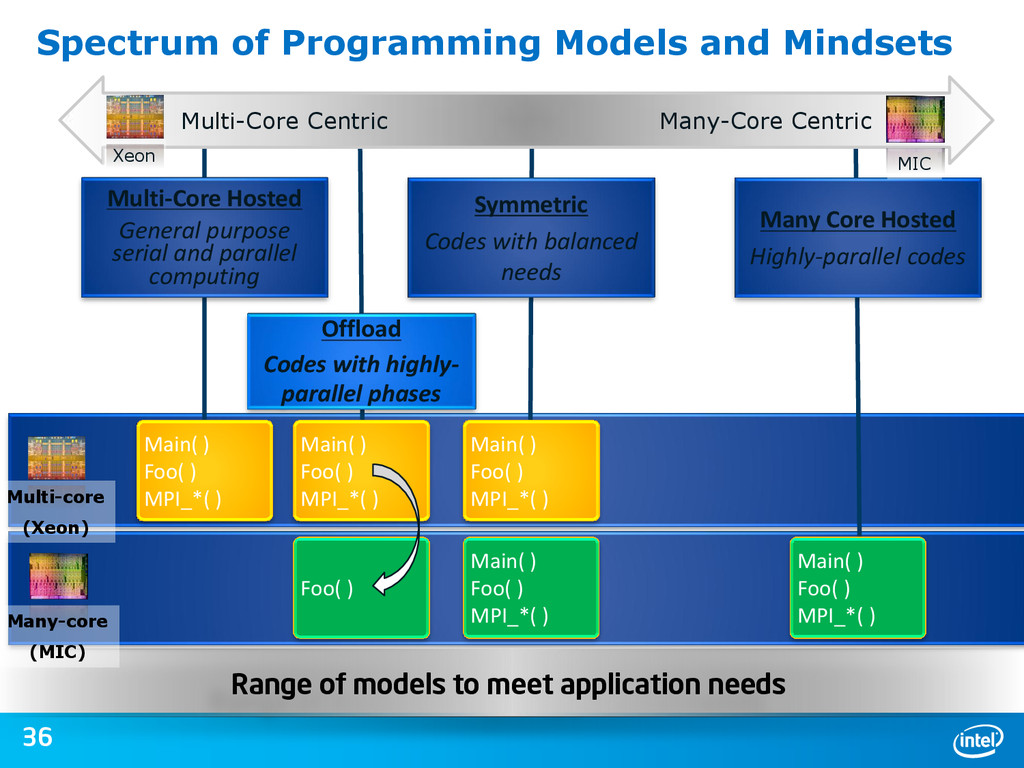{kind=link}
{kind=link}
{kind=link}
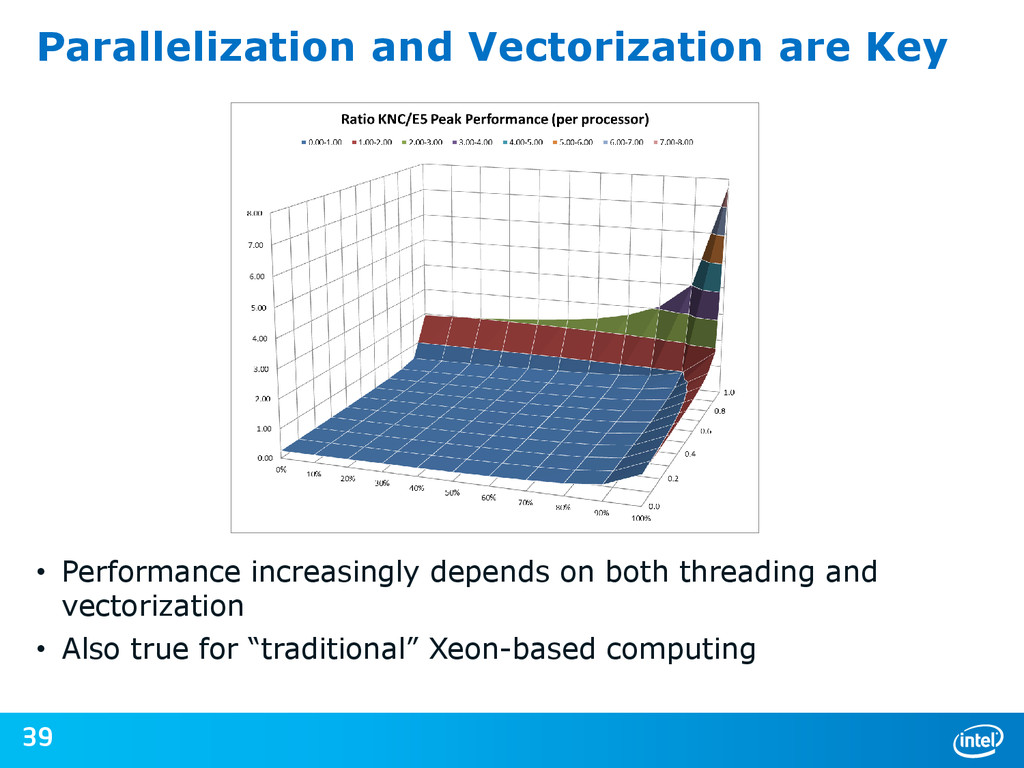{kind=link}
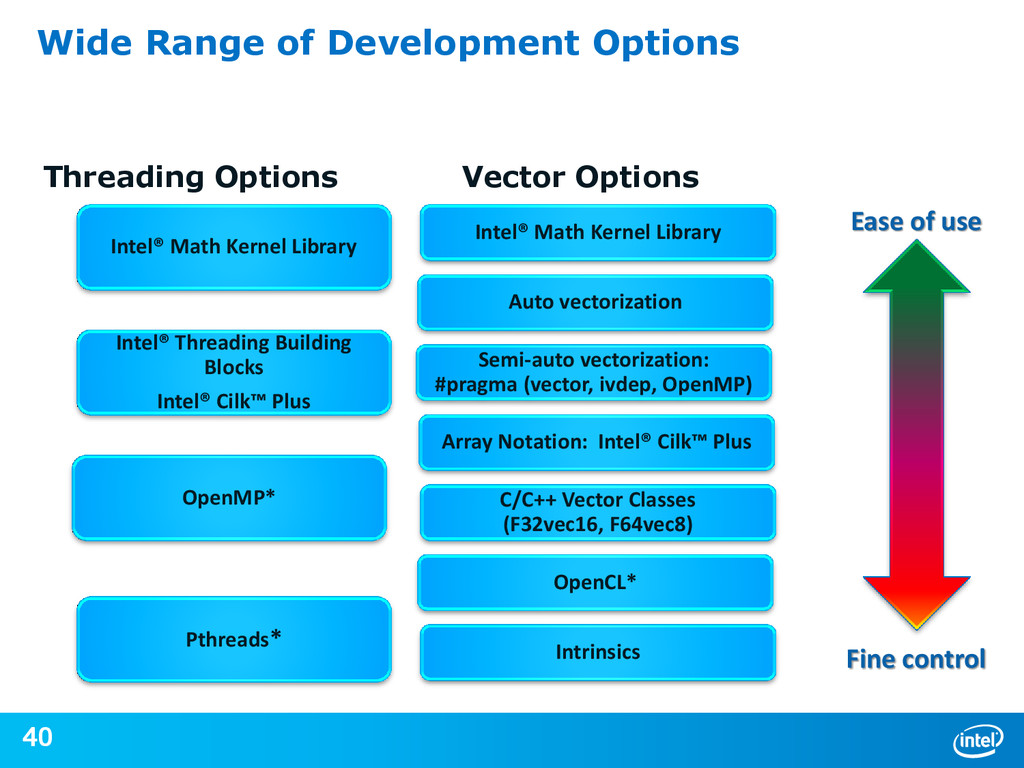{kind=link}
{kind=link}
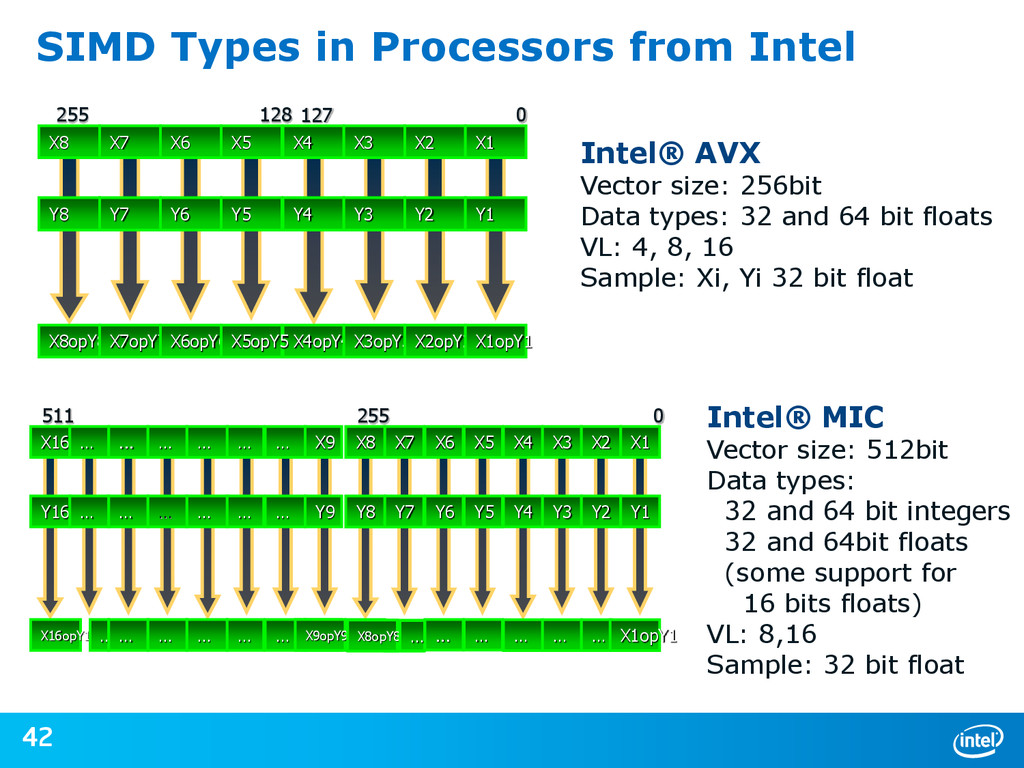{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![51 The simd construct #pragma omp simd [clauses] for-loop •](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
