Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Simply Distributed
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Nugroho Herucahyono
October 22, 2015
Technology
120
0
Share
Simply Distributed
Nugroho Herucahyono
October 22, 2015
More Decks by Nugroho Herucahyono
See All by Nugroho Herucahyono
Choosing the right technology
xinuc
0
180
This Talk is so Meta
xinuc
1
130
A Tale of a Happy Programmer
xinuc
0
150
Rails on Wiradipa - Jakarta.rb Februari 2012 - Hafiz Badrie Lubiz
xinuc
1
170
Why Ruby? - View from business aspect - Jakarta.rb Februari 2012 - Fajrin Rasyid
xinuc
1
360
Other Decks in Technology
See All in Technology
PostgreSQL 18のNOT ENFORCEDな制約とDEFERRABLEの関係
yahonda
1
210
Podcast配信で広がったアウトプットの輪~70人と音声発信してきた7年間~/outputconf_01
fortegp05
0
190
互換性のある(らしい)DBへの移行など考えるにあたってたいへんざっくり
sejima
PRO
0
520
Data Enabling Team立ち上げました
sansantech
PRO
0
210
OCI技術資料 : ロード・バランサ 概要 - FLB・NLB共通
ocise
4
27k
AI時代のIssue駆動開発のススメ
moongift
PRO
0
340
最大のアウトプット術は問題を作ること
ryoaccount
0
270
Databricks Lakebaseを用いたAIエージェント連携
daiki_akimoto_nttd
0
120
トイルを超えたCREは何屋になるのか
bengo4com
0
120
OCI技術資料 : 証明書サービス概要
ocise
1
7.2k
Tour of Agent Protocols: MCP, A2A, AG-UI, A2UI with ADK
meteatamel
0
190
Zephyr(RTOS)でOpenPLCを実装してみた
iotengineer22
0
180
Featured
See All Featured
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
160
Believing is Seeing
oripsolob
1
100
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Making Projects Easy
brettharned
120
6.6k
Design in an AI World
tapps
0
190
Reality Check: Gamification 10 Years Later
codingconduct
0
