This talk discusses some of the additional tooling Forward have employed to allow us to deploy node applications at large scale with very high availability.
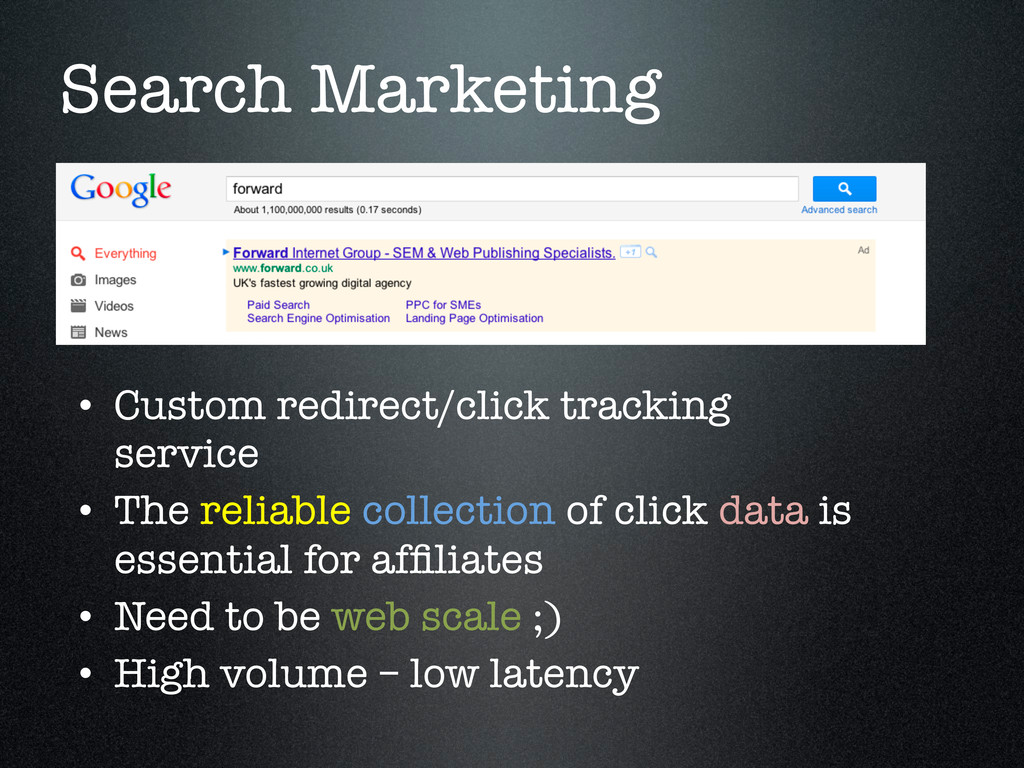
the opportunity to place JS on the landing page of a major client • Allowed us to track user actions of interest. • Needed a way to track and persist the events