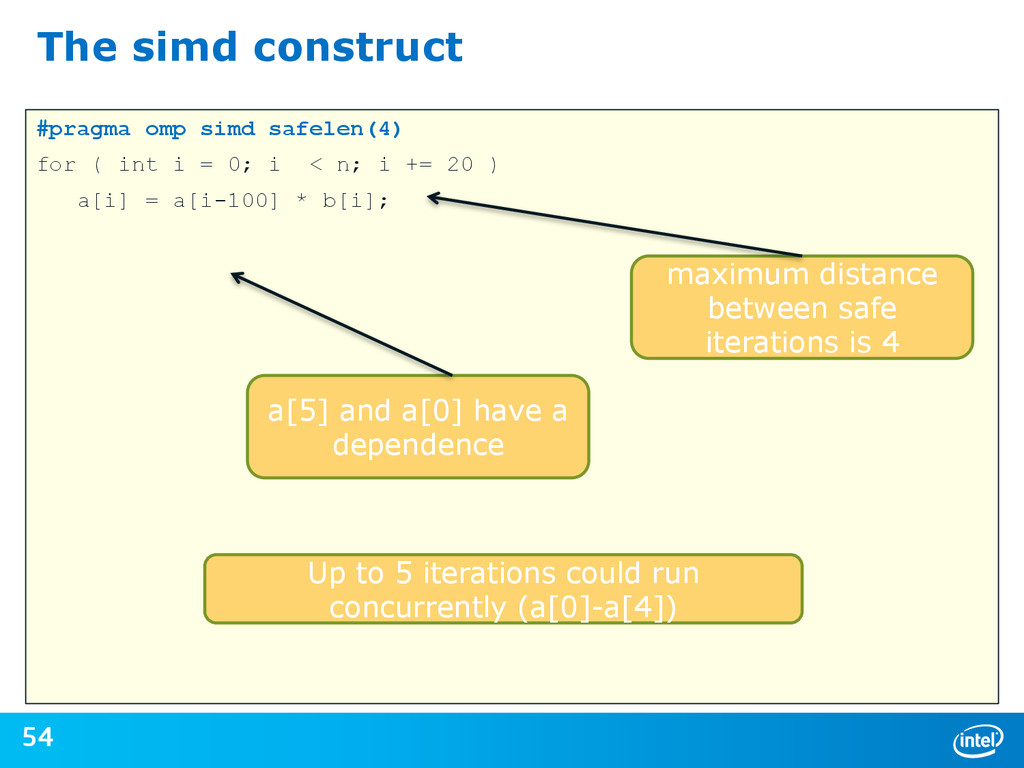{kind=link}
![55 The declare simd construct #pragma declare simd [clauses] [#pragma](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
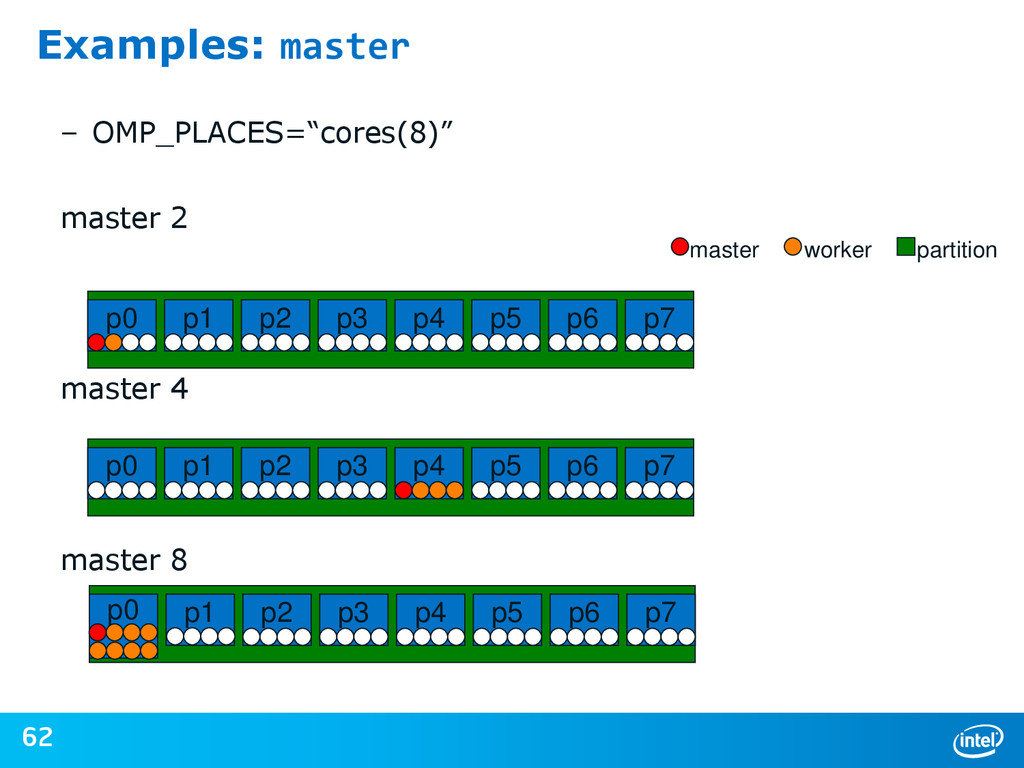{kind=link}
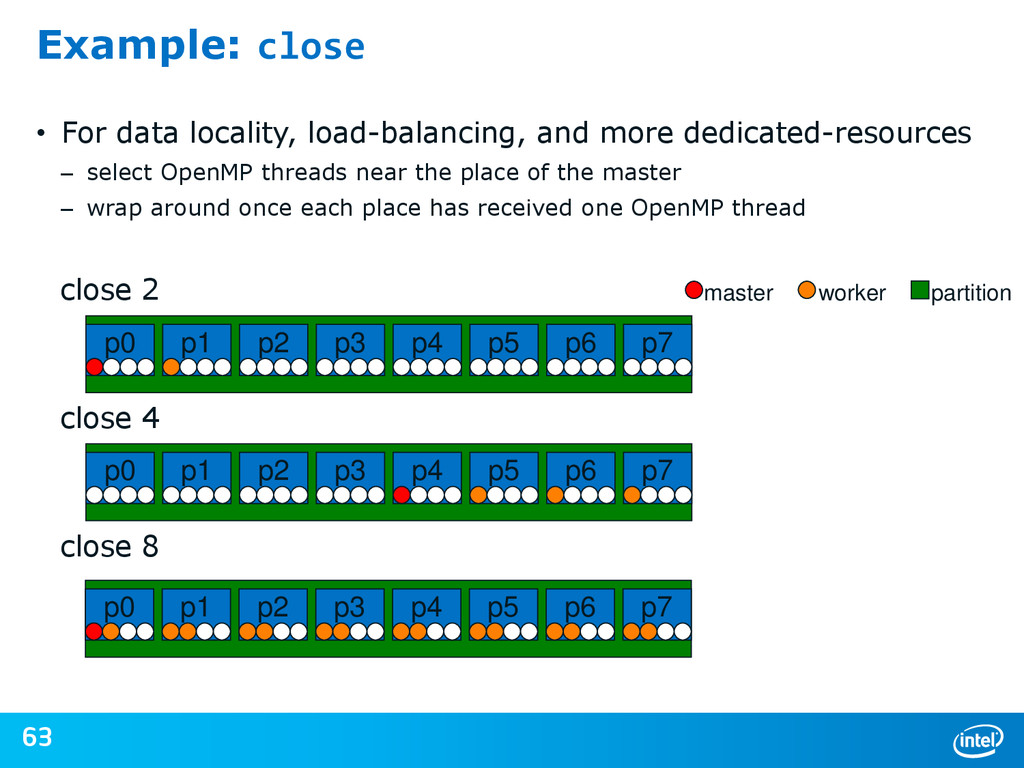{kind=link}
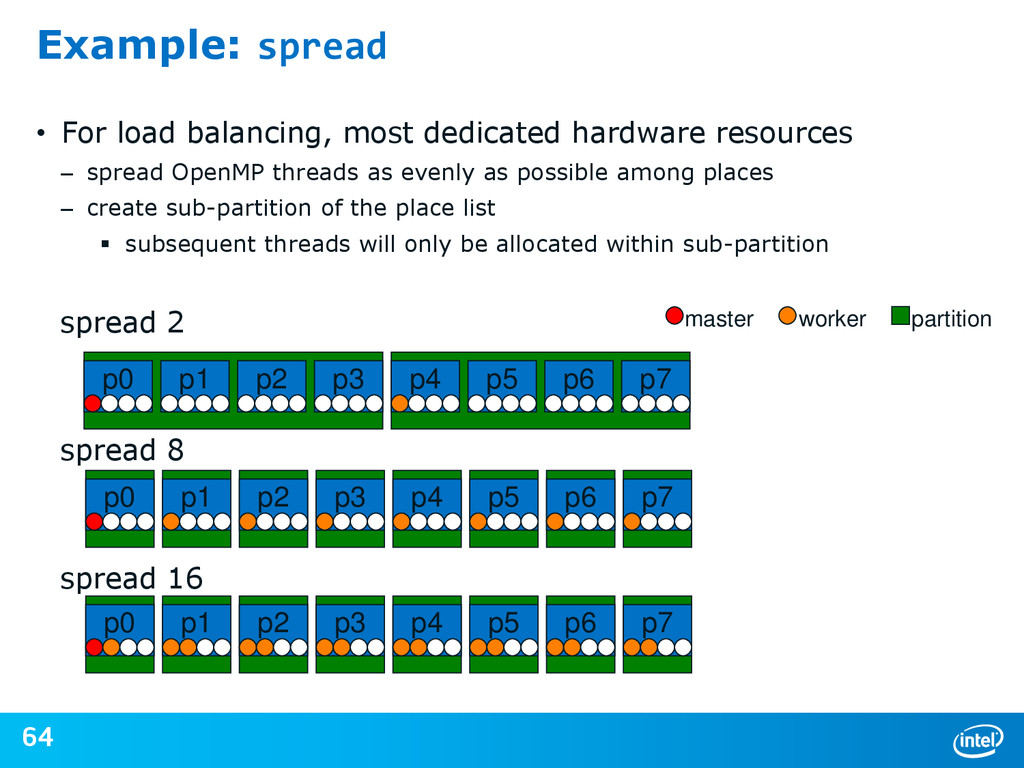{kind=link}
{kind=link}
