Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Database Integration to Improve Accessibility t...
Search
Tazro Inutano Ohta
July 04, 2014
Science
0
150
Database Integration to Improve Accessibility to Public High-throughput Sequencing Data
A Presentation at National Institute of Genetics, Japan Retreat 2014
Tazro Inutano Ohta
July 04, 2014
Tweet
Share
More Decks by Tazro Inutano Ohta
See All by Tazro Inutano Ohta
Yevis: System to support building a workflow registry with automated quality control
inutano
0
140
Standardization of biological sample information database
inutano
0
86
Describe data analysis workflow with workflow languages
inutano
5
5.8k
Container virtualization technologies and workflow languages improve portability and reproducibility of data analysis environment
inutano
3
360
次世代シーケンサーによるメタゲノム解析:桜の花びらに付着した環境DNAを解析する
inutano
0
120
Workflows that run everywhere and where to run them
inutano
0
170
The Sequence Read Archive search system to make use of public high-throughput sequencing data
inutano
0
310
Improve portability of bioinformatics software across HPC and cloud infrastructures
inutano
1
130
Container, Cloud, and HPC
inutano
0
190
Other Decks in Science
See All in Science
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.3k
DMMにおけるABテスト検証設計の工夫
xc6da
1
1.5k
タンパク質間相互作⽤を利⽤した⼈⼯知能による新しい薬剤遺伝⼦-疾患相互作⽤の同定
tagtag
PRO
0
140
Algorithmic Aspects of Quiver Representations
tasusu
0
190
Accelerated Computing for Climate forecast
inureyes
PRO
0
150
Agent開発フレームワークのOverviewとW&B Weaveとのインテグレーション
siyoo
0
420
Optimization of the Tournament Format for the Nationwide High School Kyudo Competition in Japan
konakalab
0
150
知能とはなにかーヒトとAIのあいだー
tagtag
PRO
0
170
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.1k
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
190
生成検索エンジン最適化に関する研究の紹介
ynakano
2
2k
KH Coderチュートリアル(スライド版)
koichih
1
58k
Featured
See All Featured
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
55k
Side Projects
sachag
455
43k
How to train your dragon (web standard)
notwaldorf
97
6.5k
Being A Developer After 40
akosma
91
590k
Context Engineering - Making Every Token Count
addyosmani
9
670
Believing is Seeing
oripsolob
1
58
Reality Check: Gamification 10 Years Later
codingconduct
0
2k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
0
1.1k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
1
58
A Tale of Four Properties
chriscoyier
162
24k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
130
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
22k
Transcript
Database Integration to Improve Accessibility to High-Throughput Seq Data
TAZRO OHTA @inutano
None
What do you imagine with a term “Database”?
None
None
None
Knowledge Scientific data Experimental data
Knowledge base Database Raw Data repository
Knowledge base Database Raw Data repository
What kind of data? Next-generation is already out there…
We all need Raw data repo for NGS
We’ve already seen WHY WE NEED
None
Reproducibility is what makes science fair.
