Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[freee] 機械学習基盤におけるスポットインスタンスの有効活用
Search
Hiroyuki Tanaka
June 10, 2020
Technology
0
7.3k
[freee] 機械学習基盤におけるスポットインスタンスの有効活用
【オンラインセミナー】「コンテナ × スポットインスタンス」 活用セミナーの資料です
https://aws-seminar.smktg.jp/public/seminar/view/2212
Hiroyuki Tanaka
June 10, 2020
Tweet
Share
Other Decks in Technology
See All in Technology
ECS障害を例に学ぶ、インシデント対応に備えた AIエージェントの育て方 / How to develop AI agents for incident response with ECS outage
iselegant
4
460
Tebiki Engineering Team Deck
tebiki
0
24k
22nd ACRi Webinar - ChipTip Technology Eric-san's slide
nao_sumikawa
0
100
ブロックテーマ、WordPress でウェブサイトをつくるということ / 2026.02.07 Gifu WordPress Meetup
torounit
0
210
広告の効果検証を題材にした因果推論の精度検証について
zozotech
PRO
0
210
We Built for Predictability; The Workloads Didn’t Care
stahnma
0
150
プレビュー版のDevOpsエージェントを現段階で触ってみた
ad_motsu
1
110
[CV勉強会@関東 World Model 読み会] Orbis: Overcoming Challenges of Long-Horizon Prediction in Driving World Models (Mousakhan+, NeurIPS 2025)
abemii
0
150
Claude Code for NOT Programming
kawaguti
PRO
1
110
量子クラウドサービスの裏側 〜Deep Dive into OQTOPUS〜
oqtopus
0
150
10Xにおける品質保証活動の全体像と改善 #no_more_wait_for_test
nihonbuson
PRO
2
340
ClickHouseはどのように大規模データを活用したAIエージェントを全社展開しているのか
mikimatsumoto
0
270
Featured
See All Featured
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.1k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
88
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.7k
jQuery: Nuts, Bolts and Bling
dougneiner
65
8.4k
The SEO identity crisis: Don't let AI make you average
varn
0
330
Mind Mapping
helmedeiros
PRO
0
90
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
330
Writing Fast Ruby
sferik
630
62k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
