When we moved from single to multi-processor systems to run our programs faster, we created significant problems for language designers, compiler writers and programmers. Hardware and compiler optimisations can arbitrarily invalidate programs that ran correctly before, and makes the execution dependent on the machine you're running it on, which is not what you want.
To solve this, we need precise definitions of what is expected from compilers and programmers, serving as a contract between them, and a language's memory model provides just that.
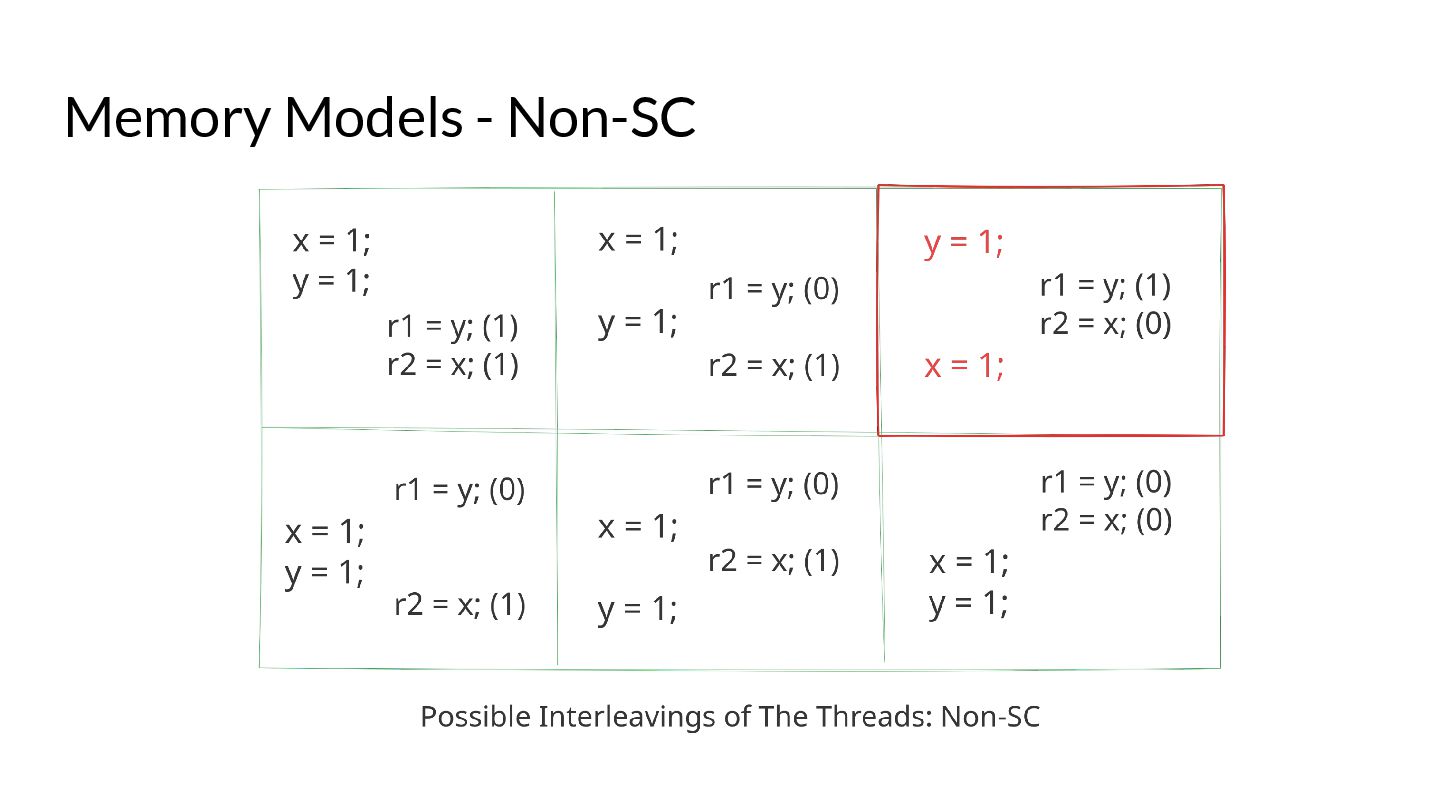
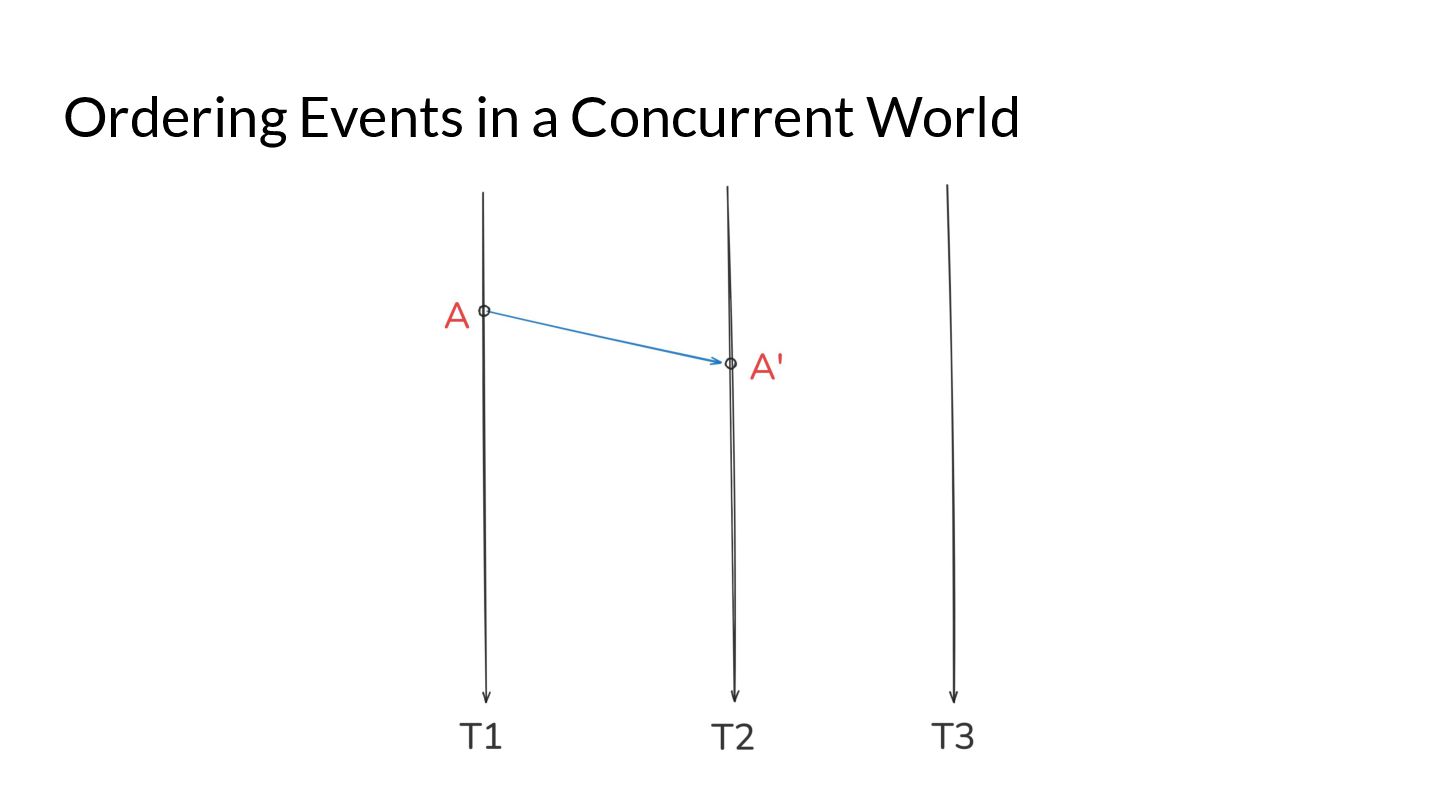
