Error z value Pr(>|z|) (Intercept) -8.36105 0.33248 -25.148 < 2e-16 *** no_papers_phd_b(4, 7] -0.38626 0.19965 -1.935 0.053028 . no_papers_phd_b(7, 31] -0.61925 0.23726 -2.610 0.009052 ** no_papers_phd_b[1, 2] 0.27275 0.17519 1.557 0.119504 coauthors_b(2.53, 3] 0.10902 0.21442 0.508 0.611130 coauthors_b(3, 3.4] -0.29622 0.27446 -1.079 0.280464 coauthors_b(3.4, 6] 0.33955 0.25579 1.327 0.184352 coauthors_b[0, 2] 0.75420 0.22291 3.383 0.000716 *** pub_time_b(216.4, 313.987] -0.23674 0.21340 -1.109 0.267268 pub_time_b(313.987, 517.4] -0.01697 0.21339 -0.080 0.936598 pub_time_b(517.4, 1823] -0.37342 0.23740 -1.573 0.115727 pub_time_b[0, 143.667] -0.67463 0.23737 -2.842 0.004482 ** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Approximate significance of smooth terms: edf Ref.df Chi.sq p-value s(stop) 3.103 3.736 12.05 0.0188 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 R-sq.(adj) = -0.0701 Deviance explained = 3.05% -REML = 2003.7 Scale est. = 1 n = 12300 Call: coxph n= 492, number of events= 232 coef