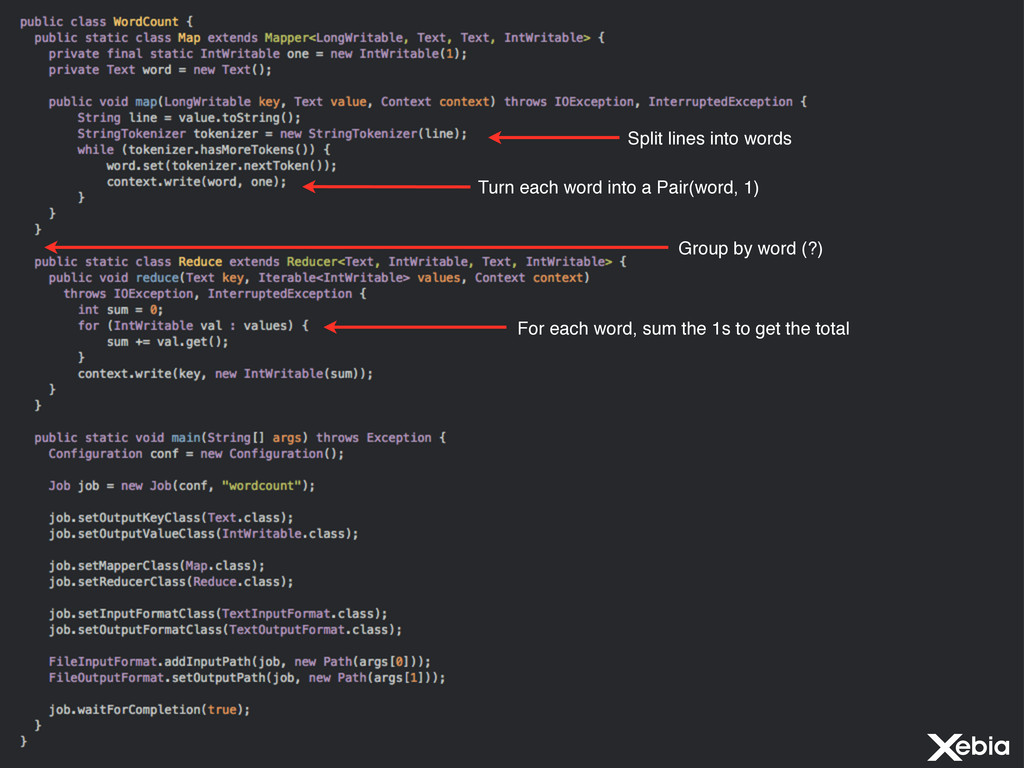
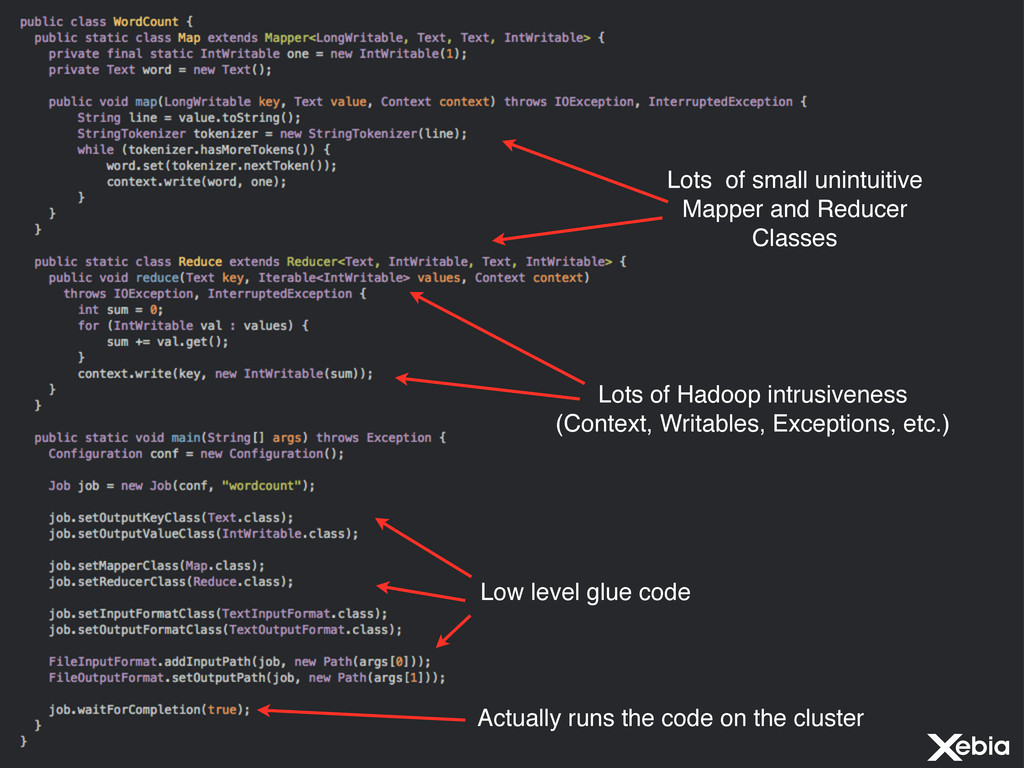
things that are a little bit more complicated than counting words Hard to compose/chain jobs into real programs Unintuitive, invasive programming model Lots of low-level boilerplate code Branching, Joins, CoGroups, etc. hard to implement
class Main { public static void main( String[] args ) { String inputPath = args[0]; String outputPath = args[1]; Scheme inputScheme = new TextLine(new Fields("offset", "line")); Scheme outputScheme = new TextLine(); Tap sourceTap = inputPath.matches( "^[^:]+://.*") ? new Hfs(inputScheme, inputPath) : new Lfs(inputScheme, inputPath); Tap sinkTap = outputPath.matches("^[^:]+://.*") ? new Hfs(outputScheme, outputPath) : new Lfs(outputScheme, outputPath); Pipe wcPipe = new Each("wordcount", new Fields("line"), new RegexSplitGenerator(new Fields("word"), "\\s+"), new