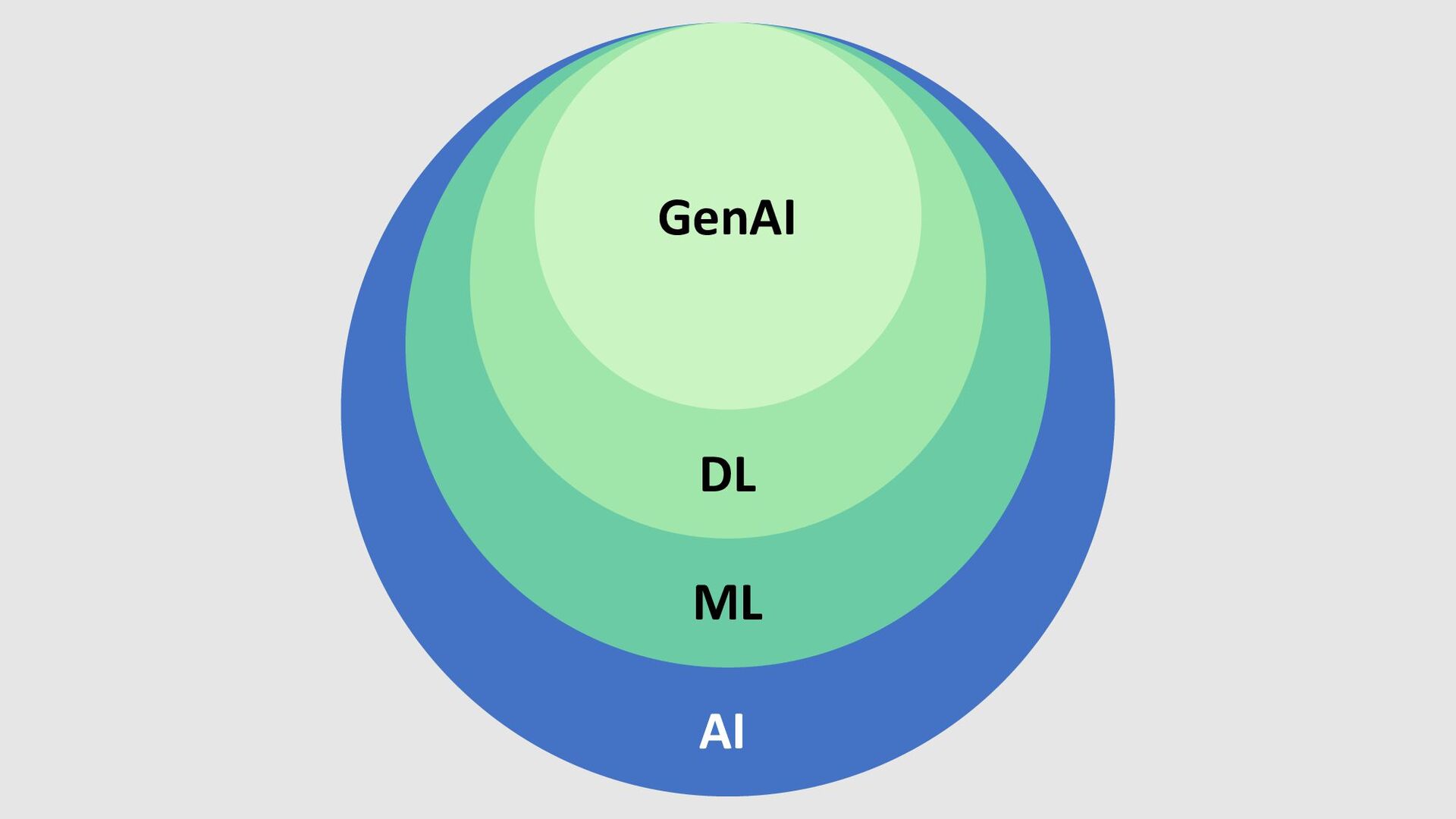
Generative AI is on everyone's lips. Enthusiastic praise for OpenAI's ChatGPT (175 billion trainable parameters), which was released in November 2022 by the first users quickly led to projections of productivity gains for companies and the global economy by relevant analysts. The stock market is also going crazy and