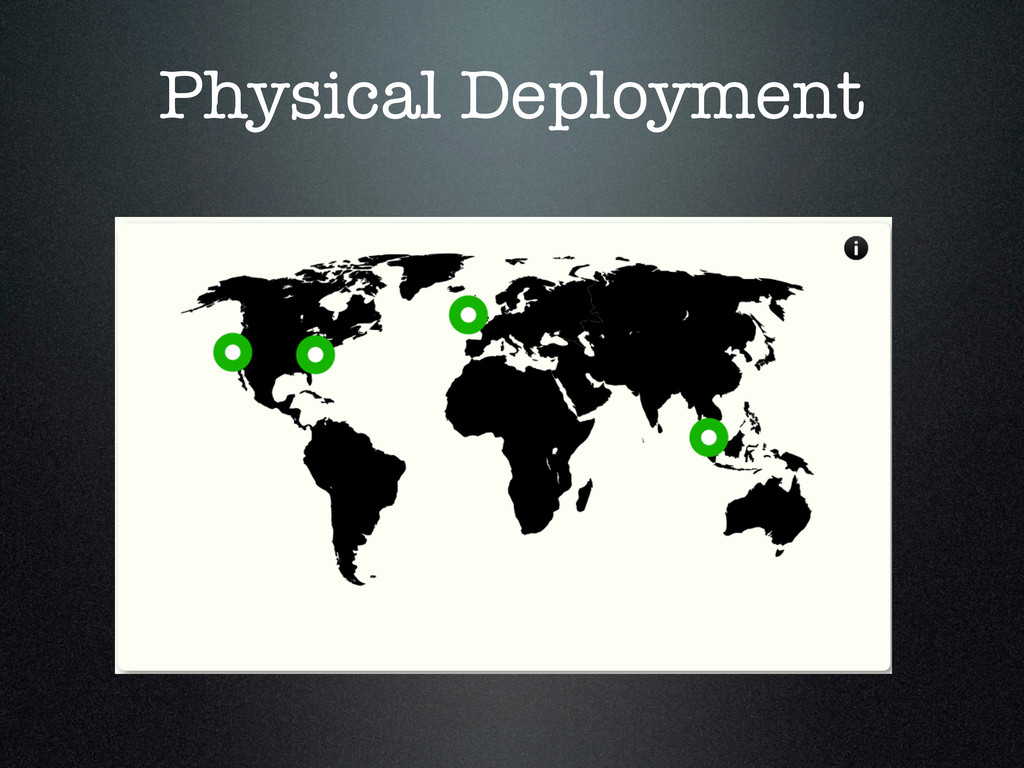
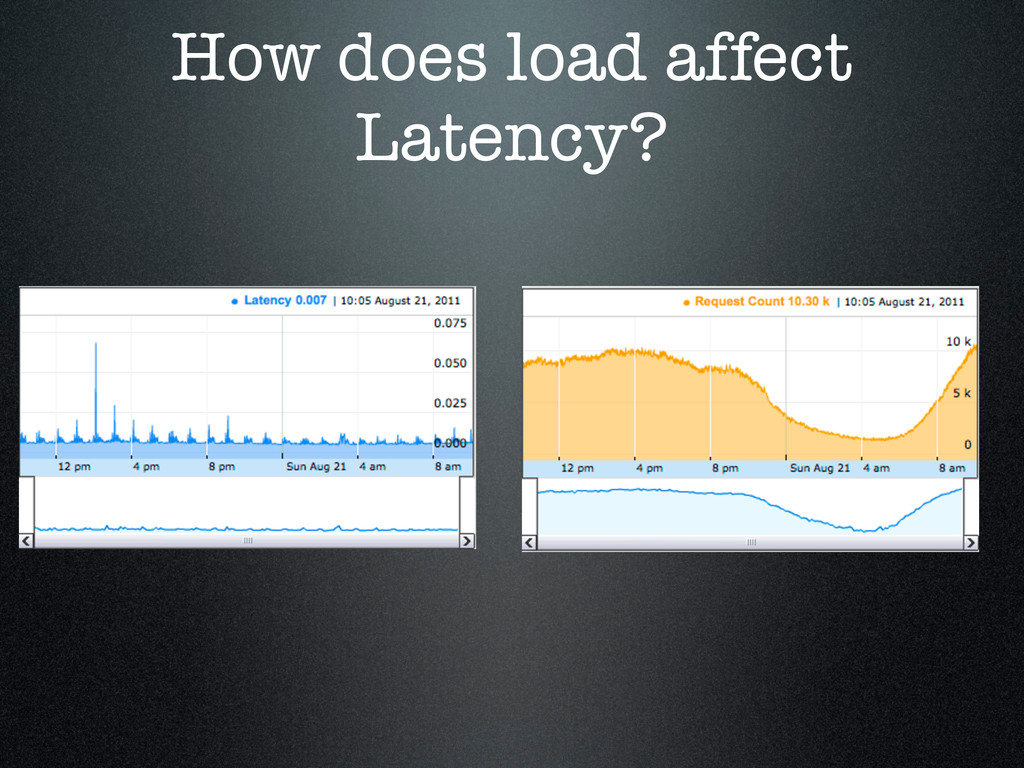
passed to disk • This was a perfect match for node’s non blocking IO. • No need for queues • Deployed to the same machines as redirect service • Av. Latency was half!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}