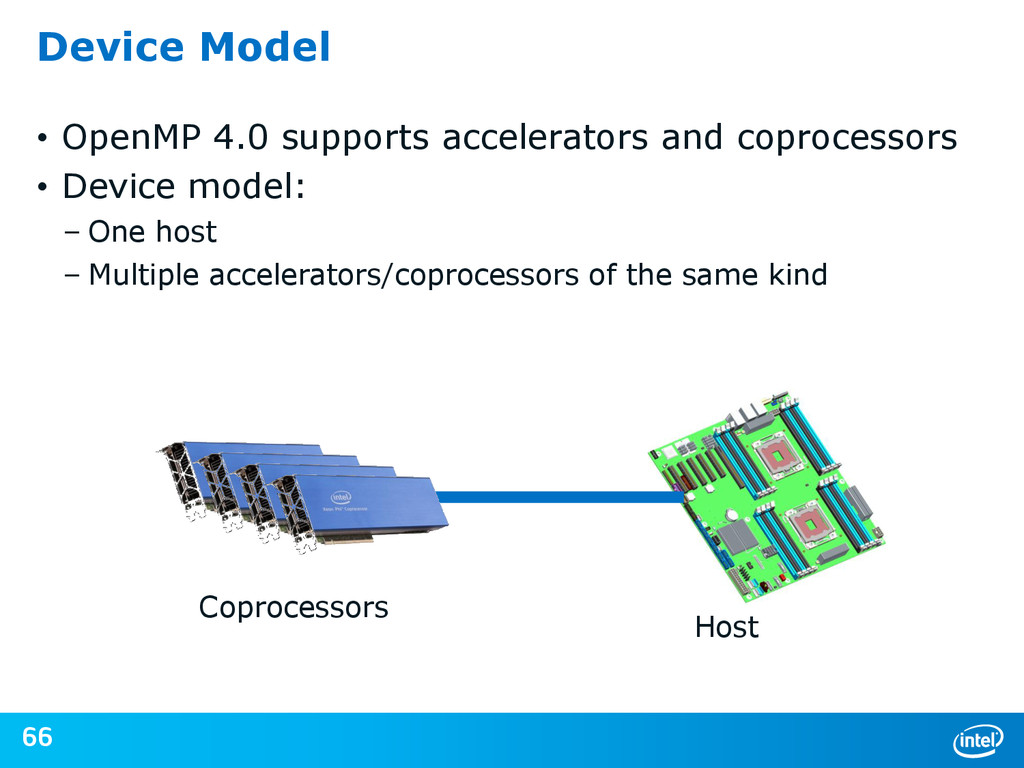{kind=link}
![67 The target construct #pragma omp target [clauses] structured block](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_66.jpg){kind=link}
{kind=link}
![69 Target construct example int a[N],int res; #pragma omp target](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_68.jpg){kind=link}
