agent (real or virtual) makes decisions in an environment. The state evolves with the actions performed by the agent. The transitions from one state to another can be: 3
agent (real or virtual) makes decisions in an environment. The state evolves with the actions performed by the agent. The transitions from one state to another can be: 1. deterministic (known in advance) → closing a door 3
agent (real or virtual) makes decisions in an environment. The state evolves with the actions performed by the agent. The transitions from one state to another can be: 1. deterministic (known in advance) → closing a door 2. stochastic (with probabilities) → the door may be locked 3
agent (real or virtual) makes decisions in an environment. The state evolves with the actions performed by the agent. The transitions from one state to another can be: 1. deterministic (known in advance) → closing a door 2. stochastic (with probabilities) → the door may be locked 3. etc. 3
agent (real or virtual) makes decisions in an environment. The state evolves with the actions performed by the agent. The transitions from one state to another can be: 1. deterministic (known in advance) → closing a door 2. stochastic (with probabilities) → the door may be locked 3. etc. Do the probabilities evolve with the time? no the environment is stationary yes the environment is non-stationary 3
decision-making problem 2. under uncertainty (with stochastic dynamics) 3. in non-stationary environments Many problems fall into this category (MAS, exogenous events, etc.). 4
decision-making problem 2. under uncertainty (with stochastic dynamics) 3. in non-stationary environments Many problems fall into this category (MAS, exogenous events, etc.). The non-stationarity makes the problem very hard to solve. 4
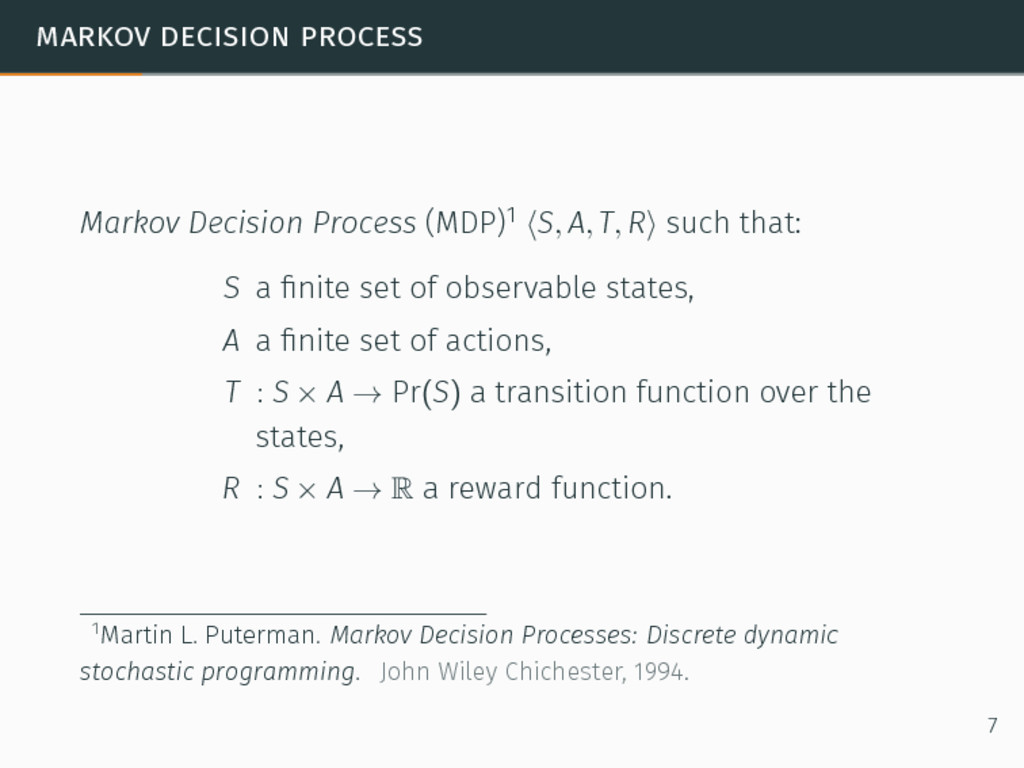
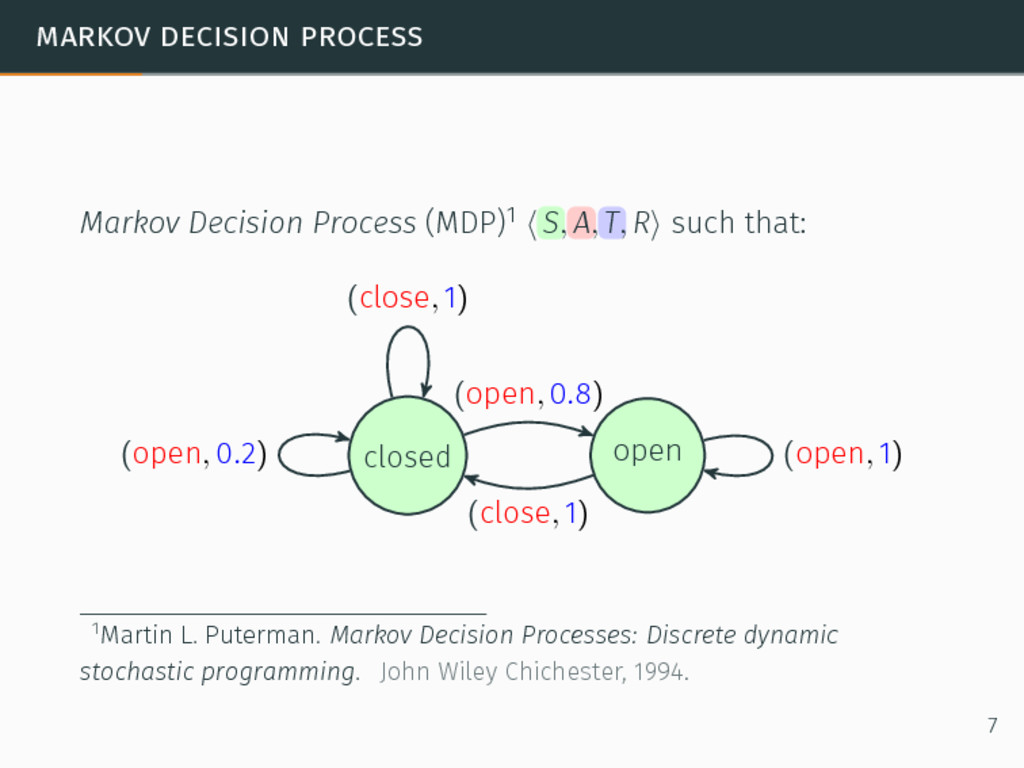
R⟩ such that: S a finite set of observable states, 1Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 7
R⟩ such that: S a finite set of observable states, A a finite set of actions, 1Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 7
R⟩ such that: S a finite set of observable states, A a finite set of actions, T : S × A → Pr(S) a transition function over the states, 1Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 7
R⟩ such that: S a finite set of observable states, A a finite set of actions, T : S × A → Pr(S) a transition function over the states, R : S × A → R a reward function. 1Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 7
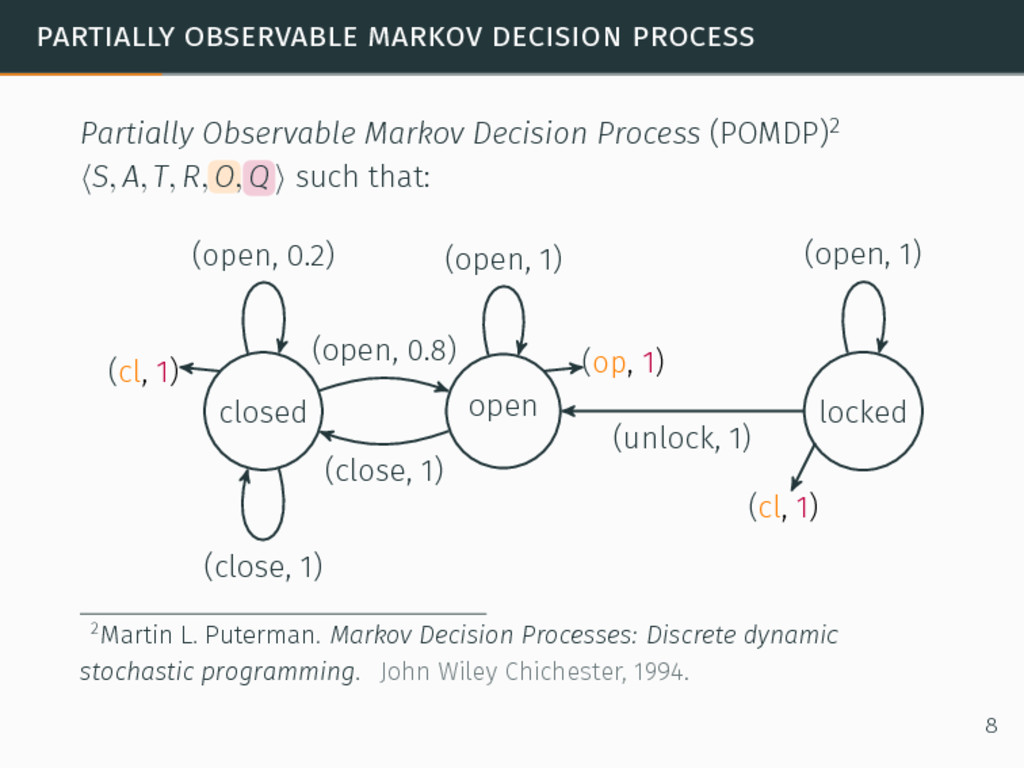
(POMDP)2 ⟨S, A, T, R, O, Q⟩ such that: 2Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 8
(POMDP)2 ⟨S, A, T, R, O, Q⟩ such that: S, A, T, R as in MDPs, with S non-observable, 2Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 8
(POMDP)2 ⟨S, A, T, R, O, Q⟩ such that: S, A, T, R as in MDPs, with S non-observable, O a finite set of observations, 2Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 8
