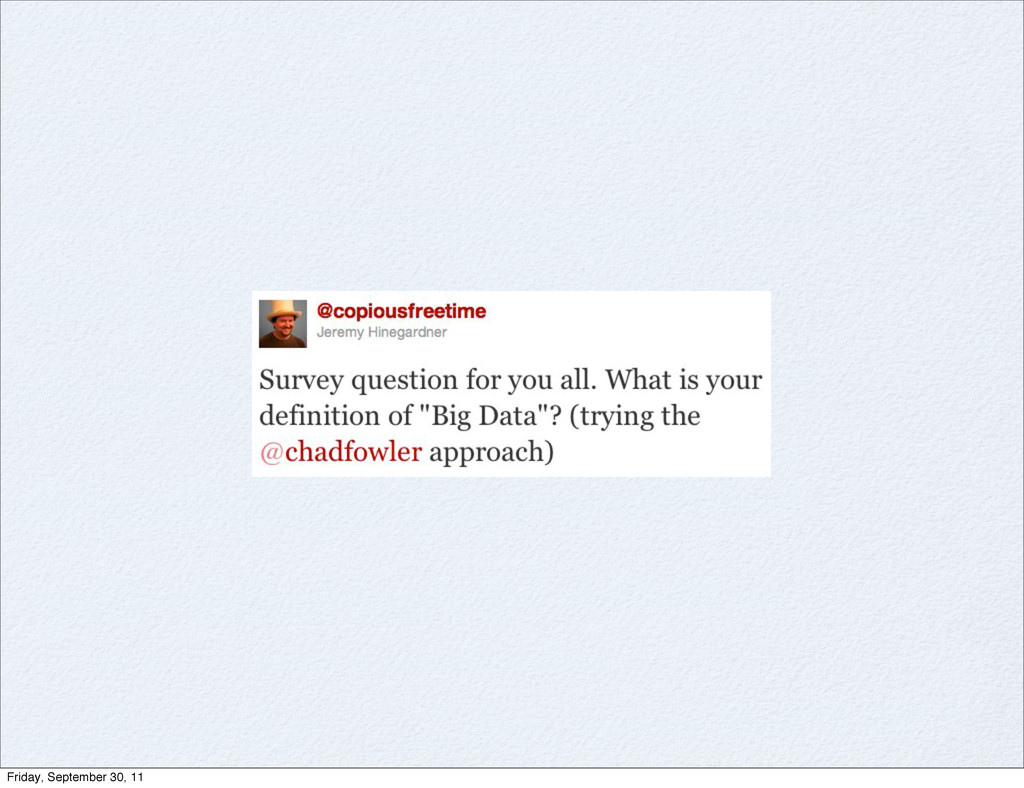
This is an overview talk discussion the basics of what people think the term "Big Data" is, and when you have a Big Data problem, some of the tools from the Hadoop ecosystem that may help you out.
sets whose size is beyond the ability of commonly used software tools to capture, manage, and process the data within a tolerable elapsed time.” -- Wikipedia (Big_Data) Friday, September 30, 11
day, to run Yeah, we need do that over. Its wrong And we’ll need to run that every day, “You need the number of WHAT by tomorrow?!? &#@!” Unofficially... Friday, September 30, 11
day, to run Yeah, we need do that over. Its wrong And we’ll need to run that every day, and it needs to be done by 8 a.m. “You need the number of WHAT by tomorrow?!? &#@!” Unofficially... Friday, September 30, 11
day, to run Yeah, we need do that over. Its wrong And we’ll need to run that every day, and it needs to be done by 8 a.m. On the previous day’s data. “You need the number of WHAT by tomorrow?!? &#@!” Unofficially... Friday, September 30, 11