exp(coef) se(coef) z Pr(>|z|) no_papers_phd_b(4, 7] -0.38948 0.67741 0.19979 -1.950 0.051234 . no_papers_phd_b(7, 31] -0.61863 0.53868 0.23752 -2.605 0.009199 ** no_papers_phd_b[1, 2] 0.27444 1.31580 0.17532 1.565 0.117489 coauthors_b(2.53, 3] 0.10580 1.11159 0.21433 0.494 0.621580 coauthors_b(3, 3.4] -0.30237 0.73906 0.27435 -1.102 0.270406 coauthors_b(3.4, 6] 0.33886 1.40335 0.25563 1.326 0.184976 coauthors_b[0, 2] 0.75185 2.12092 0.22292 3.373 0.000744 *** pub_time_b(216.4, 313.987] -0.22739 0.79661 0.21335 -1.066 0.286511 pub_time_b(313.987, 517.4] -0.01511 0.98501 0.21362 -0.071 0.943627 pub_time_b(517.4, 1823] -0.38407 0.68108 0.23780 -1.615 0.106285 pub_time_b[0, 143.667] -0.66126 0.51620 0.23704 -2.790 0.005277 ** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Concordance= 0.697 (se = 0.021 ) Rsquare= 0.187 (max possible= 0.995 ) Likelihood ratio test= 101.7 on 30 df, p=1.003e-09 Wald test = 97.08 on 30 df, p=5.339e-09 Score (logrank) test = 106.5 on 30 df, p=1.673e-10 PGAMs for Survival Analysis
