Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
How to use scikit-learn to solve machine learni...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Olivier Grisel
April 22, 2015
Technology
0
1.1k
How to use scikit-learn to solve machine learning problems
AutoML Hackathon - Paris - April 2015
Olivier Grisel
April 22, 2015
Tweet
Share
More Decks by Olivier Grisel
See All by Olivier Grisel
Intro to scikit-learn
ogrisel
5
720
An Intro to Deep Learning
ogrisel
1
290
Predictive Modeling and Deep Learning
ogrisel
2
370
Intro to scikit-learn and what's new in 0.17
ogrisel
1
390
Big Data, Predictive Modeling and tools
ogrisel
2
300
Recent Developments in Deep Learning
ogrisel
3
700
Documentation
ogrisel
2
260
Build and test wheel packages on Linux, OSX and Windows
ogrisel
2
350
Big Data and Predictive Modeling
ogrisel
3
240
Other Decks in Technology
See All in Technology
コミュニティが変えるキャリアの地平線:コロナ禍新卒入社のエンジニアがAWSコミュニティで見つけた成長の羅針盤
kentosuzuki
0
130
学生・新卒・ジュニアから目指すSRE
hiroyaonoe
2
720
OCI Database Management サービス詳細
oracle4engineer
PRO
1
7.4k
Frontier Agents (Kiro autonomous agent / AWS Security Agent / AWS DevOps Agent) の紹介
msysh
3
180
Cosmos World Foundation Model Platform for Physical AI
takmin
0
960
仕様書駆動AI開発の実践: Issue→Skill→PRテンプレで 再現性を作る
knishioka
2
680
Amazon Bedrock Knowledge Basesチャンキング解説!
aoinoguchi
0
160
SRE Enabling戦記 - 急成長する組織にSREを浸透させる戦いの歴史
markie1009
0
150
インフラエンジニア必見!Kubernetesを用いたクラウドネイティブ設計ポイント大全
daitak
1
380
顧客の言葉を、そのまま信じない勇気
yamatai1212
1
360
AWS Network Firewall Proxyを触ってみた
nagisa53
1
240
FinTech SREのAWSサービス活用/Leveraging AWS Services in FinTech SRE
maaaato
0
130
Featured
See All Featured
Crafting Experiences
bethany
1
50
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
1
100
Designing Experiences People Love
moore
144
24k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
460
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
270
Un-Boring Meetings
codingconduct
0
200
Abbi's Birthday
coloredviolet
1
4.8k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
190
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
1.7k
Stop Working from a Prison Cell
hatefulcrawdad
273