(POMDP)2 ⟨S, A, T, R, O, Q⟩ such that: S, A, T, R as in MDPs, with S non-observable, O a finite set of observations, Q : S → Pr(O) an observation function. 2Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 8
(POMDP)2 ⟨S, A, T, R, O, Q⟩ such that: S, A, T, R as in MDPs, with S non-observable, O a finite set of observations, Q : S → Pr(O) an observation function. As the state is not observable → belief state, a distribution of probabilities on all possible current states. 2Martin L. Puterman. Markov Decision Processes: Discrete dynamic stochastic programming. John Wiley Chichester, 1994. 8
(MOMDP)3 ⟨Sv, Sh, A, T, R, Ov, Oh, Q⟩ such that: 3S.C.W. Ong et al. “Planning under uncertainty for robotic tasks with mixed observability”. In: The International Journal of Robotics Research. 2010. 9
(MOMDP)3 ⟨Sv, Sh, A, T, R, Ov, Oh, Q⟩ such that: Sv, Sh the visible and hidden parts of the state, 3S.C.W. Ong et al. “Planning under uncertainty for robotic tasks with mixed observability”. In: The International Journal of Robotics Research. 2010. 9
(MOMDP)3 ⟨Sv, Sh, A, T, R, Ov, Oh, Q⟩ such that: Sv, Sh the visible and hidden parts of the state, Ov, Oh the observations on the visible part and the hidden part of the state, 3S.C.W. Ong et al. “Planning under uncertainty for robotic tasks with mixed observability”. In: The International Journal of Robotics Research. 2010. 9
(MOMDP)3 ⟨Sv, Sh, A, T, R, Ov, Oh, Q⟩ such that: Sv, Sh the visible and hidden parts of the state, Ov, Oh the observations on the visible part and the hidden part of the state, A, T, R, Q as before. 3S.C.W. Ong et al. “Planning under uncertainty for robotic tasks with mixed observability”. In: The International Journal of Robotics Research. 2010. 9
(MOMDP)3 ⟨Sv, Sh, A, T, R, Ov, Oh, Q⟩ such that: Sv, Sh the visible and hidden parts of the state, Ov, Oh the observations on the visible part and the hidden part of the state, A, T, R, Q as before. Note that ⟨Sv × Sh = S, A, T, R, Ov × Oh = O, Q⟩ is a POMDP. 3S.C.W. Ong et al. “Planning under uncertainty for robotic tasks with mixed observability”. In: The International Journal of Robotics Research. 2010. 9
the previous example, that there is the possible presence of a key on the door lock: Sv {key, no key}, Sh {open, closed, locked}, Ov {k, n-k}, Oh {op, cl}. 10
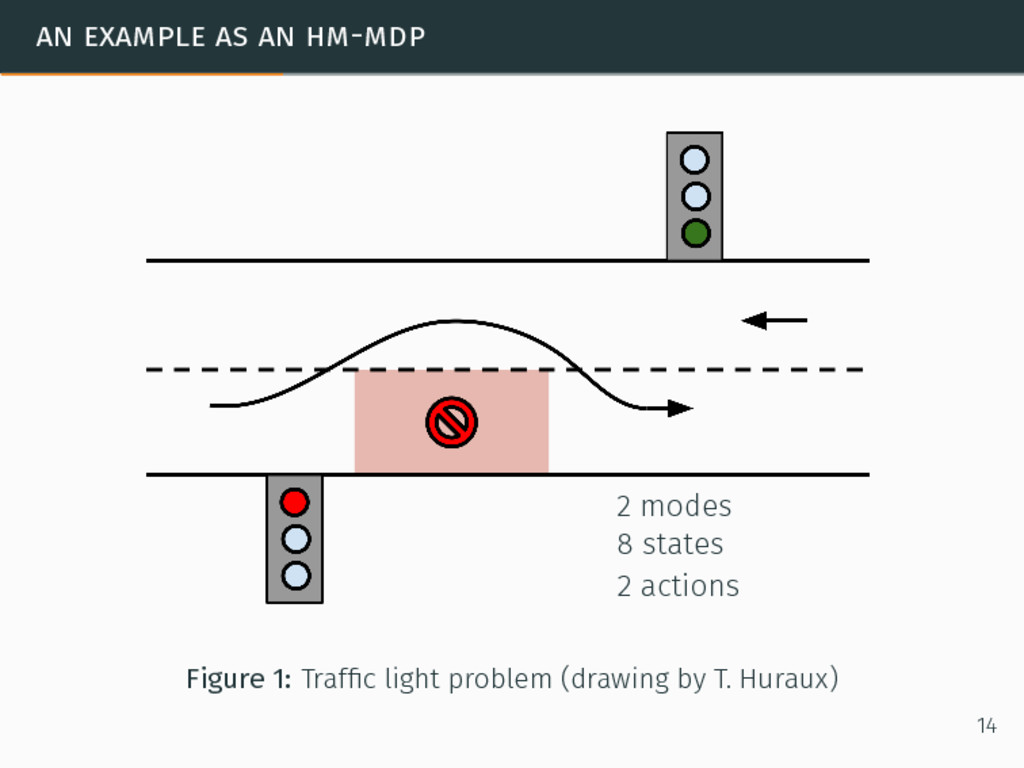
mandatory stationarity. It is a limitation in many cases but we cannot take into account all types of non-stationarity. One assumption The non-stationarity is limited to a set of stationary modes, or contexts. 11
we can use Hidden-Mode Markov Decision Processes (HM-MDPs)4. 4S.P.-M. Choi, N.L. Zhang, and D.-Y. Yeung. “Solving Hidden-Mode Markov Decision Problems”. In: Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics (AISTATS). 2001, pp. 19–26. 13
we can use Hidden-Mode Markov Decision Processes (HM-MDPs)4. ⟨M, C⟩ such that: 4S.P.-M. Choi, N.L. Zhang, and D.-Y. Yeung. “Solving Hidden-Mode Markov Decision Problems”. In: Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics (AISTATS). 2001, pp. 19–26. 13