![70 Target construct example int a[N],int res; #pragma omp target](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_69.jpg){kind=link}
{kind=link}
![72 Target construct example int a[N],int res; #pragma omp target](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_71.jpg){kind=link}
![73 The target data construct #pragma omp target data [clauses]](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
![76 The target update construct #pragma omp target update [clauses]](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![81 team Constructs #pragma omp team [clauses] structured-block Clauses: num_teams(](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_80.jpg){kind=link}
![82 Distribute Constructs #pragma omp distribute [clauses] for-loops Clauses: private(](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
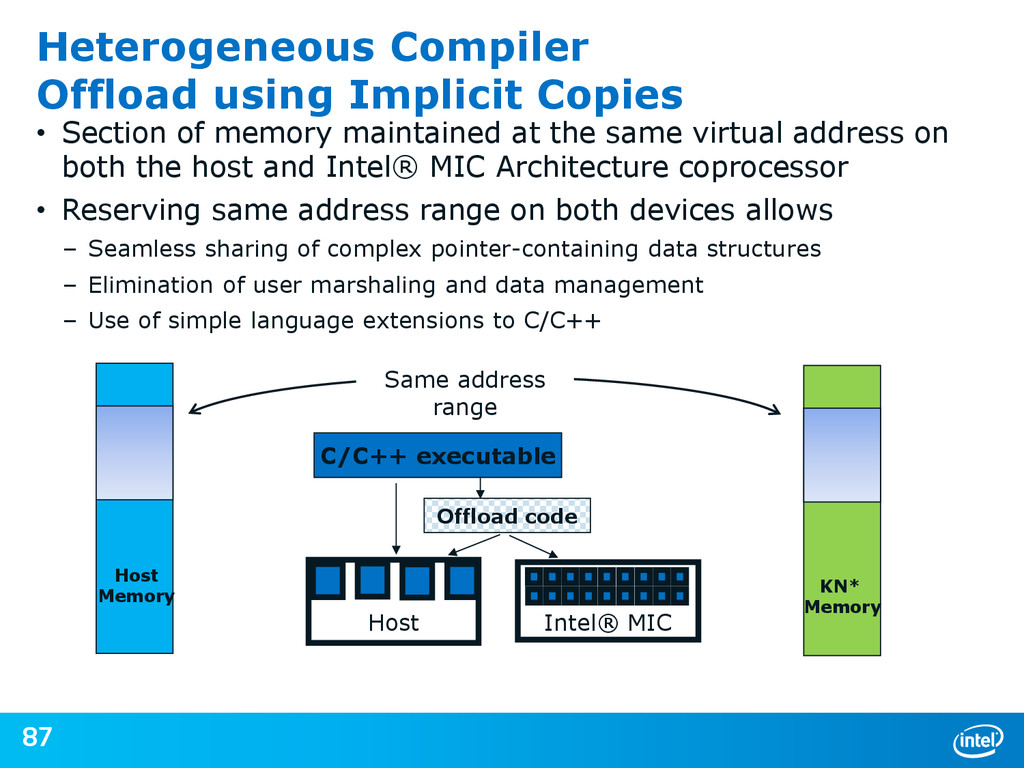{kind=link}
{kind=link}
{kind=link}
{kind=link}
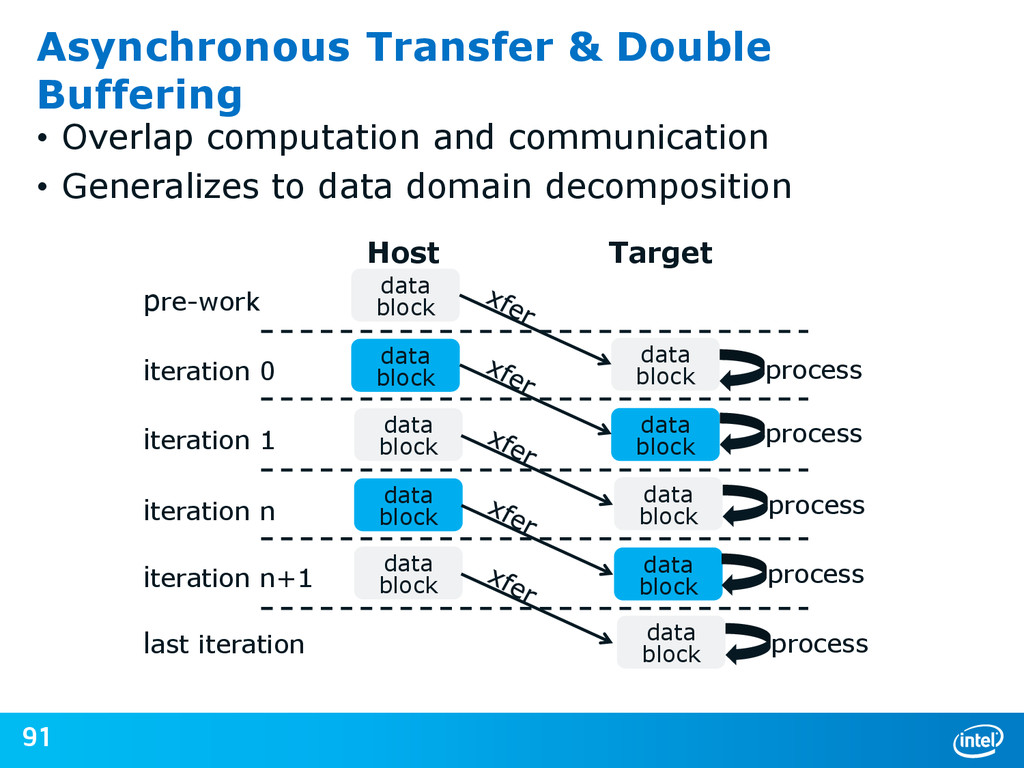{kind=link}
![92 Double Buffering I int main(int argc, char* argv[]) {](https://files.speakerdeck.com/presentations/5eca363090a50131d153667eabeb1a03/slide_91.jpg){kind=link}