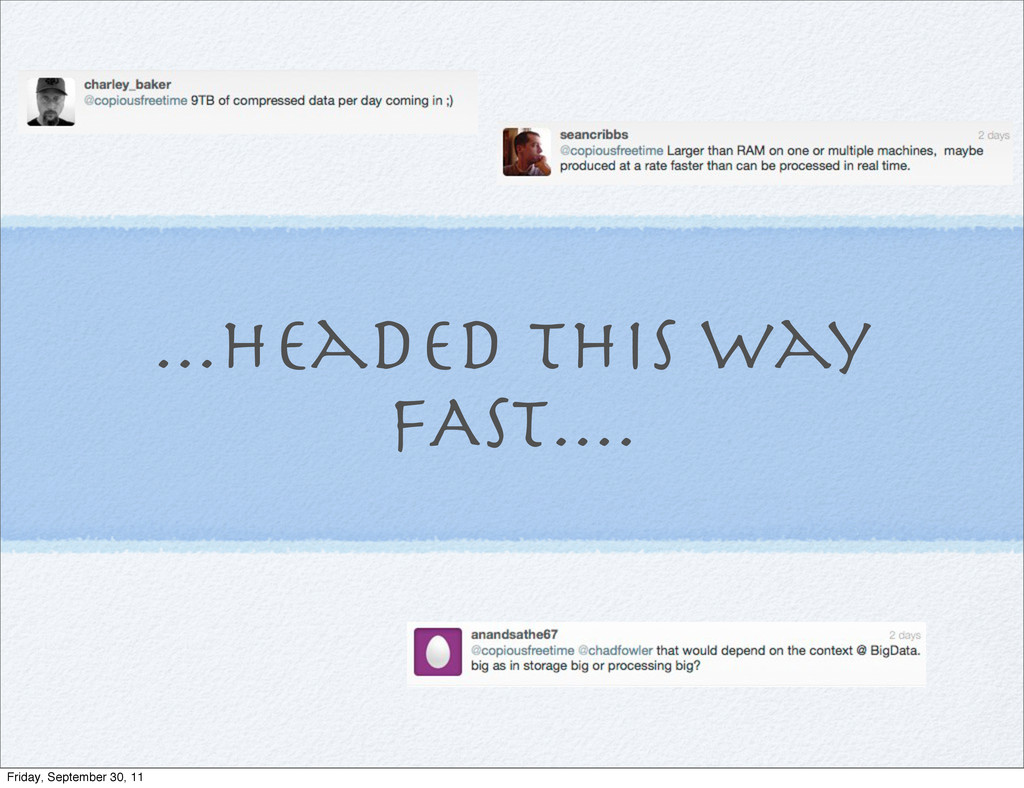
/ hour 4,484,953 bytes / second 4.2 Megabytes / second or http://blog.gnip.com/handling-high-volume-realtime- big-social-data/ Friday, September 30, 11
/ hour 4,484,953 bytes / second 4.2 Megabytes / second or 33.8 Megabits / second http://blog.gnip.com/handling-high-volume-realtime- big-social-data/ Friday, September 30, 11
/ hour 4,484,953 bytes / second 4.2 Megabytes / second or 33.8 Megabits / second or http://blog.gnip.com/handling-high-volume-realtime- big-social-data/ Friday, September 30, 11
/ hour 4,484,953 bytes / second 4.2 Megabytes / second or 33.8 Megabits / second or Majority of an OC-1 SONET line http://blog.gnip.com/handling-high-volume-realtime- big-social-data/ Friday, September 30, 11
Things do you NEED to look at to make an analysis about the Population. http://www.custominsight.com/articles/random- sample-calculator.asp Friday, September 30, 11