2.1k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
199
73k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.6k
Speed Design
sergeychernyshev
33
1.6k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
320
Navigating Team Friction
lara
192
16k
Context Engineering - Making Every Token Count
addyosmani
9
790
Transcript
Simply Distributed KNIF 2015, Bandung
Who? Nugroho Herucahyono @xinuc Programmer @Bukalapak
Keandalan Sistem dalam Mendukung Penyediaan Layanan
“Andal" => reliable & scalable
reliable: fault tolerant scalable: able to grow
How a reliable & scalable system built?
Most systems start small
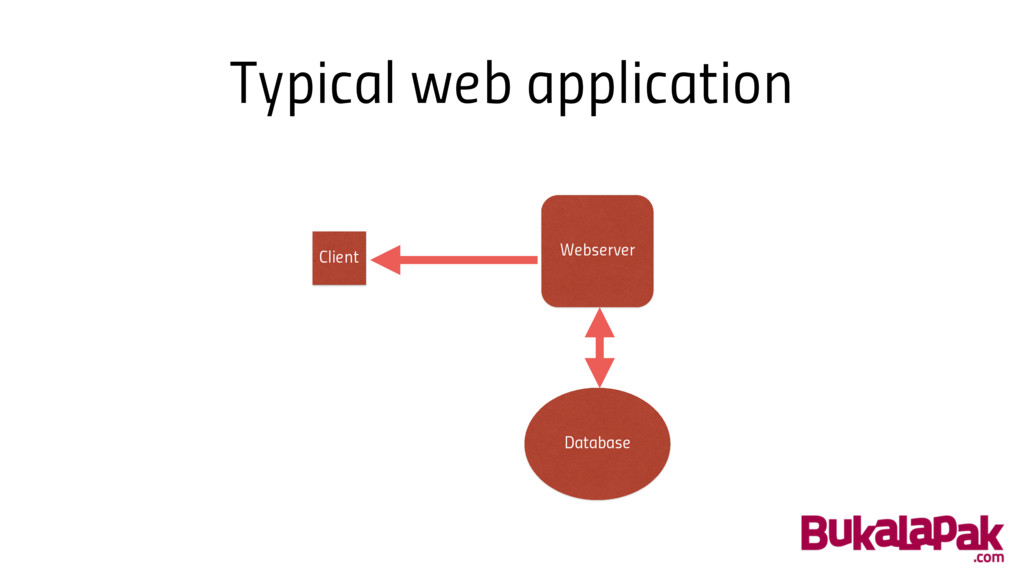
Typical web application Webserver Database Client
Typical web application • Need more features • Serve more
users • Need to be more reliable
More features Add more code Split the system
More users Need to scale machine limitation add more machines
More business value Need more reliable System should be fault
tolerant Self healing Backup, redundancy
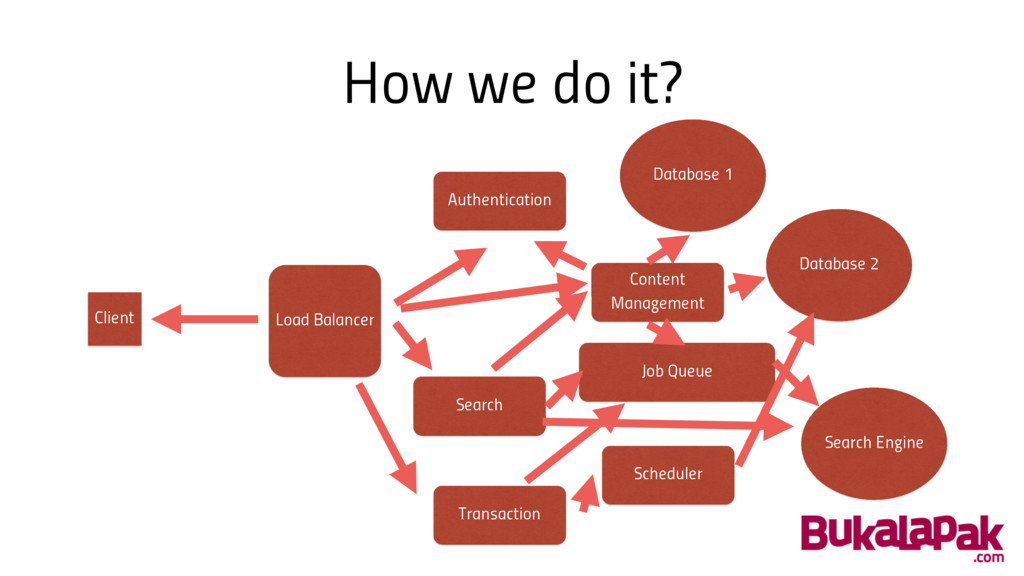
How we do it? Current “Best practice”: • Split system
into smaller services • Communicate with http • Scale independently • Gracefully handle failure
How we do it? Load Balancer Search Engine Client Authentication
Content Management Search Scheduler Transaction Database 2 Database 1 Job Queue
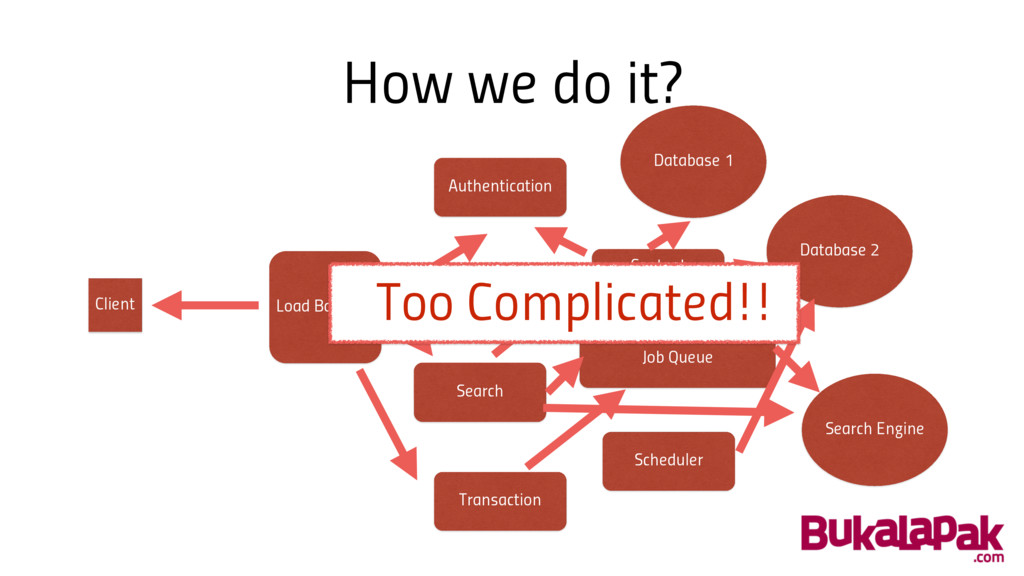
How we do it? Current “Best practice” apparently is not
the best: • Requires massive change to our system • Manual load balancing, replication • Manual resource management • Inefficient communication (http? really?)