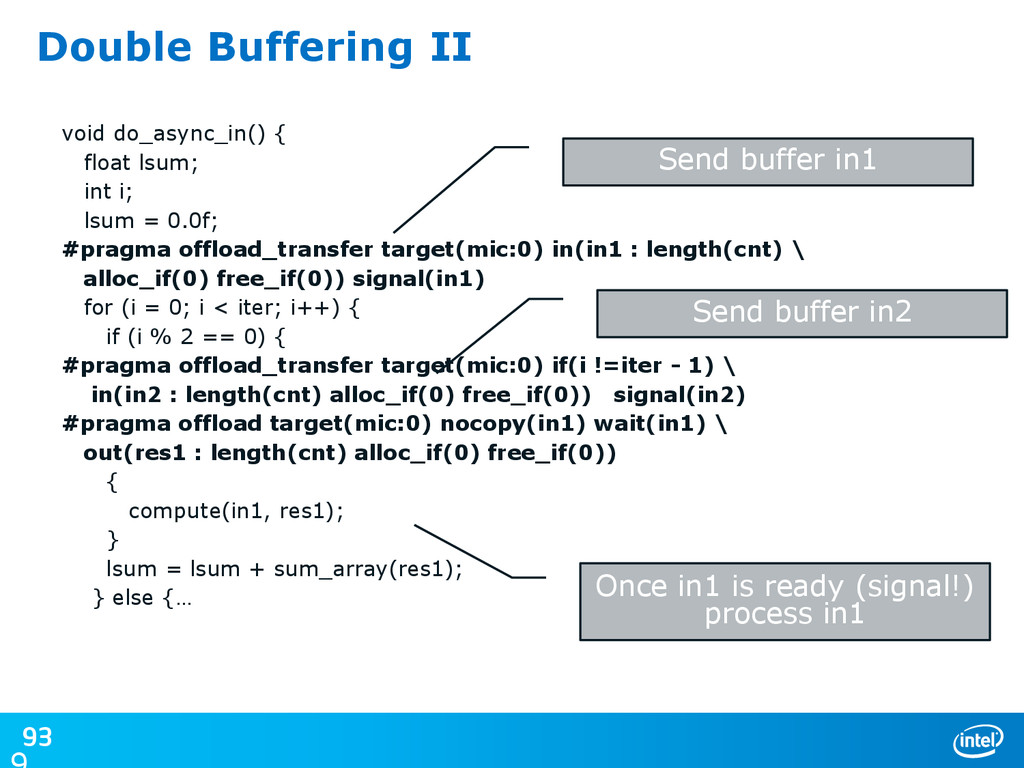{kind=link}
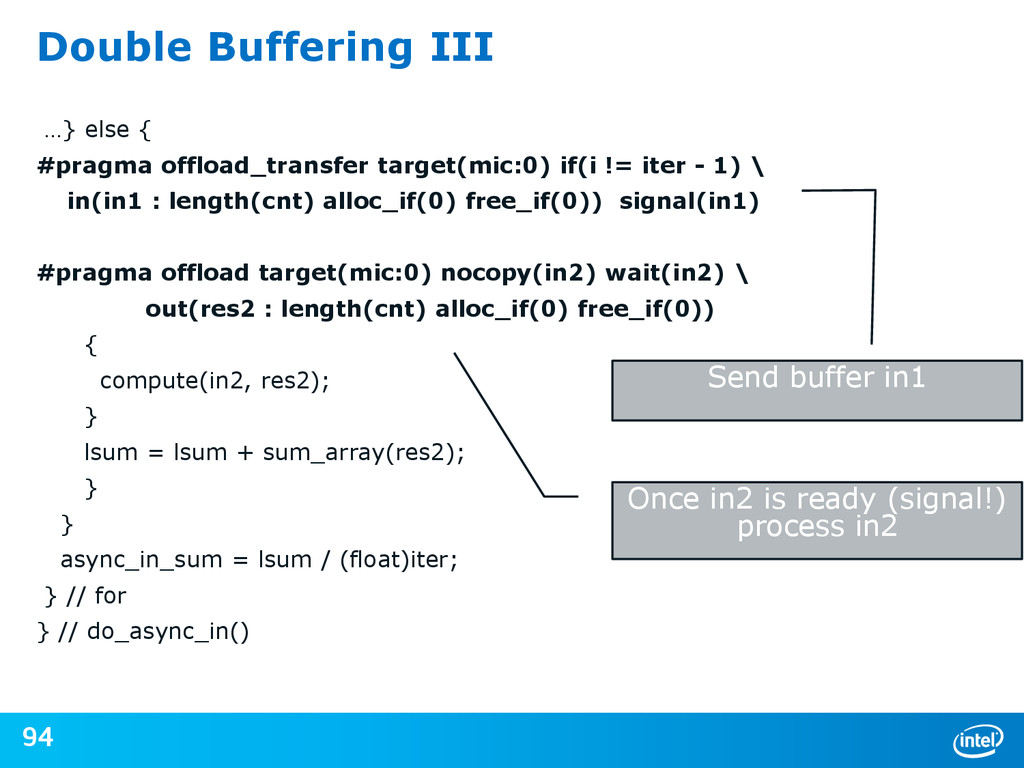{kind=link}
{kind=link}
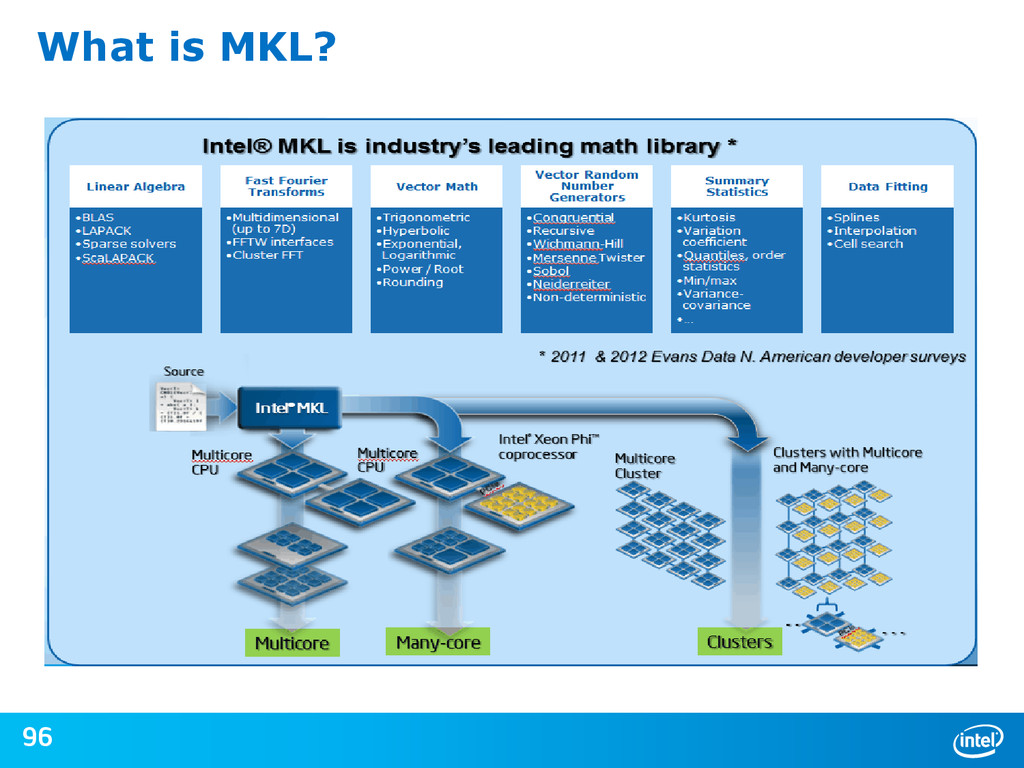{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
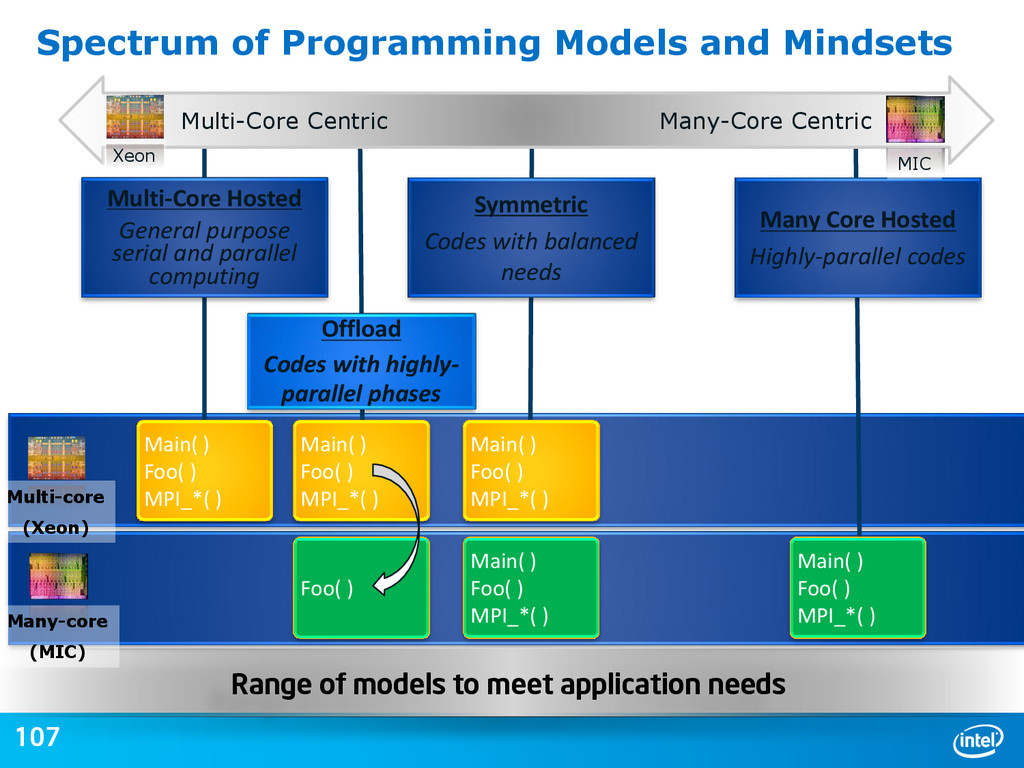{kind=link}
{kind=link}
{kind=link}
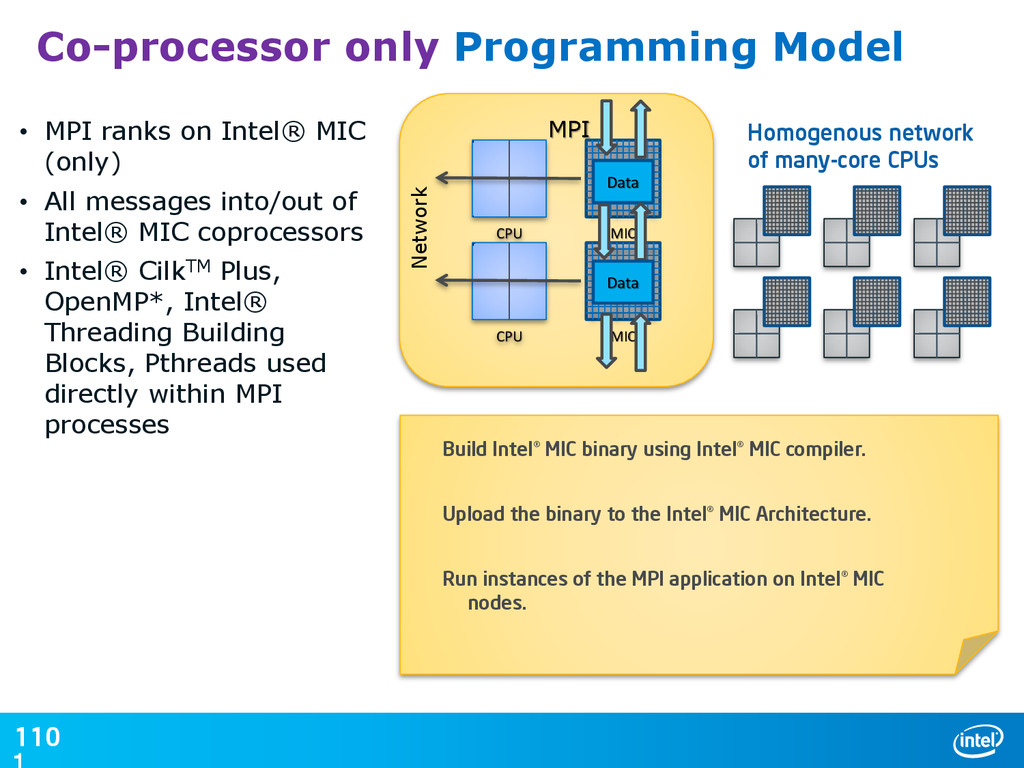{kind=link}
{kind=link}
