Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介:Fine-Grained Contextual Predictions for Ha...
Search
Shohei Okada
November 04, 2014
Research
0
90
文献紹介:Fine-Grained Contextual Predictions for Hard Sentiment Words
動画
https://www.youtube.com/watch?v=69WnudOGIBw&list=PL6SnxjlP6lpHdWaieYa0BGVuj8fgfiIw1&index=47
Shohei Okada
November 04, 2014
Tweet
Share
More Decks by Shohei Okada
See All by Shohei Okada
たった 1 枚の PHP ファイルで実装する MCP サーバ / MCP Server with Vanilla PHP
okashoi
1
730
どうして手を動かすよりもチーム内のコードレビューを優先するべきなのか
okashoi
2
2k
パスワードのハッシュ、ソルトってなに? - What is hash and salt for password?
okashoi
3
330
設計の考え方 - インターフェースと腐敗防止層編 #phpconfuk / Interface and Anti Corruption Layer
okashoi
11
5.4k
"config" ってなんだ? / What is "config"?
okashoi
0
1.6k
ファイル先頭の use の意味、説明できますか? 〜PHP の namespace と autoloading の関係を正しく理解しよう〜 / namespace and autoloading in php
okashoi
4
2k
MySQL のインデックスの種類をおさらいしよう! / overviewing indexes in MySQL
okashoi
0
1.2k
PHP における静的解析(あるいはそもそも静的解析とは) / #phpcondo_yasai static analysis for PHP
okashoi
1
1.2k
【PHPカンファレンス沖縄 2023】素朴で考慮漏れのある PHP コードをテストコードとともに補強していく(ライブコーディング補足資料) / #phpcon_okinawa 2023 livecoding supplementary material
okashoi
3
2.1k
Other Decks in Research
See All in Research
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
66
37k
Sat2City:3D City Generation from A Single Satellite Image with Cascaded Latent Diffusion
satai
4
670
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diffusion World Model for Autonomous Driving
kentosasaki
0
360
LiDARセキュリティ最前線(2025年)
kentaroy47
0
140
病院向け生成AIプロダクト開発の実践と課題
hagino3000
0
540
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
340
HoliTracer:Holistic Vectorization of Geographic Objects from Large-Size Remote Sensing Imagery
satai
3
630
生成AI による論文執筆サポート・ワークショップ ─ サーベイ/リサーチクエスチョン編 / Workshop on AI-Assisted Paper Writing Support: Survey/Research Question Edition
ks91
PRO
0
140
ドメイン知識がない領域での自然言語処理の始め方
hargon24
1
240
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.1k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
230
離散凸解析に基づく予測付き離散最適化手法 (IBIS '25)
taihei_oki
PRO
1
690
Featured
See All Featured
Tell your own story through comics
letsgokoyo
1
810
First, design no harm
axbom
PRO
2
1.1k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
170
Paper Plane
katiecoart
PRO
0
46k
Chasing Engaging Ingredients in Design
codingconduct
0
120
Between Models and Reality
mayunak
1
200
So, you think you're a good person
axbom
PRO
2
1.9k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.1k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
190
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.7k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
180
Transcript
文献紹介 2014/11/04 長岡技術科学大学 自然言語処理研究室 岡田 正平
文献情報 Sebastian Ebert and Hinrich Schütze Fine-Grained Contextual Predictions for
Hard Sentiment Words In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, pp 1210-1215. 2014. 2014/11/04 文献紹介 2
概要 仮説 「高精度な感情解析には,感情極性が異なる語義を 正確に識別することが不可欠」 語義による感情極性の異なりを扱う 1. “hard”という語に対して解析(仮説の検証) 2. 語義曖昧性解消のための特徴量を学習 3.
実験による精度向上の確認 2014/11/04 文献紹介 3
概要 仮説 「高精度な感情解析には,感情極性が異なる語義を 正確に識別することが不可欠」 語義による感情極性の異なりを扱う 1. “hard”という語に対して解析(仮説の検証) 2. 語義曖昧性解消のための特徴量を学習 3.