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![21 data Population if __name__ == "__main__": date_start = sys.argv[1]](https://files.speakerdeck.com/presentations/4c82786260784b538ab84eb9133d4087/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
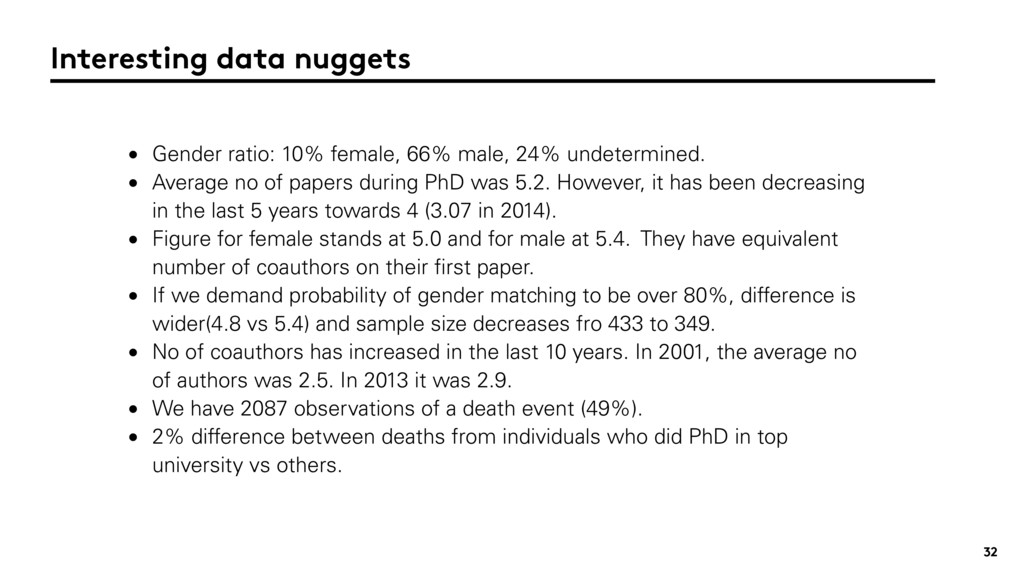{kind=link}
{kind=link}
{kind=link}
{kind=link}
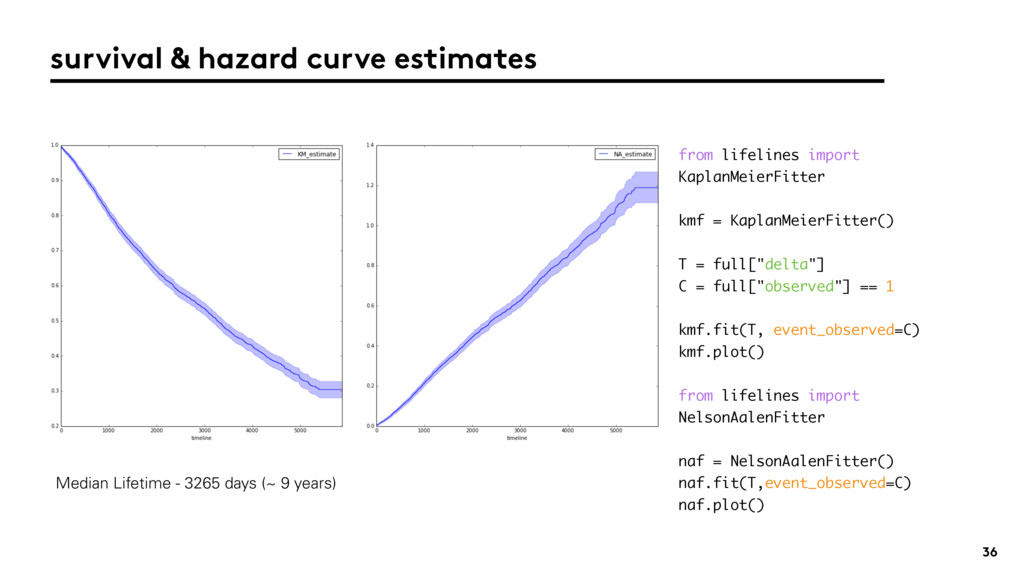{kind=link}
{kind=link}
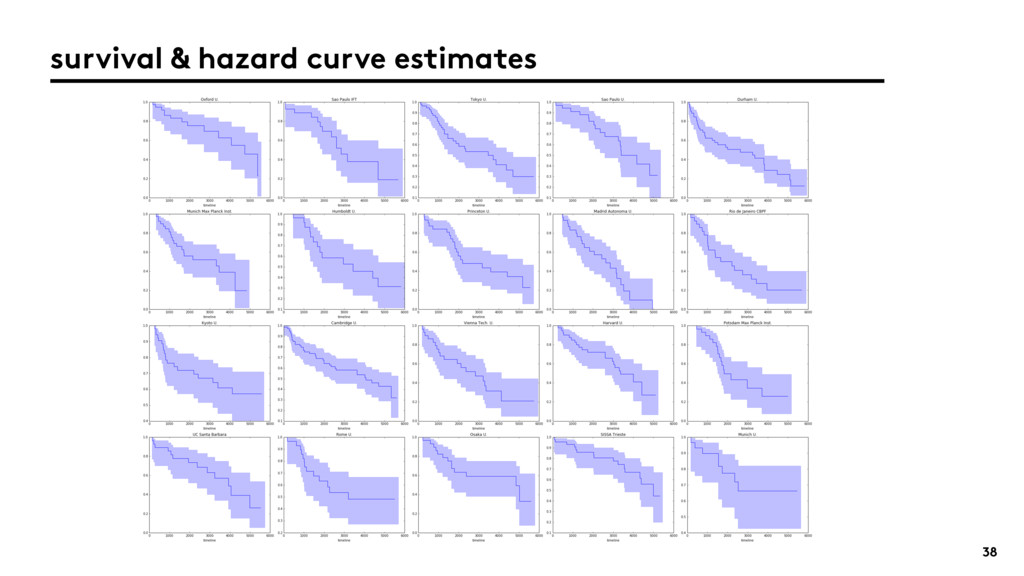{kind=link}
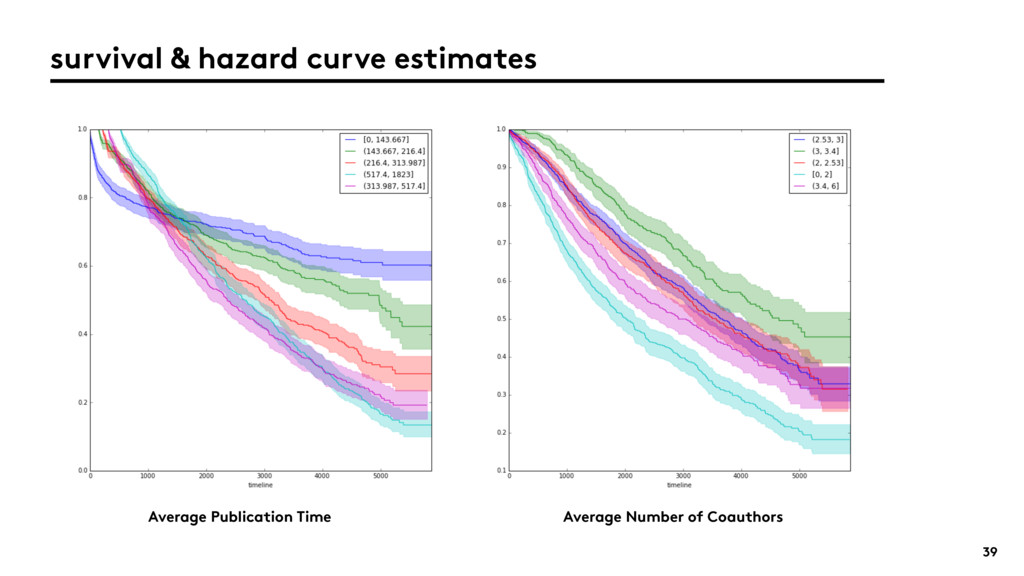{kind=link}
