across millions of tokens of context ⾃⼰修正 • Self-Reflection in LLM Agents: Effects on Problem-Solving Performance 計画 • Large Language Models as Planning Domain Generators ⻑いコンテキスト理解 • Many-Shot In-Context Learning in Multimodal Foundation Models • CinePile: A Long Video Question Answering Dataset and Benchmark エージェントの評価 • Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models Agent Framework • How Far Are We From AGI? • Towards Guaranteed Safe AI:A Framework for Ensuring Robust and Reliable AI Systems Multi Agent Systems • AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
basic world knowledge in language models • AIエージェントにとって、世界モデルを構築して活⽤する能⼒は重要だが、世界モデルの構成要素が明確に定 義されていないため、評価するのは難しい • EWOK(Elements of World Knowledge)フレームワークを提案 • LLMが特定の概念に関する知識を使⽤して、ターゲットテキストと同じ⽂脈テキストか分類する能⼒をテストする • コンセプト:社会的相互作⽤、空間関係、直感的物理、数の感覚、エージェントの推論など • LLMは、社会的相互作⽤(例えば、助ける、妨げるなどの⾏動)を理解する能⼒が⽐較的⾼い • LLMは、空間関係の能⼒が低く、「左/右」といった具体的な空間的指⽰に基づいた⽂脈の判断が難しい Agent Capabilities