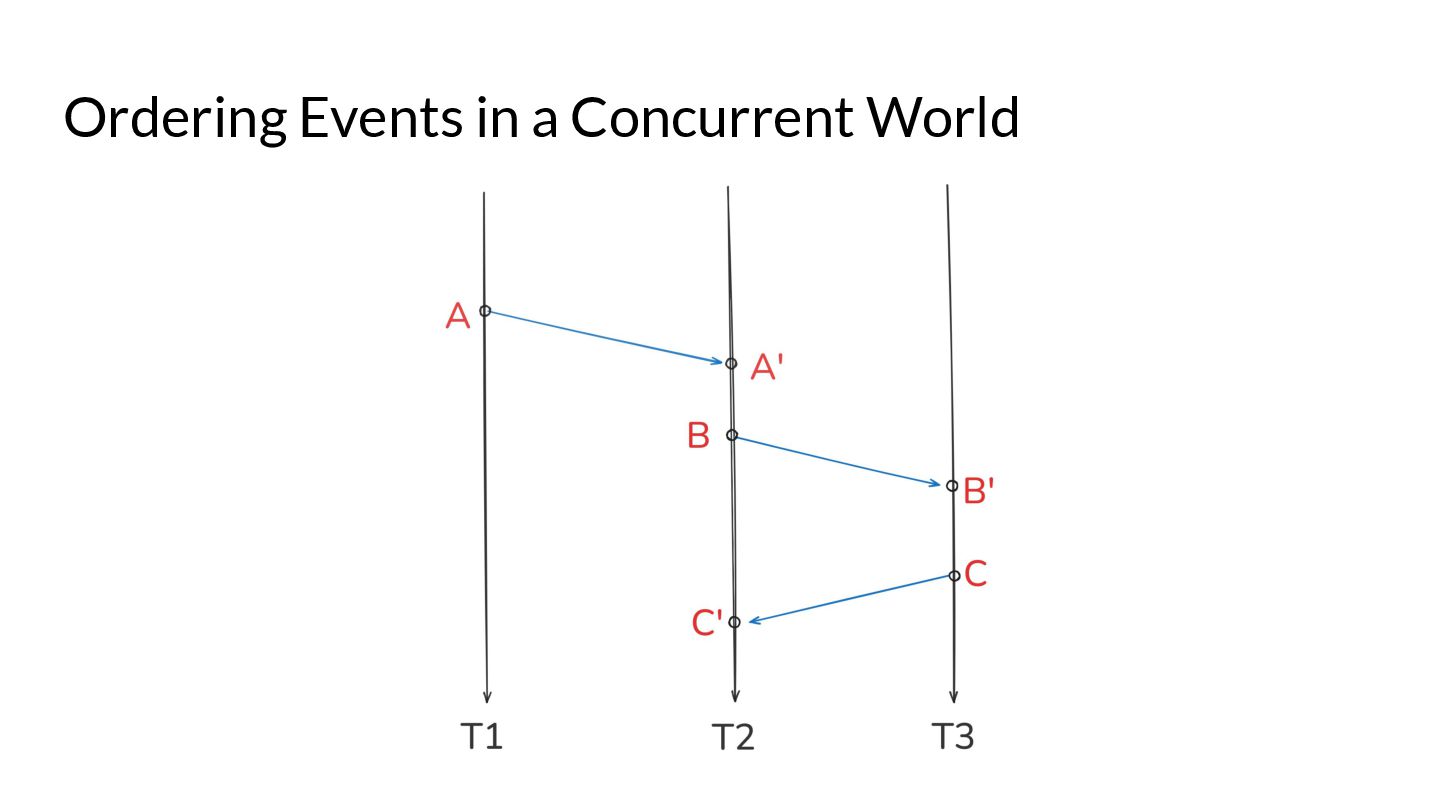
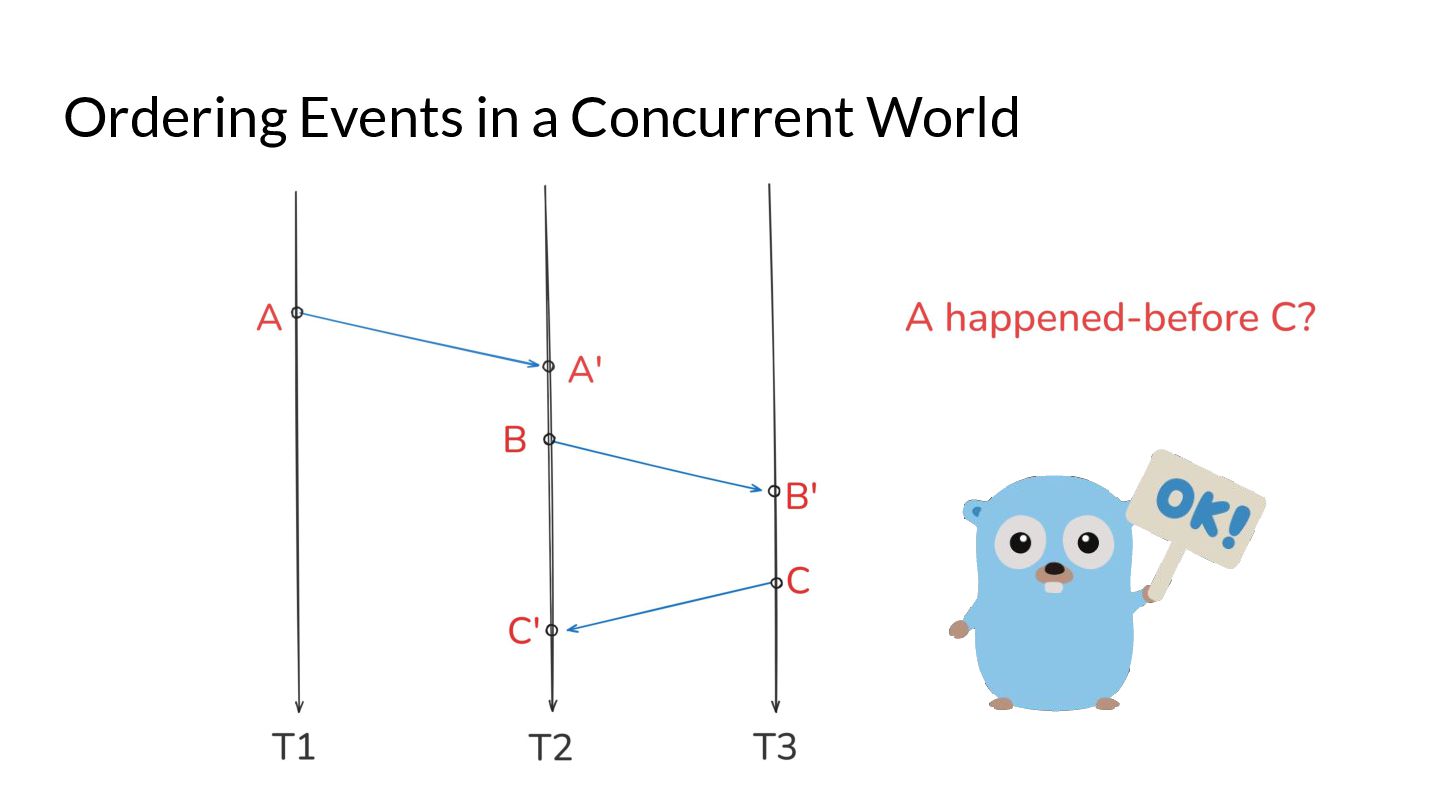
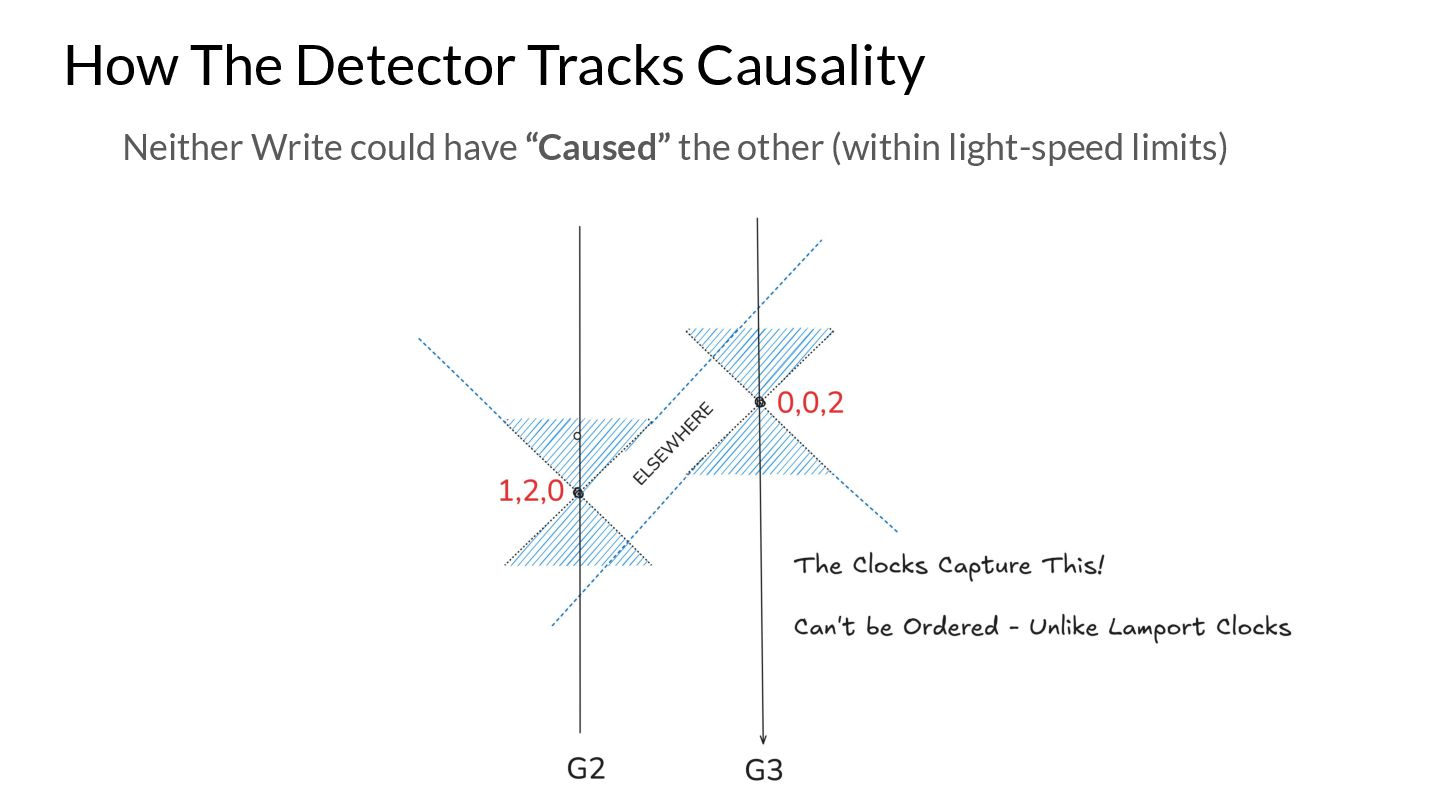
What are the optimisations that are allowed by Go compilers and the different hardware? What synchronisation mechanisms are provided by the language? What guarantees does a program