KMC 春合宿2024の講座として発表したスライド資料です.内容はNeural Radiance FieldsをCUDA C++でフルスクラッチ実装してみたので,そのうえで実装に近い視点でNeural Radiance Fieldsを説明していくものとなります.実装に完全に特化した説明を読みたい場合は私が先日書いた記事を参考にしていただけると嬉しいです.CUDAによる実装(ソースコード)の一部とそれに対する説明,そしてそのプログラムを動かした結果などが記述されています.
[URL]
Part1: MLP編: https://tetrisyoshi.hatenablog.com/entry/2024/01/21/213713
Part2: エンコーダー編: https://tetrisyoshi.hatenablog.com/entry/2024/02/13/141046
Part3: NeRF編: https://tetrisyoshi.hatenablog.com/entry/2024/02/24/155515
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Neural Radiance Fields [Ben M. et.al. ECCV 2020] 略して“NeRF(ナーフ)”と書かれることが多い 2次元の色んな視点から見た空間の画像をもとに,対象の3次元空間を推定](https://files.speakerdeck.com/presentations/2e4e2994a6094b9f860a85c0681d35d8/slide_4.jpg){kind=link}
![Instant NeRF [NVIDIA, 2022] 6](https://files.speakerdeck.com/presentations/2e4e2994a6094b9f860a85c0681d35d8/slide_5.jpg){kind=link}
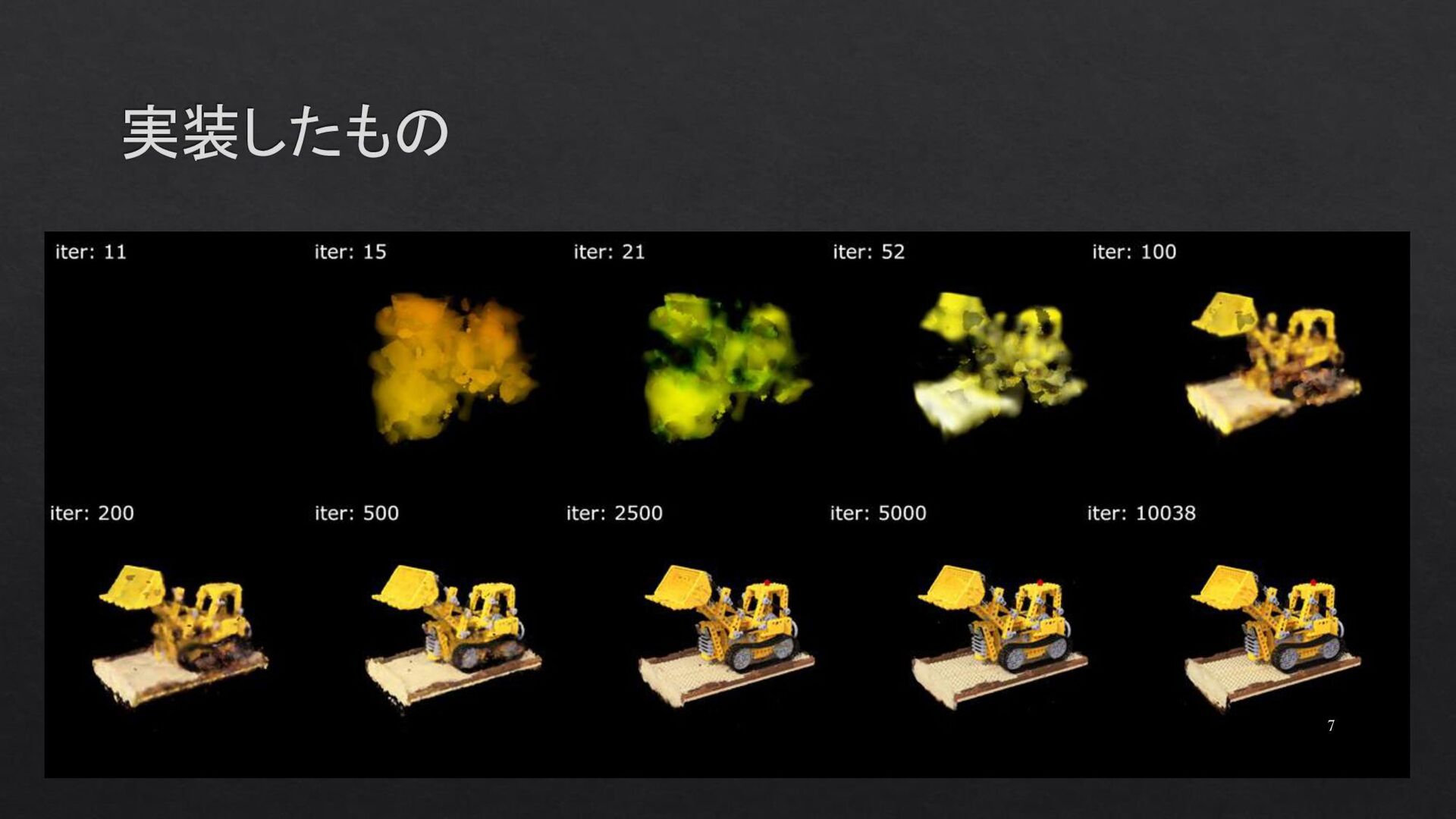{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
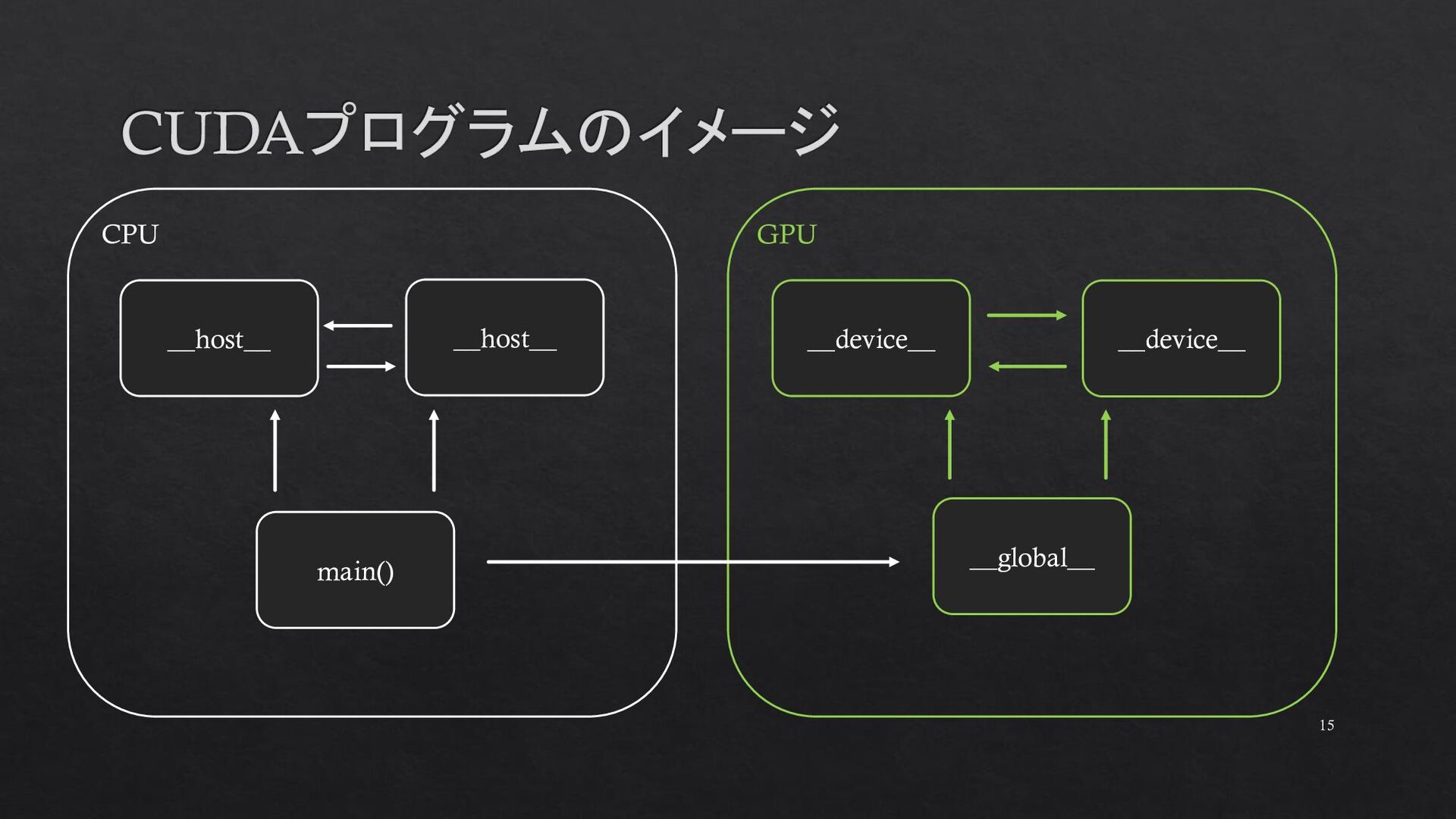{kind=link}
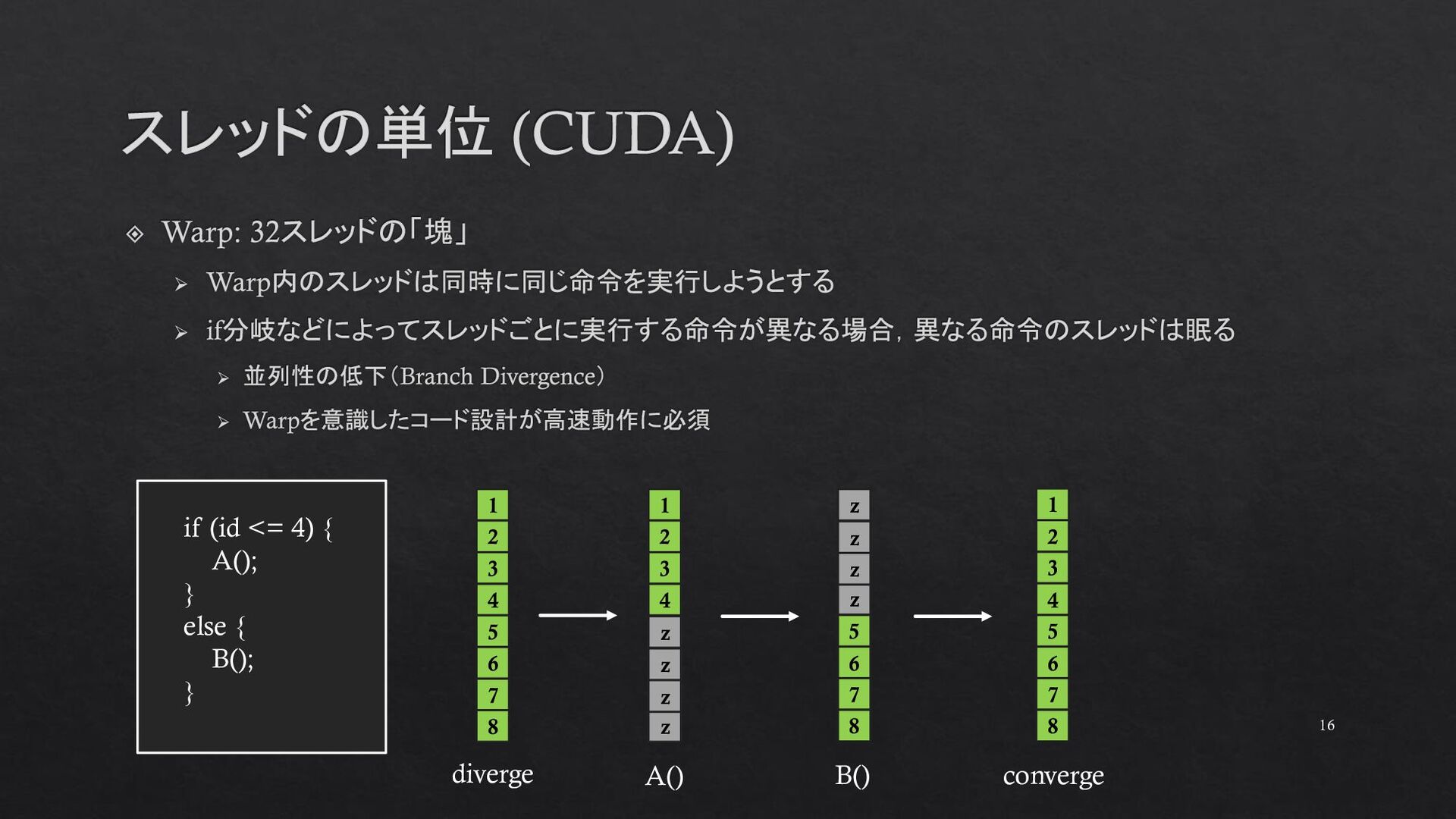{kind=link}
{kind=link}
