attributes on the current instance. """ assert obj, "Instance has not yet been created." obj.__class__._base_manager.using(using)\ .filter(pk=obj) .update(**kwargs) for k, v in kwargs.iteritems(): if isinstance(v, ExpressionNode): # NotImplemented continue setattr(obj, k, v) A better way to approach updates http://github.com/andymccurdy/django-tips-and-tricks/blob/master/model_update.py 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
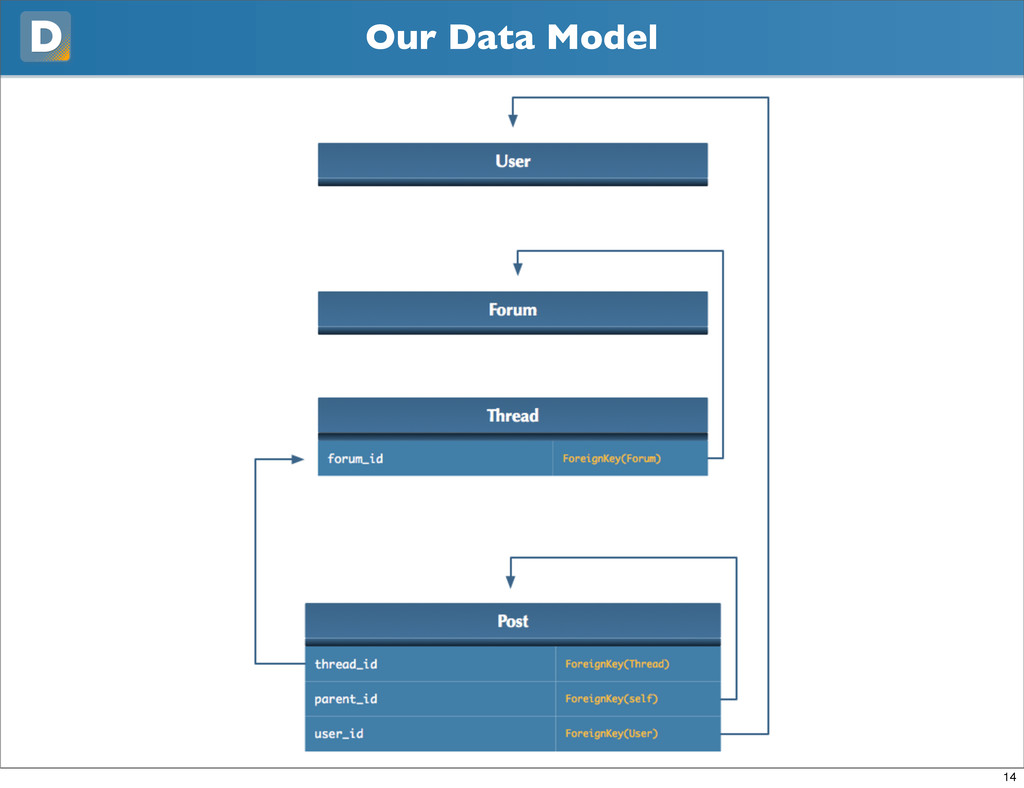{kind=link}
{kind=link}
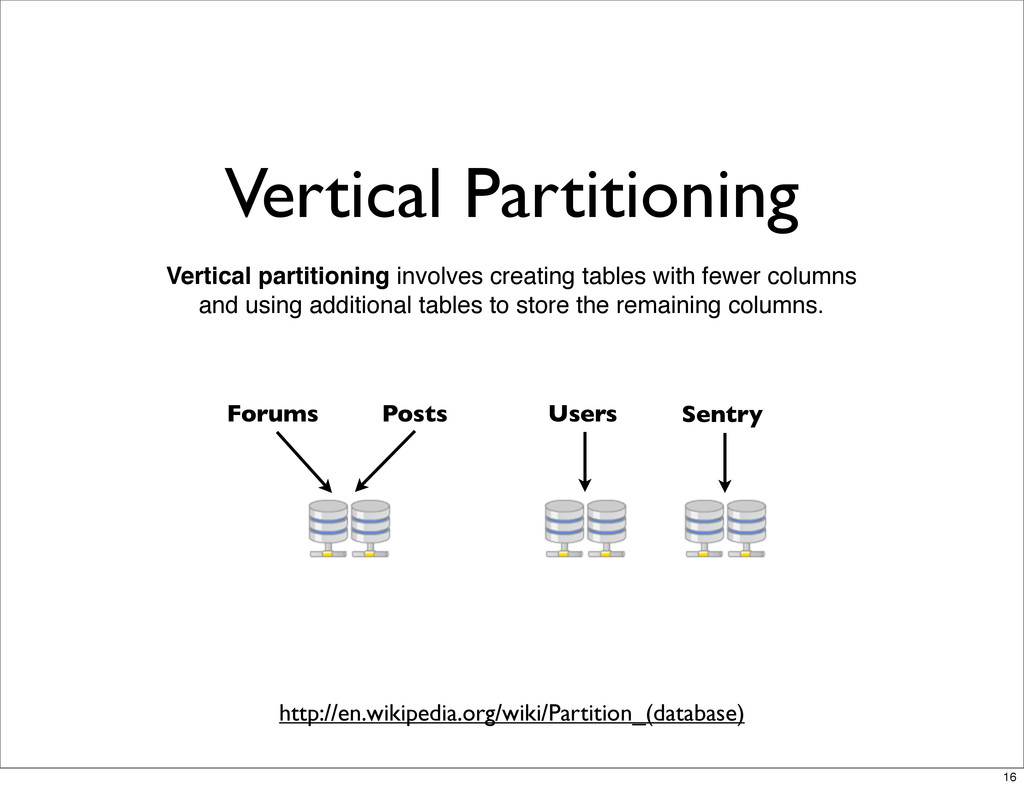{kind=link}
![Pythonic Joins posts = Post.objects.all()[0:25] # store users in