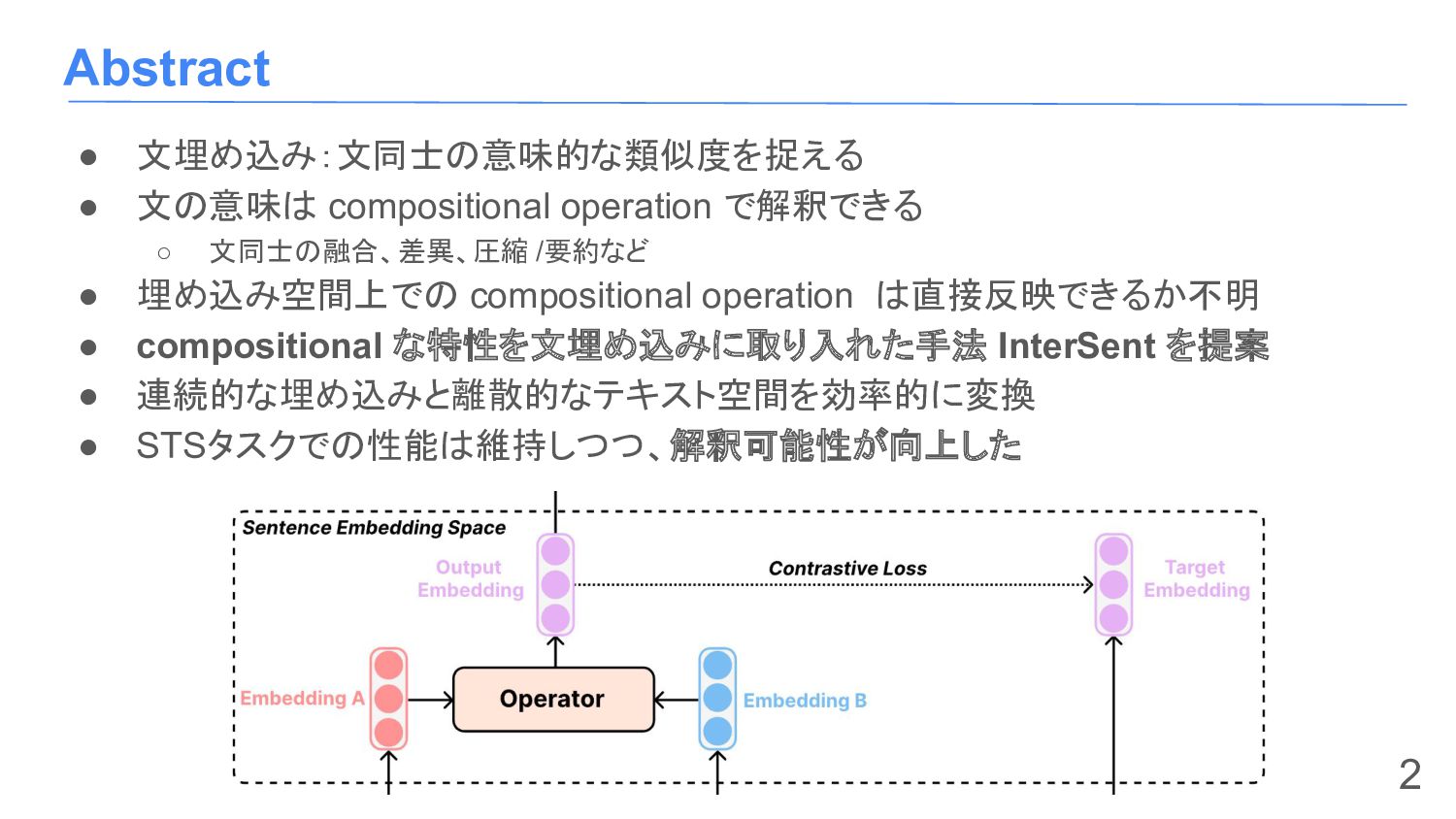
教師なし文埋め込み [Kiros+, 2015][Hill+, 2016][Logeswaran and Lee, 2018] ◦ 教師あり文埋め込み [Conneau+, 2017][Cer+, 2018][Reimers and Gurevych, 2019] ◦ 対照学習 [Giorgi+, 