{kind=link}
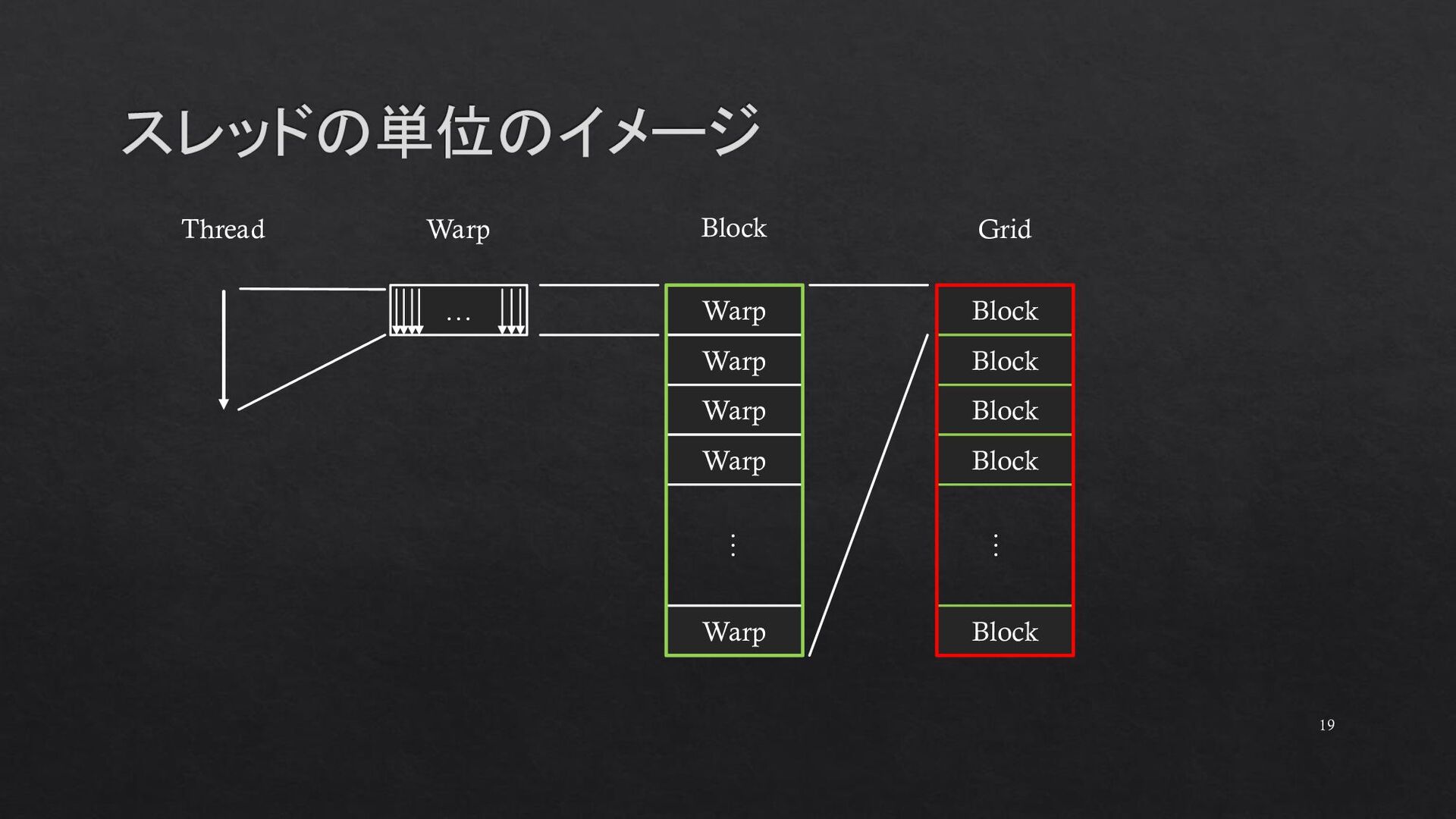{kind=link}
{kind=link}
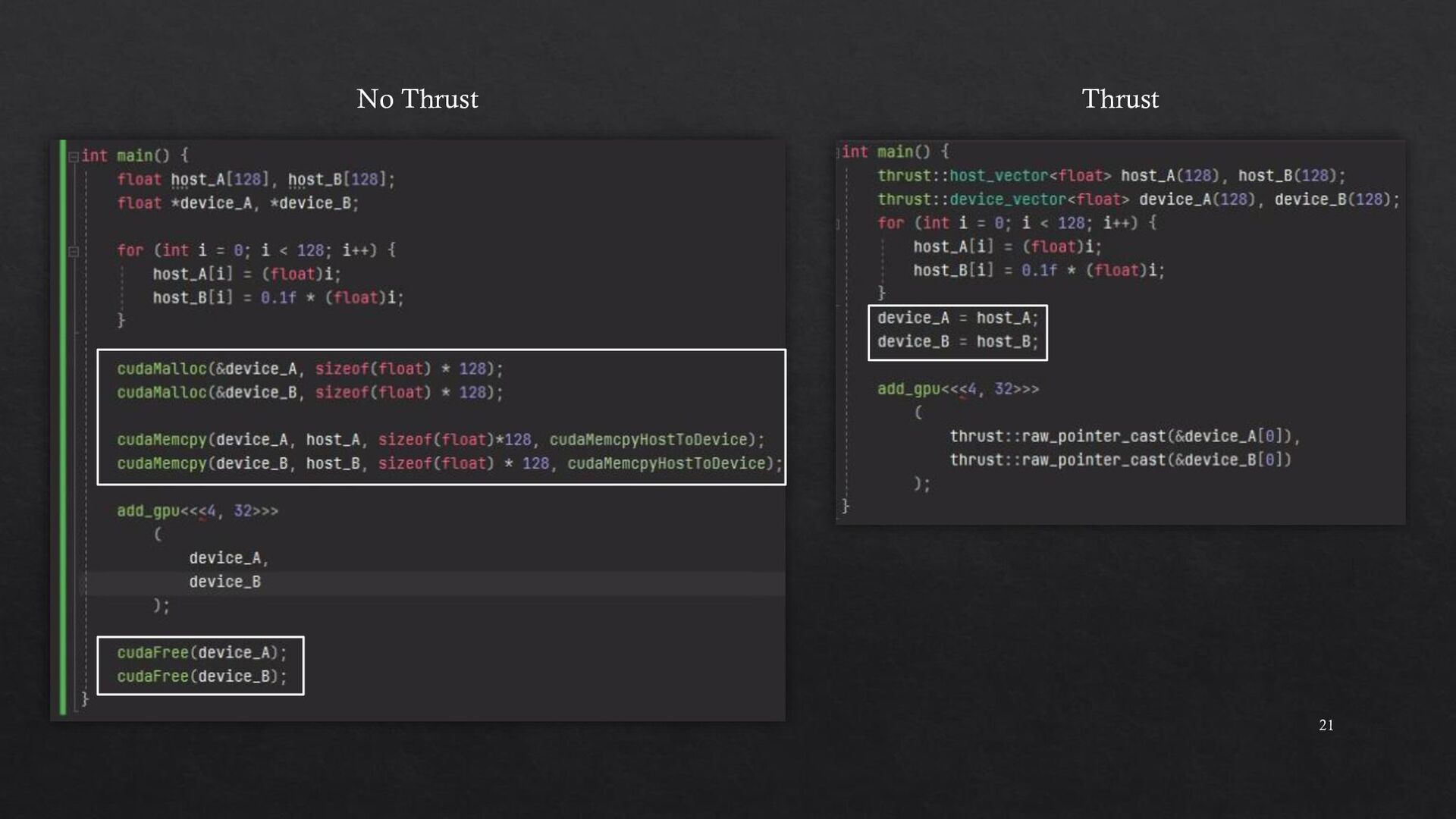{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
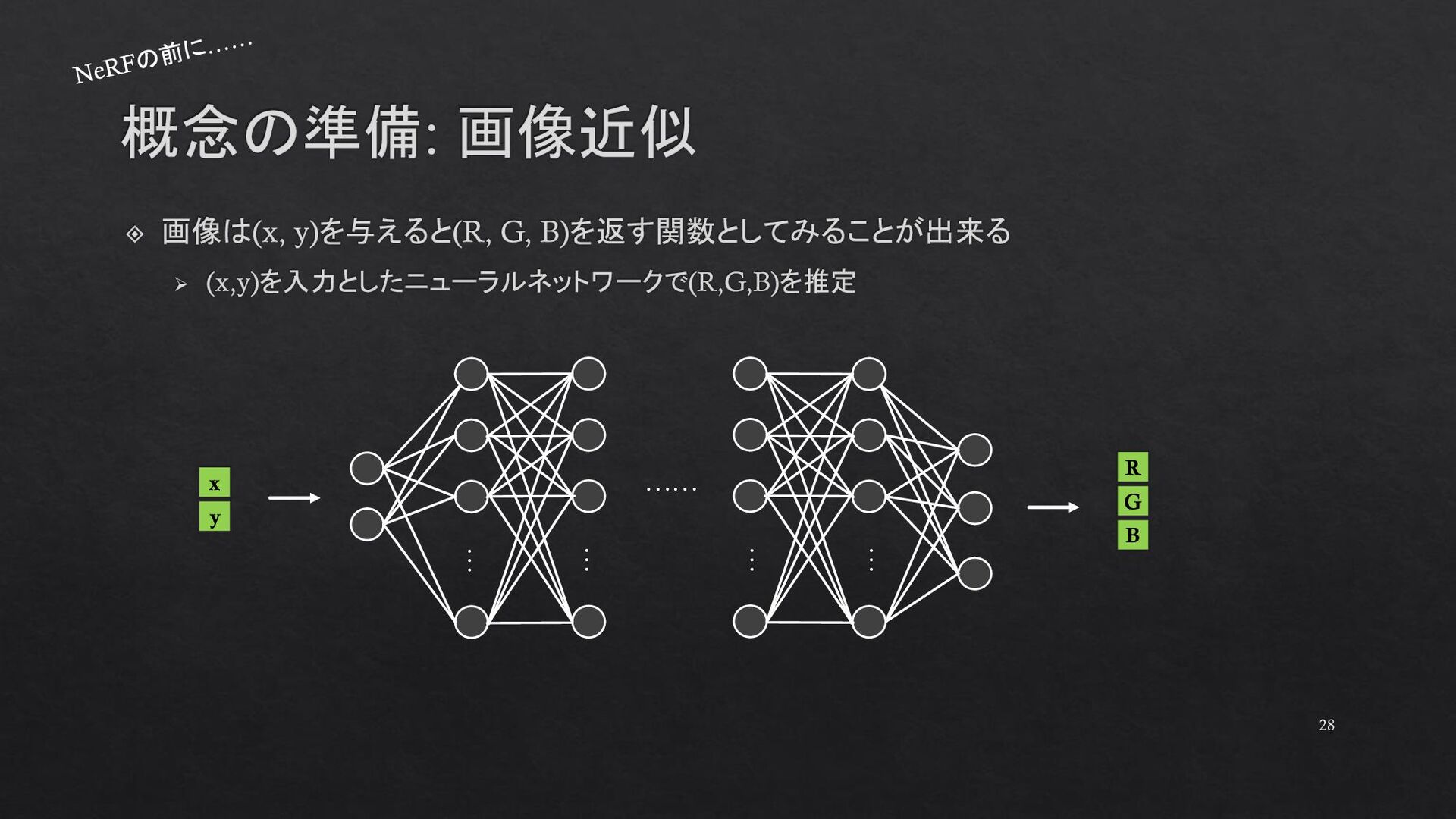{kind=link}
{kind=link}
{kind=link}
{kind=link}
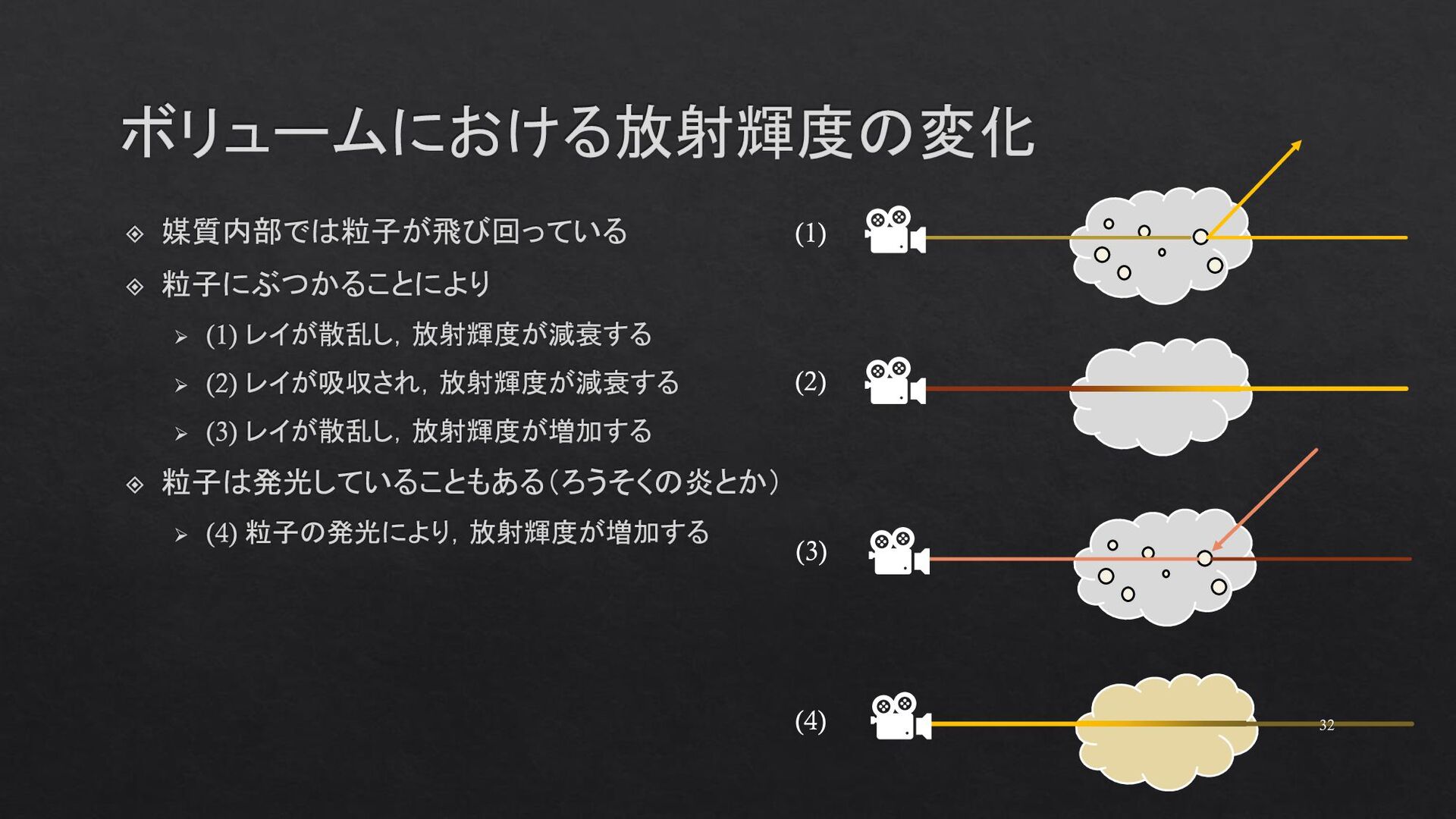{kind=link}
{kind=link}
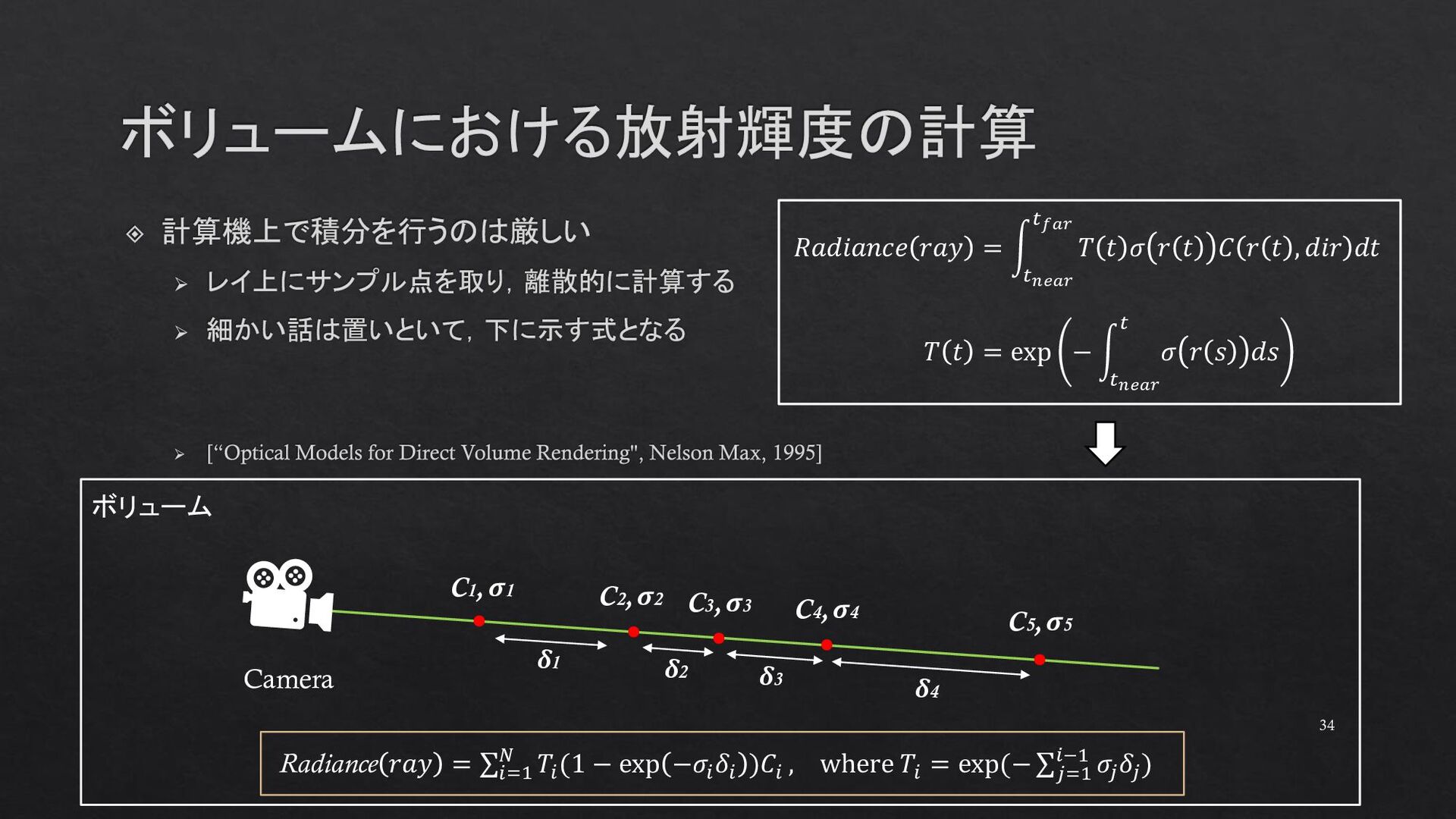{kind=link}