Things do you NEED to look at to make an analysis about the Population. http://www.custominsight.com/articles/random- sample-calculator.asp 1% error tolerance 99% confidence Friday, September 30, 11
Things do you NEED to look at to make an analysis about the Population. http://www.custominsight.com/articles/random- sample-calculator.asp 1% error tolerance 99% confidence 16,588 Friday, September 30, 11
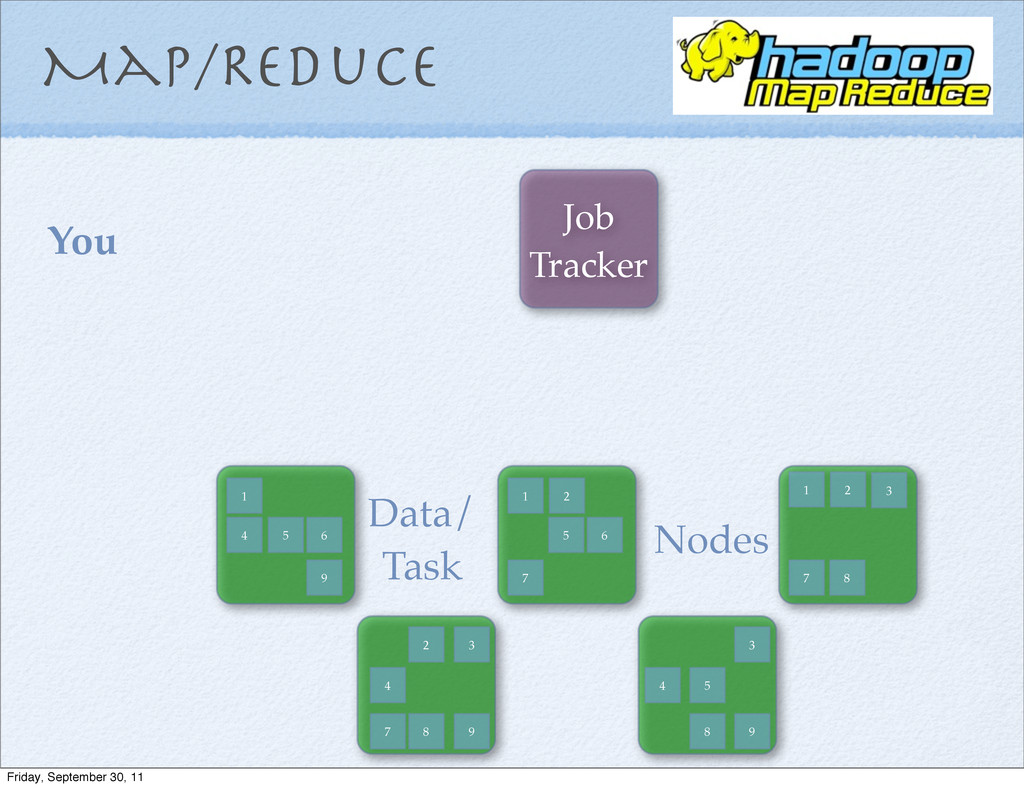
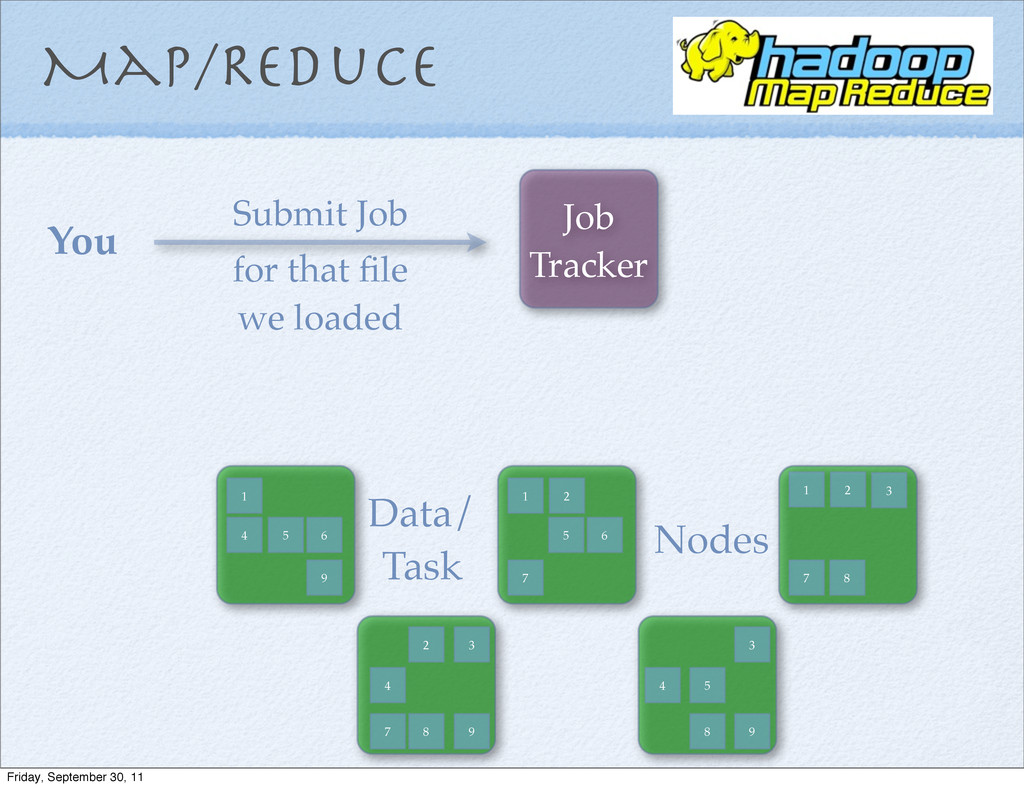
MapInput.each do |x,y| a, b = map(x, y) MapResult << [ a, b ] end ReduceInput = MapResult.group_by { |mr| m[0] } Final =ReduceInput.collect { |g, list|reduce(g,list) } Map/Reduce Friday, September 30, 11
MapInput.each do |x,y| a, b = map(x, y) MapResult << [ a, b ] end ReduceInput = MapResult.group_by { |mr| m[0] } Final =ReduceInput.collect { |g, list|reduce(g,list) } Map/Reduce Embarrassingly Parallel Problems Friday, September 30, 11