2021][Yan+, 2021][Gao+, 2021][Chuang+, 2022] • Representation Interpretability ◦ 埋め込みの構成性に関する研究 ▪ 単語埋め込み [Pennington+, 2014][Arora+, 2016][Ethayarajh+, 2019] ▪ 文埋め込み [Zhu and de Melo, 2020] ▪ 事前学習済みモデルの単語 /フレーズ埋め込み [Yu and Ettinger, 2020][Hupkes+, 2020] [Dankers+, 2022][Liu and Neubig, 2022] ◦ 文埋め込みからの言語生成 [Giorgi+, 2021][Wang+, 2021][Huang+, 2021][Wu and Zhao, 2022] 3
{kind=link}
{kind=link}
![Related work • Sentence Embedding ◦ 分布仮説 [Harris, 1954] ◦](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_2.jpg){kind=link}
![SimCSE [Gao+, 2021] • 対照学習 ◦ 正例を近づけて,負例を遠ざける手法 ◦ どのように正例のペアを見つけるかが重要 ◦](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
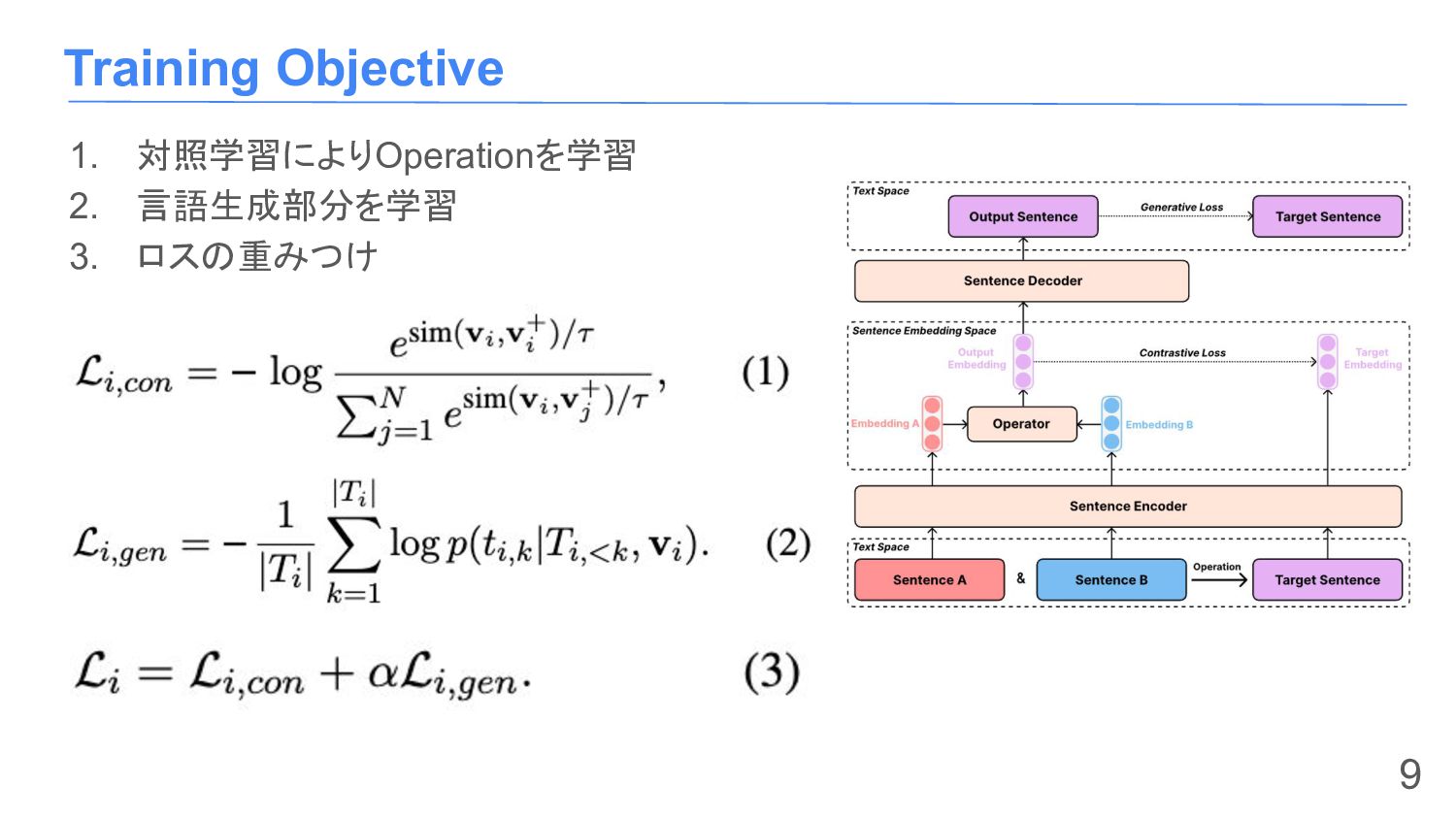{kind=link}
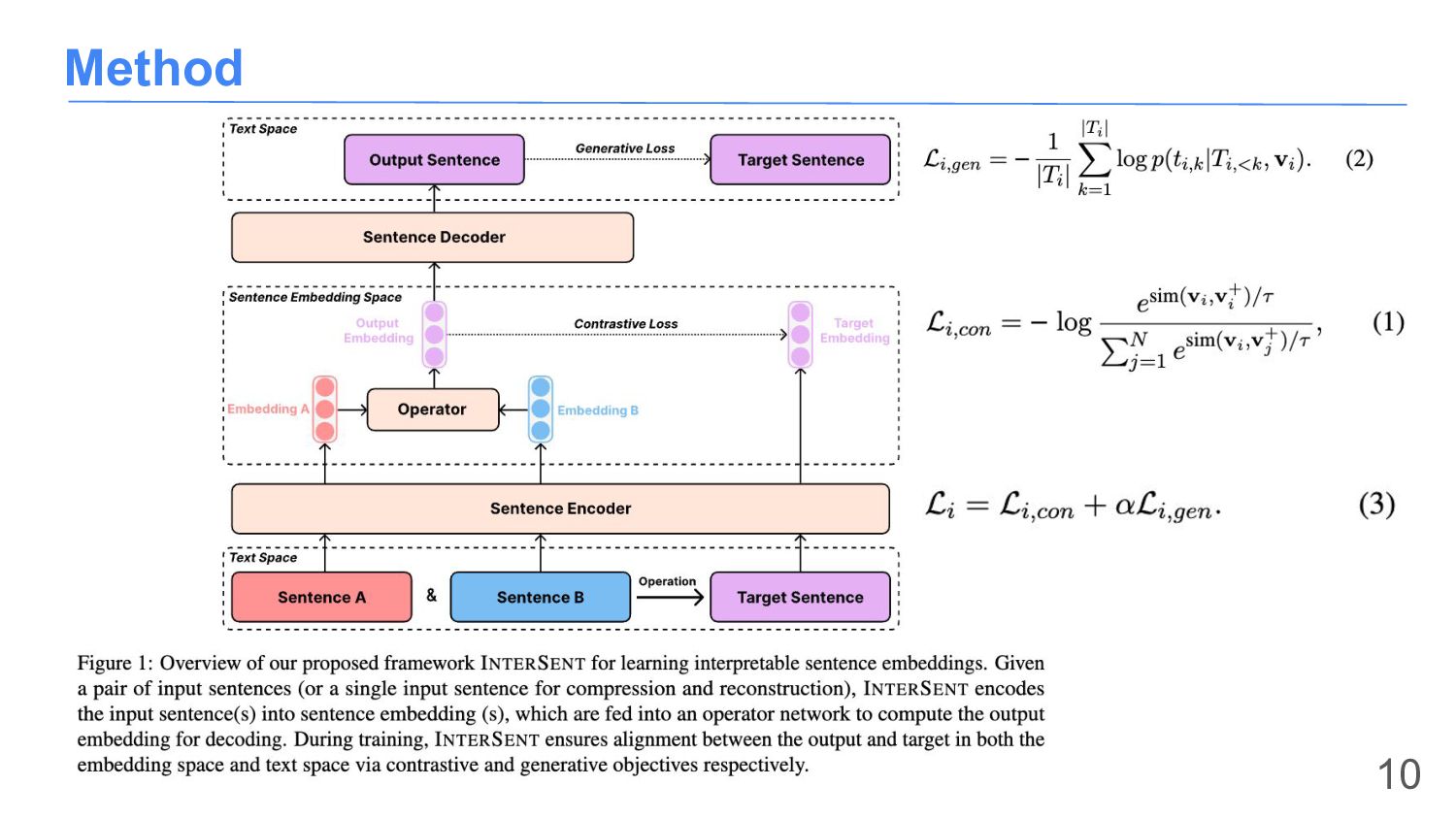{kind=link}
{kind=link}
