Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PRML Chapter 1 (1.3-1.6)
Search
shogo-d-nakamura
November 01, 2023
Science
1
370
PRML Chapter 1 (1.3-1.6)
PRML, Pattern Recognition and Machine Learning
chapter 1
shogo-d-nakamura
November 01, 2023
Tweet
Share
More Decks by shogo-d-nakamura
See All by shogo-d-nakamura
Deep Learning Chapter 7
snkmr
0
64
PRML Chapter 9
snkmr
1
320
PRML Chapter 5 (5.0-5.4)
snkmr
1
490
PRML Chapter 8 (8.0-8.3)
snkmr
1
350
PRML Chapter 11 (11.0-11.2)
snkmr
1
420
Other Decks in Science
See All in Science
Lean4による汎化誤差評価の形式化
milano0017
1
430
機械学習 - SVM
trycycle
PRO
1
980
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.1k
20251212_LT忘年会_データサイエンス枠_新川.pdf
shinpsan
0
230
高校生就活へのDA導入の提案
shunyanoda
1
6.2k
Text-to-SQLの既存の評価指標を問い直す
gotalab555
1
170
データから見る勝敗の法則 / The principle of victory discovered by science (open lecture in NSSU)
konakalab
1
270
生成検索エンジン最適化に関する研究の紹介
ynakano
2
2k
2025-05-31-pycon_italia
sofievl
0
140
中央大学AI・データサイエンスセンター 2025年第6回イブニングセミナー 『知能とはなにか ヒトとAIのあいだ』
tagtag
PRO
0
120
Algorithmic Aspects of Quiver Representations
tasusu
0
190
主成分分析に基づく教師なし特徴抽出法を用いたコラーゲン-グリコサミノグリカンメッシュの遺伝子発現への影響
tagtag
PRO
0
180
Featured
See All Featured