without races have? These are questions that are expected to be answered by the Go memory model. We also look at how a Go developer can use existing Go semantics to achieve data race freedom by following simple rules, and achieve the gold standard of consistency models in their code - Sequential Consistency.
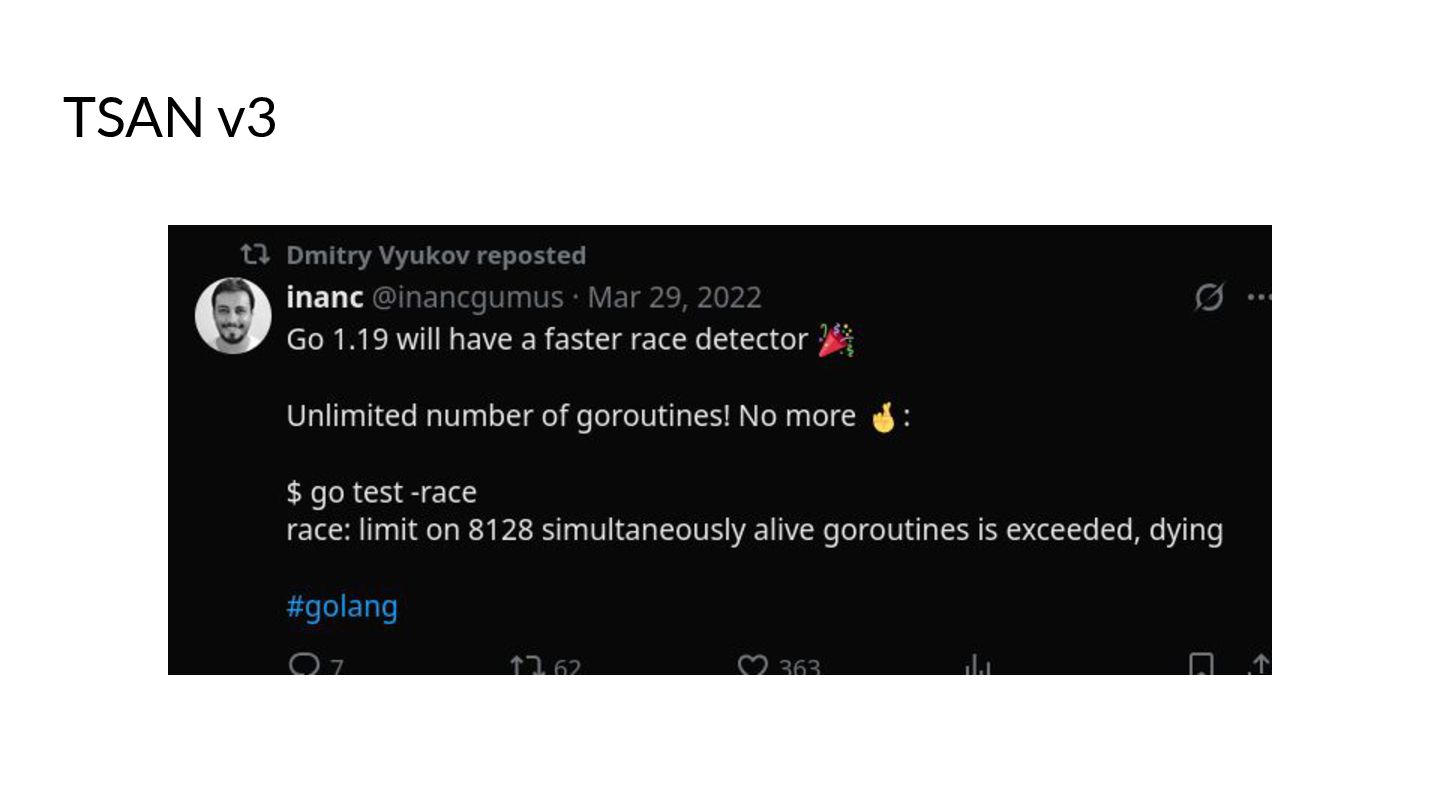
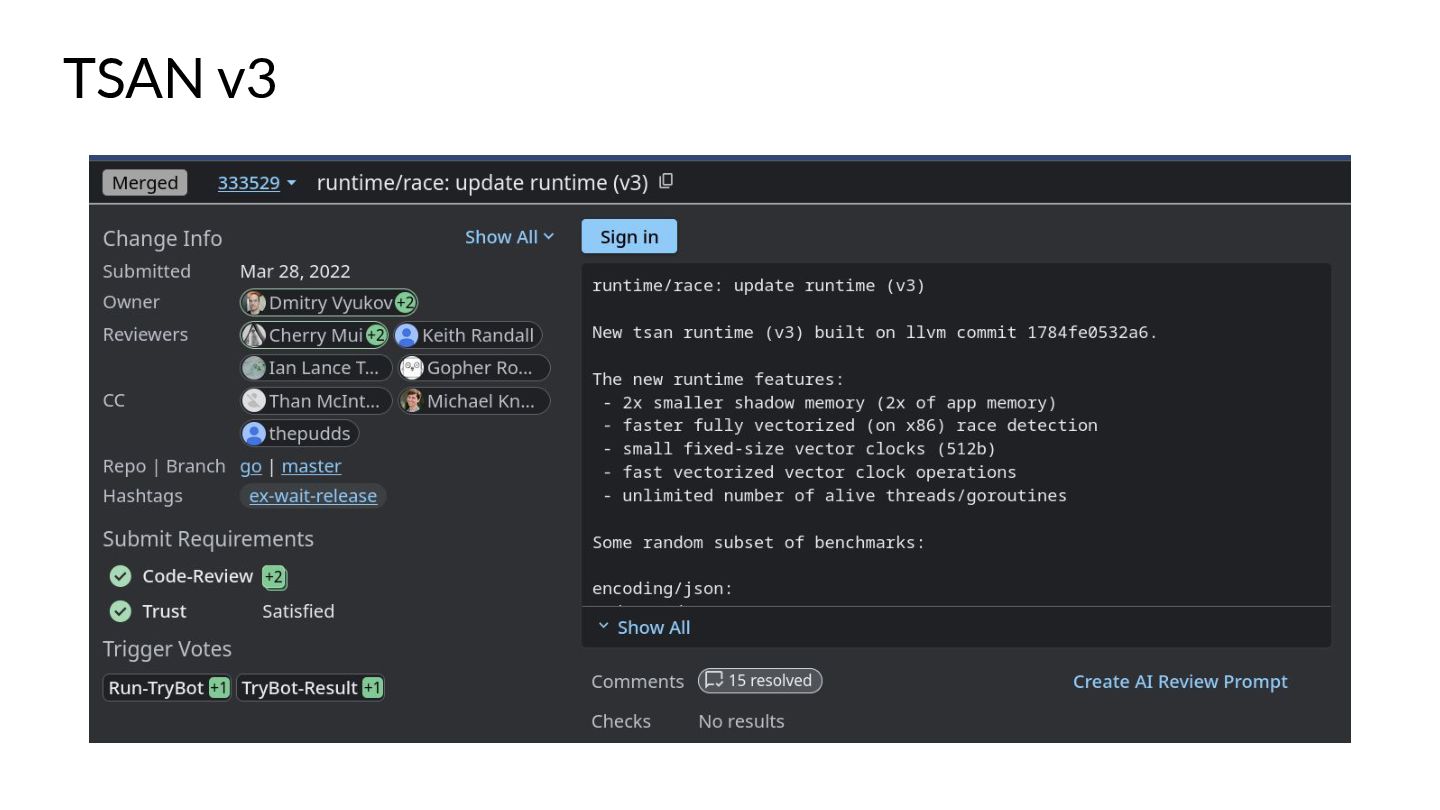
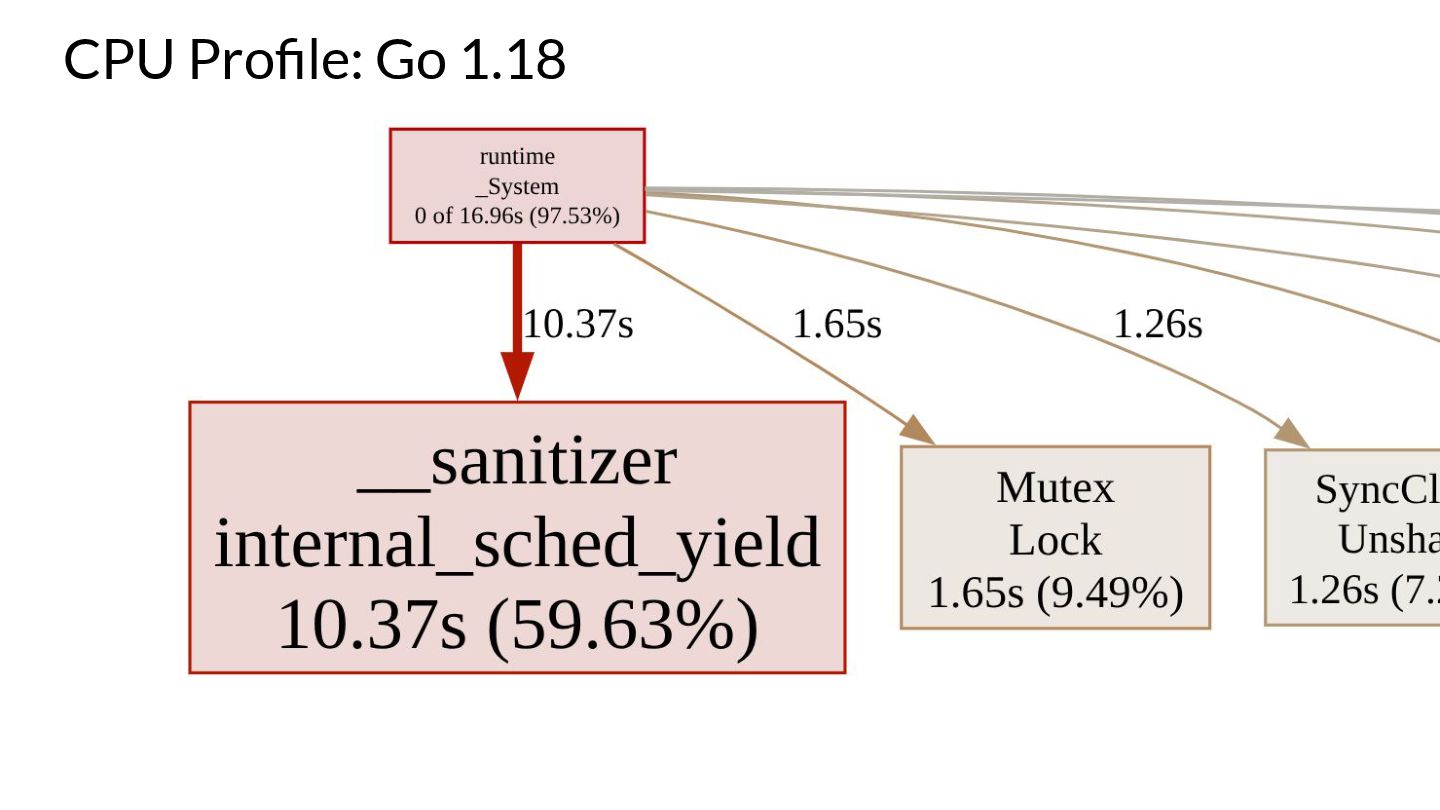
Go is also pre-packaged with a Race Detector based on LLVM's TSAN v2, that can help you find pesky race conditions in your code during run-time. We will dive into the internals of it briefly, as