{kind=link}
![Baselines • 従来のモデル ◦ RoBERTa-cls:RoBERTa で [CLS] を文埋め込みとして扱う ◦ RoBERTa-avg:RoBERTa](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_12.jpg){kind=link}
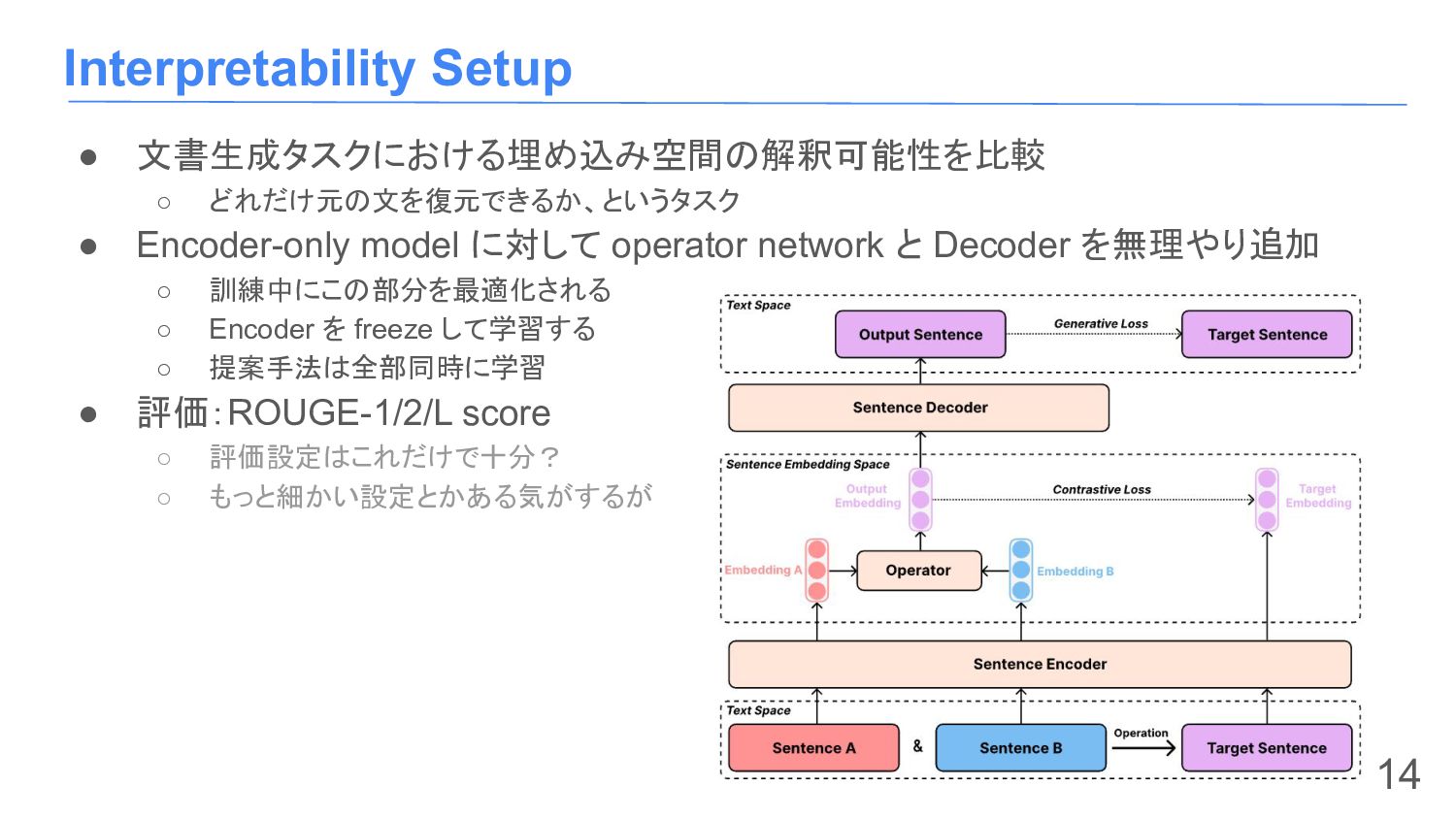{kind=link}
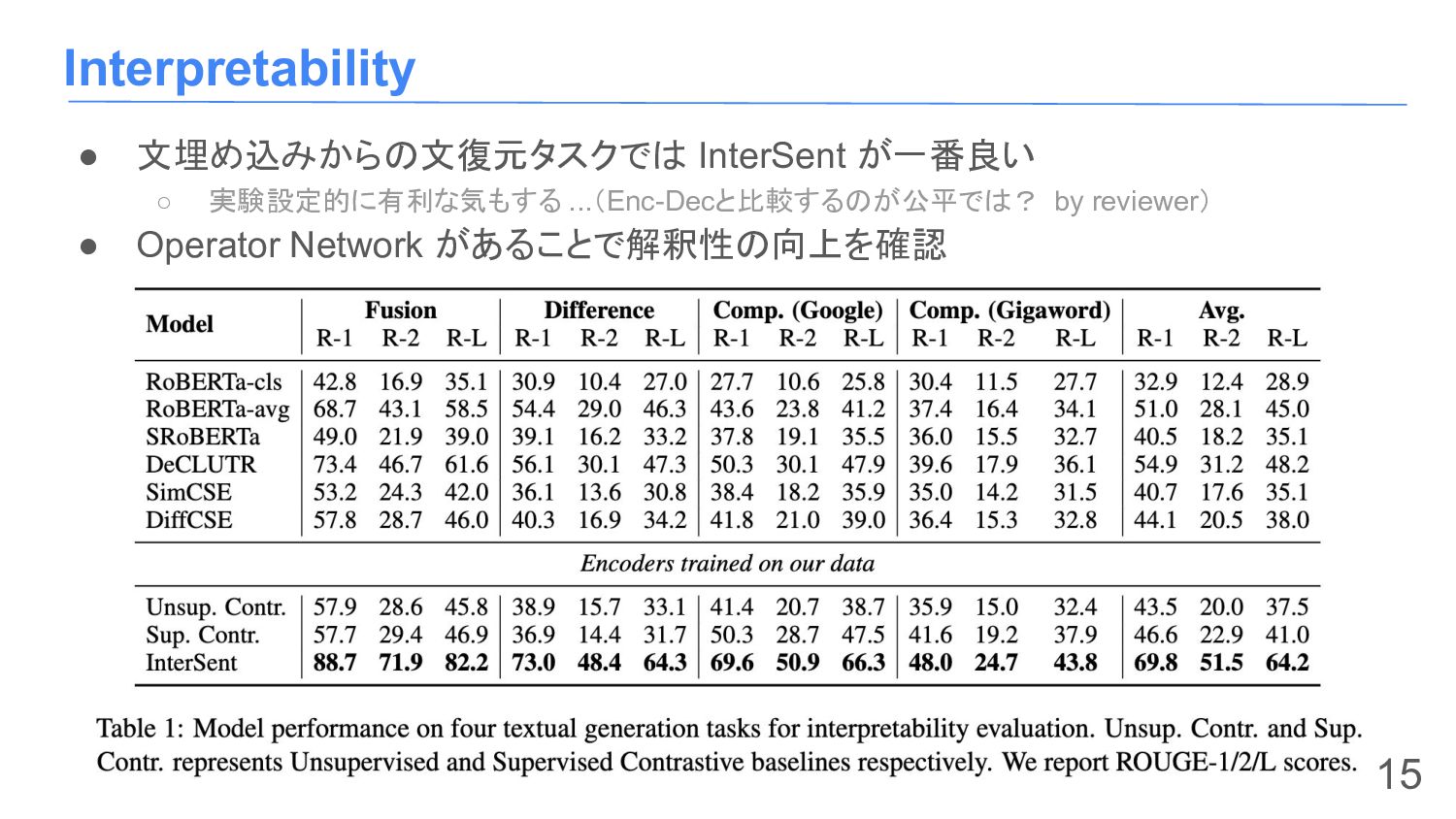{kind=link}
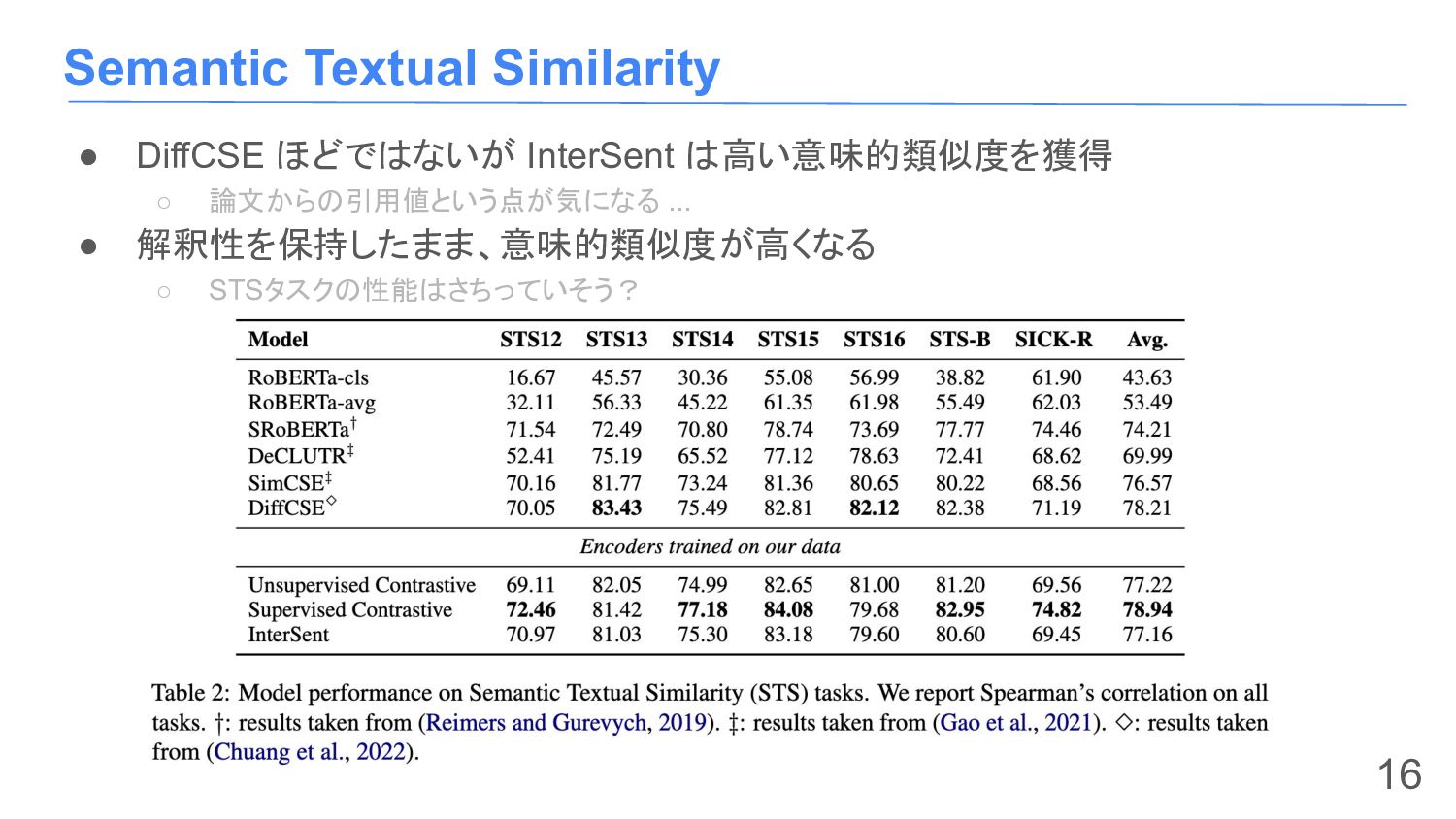{kind=link}
![Sentence Retrieval • 文抽出タスク ◦ Dataset:QQP ◦ BEIR [Thakur+, 