Building a Modern Day E-commerce SEO Strategy
aleyda
45
8.7k
Building Adaptive Systems
keathley
44
2.9k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
1.6k
Un-Boring Meetings
codingconduct
0
200
Claude Code のすすめ
schroneko
67
210k
Done Done
chrislema
186
16k
Context Engineering - Making Every Token Count
addyosmani
9
660
So, you think you're a good person
axbom
PRO
2
1.9k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
760
Optimizing for Happiness
mojombo
379
71k
Bash Introduction
62gerente
615
210k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
410
Transcript
2023/04/28 D2 中村 Chapter 1 後半
目次 2 1.1 多項式曲線フィッティング 11.5.1 誤識別率の最小化 1.2 確率論 1.3 モデル選択
1.4 次元の呪い 1.5 決定理論 1.6 情報理論 11.5.2 期待損失の最小化 11.5.3 棄却オプション 11.5.4 推論と決定 11.5.5 回帰のための損失関数 11.6.1 相対エントロピーと相互情報量
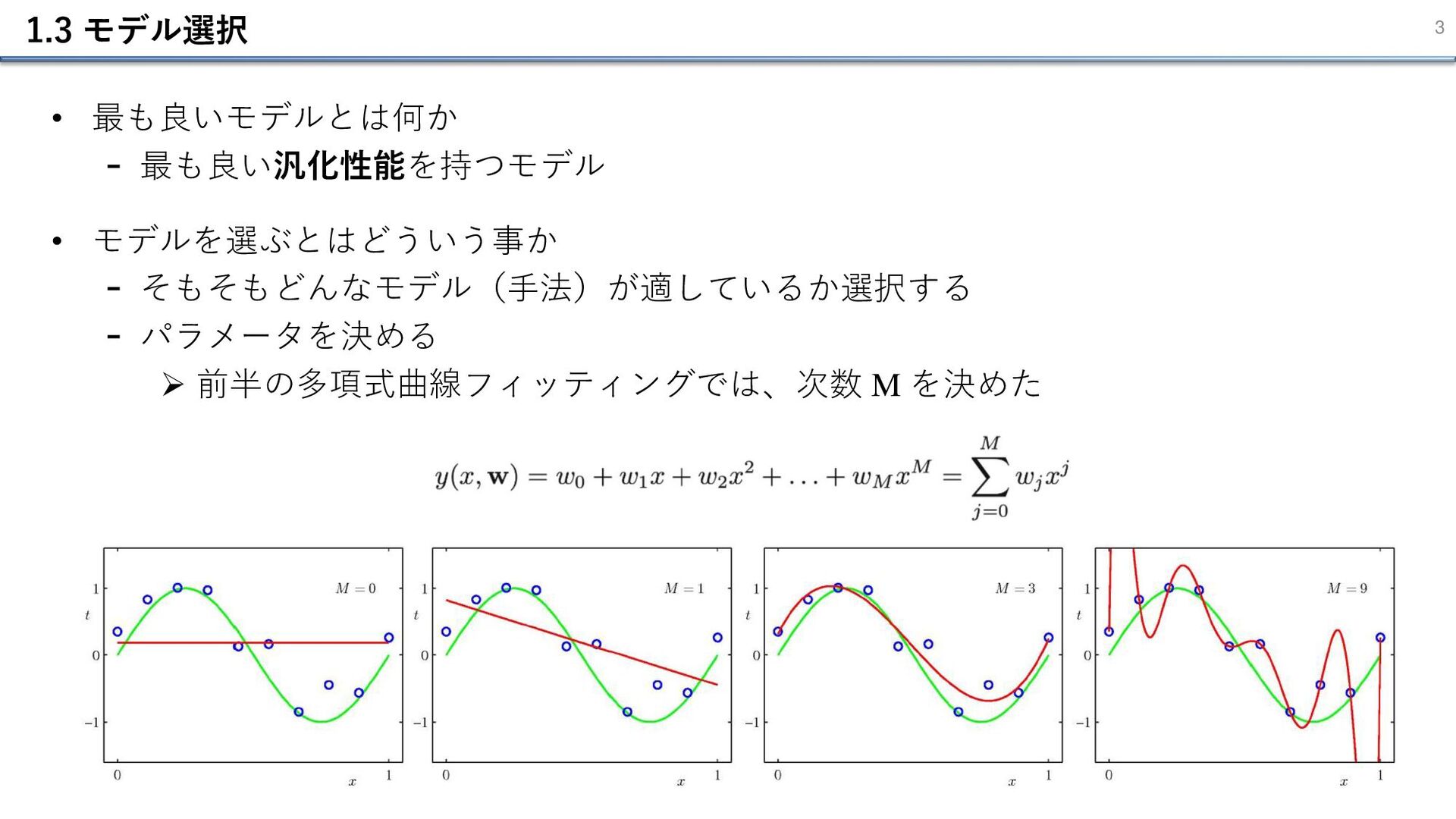
1.3 モデル選択 3 • 最も良いモデルとは何か - 最も良い汎化性能を持つモデル • モデルを選ぶとはどういう事か -
そもそもどんなモデル(手法)が適しているか選択する - パラメータを決める ➢ 前半の多項式曲線フィッティングでは、次数 M を決めた
1.3 モデル選択 4 • モデルの汎化性能を評価する - 訓練データを使って最尤推定するだけだと、過学習する場合がある - train, validation
にデータを分割し、訓練したモデルを評価する - 限られたサイズのデータ集合だと、validation データに過学習してしまう ➢ 最終的な評価のために test データをあらかじめ用意しておく • (train / valid / test の比率はタスクやデータサイズによって異なる) • (自分が使っているUSPTO dataset は 8.5 / 0.06 / 0.08)