21k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
750
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.2k
Transcript
How to use scikit-learn to solve machine learning problems AutoML
Hackathon April 2015
Outline • Machine Learning refresher • scikit-learn • Demo: interactive
predictive modeling on Census Data with IPython notebook / pandas / scikit-learn • Combining models with Pipeline and parameter search
Predictive modeling ~= machine learning • Make predictions of outcome
on new data • Extract the structure of historical data • Statistical tools to summarize the training data into a executable predictive model • Alternative to hard-coded rules written by experts
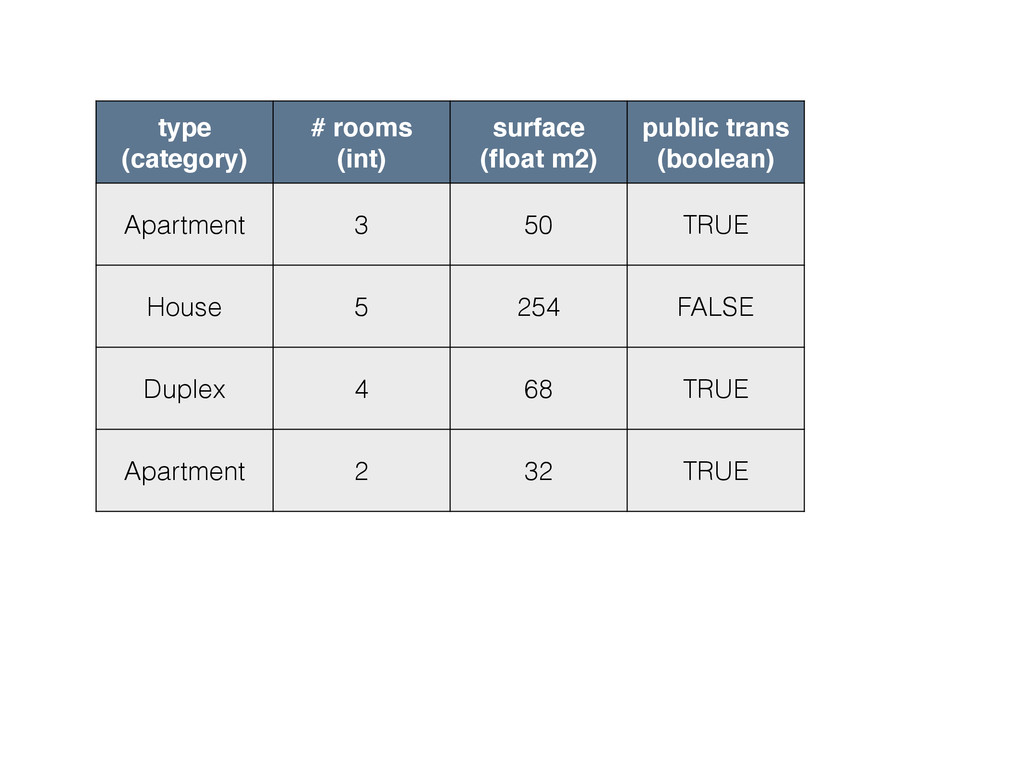
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE
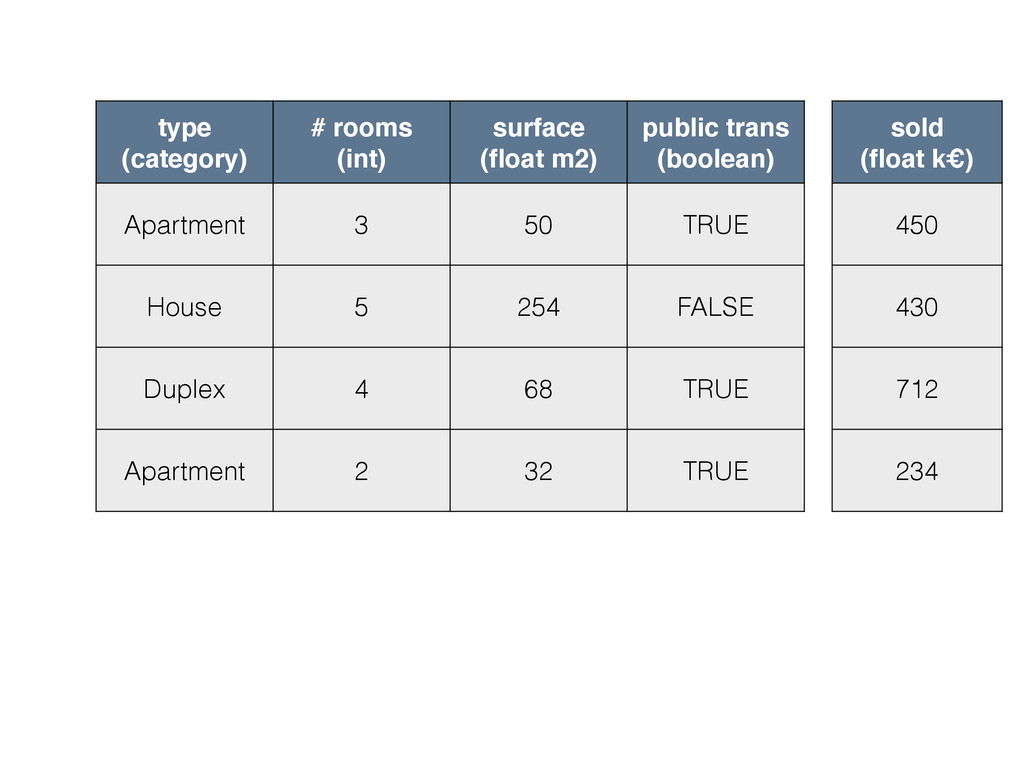
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234
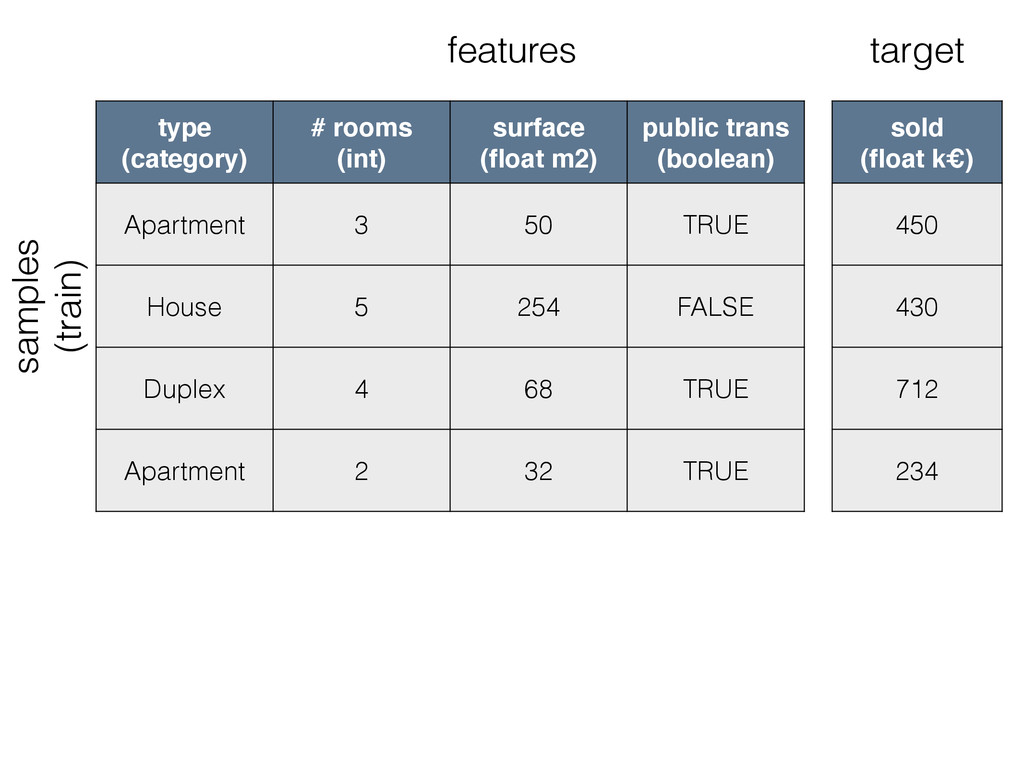
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train)
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train) Apartment 2 33 TRUE House 4 210 TRUE samples (test) ? ?
