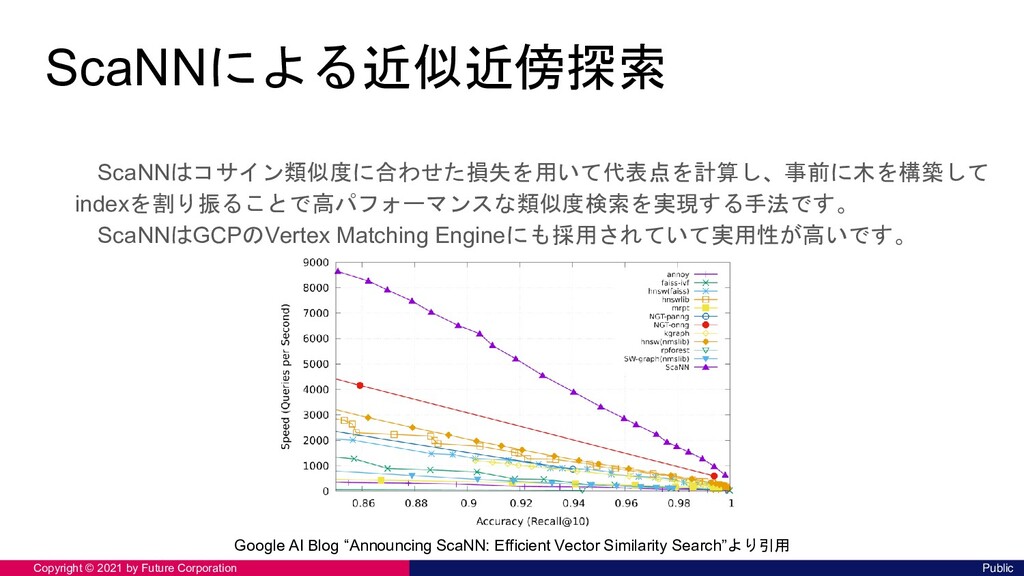
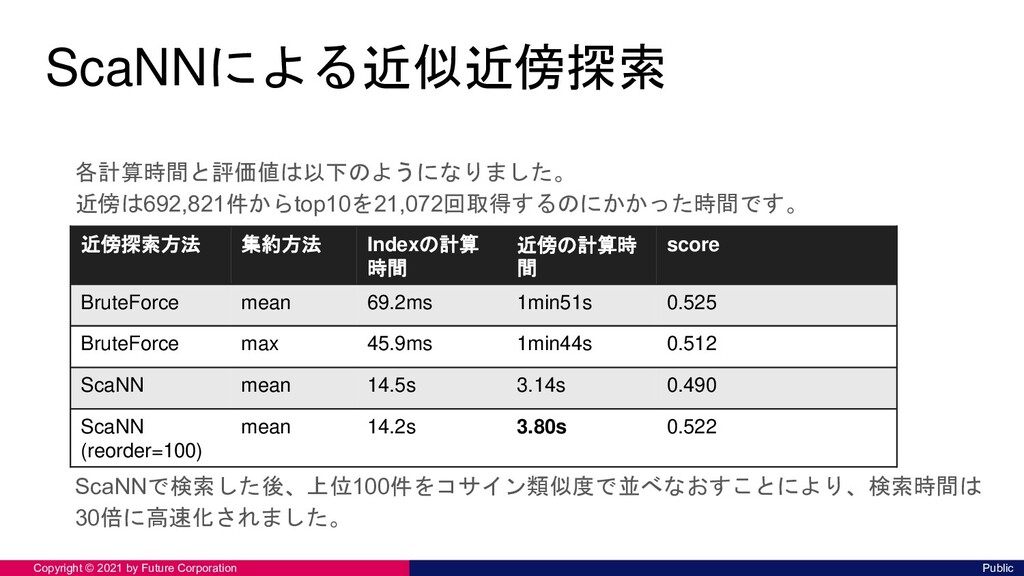
実際についていたタグ 推薦したタグ "GoのORマッパー連載を始めます " [Go, ORM, インデックス] [インデックス, Go, GoTips連載, サ ブスクリプション, Zuora] "Go1.17における go get の変更点 " [Go, Go1.17] [Go1.16, Makefile, Go, GoTips連 載, 設計] "Sesame3にICカード施錠/解錠機 能を実装してみた with Go & Python" [Go, Python, SESAME3, RaspberryPi] [S3, 登壇レポート, GitHubActions, CI/CD, Glue] “エキスパートPythonプログラミン グ改3版が出版されました” [Python, 書籍, 出版] [Python, 書籍, 出版, 登壇レポート, Java] "Adobe XDからFlutterに変換する " [AdobeXD, Flutter] [Flutter, Dart, モバイルアプリ, ケ ンオール, Proxy]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}