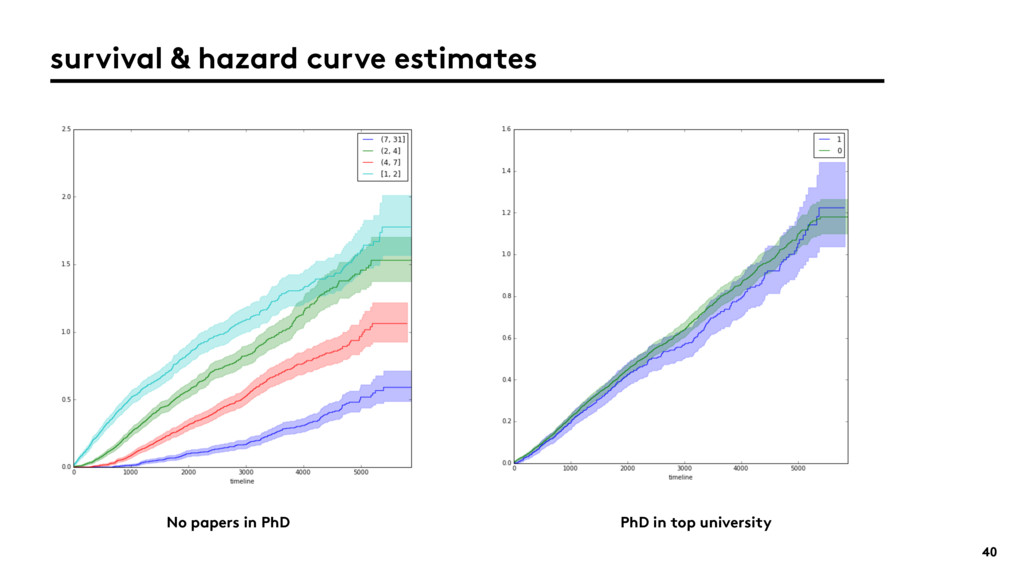{kind=link}
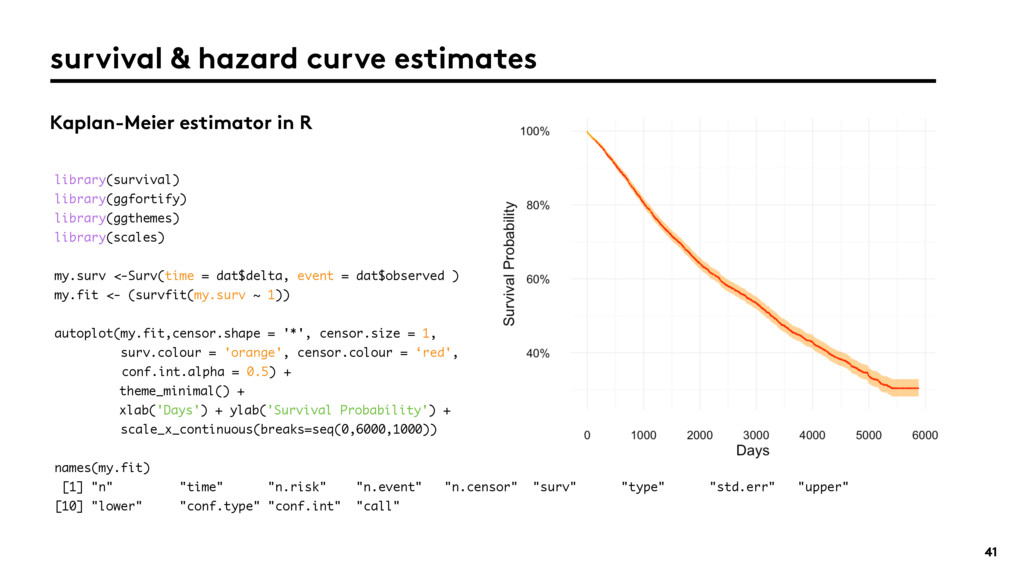{kind=link}
{kind=link}
{kind=link}
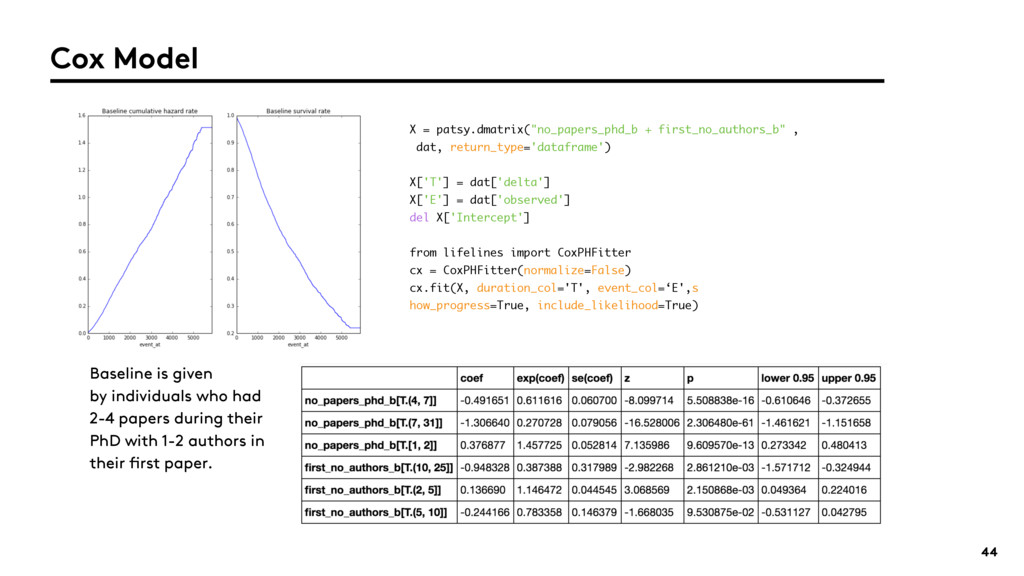{kind=link}
{kind=link}
{kind=link}
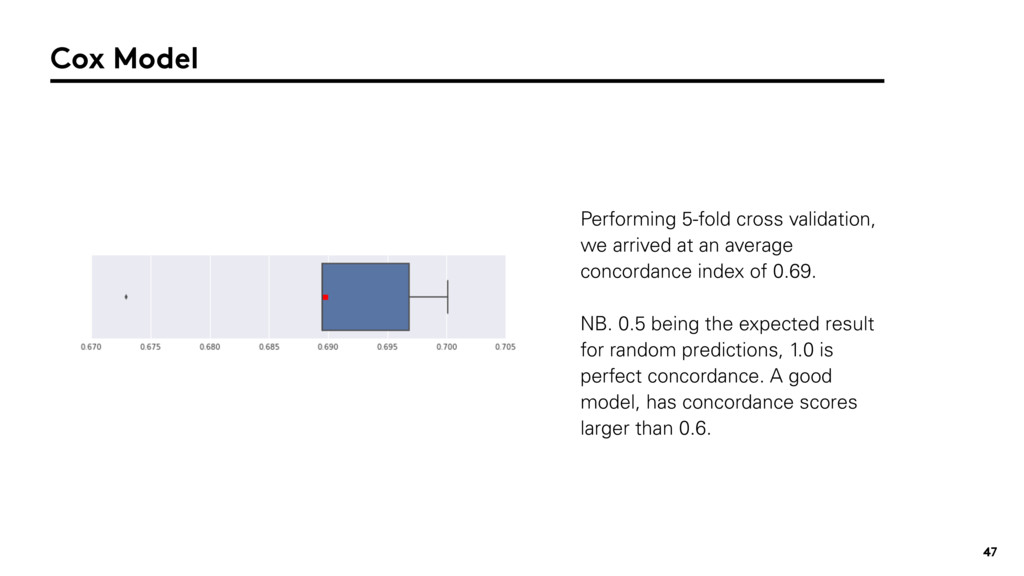{kind=link}
{kind=link}
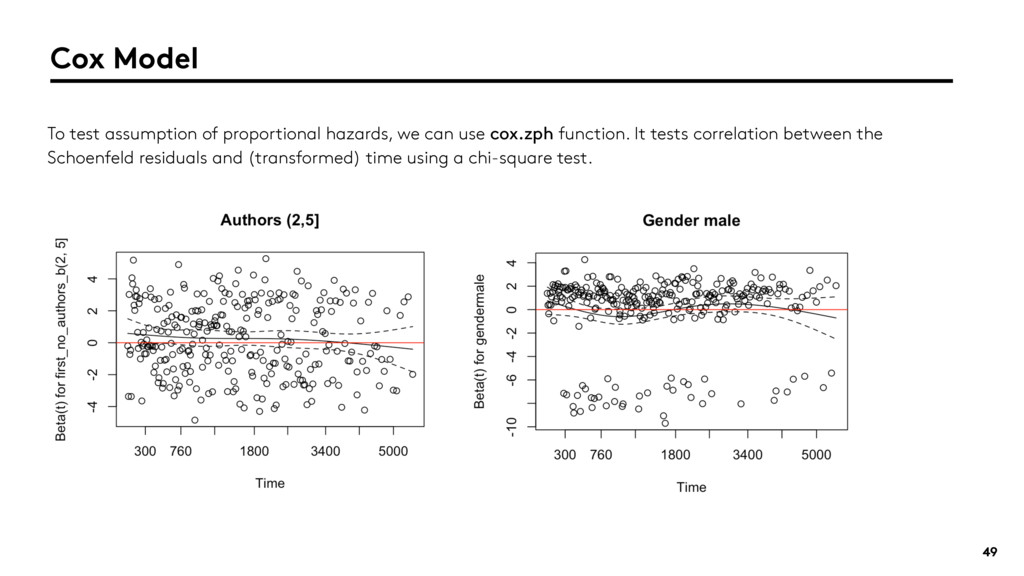{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
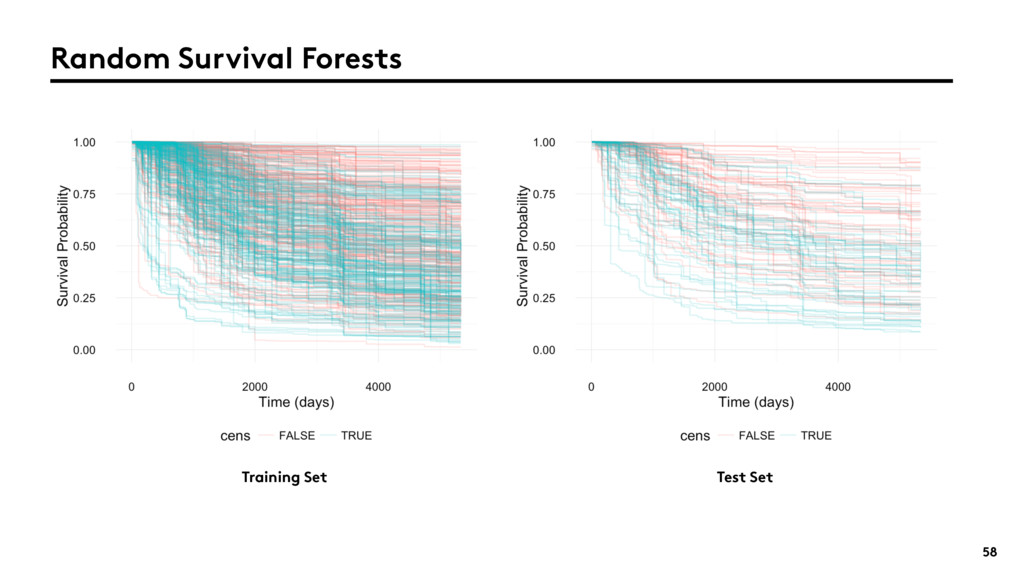{kind=link}
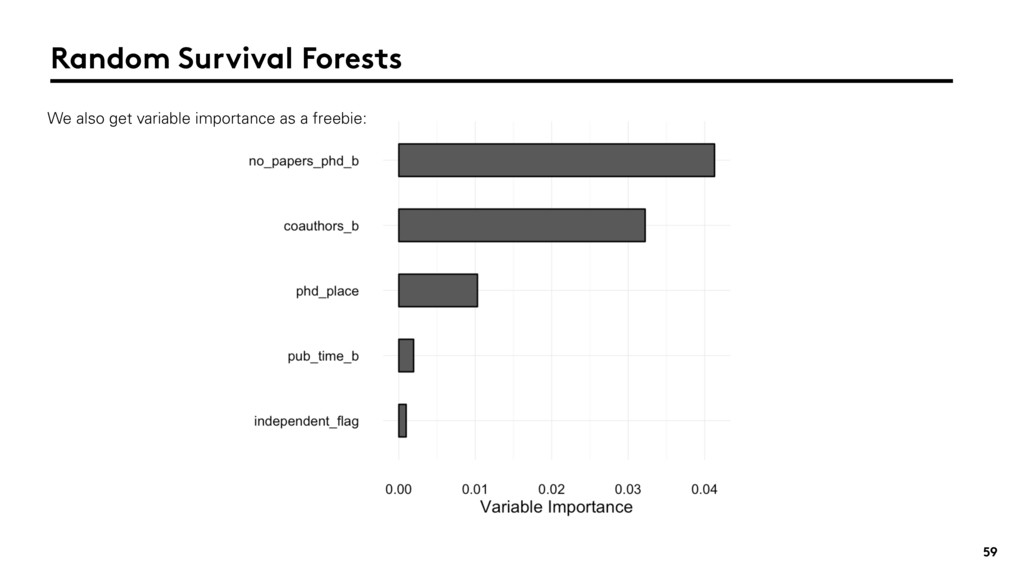{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}