the profits and losses of relevant major players are sometimes in double-digit percentages on a daily basis.
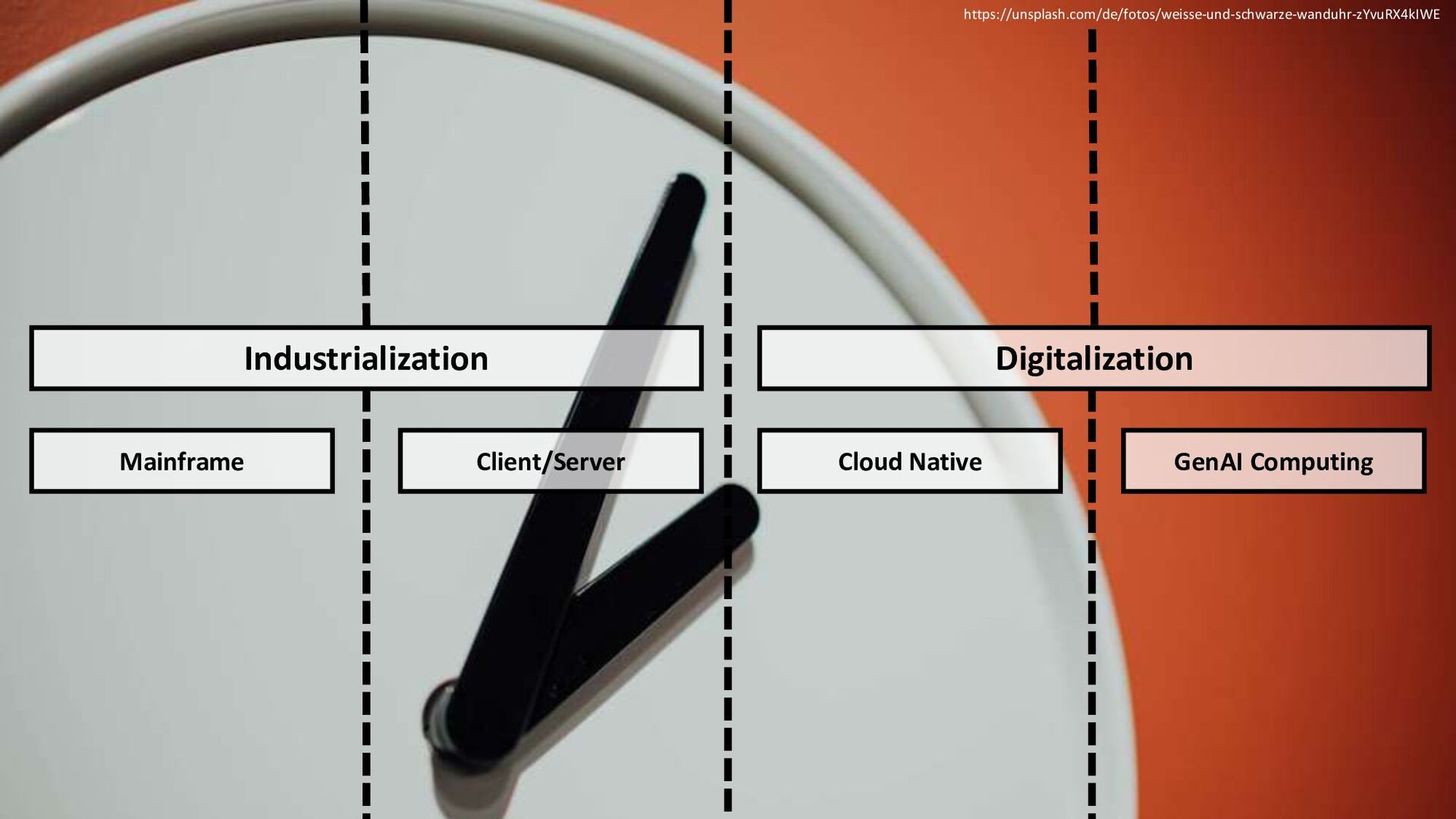
The talk is divided into three parts. In the first part, we will look at developments over the past year driven by the Attention and Diffusion architectural styles with the increasing shift to smaller and more