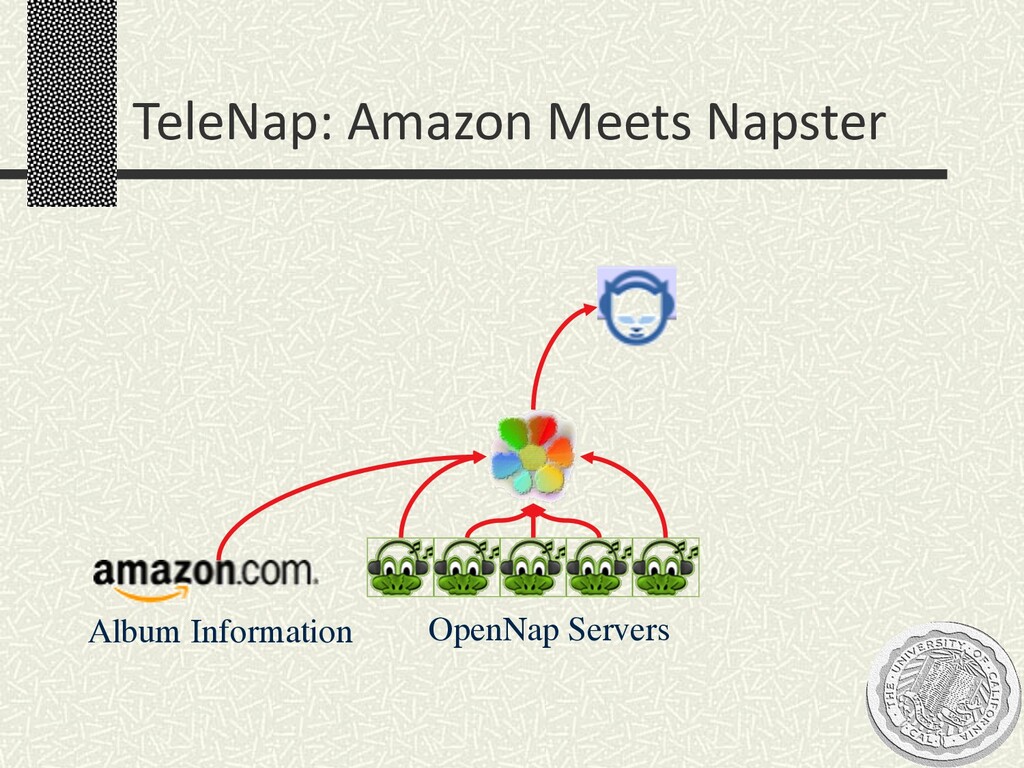
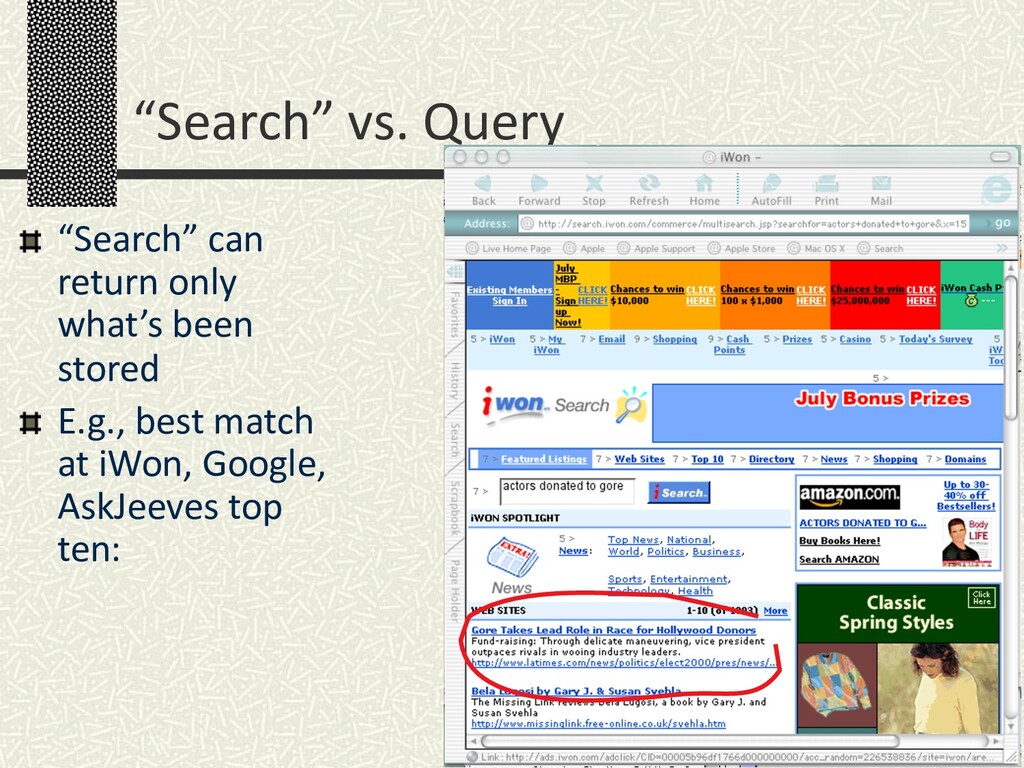
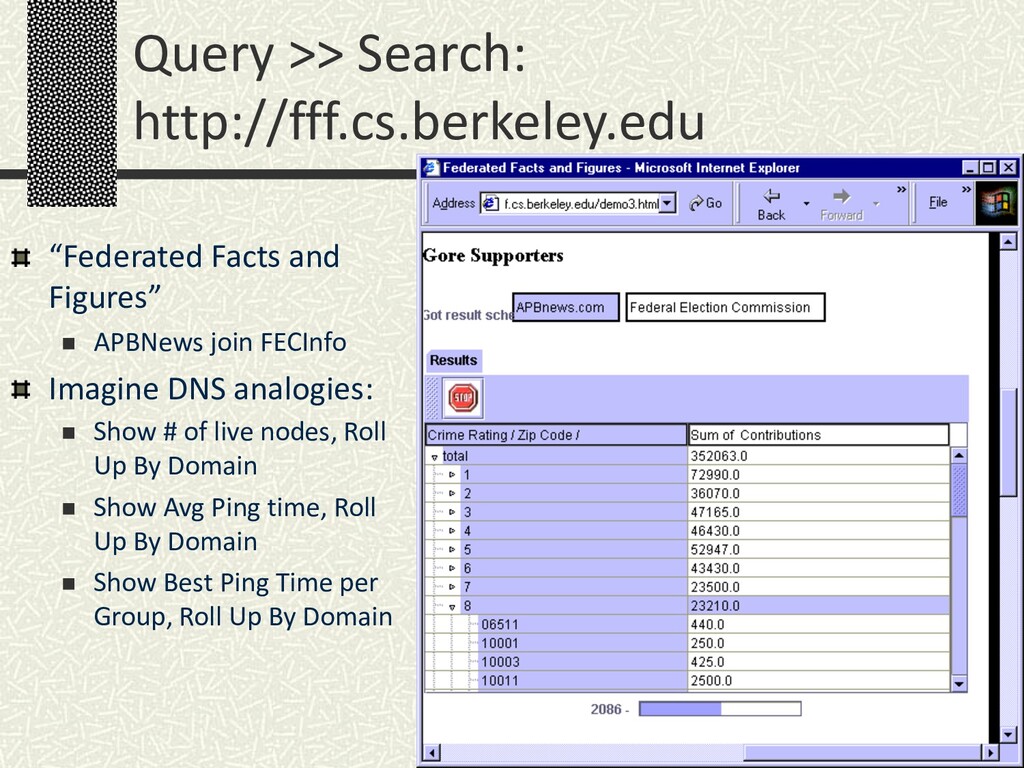
Invited talk to the National Academy of Science Committee on Internet Navigation and the Domain Name System: Technical Alternatives and Policy Implications, July 2001. As a reductio ad absurdum, it shows how much one could put into DNS with query processing technology a la Telegraph. Also makes the point that "query" means much more than "search".
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![More? [email protected] http://www.cs.berkeley.edu/~jmh Telegraph: http://telegraph.cs.berkeley.edu Federated Facts and Figures: http://fff.cs.berkeley.edu](https://files.speakerdeck.com/presentations/7cc5fd9075d04a7882cb386a4553b2ef/slide_24.jpg){kind=link}