MapInput.each do |x,y| a, b = map(x, y) MapResult << [ a, b ] end ReduceInput = MapResult.group_by { |mr| m[0] } Final =ReduceInput.collect { |g, list|reduce(g,list) } Map/Reduce Embarrassingly Parallel Problems Friday, September 30, 11
MapInput.each do |x,y| a, b = map(x, y) MapResult << [ a, b ] end ReduceInput = MapResult.group_by { |mr| m[0] } Final =ReduceInput.collect { |g, list|reduce(g,list) } Map/Reduce Embarrassingly Parallel Problems Friday, September 30, 11
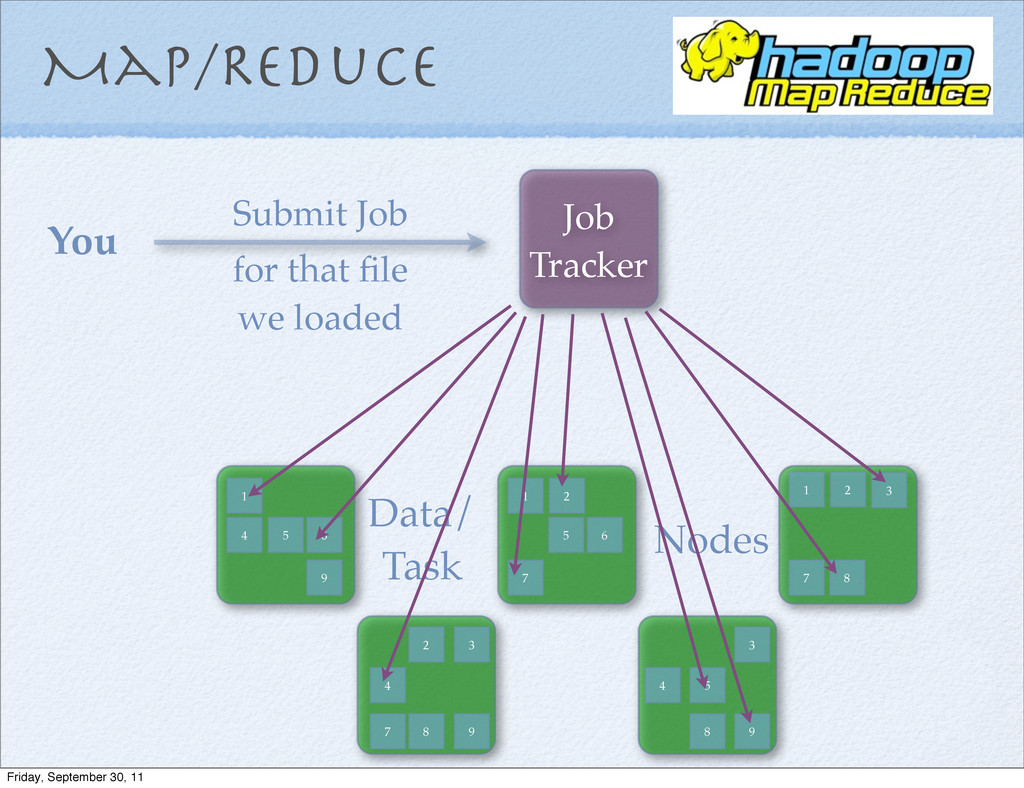
file 2. Submit the jar file to the Job Tracker 3. Job Tracker gives the jar to each Task Tracker 4. Finding the Mapper and Reducer classes is a runtime lookup starting from the Java side. Friday, September 30, 11
file 2. Submit the jar file to the Job Tracker 3. Job Tracker gives the jar to each Task Tracker 4. Finding the Mapper and Reducer classes is a runtime lookup starting from the Java side. packaging Friday, September 30, 11