・様々なGoogleアプリにエージェントが搭載 ・Atlassian Rovo/チームメイト型エージェント ・Integrating LangChain with Azure Container Apps dynamic sessions 技術記事 ・モデルの発展に伴いLLMアプリ開発者のベストプラクティスも変化 ・製造業での⽣成AI活⽤術:⾃社製品を理解した基盤モデルと検索を組み合わせた⽤途探索 ・⼩売業への⽣成AIエージェントの応⽤ ・SaaS Is Readying for an Agentic Future ・Multi AI Agent Systems with crewAI ・AIガジェット「rabbit r1」を使ってみた
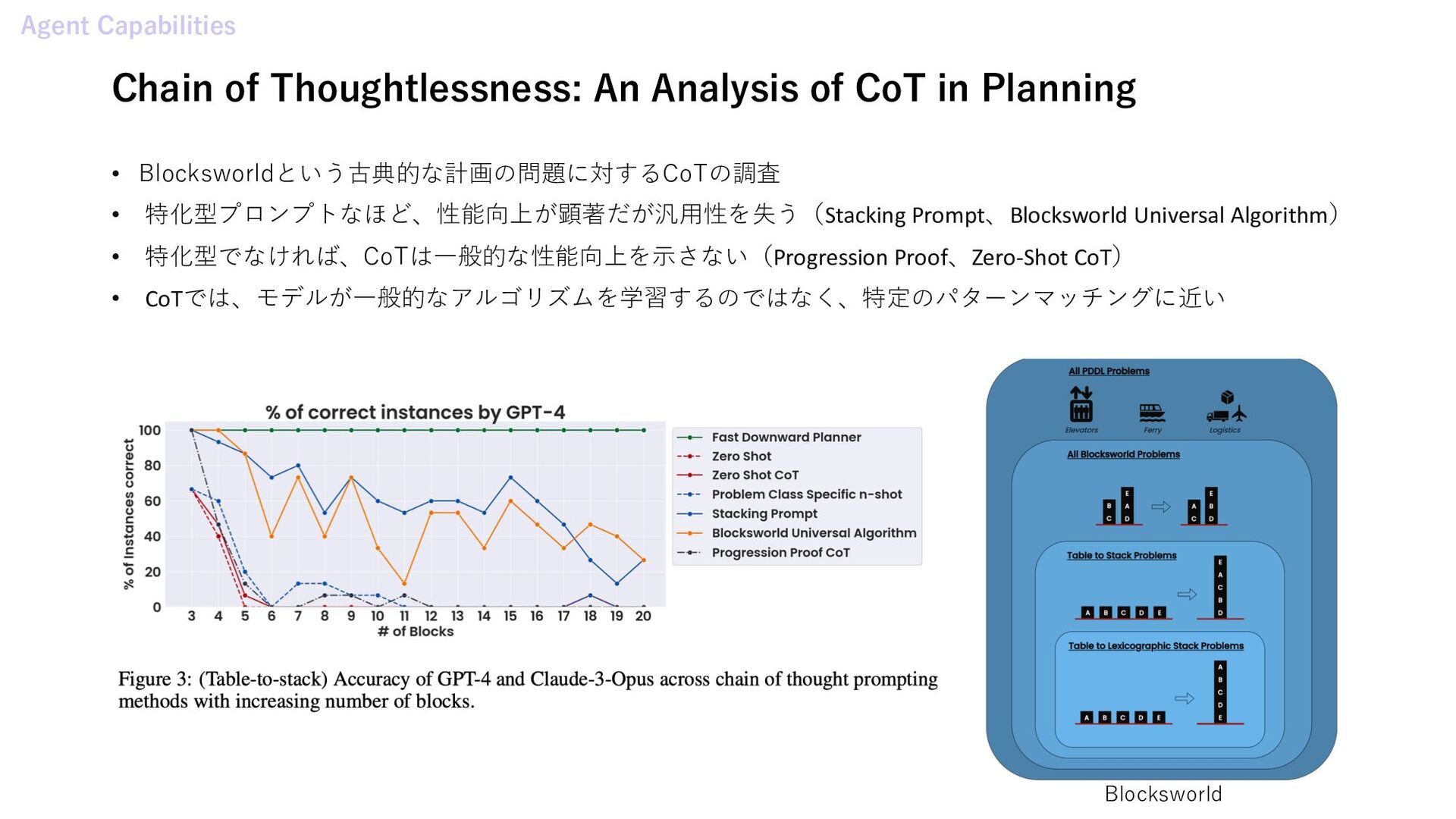
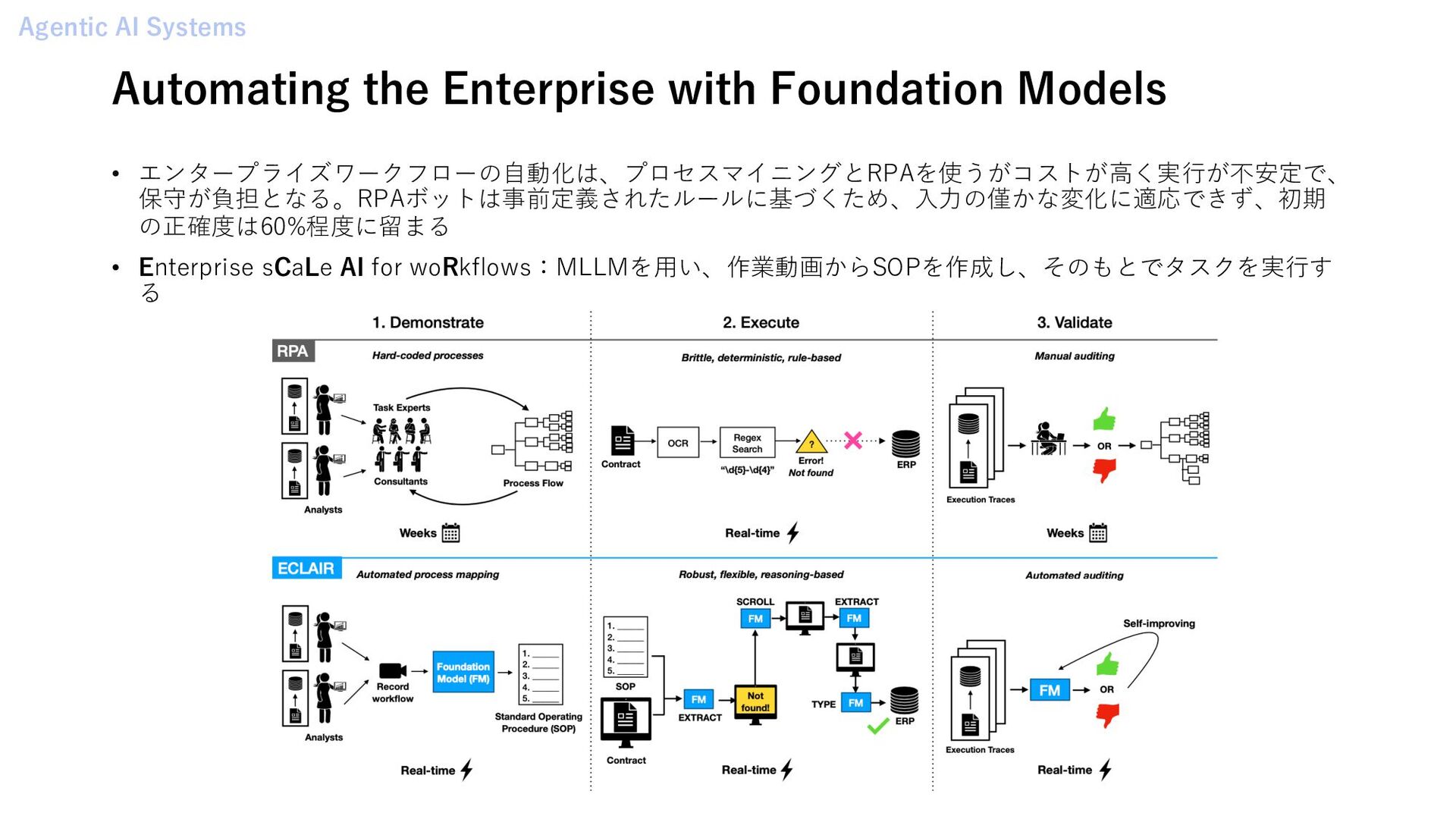
Harms from Persuasive Generative AI • In-Context Learning with Long-Context Models: An In-Depth Exploration • Sub-goal Distillation: A Method to Improve Small Language Agents • Chain of Thoughtlessness: An Analysis of CoT in Planning Agent Framework • Air Gap: Protecting Privacy-Conscious Conversational Agents • Offline Training of Language Model Agents with Functions as Learnable Weights Agentic AI Systems • Assessing and Verifying Task Utility in LLM-Powered Applications • A Unified Industrial Large Knowledge Model Framework in Smart Manufacturing • SWE-AGENT: AGENT-COMPUTER INTERFACES ENABLE AUTOMATED SOFTWARE ENGINEERING • Automating the Enterprise with Foundation Models • Autonomous LLM-driven research