1.3 モデル選択 5 • 交差検証(cross-validation) - 多くの場合、訓練データをできるだけ多く確保したい - しかし、validation データが少なすぎると予測性能の推定誤差が大きくなる
➢データをS個に分割し、S-1個を訓練に使い、残りの1個をvalidationに使う - ただし、訓練に必要な計算量が多い場合は現実的ではない - 訓練回数がSに比例して増える - S=4 の場合は図のような感じ→ • LOO 法 (Leave-one-out method) - cross-validation で、S=Nの時を特にLOO法と呼ぶ。 - test 用に1個だけデータを抜き取り、N-1個のデータで訓練する ←train ←validation 図 1.18
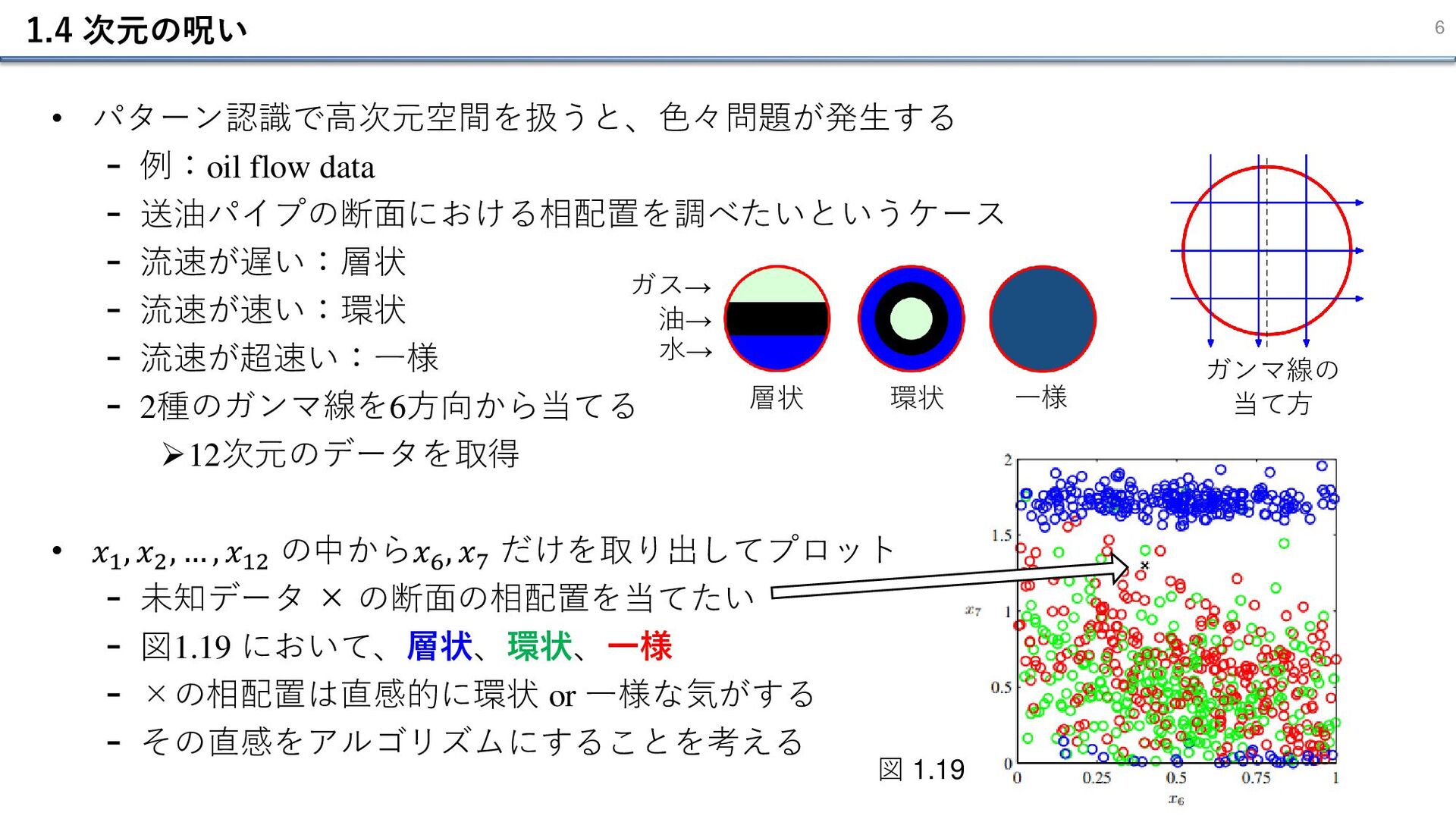
1.4 次元の呪い 6 • パターン認識で高次元空間を扱うと、色々問題が発生する - 例:oil flow data -
送油パイプの断面における相配置を調べたいというケース - 流速が遅い:層状 - 流速が速い:環状 - 流速が超速い:一様 - 2種のガンマ線を6方向から当てる ➢12次元のデータを取得 • 𝑥1 , 𝑥2 , … , 𝑥12 の中から𝑥6 , 𝑥7 だけを取り出してプロット - 未知データ × の断面の相配置を当てたい - 図1.19 において、層状、環状、一様 - ×の相配置は直感的に環状 or 一様な気がする - その直感をアルゴリズムにすることを考える 層状 環状 一様 水→ 油→ ガス→ ガンマ線の 当て方 図 1.19
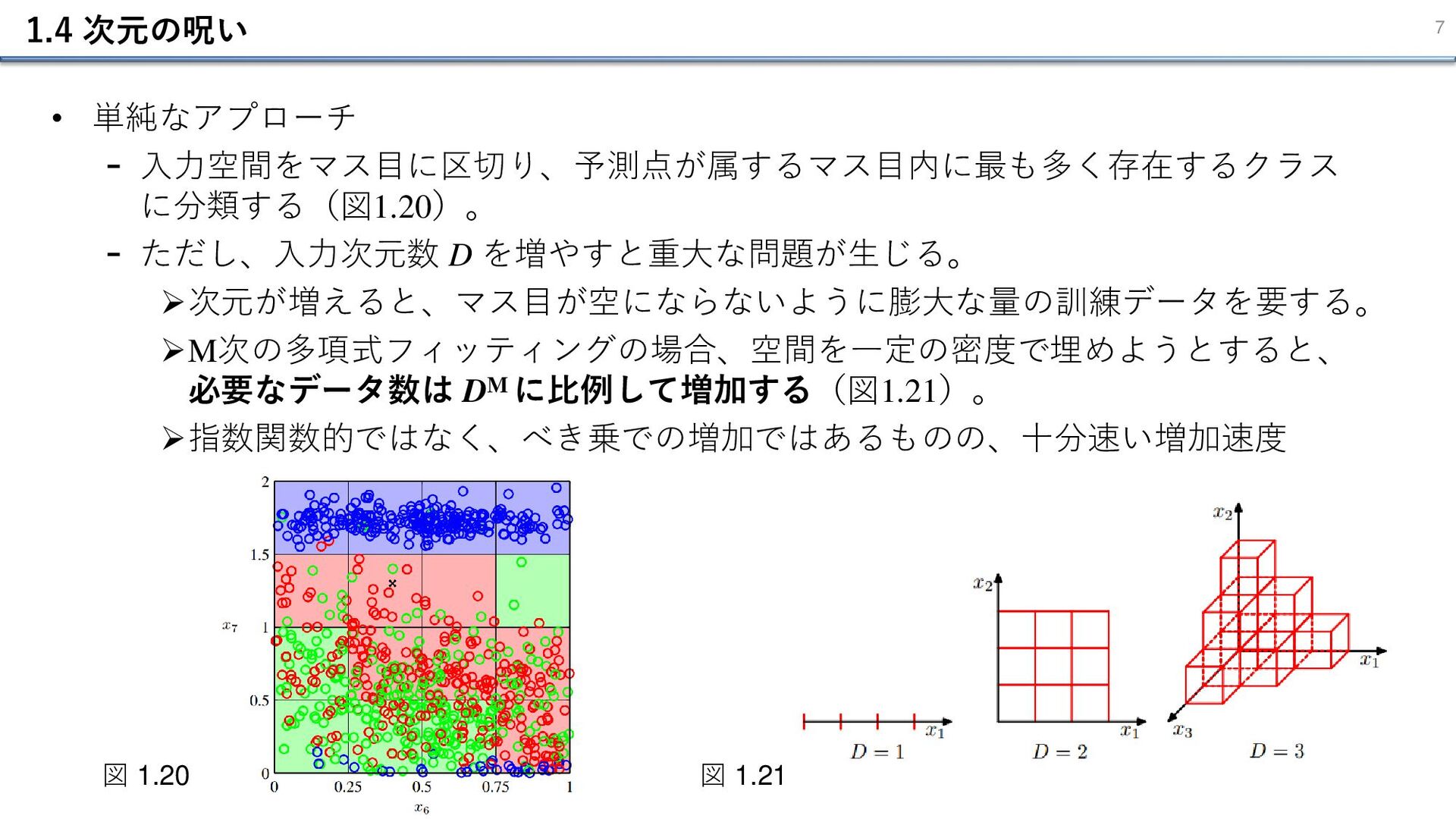
1.4 次元の呪い 7 • 単純なアプローチ - ⼊⼒空間をマス⽬に区切り、予測点が属するマス⽬内に最も多く存在するクラス に分類する(図1.20)。 - ただし、⼊⼒次元数
D を増やすと重大な問題が生じる。 ➢次元が増えると、マス⽬が空にならないように膨大な量の訓練データを要する。 ➢M次の多項式フィッティングの場合、空間を一定の密度で埋めようとすると、 必要なデータ数は DM に比例して増加する(図1.21)。 ➢指数関数的ではなく、べき乗での増加ではあるものの、十分速い増加速度 図 1.20 図 1.21
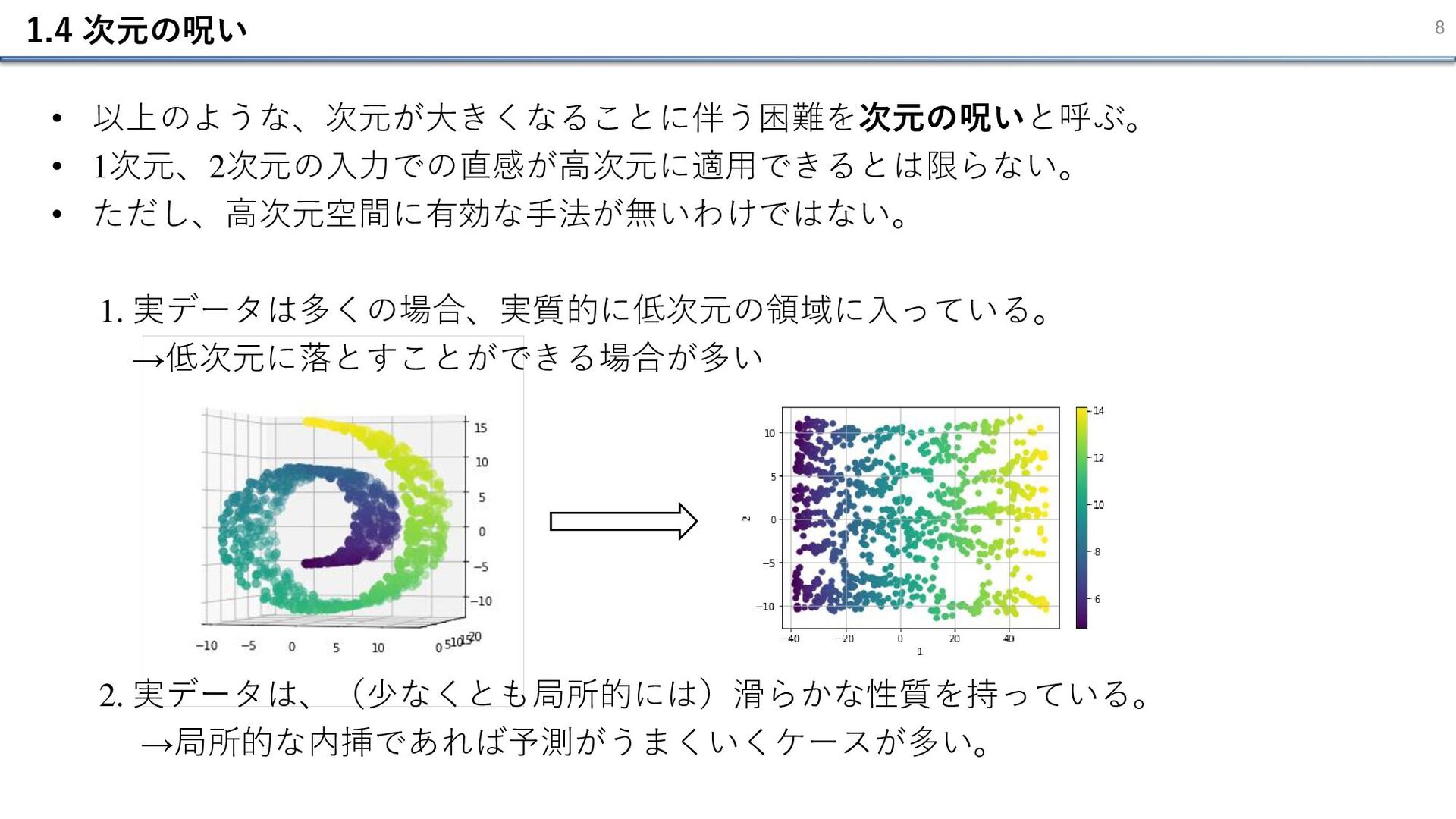
1.4 次元の呪い 8 • 以上のような、次元が大きくなることに伴う困難を次元の呪いと呼ぶ。 • 1次元、2次元の⼊⼒での直感が高次元に適用できるとは限らない。 • ただし、高次元空間に有効な手法が無いわけではない。 1.