we can use Hidden-Mode Markov Decision Processes (HM-MDPs)4. ⟨M, C⟩ such that: M a set of modes → mi = ⟨S, A, Ti, Ri⟩, ∀mi ∈ M, 4S.P.-M. Choi, N.L. Zhang, and D.-Y. Yeung. “Solving Hidden-Mode Markov Decision Problems”. In: Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics (AISTATS). 2001, pp. 19–26. 13
we can use Hidden-Mode Markov Decision Processes (HM-MDPs)4. ⟨M, C⟩ such that: M a set of modes → mi = ⟨S, A, Ti, Ri⟩, ∀mi ∈ M, C : M → Pr(M) a transition function over modes. 4S.P.-M. Choi, N.L. Zhang, and D.-Y. Yeung. “Solving Hidden-Mode Markov Decision Problems”. In: Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics (AISTATS). 2001, pp. 19–26. 13
we can use Hidden-Mode Markov Decision Processes (HM-MDPs)4. ⟨M, C⟩ such that: M a set of modes → mi = ⟨S, A, Ti, Ri⟩, ∀mi ∈ M, C : M → Pr(M) a transition function over modes. S and A are common to each modes mi ∈ M. 4S.P.-M. Choi, N.L. Zhang, and D.-Y. Yeung. “Solving Hidden-Mode Markov Decision Problems”. In: Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics (AISTATS). 2001, pp. 19–26. 13
we can use Hidden-Mode Markov Decision Processes (HM-MDPs)4. ⟨M, C⟩ such that: M a set of modes → mi = ⟨S, A, Ti, Ri⟩, ∀mi ∈ M, C : M → Pr(M) a transition function over modes. S and A are common to each modes mi ∈ M. S is observable, M is not. 4S.P.-M. Choi, N.L. Zhang, and D.-Y. Yeung. “Solving Hidden-Mode Markov Decision Problems”. In: Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics (AISTATS). 2001, pp. 19–26. 13
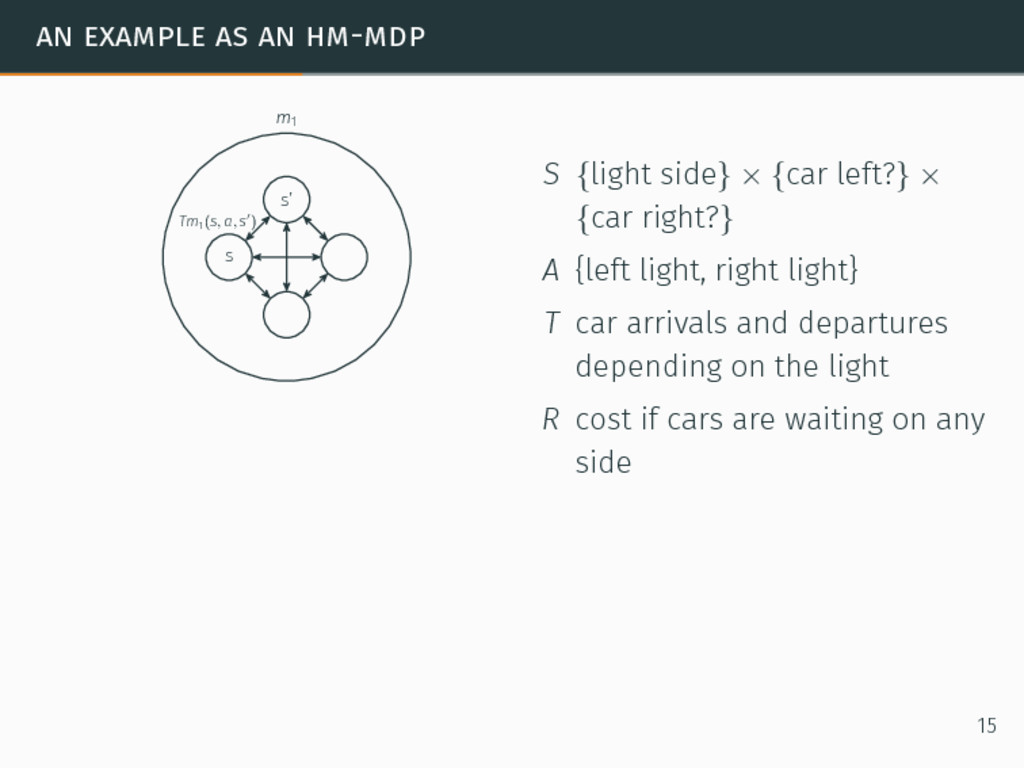
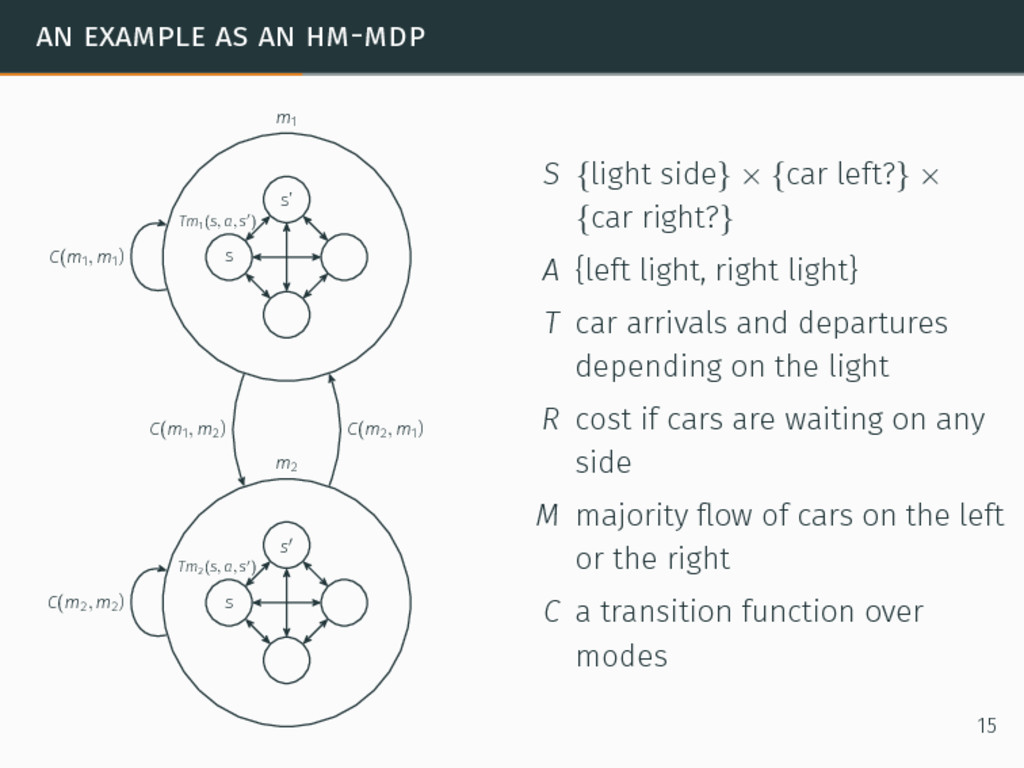
m1 S {light side} × {car left?} × {car right?} A {left light, right light} T car arrivals and departures depending on the light R cost if cars are waiting on any side 15
m1 s′ s Tm2(s, a, s′) m2 C(m1, m2 ) C(m2, m1 ) C(m1, m1 ) C(m2, m2 ) S {light side} × {car left?} × {car right?} A {left light, right light} T car arrivals and departures depending on the light R cost if cars are waiting on any side M majority flow of cars on the left or the right C a transition function over modes 15
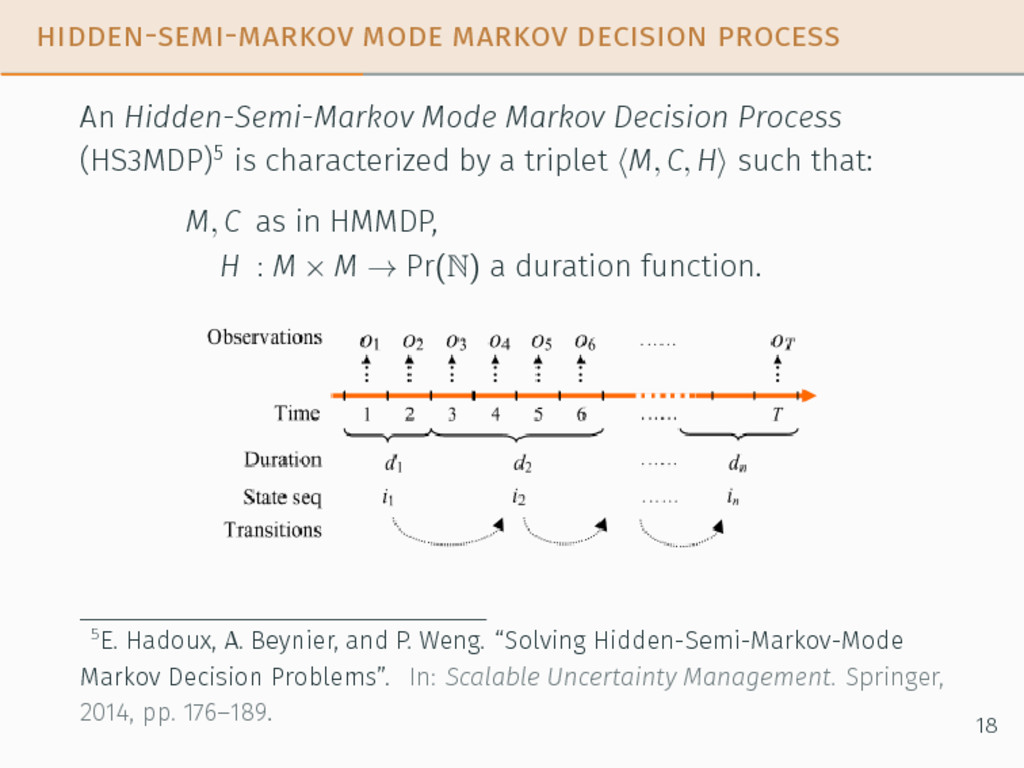
Process (HS3MDP)5 is characterized by a triplet ⟨M, C, H⟩ such that: 5E. Hadoux, A. Beynier, and P. Weng. “Solving Hidden-Semi-Markov-Mode Markov Decision Problems”. In: Scalable Uncertainty Management. Springer, 2014, pp. 176–189. 18
Process (HS3MDP)5 is characterized by a triplet ⟨M, C, H⟩ such that: M, C as in HMMDP, 5E. Hadoux, A. Beynier, and P. Weng. “Solving Hidden-Semi-Markov-Mode Markov Decision Problems”. In: Scalable Uncertainty Management. Springer, 2014, pp. 176–189. 18
Process (HS3MDP)5 is characterized by a triplet ⟨M, C, H⟩ such that: M, C as in HMMDP, H : M × M → Pr(N) a duration function. 5E. Hadoux, A. Beynier, and P. Weng. “Solving Hidden-Semi-Markov-Mode Markov Decision Problems”. In: Scalable Uncertainty Management. Springer, 2014, pp. 176–189. 18