from data to human-verifiable research papers Multi Agent Systems • Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents • MARE: Multi-Agents Collaboration Framework for Requirements Engineering Computer Controlled Agents • Unveiling Disparities in Web Task Handling Between Human and Web Agent
• AgentEval は3つのエージェント(CriticAgent、QuantifierAgent、VerifierAgent)を通じておこなう CriticAgent:タスクの記述や成功・失敗した例に基づいて、タスクの有⽤性を評価するための基準を提案 QuantifierAgent:提案された基準に基づいて、アプリケーションのタスク有⽤性を定量化 VerifierAgent:最終的にCriticAgentが提案した基準が問題ないか検証 Agentic AI Systems
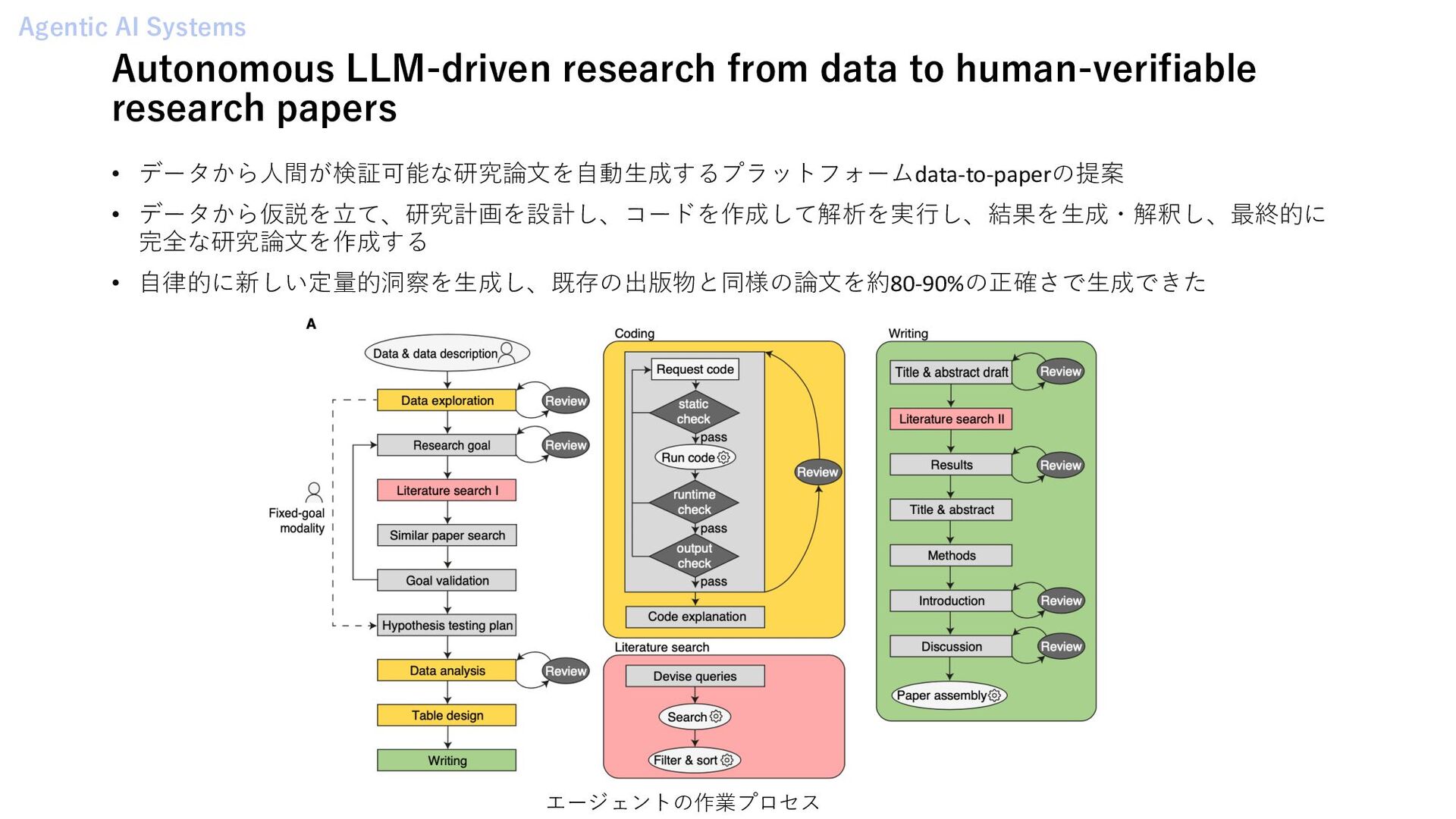
データから⼈間が検証可能な研究論⽂を⾃動⽣成するプラットフォームdata-to-paperの提案 • データから仮説を⽴て、研究計画を設計し、コードを作成して解析を実⾏し、結果を⽣成・解釈し、最終的に 完全な研究論⽂を作成する • ⾃律的に新しい定量的洞察を⽣成し、既存の出版物と同様の論⽂を約80-90%の正確さで⽣成できた エージェントの作業プロセス Agentic AI Systems
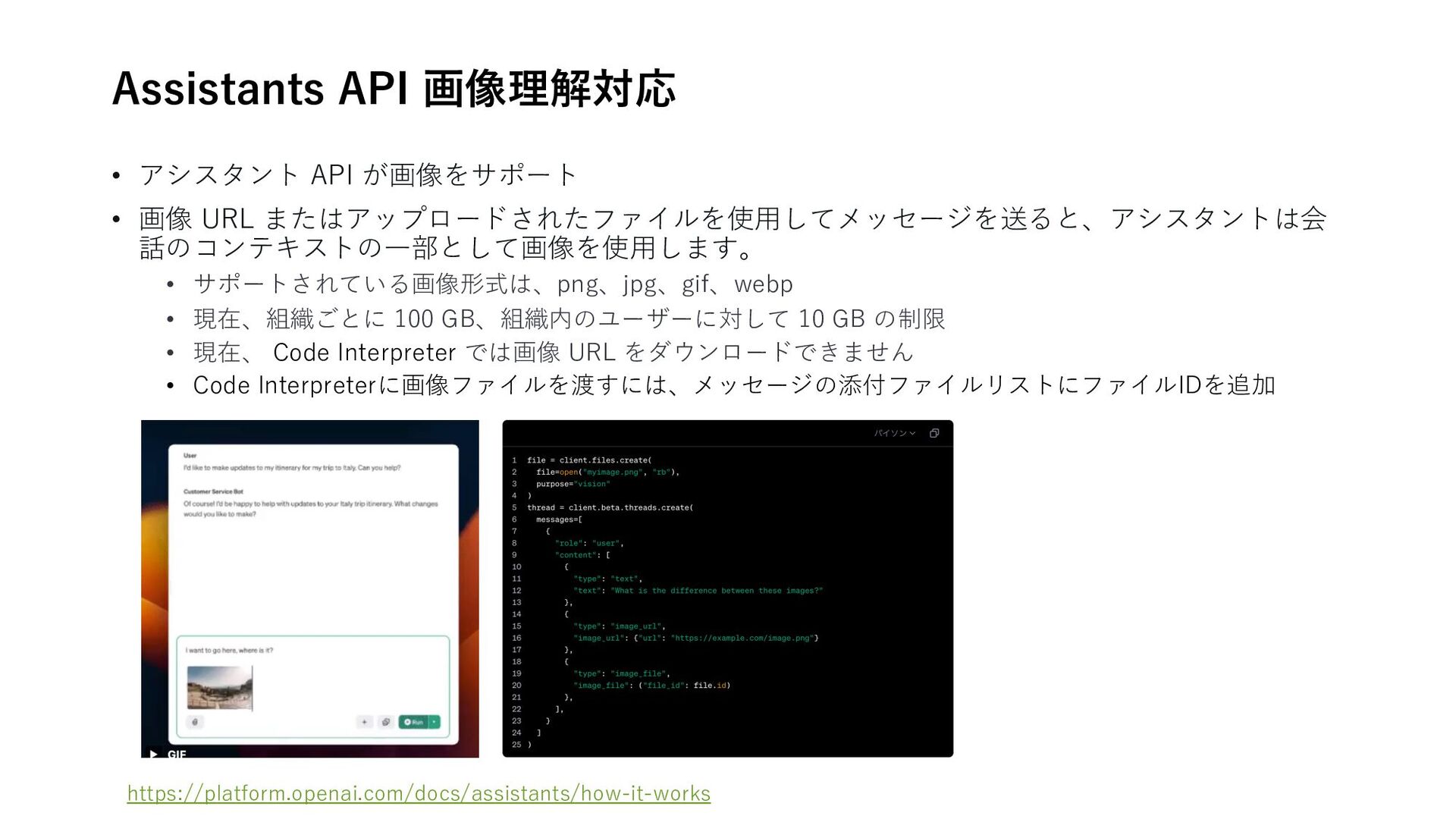
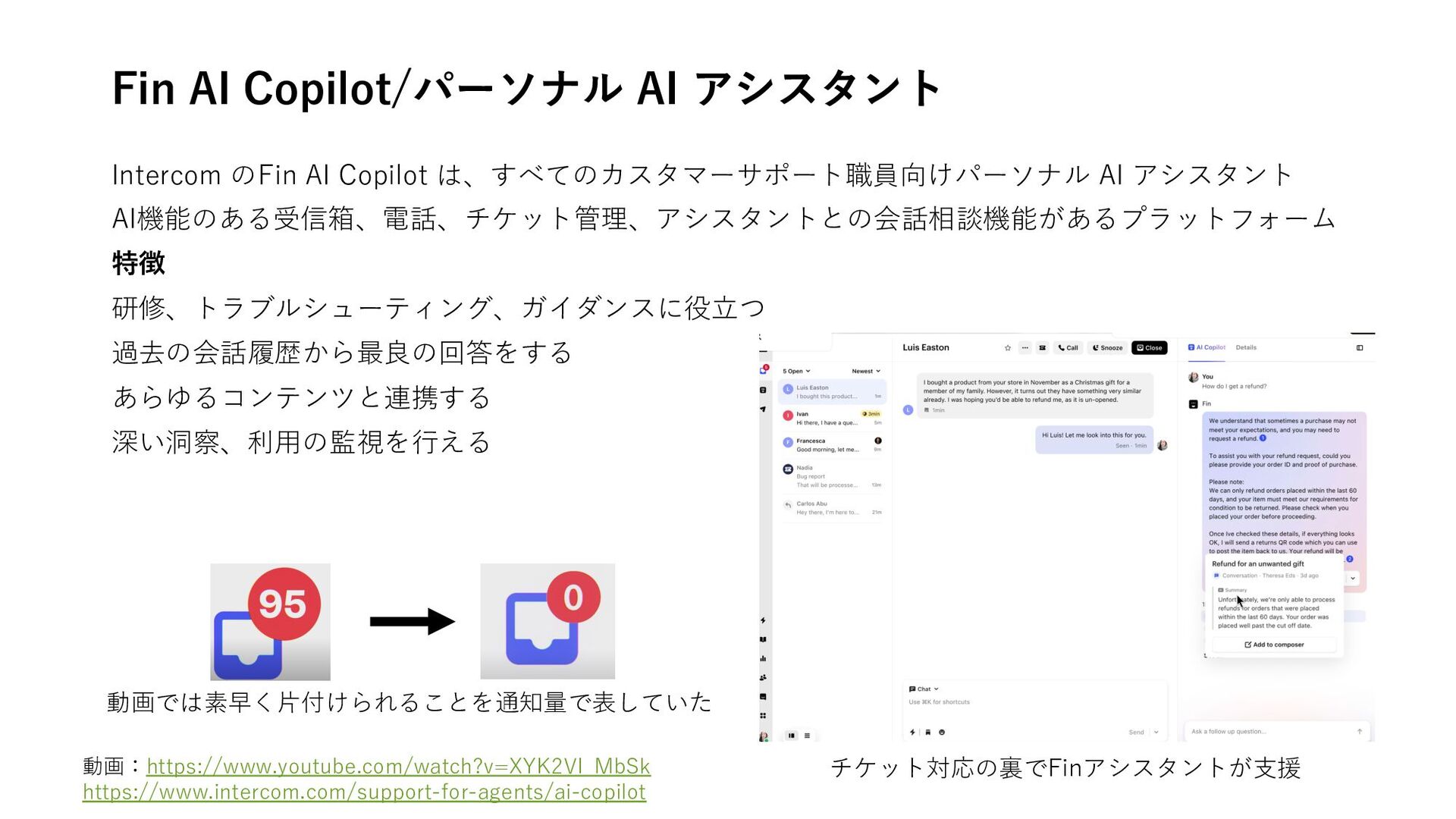
How to get AI ʻagentsʼ working like humans • 新たな AI AgentOps の展望 • AIの職場導⼊に関する最新のトレンド from Microsoft and LinkedIn • Largest library of AI-UX Interactions 技術記事 • Agents for Amazon