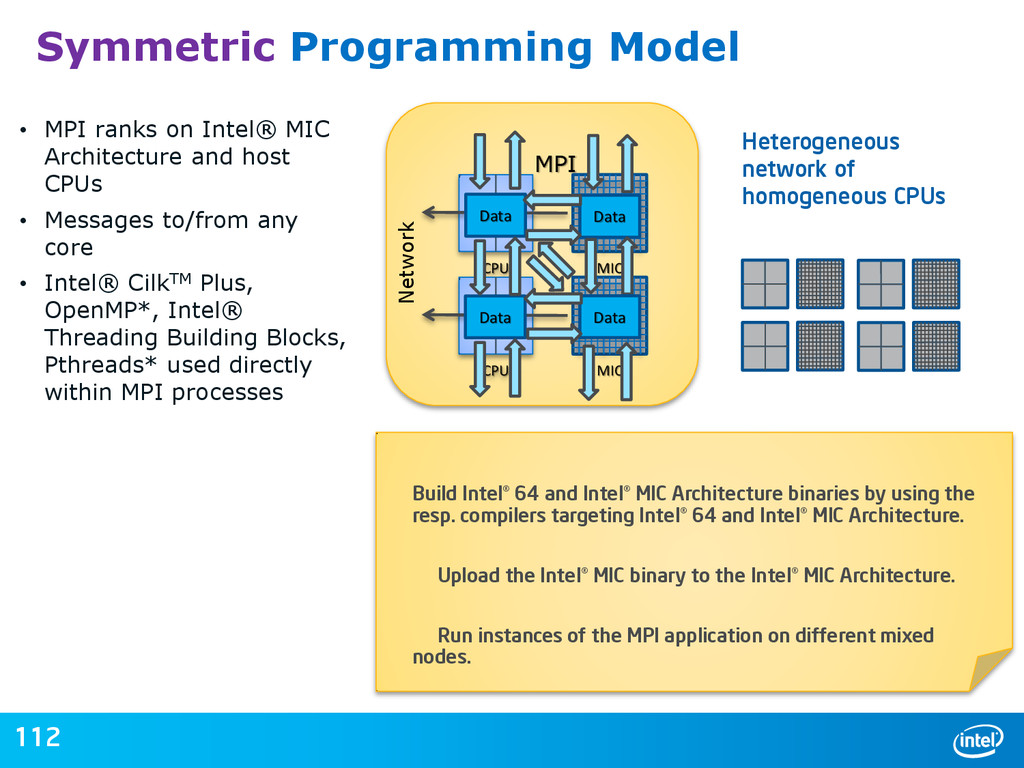{kind=link}
{kind=link}
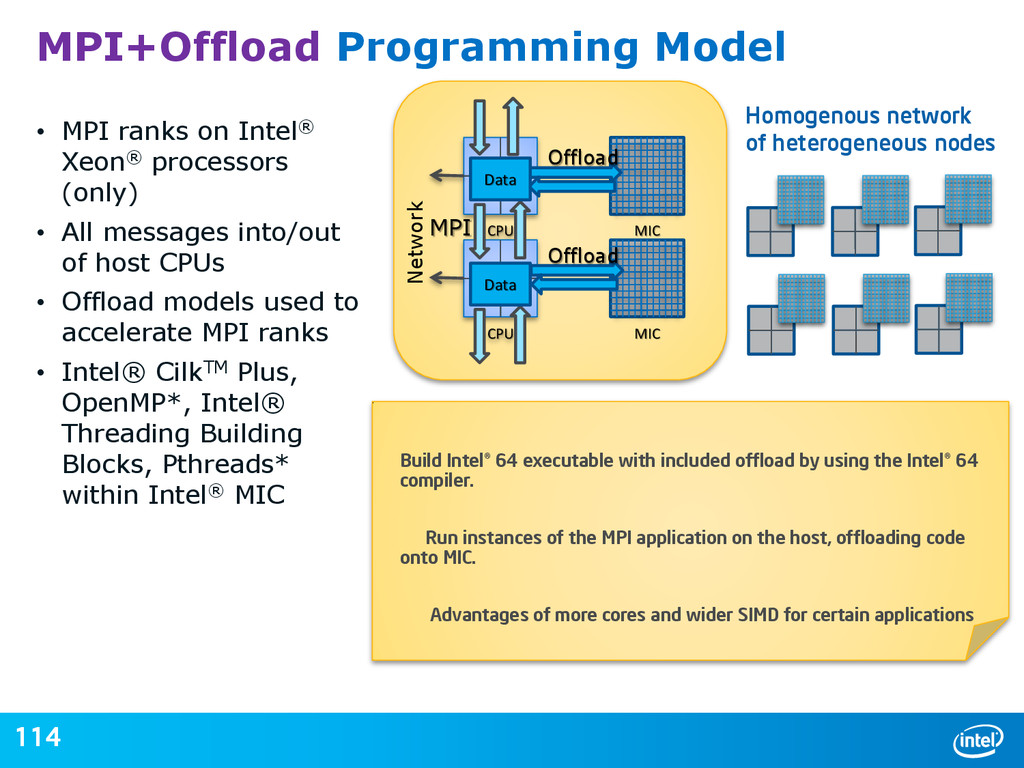{kind=link}
{kind=link}
{kind=link}
{kind=link}
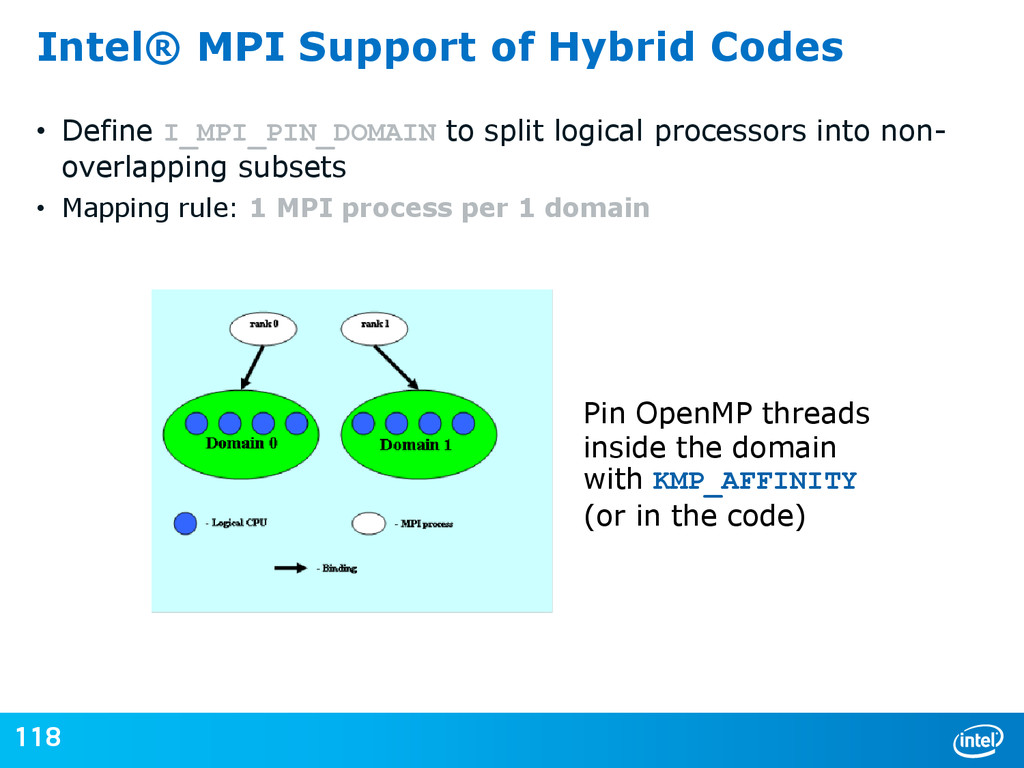{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
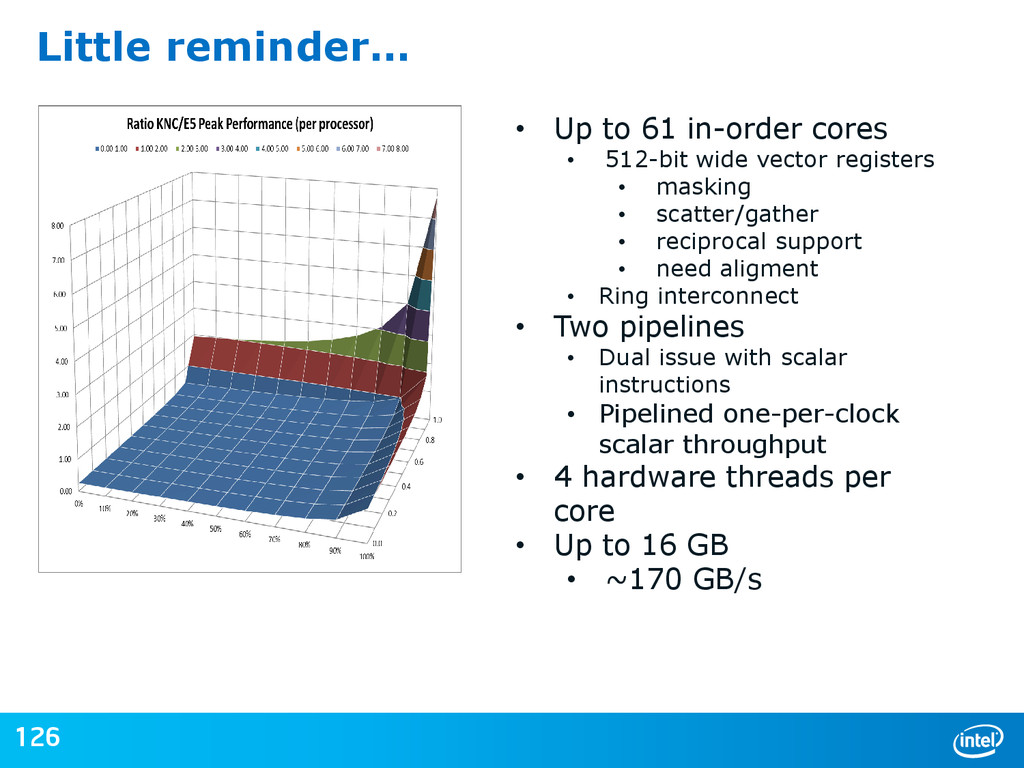{kind=link}
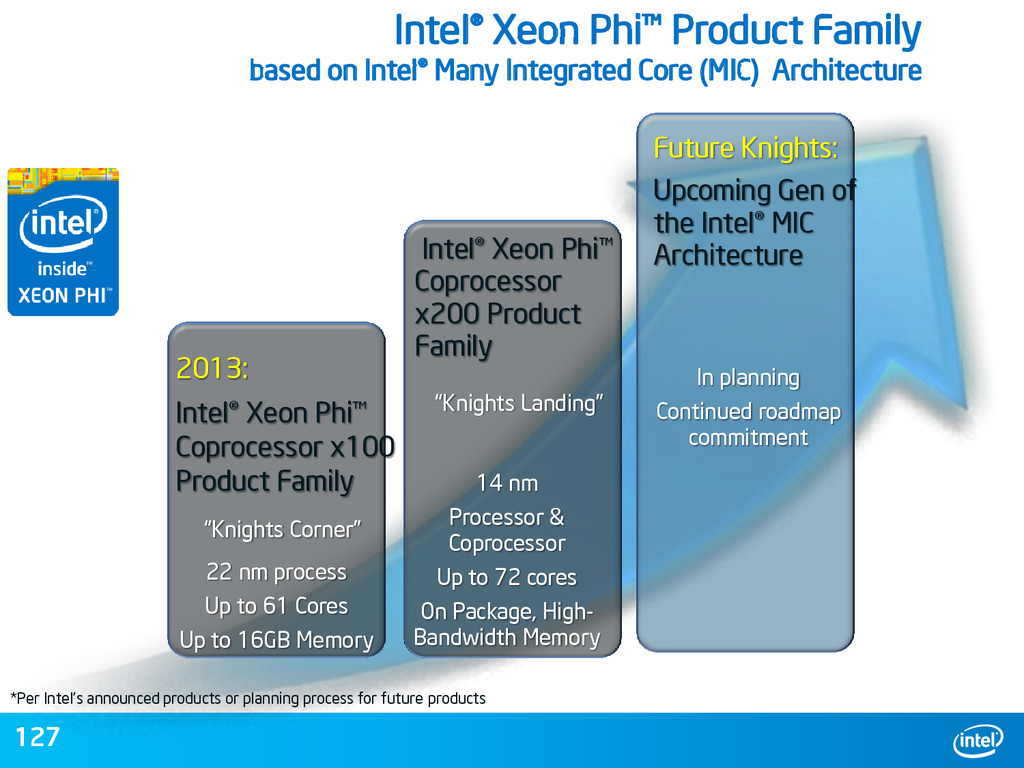{kind=link}
{kind=link}
{kind=link}
{kind=link}