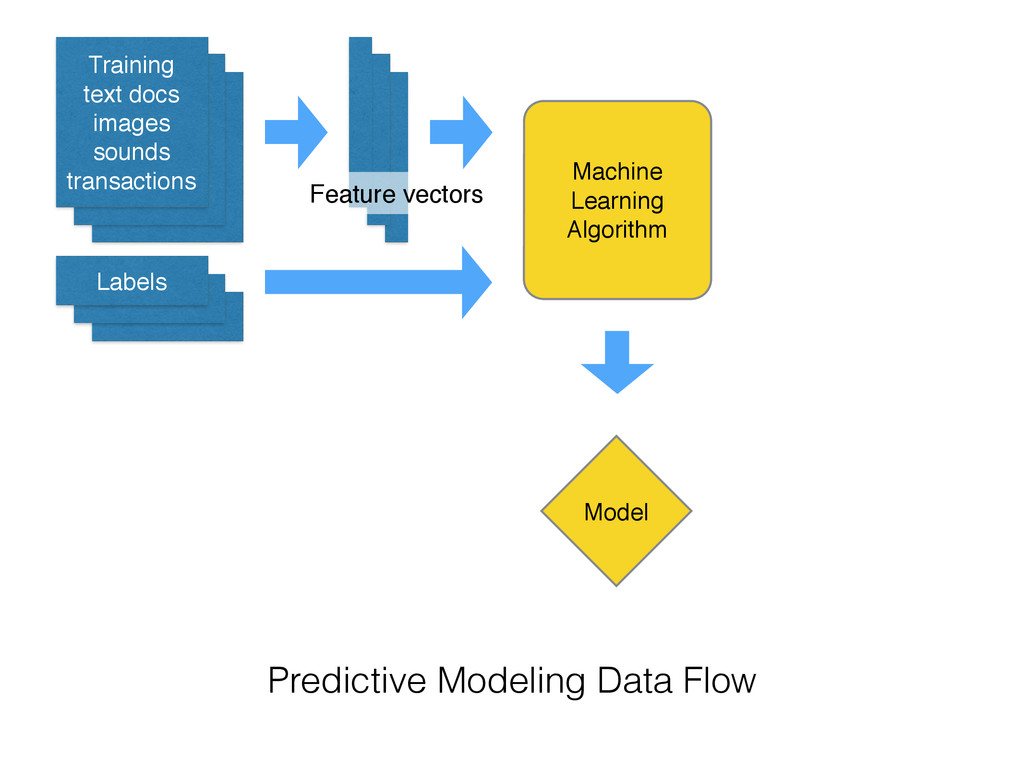
Training text docs images sounds transactions Labels Machine Learning Algorithm
Model Predictive Modeling Data Flow Feature vectors
New text doc image sound transaction Model Expected Label Predictive
Modeling Data Flow Feature vector Training text docs images sounds transactions Labels Machine Learning Algorithm Feature vectors
Inventory forecasting & trends detection Predictive modeling in the wild
Personalized radios Fraud detection Virality and readers engagement Predictive maintenance Personality matching
• Library of Machine Learning algorithms • Focus on established
methods (e.g. ESL-II) • Open Source (BSD) • Simple fit / predict / transform API • Python / NumPy / SciPy / Cython • Model Assessment, Selection & Ensembles
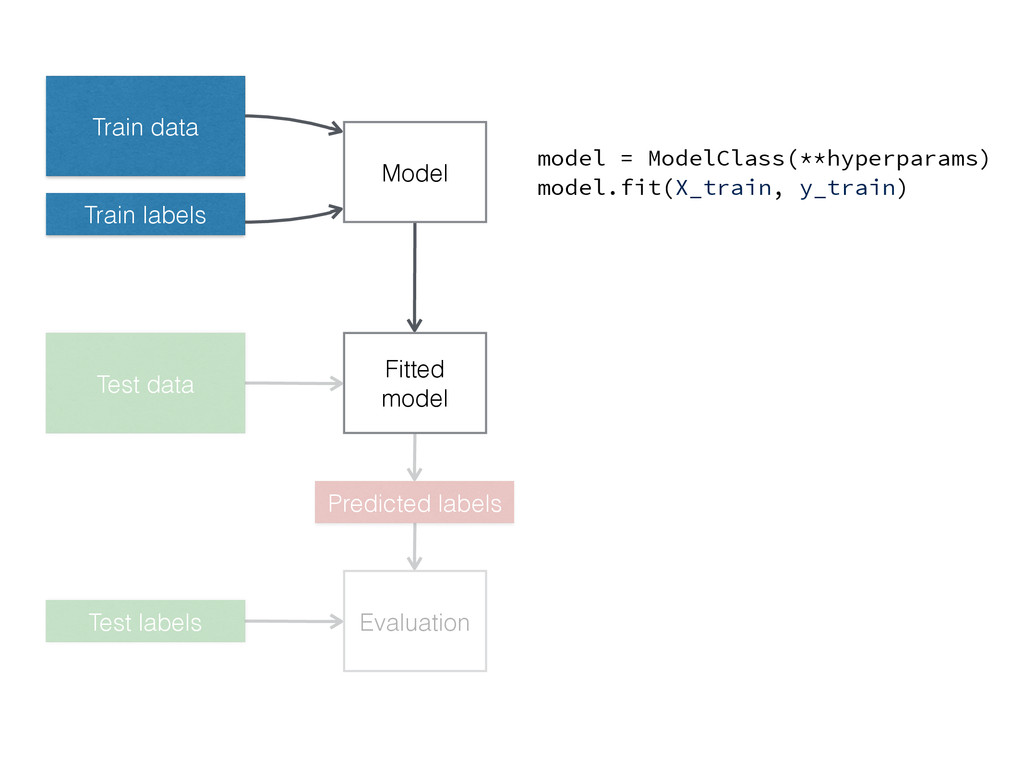
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train)
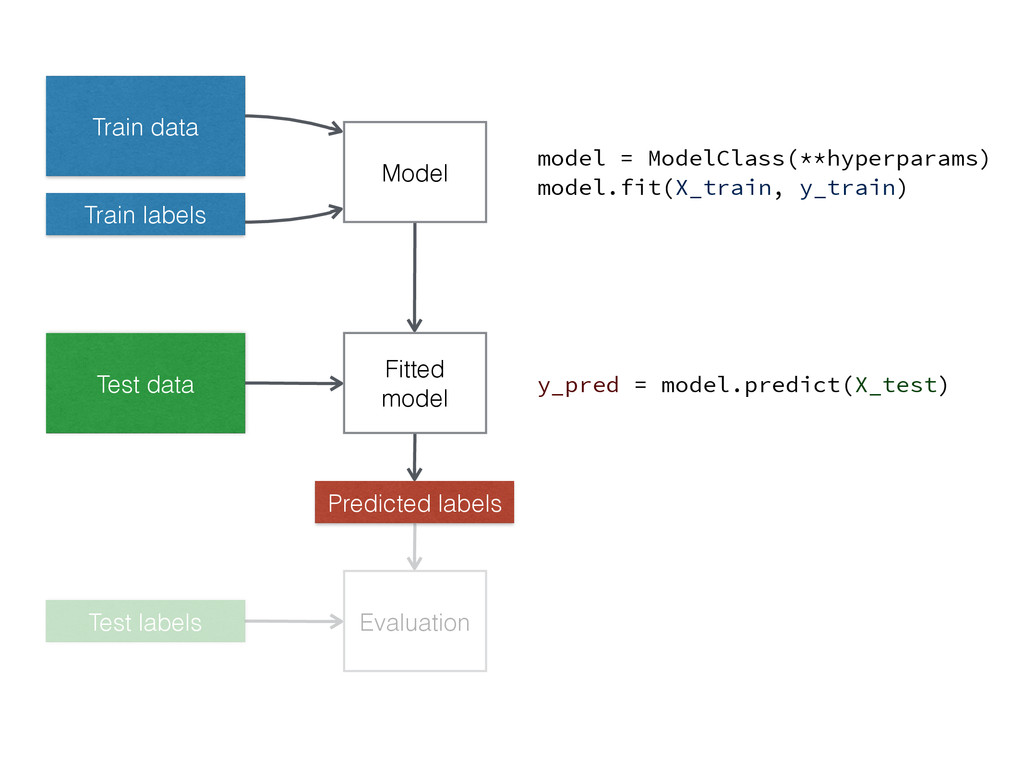
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train) y_pred = model.predict(X_test)
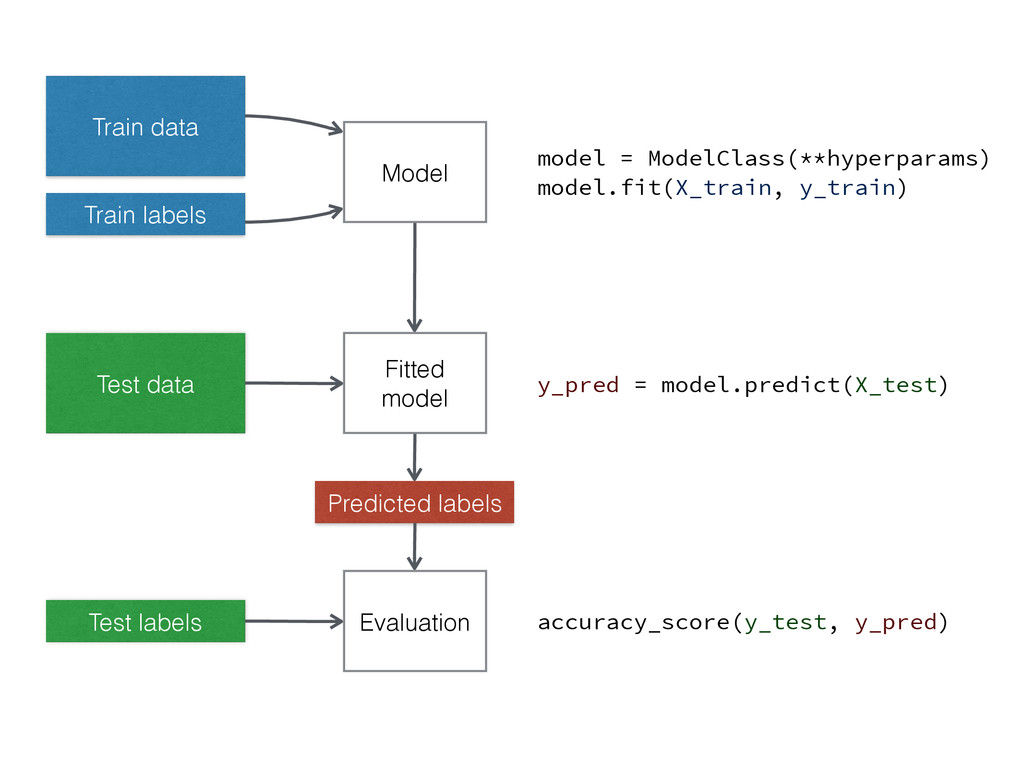
