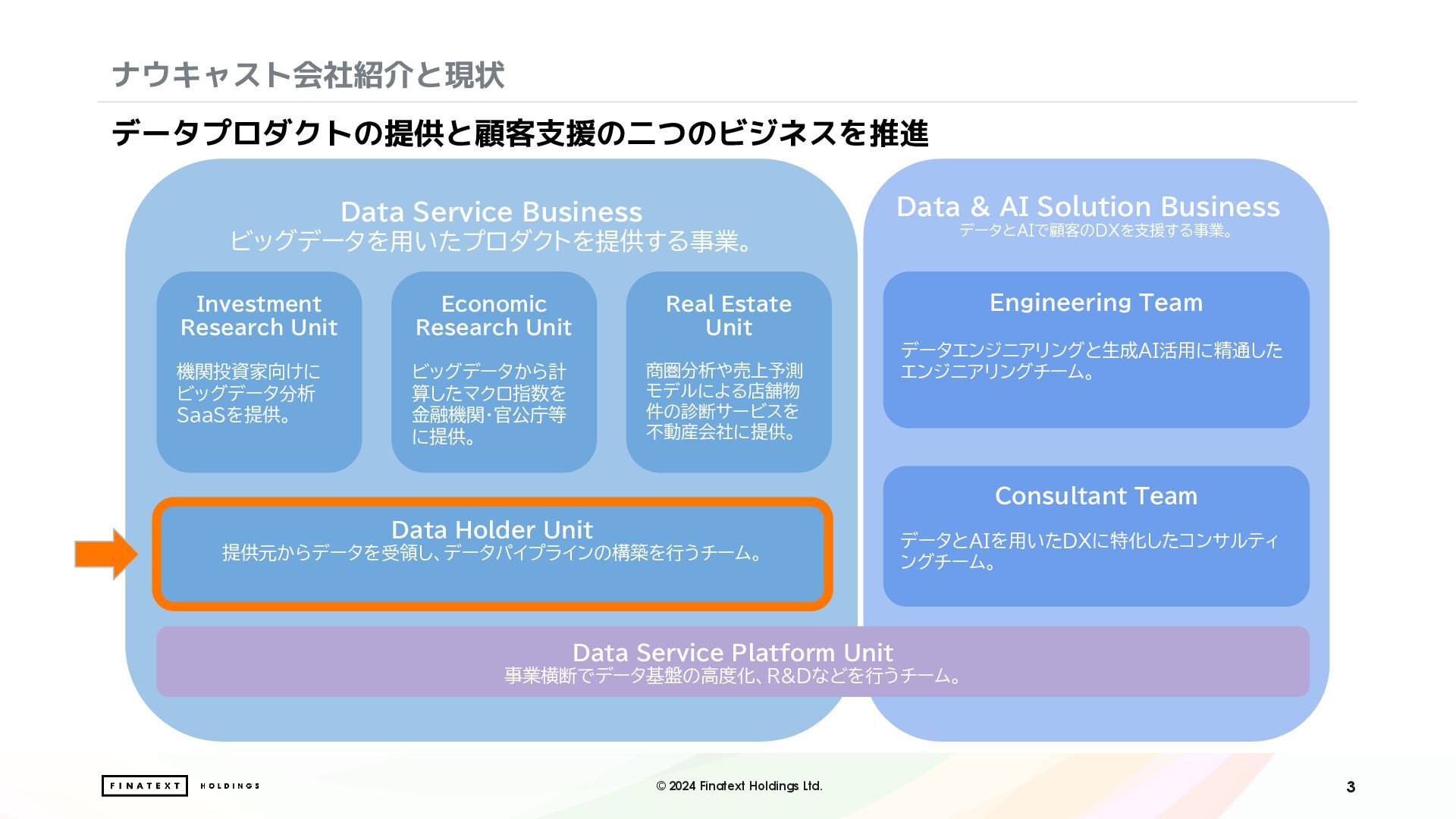
ビッグデータを用いたプロダクトを提供する事業。 Data & AI Solution Business データとAIで顧客のDXを支援する事業。 Data Service Platform Unit 事業横断でデータ基盤の高度化、R&Dなどを行うチーム。 Investment Research Unit 機関投資家向けに ビッグデータ分析 SaaSを提供。 Real Estate Unit 商圏分析や売上予測 モデルによる店舗物 件の診断サービスを 不動産会社に提供。 Data Holder Unit 提供元からデータを受領し、データパイプラインの構築を行うチーム。 Engineering Team データエンジニアリングと生成AI活用に精通した エンジニアリングチーム。 Consultant Team データとAIを用いたDXに特化したコンサルティ ングチーム。 