Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NLTK Intro for PUGS
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Victor Neo
March 27, 2012
Programming
600
7
Share
NLTK Intro for PUGS
Slides for the NLTK talk given on March 2012 for Python User Group SG Meetup.
Victor Neo
March 27, 2012
More Decks by Victor Neo
See All by Victor Neo
Django - The Next Steps
victorneo
5
690
DevOps: Python tools to get started
victorneo
9
13k
Git and Python workshop
victorneo
2
810
Other Decks in Programming
See All in Programming
「AIで開発し、AIを届ける」をEvalでつなぐ 〜AIネイティブに始めるプロダクト開発の実践〜 / Connecting "Develop with AI, deliver AI" with Eval
rkaga
2
600
RTSPクライアントを自作してみた話
simotin13
0
420
柔軟なPDFレイアウトエディタを支える型システム設計 — Discriminated UnionとConditional Typeの実践
minako__ph
4
1.3k
Oxlintのカスタムルールの現況
syumai
5
950
セキュリティの専門家じゃなくてもできる。「セキュリティ意識」をアップデートして サプライチェーン攻撃への耐性を高めよう。
tk3fftk
3
210
サーバーレスで作る、動画データ管理基盤
oyasumipants
0
340
脅威をエンジニアリングの糧にして――現場編 / Turning Threats into Engineering Fuel — Field Edition
nrslib
0
230
初めてのRubyKaigiはこう見えた
jellyfish700
0
400
AI駆動開発勉強会 広島支部 第一回勉強会 AI駆動開発概要とワークショップ
hayatoshimiu
0
430
AIチームを指揮するOSS「TAKT」活用術 / How to Use “TAKT,” an OSS Tool for Orchestrating AI Teams
nrslib
6
770
次世代リンターで探る、tsgo 時代における型認識カスタムルールの現実解
ytakahashii
3
1.4k
Transactional Change Stream Processing With Debezium and Apache Flink
gunnarmorling
1
150
Featured
See All Featured
Code Reviewing Like a Champion
maltzj
528
40k
AI: The stuff that nobody shows you
jnunemaker
PRO
7
670
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
55k
