Craig Stuntz Improving Enterprises
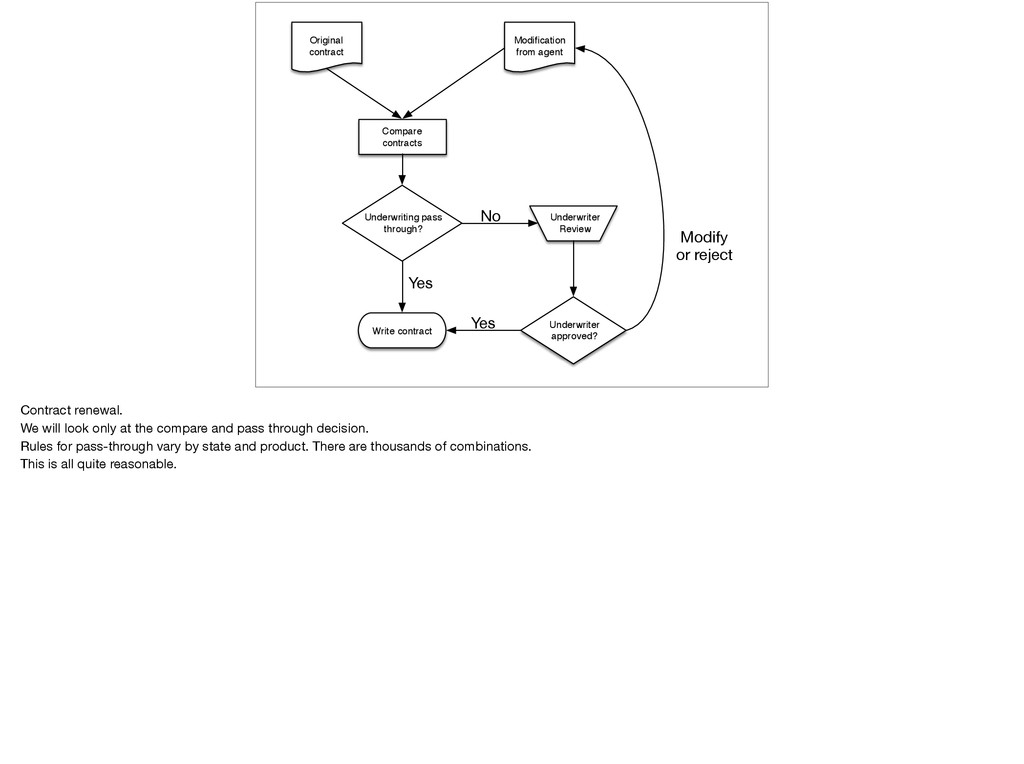
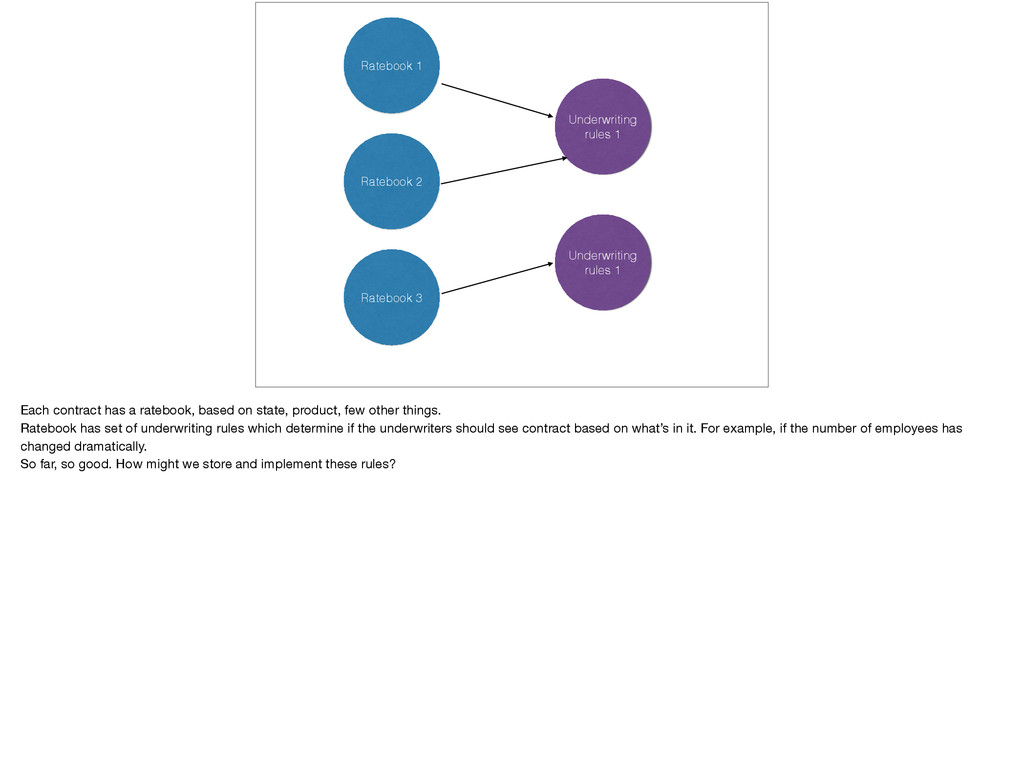
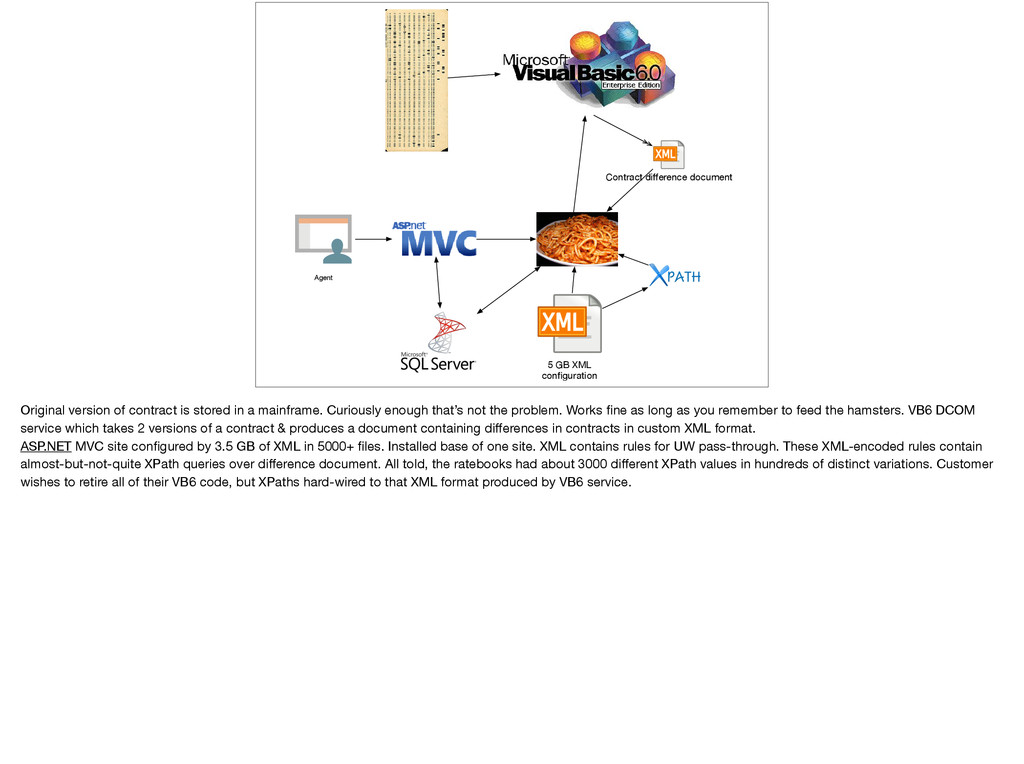
[email protected] Abstract— When you leave Lambda Jam and return to work, do you expect to apply what you’ve learned here to hard problems, or is there just never time or permission to venture outside of fixing “undefined is not a function" in JavaScript? Many of us do use functional languages, machine learning, proof assistants, parsing, and formal methods in our day jobs, and employment by a CS research department is not a prerequisite. As a consultant who wants to choose the most effective tool for the job and keep my customers happy in the process, I’ve developed a structured approach to finding ways to use the tools of the future (plus a few from the 70s!) in the enterprises of today. I’ll share that with you and examine research into the use of formal methods in other companies. I hope you will leave the talk This talk combines general techniques for finding freedom to use the best tool for the job with my real-world experience using F#, machine learning, parsing, and constructive logic in an organization with conservative architectural guidelines which forbid most of this explicitly. I’ll expand on this in the presentation, but the elevator pitch is: “Look for unpopular but potentially costly problems; find the looming technical debt that other developers are afraid to touch and use formal methods to break it wide open.” The running example is a smoldering tire fire of 3.5 GB of XML, custom-not-quite-XPath, multiple ad- hoc DSLs, and VB6 services used to configure a single web site in an otherwise successful business. I like to hack on compilers. People often say, “I studied [compilers, FP, etc.] in college, never touched it again.”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Craig Stuntz @craigstuntz [email protected] http://blogs.teamb.com/craigstuntz http://www.meetup.com/Papers-We-Love-Columbus/ Thanks so much for](https://files.speakerdeck.com/presentations/dd4b7b8caed7457daca904d06b3a974d/slide_48.jpg){kind=link}