a](https://files.speakerdeck.com/presentations/4e80d5fe5cc0ec0063000376/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
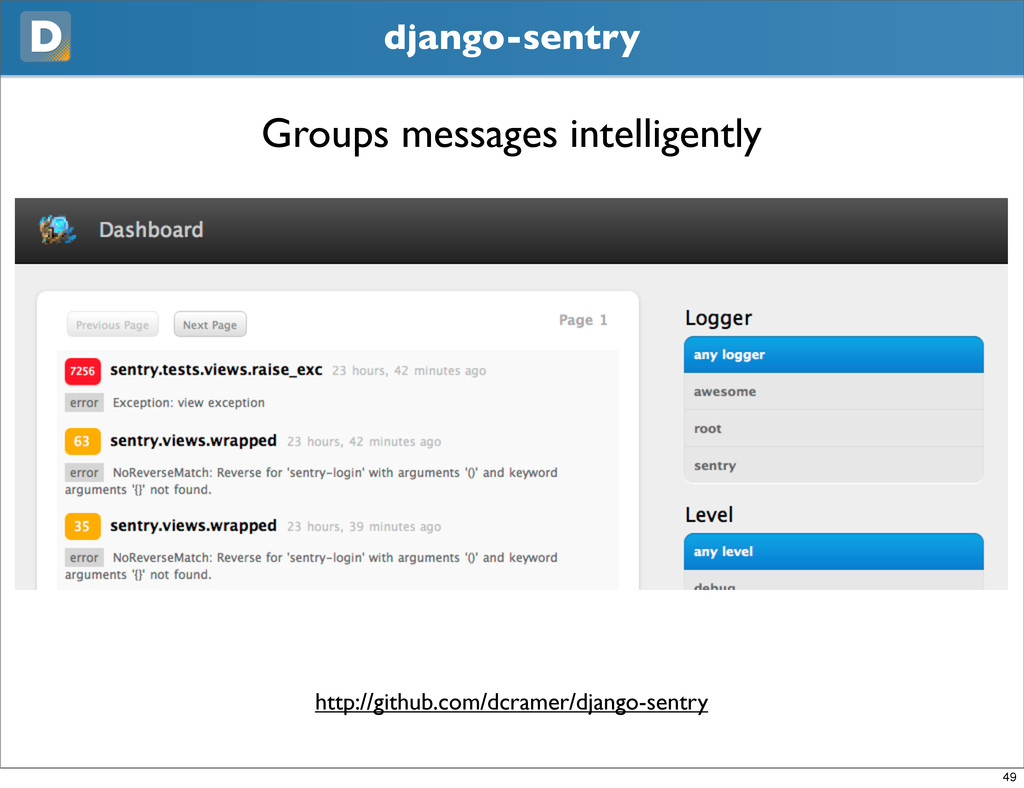{kind=link}
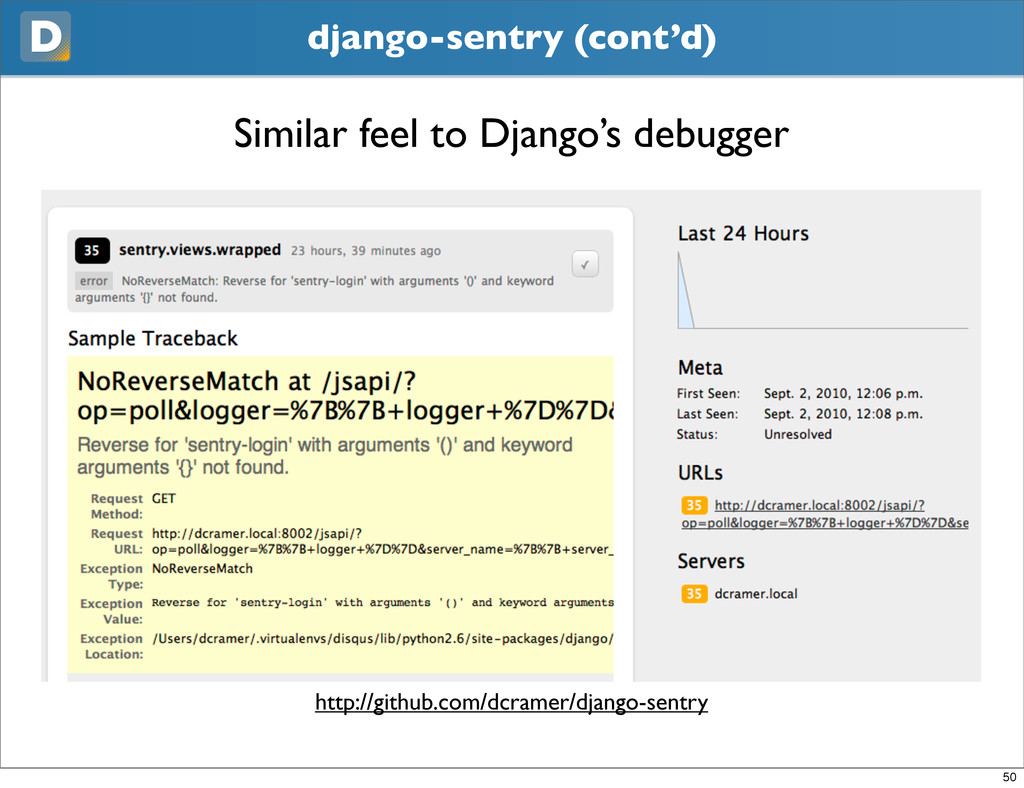{kind=link}
{kind=link}
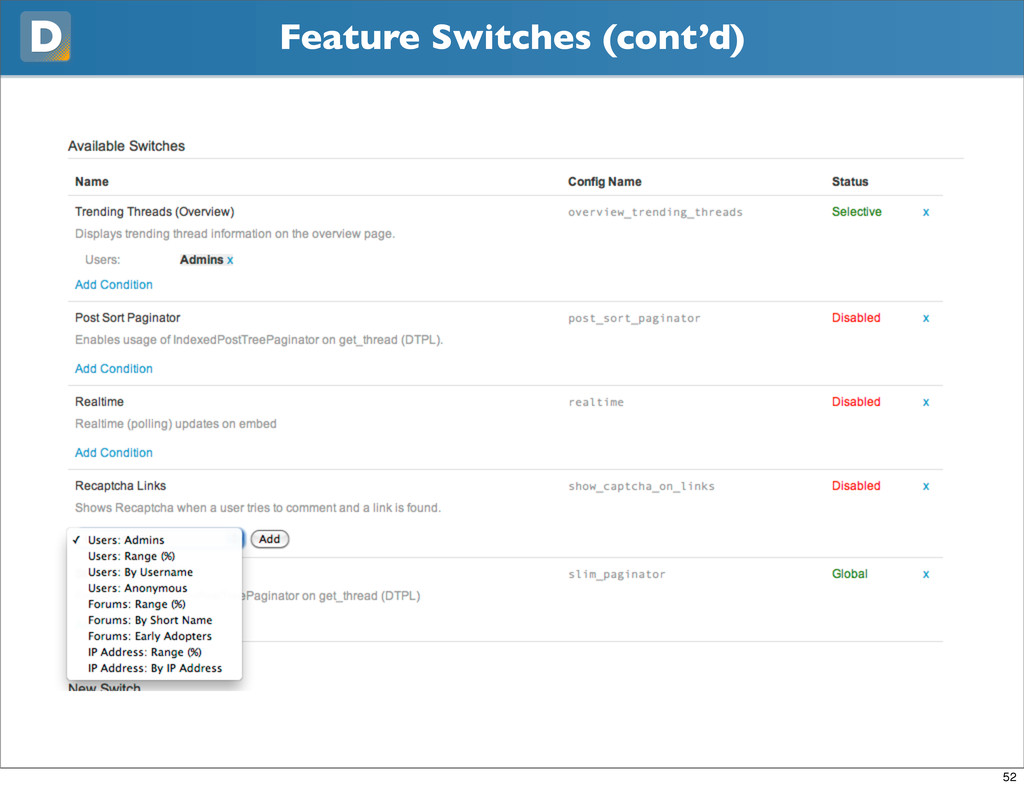{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}