Process (HS3MDP)5 is characterized by a triplet ⟨M, C, H⟩ such that: M, C as in HMMDP, H : M × M → Pr(N) a duration function. 5E. Hadoux, A. Beynier, and P. Weng. “Solving Hidden-Semi-Markov-Mode Markov Decision Problems”. In: Scalable Uncertainty Management. Springer, 2014, pp. 176–189. 18
Process (HS3MDP)5 is characterized by a triplet ⟨M, C, H⟩ such that: M, C as in HMMDP, H : M × M → Pr(N) a duration function. New duration h after a decision step in mode m if h > 0 m′ = m, h′ = h − 1 if h = 0 m′ ∼ C(m, ·), h′ = k − 1 where k ∼ H(m, m′, ·) 5E. Hadoux, A. Beynier, and P. Weng. “Solving Hidden-Semi-Markov-Mode Markov Decision Problems”. In: Scalable Uncertainty Management. Springer, 2014, pp. 176–189. 18
a (potentially infinite) HM-MDP. Conversion • An HS3MDP is a subclass of MOMDP (S → Sv , M, H → Sh ), • An HS3MDP can be rewritten as a POMDP (as MOMDP is a subclass of POMDP). 19
a (potentially infinite) HM-MDP. Conversion • An HS3MDP is a subclass of MOMDP (S → Sv , M, H → Sh ), • An HS3MDP can be rewritten as a POMDP (as MOMDP is a subclass of POMDP). Solving Therefore, MO/POMDP algorithms can be used with HS3MDPs. But finding an optimal policy is PSPACE-complet → scalability problem ⇒ approximate solution 19
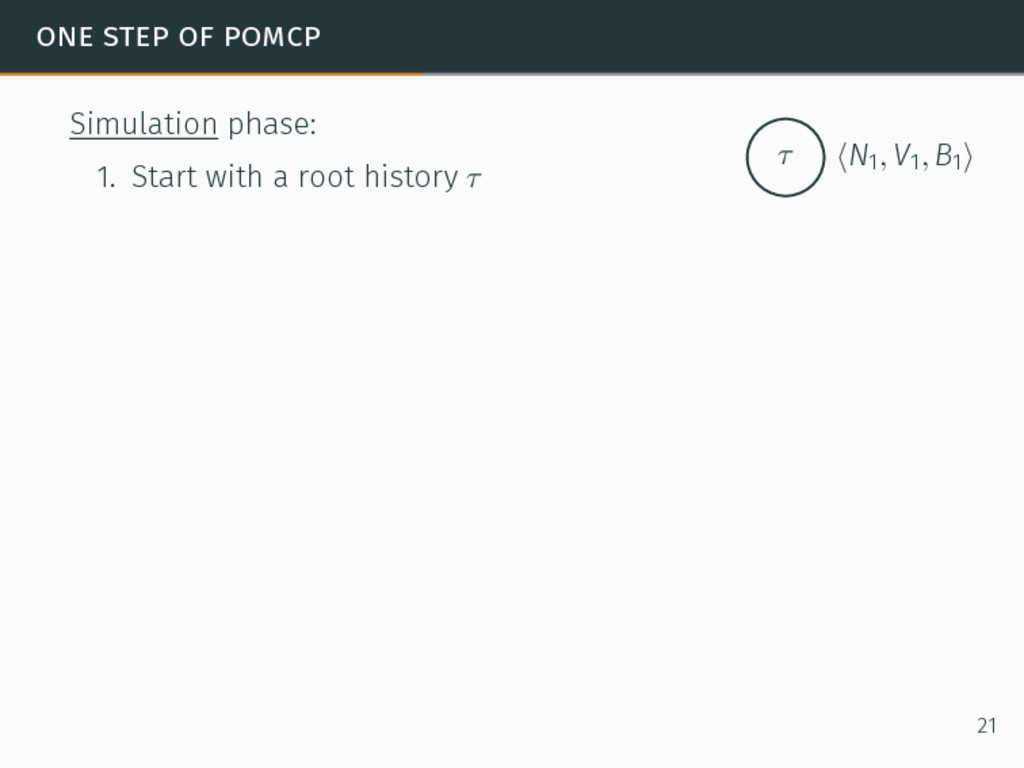
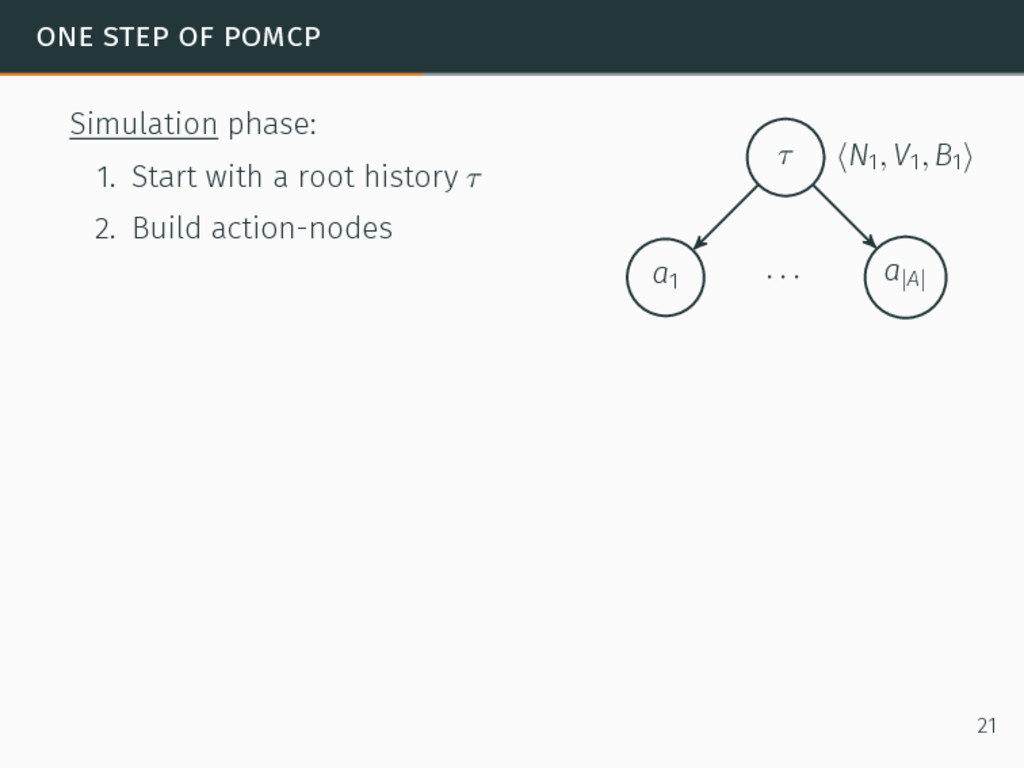
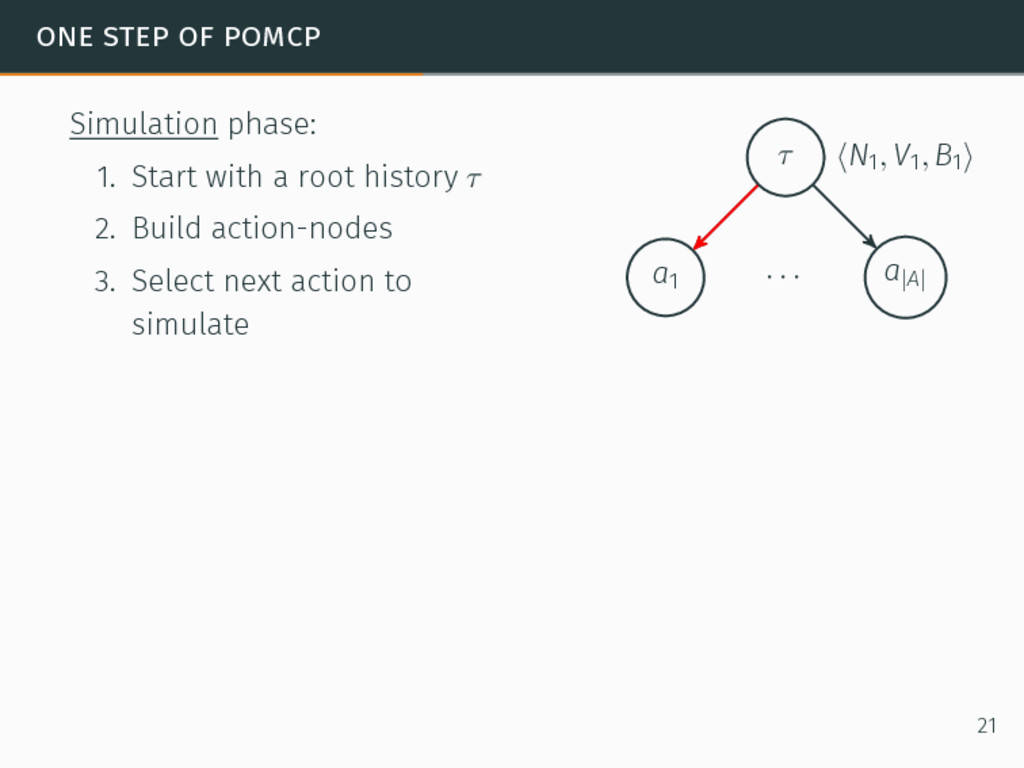
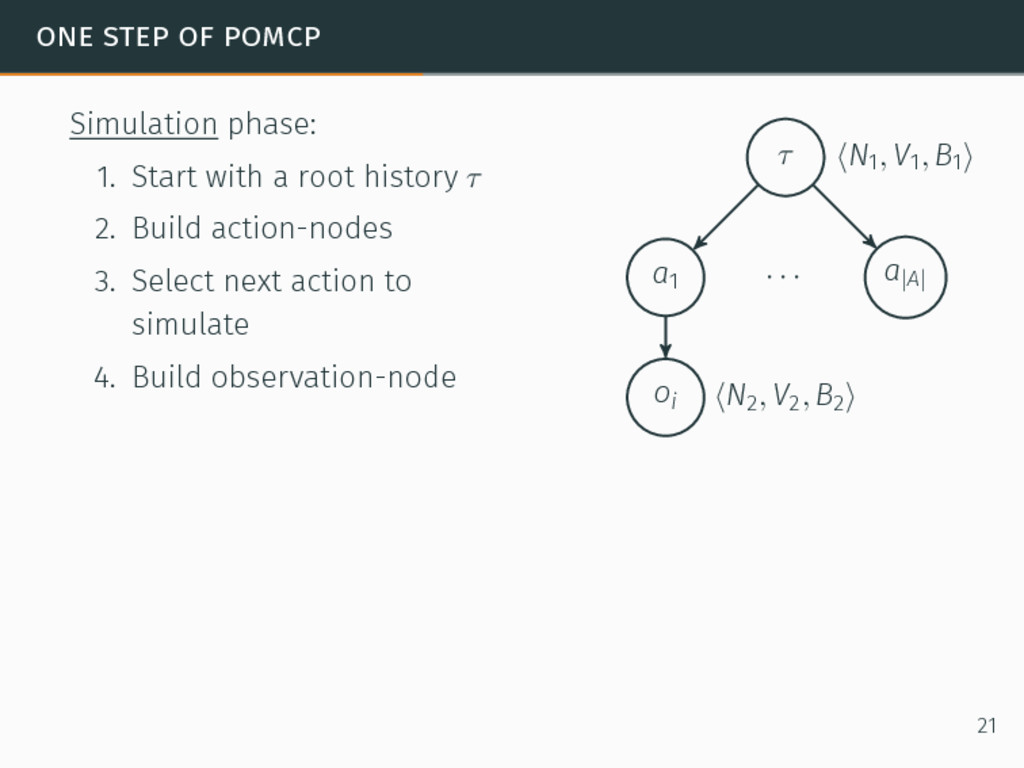
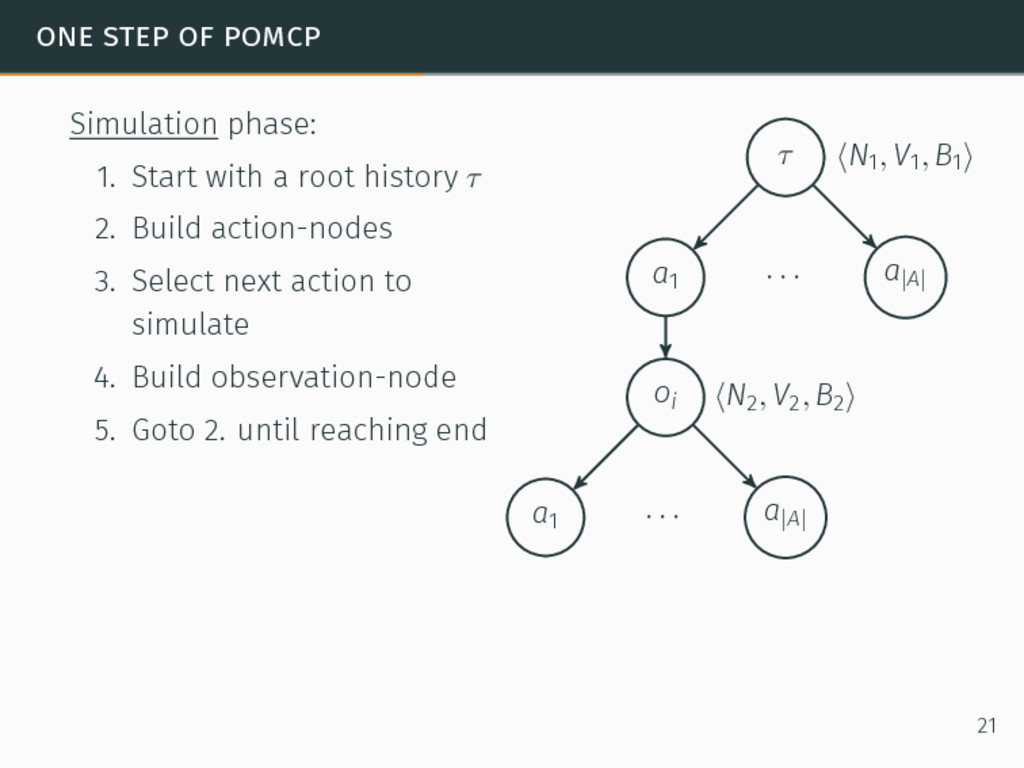
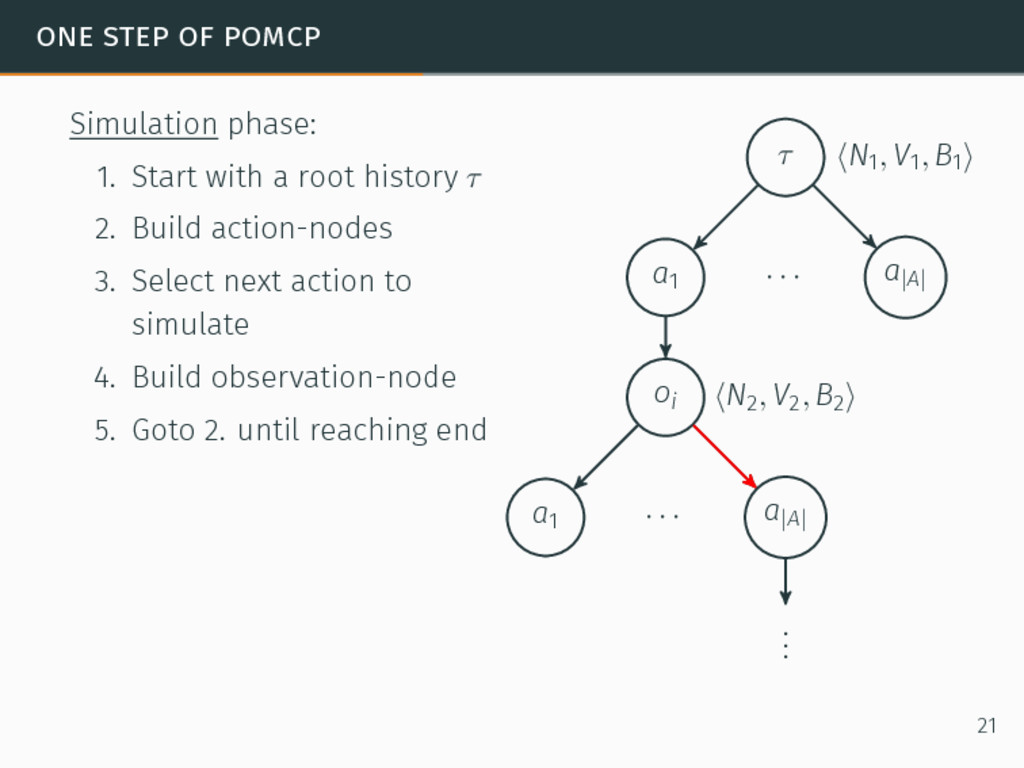
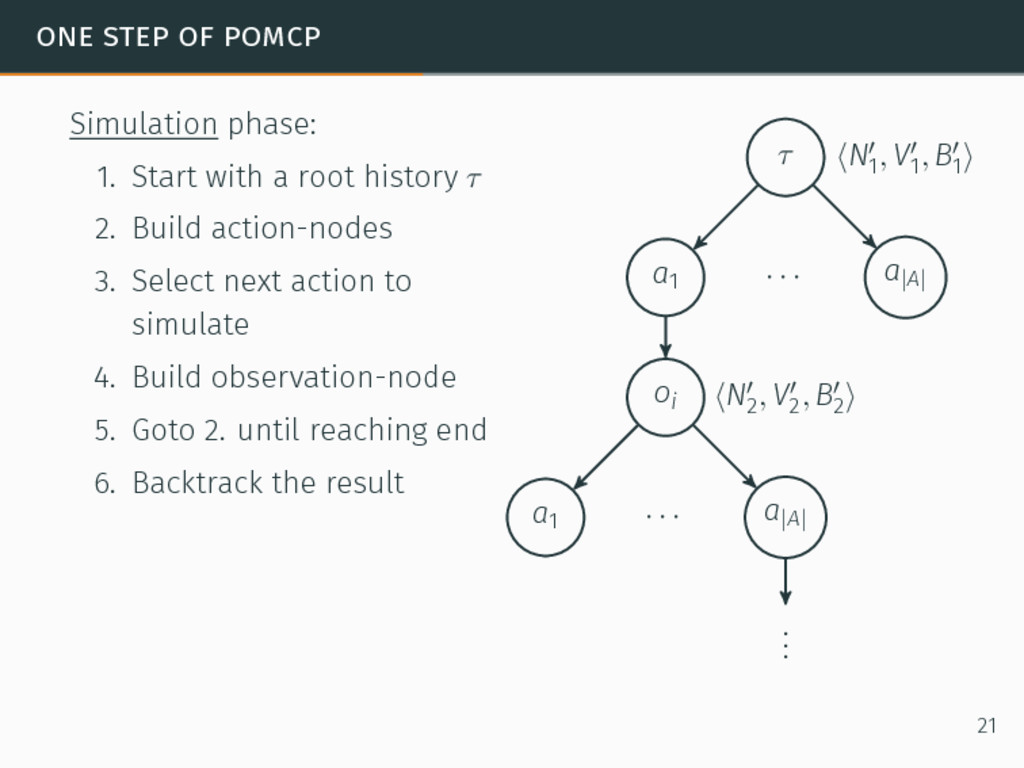
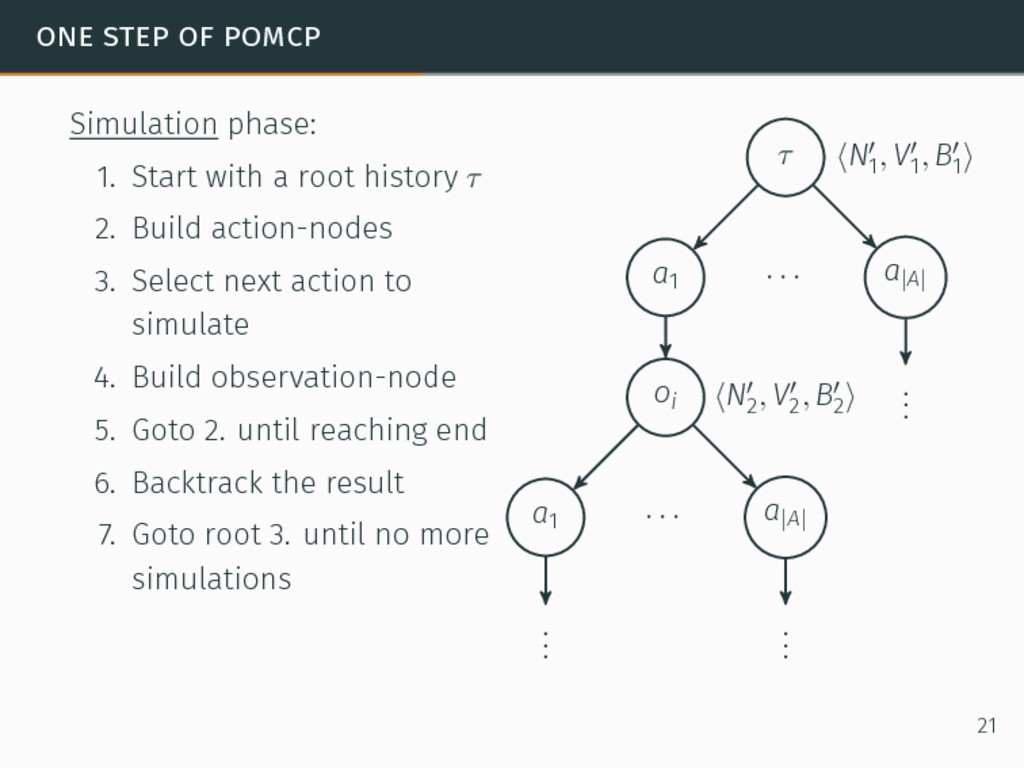
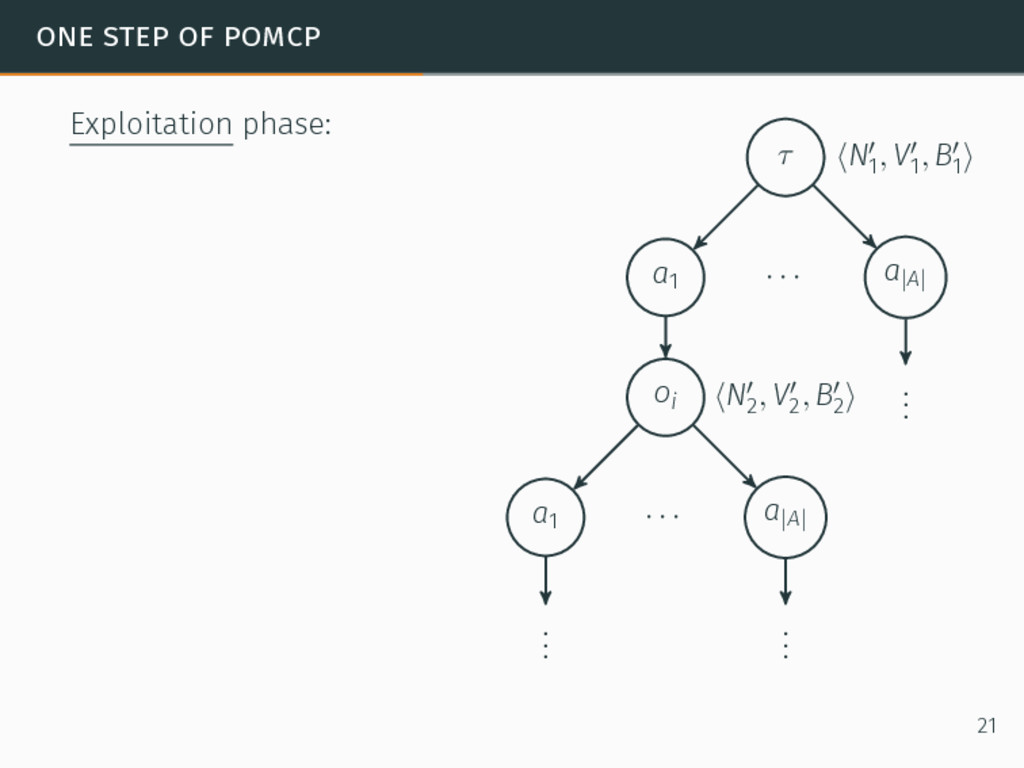
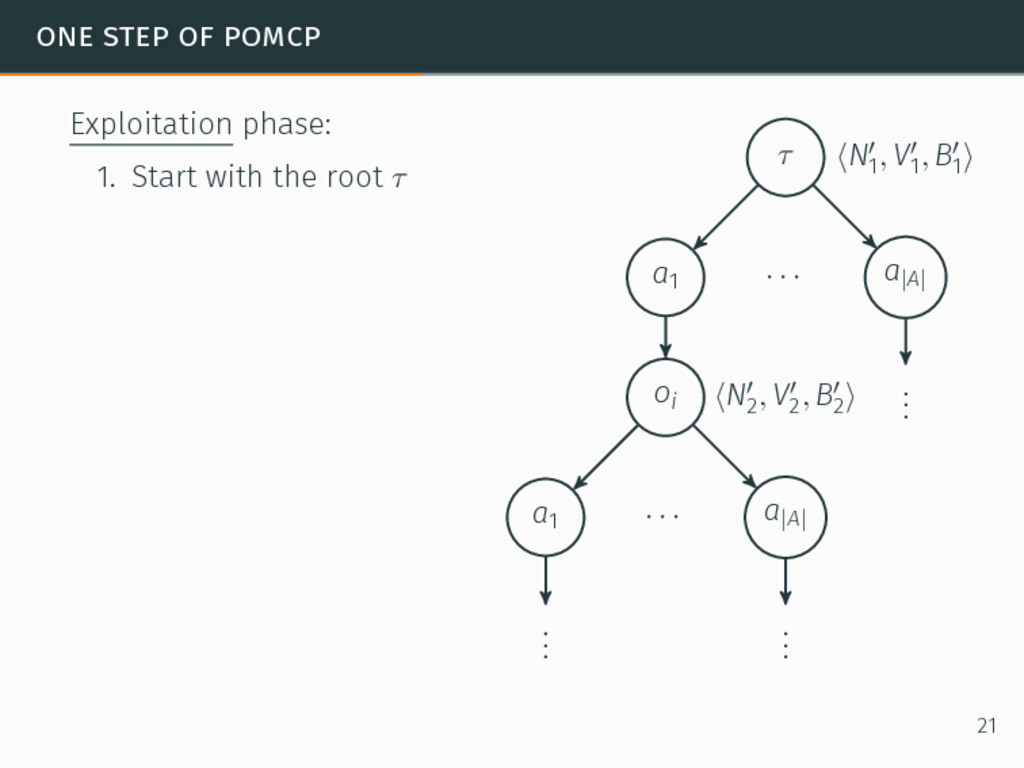
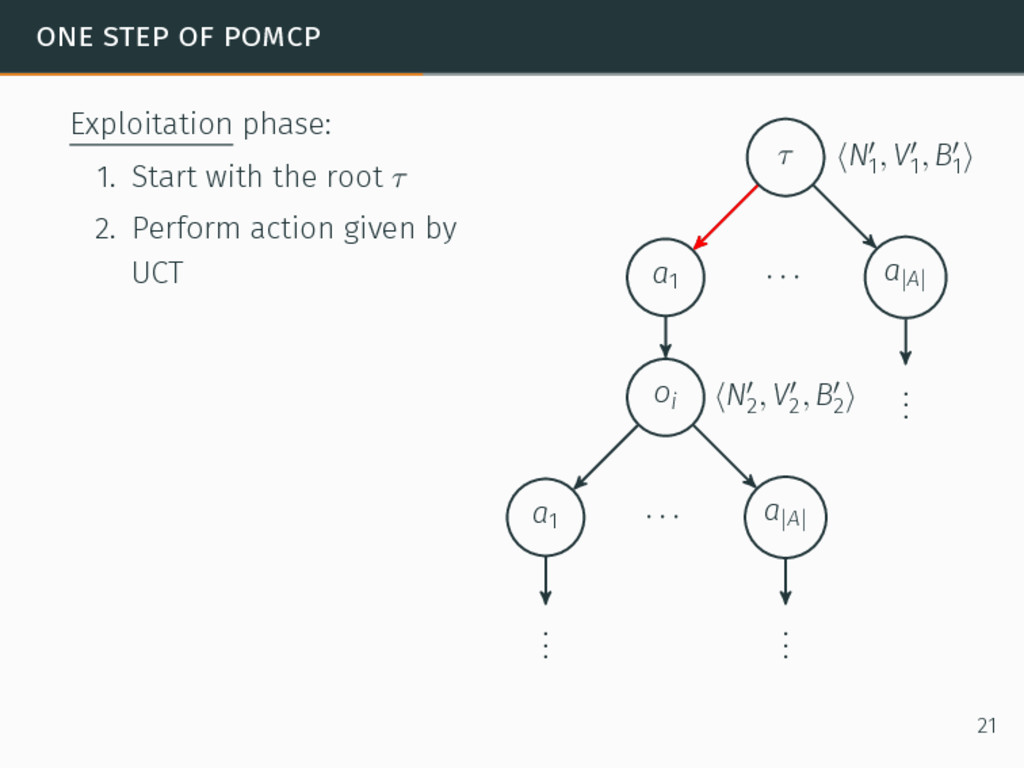
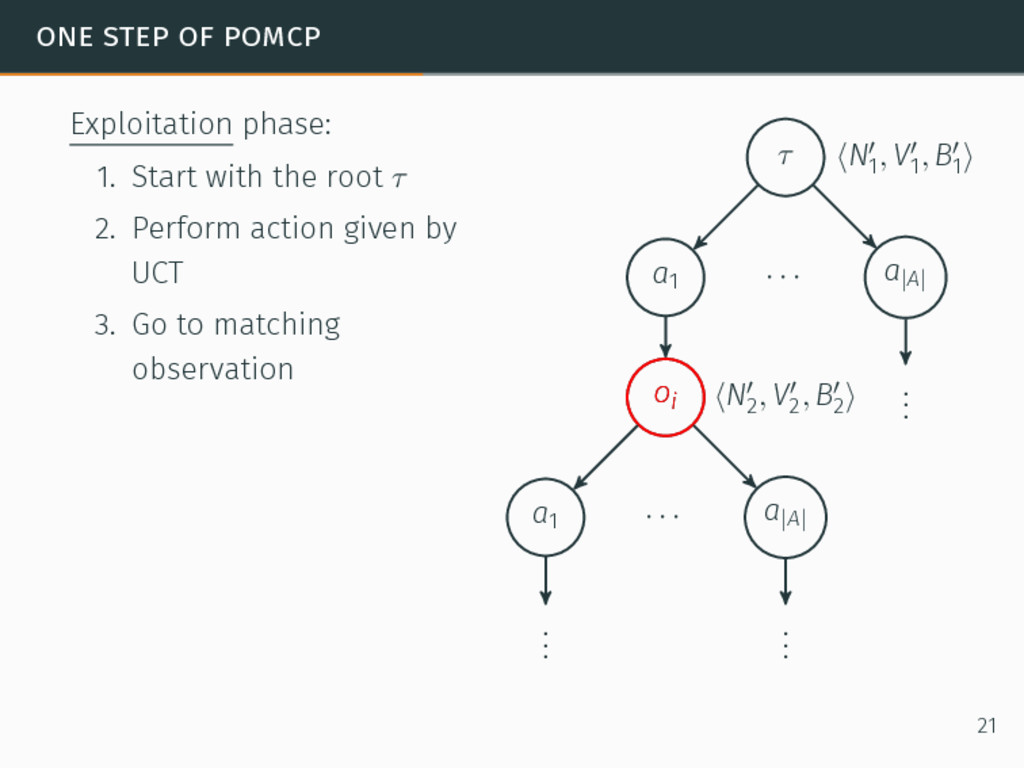
one of the most efficient algorithms for large-sized POMDPs. POMCP characteristics 6David Silver and Joel Veness. “Monte-Carlo planning in large POMDPs”. In: Proceedings of the 24th Conference on Neural Information Processing Systems (NIPS). 2010, pp. 2164–2172. 20
one of the most efficient algorithms for large-sized POMDPs. POMCP characteristics • Uses a set of particles to approximate the belief state, 6David Silver and Joel Veness. “Monte-Carlo planning in large POMDPs”. In: Proceedings of the 24th Conference on Neural Information Processing Systems (NIPS). 2010, pp. 2164–2172. 20
one of the most efficient algorithms for large-sized POMDPs. POMCP characteristics • Uses a set of particles to approximate the belief state, • One particle = one state → ∞ particles = belief state, 6David Silver and Joel Veness. “Monte-Carlo planning in large POMDPs”. In: Proceedings of the 24th Conference on Neural Information Processing Systems (NIPS). 2010, pp. 2164–2172. 20
one of the most efficient algorithms for large-sized POMDPs. POMCP characteristics • Uses a set of particles to approximate the belief state, • One particle = one state → ∞ particles = belief state, • Requires a simulator of the problem → relaxation of the known-model constraint. 6David Silver and Joel Veness. “Monte-Carlo planning in large POMDPs”. In: Proceedings of the 24th Conference on Neural Information Processing Systems (NIPS). 2010, pp. 2164–2172. 20