How we do it? Load Balancer Search Engine Client Authentication
Content Management Search Scheduler Transaction Database 2 Database 1 Job Queue Too Complicated!!
What would a good computer scientist do?
Introduce a new layer of abstraction!
A new layer of abstraction • Handle resource management •
Handle load balancing • Handle service communication • Handle service failure • Handle replication
A new layer of abstraction We need “Operating System” of
a cluster
A new layer of abstraction Cluster Operating system Operating System
Pod Application Hardware Operating System Pod Application Hardware Operating System Pod Application Hardware
Cluster Operating System • Build in interprocess communication • Build
in monitoring & supervision • Automatic load balancing • Automatic resource management • Scale with little / no system modification
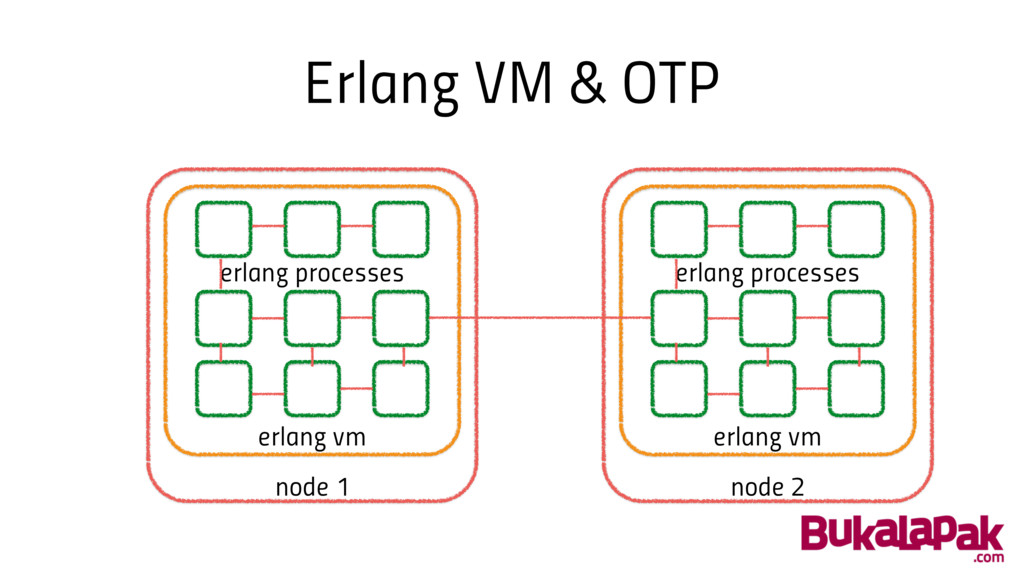
What do we have now? • Erlang VM & OTP
• Docker, Kubernetes
Erlang VM & OTP node 1 erlang vm erlang processes
node 2 erlang vm erlang processes
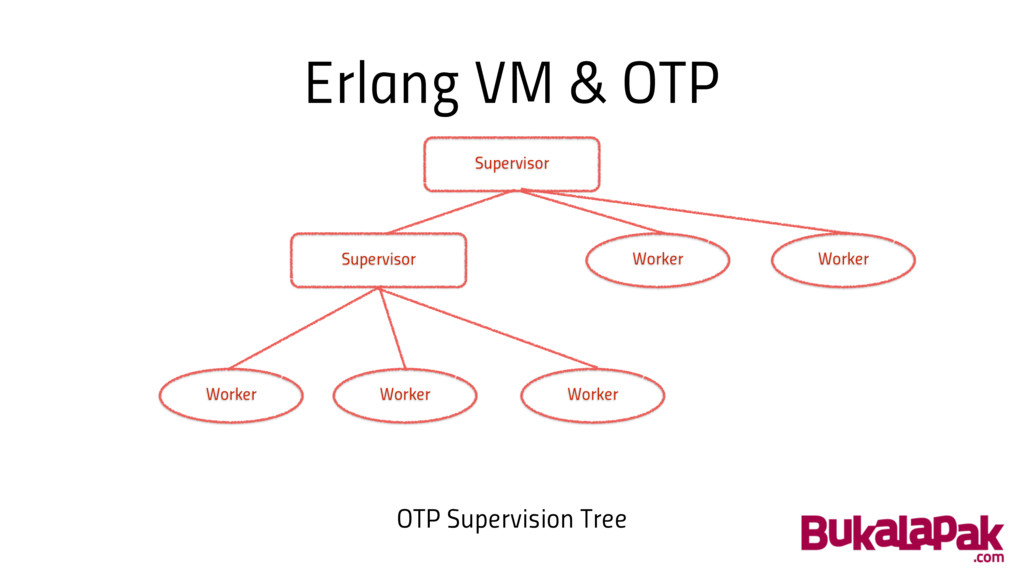
Erlang VM & OTP Supervisor Supervisor Worker Worker Worker Worker
Worker OTP Supervision Tree
