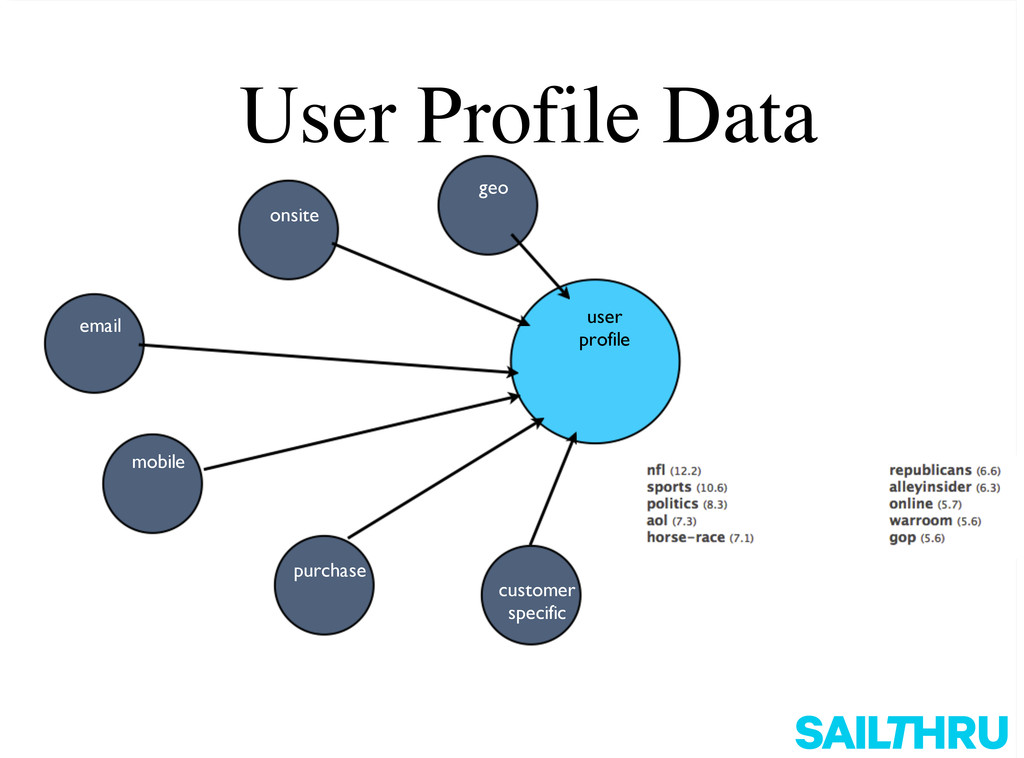
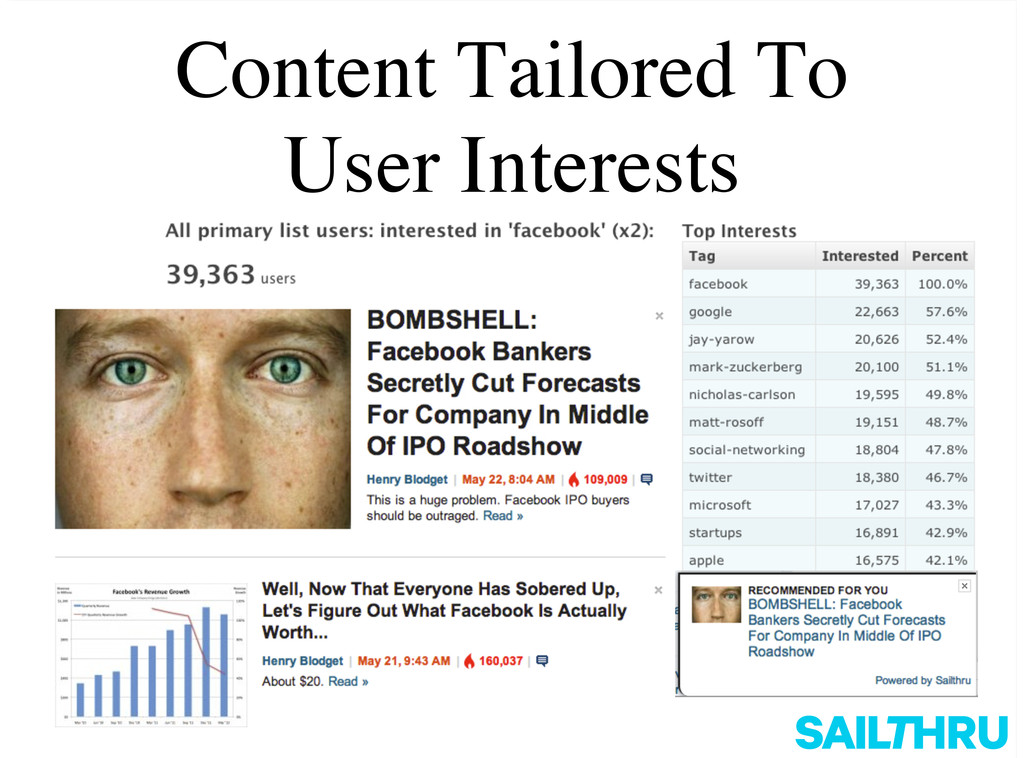
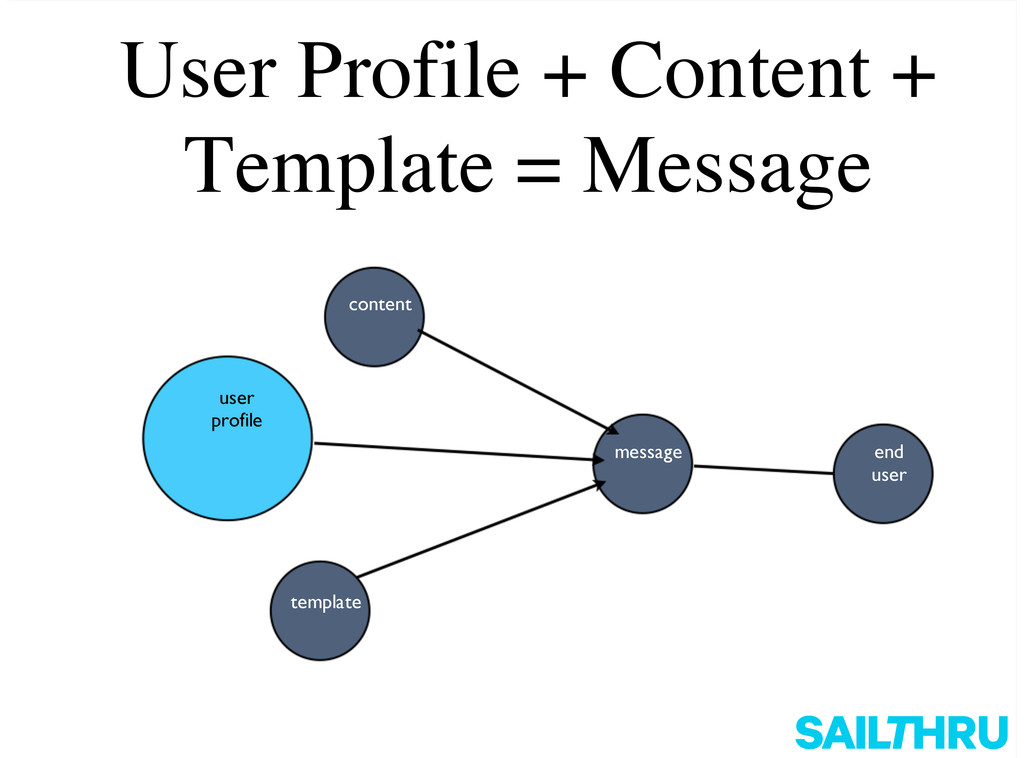
MongoNYC 2012: Two Years of MongoDB at Sailthru: Scaling and Design, Ian White, Sailthru. Sailthru is a behavioral communication and analytics platform focusing on email, onsite, and mobile personalization. Sailthru stores terabytes of data for hundreds of millions of end users and billions of messages, all in MongoDB. Since we presented last year, we've had 10x growth and experienced lots of challenges scaling on AWS. We've learned lots of lessons about building and designing for MongoDB at scale, and we'll share them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Looking for a job? [email protected] @eonwhite](https://files.speakerdeck.com/presentations/4fbf9f58ec4c24001f0229ed/slide_38.jpg){kind=link}