Bedrock: Handling return of control in code • Generative AIが製品設計に与える影響とその調整 • The Agentic Era of UX リリース情報 • Assistants API 画像理解対応 • OpenAI Model Spec公開 海外ベンチャー企業 • Assista/単⼀のアプリからビジネス管理 • Fin AI Copilot/パーソナル AI アシスタント
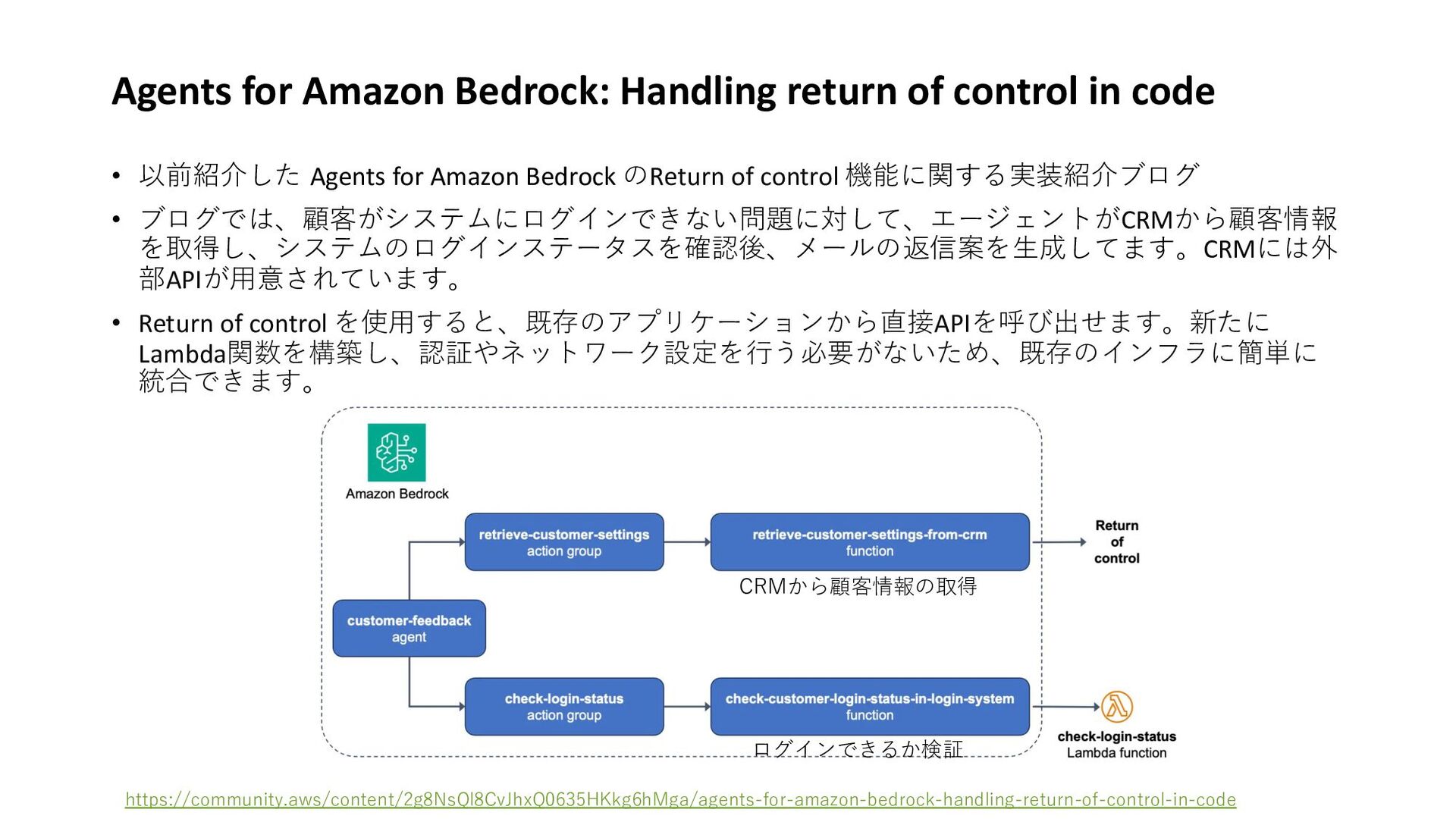
• 以前紹介した Agents for Amazon Bedrock のReturn of control 機能に関する実装紹介ブログ • ブログでは、顧客がシステムにログインできない問題に対して、エージェントがCRMから顧客情報 を取得し、システムのログインステータスを確認後、メールの返信案を⽣成してます。CRMには外 部APIが⽤意されています。 • Return of control を使⽤すると、既存のアプリケーションから直接APIを呼び出せます。新たに Lambda関数を構築し、認証やネットワーク設定を⾏う必要がないため、既存のインフラに簡単に 統合できます。 CRMから顧客情報の取得 ログインできるか検証 https://community.aws/content/2g8NsQl8CvJhxQ0635HKkg6hMga/agents-for-amazon-bedrock-handling-return-of-control-in-code
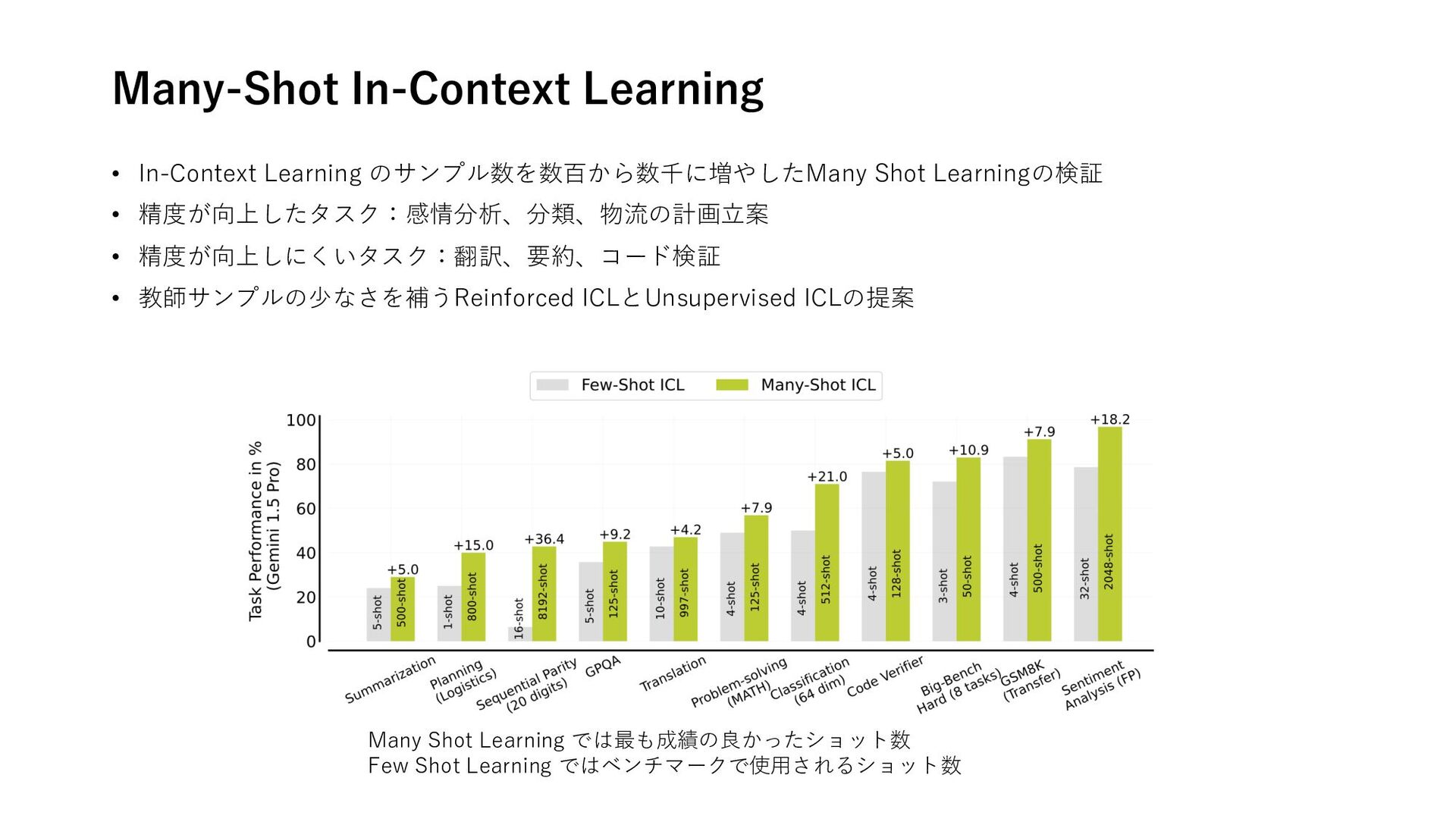
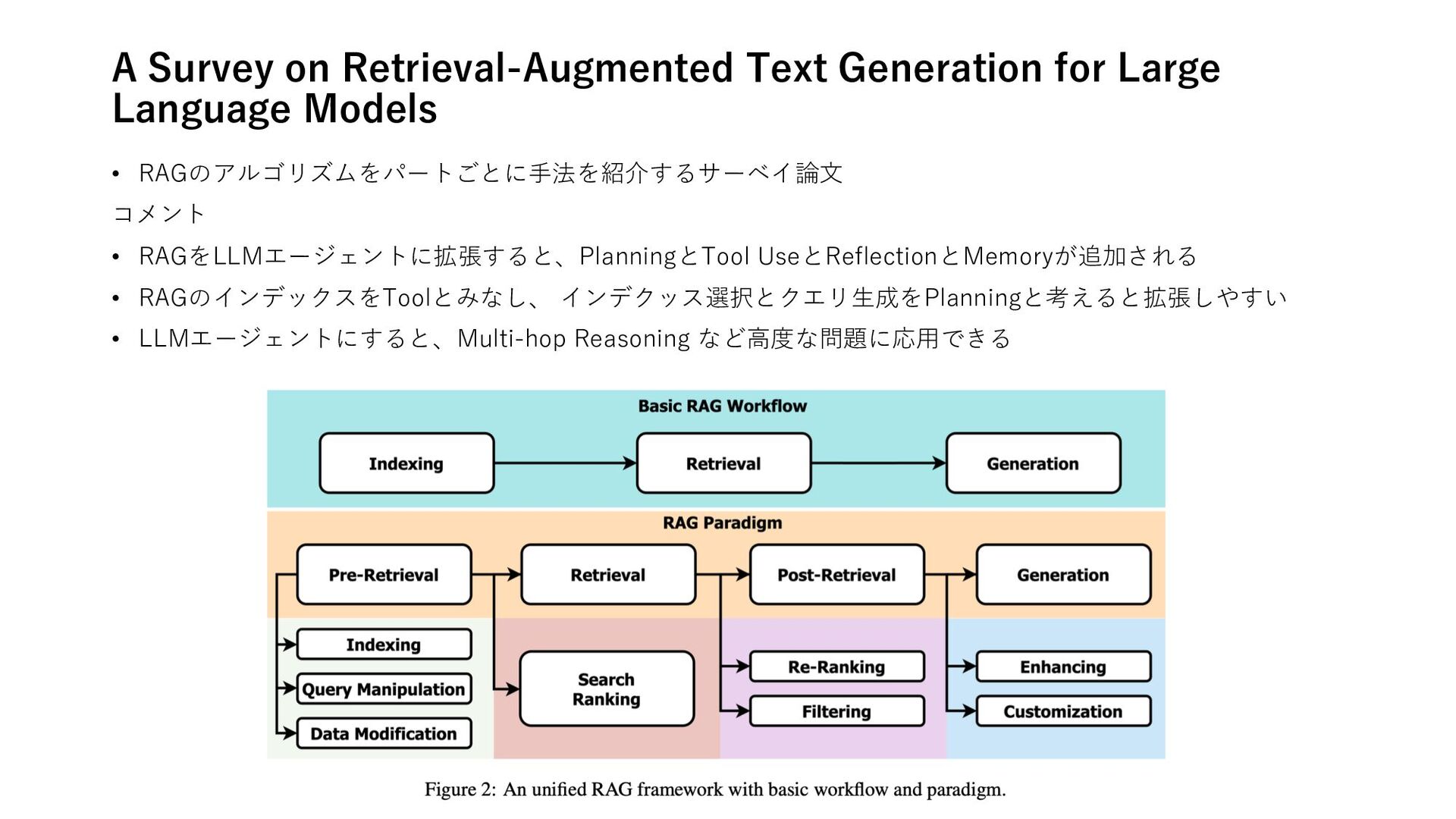
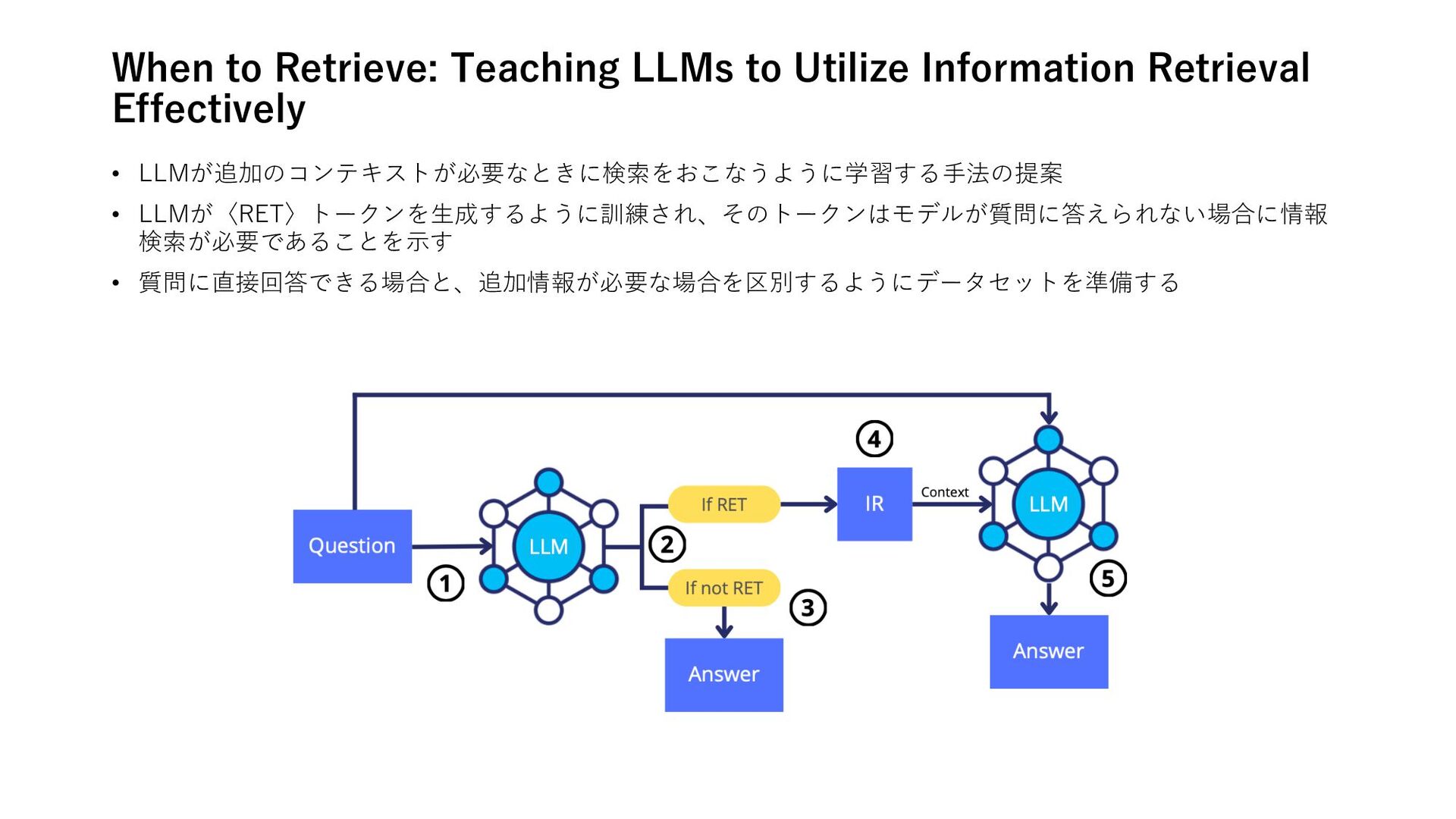
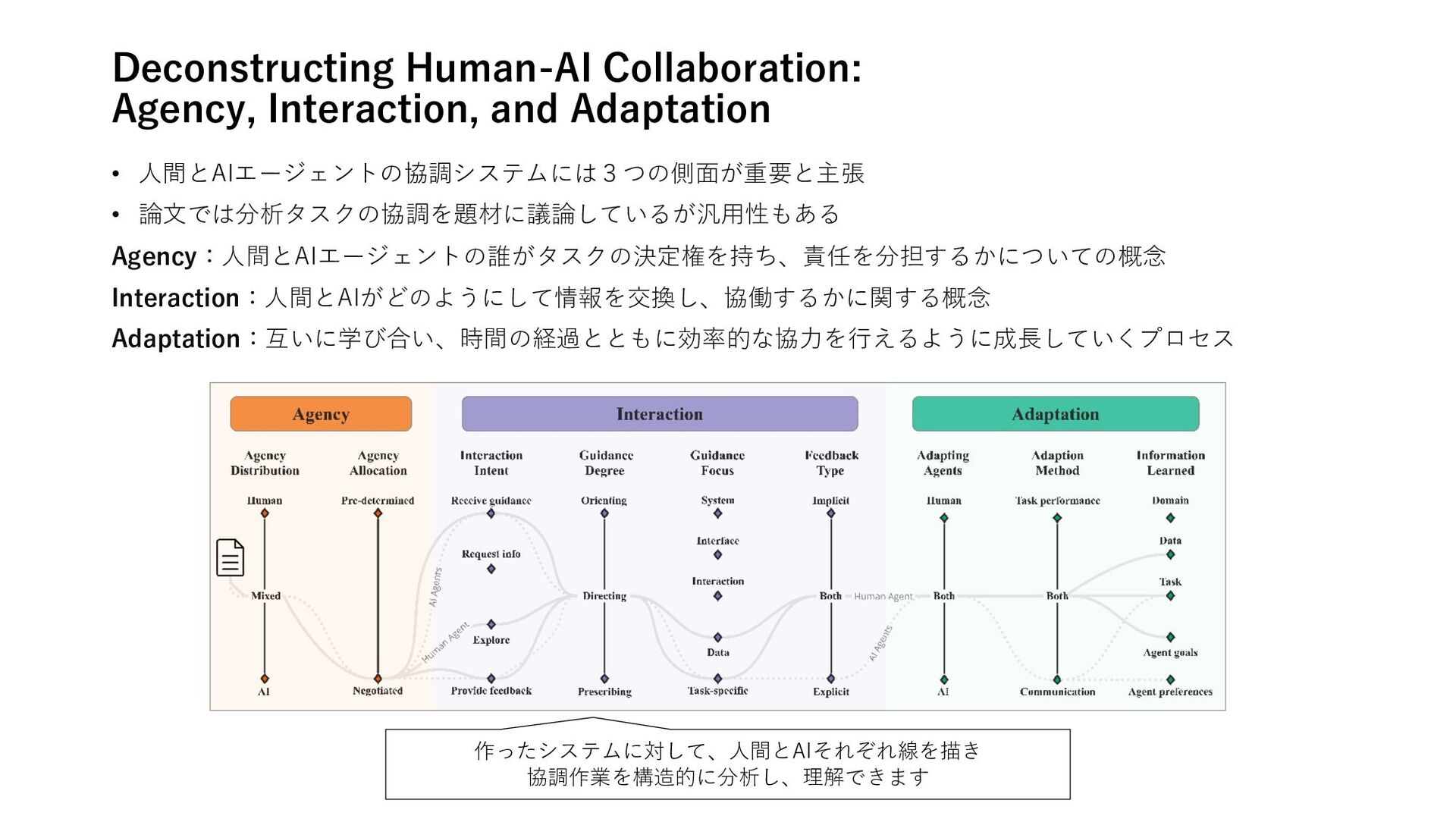
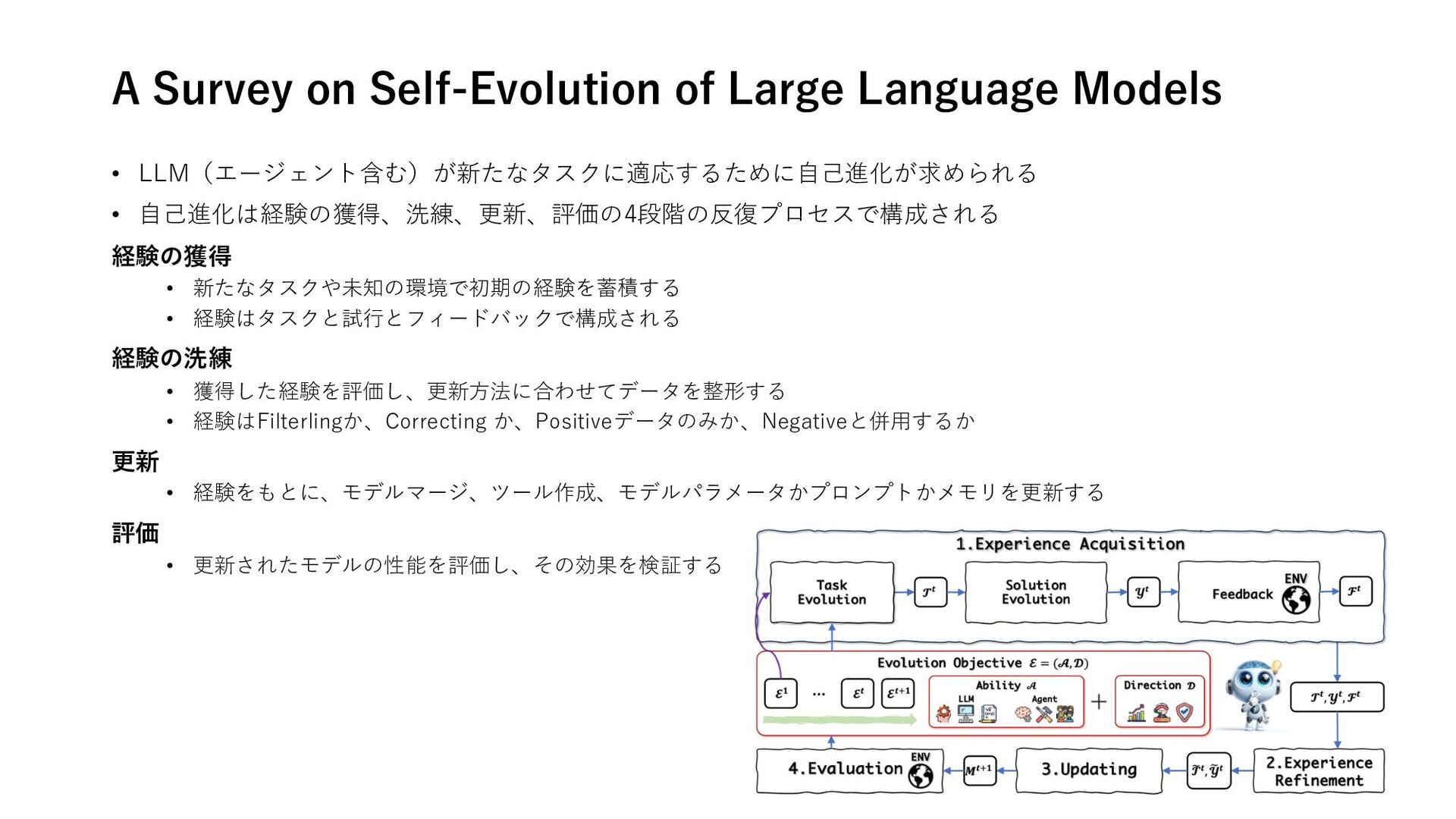
