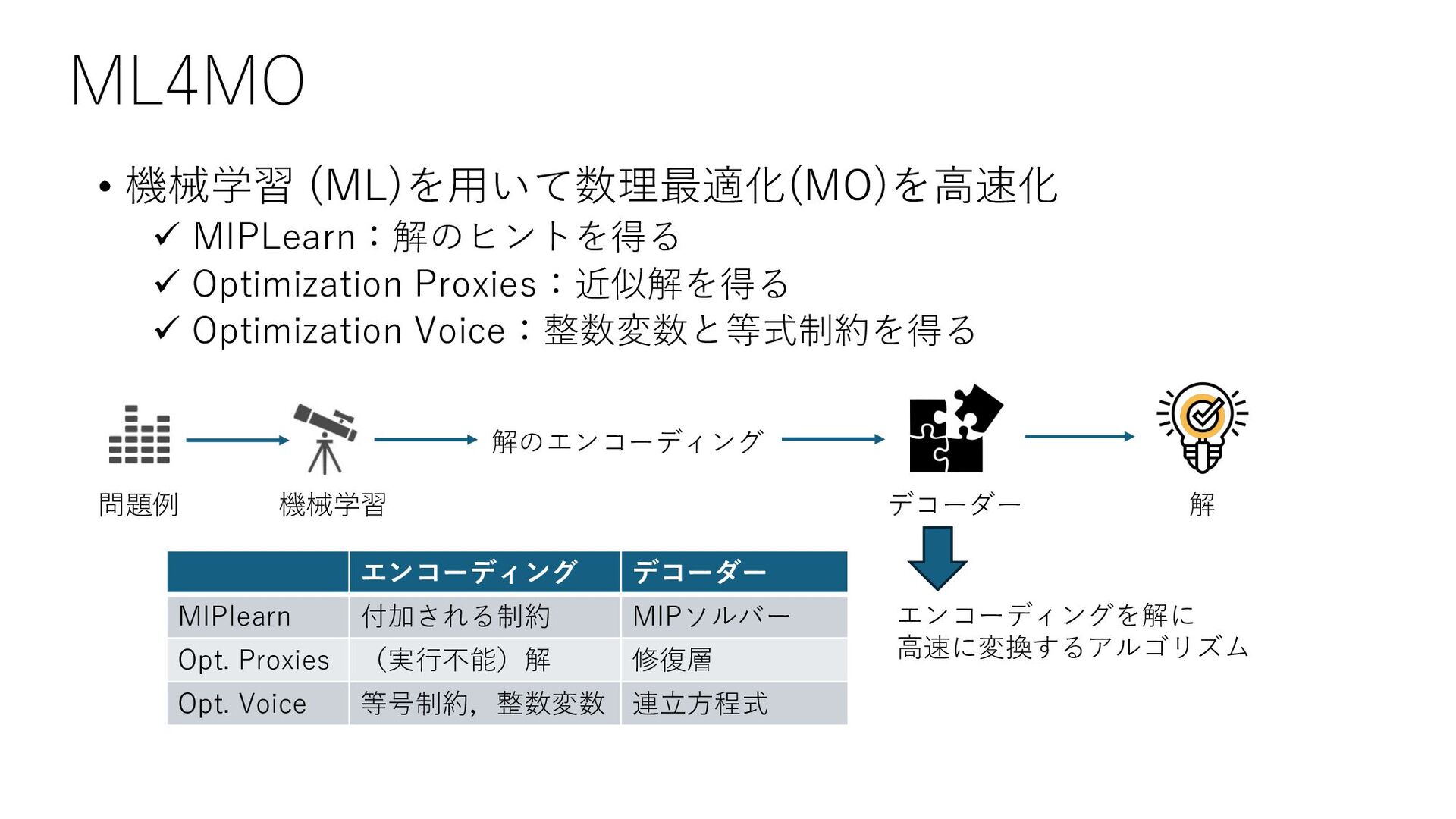
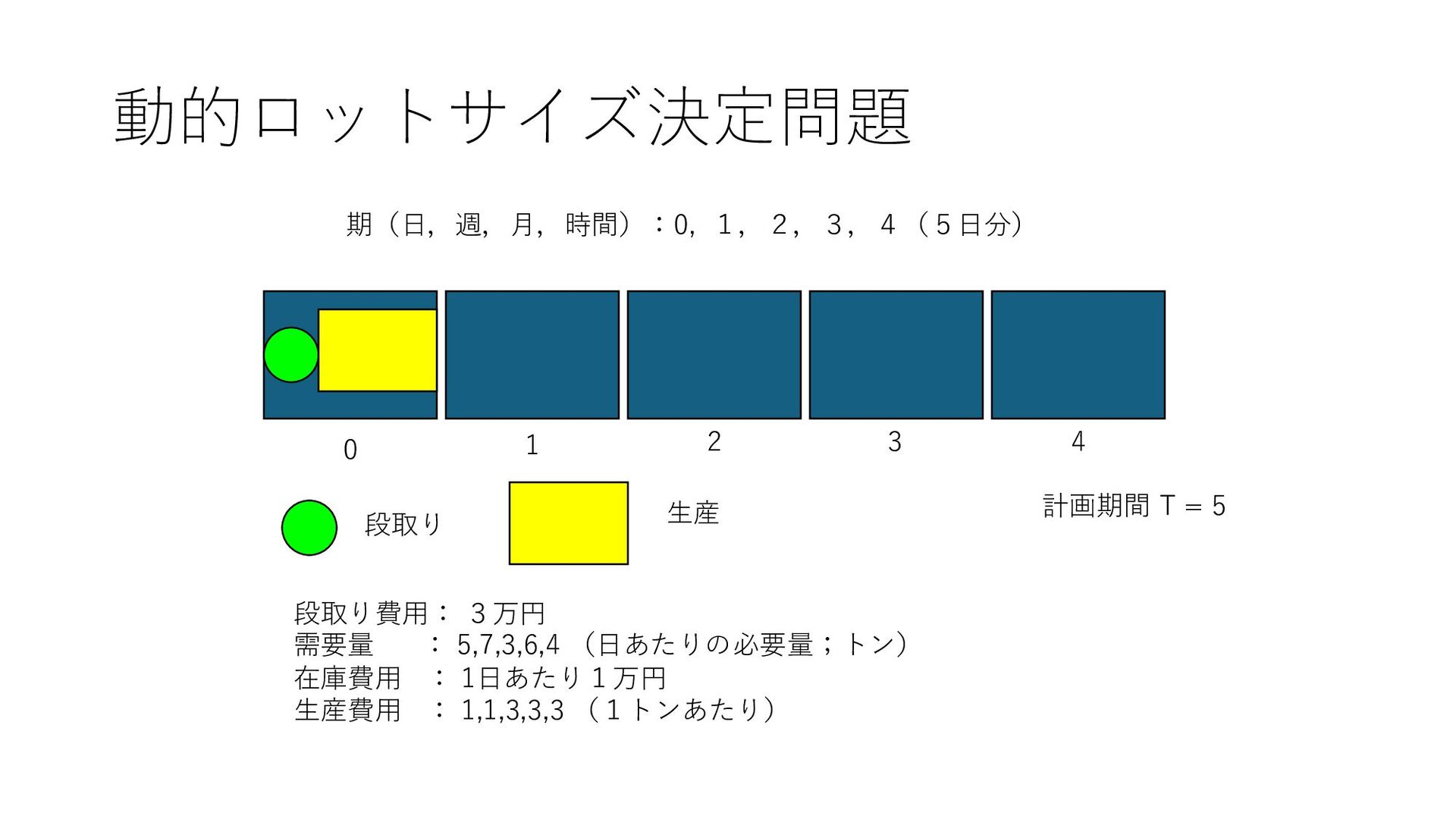
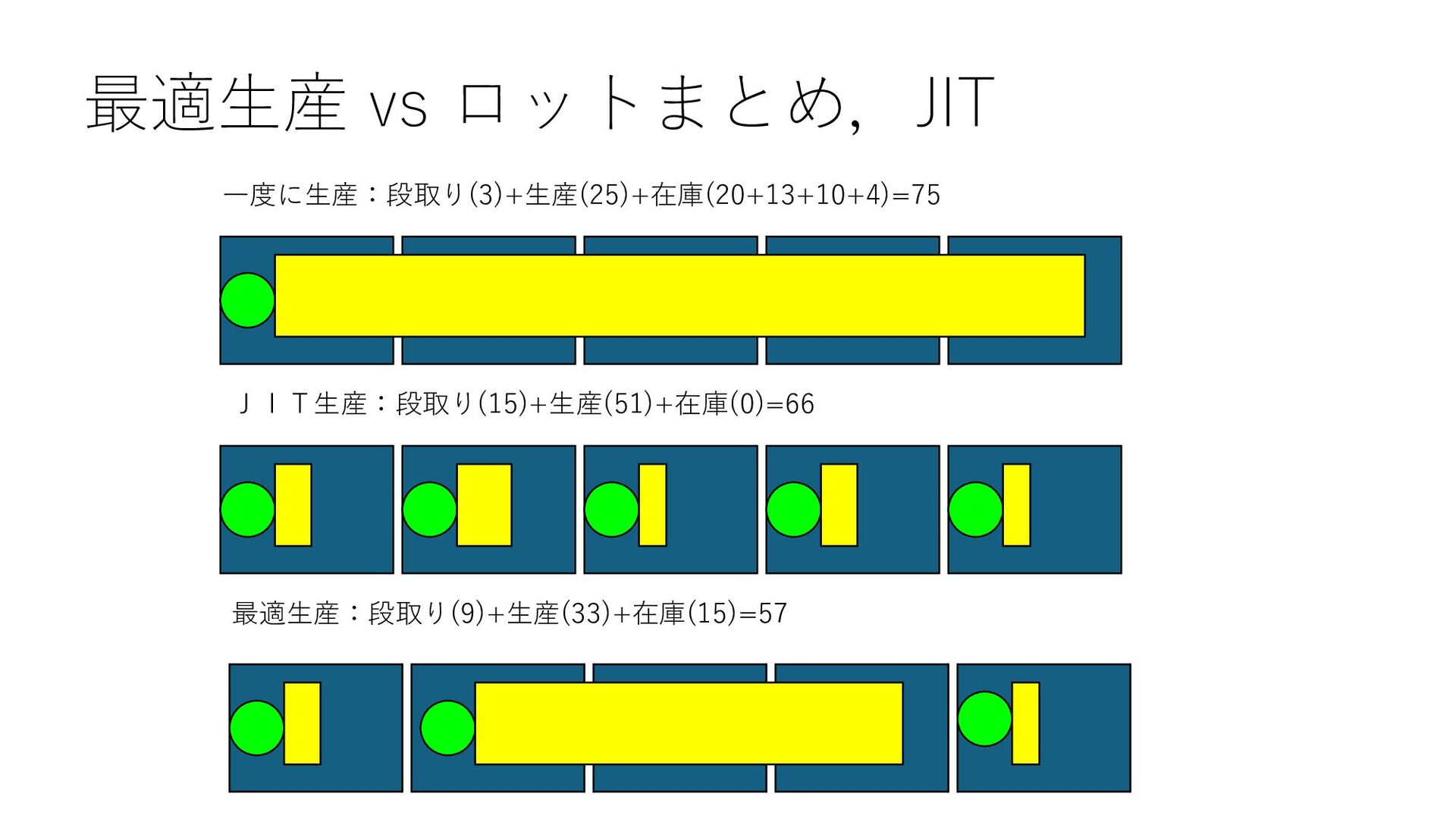
8., 4., ..., 1., 3., 3.], [5., 9., 5., ..., 3., 8., 7.], ..., [2., 9., 2., ..., 6., 2., 6.], [7., 4., 6., ..., 6., 7., 2.], [1., 2., 4., ..., 7., 6., 7.]]) サンプル数 × T k-近傍 array([[1, 1, 1, ..., 0, 1, 1], [1, 1, 1, ..., 1, 0, 1], [1, 1, 0, ..., 0, 1, 0], ..., [1, 1, 1, ..., 0, 0, 1], [1, 0, 1, ..., 0, 1, 0], [1, 0, 1, ..., 1, 0, 1]]) 段取りデータ サンプル数 × T 機械学習 訓練データ [6., 4., 6., ..., 6., 7., 2.] テストデータ [1, 0, 1, ..., 0, 0, 1], [1, 0, 1, ..., 1, 1, 0], [1, 0, 1, ..., 1, 0, 1] テストデータに近い k 個の サンプル需要に対する最適解 段取り頻度が⼤きいものは 1 に固定 ⼩さいものは0に固定 ソルバーで求解
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MIPLearnの適⽤ 需要データ array([[1., 6., 8., ..., 8., 7., 5.], [1.,](https://files.speakerdeck.com/presentations/717c6eb167e44c76aa1a97af3fb62a47/slide_8.jpg){kind=link}
{kind=link}