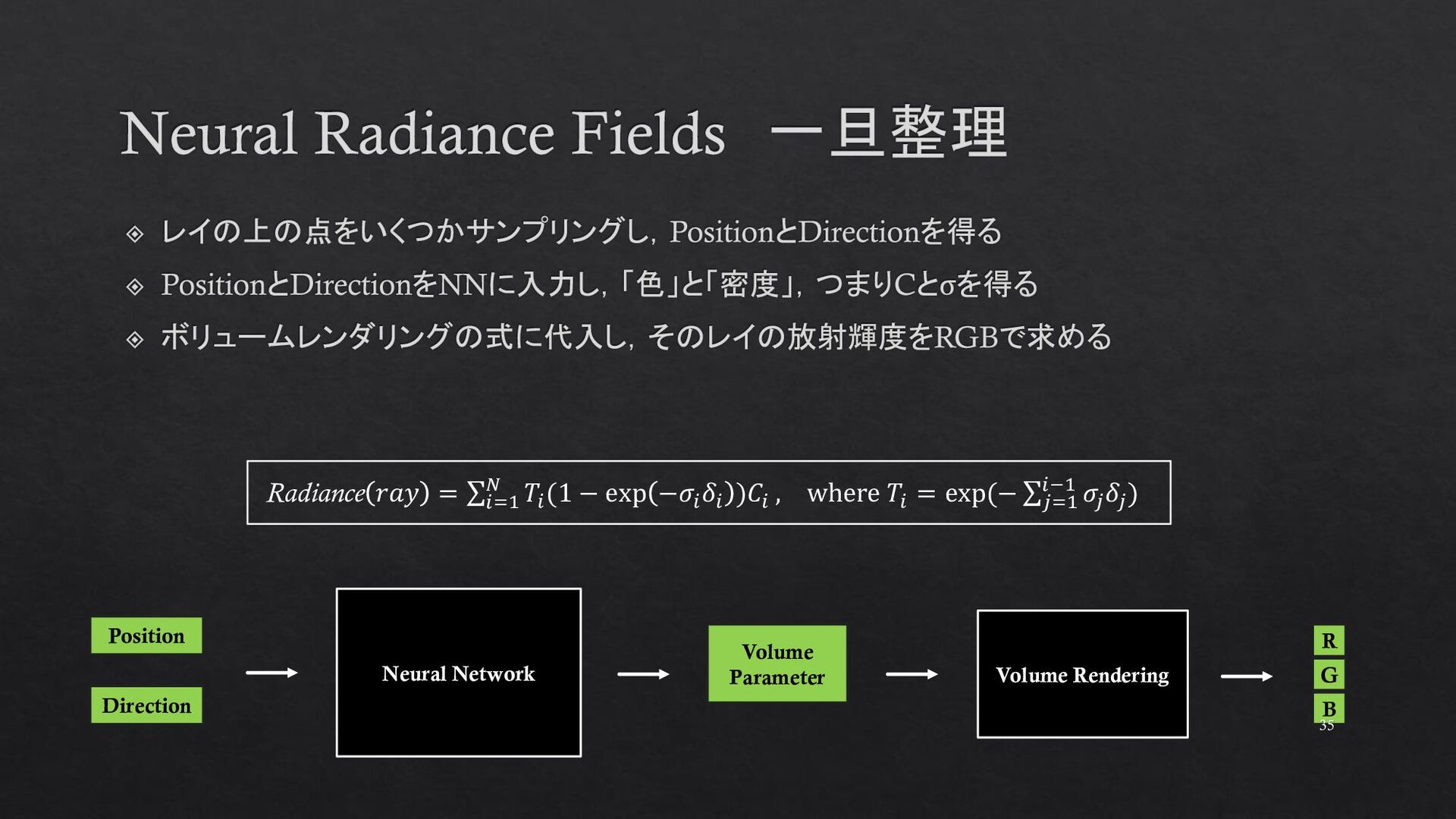{kind=link}
{kind=link}
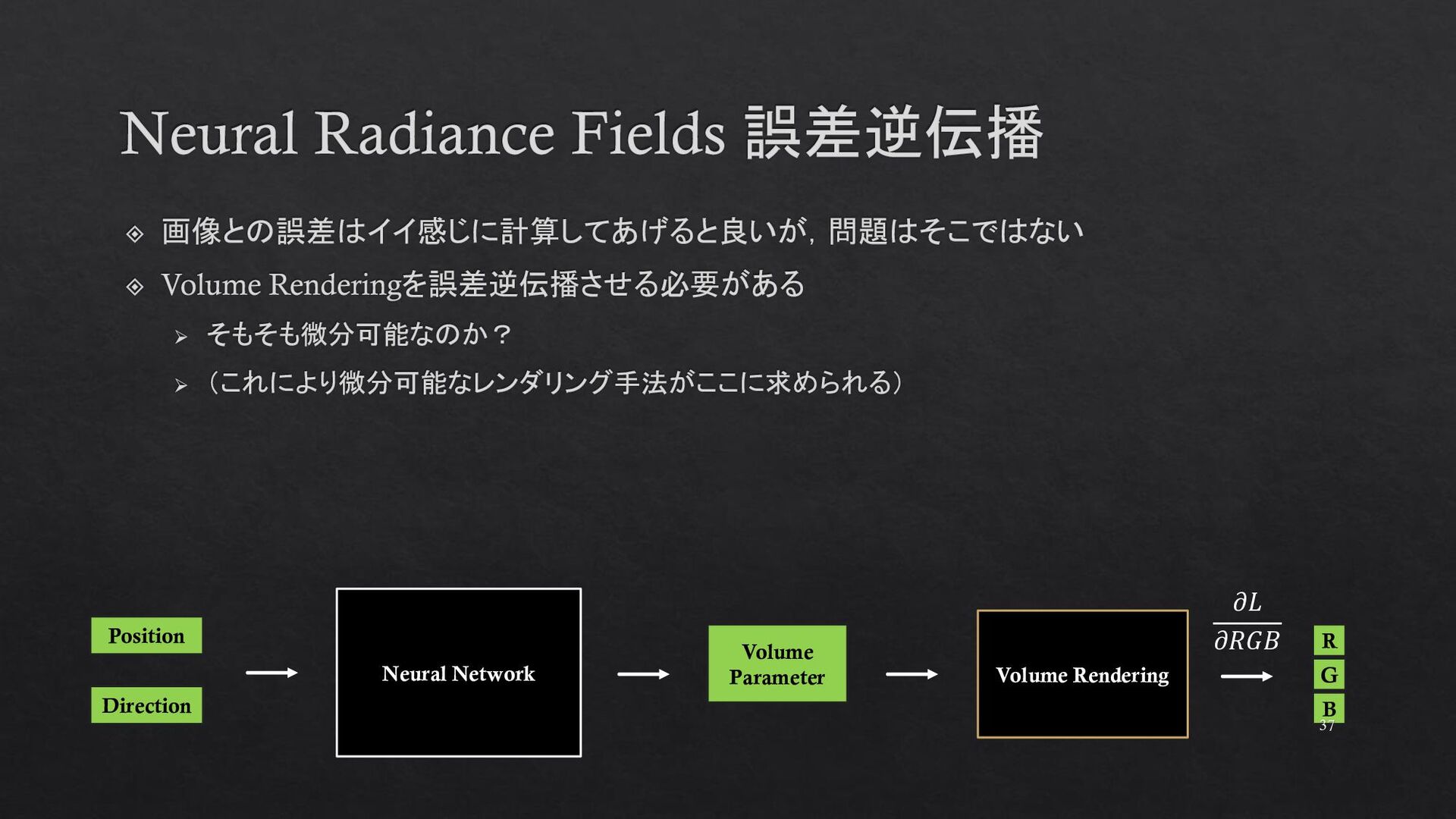{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
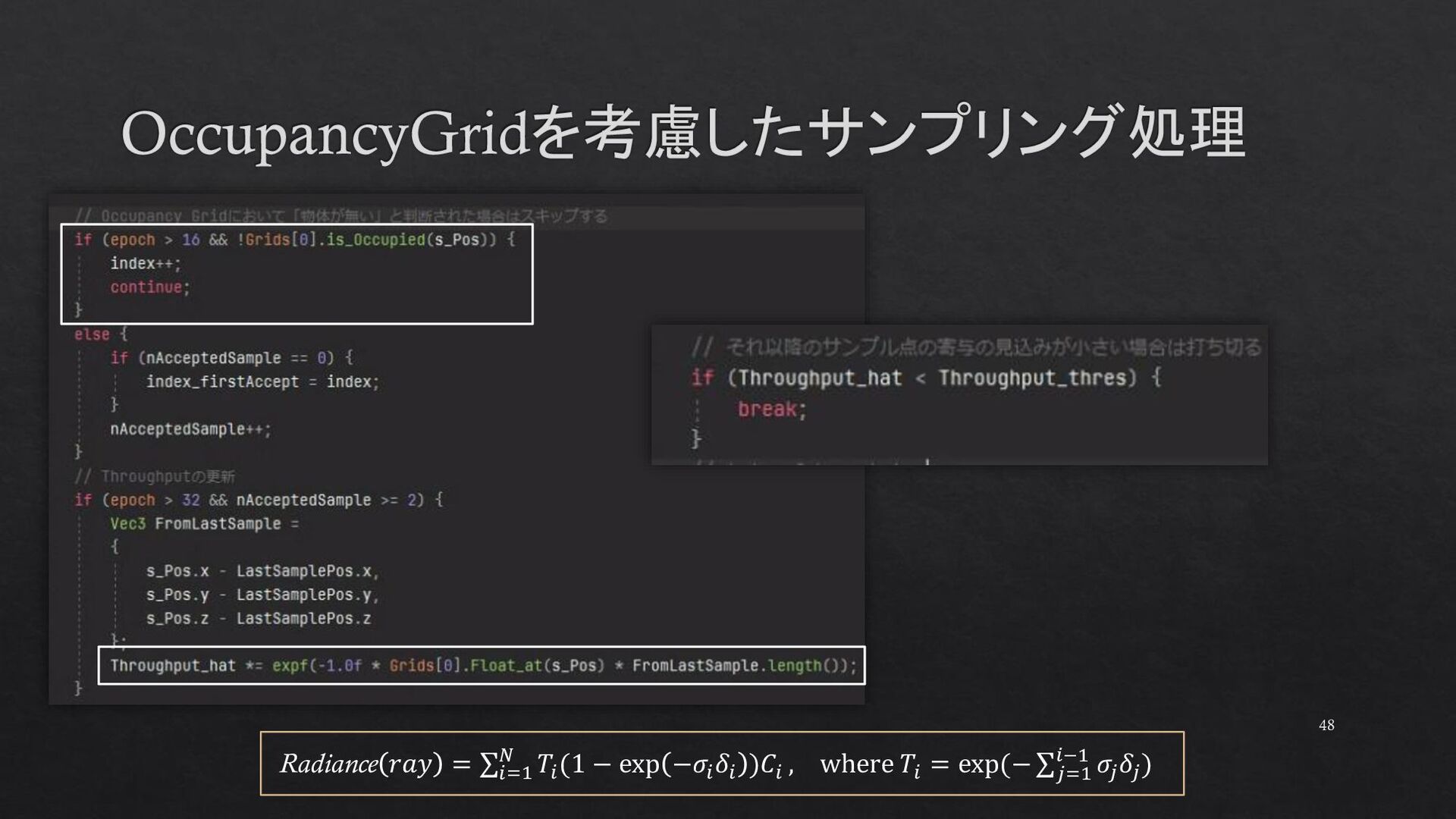{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
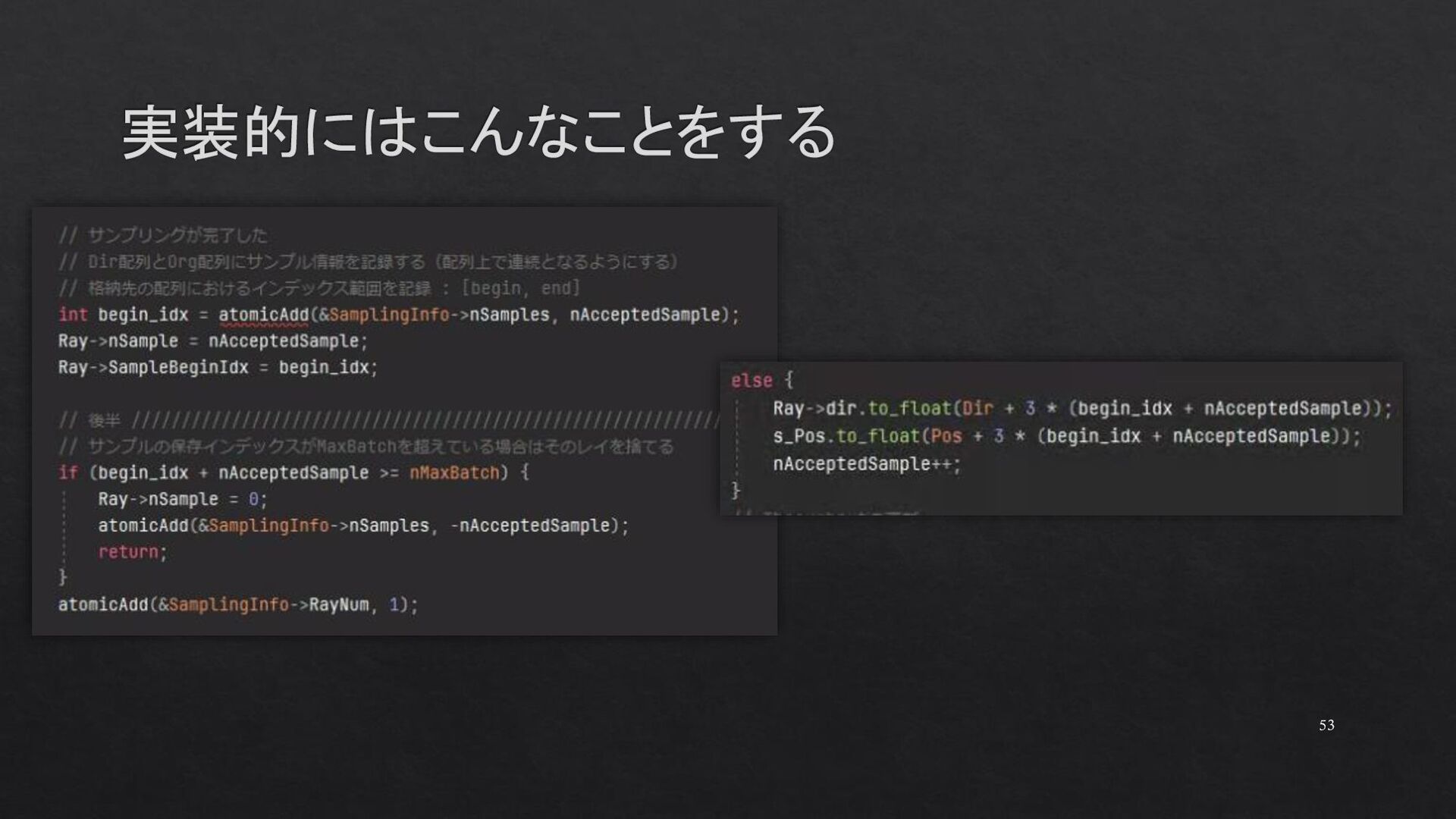{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