We defined two adaptations of POMCP for HS3MDPs: 1. Adaptation to the structure 2. Exact representation of the belief state Adaptation to the structure (SA) In HS3MDP, a state = a visible part and a hidden part. The former can be removed from the particle representation as it is directly observed. → a particle = a possible hidden part 23
We defined two adaptations of POMCP for HS3MDPs: 1. Adaptation to the structure 2. Exact representation of the belief state Exact representation of the belief state (SAER) Replace the sets of particles by the exact distribution µ: µ′(m′, h′) = 1 K ( Tm′ (s, a, s′) × µ(m′, h′ + 1) + ∑ m∈M C(m, m′) × Tm(s, a, s′) × µ(m, 0) × H(m, m′, h′ + 1) ) Complexity: O(|M| × hmax) ≷ O(N) with N the number of sim- ulations in the original POMCP 23
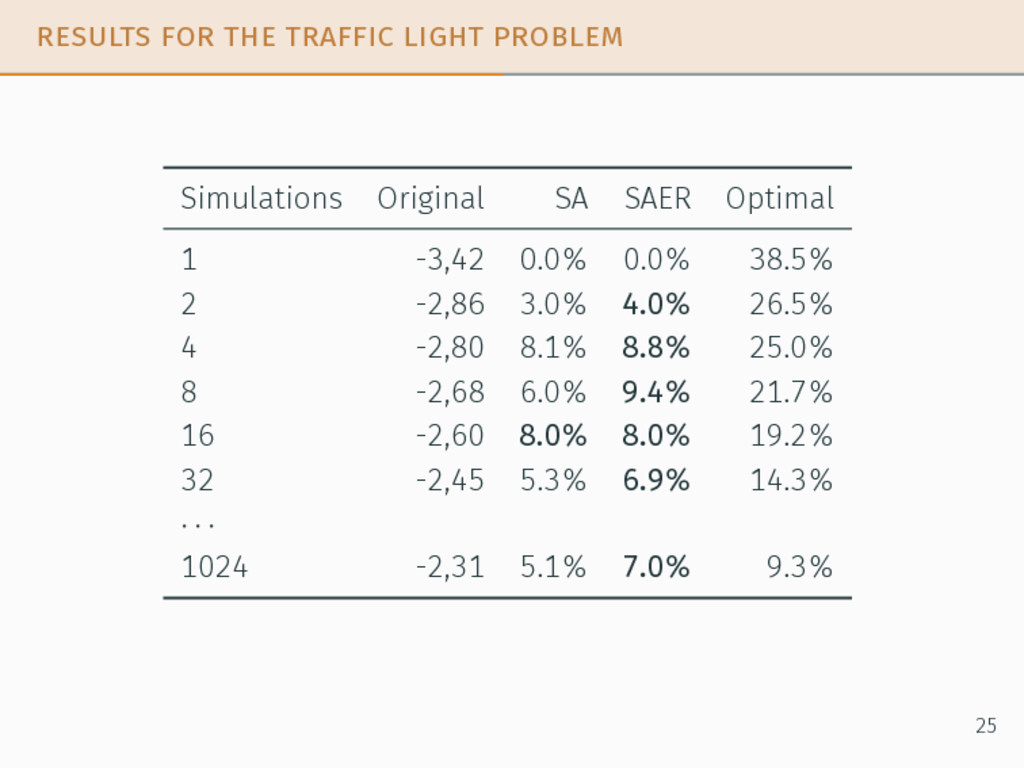
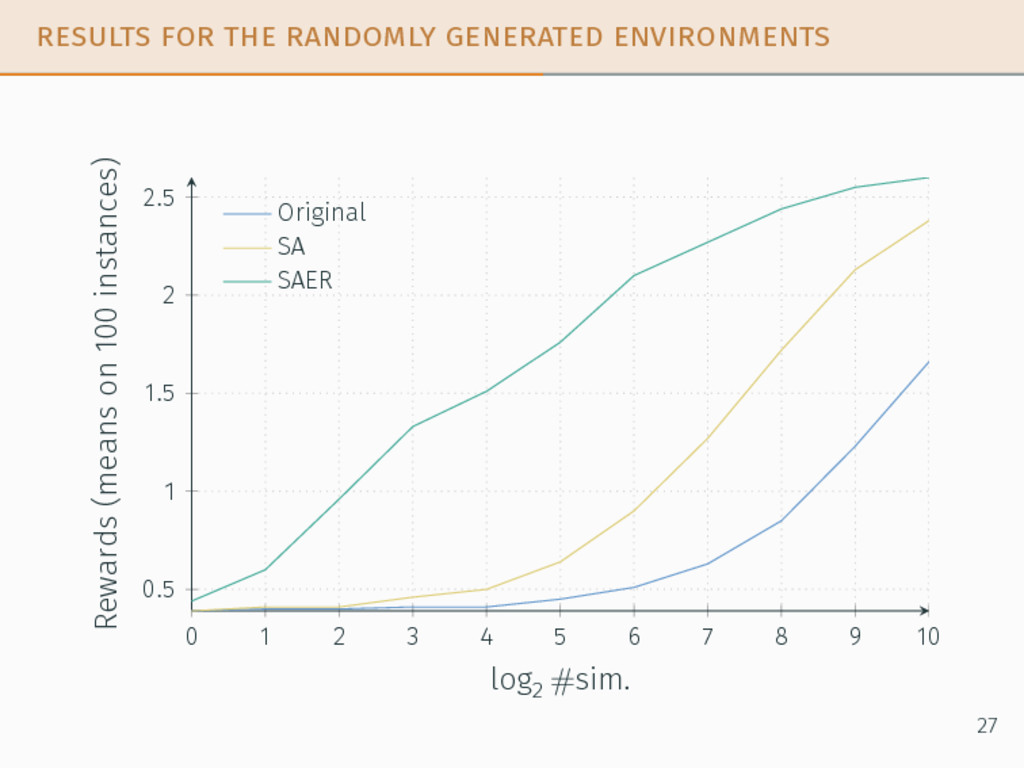
taken from the literature. We compared the performances of: • the original POMCP algorithm, • our adaptations SA and SAER, • the optimal policy when it can be computed 24
new model able to represent in a more realistic way non-stationary decision-making problems (HS3MDP), • Adaptations of POMCP to tackle large-size problems, outperforming it. 28
a subclass of those problems called RLCD with SCD7. 7Emmanuel Hadoux, Aurélie Beynier, and Paul Weng. “Sequential Decision-Making under Non-stationary Environments via Sequential Change-point Detection”. In: First International Workshop on Learning over Multiple Contexts (LMCE) @ ECML. 2014. 29
a subclass of those problems called RLCD with SCD7. This method is able to learn a part of the dynamics, without requiring to know the number of modes a priori. 7Emmanuel Hadoux, Aurélie Beynier, and Paul Weng. “Sequential Decision-Making under Non-stationary Environments via Sequential Change-point Detection”. In: First International Workshop on Learning over Multiple Contexts (LMCE) @ ECML. 2014. 29
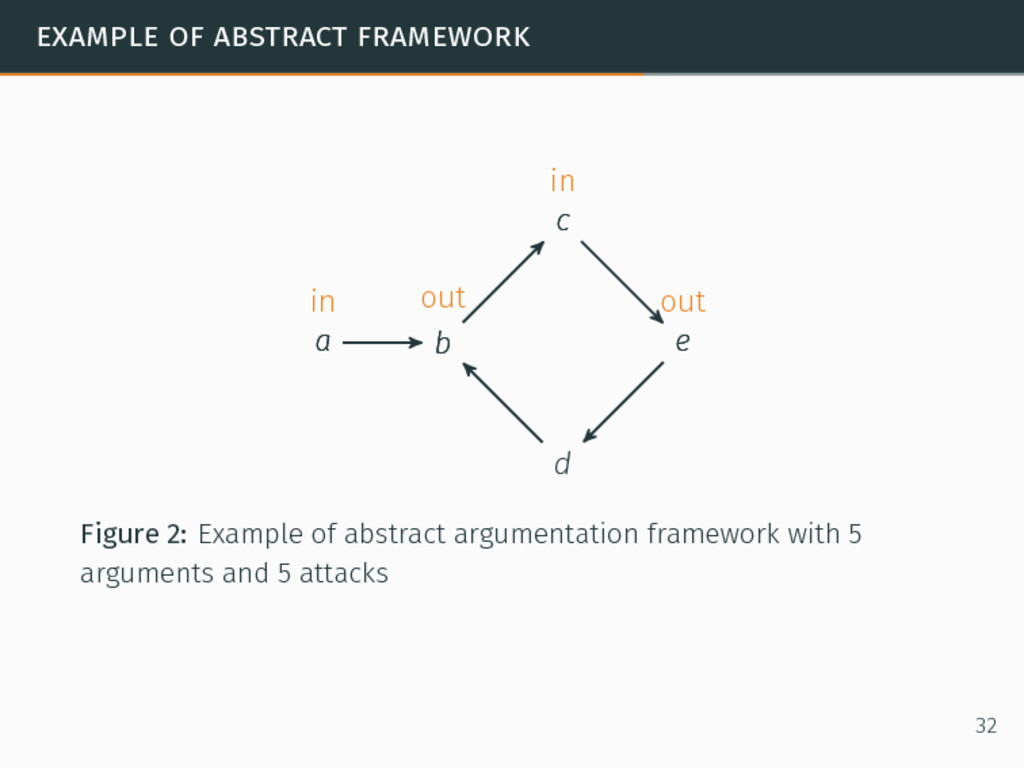
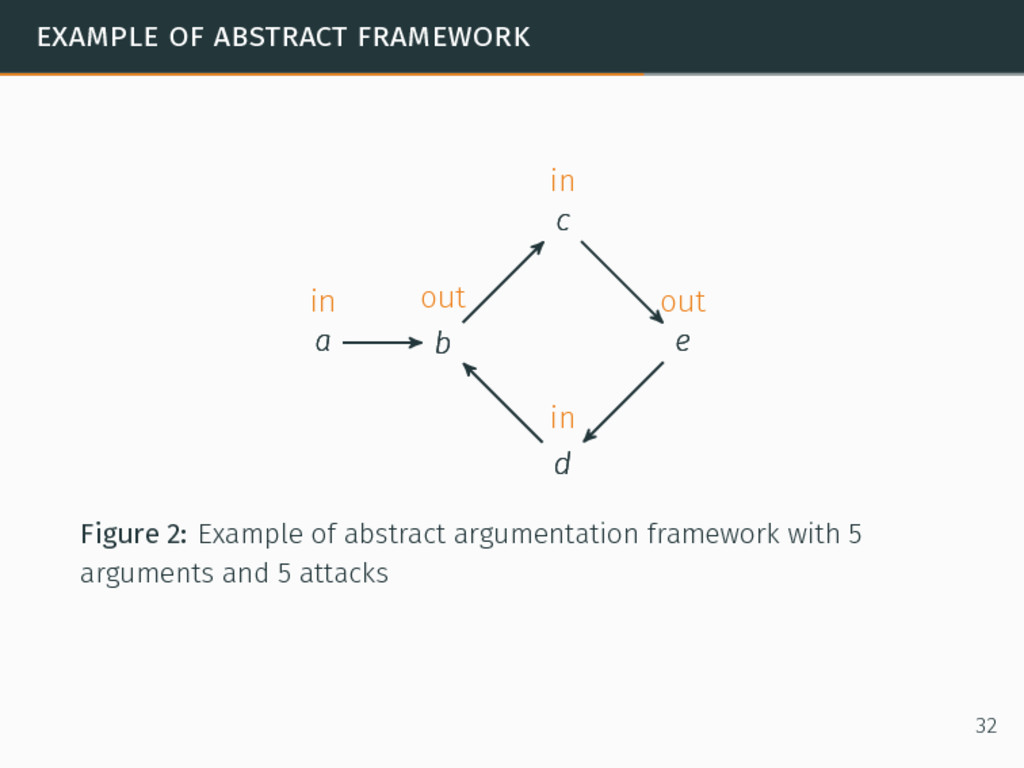
in argumentation. 8Phan Minh Dung. “On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games”. In: Artificial Intelligence 77.2 (1995), pp. 321–358. 31
in argumentation. In abstract argumentation, agents exchange arguments and use attacks as relations between the arguments. 8Phan Minh Dung. “On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games”. In: Artificial Intelligence 77.2 (1995), pp. 321–358. 31
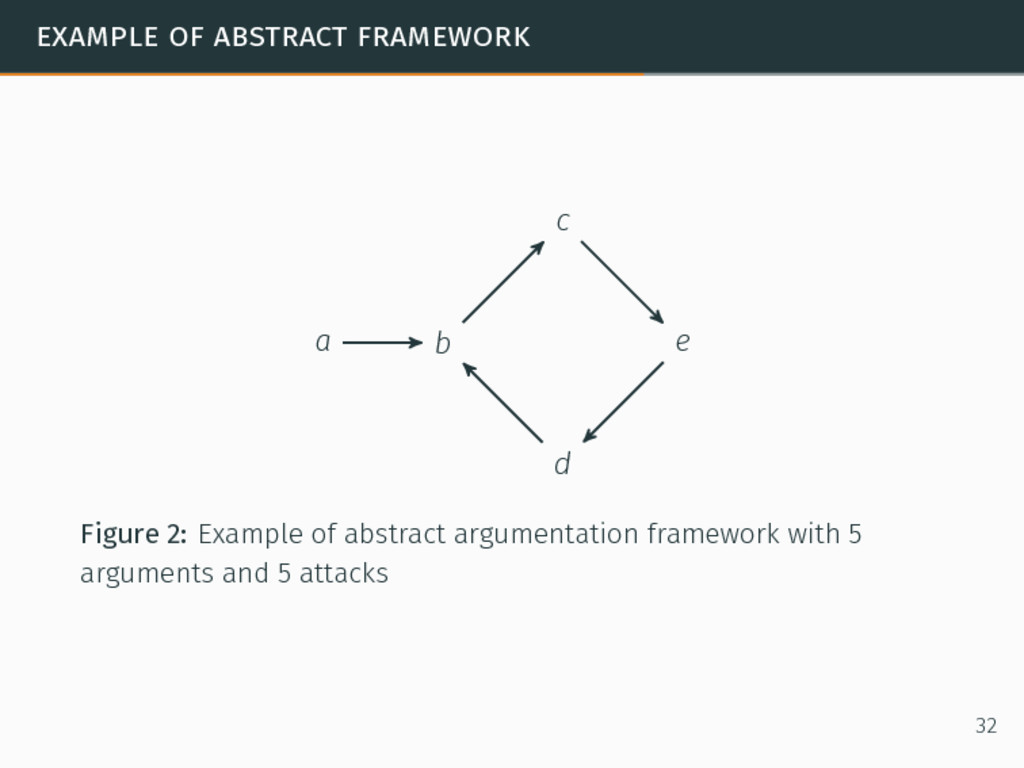
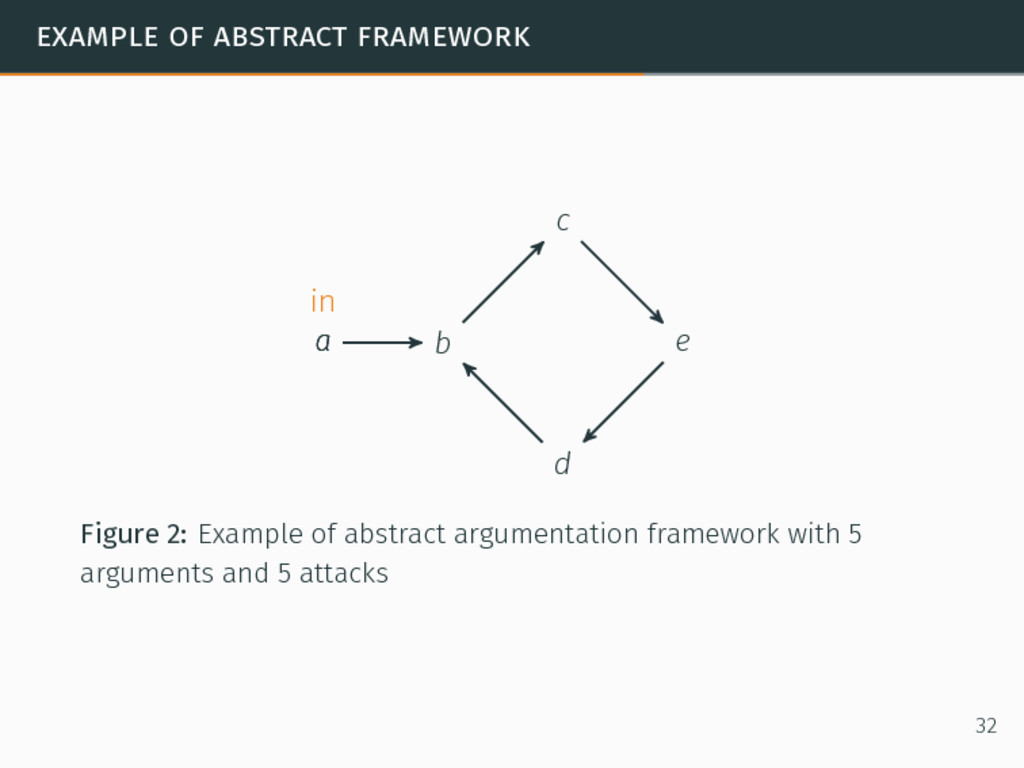
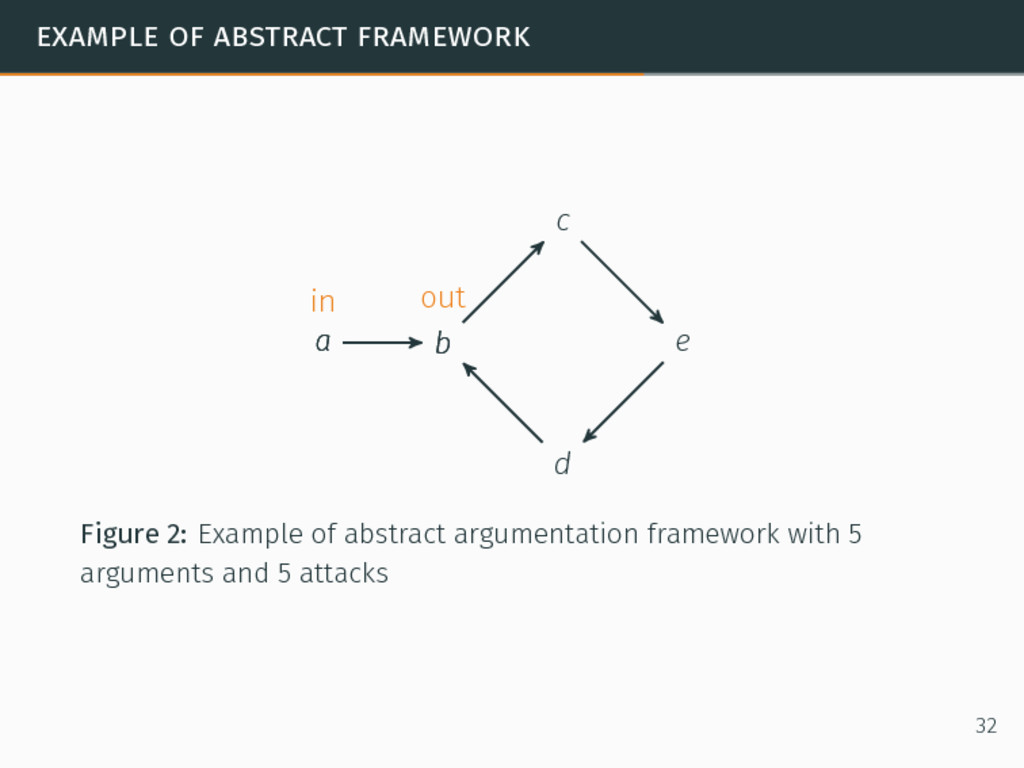
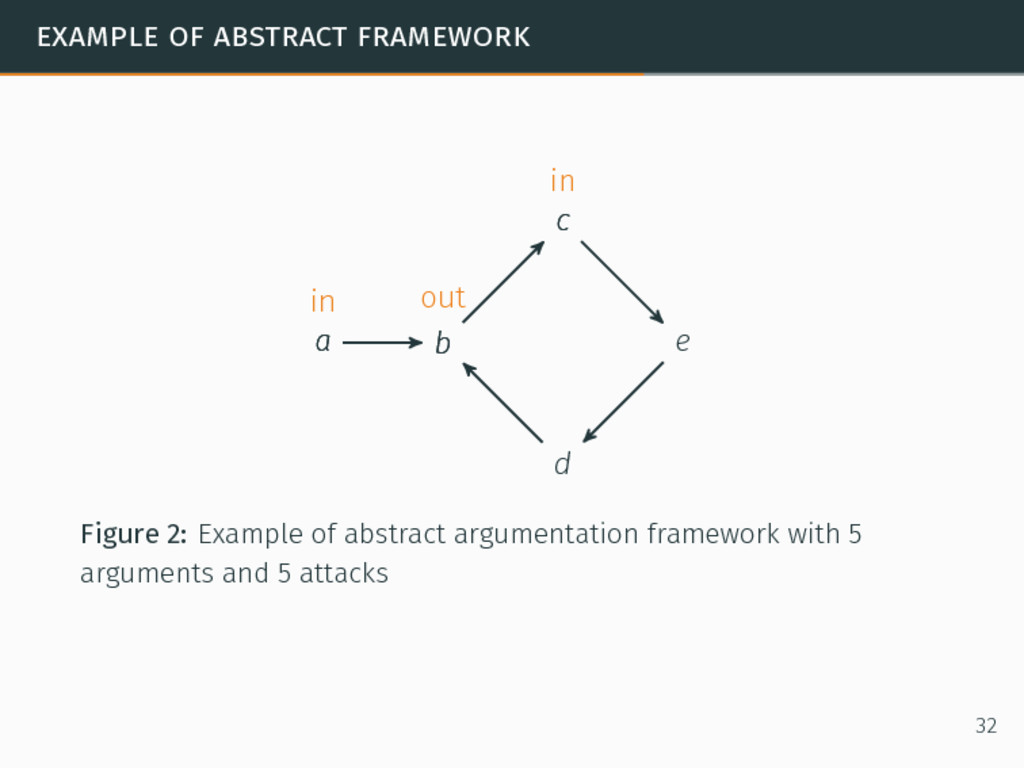
in argumentation. In abstract argumentation, agents exchange arguments and use attacks as relations between the arguments. Formal abstract argumentation framework8 ⟨A, E⟩ such that: 8Phan Minh Dung. “On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games”. In: Artificial Intelligence 77.2 (1995), pp. 321–358. 31