open models. In the second part, we will take a closer look at where the parameters in Transformer architectures (Attention) are and what this means for the design of the number and size of CPUs and GPUs for training and inference. In the third part, we will trace the technological development of graphics cards - or accelerators in general - with the top dog NVIDIA (in particular the brand new Blackwell @ GTC 2024), but also AMD and large cloud providers. And in the fourth part, a small practical demo will show how democratization through smaller and more open models makes the possibilities of Generative AI easier, faster and more widely available.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
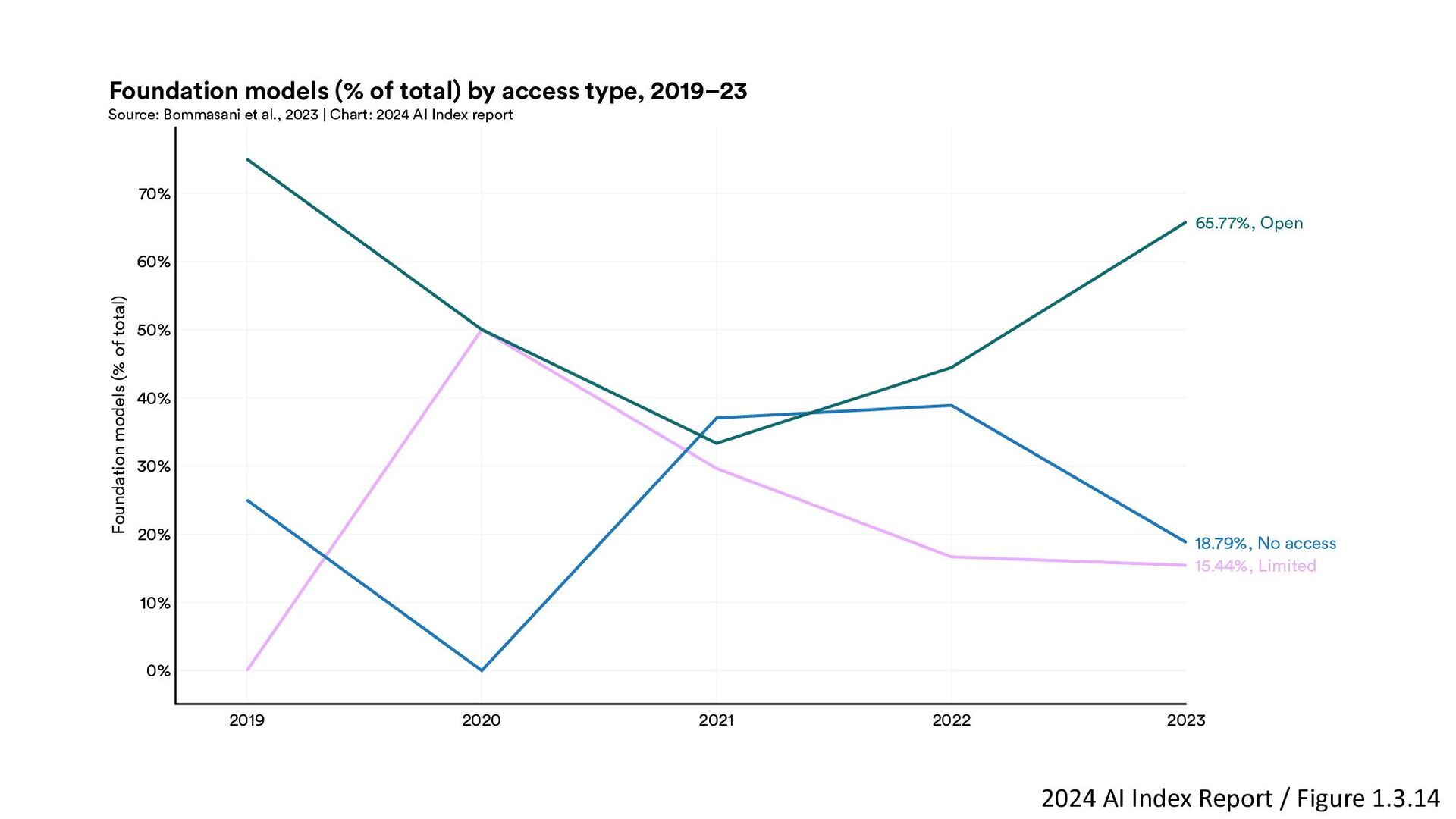{kind=link}
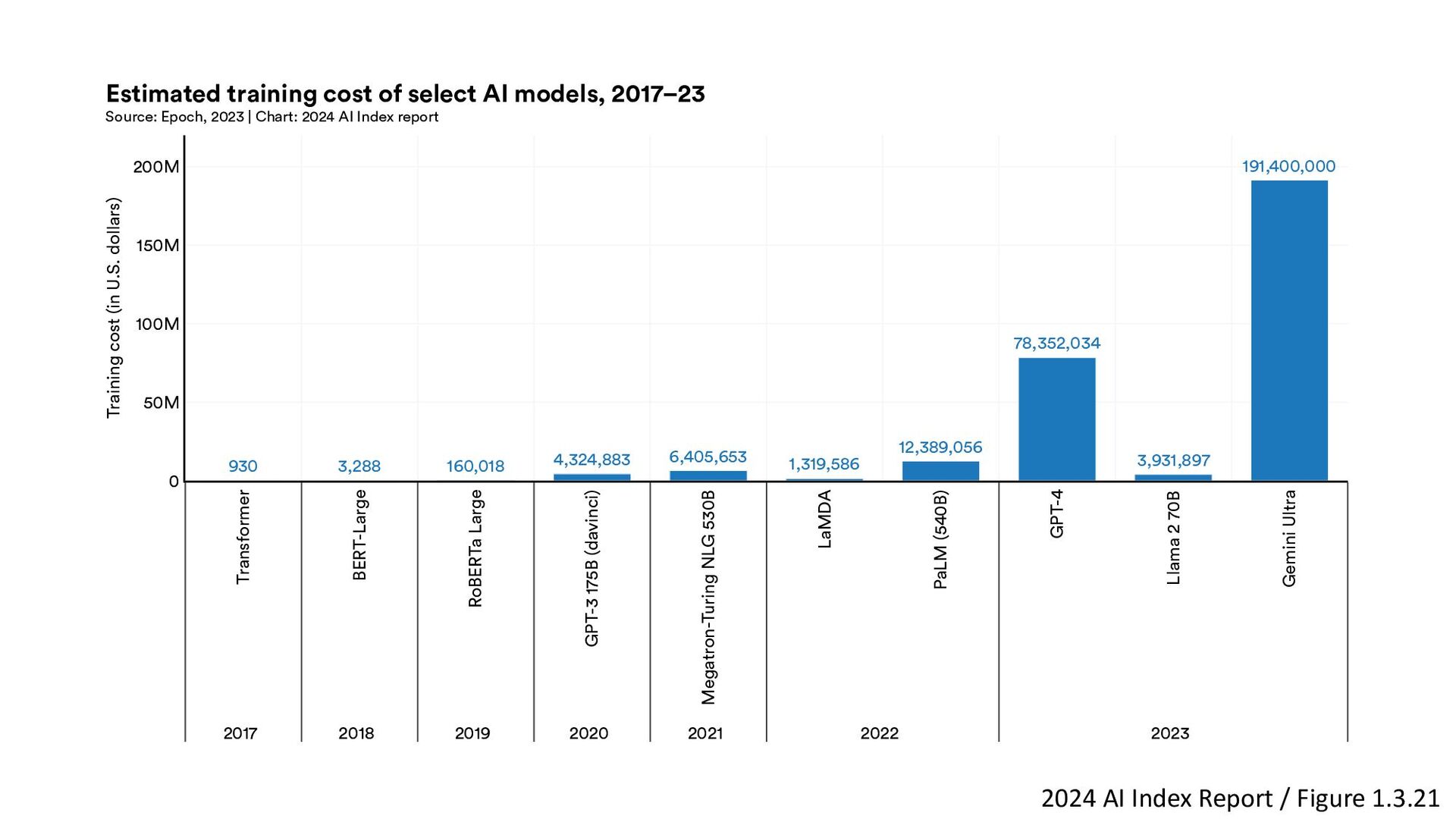{kind=link}
{kind=link}
{kind=link}
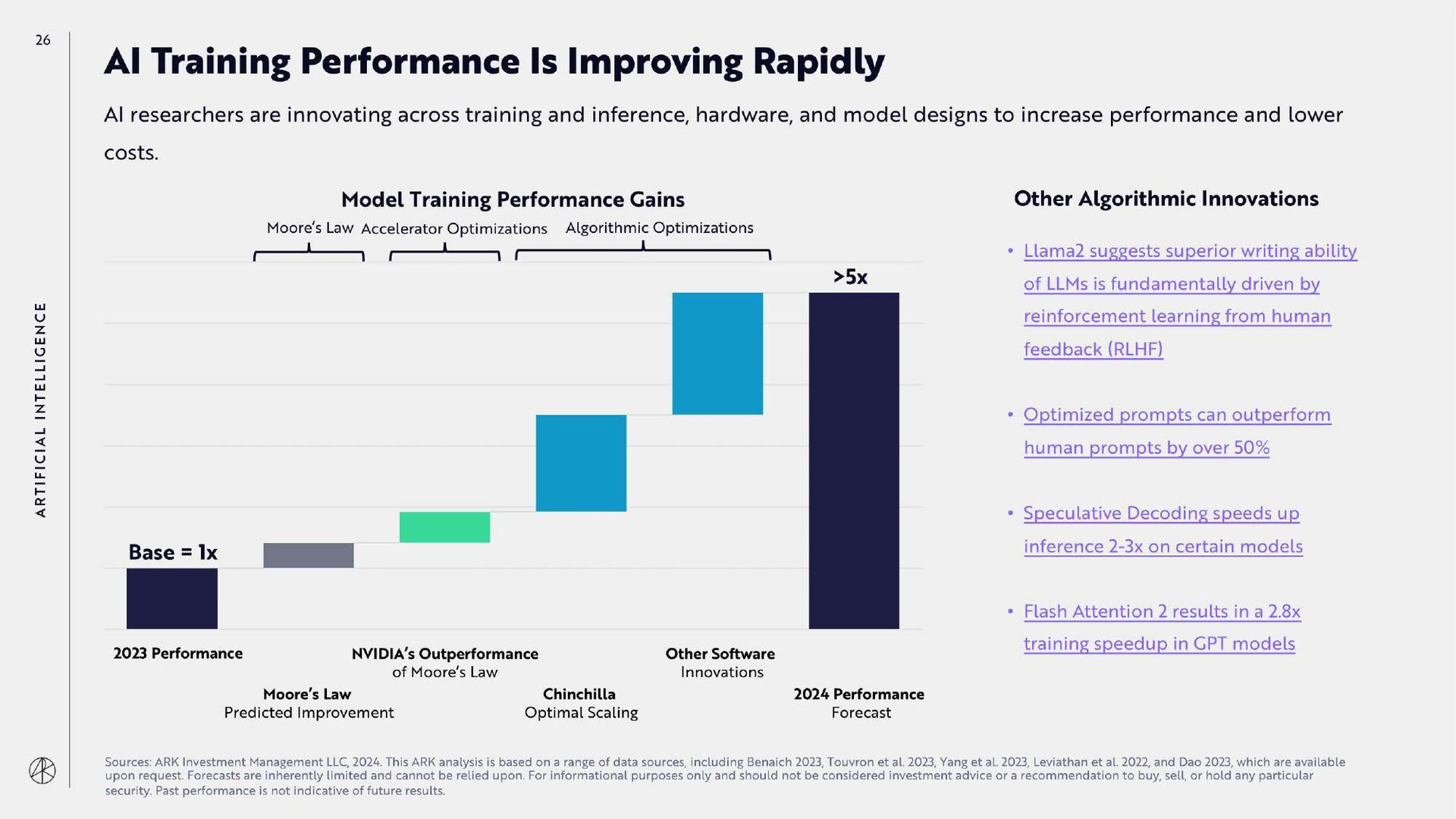{kind=link}
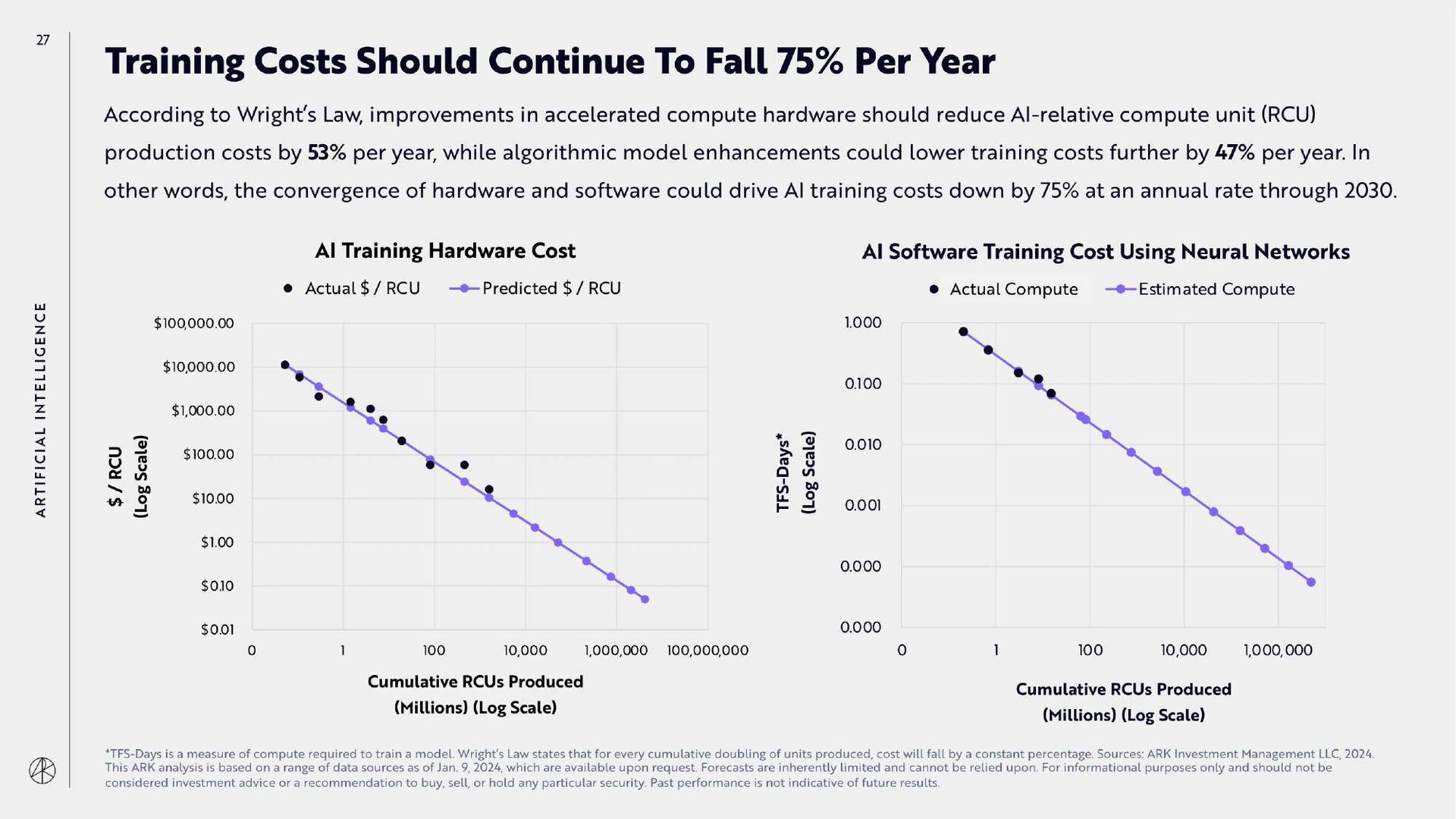{kind=link}
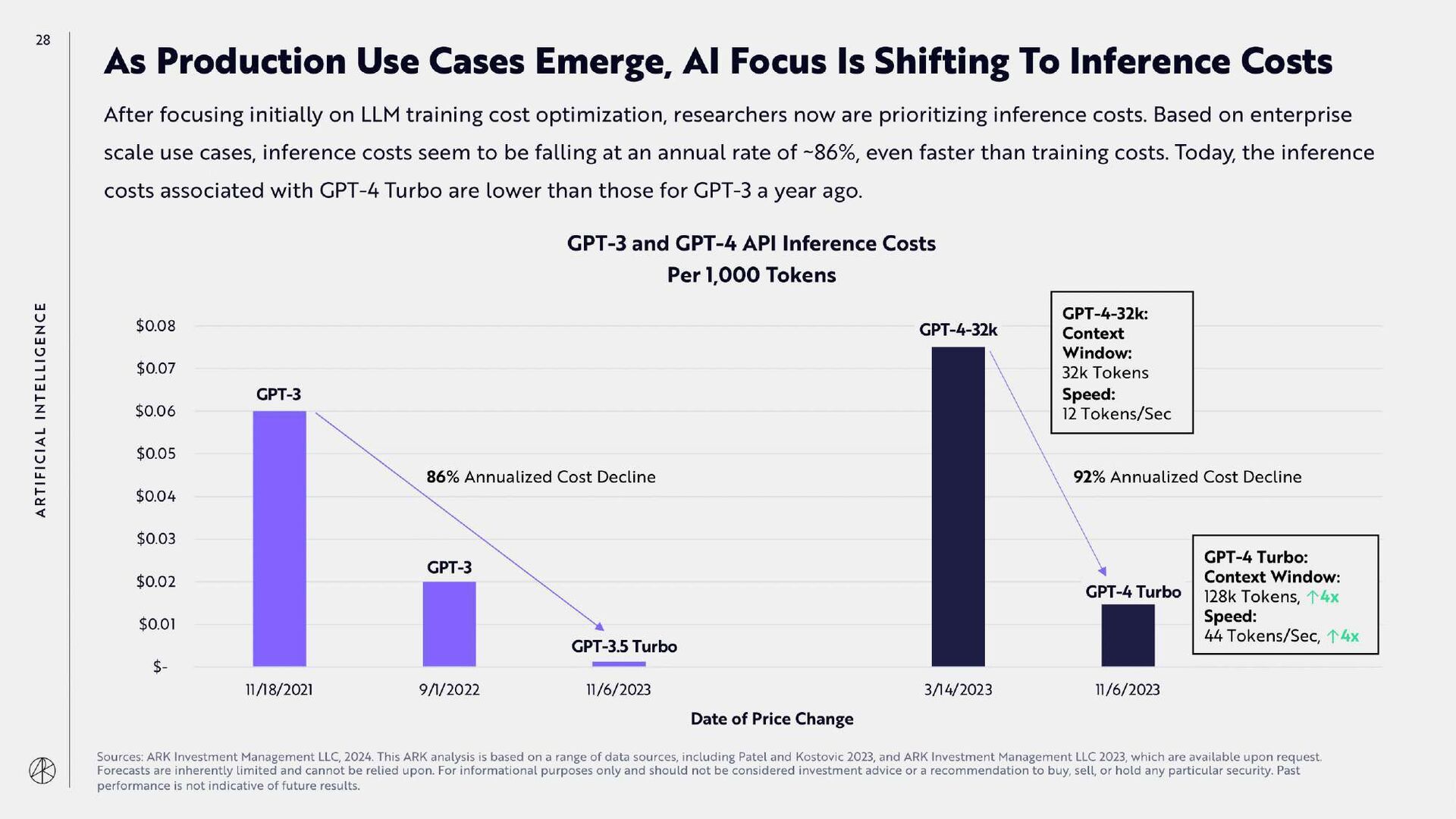{kind=link}
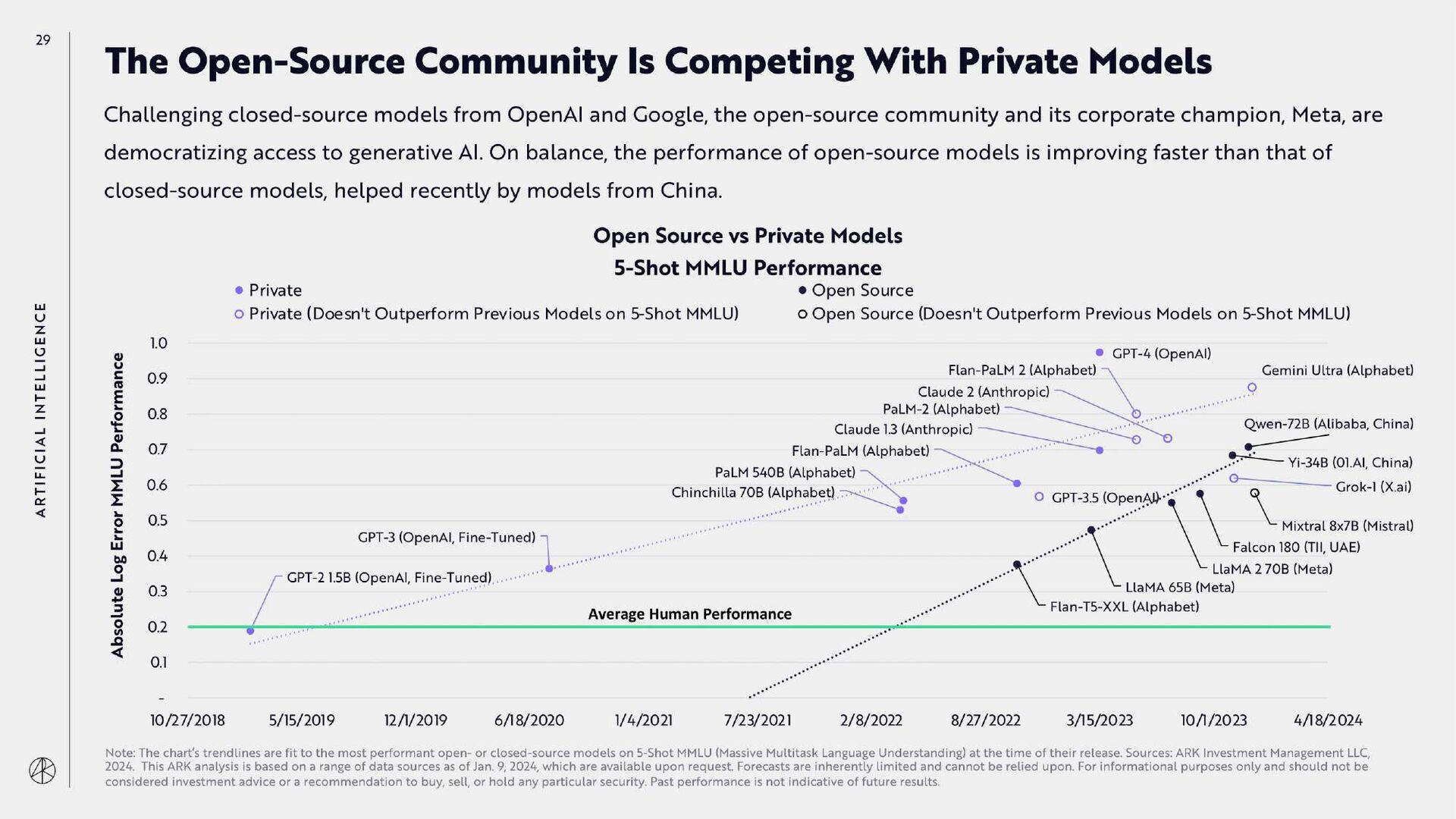{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