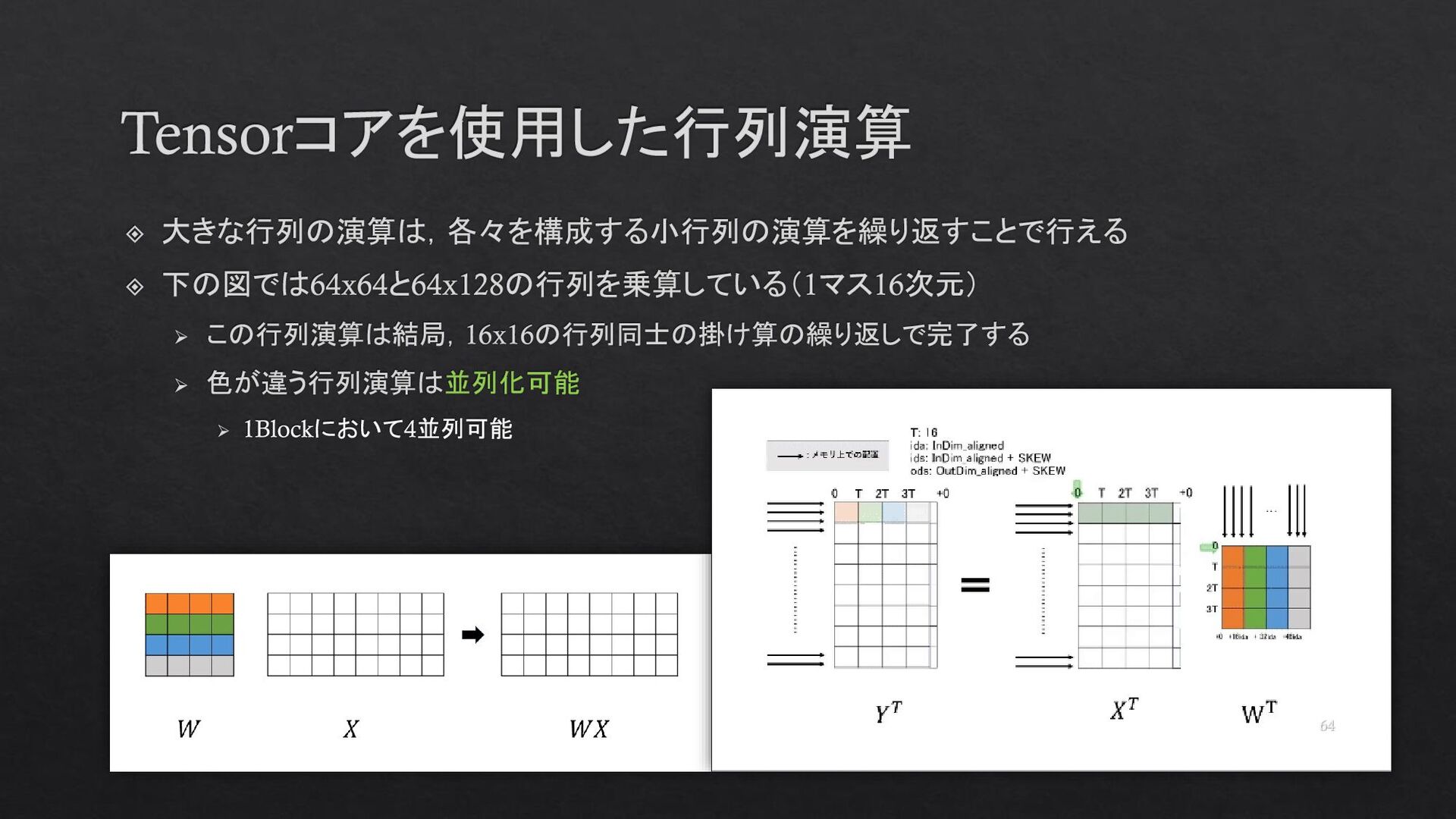
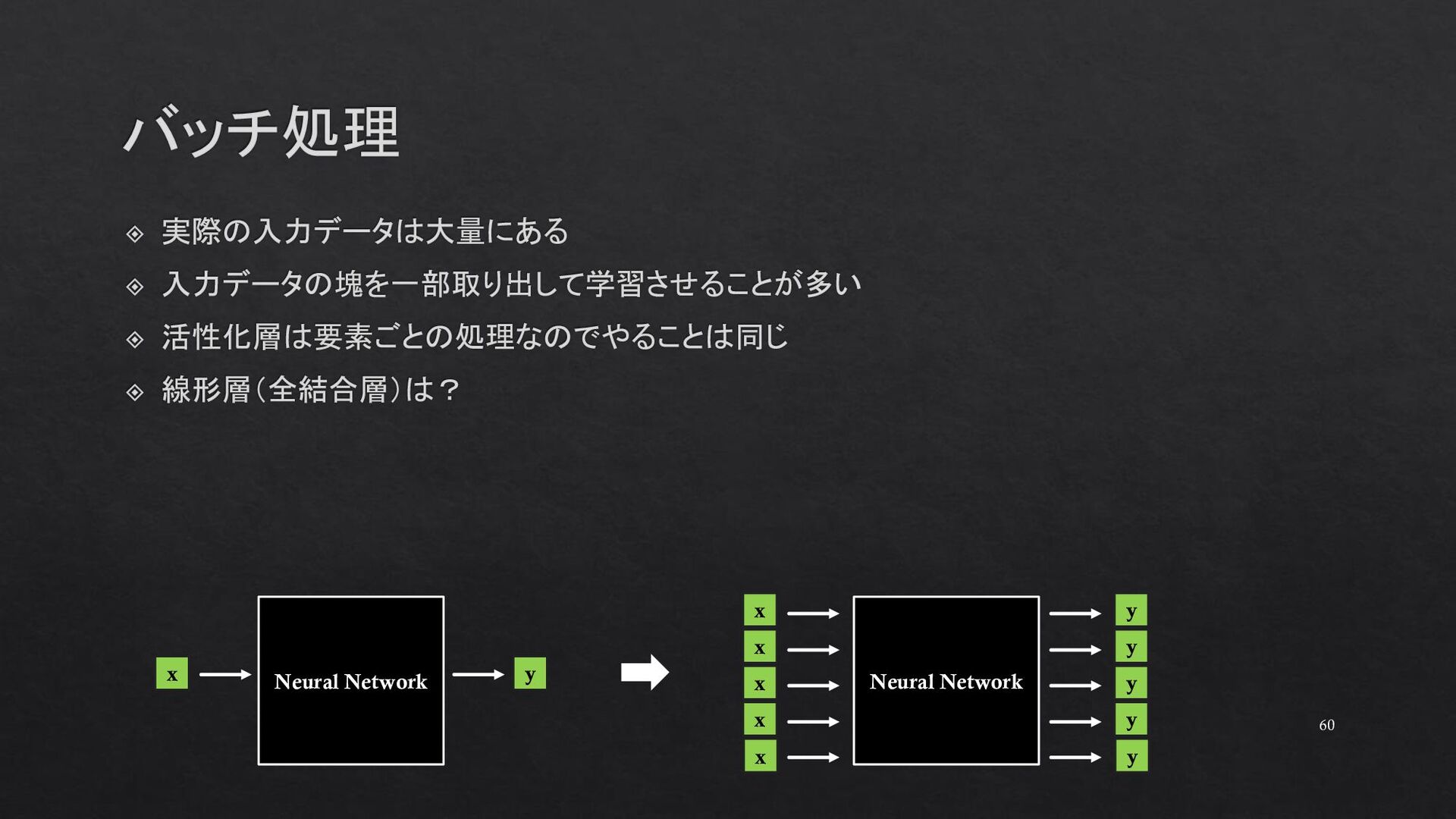{kind=link}
{kind=link}
{kind=link}
![Fully Fused MLP [NVIDIA 2021] NVIDIA GPUに最適化されたMLPの実装 shared memoryを最大活用し,global memoryとのやり取りを最小限に抑える](https://files.speakerdeck.com/presentations/2e4e2994a6094b9f860a85c0681d35d8/slide_62.jpg){kind=link}