Erlang VM & OTP • Build in interprocess communication √
• Build in monitoring & supervision √ • Automatic load balancing X • Automatic resource management X • Scale with little / no system modification √
Erlang VM & OTP • The building block is too
low level? (erlang processes) • Your application need to be written in erlang (or other erlang vm languages)
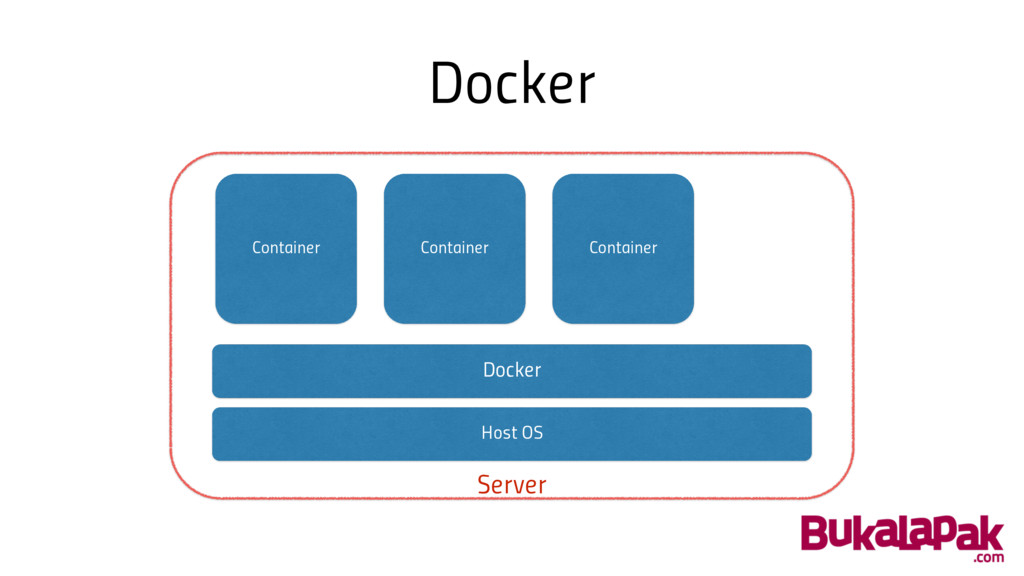
Docker • Like virtual machine, but much lighter • Encapsulate
our application into single “executable” • Remove dependencies, development vs production headache
Docker Host OS Docker Container Container Container Server
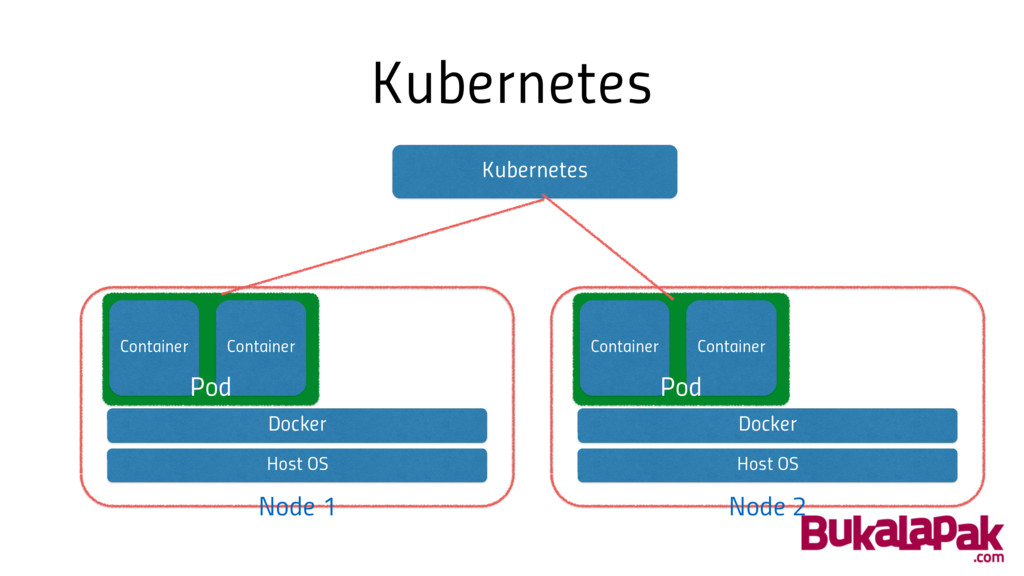
Kubernetes • Manages & monitors containers • Resource allocation between
containers
Kubernetes Host OS Docker Container Container Pod Host OS Docker
Container Container Pod Node 1 Node 2 Kubernetes
Docker & Kubernetes • Build in interprocess communication X •
Build in monitoring & supervision √ • Automatic load balancing √ • Automatic resource management √ • Scale with little / no system modification X
Docker & Kubernetes • No build in interprocess communication •