in argumentation. In abstract argumentation, agents exchange arguments and use attacks as relations between the arguments. Formal abstract argumentation framework8 ⟨A, E⟩ such that: A a set of arguments, 8Phan Minh Dung. “On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games”. In: Artificial Intelligence 77.2 (1995), pp. 321–358. 31
in argumentation. In abstract argumentation, agents exchange arguments and use attacks as relations between the arguments. Formal abstract argumentation framework8 ⟨A, E⟩ such that: A a set of arguments, E a set of relations such that (a, b) ∈ E if a ∈ A and b ∈ A and a attacks b. 8Phan Minh Dung. “On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games”. In: Artificial Intelligence 77.2 (1995), pp. 321–358. 31
against stochastic opponents. Agents play a turn-based game → argumentative dialogue 9Anthony Hunter. “Probabilistic Strategies in Dialogical Argumentation”. In: International Conference on Scalable Uncertainty Management (SUM) LNCS volume 8720. 2014. 33
against stochastic opponents. Agents play a turn-based game → argumentative dialogue Uses executable logic to represent the actions of an agent in the debate. 9Anthony Hunter. “Probabilistic Strategies in Dialogical Argumentation”. In: International Conference on Scalable Uncertainty Management (SUM) LNCS volume 8720. 2014. 33
state. The problem has a public space. A rule for an agent is defined as Premises ⇒ Pr(Acts) such that: • Premises: a conjunction of a(x), hi(x), e(x, y), 34
state. The problem has a public space. A rule for an agent is defined as Premises ⇒ Pr(Acts) such that: • Premises: a conjunction of a(x), hi(x), e(x, y), • Acts: conjunction of ⊞, ⊟ on a(), e() and ⊕, ⊖ on hi(), 34
state. The problem has a public space. A rule for an agent is defined as Premises ⇒ Pr(Acts) such that: • Premises: a conjunction of a(x), hi(x), e(x, y), • Acts: conjunction of ⊞, ⊟ on a(), e() and ⊕, ⊖ on hi(), Example h1(b) ∧ a(f) ∧ e(b, f) ⇒ 0.5 : ⊞a(b) ∨ 0.5 : ⊞a(c) 34
state. The problem has a public space. A rule for an agent is defined as Premises ⇒ Pr(Acts) such that: • Premises: a conjunction of a(x), hi(x), e(x, y), • Acts: conjunction of ⊞, ⊟ on a(), e() and ⊕, ⊖ on hi(), Example h1(b) ∧ a(f) ∧ e(b, f) ⇒ 0.5 : ⊞a(b) ∨ 0.5 : ⊞a(c) Purpose Optimize the sequence of arguments of one agent. 34
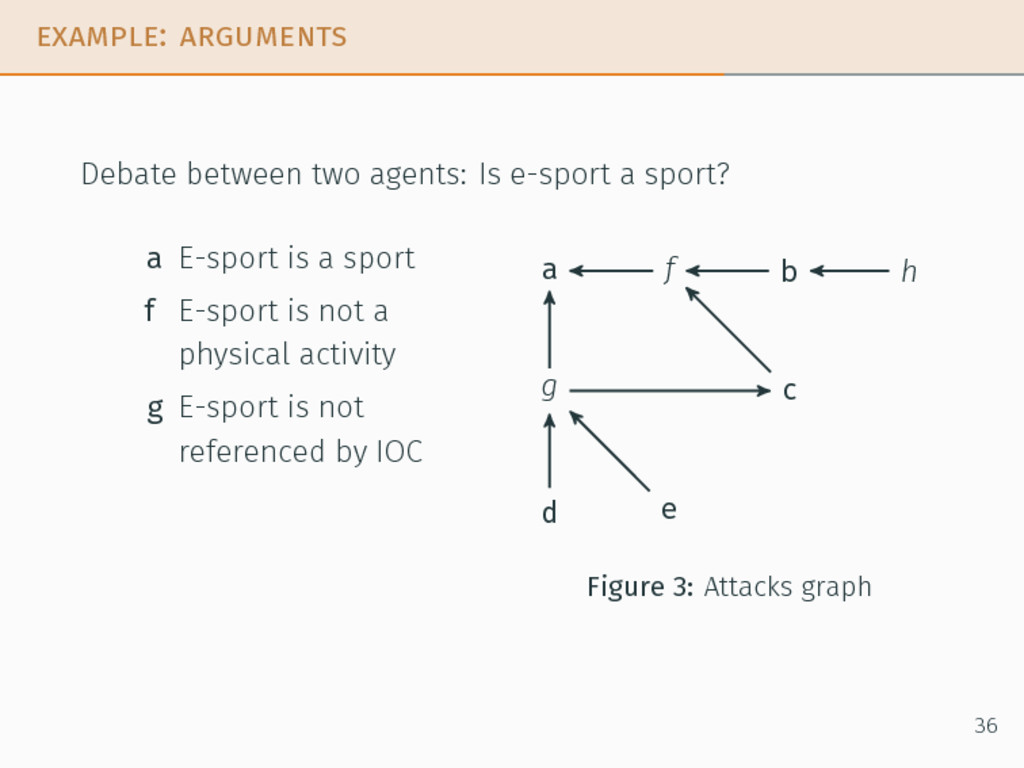
(APS)10 ⟨A, E, Si, P, G, gi, Ri⟩ such that: A, E a set of arguments and attacks, 10Emmanuel Hadoux et al. “Optimization of Probabilistic Argumentation with Markov Decision Models”. In: IJCAI, Buenos Aires, Argentina. 2015. 35
(APS)10 ⟨A, E, Si, P, G, gi, Ri⟩ such that: A, E a set of arguments and attacks, Si the set of private states of agent i, 10Emmanuel Hadoux et al. “Optimization of Probabilistic Argumentation with Markov Decision Models”. In: IJCAI, Buenos Aires, Argentina. 2015. 35
(APS)10 ⟨A, E, Si, P, G, gi, Ri⟩ such that: A, E a set of arguments and attacks, Si the set of private states of agent i, P = 2A × 2E the public space, 10Emmanuel Hadoux et al. “Optimization of Probabilistic Argumentation with Markov Decision Models”. In: IJCAI, Buenos Aires, Argentina. 2015. 35