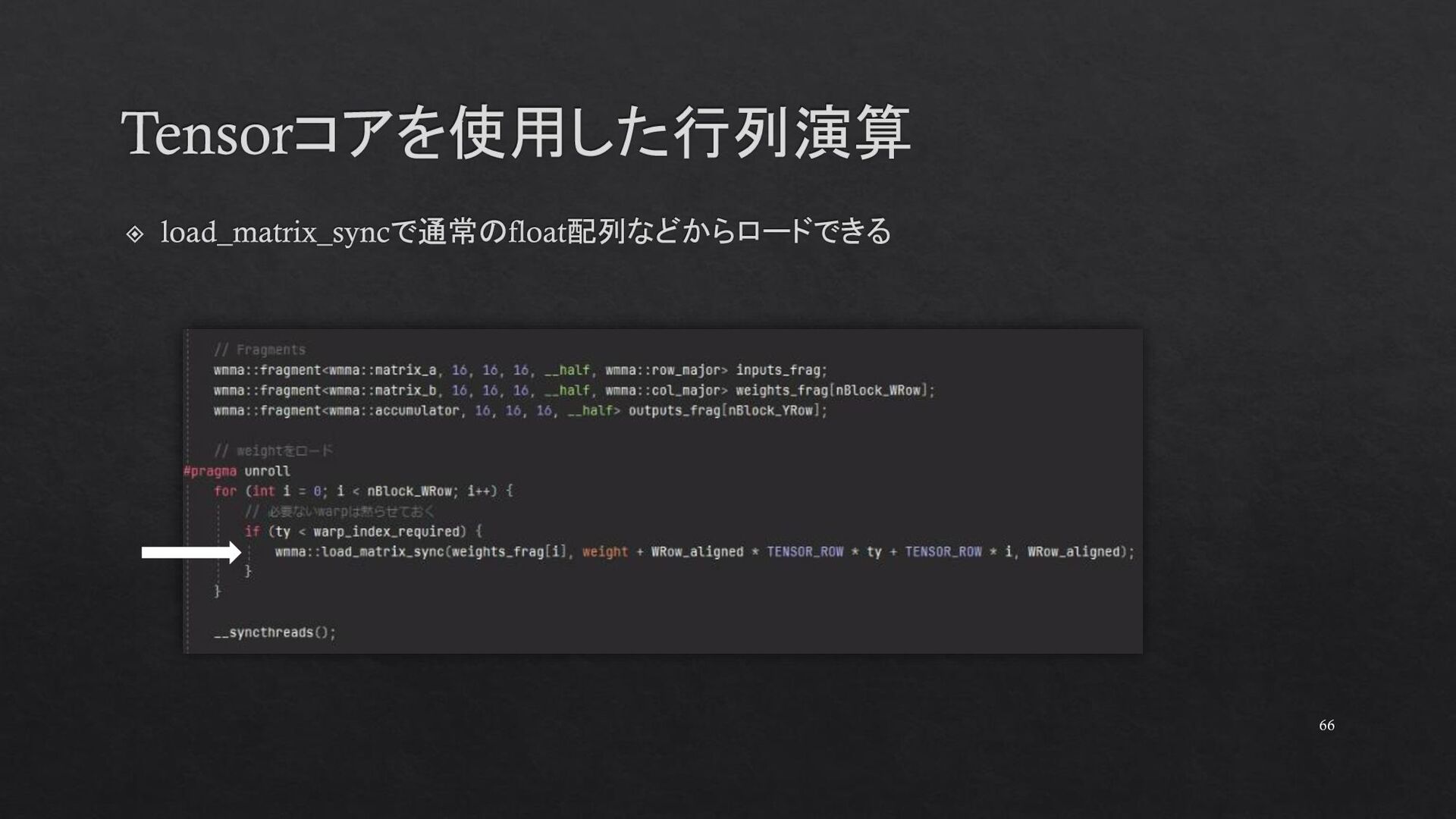
{kind=link}
{kind=link}
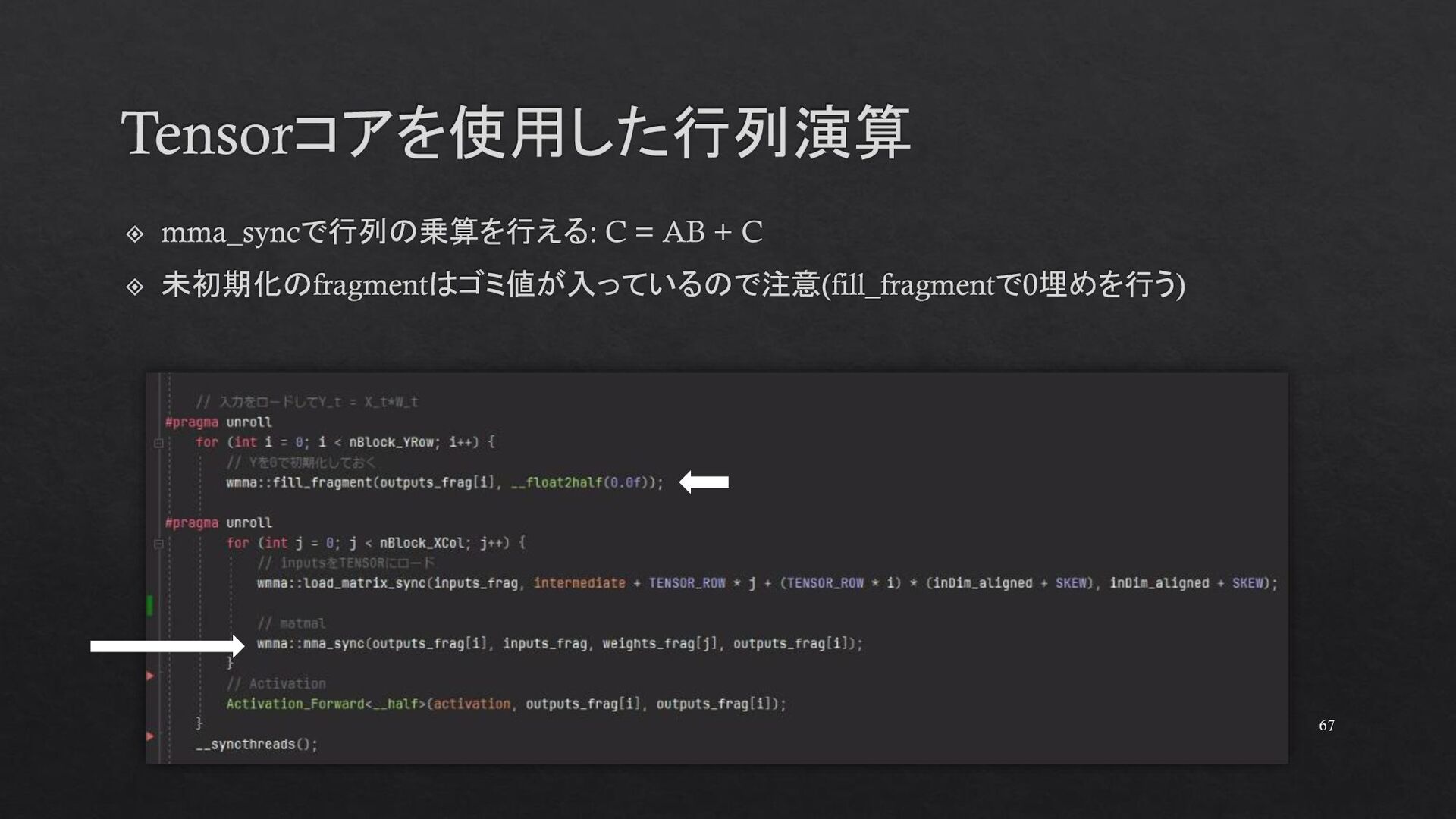
{kind=link}
{kind=link}
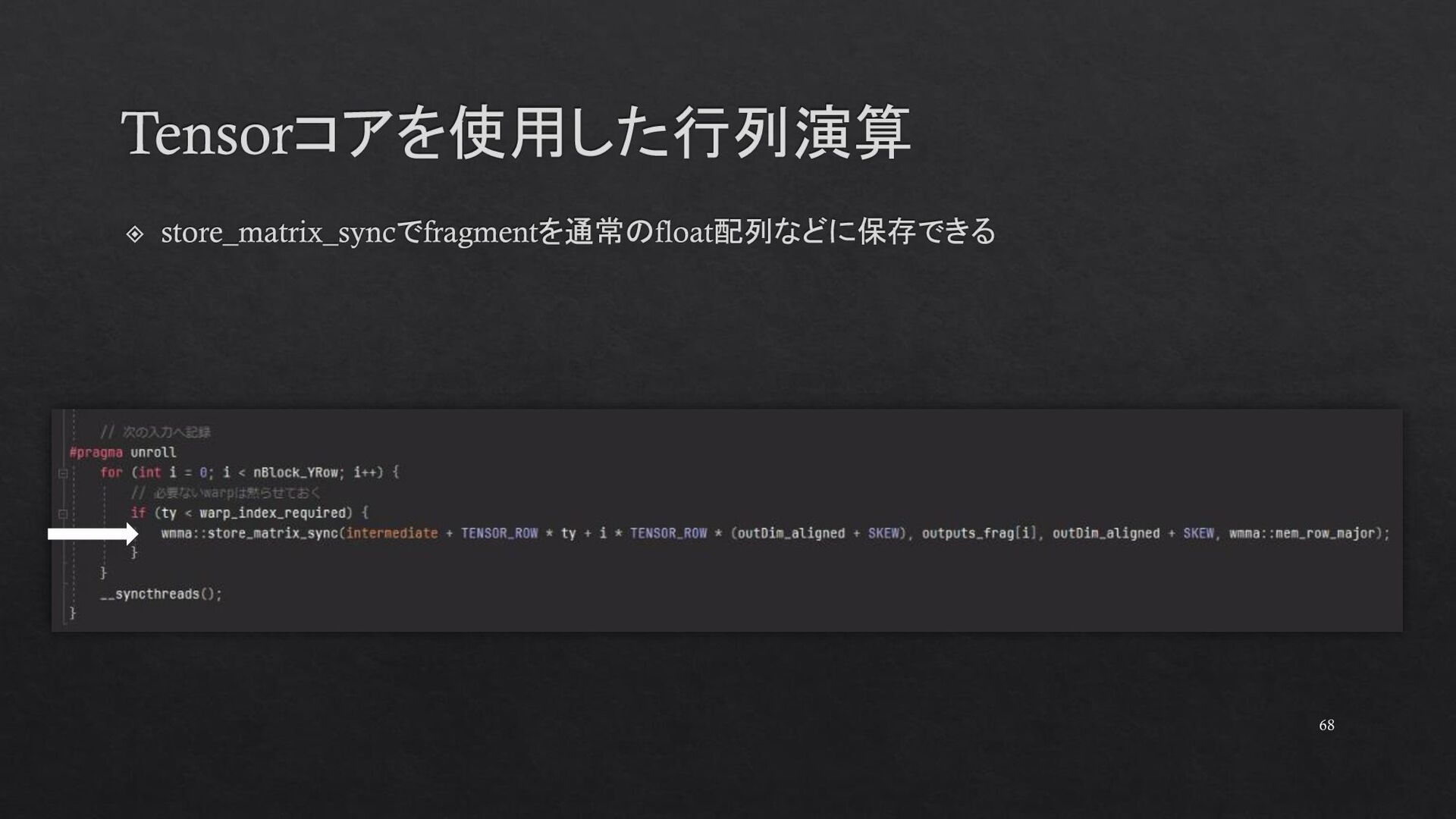{kind=link}
{kind=link}
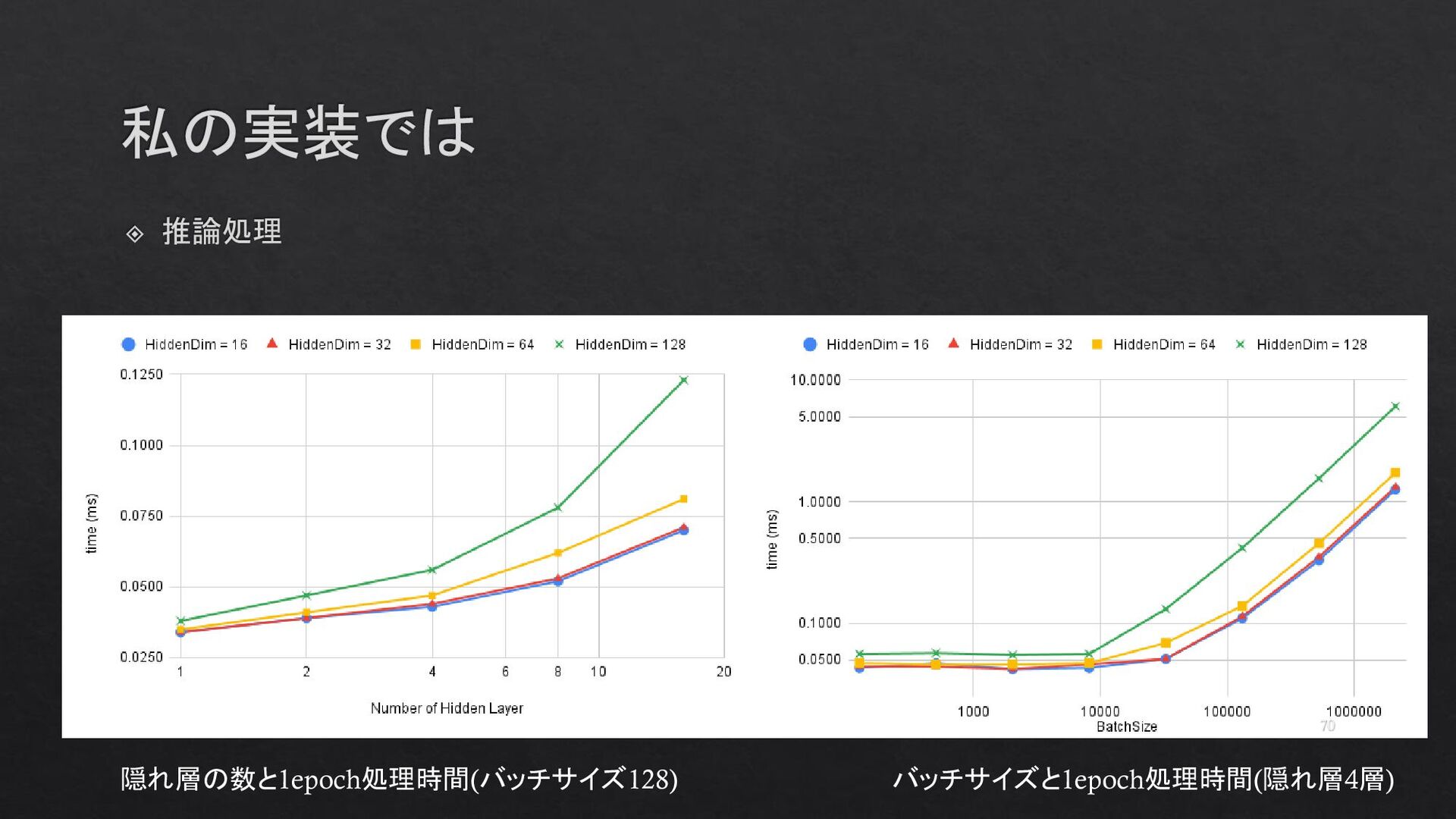{kind=link}
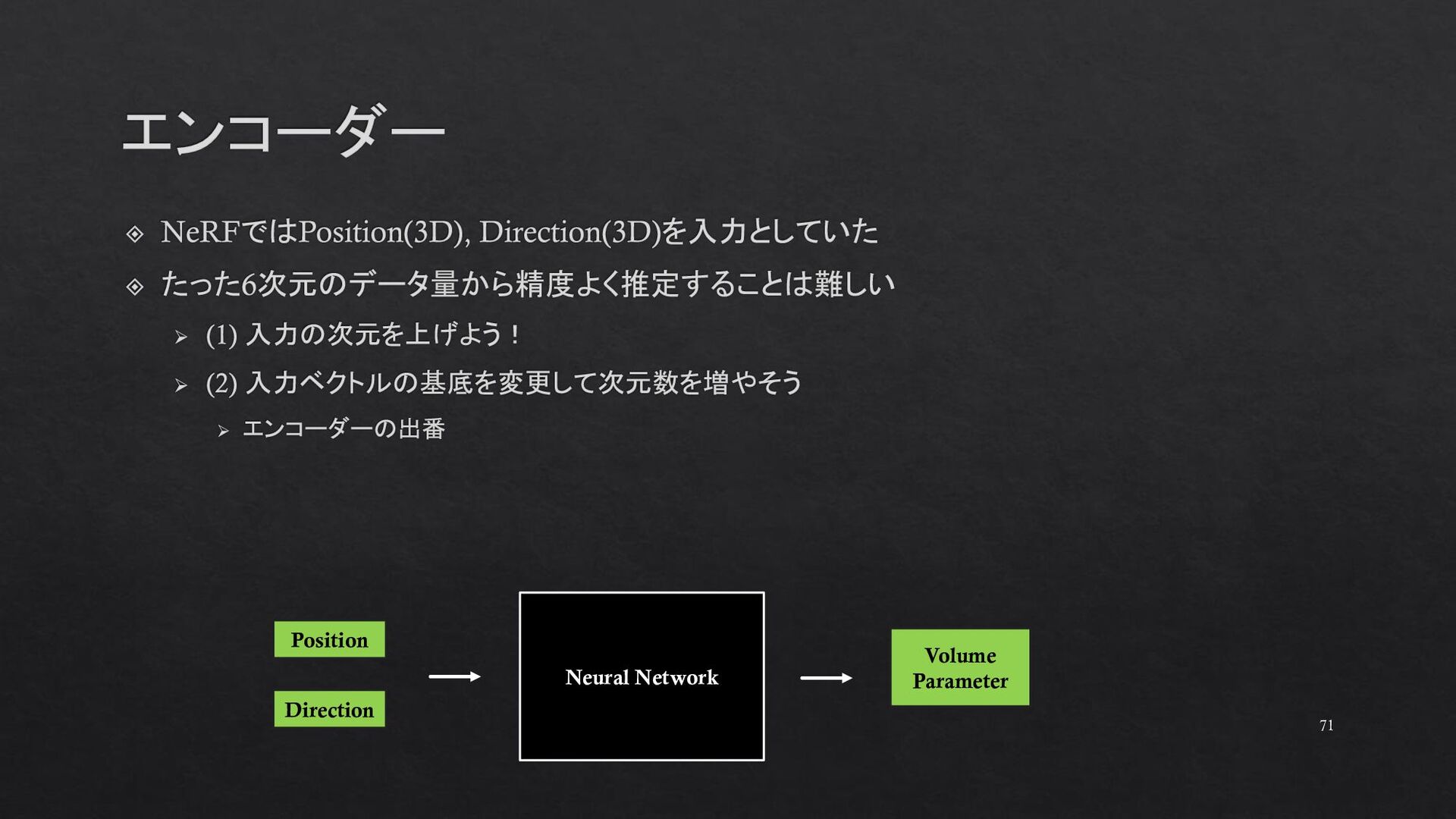{kind=link}
{kind=link}
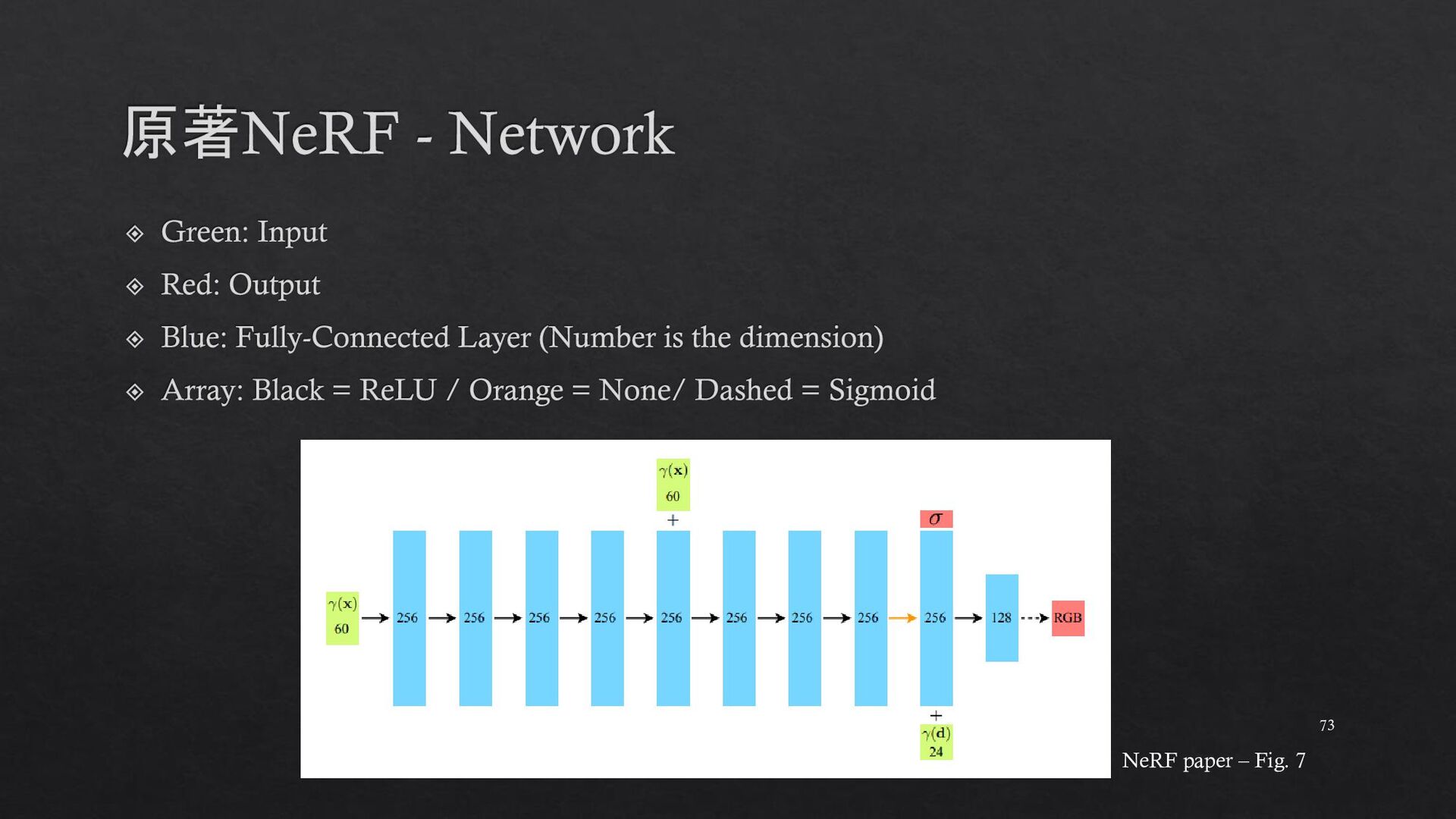{kind=link}