実データは多くの場合、実質的に低次元の領域に⼊っている。 →低次元に落とすことができる場合が多い 2. 実データは、(少なくとも局所的には)滑らかな性質を持っている。 →局所的な内挿であれば予測がうまくいくケースが多い。
1.5 決定理論 9 • §1.2 確率論で、不確実性を定量化するための数学的枠組みを扱った。 • §1.5 決定理論では、不確かさを含む状況で意思決定を行う枠組みを扱う。 •
推論 - ⼊⼒ベクトル 𝑥 と⽬標変数 𝑡 があるとき、同時確率分布 𝑝(𝑥, 𝑡) を求めること - 推論の後に、求めた 𝑝(𝑥, 𝑡) から意思決定を行う • 決定 - ある基準を設けて、どの行動を起こすかを選択する - 決定理論の主題 - 推論が解けていれば、決定は一般に単純
1.5 決定理論 10 • 例:医療診断問題 • ⼊⼒ 𝐱 :患者のX線画像のピクセル行列 •
⽬標変数 𝑡 :癌 or 癌じゃない を表すクラス, 𝐶𝑘 • 新たな画像 𝐱 が与えられた時、各クラスに割り当てられる確率は、ベイズの定理により 以下のように記述される。 𝑝 𝐶𝑘 𝐱 = 𝑝 𝐱 𝐶𝑘 𝑝 𝐶𝑘 𝑝(𝐱) 1.77 • (1.77) に現れる量は、全て 𝑝(𝐱, 𝐶𝑘 ) から計算できる。 - 𝑝 𝐱 𝐶𝑘 𝑝 𝐶𝑘 = 𝑝(𝐱, 𝐶𝑘 ) (乗法定理) - 𝑝 𝐱 = σ𝑘 𝑝(𝐱, 𝐶𝑘 ) (周辺化) • 誤ったクラスに分類する可能性を最小にしたい - 直感的には事後確率 𝑝 𝐶𝑘 𝐱 が高いほうのクラスを選べば良さそう。 - 決定理論では、この直感が正しい事を示す。
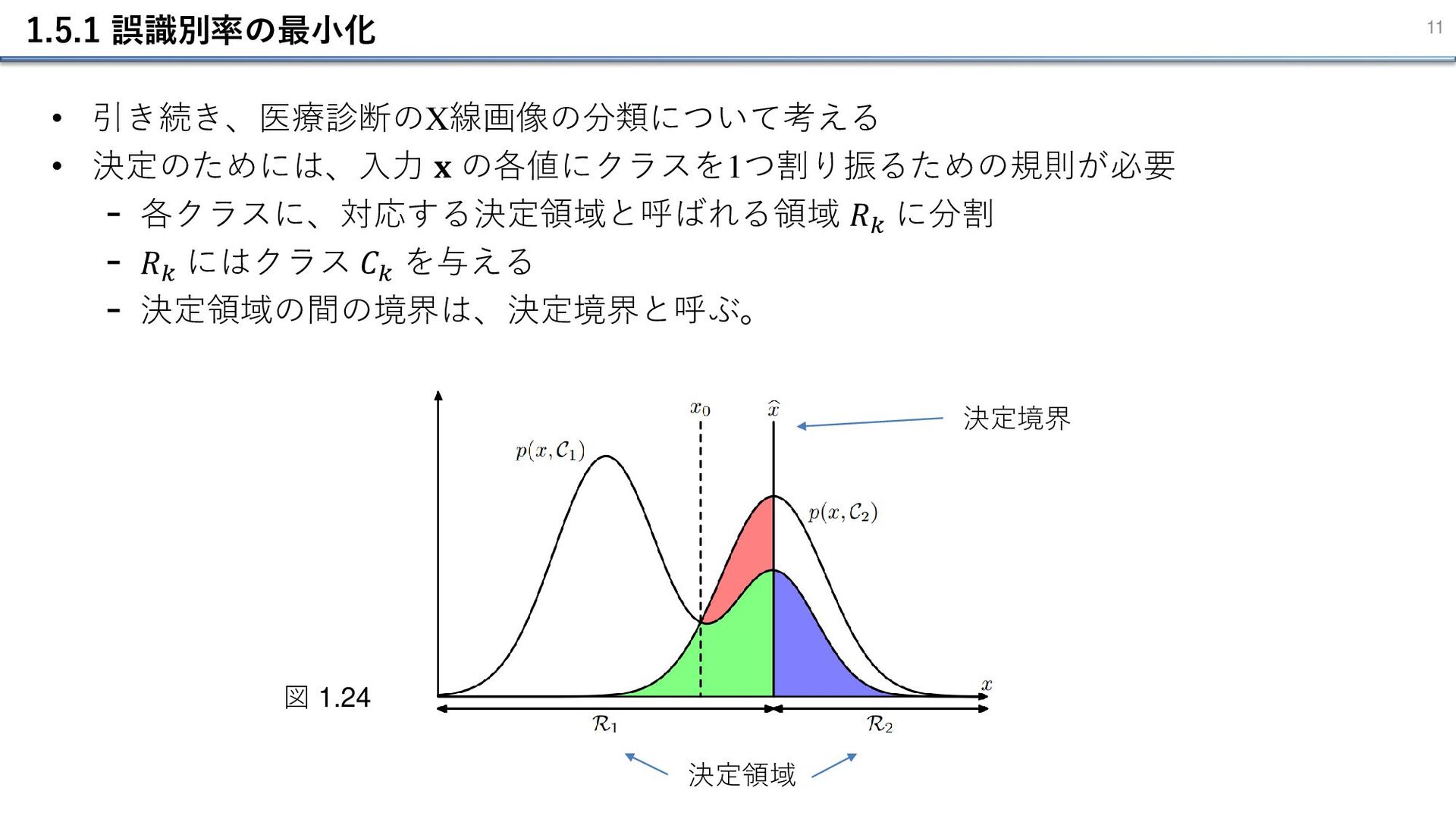
1.5.1 誤識別率の最小化 11 • 引き続き、医療診断のX線画像の分類について考える • 決定のためには、⼊⼒ 𝐱 の各値にクラスを1つ割り振るための規則が必要 -
各クラスに、対応する決定領域と呼ばれる領域 𝑅𝑘 に分割 - 𝑅𝑘 にはクラス 𝐶𝑘 を与える - 決定領域の間の境界は、決定境界と呼ぶ。 図 1.24 決定領域 決定境界
1.5.1 誤識別率の最小化 12 • 誤識別が起きる確率 𝑝(mistake) は以下の式で表される。 図 1.24 𝑝
𝐱, 𝐶2 > 𝑝(𝐱, 𝐶1 ) なのに𝐶1 に分類している →誤分類が発生している領域 決定境界が𝑥0 なら、 部分の面積を0にできる。 1.78 • この式を最小にするには、 𝑝 𝐱, 𝐶1 > 𝑝(𝐱, 𝐶2 )のときに 𝐶1 を割り振ればよい 。 • 下図で、最適な決定境界は 𝑥0 の位置
1.5.1 誤識別率の最小化 13 • より一般的なKクラス分類では、誤識別の最小化よりも正解確率の最大化の方が易しい。 1.79 • 前ページ「 𝑝 𝐱,
𝐶1 > 𝑝(𝐱, 𝐶2 ) のときに 𝐶1 を割り振ればよい」 - 𝑝 𝐱, 𝐶𝑘 = 𝑝 𝐶𝑘 𝐱 𝑝 𝐱 (乗法定理) - 𝑝 𝐱 はクラスによらない共通の因子なので、 𝑝 𝐶𝑘 𝐱 が大きい方を選べばよい。 - 資料 p10「直感的には 𝑝 𝐶𝑘 𝐱 が高いほうのクラスを選べば良さそう」が示された。
1.5.2 期待損失の最小化 14 • 実際の応用では,単に誤識別率だけを⾒るのでは⾜りないことが多い - 癌患者を「癌でない」と診断する誤りの方が深刻な結果をもたらす • 損失関数・損失行列を導⼊して、これを定式化できる。 真