2 things required for data repository is…
1: Reliability Data should be archived correctly, with explicit metadata
2: Accessibility Data should be able to be accessed by anyone, without special trick
1: Reliability needs curation Data should be archived correctly, with
explicit metadata 2: Accessibility needs good interface Data should be able to be accessed by anyone, without special trick
1: Reliability needs curation Data should be archived correctly, with
explicit metadata 2: Accessibility needs good interface Data should be able to be accessed by anyone, without special trick
1: Reliability needs curation Data should be archived correctly, with
explicit metadata 2: Accessibility needs good interface Data should be able to be accessed by anyone, without special trick
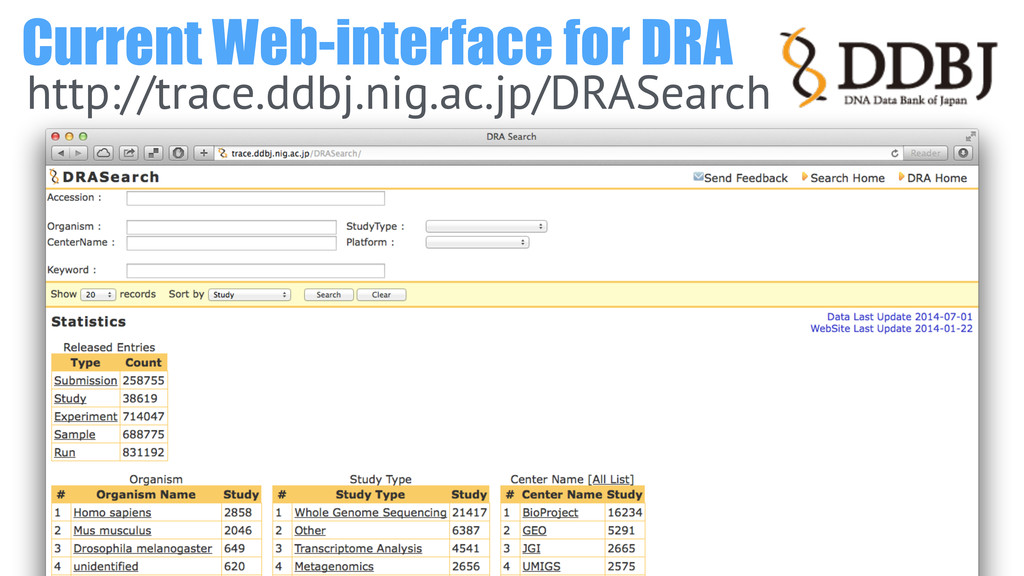
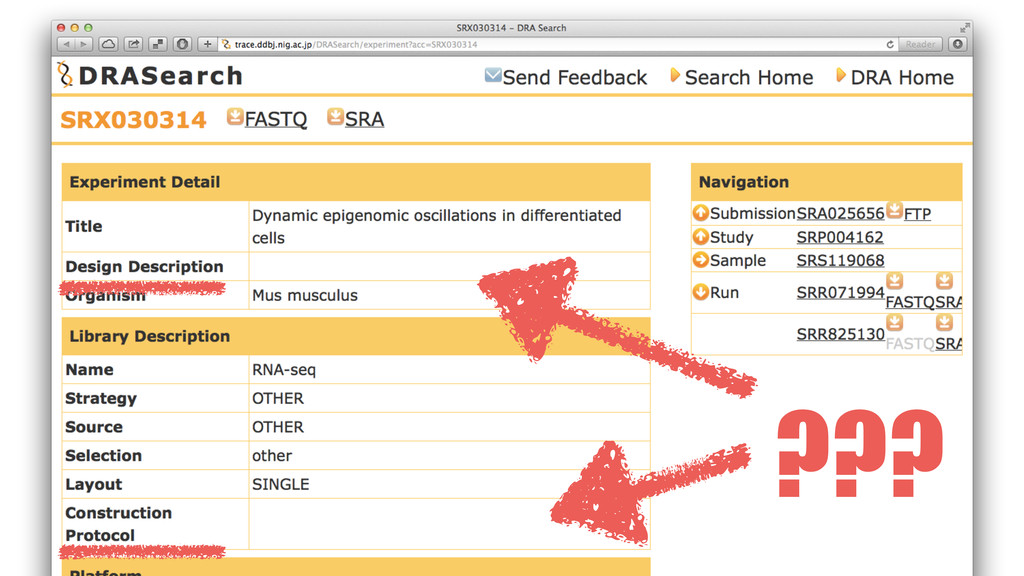
Current Web-interface for DRA http://trace.ddbj.nig.ac.jp/DRASearch
Good: Simple, Fast, and no bugs (!) Challenge: Lack of
metadata caused “NOT FOUND”
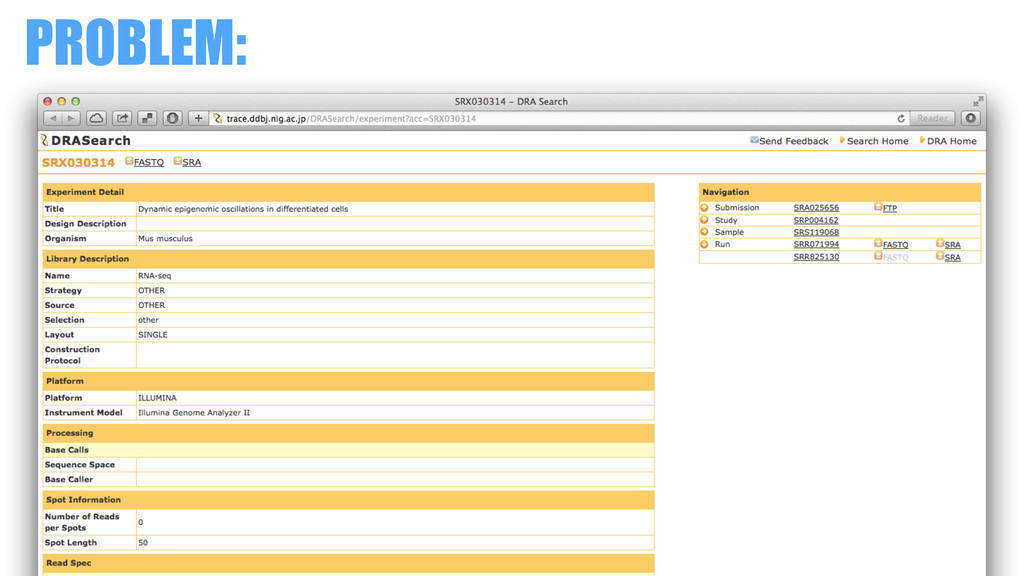
PROBLEM:
???
DRASearch can NOT find Data without metadata …but they definitely
exist in the repo.
Too many to ask submitters; then we implemented a system
to make metadata rich enough
2 sources into DRA DDBJ Read Archive
Publications can have details of seq process, Seq Read Quality
can be a source of data quality. DDBJ Read Archive PubMed PMC Extracted Read Quality
And then: integration enables to implement Efficient Data Search
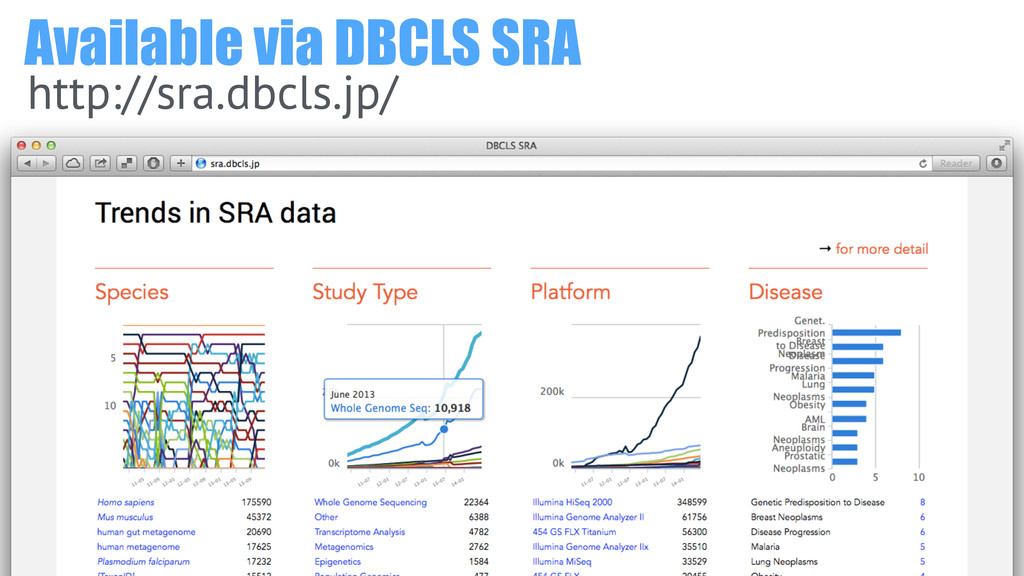
Available via DBCLS SRA http://sra.dbcls.jp/