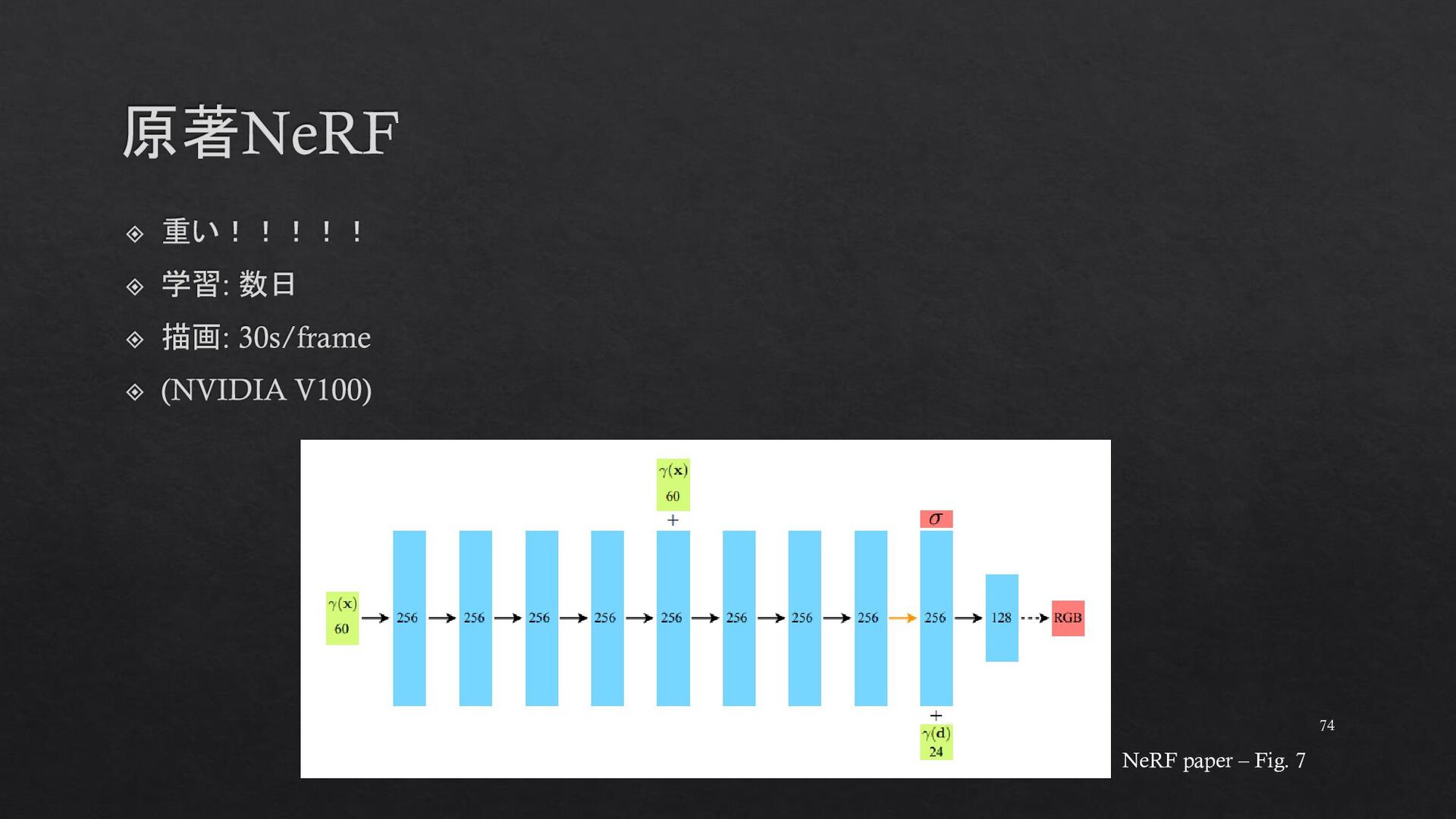{kind=link}
{kind=link}
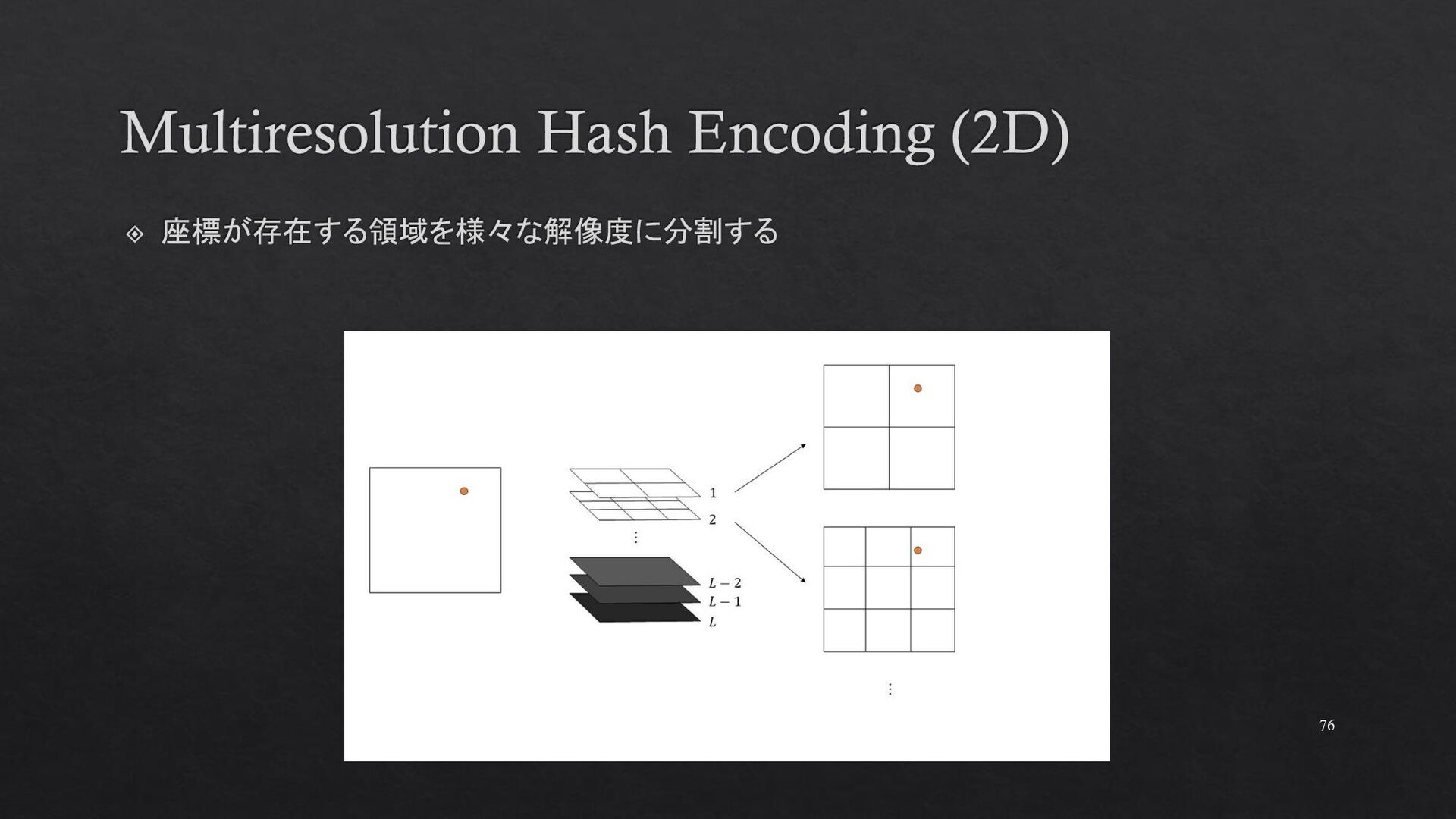{kind=link}
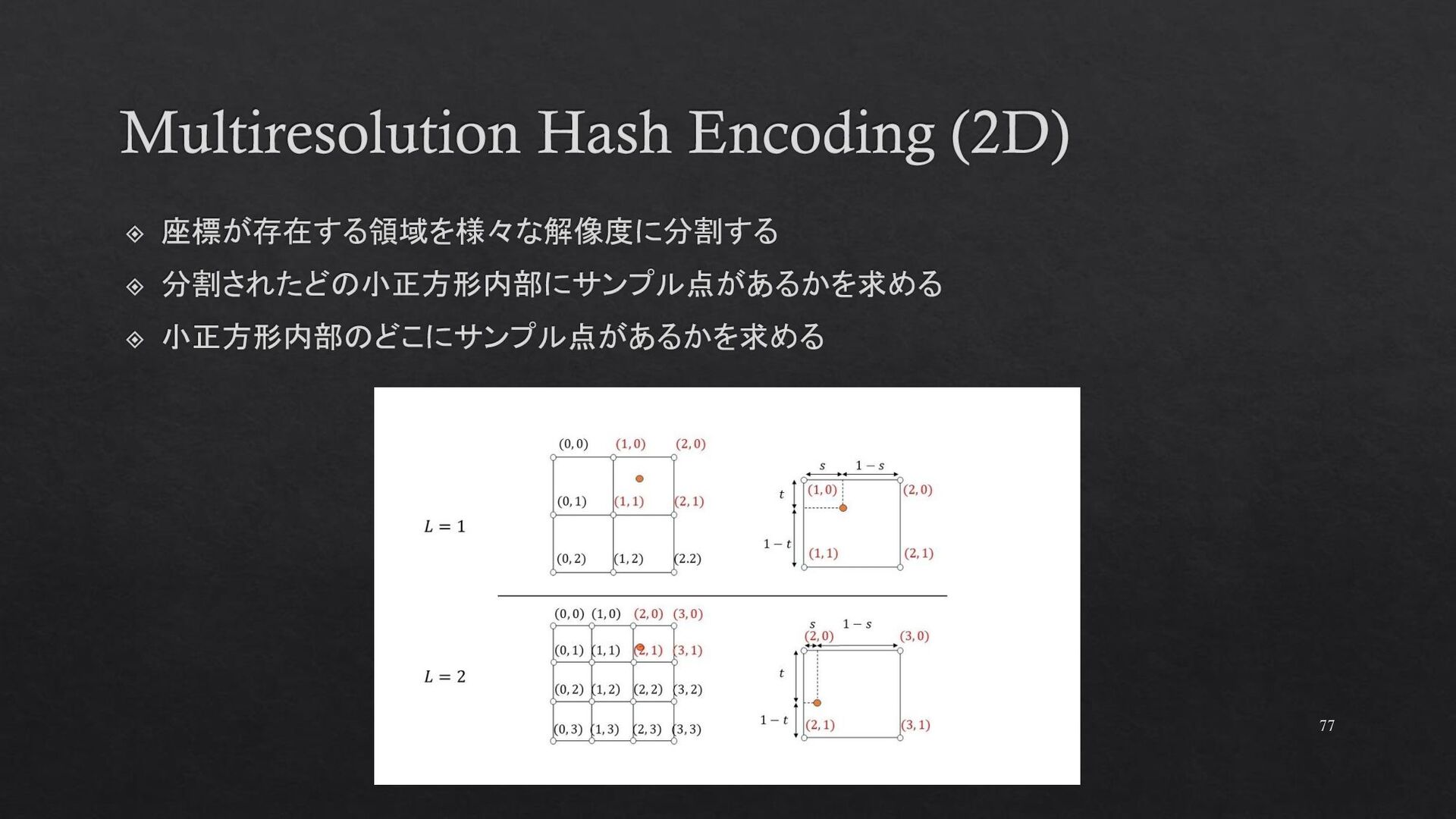{kind=link}
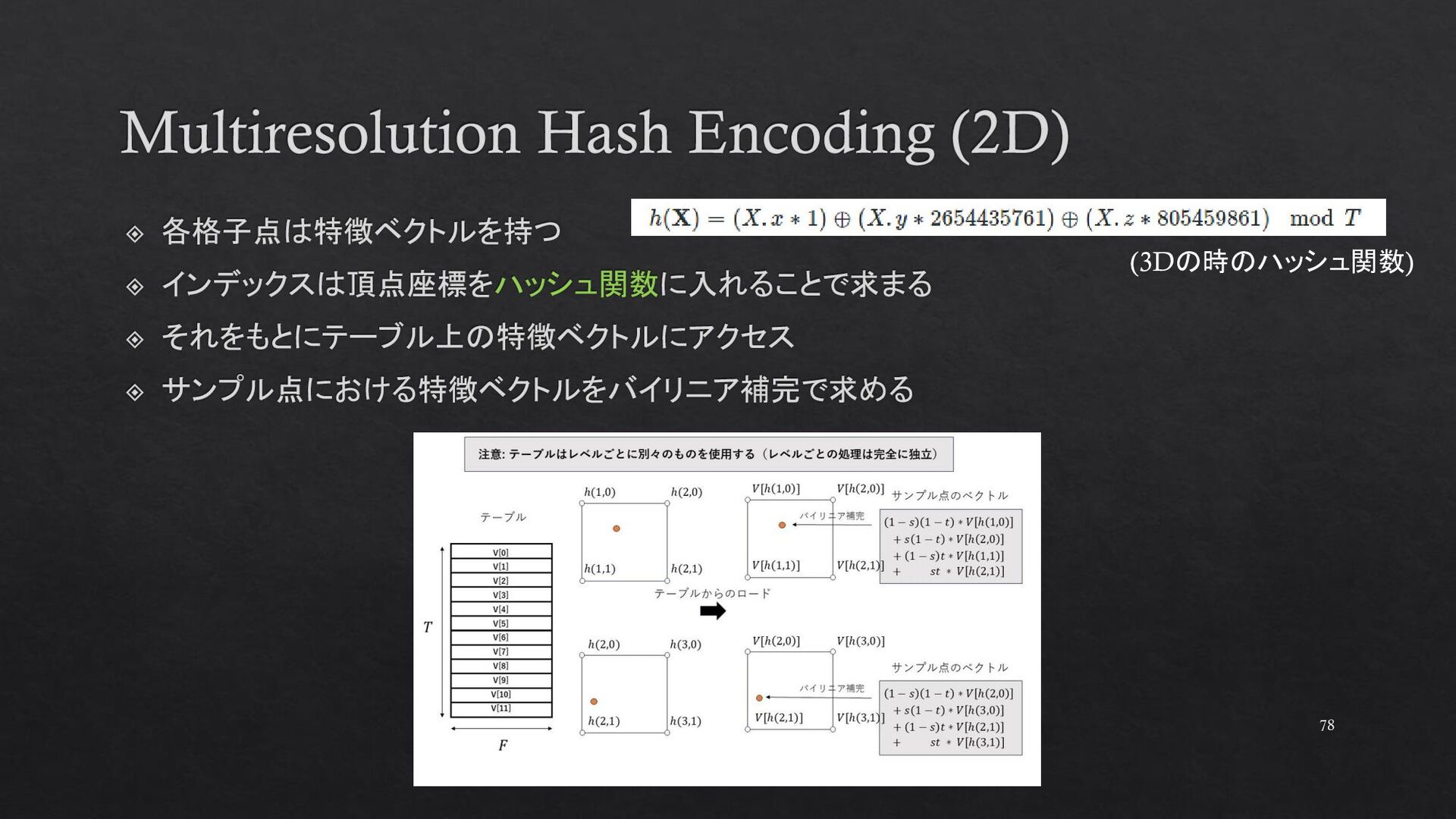{kind=link}
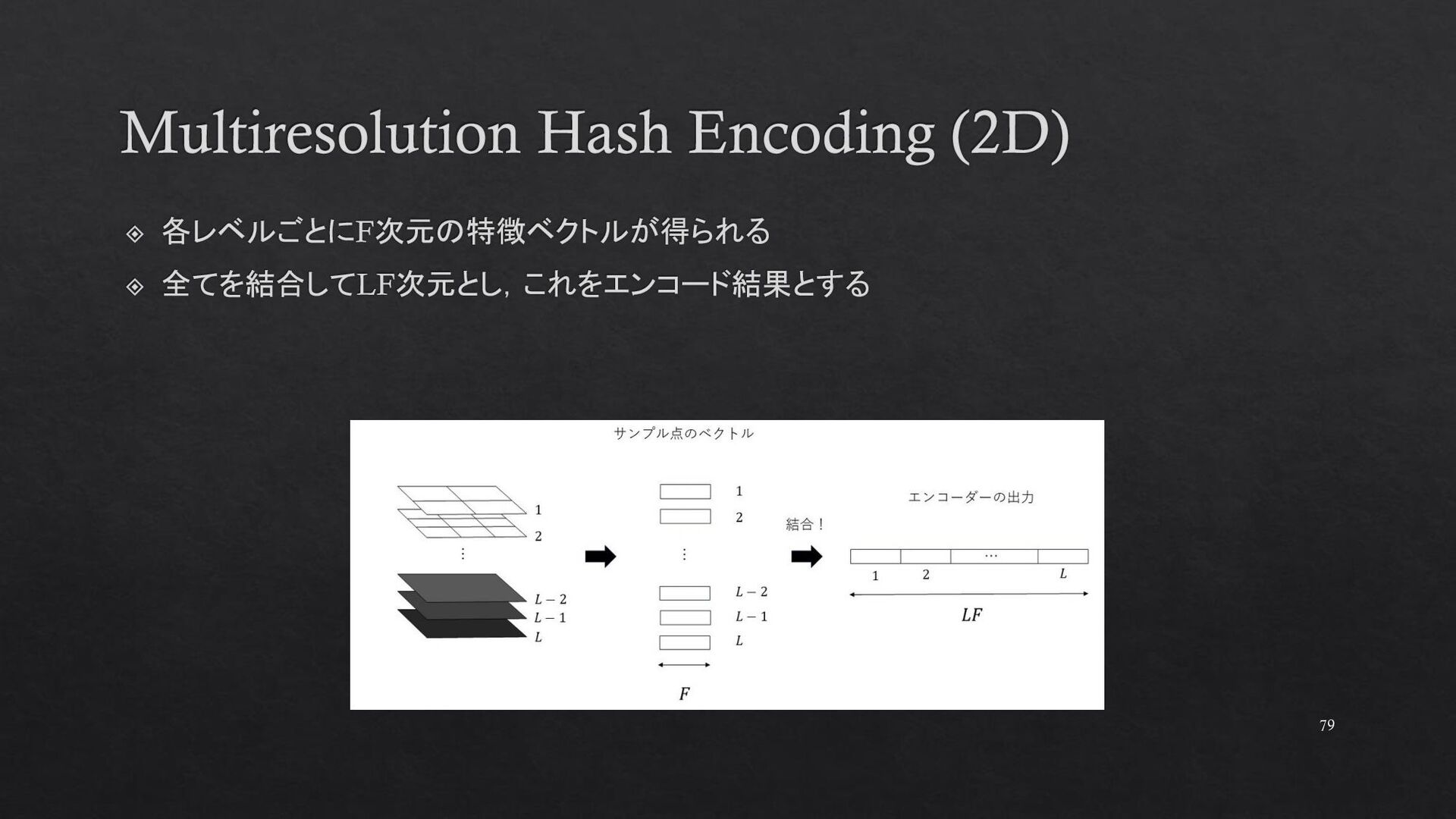{kind=link}
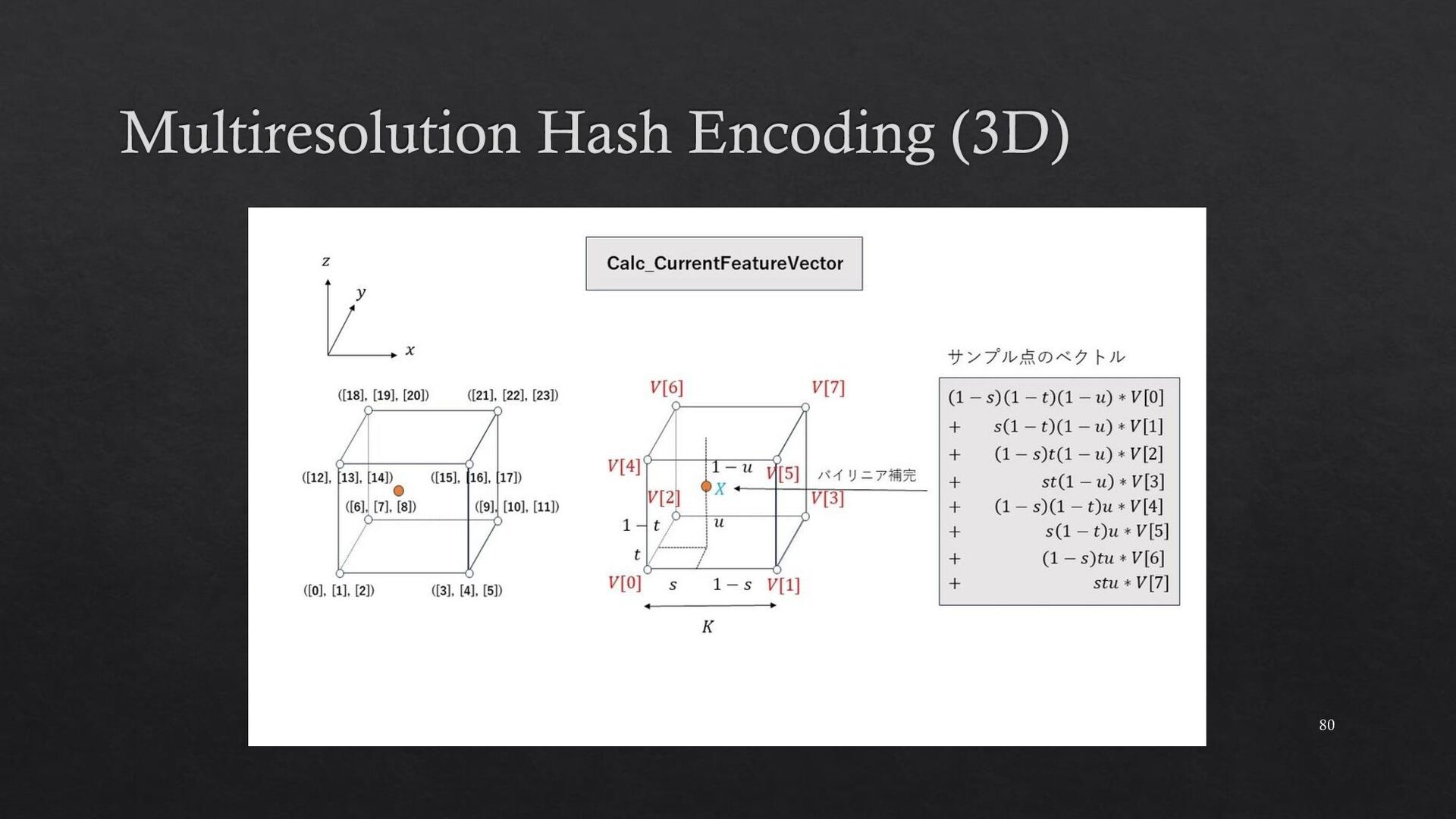{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}