2021]](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
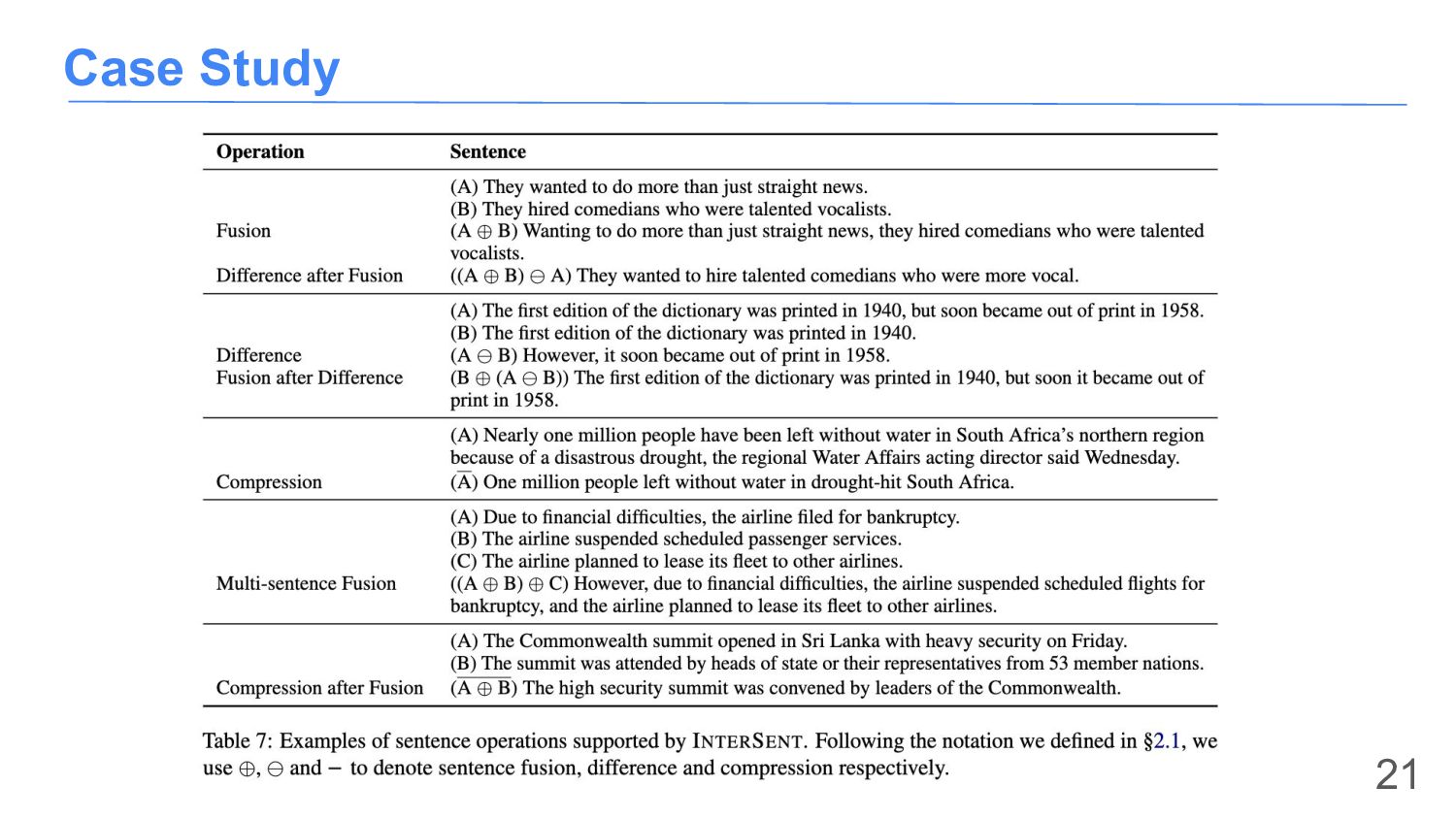{kind=link}
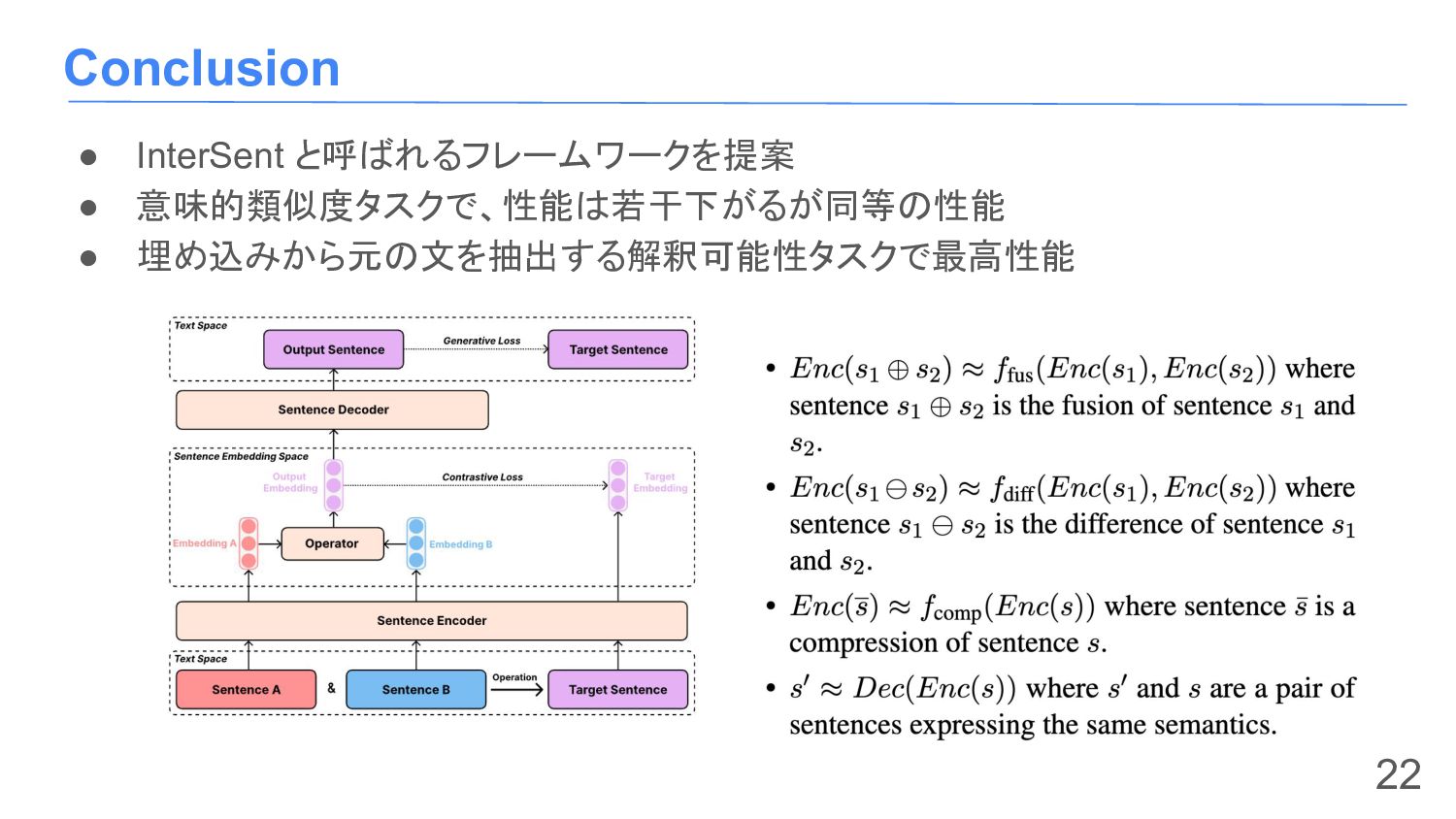{kind=link}
{kind=link}
{kind=link}