A Survey on Role-Playing Language Agents 推論 • Hallucination of Multimodal Large Language Models: A Survey • Many-Shot In-Context Learning 計画 • Testing and Understanding Erroneous Planning in LLM Agents through Synthesized User Inputs RAG • A Survey on Retrieval-Augmented Text Generation for Large Language Models • When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively フレームワーク • Deconstructing Human-AI Collaboration: Agency, Interaction, and Adaptation • A Survey on Self-Evolution of Large Language Models • The Ethics of Advanced AI Assistants
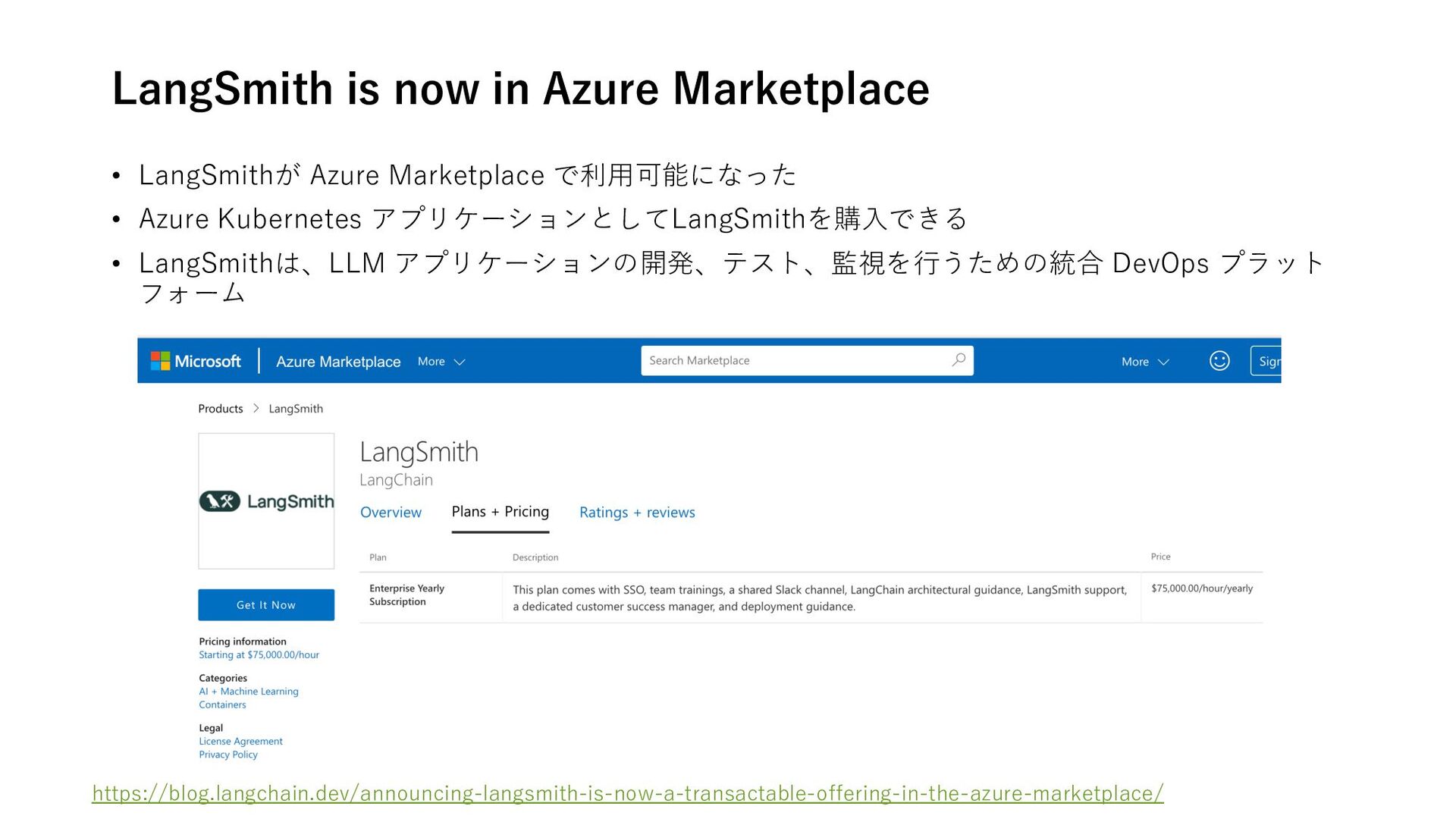
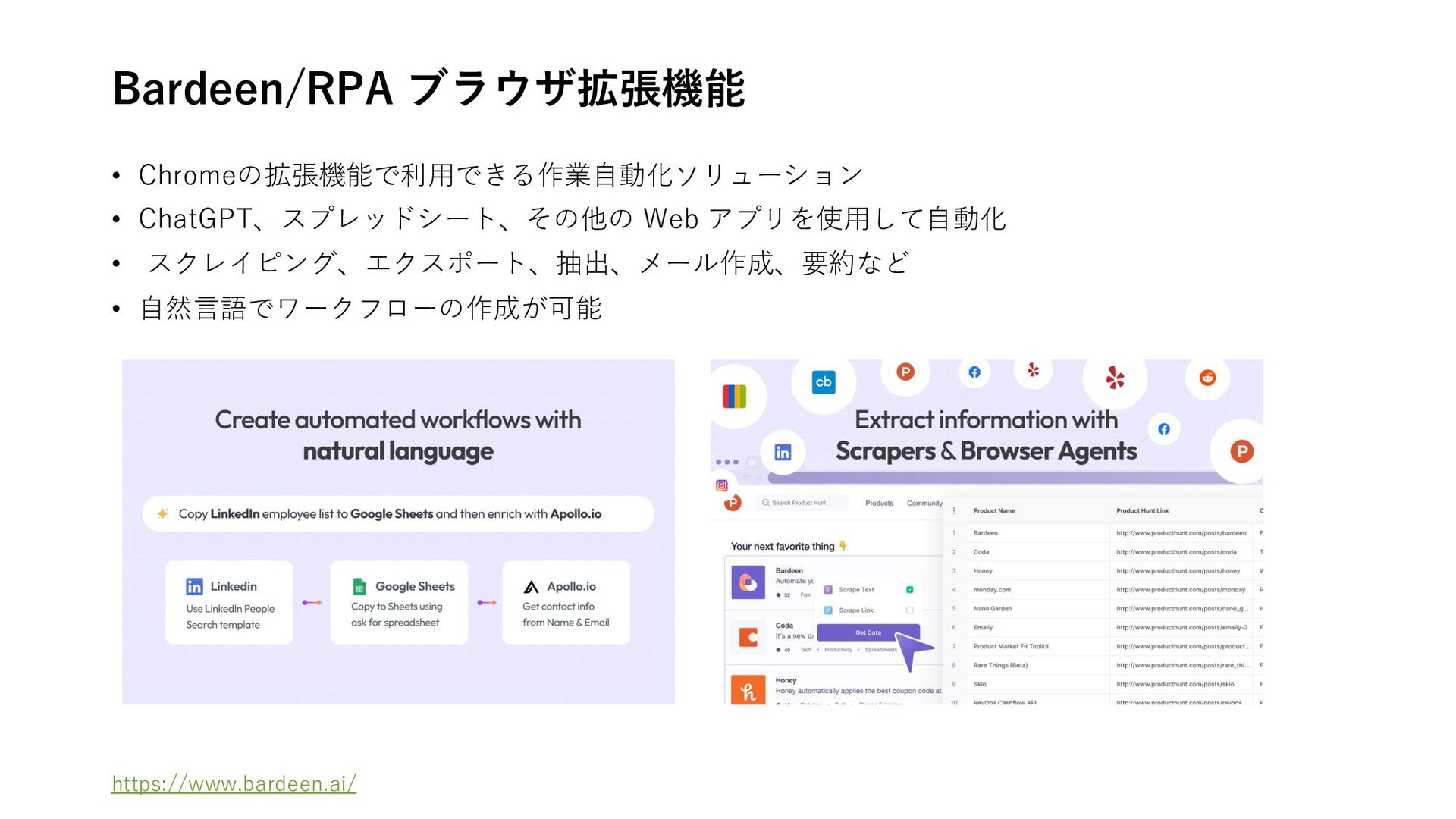
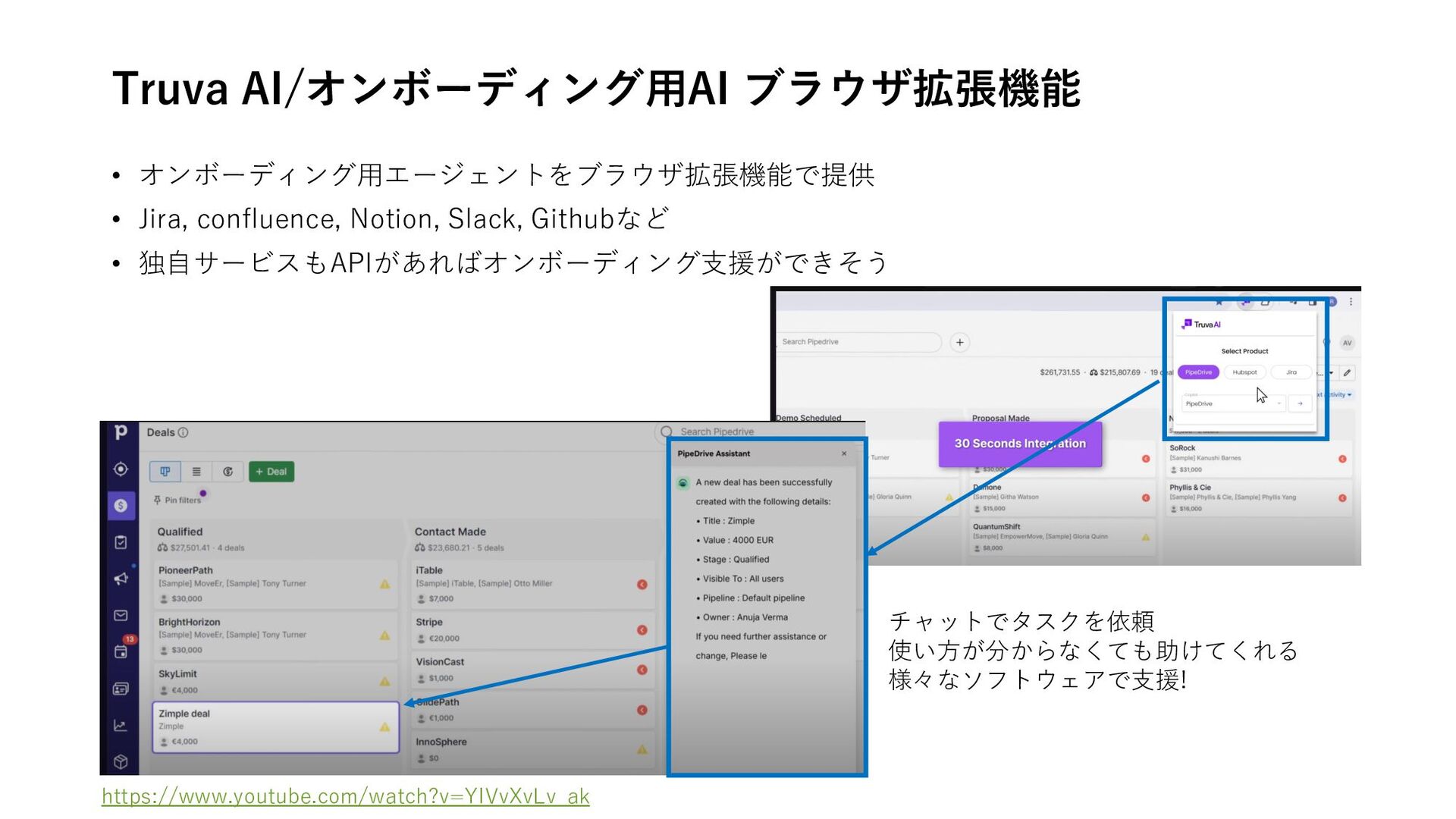
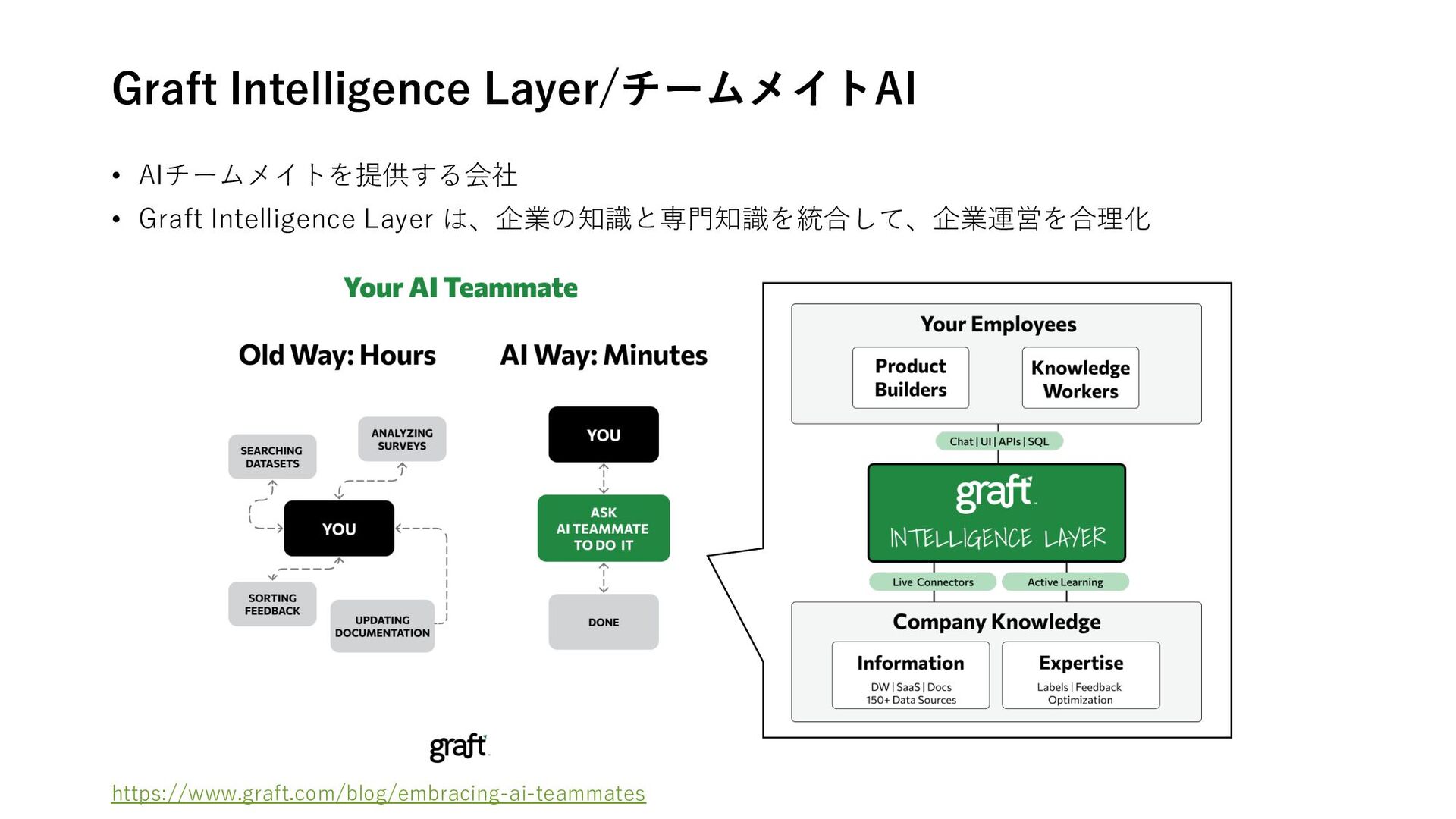
LangSmith is now in Azure Marketplace • What is an Enterprise AI Agent? 海外ベンチャー企業 • Magical AI/RPA ブラウザ拡張機能 • Bardeen /RPA ブラウザ拡張機能 • ELEVENTH AI /RPAワークフロー⾃動化 • Truva AI/オンボーディング⽤AI ブラウザ拡張機能 • Graft Intelligence Layer/チームメイトAI • Kin /メモリに基づくパーソナライズAI • Sema4.ai/エンタープライズ向けGPTs
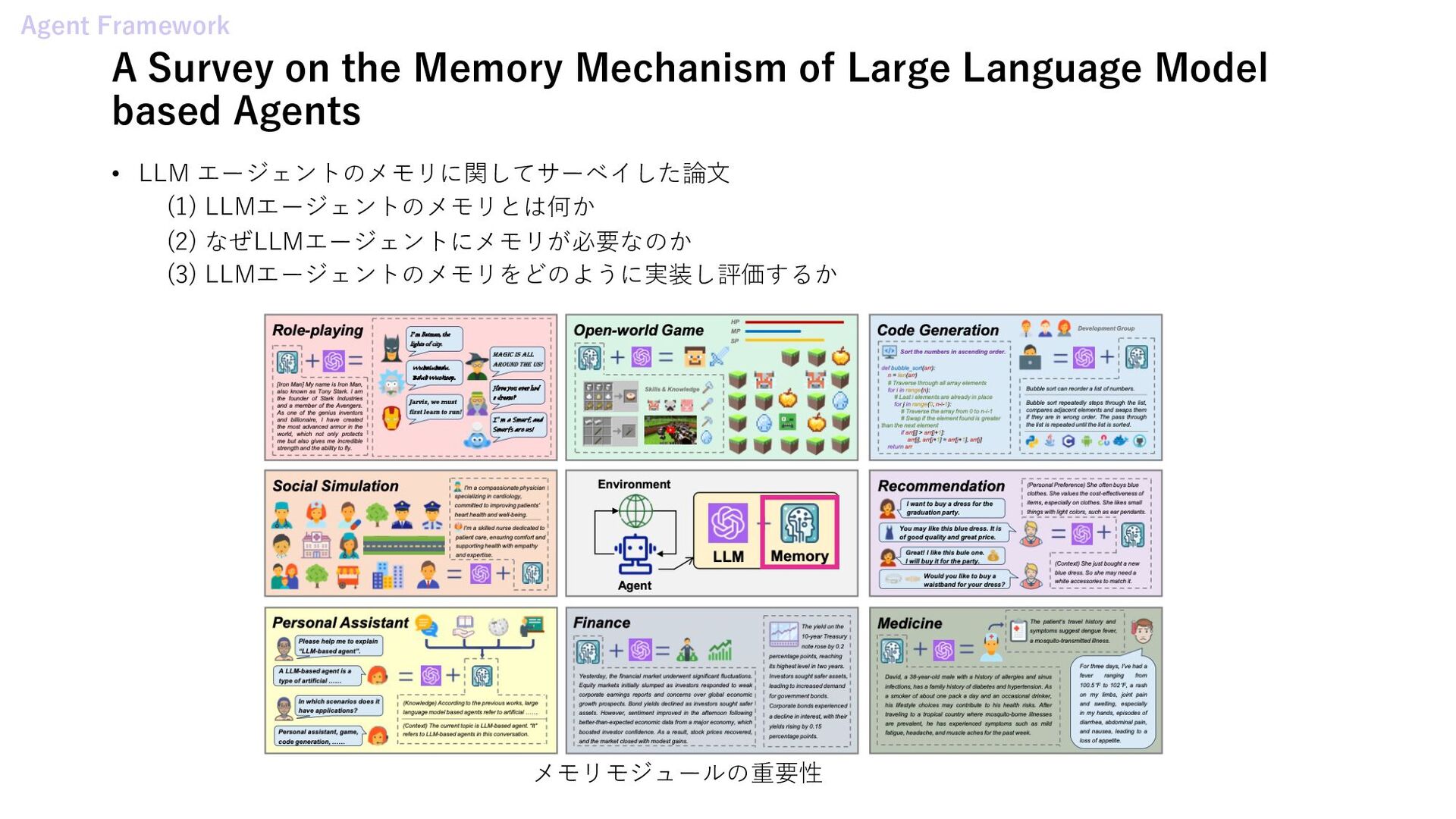
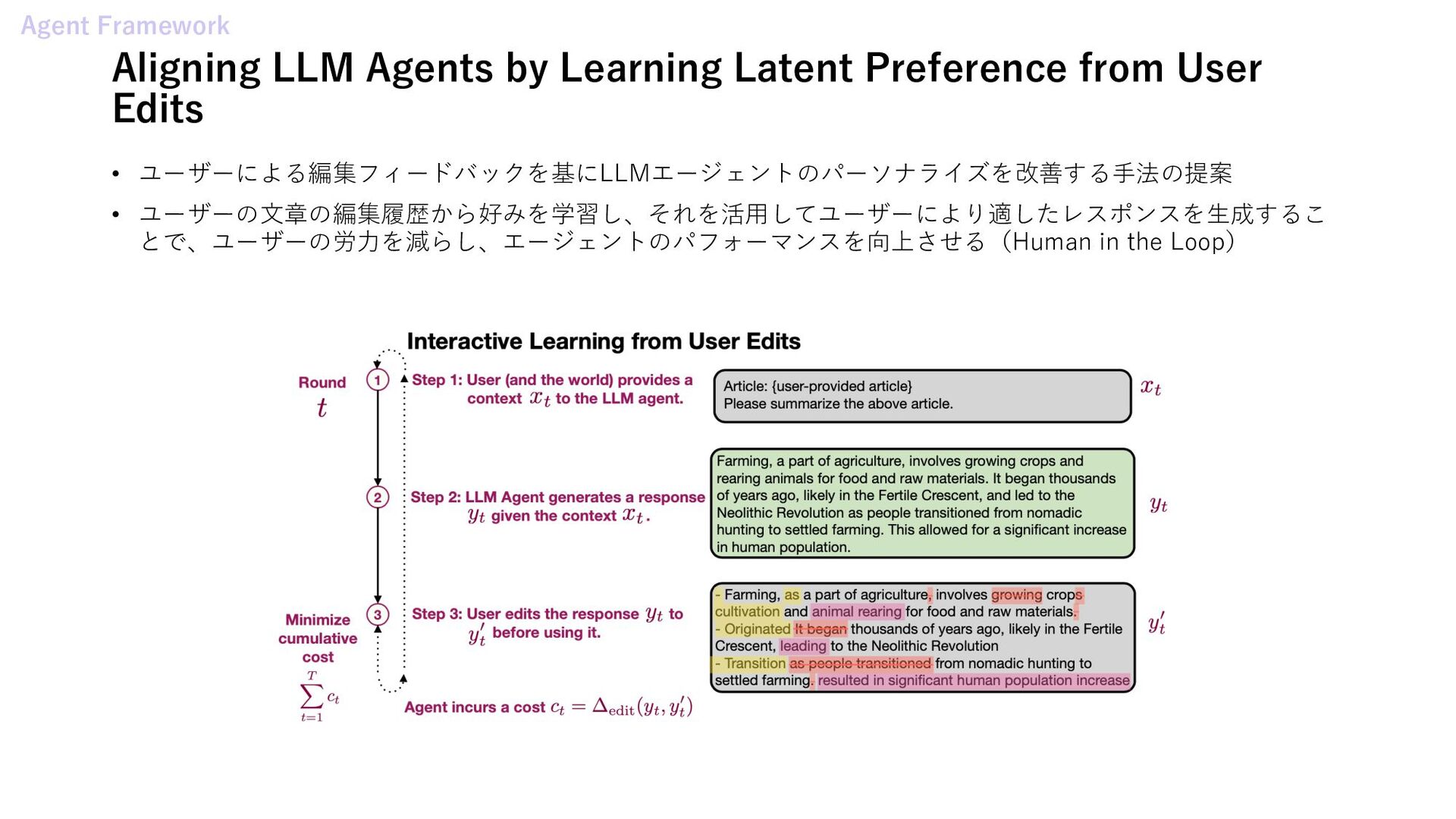