(APS)10 ⟨A, E, Si, P, G, gi, Ri⟩ such that: A, E a set of arguments and attacks, Si the set of private states of agent i, P = 2A × 2E the public space, G the set of all possible goals, 10Emmanuel Hadoux et al. “Optimization of Probabilistic Argumentation with Markov Decision Models”. In: IJCAI, Buenos Aires, Argentina. 2015. 35
(APS)10 ⟨A, E, Si, P, G, gi, Ri⟩ such that: A, E a set of arguments and attacks, Si the set of private states of agent i, P = 2A × 2E the public space, G the set of all possible goals, gi the goal of agent i → Dung, 10Emmanuel Hadoux et al. “Optimization of Probabilistic Argumentation with Markov Decision Models”. In: IJCAI, Buenos Aires, Argentina. 2015. 35
(APS)10 ⟨A, E, Si, P, G, gi, Ri⟩ such that: A, E a set of arguments and attacks, Si the set of private states of agent i, P = 2A × 2E the public space, G the set of all possible goals, gi the goal of agent i → Dung, Ri a set of rules for agent i 10Emmanuel Hadoux et al. “Optimization of Probabilistic Argumentation with Markov Decision Models”. In: IJCAI, Buenos Aires, Argentina. 2015. 35
for agent 1, we could optimize the PFSM but: 1. depends of the initial state 2. requires knowledge of the private state of the opponent Using MOMDPs, we can relax assumptions 1 and 2. 38
the point of view of agent 1, can be transformed to a MOMDP: • Sv = S1 × P, Sh = S2 , • Ov = Sv and Oh = ∅, • A = {prem(r) ⇒ m|r ∈ R1 and m ∈ acts(r)} 39
the point of view of agent 1, can be transformed to a MOMDP: • Sv = S1 × P, Sh = S2 , • Ov = Sv and Oh = ∅, • A = {prem(r) ⇒ m|r ∈ R1 and m ∈ acts(r)} Example h1(b) ∧ a(f) ∧ h1(c) 0.5 : ⊞a(b) ∧ ⊞e(b, f)∨ ⇒ ∧e(b, f) ∧ e(c, f) 0.5 : ⊞a(c) ∧ ⊞e(c, f) 39
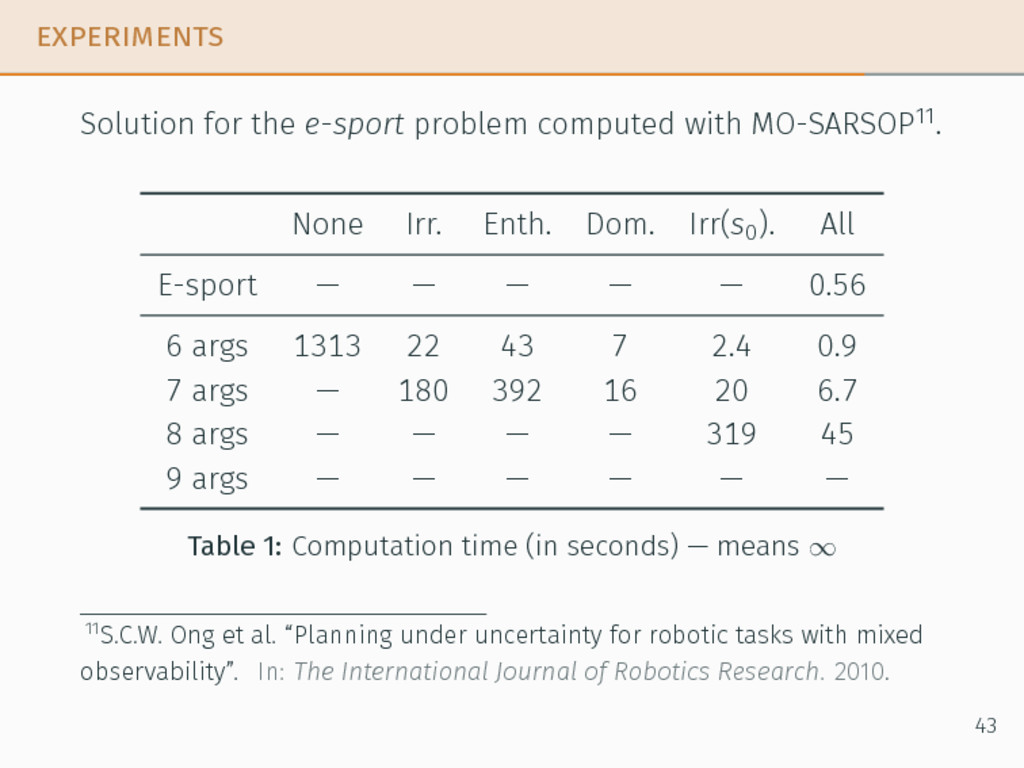
8 attacks, 6 rules POMDP : 4 294 967 296 states MOMDP : 16 777 216 states We want to have the policy → cannot use POMCP. We need to reduce the size of the instances to use traditional methods. 40
8 attacks, 6 rules POMDP : 4 294 967 296 states MOMDP : 16 777 216 states We want to have the policy → cannot use POMCP. We need to reduce the size of the instances to use traditional methods. Two kinds of size-reducing procedures: with or without dependencies on the initial state. 40
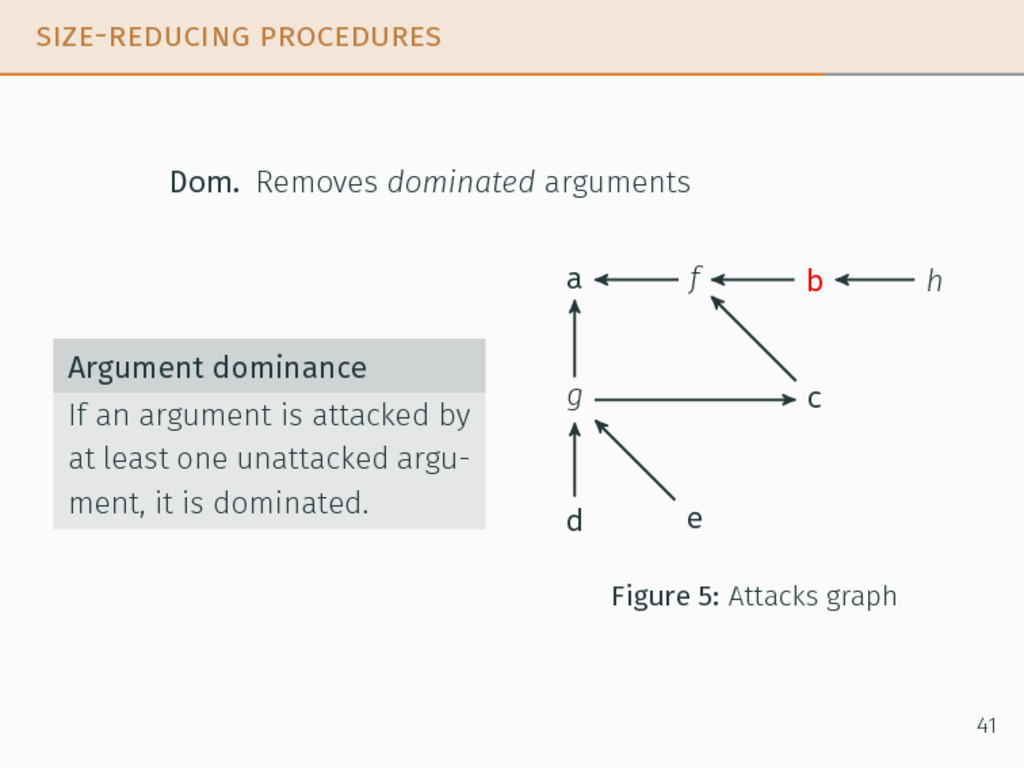
incompatible with initial state. Enth. Infers attacks Optimal sequence of procedures 1. Irr(s0 ), Irr. until stable 2. Dom., 1. until stable 3. Enth. Guarantees On the unicity and optimality of the solution 42
agents split in teams. 12Elise Bonzon and Nicolas Maudet. “On the outcomes of multiparty persuasion”. In: AAMAS. 2011, pp. 47–54. 13Michal Chalamish and Sarit Kraus. “AutoMed: an automated mediator for multi-issue bilateral negotiations”. In: JAAMAS 24.3 (2012), pp. 536–564. 44
agents split in teams. We need a mediator to give the speak-turns. 12Elise Bonzon and Nicolas Maudet. “On the outcomes of multiparty persuasion”. In: AAMAS. 2011, pp. 47–54. 13Michal Chalamish and Sarit Kraus. “AutoMed: an automated mediator for multi-issue bilateral negotiations”. In: JAAMAS 24.3 (2012), pp. 536–564. 44