実験による精度向上の確認 2014/11/04 文献紹介 4
Linguistic analysis of sentiment contexts of “hard”
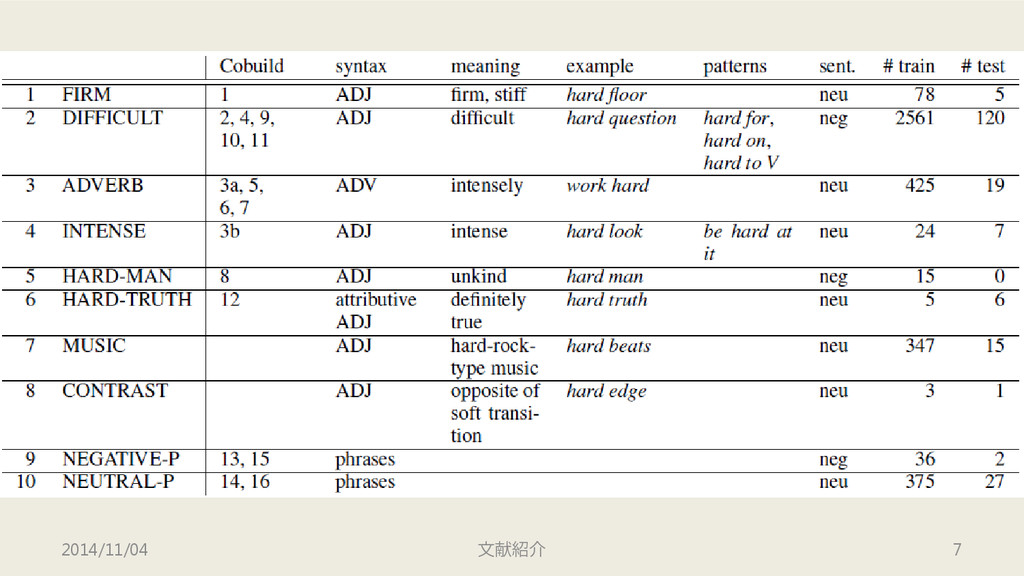
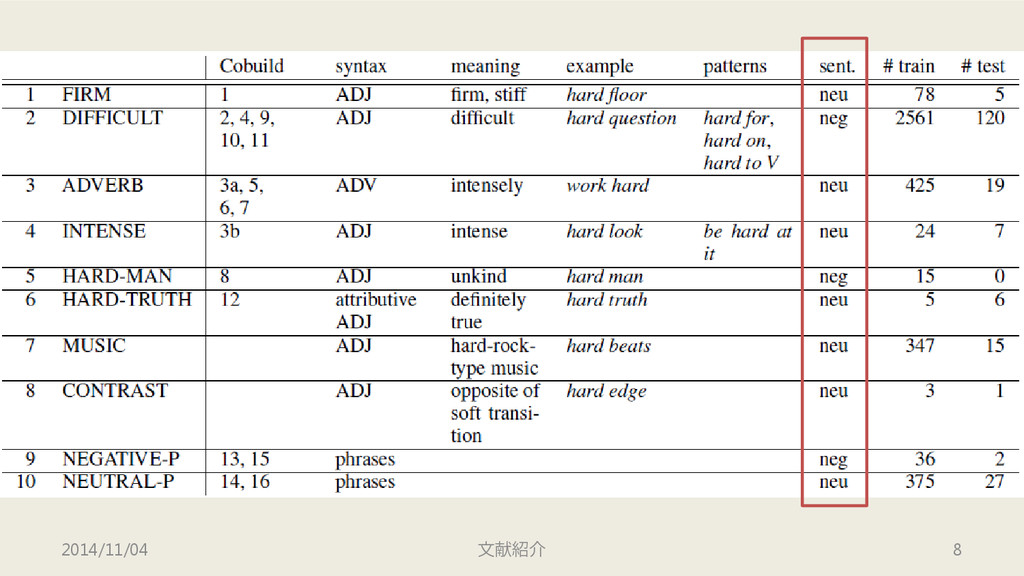
語 “hard” についての解析 • Amazon Product Review Data より 5,000
文脈を取得 • うち 4,600 文脈に対して解析を行う – 語義・極性・文脈 – 語義は Cobuild (Sinclair, 1987) をベースにしている – Cobuild 16 語義 → 10 語義 • 200 文脈に対して2名のPhD学生が 10語義 をアノテート – κ=0.78 (かなりの一致) 2014/11/04 文献紹介 6
2014/11/04 文献紹介 7
2014/11/04 文献紹介 8
概要 仮説 「高精度な感情解析には,感情極性が異なる語義を 正確に識別することが不可欠」 語義による感情極性の異なりを扱う 1. “hard”という語に対して解析(仮説の検証) 2. 語義曖昧性解消のための特徴量を学習 3.