Fields("word")); wcPipe = new GroupBy(wcPipe, new Fields("word")); wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word")); Properties properties = new Properties(); FlowConnector.setApplicationJarClass(properties, Main.class); Flow parsedLogFlow = new FlowConnector(properties) .connect(sourceTap, sinkTap, wcPipe); parsedLogFlow.start(); parsedLogFlow.complete(); } } Counting Words using Apache Cascading Pipes & Filters Not very intuitive Lots of boilerplate code Very powerful Record Model
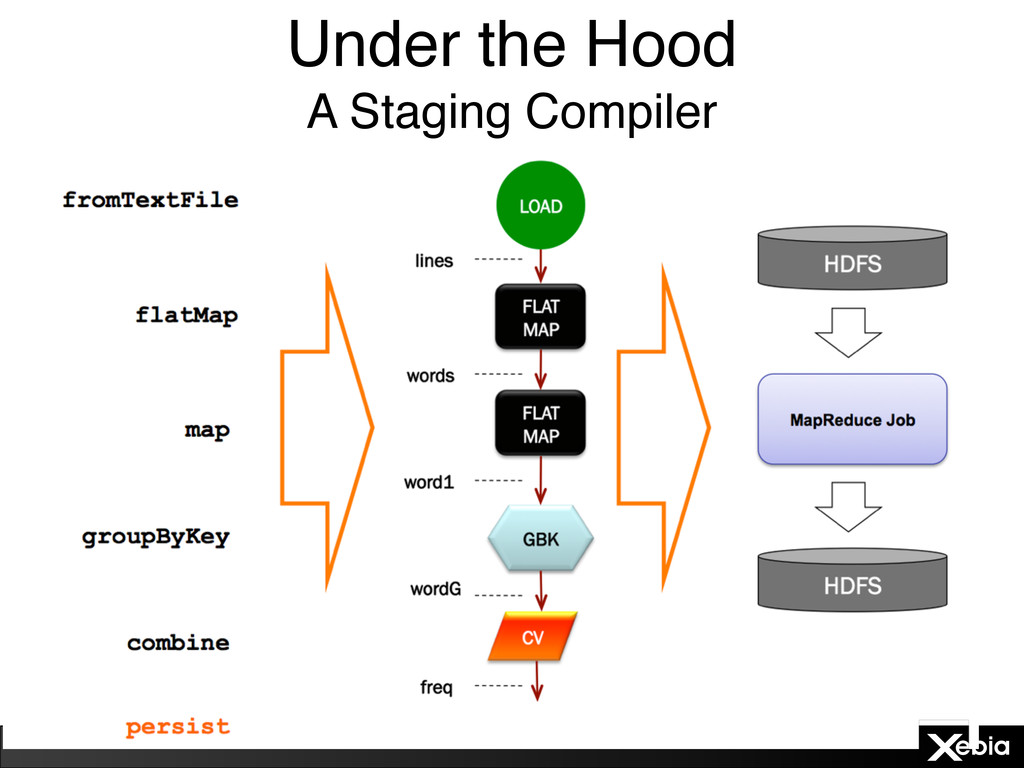
objects abstract data in HDFS • Methods on these objects abstract map/reduce operations • Programs manipulate distributed collections objects • Scoobi turns these manipulations into MapReduce jobs • Based on Google’s FlumeJava / Cascades • A source code generator • A staging compiler • A job plan optimizer • Open sourced by NICTA • Written in Scala (W00t!)