の ク ラ ス 予測されたクラス 癌患者を正常と判断した場合 1000倍の重みで損失を与える • 損失行列を𝐿𝑘𝑗 で表す。 𝑘 = 𝑗 で分類に成功した場合、損失は0 • 損失関数を計算するためには、真のクラス 𝐶𝑘 を扱う必要がある。 - 予測の不確実性を示す 𝑝 𝐱, 𝐶𝑘 と損失行列 𝐿 を用いて損失の平均を計算する 1.80 図 1.25
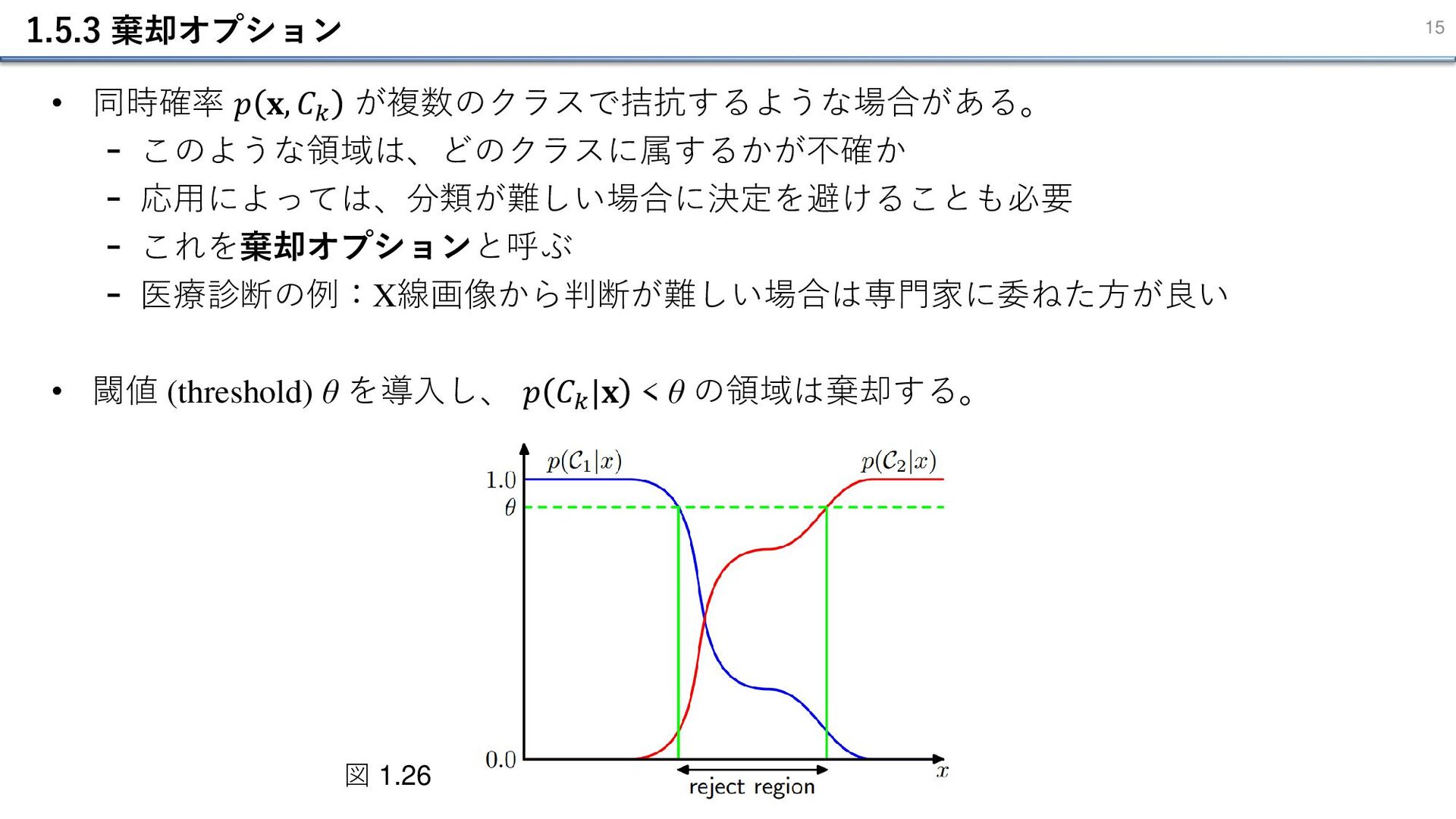
1.5.3 棄却オプション 15 • 同時確率 𝑝 𝐱, 𝐶𝑘 が複数のクラスで拮抗するような場合がある。 -
このような領域は、どのクラスに属するかが不確か - 応用によっては、分類が難しい場合に決定を避けることも必要 - これを棄却オプションと呼ぶ - 医療診断の例:X線画像から判断が難しい場合は専門家に委ねた方が良い • 閾値 (threshold) θ を導⼊し、 𝑝 𝐶𝑘 |𝐱 < θ の領域は棄却する。 図 1.26
1.5.4 推論と決定 16 • ここまでは、クラス分類を推論と決定に分けて考えていた。 - 推論:訓練データから 𝑝 𝐶𝑘 |𝐱
を学習する。 - 決定: 𝑝 𝐶𝑘 |𝐱 を使って分類するクラスを決定する。 • 他の可能性として、推論と決定を同時に解いて、⼊⼒ x から直接的に決定関数を学習 する手法が考えられ、これを識別関数と呼ぶ。 • 実際の応用では以下3つのアプローチが使われている - 生成モデル - 識別モデル - 識別関数
1.5.4 推論と決定 17 • 生成モデル - クラスの条件付き密度 𝑝 𝐱|𝐶𝑘 を
𝐶𝑘 ごとに決める推論問題を解く - 事前クラス確率 𝑝(𝐶𝑘 ) を計算する。 - ベイズの定理を使って事後確率 𝑝 𝐶𝑘 |𝐱 を計算する。 𝑝 𝐶𝑘 𝐱 = 𝑝 𝐱|𝐶𝑘 𝑝 𝐶𝑘 𝑝(𝐱) (1.82) • これは、同時分布 𝑝 𝐱, 𝐶𝑘 を直接モデル化する事と等価 - 式1.82 の分子について、𝑝 𝐱|𝐶𝑘 𝑝 𝐶𝑘 = 𝑝 𝐱, 𝐶𝑘 • このように、出⼒の分布だけでなく⼊⼒の分布もモデル化するアプローチでは、モデル からのサンプリングによりデータ点を生成できることから、生成モデルと呼ばれる。 - 𝑝 𝐱, 𝐶𝑘 から x をサンプリングすればクラス k っぽいデータ点を生成できる。
1.5.4 推論と決定 18 • 識別モデル - 最初に事後確率 𝑝 𝐶𝑘 |𝐱
をモデル化する。 - 次に、決定理論を使ってクラスを分類する。 • 識別関数 - ⼊⼒ 𝑥 から直接クラスラベルに写像する関数 𝑓(𝑥) を見つける。 - 例えば、2クラス問題の場合、 𝑓(・)は2値
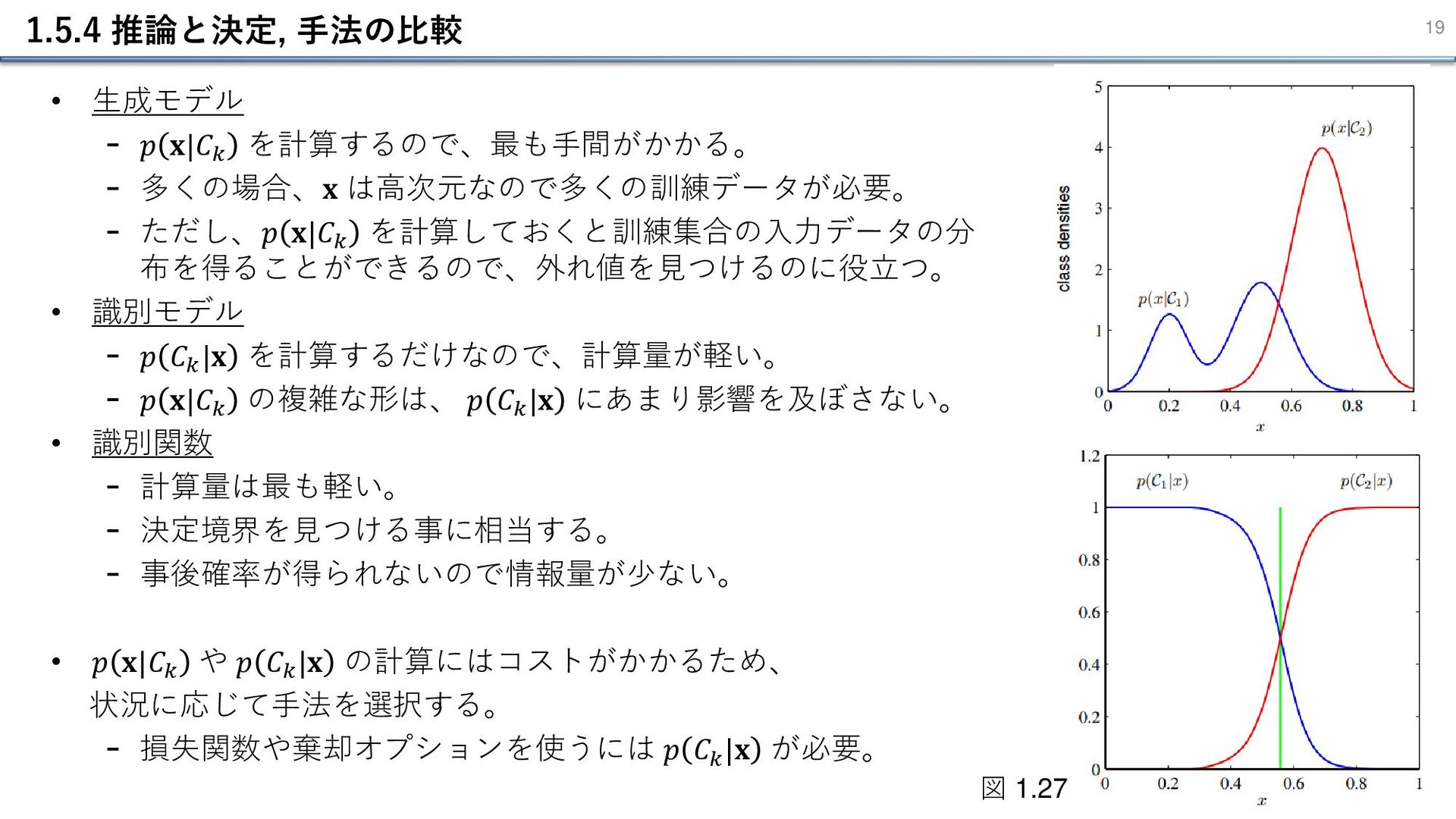
1.5.4 推論と決定, 手法の比較 19 • 生成モデル - 𝑝 𝐱|𝐶𝑘 を計算するので、最も手間がかかる。
- 多くの場合、𝐱 は高次元なので多くの訓練データが必要。 - ただし、𝑝 𝐱|𝐶𝑘 を計算しておくと訓練集合の⼊⼒データの分 布を得ることができるので、外れ値を見つけるのに役立つ。 • 識別モデル - 𝑝 𝐶𝑘 |𝐱 を計算するだけなので、計算量が軽い。 - 𝑝 𝐱|𝐶𝑘 の複雑な形は、 𝑝 𝐶𝑘 |𝐱 にあまり影響を及ぼさない。 • 識別関数 - 計算量は最も軽い。 - 決定境界を見つける事に相当する。 - 事後確率が得られないので情報量が少ない。 • 𝑝 𝐱|𝐶𝑘 や 𝑝 𝐶𝑘 |𝐱 の計算にはコストがかかるため、 状況に応じて手法を選択する。 - 損失関数や棄却オプションを使うには 𝑝 𝐶𝑘 |𝐱 が必要。 図 1.27