実験による精度向上の確認 2014/11/04 文献紹介 9
Deep learning features
Deep learning features 語義曖昧性解消を行えるようにするため Deep learning を 用いて以下2つの特徴量を学習する • word
embeddings • deep learning language model (LM) – 文脈を推定するモデル (predicted context distribution (PCD)) 2014/11/04 文献紹介 11 “serious” “difficult” word context “a * problem”
• vectorized log-bilinear language model (vLBL) = 1 , ⋯
, : context : input representation of word : target representation 2014/11/04 文献紹介 12
• 語と文脈の類似度が計算できる • パラメータθは – 入力空間および対象空間 の word embeddings –
文中の位置による重みベクトル ∈ – バイアス ∈ 2014/11/04 文献紹介 13
• English Wikipedia 中の頻出 100,000 語 が対象 • 無作為に抽出された13億の7-gramを用いて4回学習 2014/11/04
文献紹介 14
概要 仮説 「高精度な感情解析には,感情極性が異なる語義を 正確に識別することが不可欠」 語義による感情極性の異なりを扱う 1. “hard”という語に対して解析(仮説の検証) 2. 語義曖昧性解消のための特徴量を学習 3.
実験による精度向上の確認 2014/11/04 文献紹介 15
Experiments
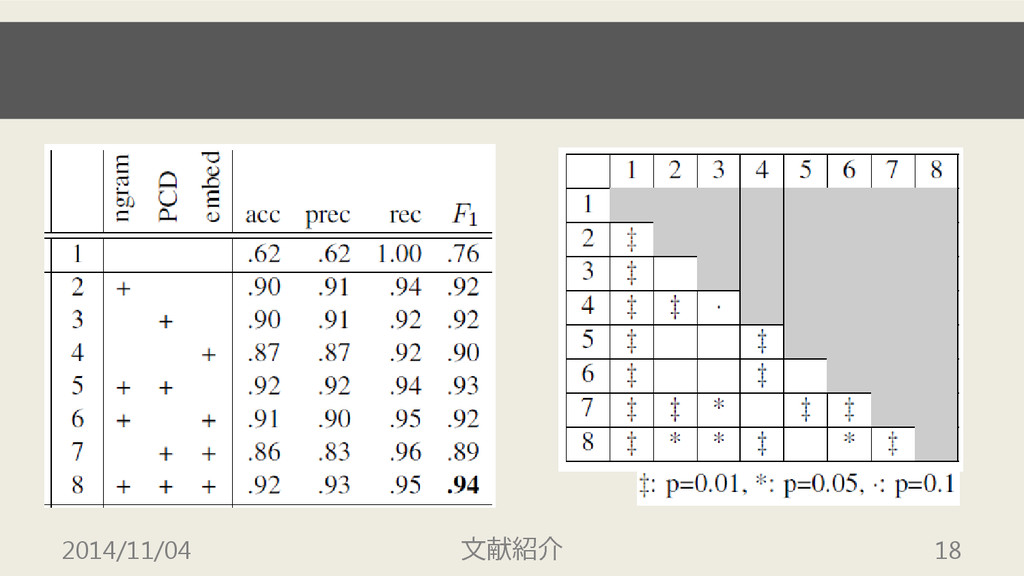
実験 1 • 語義曖昧性解消に統計的な分類モデルを使用 – liblinear を利用 • 3種の素性 –
ngrams (n = 1~3) – embeddings (Blacoe and Lapata (2012)) – PCDs (提案手法) • 4,600 文脈 → training: 4,000, development: 600 2014/11/04 文献紹介 17
2014/11/04 文献紹介 18
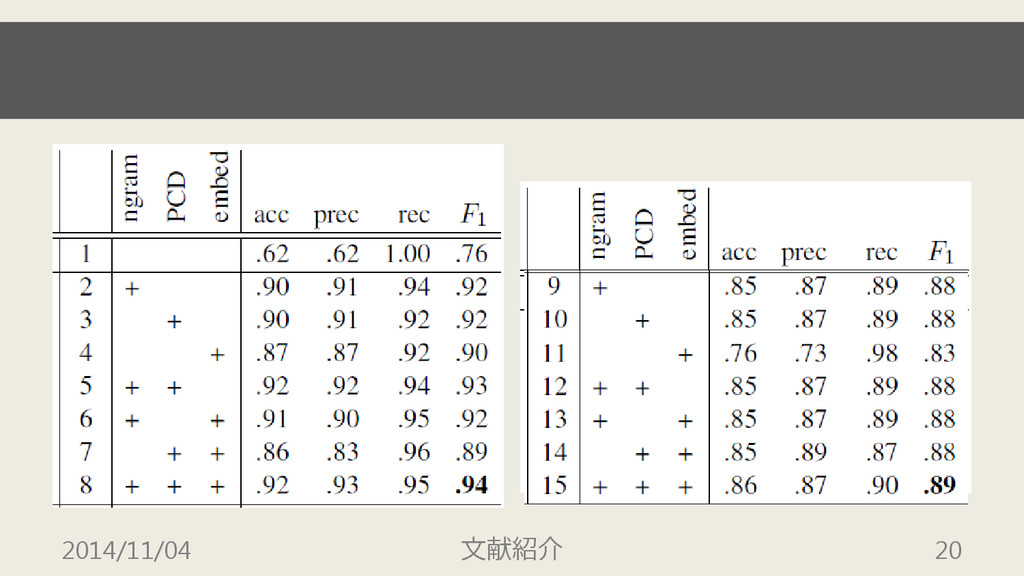
実験 2 • 4,000 文脈を 100 クラスタにクラスタリング • 各クラスタにアノテーションを行い同様の実験 –
アノテーションコストの軽減 2014/11/04 文献紹介 19
2014/11/04 文献紹介 20
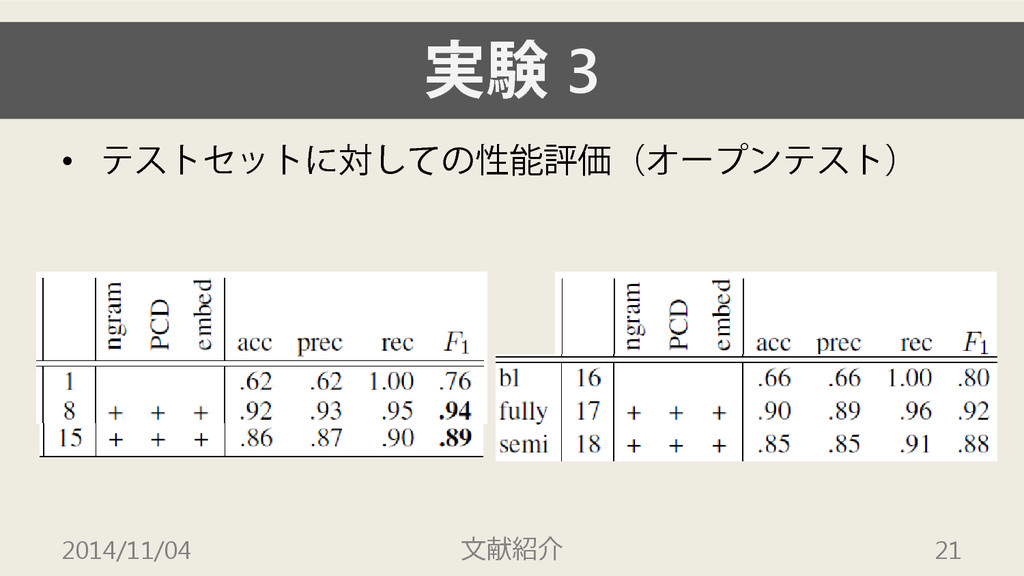
実験 3 • テストセットに対しての性能評価(オープンテスト) 2014/11/04 文献紹介 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}