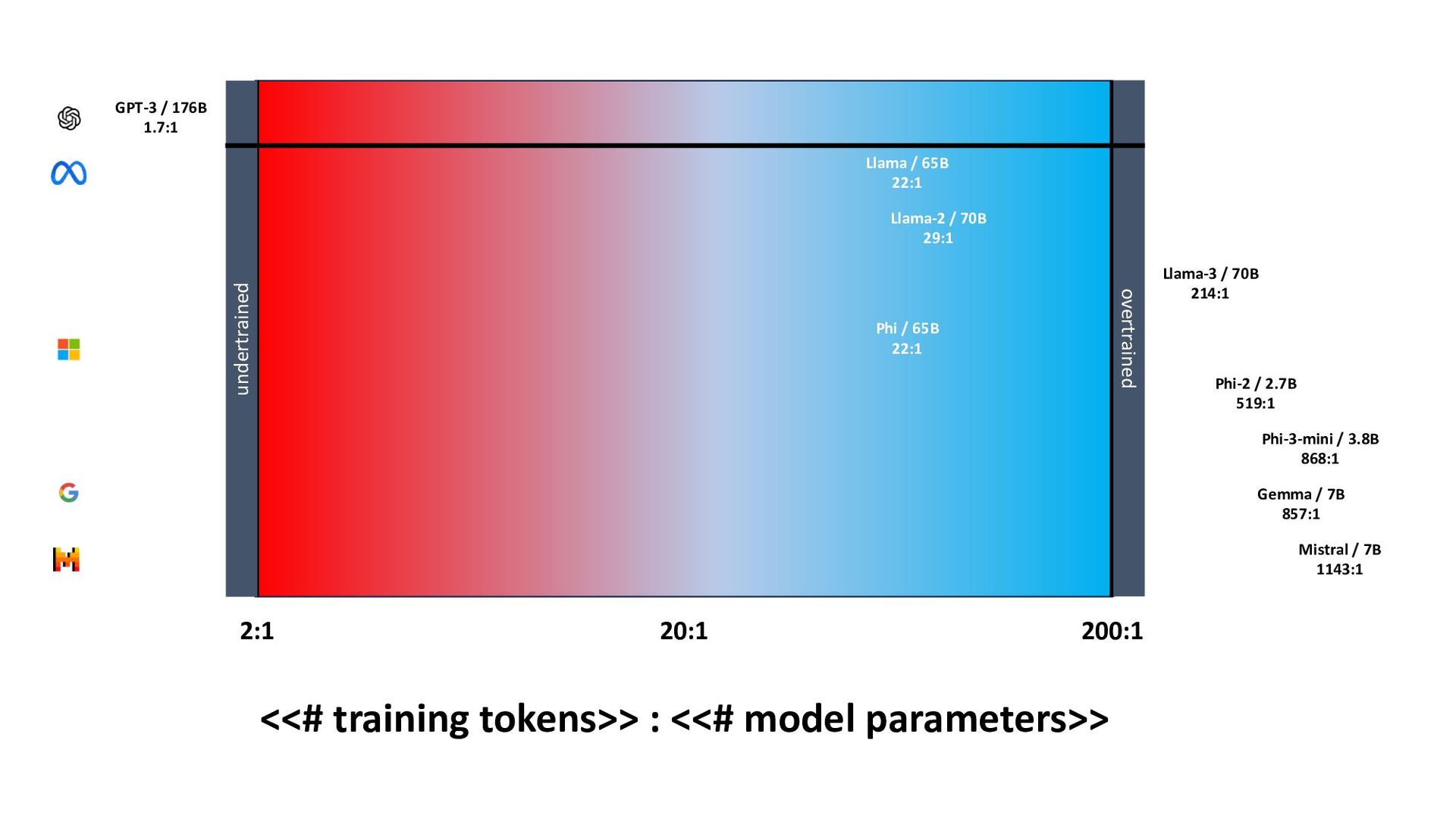{kind=link}
{kind=link}
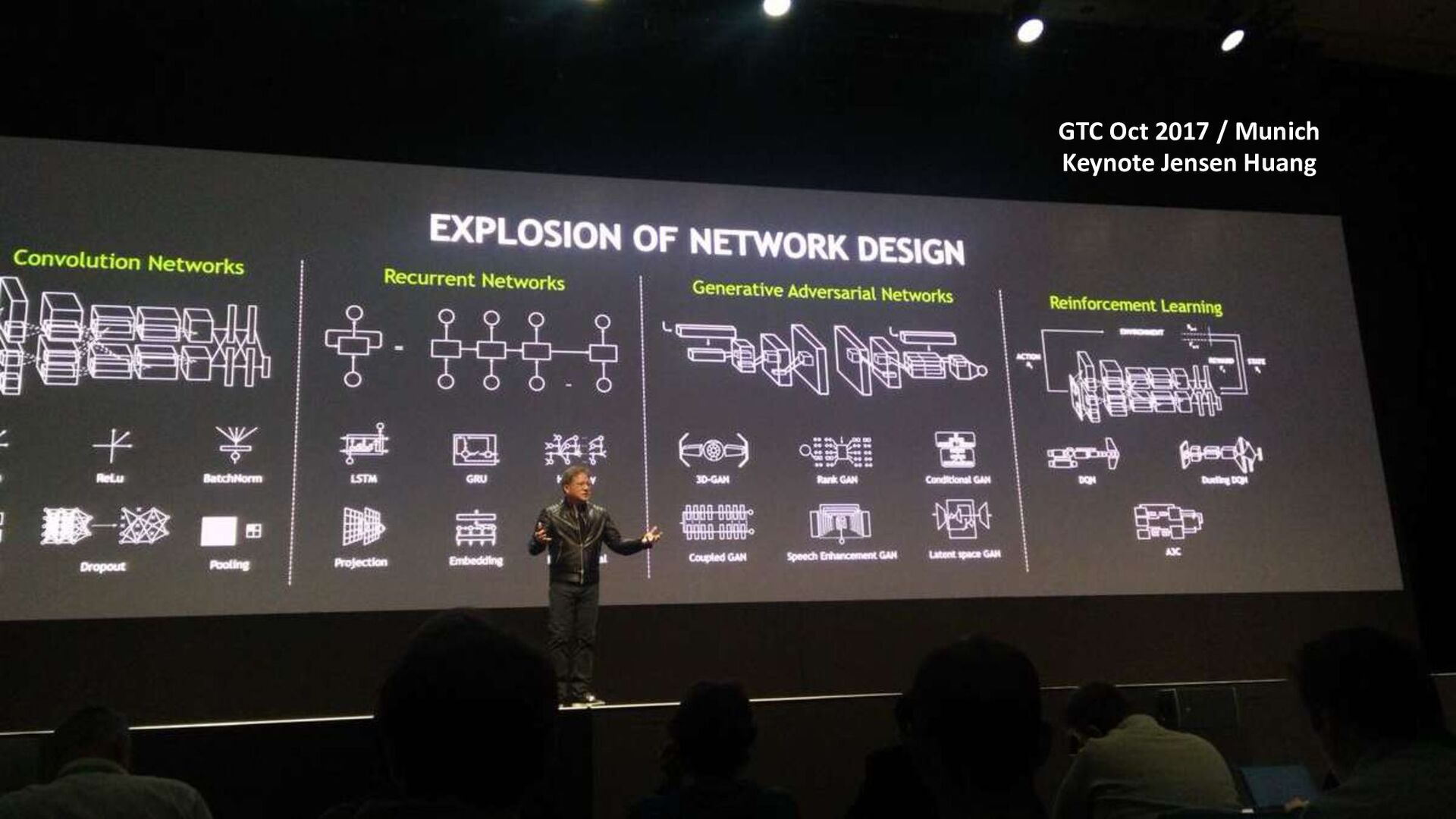{kind=link}
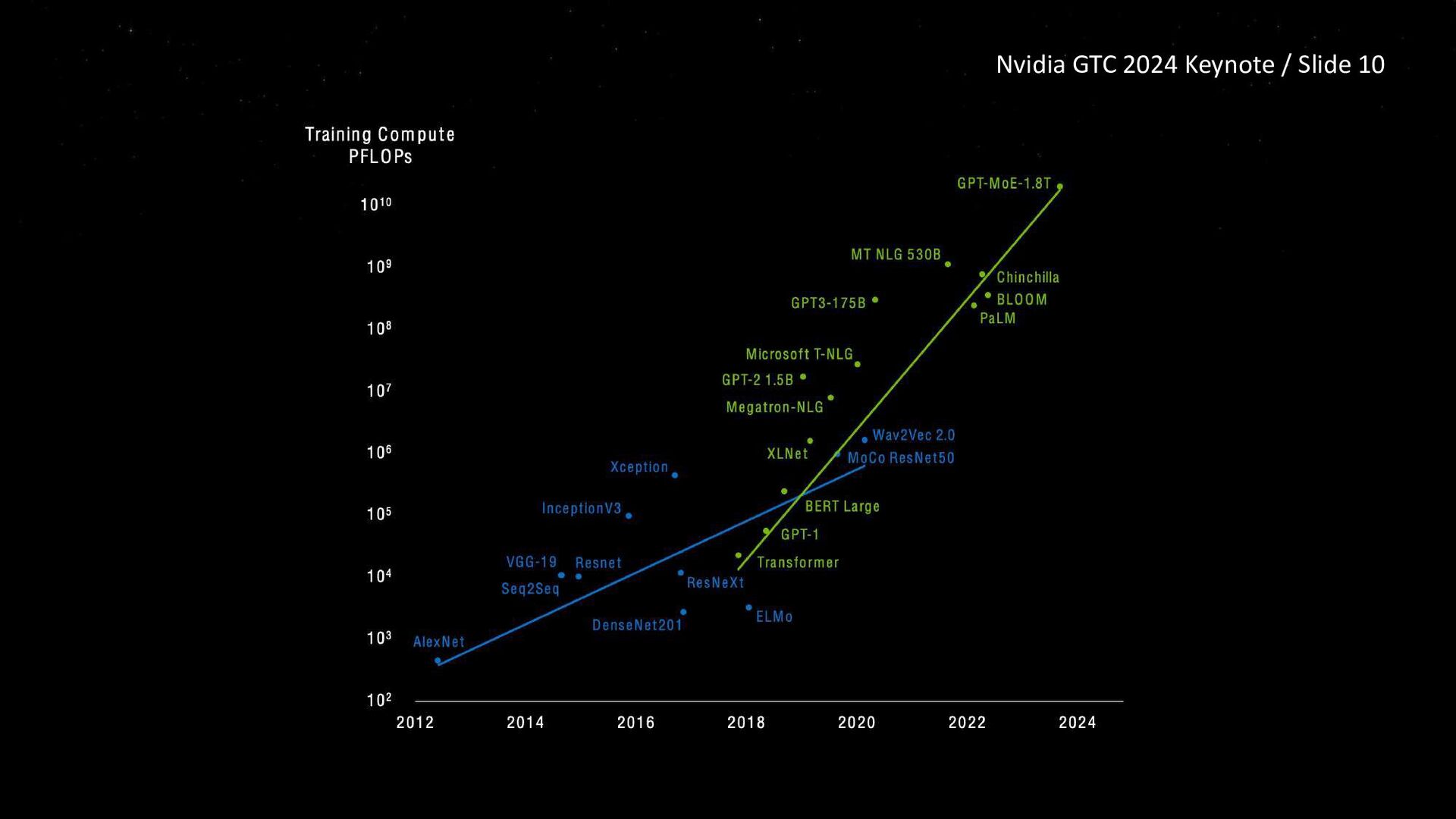{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
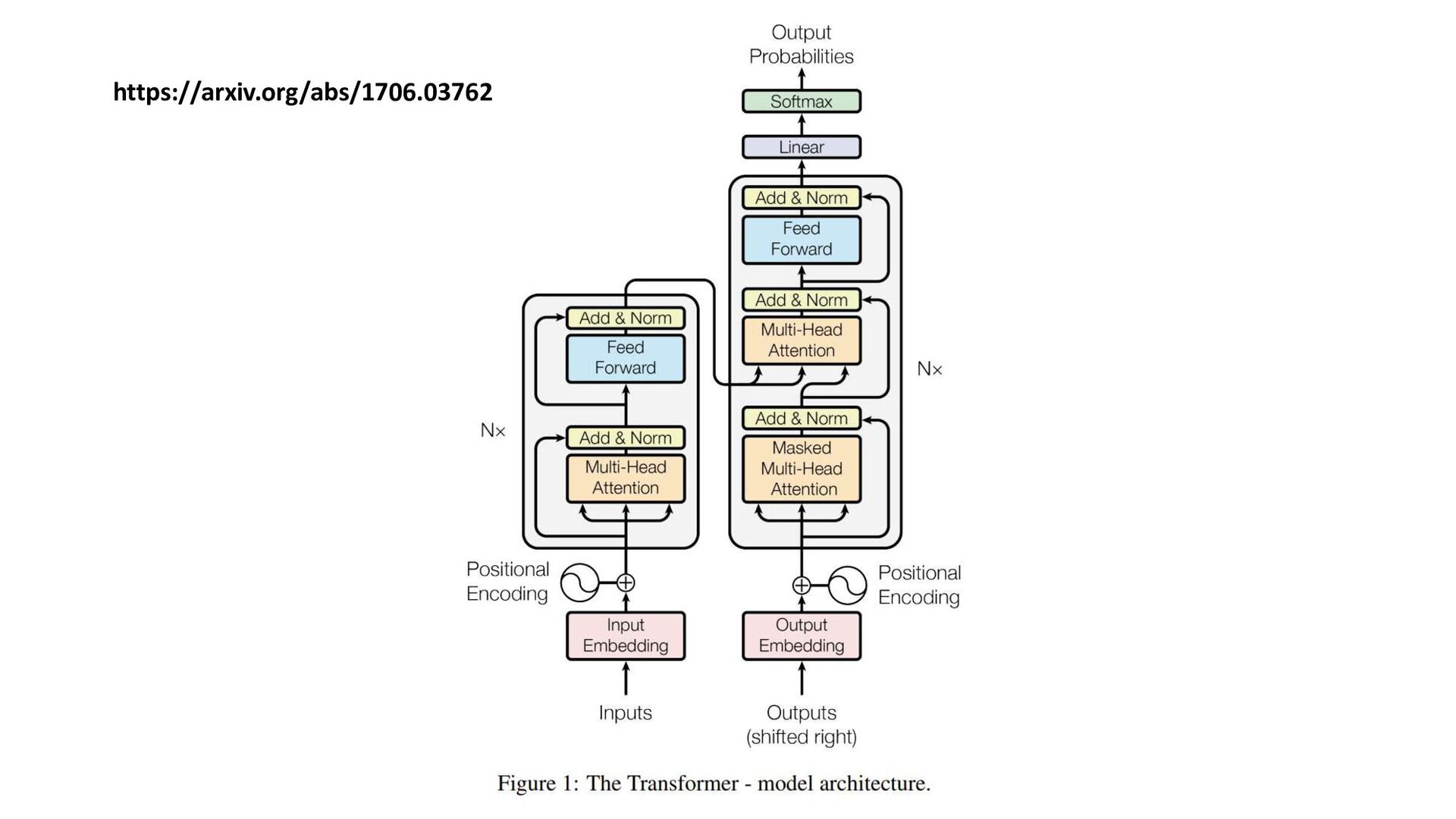{kind=link}
{kind=link}
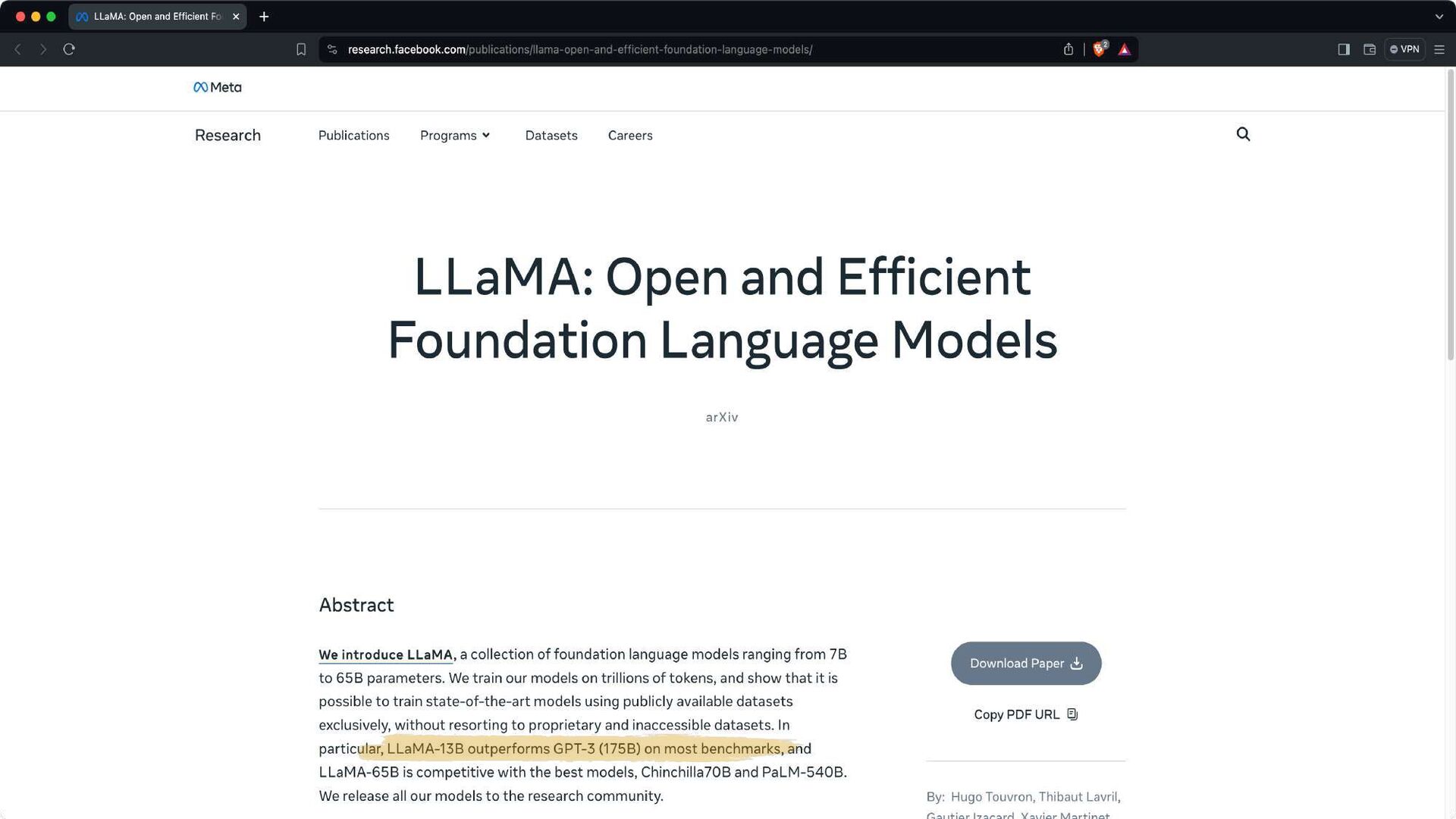{kind=link}
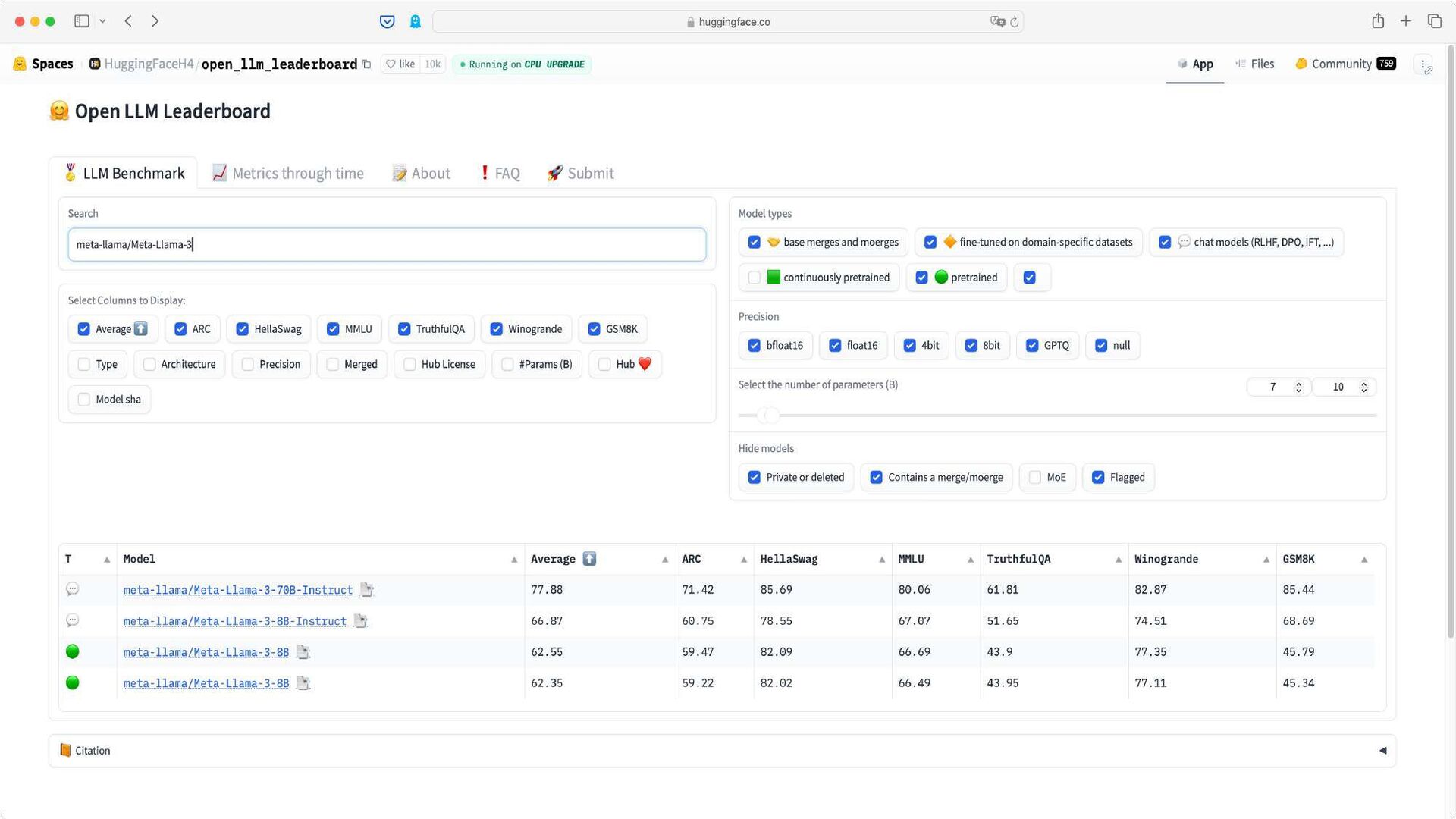{kind=link}