• Calling methods on DList objects to transform and manipulate them abstracts the mapper, combiner, sort-and-shuffle, and reducer phases of MapReduce • Persisting a DList triggers compilation of the graph into one or more MR jobs and their execution • Very familiar: like standard Scala Lists • Strongly typed • Parameterized with rich types and Tuples • Easy list manipulation using typical higher order functions like map, flatMap, filter, etc.
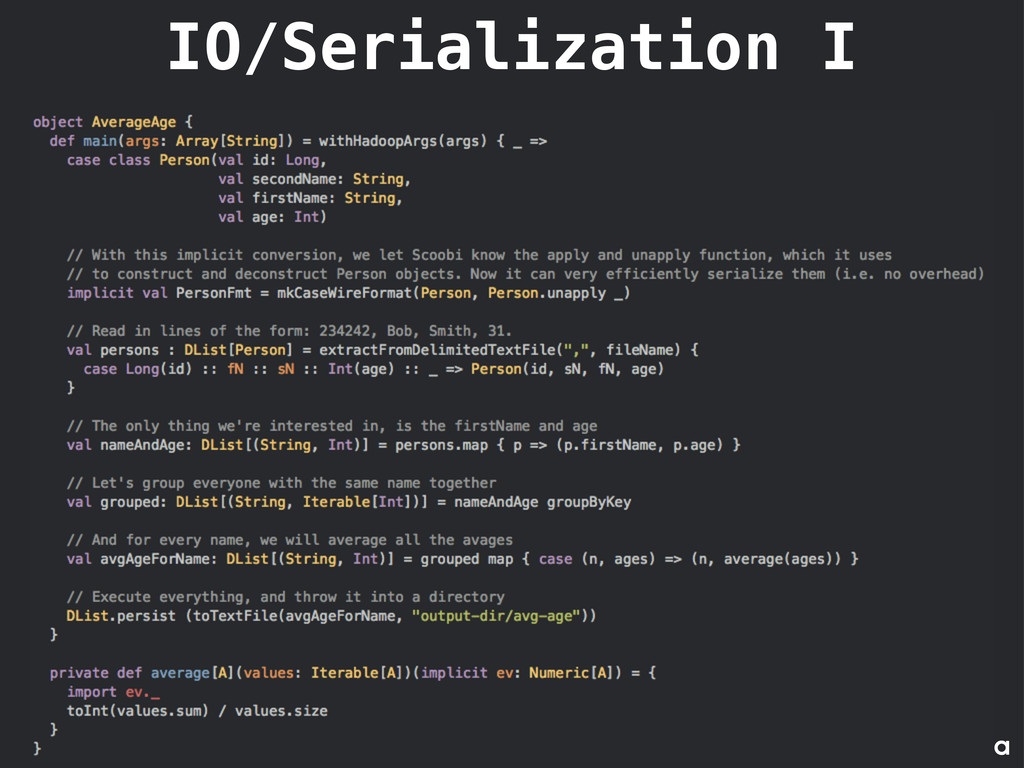
• Can influence sorting (raw, secondary) IO Serialization • Serialization of custom types through Scala type classes and WireFormat[T] • Scoobi implements WireFormat[T] for primitive types, strings, tuples, Option[T], either[T], Iterable[T] • Out of the box support for serialization of Scala case classes
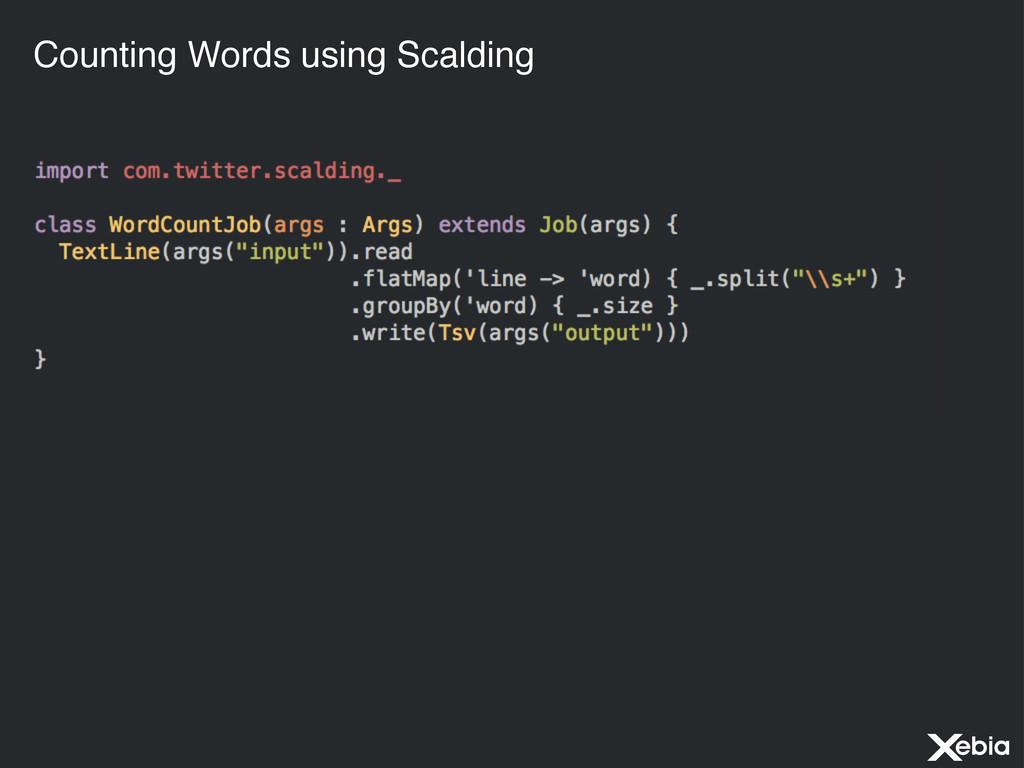
around Cascading (i.e. no source code generation) • Based on the same record model (i.e. named fields) • Less strongly typed • Uses Kryo Serialization • Used by Twitter in production • Written in Scala (W00t!)
differences, which will even out over time Scoobi gets a little closer to idiomatic Scala Twitter is definitely a bigger fish than NICTA, so Scalding gets all the attention Both open sourced (last year)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DList[T] • Abstracts storage of data and files on HDFS](https://files.speakerdeck.com/presentations/4f70bd19ca692c001f00366a/slide_19.jpg){kind=link}
![DList[T]](https://files.speakerdeck.com/presentations/4f70bd19ca692c001f00366a/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Further Info http://github.com/nicta/scoobi [email protected] [email protected] (The README is very good)](https://files.speakerdeck.com/presentations/4f70bd19ca692c001f00366a/slide_31.jpg){kind=link}
{kind=link}
{kind=link}