240
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
61
52k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Embracing the Ebb and Flow
colly
88
5k
Transcript
freee 株式会社 機械学習基盤におけるスポットインスタンスの有効活用 2020.06.10
役割 機械学習エンジニア Twitter @aflc_jp Tanaka Hiroyuki 田中 浩之
freee株式会社 smb-AI-Lab 2
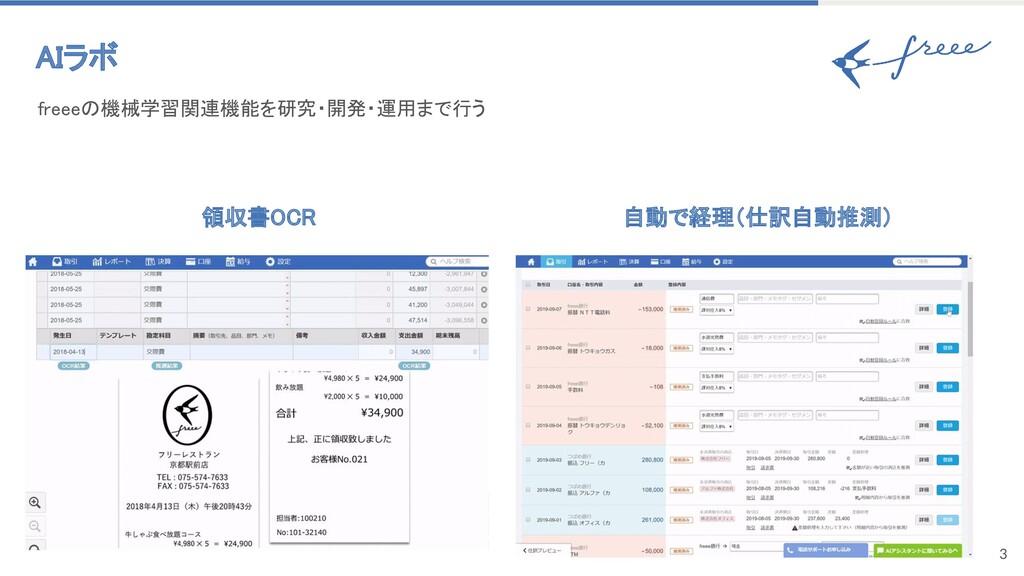
3 AIラボ freeeの機械学習関連機能を研究・開発・運用まで行う 領収書OCR 自動で経理(仕訳自動推測)
4 MLOps Workflow 自分たちが使いやすいようにDIY。現在は実験・開発フローを中心に構築中 モデル学習・パイプライン化 デプロイ・監視 仮説検証・データ設計・初期実験 企画・設計 請求
管理 コンテナベース開発環境 Custom Backend Solvarg (Internal Tool) Remote Job code-server Self-hosted パイプライン管理 学習基盤 EKS クラスタ Production EKS クラスタ
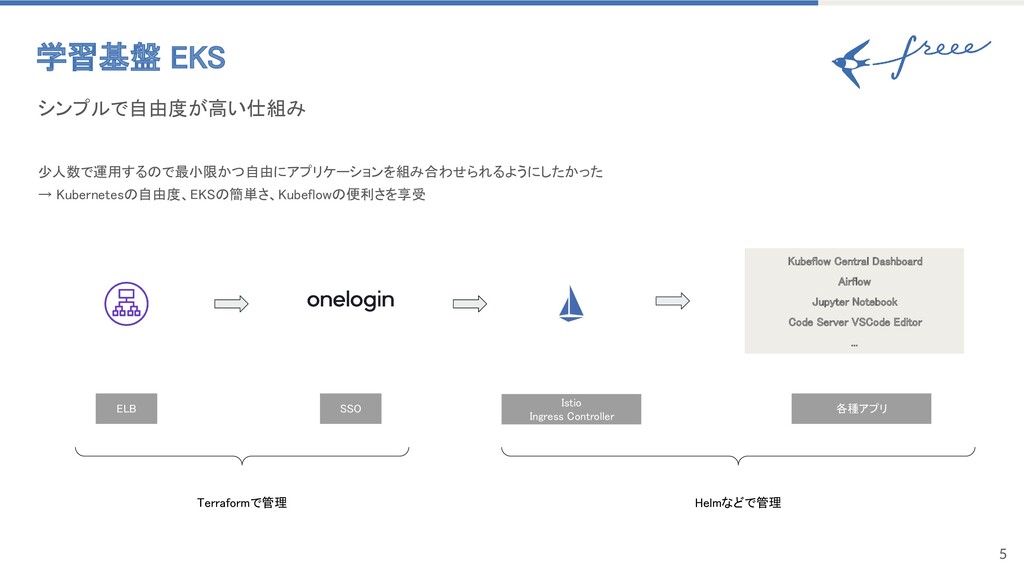
5 学習基盤 EKS 少人数で運用するので最小限かつ自由にアプリケーションを組み合わせられるようにしたかった → Kubernetesの自由度、EKSの簡単さ、Kubeflowの便利さを享受 シンプルで自由度が高い仕組み ELB SSO Istio
Ingress Controller 各種アプリ Kubeflow Central Dashboard Airflow Jupyter Notebook Code Server VSCode Editor ... Terraformで管理 Helmなどで管理
6 主なアプリケーション Kubeflow Jupyter Notebook Server機能を中心に使用中 入れるとIstio周りも自動で構成してくれるのが便利 モデル学習用のCRDなど、コンポーネントになっており選択的にインストールできる JupyterLab Custom
Image & code-server チームメンバー向けに標準化されたNotebook環境とエディタ環境を提供 Notebookでガリガリ実験するもよし、ターミナル&エディタでLinux環境(Pod)に入って開発してもよし Airflow プロダクション向けのデータ・学習パイプラインを実行する コードは独立したリポジトリで一元管理 Solvarg 社内製のKubernetes上で動くリモートジョブ実行ツール Airflowと連携出来るようになっており、実験フェイズからプロダクションフェイズにスムースに移行する事が出来る
7 作業風景
8 EKS Nodegroupsの設計 スポットインスタンスをフル活用する 最低限の基幹系Podのみをオンデマンドノードに配置し、それ以外のジョブ実行や 長時間動かすプロセスが無いものはスポットノードに配置して一旦運用中 例:
Istio、coredns、cluster-autoscaler -> オンデマンドインスタンス 学習ジョブ、Jupyter Notebook Server -> スポットインスタンス 運用してみて問題が出てきた段階でスポットからオンデマンドに切り替えればいいという割り切りでやってます Pod単位で気軽に設定・変更出来るのはEKSの強み
9 EKS Nodegroupsの設計 3種類のNodegroupを定義 system: オンデマンドインスタンスノードで、基幹系のPod用 job: スポットインスタンスノード。ジョブの一時実行用で頻繁にscale in/outする。CPUジョブ、GPUジョブ用にそれぞれNodegroupを用意 default:
それ以外の雑多なPodを配置するノード。こちらもスポットインスタンスで起動 system (on-demand) job (spot) pod pod pod pod pod pod pod pod default(spot) pod pod
10 Podの振り分け方法 NodeAffinityとTaints/Tolerationsを使う label: A NodeAffinity Pod側で指定する。特定のラベルがついたノードに配置する設定 label: B Affinity:
B Affinity: A
11 Podの振り分け方法 taints有 Taints/Tolerations ノード(taints)とPod(tolerations)にそれぞれ与える通行手形みたいなもの。同じ手形が無いと関所を通過してノードに配置できない taints無 Toleration有 Toleration無 A A
NodeAffinityとTaints/Tolerationsを使う
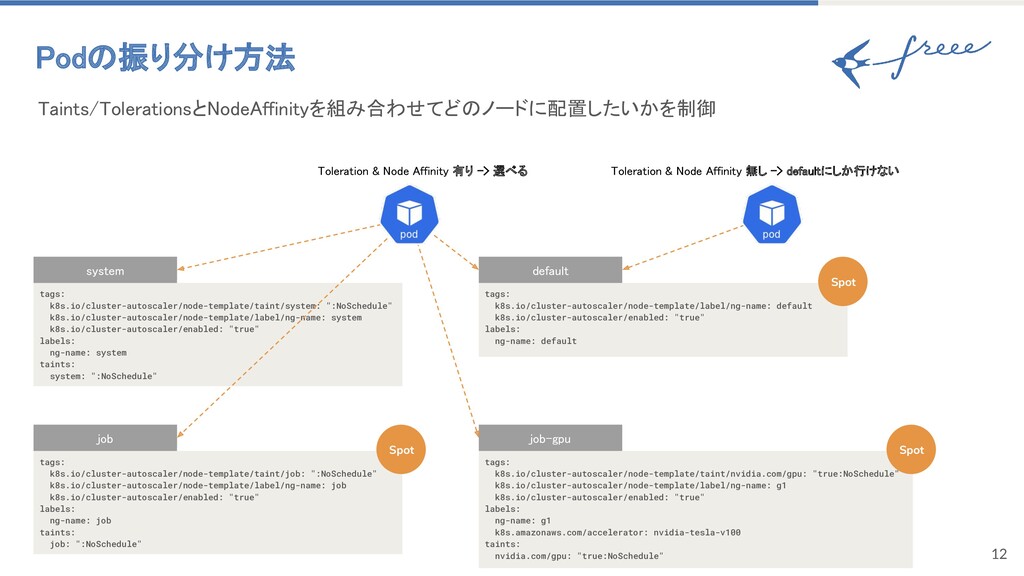
12 Podの振り分け方法 Taints/TolerationsとNodeAffinityを組み合わせてどのノードに配置したいかを制御 tags: k8s.io/cluster-autoscaler/node-template/taint/system: ":NoSchedule" k8s.io/cluster-autoscaler/node-template/label/ng-name: system k8s.io/cluster-autoscaler/enabled: "true"
labels: ng-name: system taints: system: ":NoSchedule" system tags: k8s.io/cluster-autoscaler/node-template/taint/job: ":NoSchedule" k8s.io/cluster-autoscaler/node-template/label/ng-name: job k8s.io/cluster-autoscaler/enabled: "true" labels: ng-name: job taints: job: ":NoSchedule" job tags: k8s.io/cluster-autoscaler/node-template/taint/nvidia.com/gpu: "true:NoSchedule" k8s.io/cluster-autoscaler/node-template/label/ng-name: g1 k8s.io/cluster-autoscaler/enabled: "true" labels: ng-name: g1 k8s.amazonaws.com/accelerator: nvidia-tesla-v100 taints: nvidia.com/gpu: "true:NoSchedule" job-gpu tags: k8s.io/cluster-autoscaler/node-template/label/ng-name: default k8s.io/cluster-autoscaler/enabled: "true" labels: ng-name: default default Toleration & Node Affinity 有り -> 選べる Spot Spot Spot Toleration & Node Affinity 無し -> defaultにしか行けない