file 2. Submit the jar file to the Job Tracker 3. Job Tracker gives the jar to each Task Tracker 4. Finding the Mapper and Reducer classes is a runtime lookup starting from the Java side. packaging runtime Friday, September 30, 11
‘joh’ commandline instead of the ‘hadoop’ define map/reduce methods, which end up being supported by Java shims packaging runtim e Friday, September 30, 11
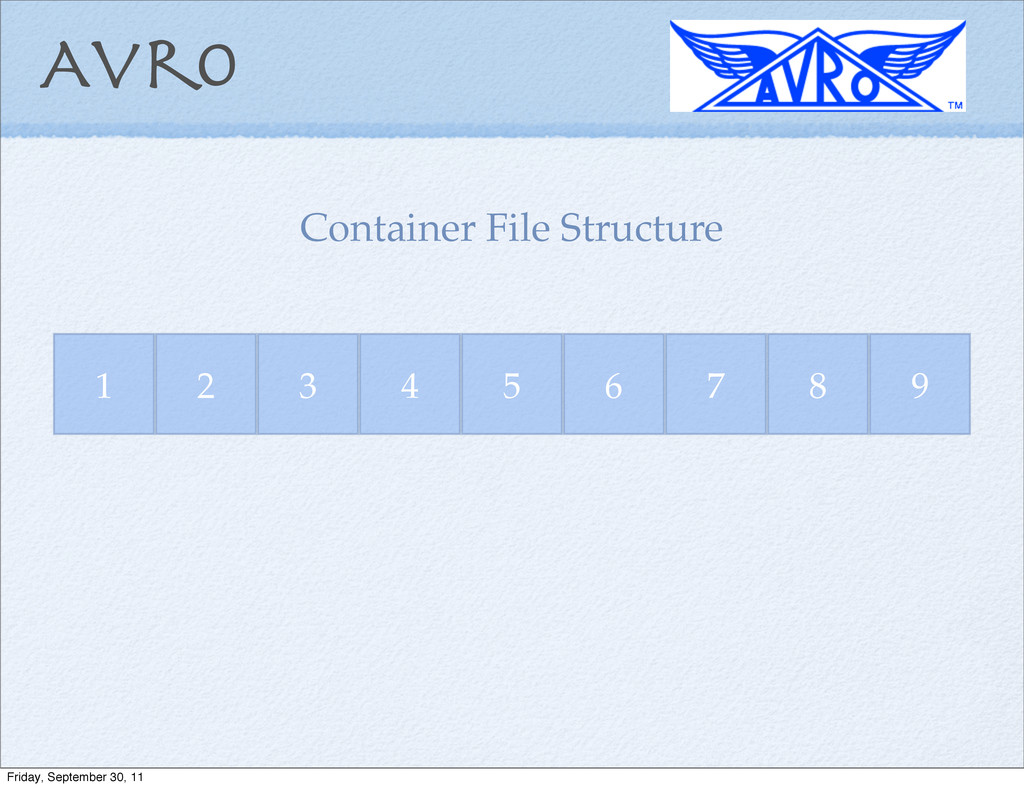
Format Container File Structure RPC/Protocol Buffer/Thrift-like ability No Code Generation Record Structure Defined via JSON Schema Friday, September 30, 11
Format Container File Structure RPC/Protocol Buffer/Thrift-like ability No Code Generation Record Structure Defined via JSON Schema Map/Reduce Friendly Friday, September 30, 11
Format Container File Structure RPC/Protocol Buffer/Thrift-like ability No Code Generation Record Structure Defined via JSON Schema Map/Reduce Friendly Compression Friday, September 30, 11