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train) y_pred = model.predict(X_test) accuracy_score(y_test, y_pred)
Support Vector Machine from sklearn.svm import SVC model = SVC(kernel="rbf",
C=1.0, gamma=1e-4) model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Linear Classifier from sklearn.linear_model import SGDClassifier model = SGDClassifier(alpha=1e-4, penalty="elasticnet")
model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Random Forests from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=200) model.fit(X_train,
y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
None
None
Demo time! http://nbviewer.ipython.org/github/ogrisel/notebooks/blob/ master/sklearn_demos/Income%20classification.ipynb https://github.com/ogrisel/notebooks
Combining Models from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA
from sklearn.svm import SVC scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train)
Pipeline from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA from
sklearn.svm import SVC from sklearn.pipeline import make_pipeline pipeline = make_pipeline( StandardScaler(), RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), ) pipeline.fit(X_train, y_train)
Scoring manually stacked models scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)
pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train) X_test_scaled = scaler.transform(X_test) X_test_pca = pca.transform(X_test_scaled) y_pred = svm.predict(X_test_pca) accuracy_score(y_test, y_pred)
Scoring a pipeline pipeline = make_pipeline( RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), )
pipeline.fit(X_train, y_train) y_pred = pipeline.predict(X_test) accuracy_score(y_test, y_pred)
Parameter search import numpy as np from sklearn.grid_search import RandomizedSearchCV
params = { 'randomizedpca__n_components': [5, 10, 20], 'svc__C': np.logspace(-3, 3, 7), 'svc__gamma': np.logspace(-6, 0, 7), } search = RandomizedSearchCV(pipeline, params, n_iter=30, cv=5) search.fit(X_train, y_train) # search.best_params_, search.grid_scores_
Thank you! • http://scikit-learn.org • https://github.com/scikit-learn/scikit-learn @ogrisel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}