1.5.5 回帰のための損失関数 20 • ここまではクラス分類問題だったので、回帰について考える • 回帰問題の⽬標は、期待損失を最小にする関数 𝑦(𝐱) を見つけること -
⼊⼒ 𝐱 に対する 𝑡 の推定値が 𝑦 𝐱 • 𝑡と予測値 𝑦 𝐱 の値に応じて損失関数 𝐿(𝑡, 𝑦(𝐱)) を与える場合、期待損失は以下 • 回帰問題の場合によく使われる損失関数は二乗誤差 - ⽬標は、この期待損失を最小にする 𝑦 𝐱 を選ぶこと • 変分法(付録D)を使って形式的に行うと、以下が得られる. • 式1.88は 𝑡 の積分なので 𝑦 𝐱 の項を外に出して簡単に解ける。 1.86 1.87 1.88 𝜕𝐺 𝜕𝑦 − 𝑑 𝑑𝑥 𝜕𝐺 𝜕𝑦′ = 0
1.5.5 回帰のための損失関数 21 • 式1.88を解くと、 • これを回帰関数と呼ぶ。 • この結果は 𝑡
が多変数ベクトルになっても同じ • 別の方法でも同じ結論を得ることができる。最適解が条件付き期待値であることが既に分 かっているので、以下のような変形を行う。 • これを条件付き期待値の式に⼊れて整理すると以下が得られる。 • 𝑦 𝐱 に依存するのは第1項だけなので、 𝔼[𝐿] を最小にする 𝑦 𝐱 はやはり 𝔼[𝑡|𝐱] になる。 1.89 1.90
1.6 情報理論 22 • 情報理論の分野から、後の章でも出てくる有用な概念を導⼊する。 • 情報量 - 離散確率変数 𝐗
を考えたとき、ある値 𝑥 を観測した時の驚きの度合い - 情報量を定義するうえで満たしてほしい条件 ➢𝑝(𝑥) が大きい値ならば ℎ(𝑥) は小さくなる ➢独立な 𝑥, 𝑦 を観測したときの情報量の和は ℎ 𝑥, 𝑦 = ℎ 𝑥 + ℎ 𝑦 - この2つの条件を満たすのは対数関数 - 底には自由度がある。 - 情報分野でよく用いられる 2 とすれば、情報量の単位はビットになる。 ℎ 𝑥 = − log2 𝑝 𝑥 (1.92) • エントロピー - ある送信者が、確率変数の値を受信者に送りたいとする。 - この場合、情報の平均量は式1.92 の 𝑝(𝑥) に関する期待値である。 H 𝑥 = − 𝑥 𝑝 𝑥 log2 𝑝 𝑥 1.93 • エントロピーは物理学に端を発する概念(p50参照)
1.6 情報理論 23 • エントロピーと符号長 • 例: x が8個の状態を等確率で取り得る場合 -
8個の状態を3ビットで表すことができる。 • x が8個の状態 {𝑎, 𝑏, 𝑐, 𝑑, 𝑒, 𝑓, 𝑔, ℎ} をそれぞれ確率 {1 2 , 1 4 , 1 8 , 1 16 , 1 64 , 1 64 , 1 64 , 1 64 } で取る時 - よく起きる事象に短い符号、あまり起きない事象に長い符号を使うことで、確率一様の時より も符号長平均を短くできる - 状態 {𝑎, 𝑏, 𝑐, 𝑑, 𝑒, 𝑓, 𝑔, ℎ} に符号 {0, 10, 110,1110,111100,1111101,111110,111111} を割り当てると - 文字列から符号への変換で曖昧さを残してはいけないので、これ以上短い符号は使えない。