13 Podの振り分け方法 ポイント • オンデマンドインスタンスに必要最小限のPodを配置出来る(但し自分で設定のカスタマイズが必要) • 何も設定していないPodは自動的にdefaultノードに行くので、全Podにaffinityを付けて回らなくても良い用になっている • 機械学習系やデータ処理など、CPU/メモリを多く使う場合はピンポイントでNodegroup(インスタンスサイズ)を指定して起動できる
◦ Resource Requestsと組み合わせて実質的にノードを一つ専有して使う事も可能 • GPUノードを必要なときだけ立ち上げて使える
14 Cluster AutoscalerとSpot Allocation Strategy Cluster Autoscaler • いろんなサイズのジョブ=インスタンスが立ち上がるので、expander=least-wasteに設定 ◦
least-waste: CPU/Memoryの空きが少なくなるように新規ノードを立ち上げる ◦ デフォルトはランダム ちょっとした設定ポイント spotAllocationStrategy • スポットインスタンスノード上で動くジョブの中断機会を減らすため、スポットインスタンスの配分戦略をデフォル トのlowestPriceではなくcapacityOptimizedにしている nodeGroups: - instancesDistribution: onDemandBaseCapacity: 0 onDemandPercentageAboveBaseCapacity: 0 spotAllocationStrategy: capacity-optimized instanceTypes: - r5.xlarge eksctl設定例
15 Tips: GPU付きのJupyter Notebookを起動する Kubeflow標準ではTolerationを付与できない為、GPUインスタンス上でJupyter Notebook Serverを起動できない → ExtendedResourceToleration
Admission Controllerを利用すると、Taintsを自動で付与できる ExtendedResourceTolerationで tolerationを自動付与 tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" GPUノードが起動 Taintsをセットする事で予期せぬPodがGPU ノードに配置されることを防ぐ • 尚、ExtendedResourceTolerationはEKSで有効化されていないので、同様の機能を持つadmission webhookを自作した ◦ https://github.com/roy-ht/extended-resource-toleration-webhook
16 まとめ 今後挑戦したいこと • 予期せぬ中断に対する対策の標準化 ◦ Airflowジョブや学習ジョブのリトライ時の挙動を統一して途中から再開できるようにしたい ▪ https://github.com/kube-aws/kube-spot-termination-notice-handler •
ただ猶予が二分しかないのでデータ処理・機械学習の場合は常にチェックポイントをS3などに保存して再開可能 にすべき • Advanced Security: SA Roleの細かい設定やOpen Policy Agentの導入 • EKSとスポットインスタンスを活用した機械学習ワークロード向けの開発基盤の構築例を ご紹介しました • 開発者の知識と権限をAWSとKubernetesでうまく分離できる所が使いやすい ◦ 一般の開発者はKubeflow/Kubernetesの最低限の使い方を覚える ◦ メンテナはEKSで運用コストを低く抑えながらk8sエコシステムの恩恵を受けられる ▪ (端的に言うとeksctlは神) • 欲を言うと、もう少しノードのプロビジョニングが速いと嬉しい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}