Still have to modify the system (split into smaller services) • Too complicated
Can we do better?
Let’s zoom out a bit • Service vs Process •
Node vs Core They’re conceptually the same
Maybe we can push down the abstraction layer?
What if, our “Cluster operating system” is a real Operating
System?
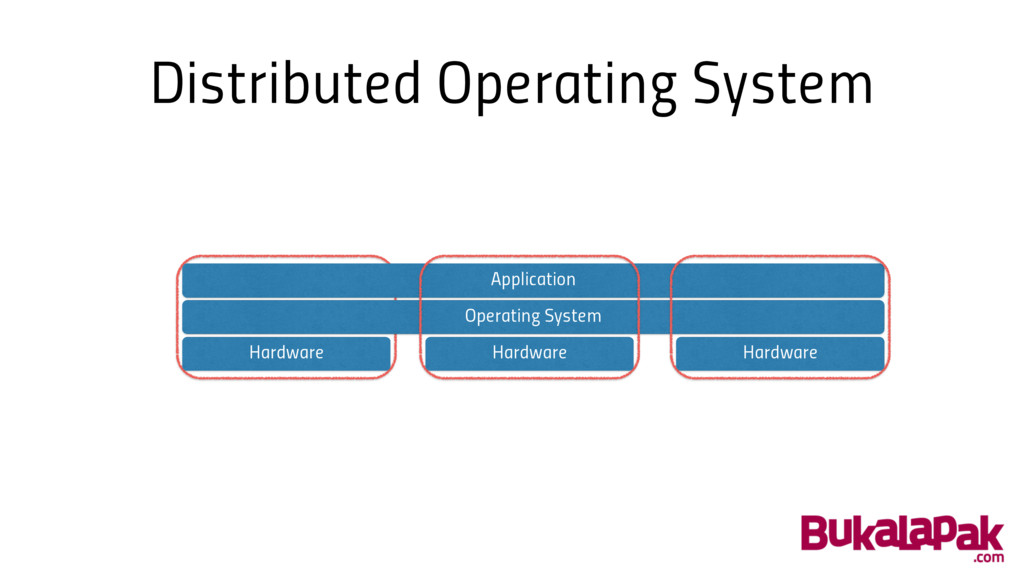
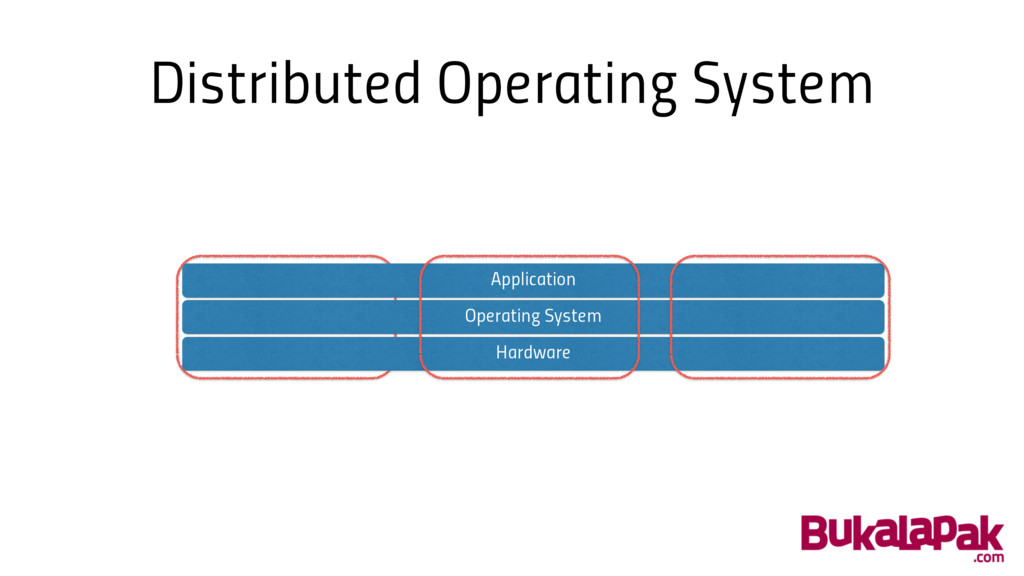
We need a real “Distributed Operating System”
Distributed Operating System Operating System Application Hardware Hardware Hardware
Distributed Operating System • Encapsulate multiple machines as a single
node • Transparent from user / application point of view • Handle load balancing, replication & distribution automatically • Better yet, if we can add more machine on the fly
Is it possible? I have no idea.
We’ve done something similar • Raid • Multiple disk, single
volume • Transparent from applications • Automatic failure handling & replication
We need Raid for CPU & Memory
Or maybe, we can push it down further, to the
hardware level?
We need a real “Distributed Motherboard” :D
Distributed Operating System Operating System Application Hardware
Distributed Motherboard • Node 1, 32 Cores, 32 GB RAM
• Node 2, 32 Cores, 32 GB RAM • Detected by operating system as 1 Node, 64 Cores, 64 GB RAM
Distributed Motherboard • We can add more node, on the
fly • Motherboard will communicate between each other • Abstract their resources as a SINGLE NODE
Again, is it possible? I have no idea.
We’ve done that too • Hardware Raid Controller • Multiple
Disk, detected as a single hardware • Transparent from operating system & application
Too much wishful thinking?
Why does it matter?
Why does it matter? Scalable & Reliable system is a
SOLVED problem We already have Google, Facebook, etc as a prove
Why does it matter? • Scalable & Reliable system is
not easy & cheap • Need a group of highly skilled experts to build
Case Study: WhatsApp
Case Study: WhatsApp • WhatsApp use Erlang VM & OTP
• They can scale it without adding too much complexity
Case Study: WhatsApp
Case Study: WhatsApp We need more companies like WhatsApp
Small Startups? Can 4-fresh-graduate startup create a product used by
a billion users?
Non profits? Can we create non profit system than serve
billons of users?
./bukalapak
more research on this, please :)
Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}