The Curious Case for Waylosing
cassininazir
1
370
Deep Space Network (abreviated)
tonyrice
0
160
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
370
Embracing the Ebb and Flow
colly
88
5.1k
Faster Mobile Websites
deanohume
310
31k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
Become a Pro
speakerdeck
PRO
31
6k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Transcript
Natural Language Toolkit @victorneo
Natural Language Processing
"the process of a computer extracting meaningful information from natural
language input and/or producing natural language output"
None
Getting started with NLTK
Open source Python modules, linguistic data and documentation for research
and development in natural language processing and text analytics, with distributions for Windows, Mac OSX and Linux. NLTK
None
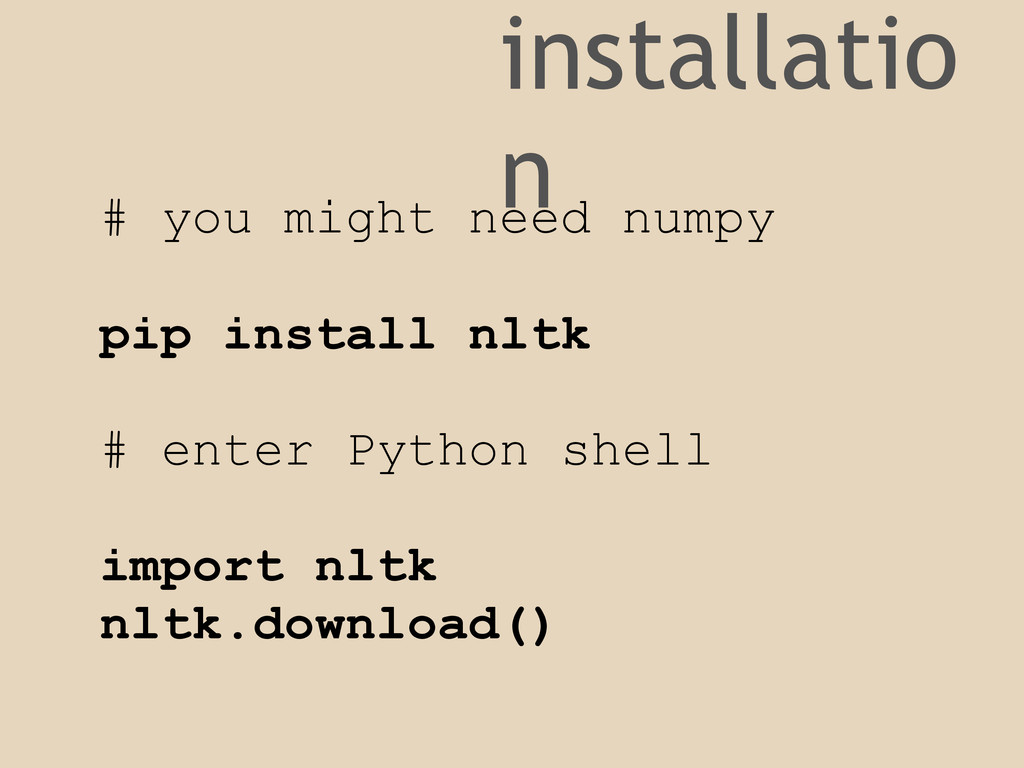
installatio n # you might need numpy pip install nltk
# enter Python shell import nltk nltk.download()
None
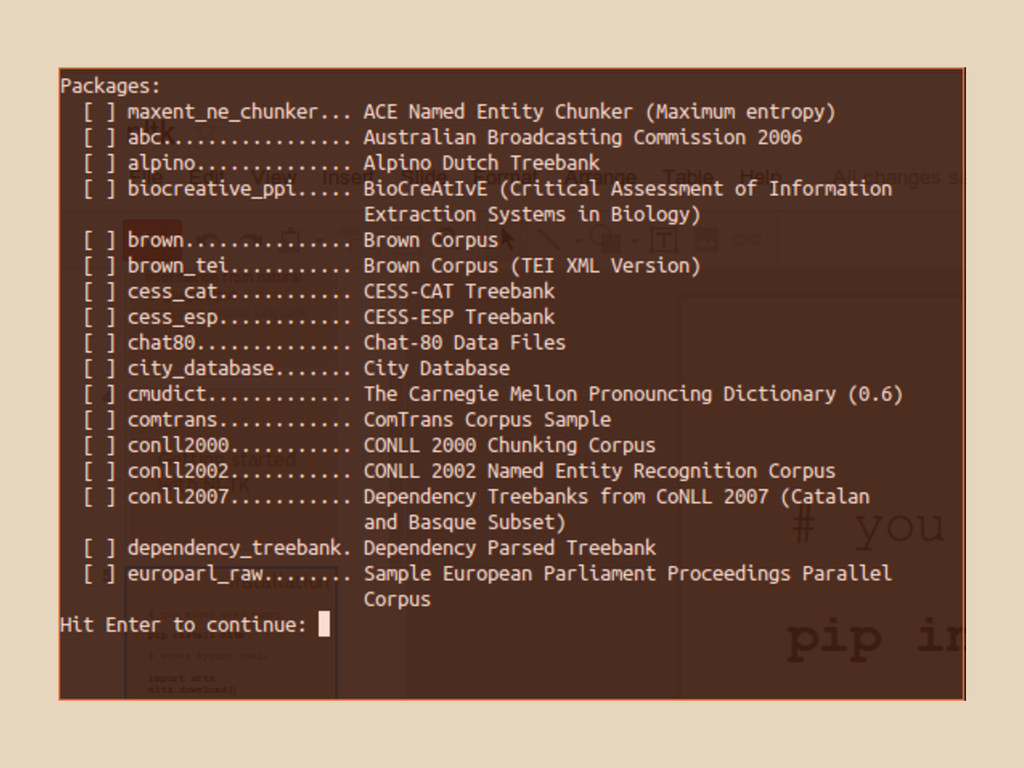
packages # For Part of Speech tagging maxent_treebank_pos_tagger # Get
a list of stopwords stopwords # Brown corpus to play around brown
Preparing data / corpus
tokens NLTK works on Tokens, for example, "Hello World!" will
be tokenized to: ['Hello', 'World', '!'] The built-in tokenizer for most use cases: nltk.word_tokenize("Hello World!")
text processing HTML text: raw = nltk.clean_html(html_text) tokens = nltk.word_tokenize(raw)
text = nltk.Text(tokens) Use BeautifulSoup for preprocessing of the HTML text to discard unnecessary data.