Available via DBCLS SRA http://sra.dbcls.jp/
Available via DBCLS SRA http://sra.dbcls.jp/
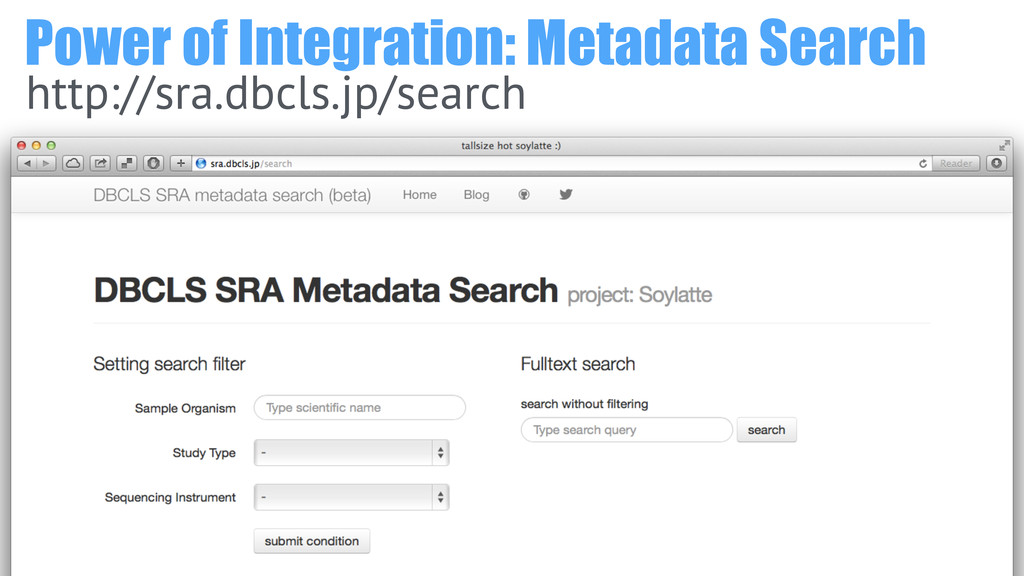
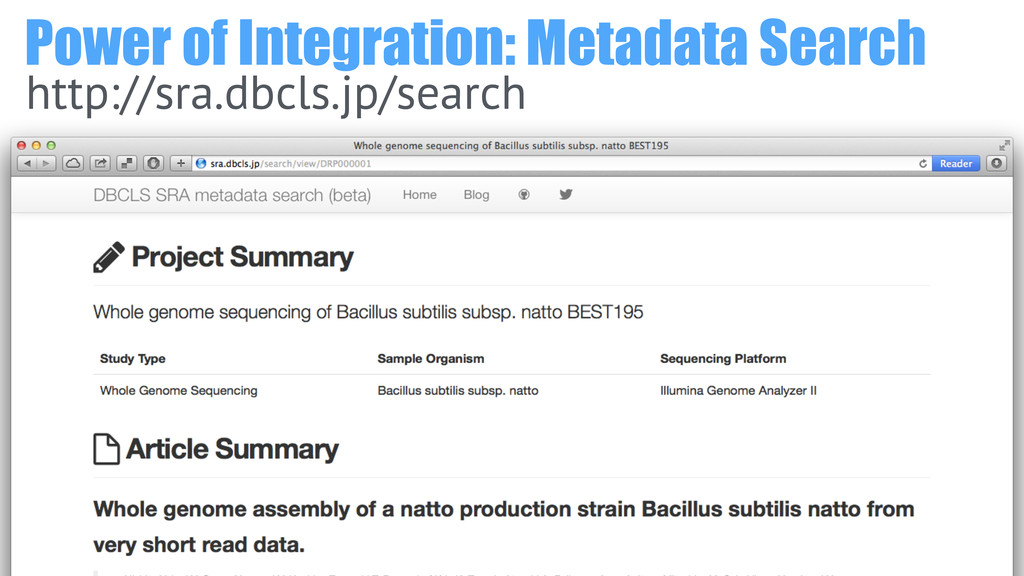
Power of Integration: Metadata Search http://sra.dbcls.jp/search
Power of Integration: Metadata Search http://sra.dbcls.jp/search
Power of Integration: Metadata Search http://sra.dbcls.jp/search
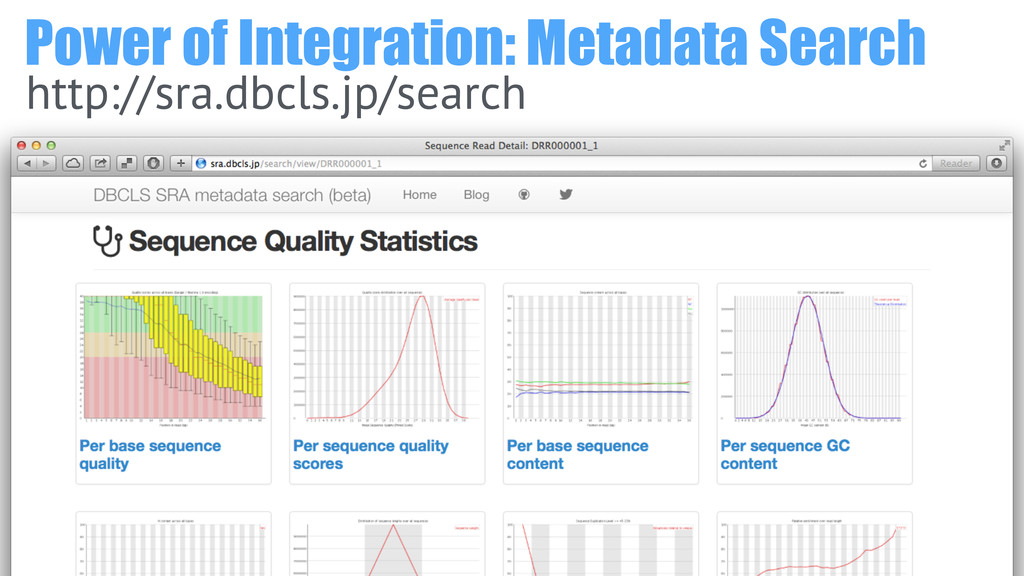
83% seq reads satisfied average quality over 30 0.03% of
seq reads fall into over 50% N content
1: Reliability from paper/data qual more description brings more proof.
2: Accessibility from text-search Search included publication brings flexibility.
2.20% of submitted projects has at least one publication 4429
/ 201558 PROBLEM:
NIH Data sharing Guideline http://www.niaid.nih.gov/LabsAndResources/resources/dmid/Pages/data.aspx
NIH Data sharing Guideline http://www.niaid.nih.gov/LabsAndResources/resources/dmid/Pages/data.aspx
What is Next-step to carry on?
1: Beyond Raw Data Archive is going to handle alignment
data. 2: Analysis Reproducibility Public repo for analysis pipeline is required.
1: Beyond Raw Data Archive is going to handle alignment
data. 2: Analysis Reproducibility Public repo for analysis pipeline is required.
Database is for Biologists not for developers.
Thank you!
[email protected]
http://speakerdeck.com/inutano
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! [email protected] http://speakerdeck.com/inutano](https://files.speakerdeck.com/presentations/f3da4e80e58a01319ec90ab05acaf620/slide_44.jpg){kind=link}