Economic Research Unit ビッグデータから計 算したマクロ指数を 金融機関・官公庁等 に提供。 データプロダクトの提供と顧客支援の二つのビジネスを推進
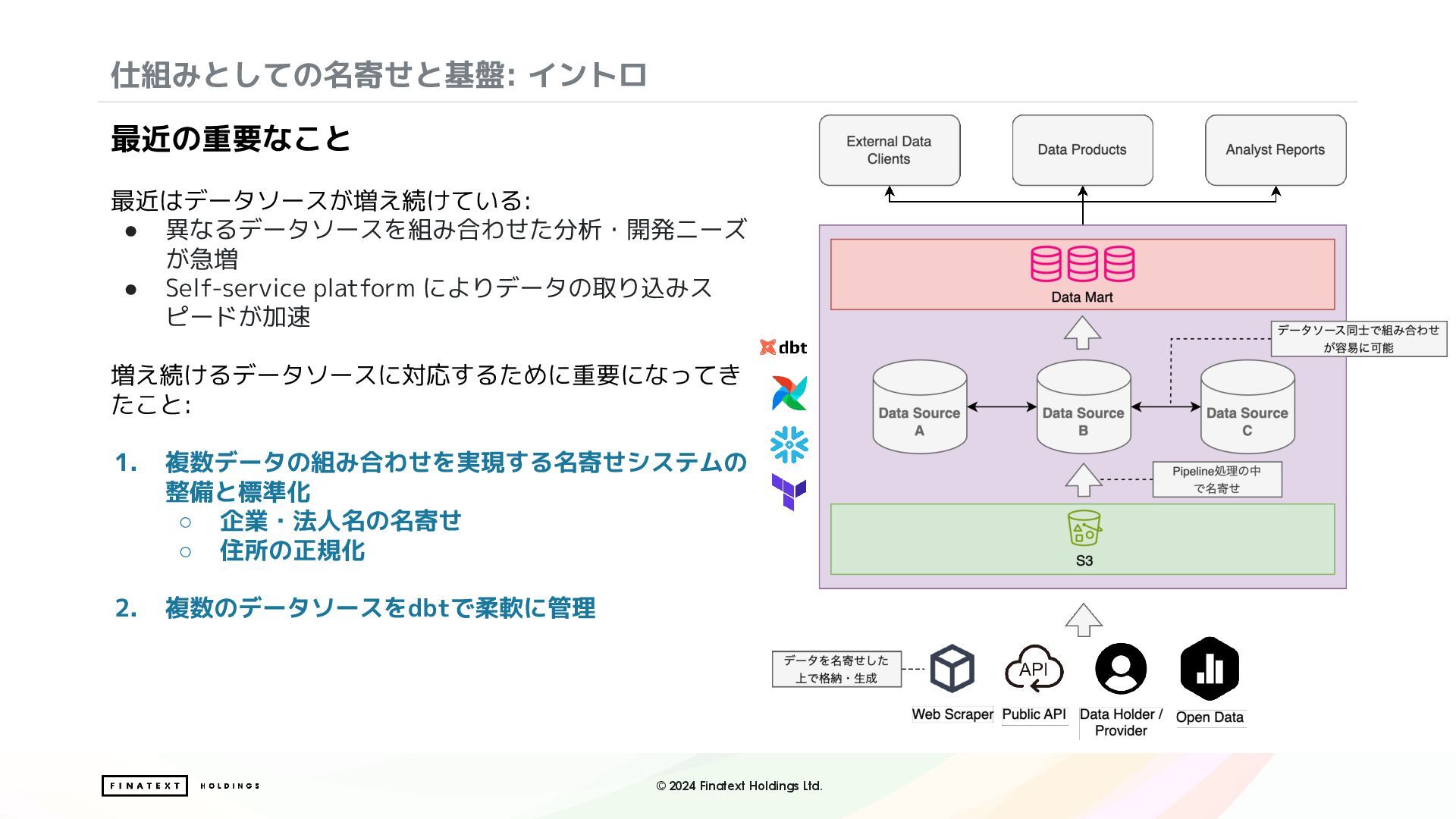
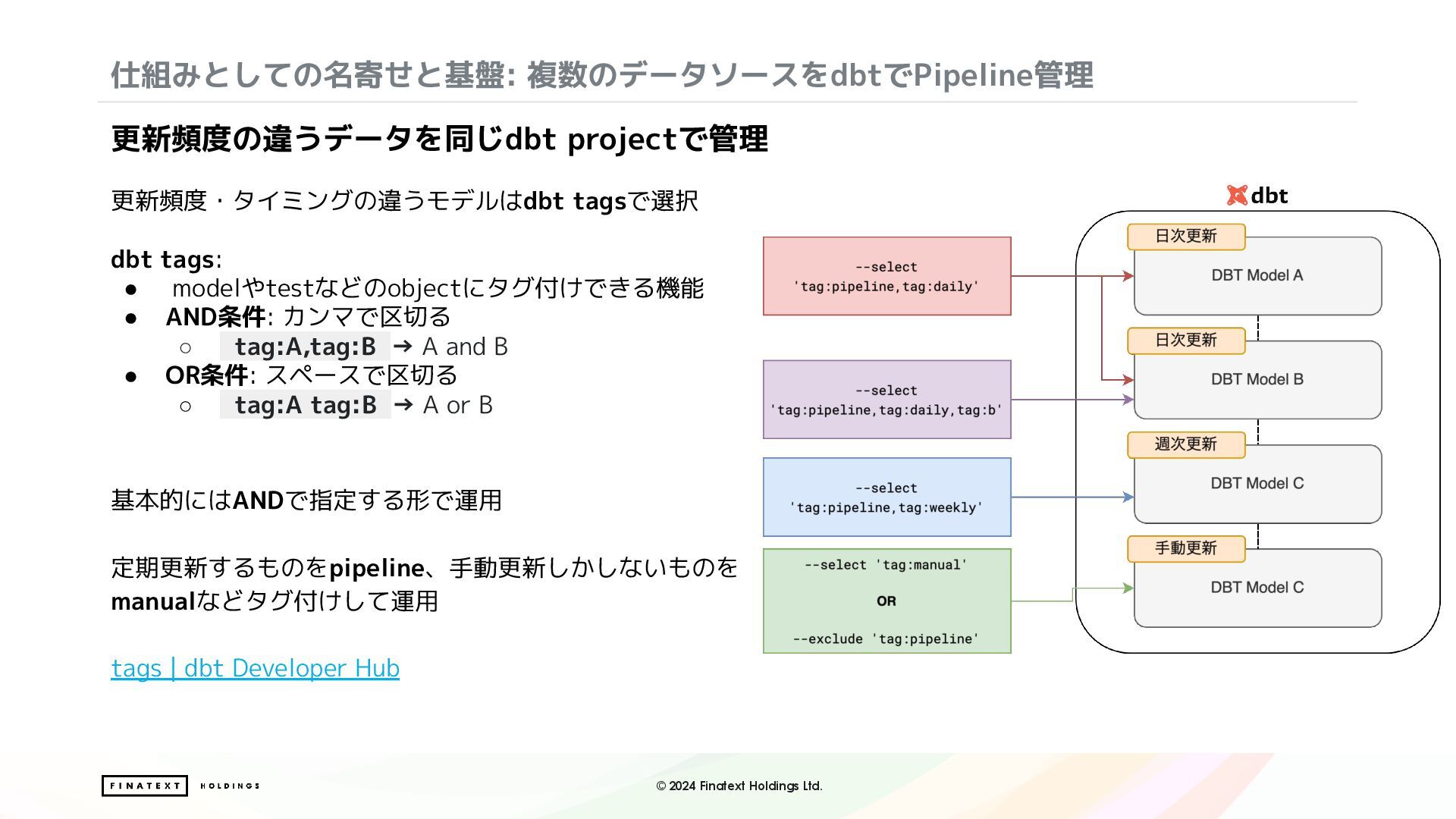
modelやtestなどのobjectにタグ付けできる機能 • AND条件: カンマで区切る ◦ _tag:A,tag:B_→ A and B • OR条件: スペースで区切る ◦ _tag:A tag:B_→ A or B 基本的にはANDで指定する形で運用 定期更新するものをpipeline、手動更新しかしないものを manualなどタグ付けして運用 tags | dbt Developer Hub 更新頻度の違うデータを同じdbt projectで管理 仕組みとしての名寄せと基盤: 複数のデータソースをdbtでPipeline管理
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© 2024 Finatext Holdings Ltd. 29 直近のチャレンジと動き [WIP] OpenMetadataの導入 (1/2)](https://files.speakerdeck.com/presentations/a1ddf1e6da8444b0b1984a29ccad80ee/slide_29.jpg){kind=link}
![© 2024 Finatext Holdings Ltd. 30 直近のチャレンジと動き [WIP] OpenMetadataの導入 (2/2)](https://files.speakerdeck.com/presentations/a1ddf1e6da8444b0b1984a29ccad80ee/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}