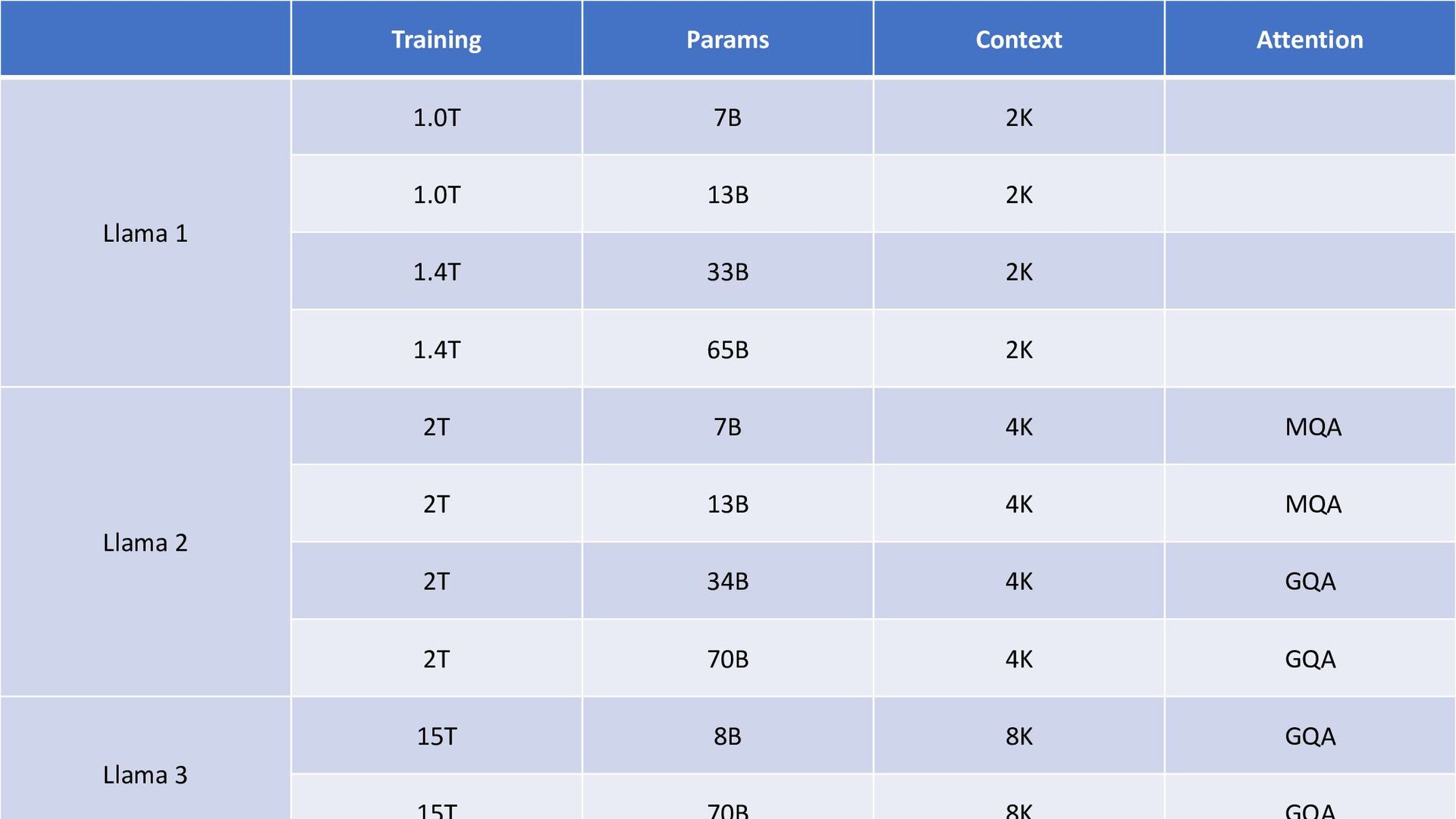{kind=link}
{kind=link}
{kind=link}
{kind=link}
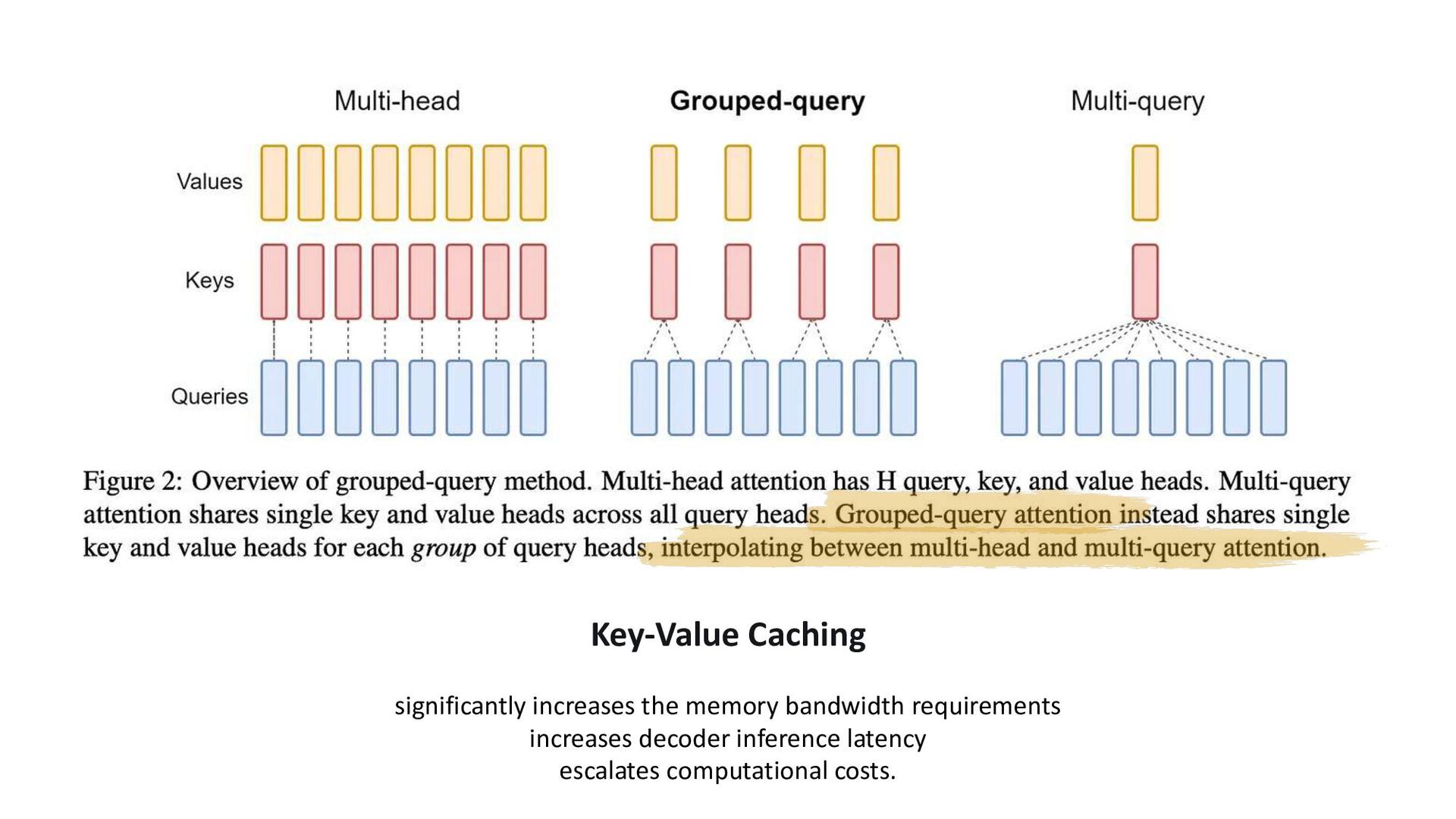{kind=link}
{kind=link}
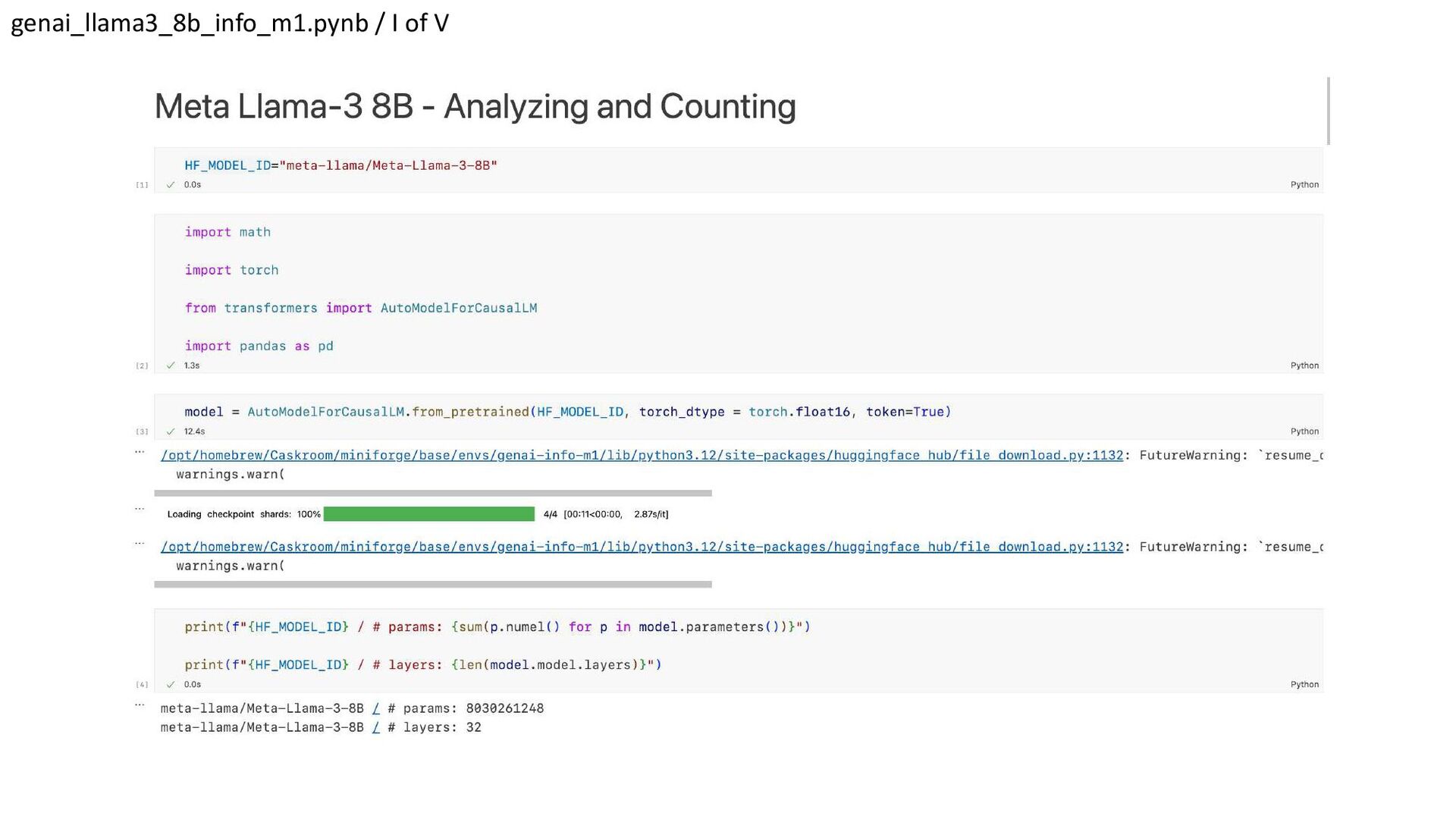{kind=link}
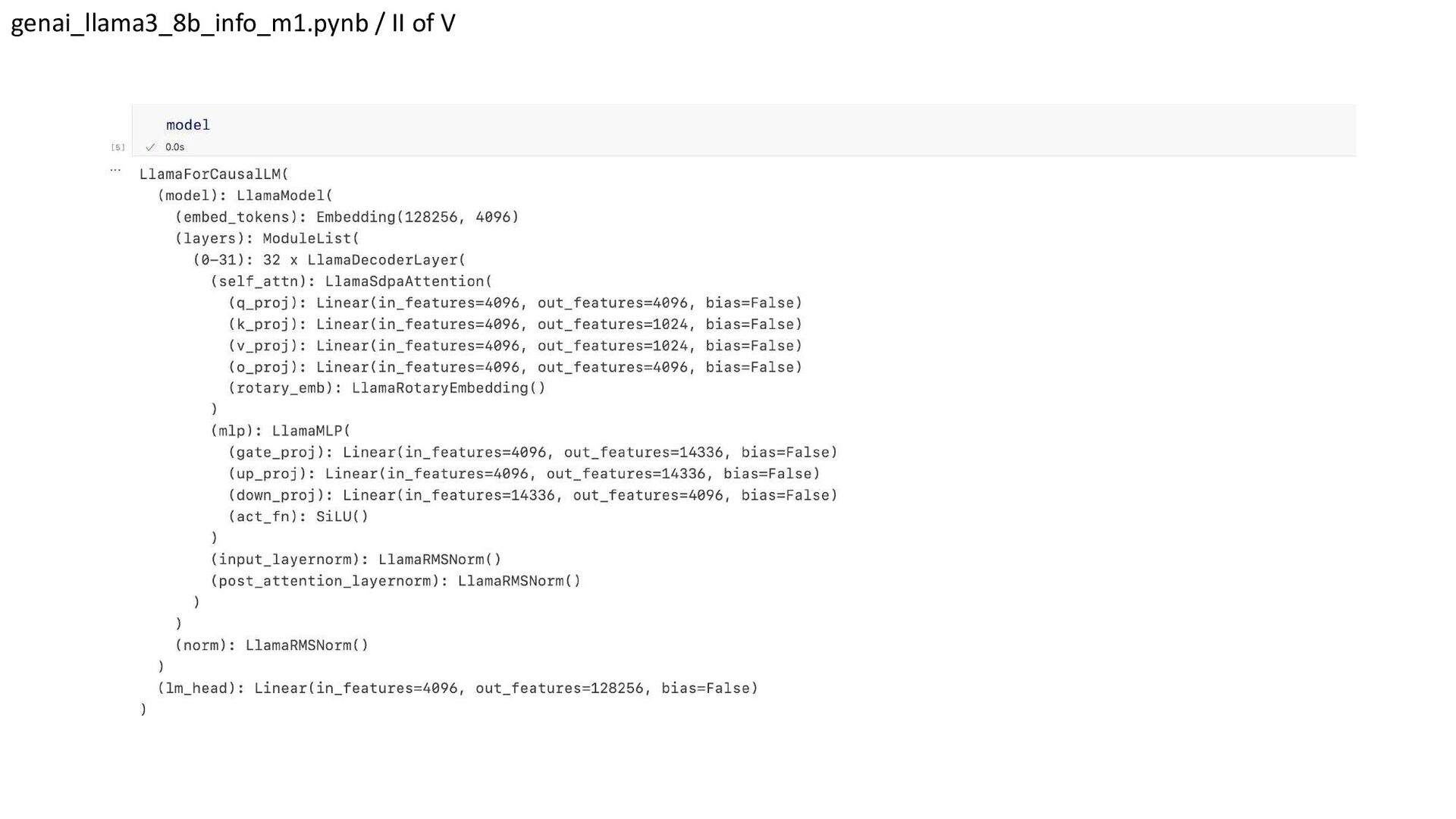{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