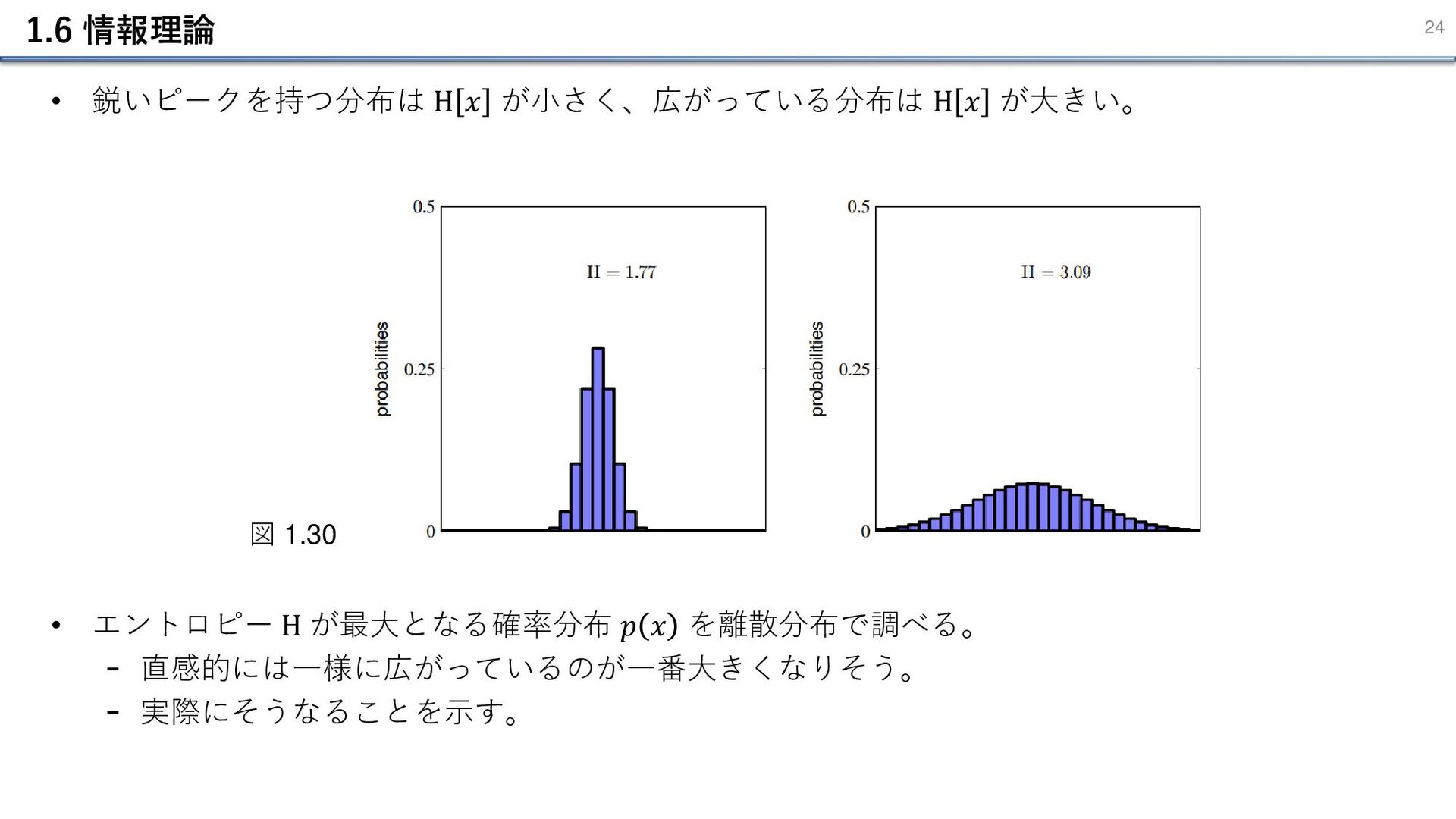
1.6 情報理論 24 • 鋭いピークを持つ分布は H 𝑥 が小さく、広がっている分布は H 𝑥
が大きい。 • エントロピー H が最大となる確率分布 𝑝 𝑥 を離散分布で調べる。 - 直感的には一様に広がっているのが一番大きくなりそう。 - 実際にそうなることを示す。 図 1.30
1.6 情報理論 25 • ラグランジュで、確率が規格化されているという制約を与えて H の最大化を考える。 - 2階微分が負定値であることから、෩ H
は凹関数であることが分かる。 - よって、停留点で最大値をとることが分かる。 𝜕෩ H 𝜕𝑝 𝑥𝑖 = − ln 𝑝 𝑥𝑖 − 1 + 𝜆 = 0 - どの 𝑥𝑖 で微分しても等しく ln𝑝 𝑥𝑖 = 1 − 𝜆 になるときに ෩ H が最大になる。 - すなわち、𝑥𝑖 の総数をMとすると、 𝑝 𝑥𝑖 = 1 𝑀 のときに෩ H が最大になる。 1.99 1.100
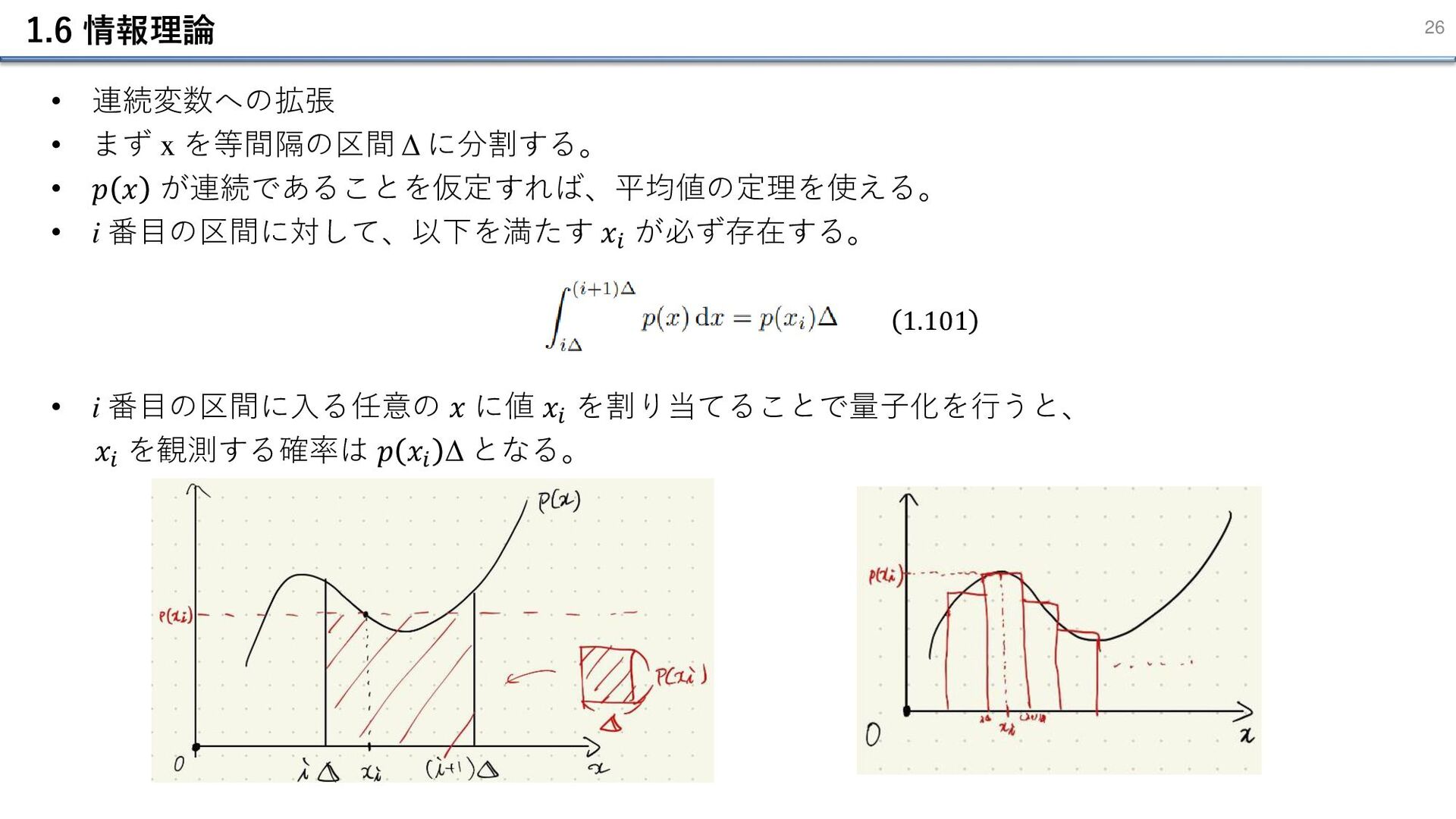
1.6 情報理論 26 • 連続変数への拡張 • まず x を等間隔の区間 Δ
に分割する。 • 𝑝 𝑥 が連続であることを仮定すれば、平均値の定理を使える。 • i 番⽬の区間に対して、以下を満たす 𝑥𝑖 が必ず存在する。 • i 番⽬の区間に⼊る任意の 𝑥 に値 𝑥𝑖 を割り当てることで量子化を行うと、 𝑥𝑖 を観測する確率は 𝑝 𝑥𝑖 Δ となる。 1.101
1.6 情報理論 27 • 𝑥𝑖 を観測する確率は 𝑝 𝑥𝑖 Δ となるので、式1.101
より σ𝑖 𝑝 𝑥𝑖 Δ = 1 を使えば、 • ここで、第1項についてΔ → 0 の極限を考えると、 • 右辺の量は微分エントロピーと呼ばれている。 • 式1.102 の −lnΔ は Δ → 0 で発散する。 - これは、連続変数を厳密に規定するのに無限のビット数を必要とすることを表している。 1.102 1.103
1.6 情報理論 28 • 離散変数では一様分布のときにエントロピーが最大になった。 • 連続変数におけるエントロピーの最大化について考える。 - 確率の総和が 1
になる事と、1次と2次のモーメントを制約条件とする。 • ラグランジュと変分法を使うと、式1.108 が得られる。 1.108
1.6 情報理論 29 • 式1.108 を制約条件の式1.105~1.107 に代⼊していくと、 𝑝 𝑥 が求まる。
- エントロピーが最大となる連続な関数は、ガウス分布であることが分かった。 • ガウス分布の微分エントロピーを実際に計算すると 1.109 1.110 - 分散が大きい(一様分布っぽい感じで広がった)ガウス分布であるほど H[x] が大きい。 - 離散分布のエントロピーは非負であったが、連続だと負になり得る。 ➢ 𝜎2 < 1 2𝜋𝑒 のとき H[x] が負になる。
1.6.1 相対エントロピーと相互情報量 30 • KLダイバージェンス - 未知である真の分布 𝑝 𝑥 を、近似的に
𝑞 𝑥 でモデル化したとする。 - この 𝑞 𝑥 を使って 𝑥 の値を送信するために符号化することを考える。 - 𝑥 の値を特定するのに必要な追加情報量の平均は、 1.113 モデルを使ったときの情報量 真の情報量 - これを相対エントロピー、または KLダイバージェンスと呼ぶ。 - 式の形からも分かるように、 KL(𝑝| 𝑞 ≠ KL(𝑞| 𝑝 - KL(𝑝| 𝑞 は非負であることを示す。