Mechanism of Large Language Model based Agents • Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs • GPT in Sheep's Clothing: The Risk of Customized GPTs • The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions • Aligning LLM Agents by Learning Latent Preference from User Edits • AgentKit: Flow Engineering with Graphs, not Coding Agentic AI Systems • CT-Agent: Clinical Trial Multi-Agent with Large Language Model-based Reasoning • Automated Social Science: Language Models as Scientist and Subjects∗ • A Multimodal Automated Interpretability Agent Multi Agent Systems • NegotiationToM: A Benchmark for Stress-testing Machine Theory of Mind on Negotiation Surrounding • AgentCoord: Visually Exploring Coordination Strategy for LLM-based Multi-Agent Collaboration • Cooperate or Collapse: Emergence of Sustainability Behaviors in a Society of LLM Agents
• ユーザーによる編集フィードバックを基にLLMエージェントのパーソナライズを改善する⼿法の提案 • ユーザーの⽂章の編集履歴から好みを学習し、それを活⽤してユーザーにより適したレスポンスを⽣成するこ とで、ユーザーの労⼒を減らし、エージェントのパフォーマンスを向上させる(Human in the Loop) Agent Framework
• ⼈間でもできる作業だが⾯倒なため、エージェントに代替 デモサイトあり:https://multimodal-interpretability.csail.mit.edu/maia/ 質問例 「特定のニューロンを活性化させる画像を教えて!」 「モデルのバイアスを教えて!」 MAIA Agentic AI Systems
