This talk presents a brief case study of long standing problems in Lucene and how they have been approached to gain sizable performance improvements. Each of the presented problems will have brief introduction, implemented solution and resulting performance improvements. This talk might be interesting even for non-lucene folks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
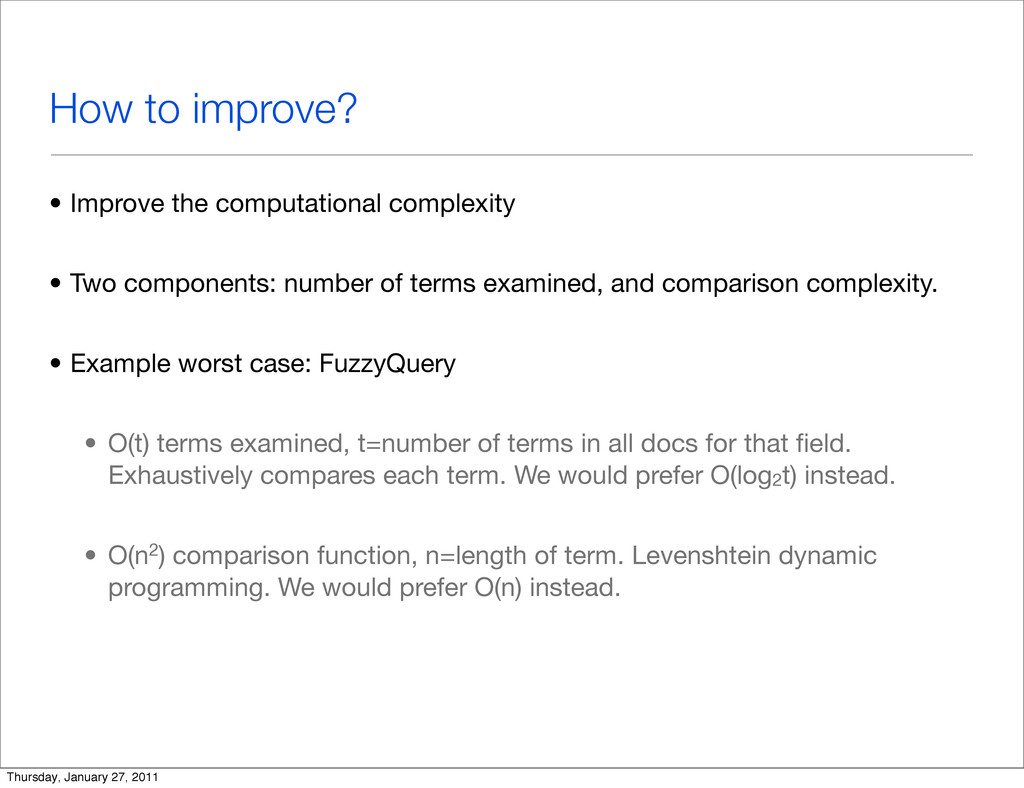{kind=link}
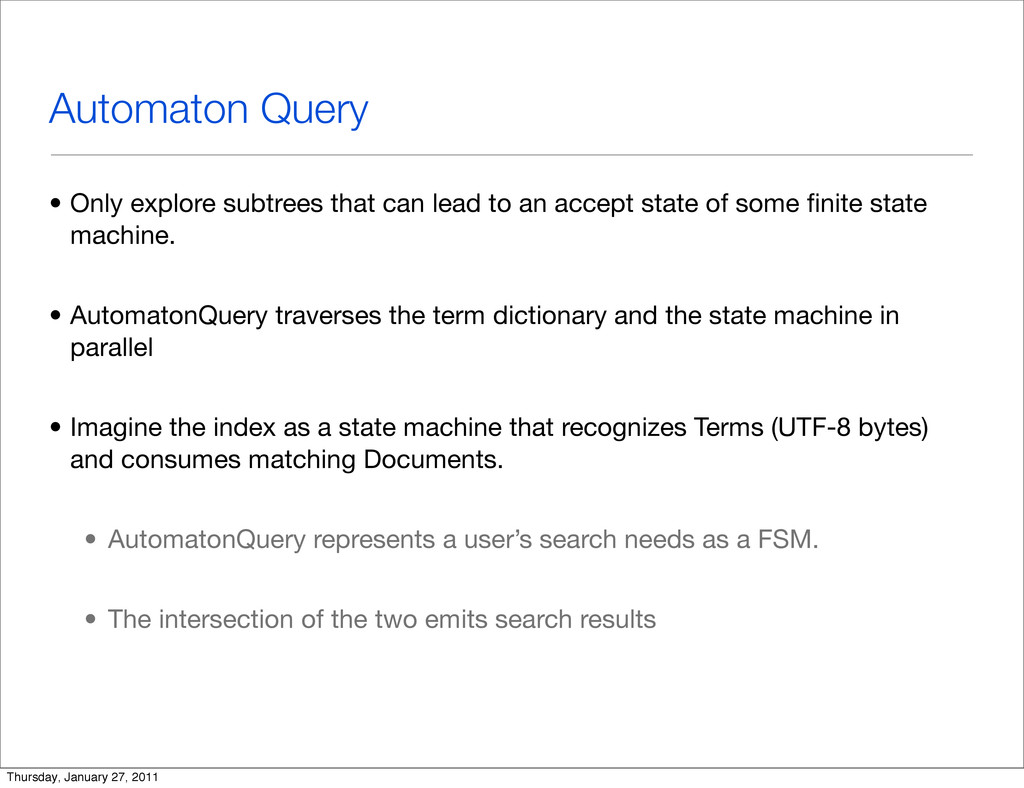{kind=link}
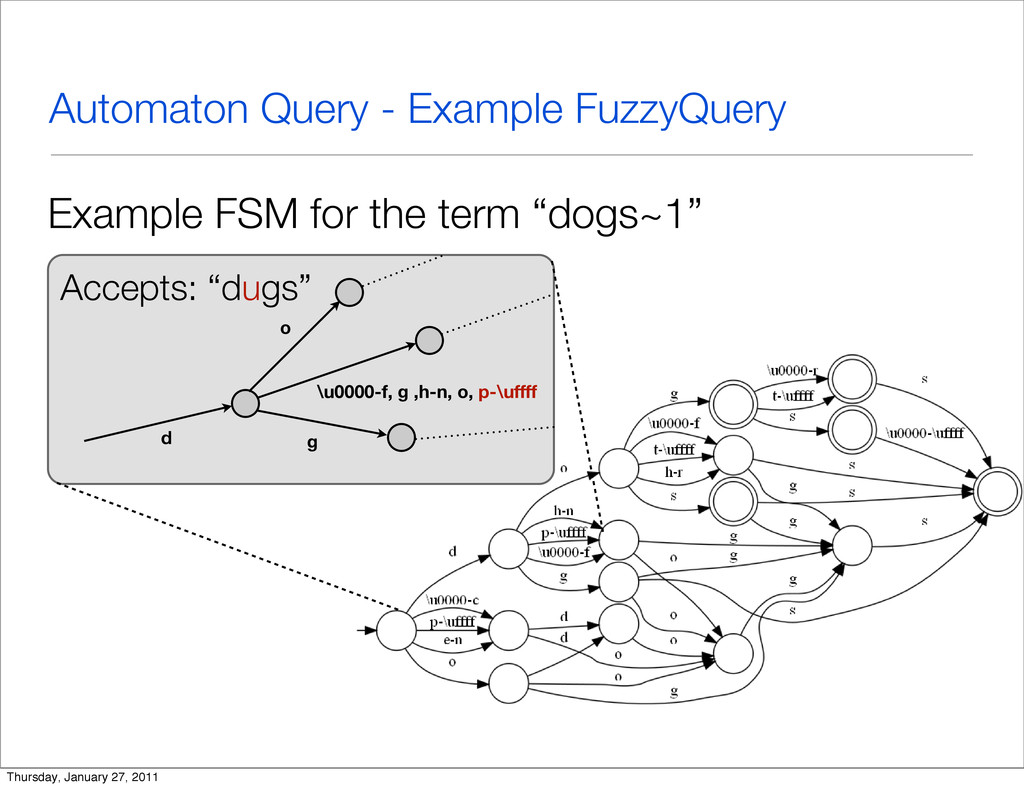{kind=link}
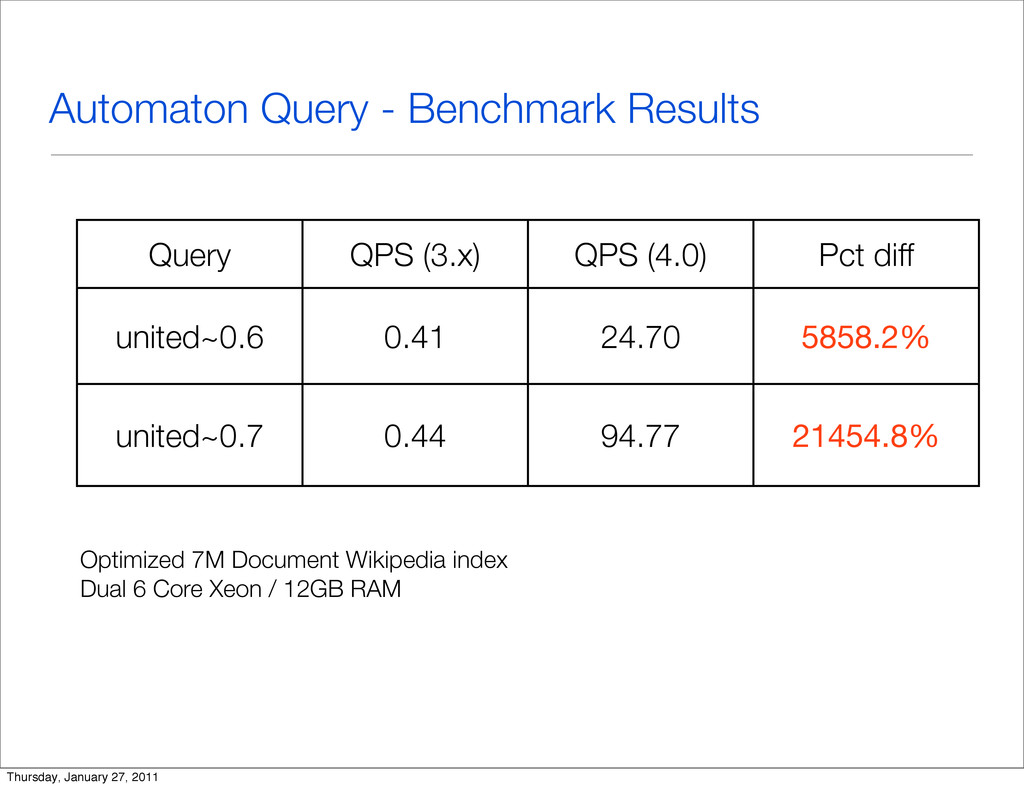{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}