agents split in teams. We need a mediator to give the speak-turns. In most cases, the mediator is not active12 or is looking for a consensus13. 12Elise Bonzon and Nicolas Maudet. “On the outcomes of multiparty persuasion”. In: AAMAS. 2011, pp. 47–54. 13Michal Chalamish and Sarit Kraus. “AutoMed: an automated mediator for multi-issue bilateral negotiations”. In: JAAMAS 24.3 (2012), pp. 536–564. 44
agents split in teams. We need a mediator to give the speak-turns. In most cases, the mediator is not active12 or is looking for a consensus13. We envision a more active mediator with her own agenda → generalization 12Elise Bonzon and Nicolas Maudet. “On the outcomes of multiparty persuasion”. In: AAMAS. 2011, pp. 47–54. 13Michal Chalamish and Sarit Kraus. “AutoMed: an automated mediator for multi-issue bilateral negotiations”. In: JAAMAS 24.3 (2012), pp. 536–564. 44
can be either of the two following modes: constructive argumenting towards the goal, destructive argumenting against the opponent’s goal. 14Still under review. 45
can be either of the two following modes: constructive argumenting towards the goal, destructive argumenting against the opponent’s goal. But other modes can be defined. 14Still under review. 45
can be either of the two following modes: constructive argumenting towards the goal, destructive argumenting against the opponent’s goal. But other modes can be defined. We proposed Dynamic Mediation Problems (DMP)14 for those problems from the viewpoint of the mediator. 14Still under review. 45
into HS3MDP modes, allowing us to convert DMPs to HS3MDPs. We can solve the problem using our adaptations of POMCP. Purpose Organize the sequence of speak-turns for the mediator. 46
formalization of debates with probabilistic strategies (APS), • How to transform APS to MOMDP and solve them, • Size-reducing procedures, • A formalization of non-stationary mediation problems (DMP), 47
formalization of debates with probabilistic strategies (APS), • How to transform APS to MOMDP and solve them, • Size-reducing procedures, • A formalization of non-stationary mediation problems (DMP), • How to transform DMP to HS3MDP and solve them. 47
methods and models for decision-making in non-stationary environments, • Exploration of a new domain combining it to argumentation. 15http://arguman.org 16https://github.com/Amande-WP5/formalarg 48
methods and models for decision-making in non-stationary environments, • Exploration of a new domain combining it to argumentation. What could be improved: • Extensive testing of the scalability, • More realistic experiments1516, • Additional theoretical properties. 15http://arguman.org 16https://github.com/Amande-WP5/formalarg 48
mode transition/duration functions in HS3MDPs, • develop our adaptations of POMCP for MOMDPs, • learn the probabilities of the acts in APS and DMPs, • take into account the goal of the opponents in APS. 49
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}