• Agents for Amazon bedrock 機能紹介 4/23アップデート含む 海外のベンチャー企業 • Introducing Dify Workflow • Dify.AI Unveils AI Agent: Creating GPTs and Assistants with Various LLMs • Bland AI/Phone Agents • NEXUS/NexusGPT • PaddleBoat • Intrvu SPACE/Interview Agent • Alpha Corp/Group Chat With AIs コラム • The UX of AI: Lessons from Perplexity • The Rise and Fall of (Autonomous) Agents
できる • ⽂字起こし、⾔語理解、テキスト読み上げモデルの組み合わせも 1 秒以内に実⾏する • 1秒以内レスポンスに向けてモデル以外にもプロンプトを⼯夫する • 電話エージェントの⼈物像、応答すべき質問の種類、応答すべきでない質問の種類、誰かが電話エージェントを脱獄しよ うとした場合の対処⽅法を記載 https://www.bland.ai/blog/how-to-build-an-ai-call-center How to build an AI Call Center( April 7, 2024 ) 電話の内容を別のツールと接続可能
Model based Agents • Foundational Challenges in Assuring Alignment and Safety of Large Language Models • ChatShop: Interactive Information Seeking with Language Agents • Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models • Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing • The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey Multi Agent Systems • Confidence Calibration and Rationalization for LLMs via Multi-Agent Deliberation Computer Controlled Agents • MMInA: Benchmarking Multihop Multimodal Internet Agents
a Runtime for Autonomous LLM Applications • AI2Apps: A Visual IDE for Building LLM-based AI Agent Applications • Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought • Graph of Thoughts: Solving Elaborate Problems with Large Language Models Agentic AI Systems • ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models • AutoCodeRover: Autonomous Program Improvement Multi Agent Systems • 360°REA: Towards A Reusable Experience Accumulation with 360° Assessment for Multi-Agent System Computer Controlled Agents • OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments • Autonomous Evaluation and Refinement of Digital Agents
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
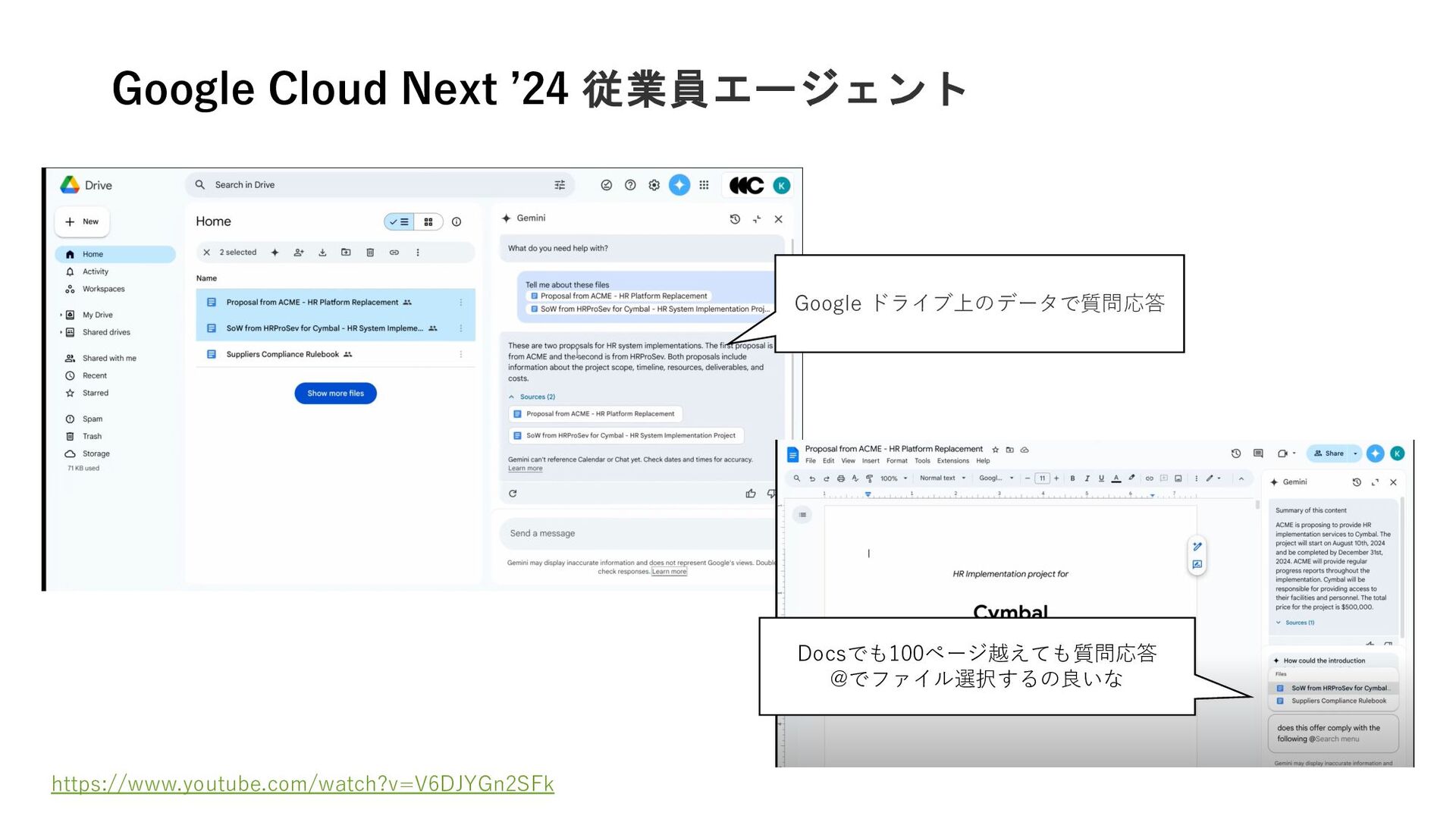{kind=link}
{kind=link}
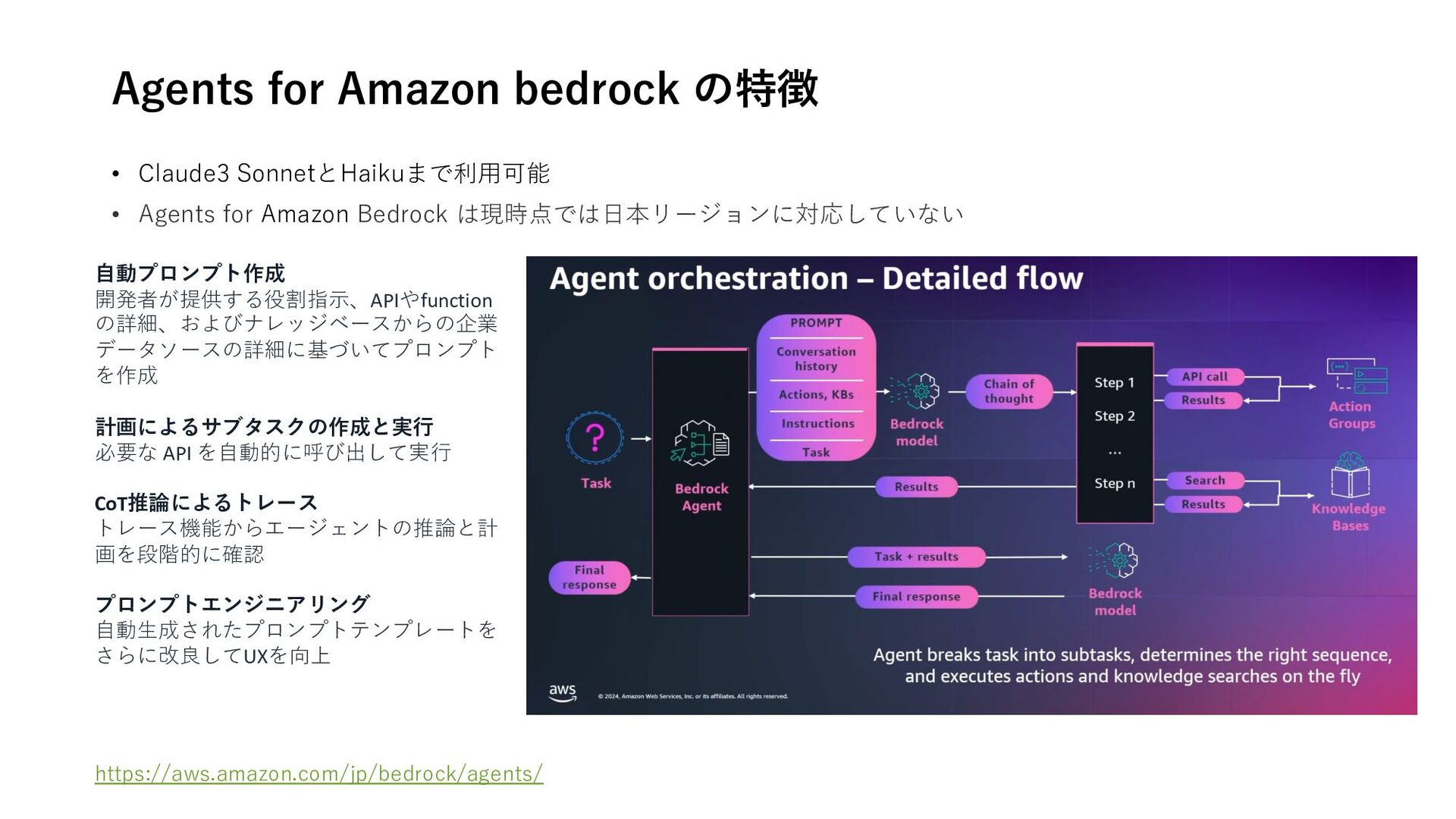{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}