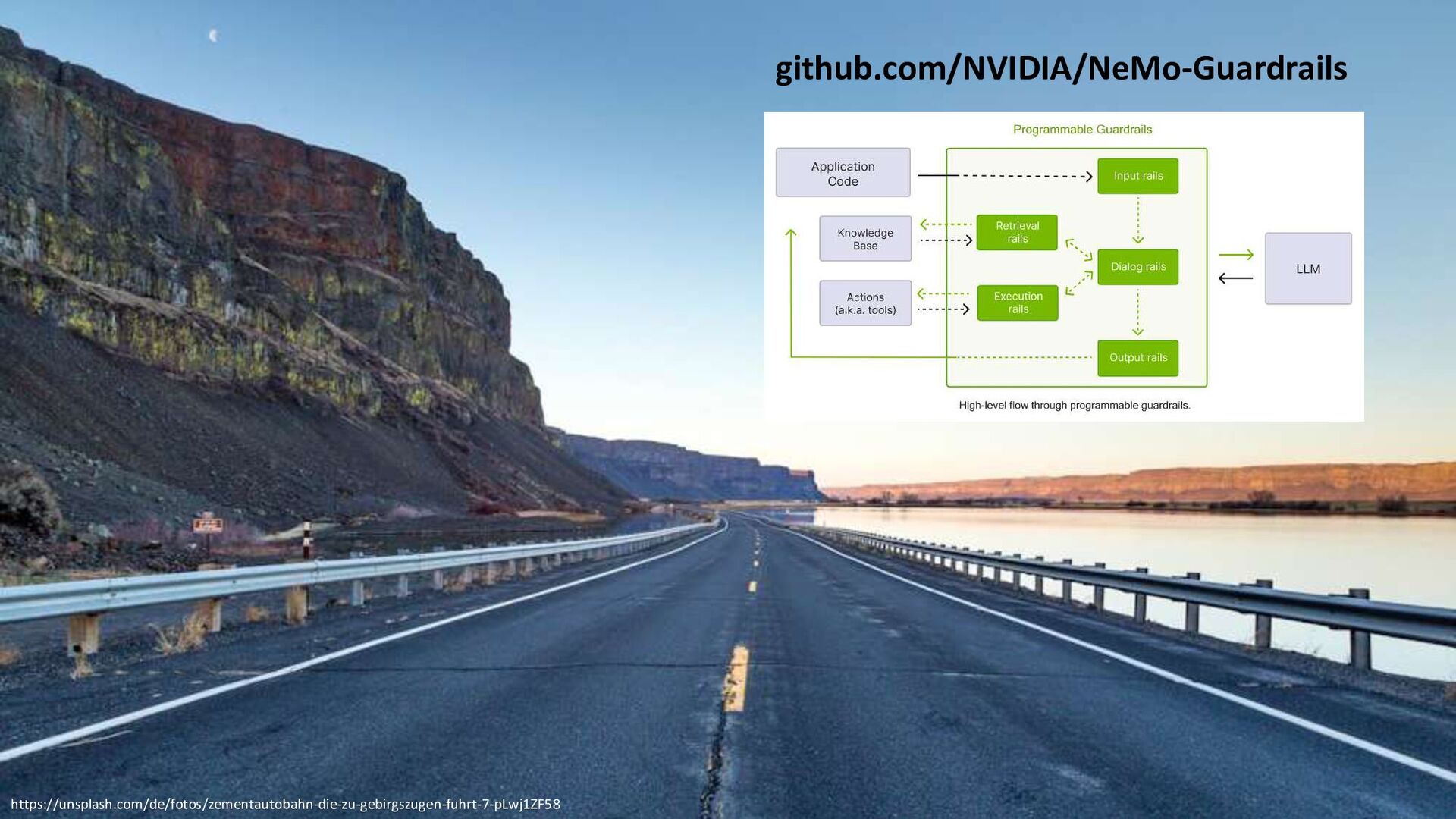{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
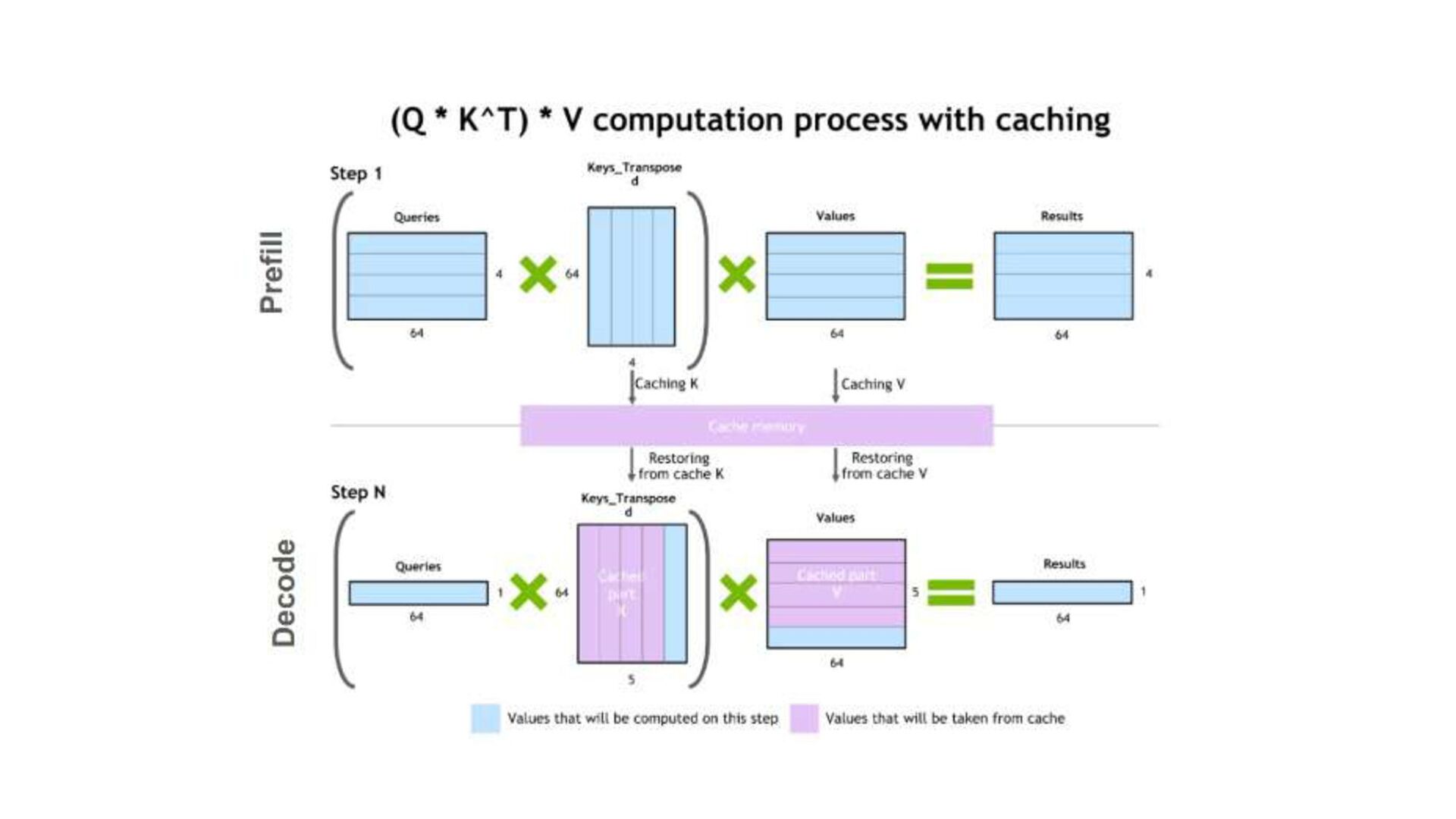{kind=link}
{kind=link}
{kind=link}
{kind=link}
![% ollama serve <<…>> [GIN-debug] POST /api/pull [GIN-debug] POST /api/generate](https://files.speakerdeck.com/presentations/7d0e2fe5d2a74d49a89ef81879f13d8e/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}