1.6.1 相対エントロピーと相互情報量 31 • KL(𝑝| 𝑞 は非負であることの証明 - 関数 𝑓
𝑥 で、全ての弦が関数に乗っているかそれよりも上であるとき凸であると呼ぶ。 - 図1.31で、a と b を 1 − 𝜆 : 𝜆 に分割する 𝑥𝜆 を考える。 - 𝑥𝜆 = 𝜆𝑎 + 1 − 𝜆 𝑏 - 𝑓 𝑥 上の点は 𝑓(𝜆𝑎 + 1 − 𝜆 𝑏) - 𝑥𝜆 と弦の交点は 𝜆𝑓(𝑎) + 1 − 𝜆 𝑓(𝑏) - 以上より凸関数では、式1.114 が成立する。 - 式1.114 から、帰納法を使うと以下が得られる。 - 証明は演習1.38 - 0 ≤ 𝜆 ≤ 1 で成立するこの式をイェンセンの不等式と呼ぶ。 1.114 図1.31 𝜆𝑎 + 1 − 𝜆 𝑏 𝜆𝑓(𝑎) + (1 − 𝜆)𝑓(𝑏) 𝑓(𝜆𝑎 + 1 − 𝜆 𝑏) 1.115
1.6.1 相対エントロピーと相互情報量 32 • 連続変数では次のようになる - 𝜆 (0 ≤ 𝜆
≤ 1) が 𝑝(𝐱) に置き換わっている • 式1.117 を KLダイバージェンスに適用すると - 𝑓 𝑥 = −ln(𝐱) とし, −ln(𝐱) が凸関数であることと ∫ 𝑞 𝐱 𝑑𝐱 = 1 を利用 - 等号は全ての 𝐱 について 𝑝 𝐱 = 𝑞(𝐱) の時に限り成立 • KLダイバージェンスは 𝑝 𝐱 と 𝑞(𝐱) のとの隔たりを表す尺度として解釈可能 - ただし KL(𝑝| 𝑞 ≠ KL(𝑞| 𝑝 であるため、距離ではないことに注意 1.117
1.6.1 相対エントロピーと相互情報量 33 • データが道の分布 𝑝(𝐱) から生成される時の密度推定について考える。 - 𝑝(𝐱) をモデル化する際、パラメータ
𝜃 を持つパラメトリックな分布 𝑞(𝐱|𝜃) 使う。 - 最適な 𝜃 を決める一つの手段として、 KL(𝑝| 𝑞 を最小にする 𝜃 を選ぶ手法が考えられる。 - ただし、 𝑝(𝐱) は未知なので、直接 KL(𝑝| 𝑞 を計算することは不可能 • 𝑝(𝐱) からデータ集合 𝑥𝑛 (𝑛 = 1, 2, … 𝑁) が得られる場合、有限和近似によって以下が得られる。 • このとき、KLダイバージェンスの最小化=負の対数尤度の最小化 - やっていることは対数尤度の最大化と同じ 1.119 KLダイバージェンスの式 負の対数尤度
まとめ 34 1.3 モデル選択 データ量は有限なので、最適なモデルを決めるためにCVしましょう ただしディープなど学習に計算コストがかかる時はやらない 1.4 次元の呪い 高次元空間を埋めるだけのデータ量を用意するのは大変で、 内挿するのが難しくなるが後の章で次元削減などの手法が出てくる
1.5 決定理論 推論と決定について 状況に応じて生成モデル、識別モデル、識別関数を使い分ける 計算コストが多く複雑な手法ほど多くの情報を持っている 1.6 情報理論 情報量とエントロピーについて 離散と連続でエントロピーが最大になる分布について考えた 2つの分布の隔たりを KLダイバージェンスで調べることができる (VAEなど変分下限の最大化を考えるときにも出てくる)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}