Part-of-speech tagging
pos tagging text = "Run away!" nltk.word_tokenize(text) nltk.pos_tag(tokens) [('Run', 'NNP'),
('away', 'RB'), ('!', '.')]
pos tagging [('Run', 'NNP'), ('away', 'RB'), ('!', '.')] NNP: Proper
Noun, Singular RB : Adverb http://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos. html
pos tagging "The sailor dogs the barmaid." [('The', 'DT'), ('sailor',
'NN'), ('dogs', 'NNS'), ('the', 'DT'), ('barmaid', 'NN'), ('.', '.')]
Sentiment Analysis Code: http://bit.ly/GLu2Q9
Differentiate between "happy" and "sad" tweets. Teach the classifier the
"features" of happy & sad tweets and test how good it is.
Happy: "Looking through old pics and realizing everything happens for
a reason. So happy with where I am right now" Sad: "So sad I have 8 AM class tomorrow"
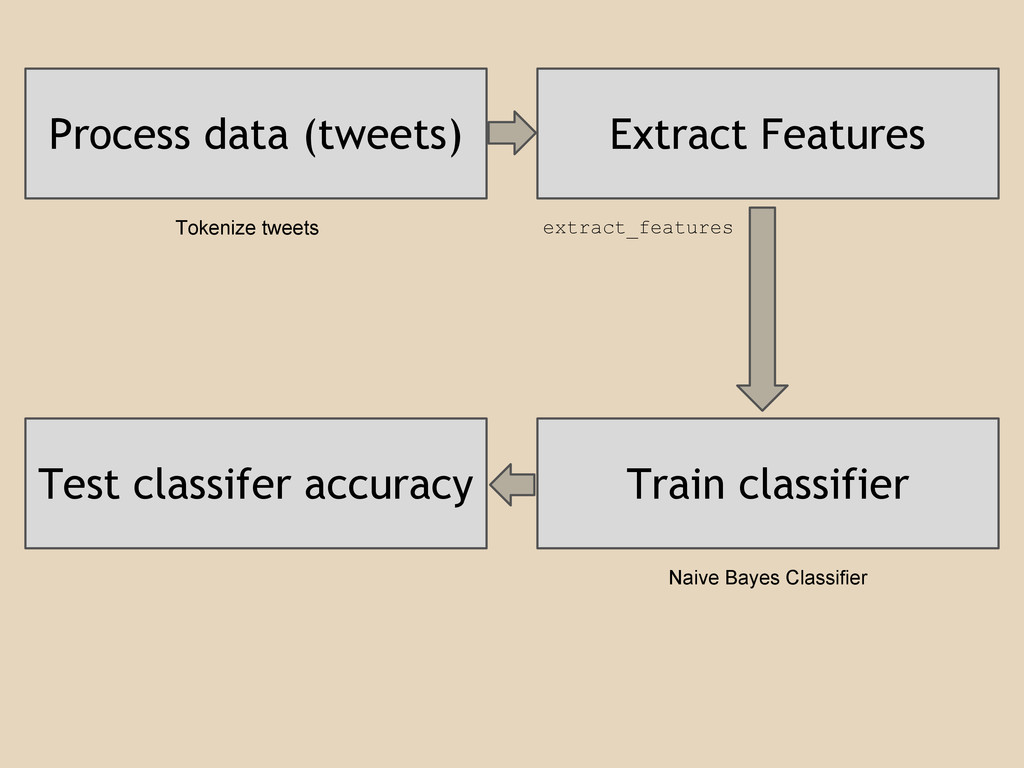
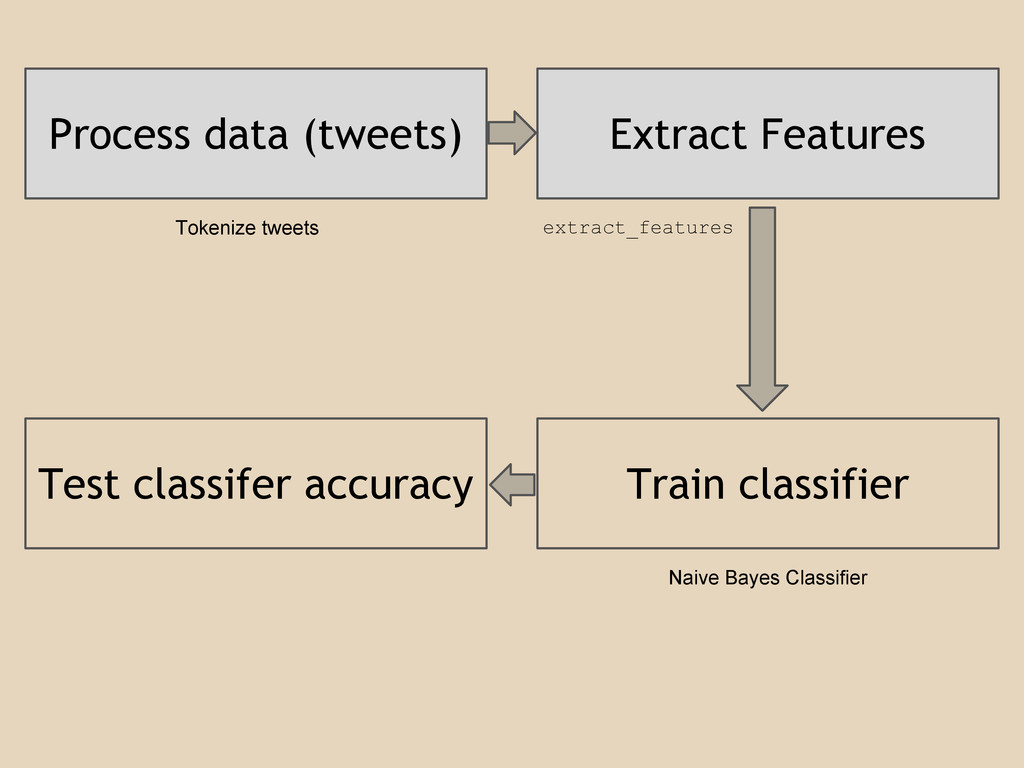
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
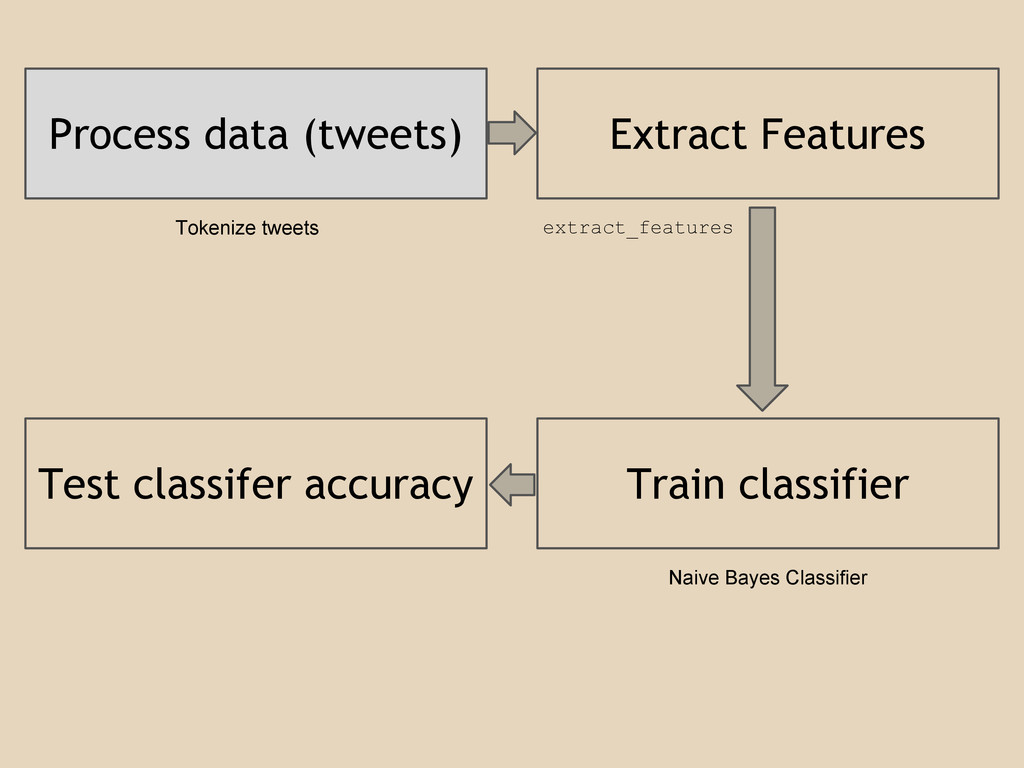
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
happy.txt sad.txt happy_test.txt sad_test.txt } training data } testing data
Tweets obtained from Twitter Search API
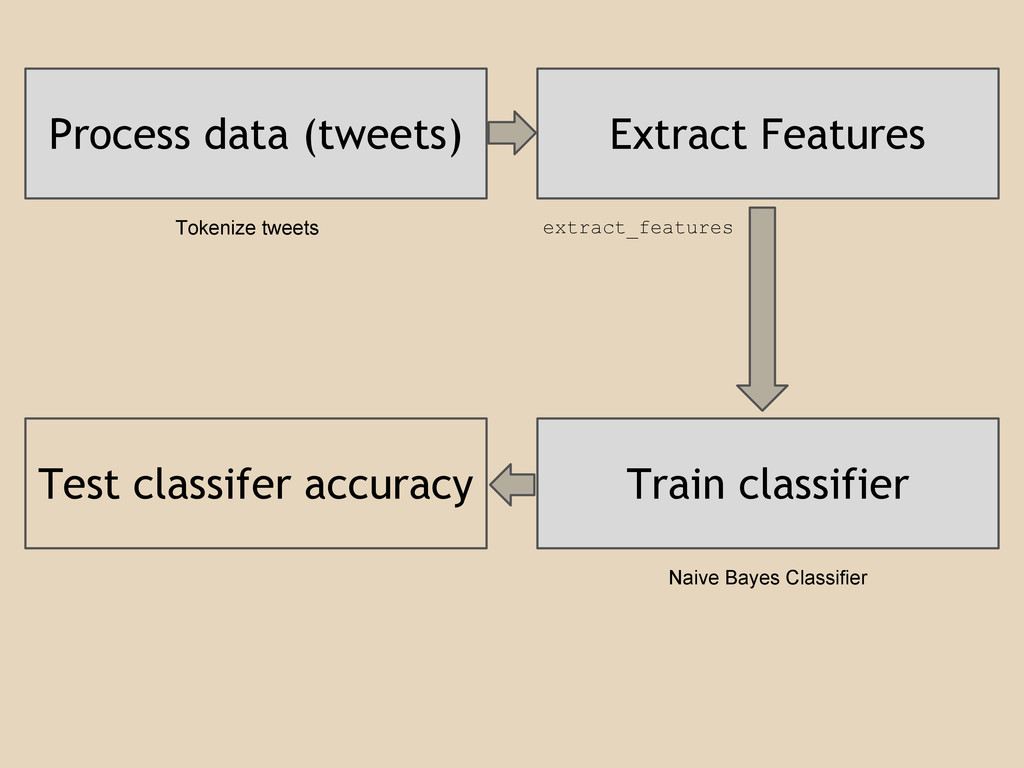
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
Happy tweets usually contain the following words: "am happy", "great
day" etc. Sad tweets usually contain the following: "not happy", "am sad" etc. features