Format Container File Structure RPC/Protocol Buffer/Thrift-like ability No Code Generation Record Structure Defined via JSON Schema Map/Reduce Friendly Compression Language Neutral Friday, September 30, 11
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MapInput = [ [x0,y0], ... , [ xi, yi ]]](https://files.speakerdeck.com/presentations/4e85e2ce58269d005000964b/slide_50.jpg){kind=link}
![MapInput = [ [x0,y0], ... , [ xi, yi ]]](https://files.speakerdeck.com/presentations/4e85e2ce58269d005000964b/slide_51.jpg){kind=link}
![MapInput = [ [x0,y0], ... , [ xi, yi ]]](https://files.speakerdeck.com/presentations/4e85e2ce58269d005000964b/slide_52.jpg){kind=link}
![MapInput = [ [x0,y0], ... , [ xi, yi ]]](https://files.speakerdeck.com/presentations/4e85e2ce58269d005000964b/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
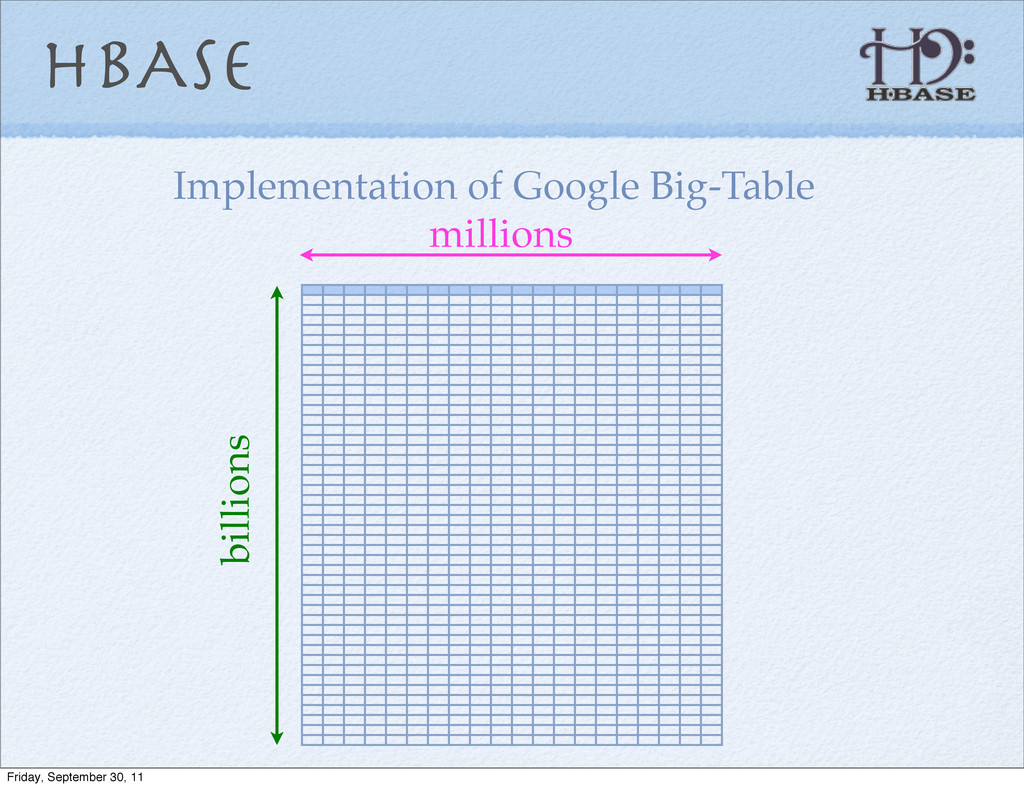{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}