{'contains(not)': False, 'contains(view)': False, 'contains(best)': False, 'contains(excited)': False, 'contains(morning)': False,
'contains(about)': False, 'contains(horrible)': True, 'contains(like)': False, ... } output of extract_features()
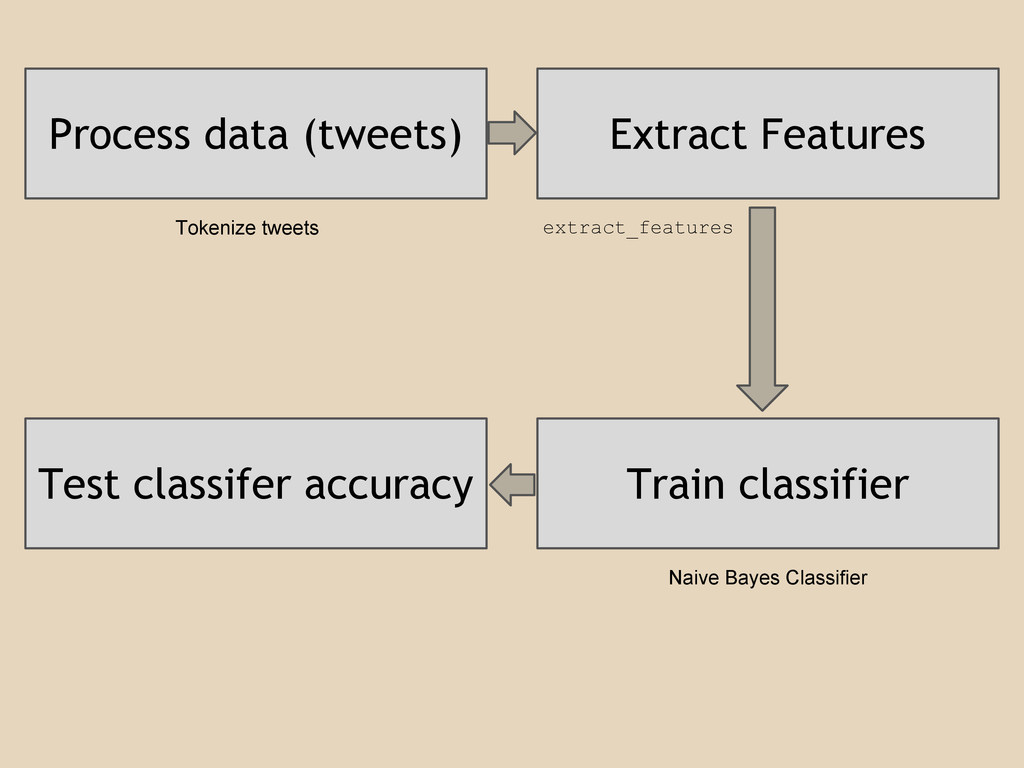
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
training_set = \ nltk.classify.util.\ apply_features(extract_features, tweets) classifier = \ NaiveBayesClassifier.train
(training_set) training the classifer training classifer
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
def classify_tweet(tweet): return \ classifier.classify(extract_features (tweet)) testing classifer
$ python classification.py Total accuracy: 90.00% (18/20) 18 tweets got
classified correctly.
Where to go from here.
http://www.nltk.org/book
https://class.coursera.org/nlp/auth/welcome
http://www.slideshare.net/shanbady/nltk-boston-text-analytics
[('Thank', 'NNP'), ('you', 'PRP'), ('.', '.')] @victorneo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pos tagging [('Run', 'NNP'), ('away', 'RB'), ('!', '.')] NNP: Proper](https://files.speakerdeck.com/presentations/4f71dcc0a1d1bd00220233b1/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[('Thank', 'NNP'), ('you', 'PRP'), ('.', '.')] @victorneo](https://files.speakerdeck.com/presentations/4f71dcc0a1d1bd00220233b1/slide_35.jpg){kind=link}