well as discuss the new changes the latest TSAN v3 brings! How TSAN managed to improve it's detector drastically will be highlighted in the presentation as this new version was ported to the later versions of Go.
Finally the demo segment of the talk will dive into the buggy examples covered in the Data Race Freedom section, and we will try to see if the race detector can flag these bugs. We will also put TSAN v2 and v3 head to head, profiling them as they race to find these races to look under the hood at what's changed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
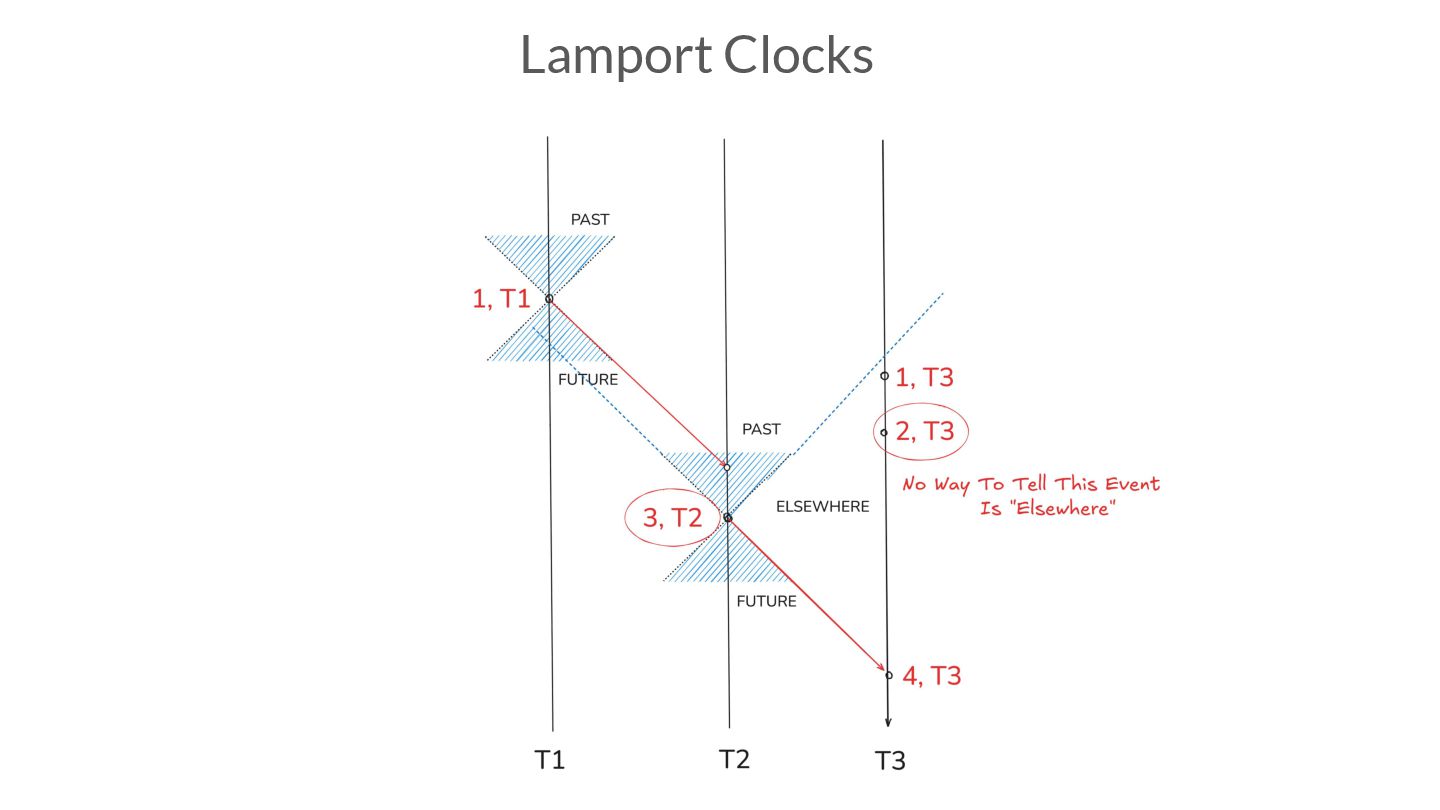{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
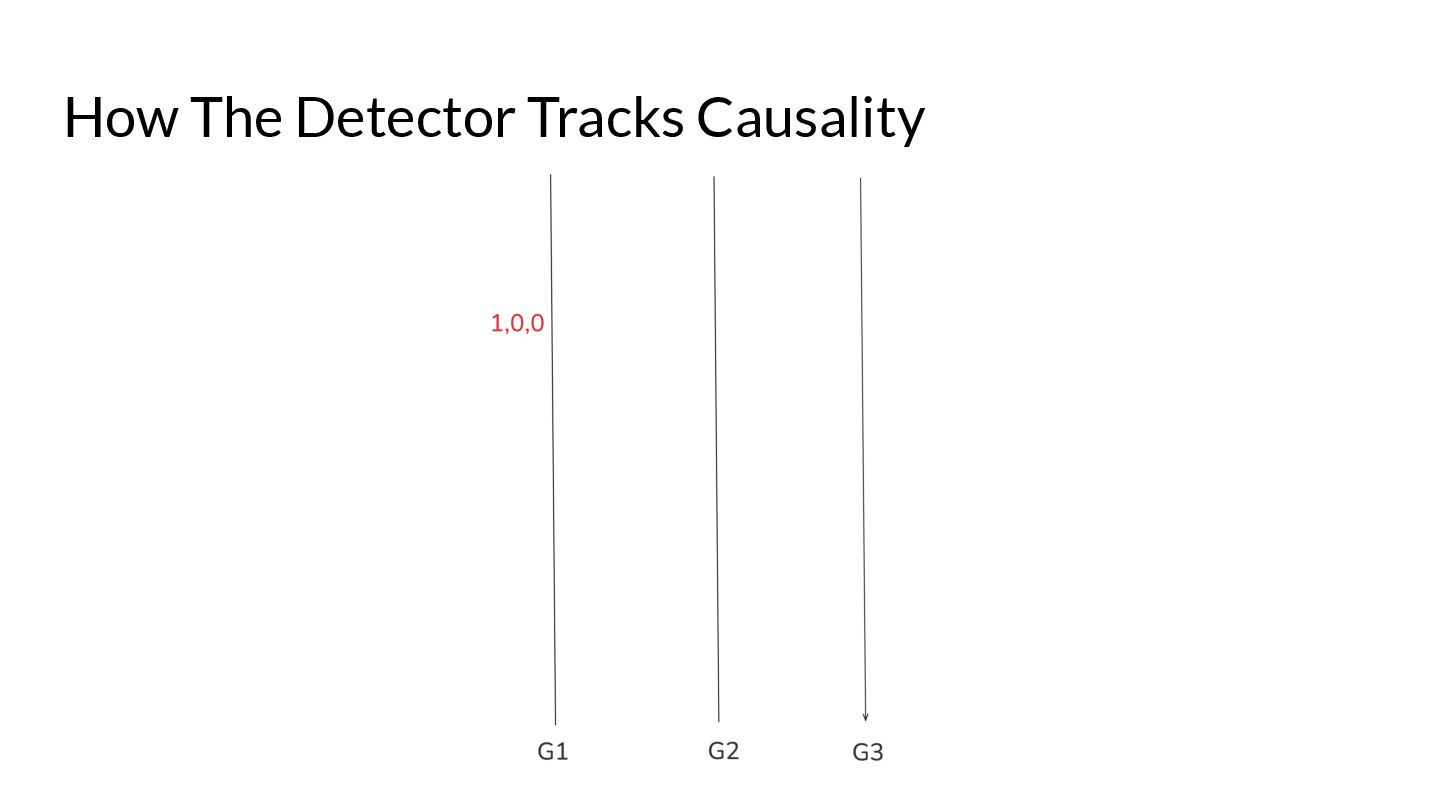{kind=link}
{kind=link}
{kind=link}
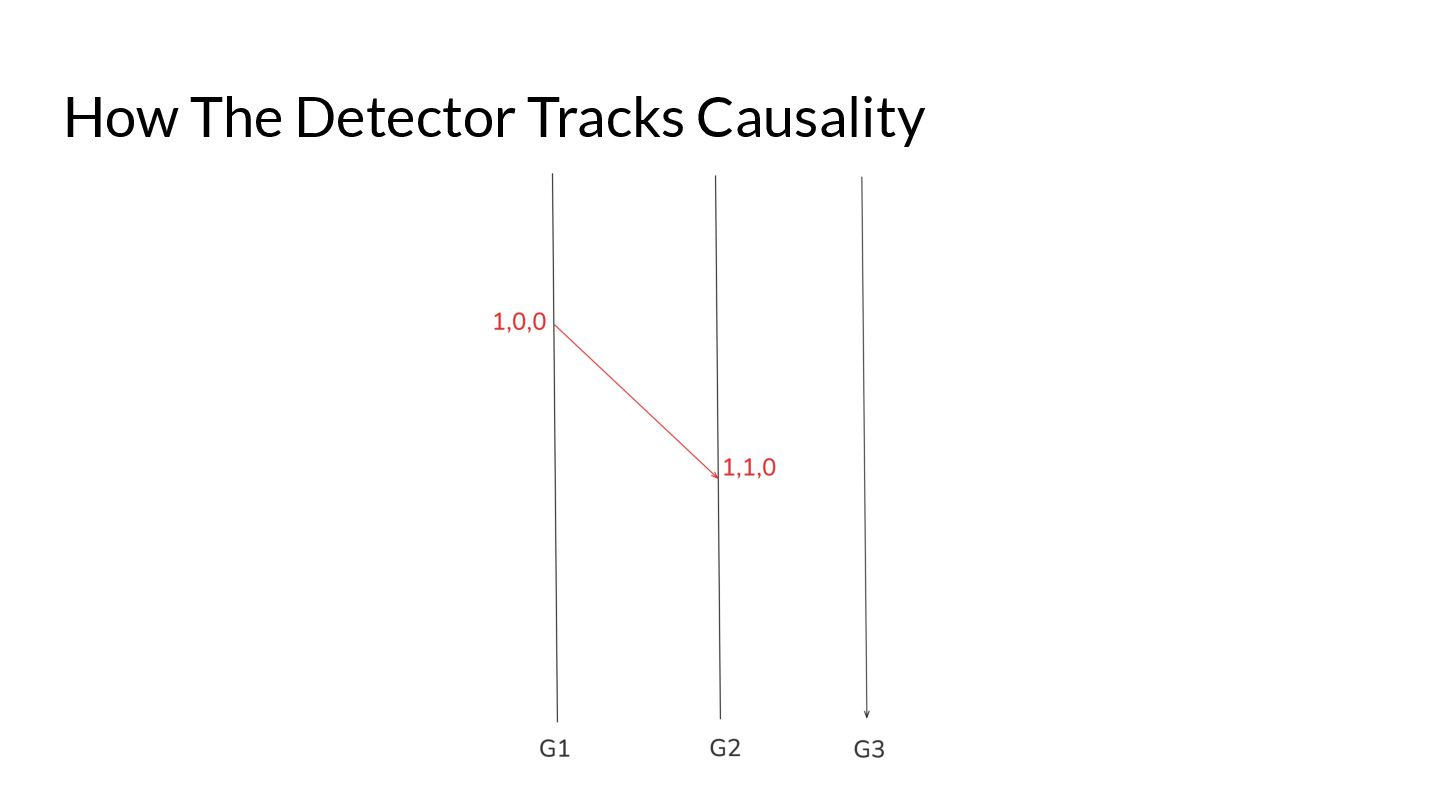{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
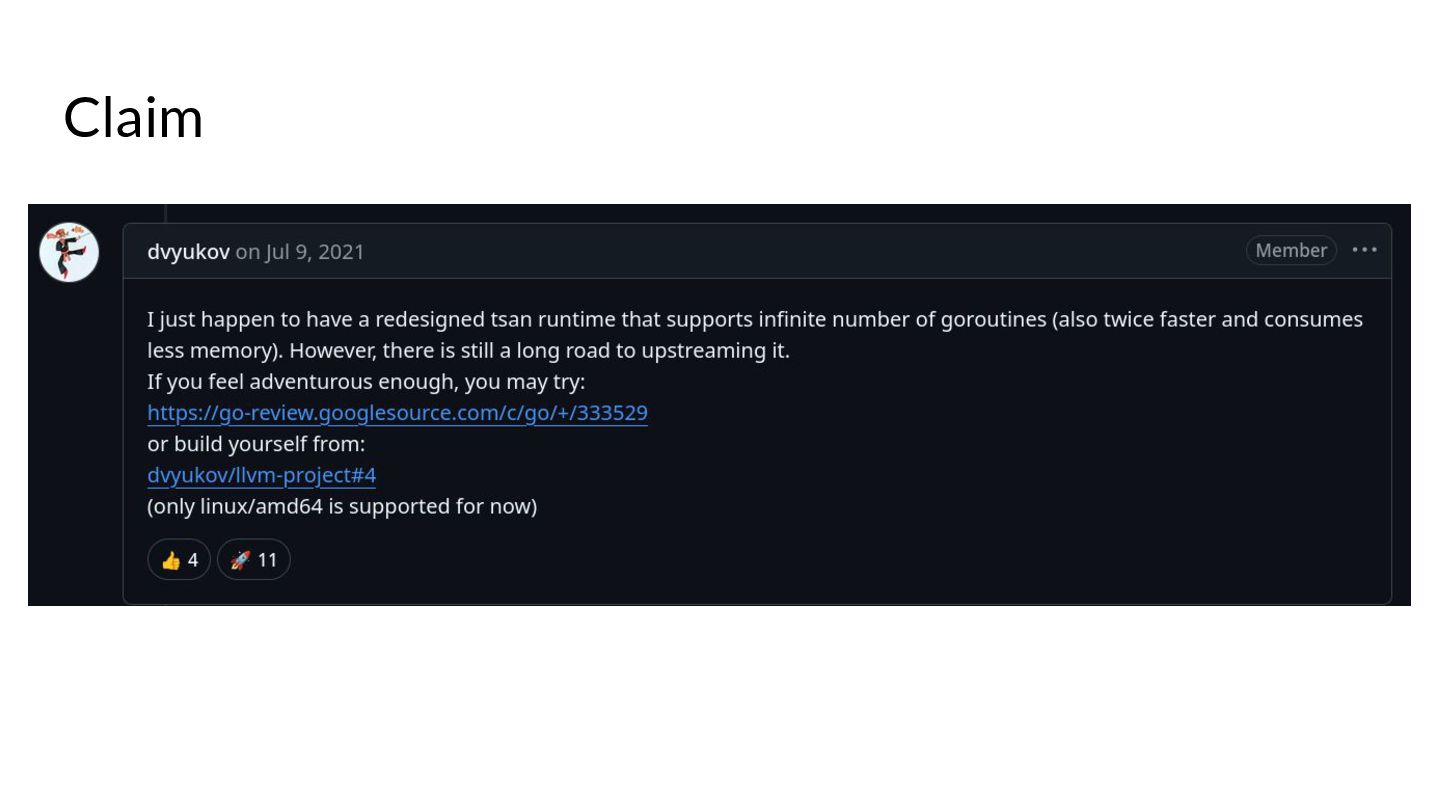{kind=link}
{kind=link}
{kind=link}
{kind=link}
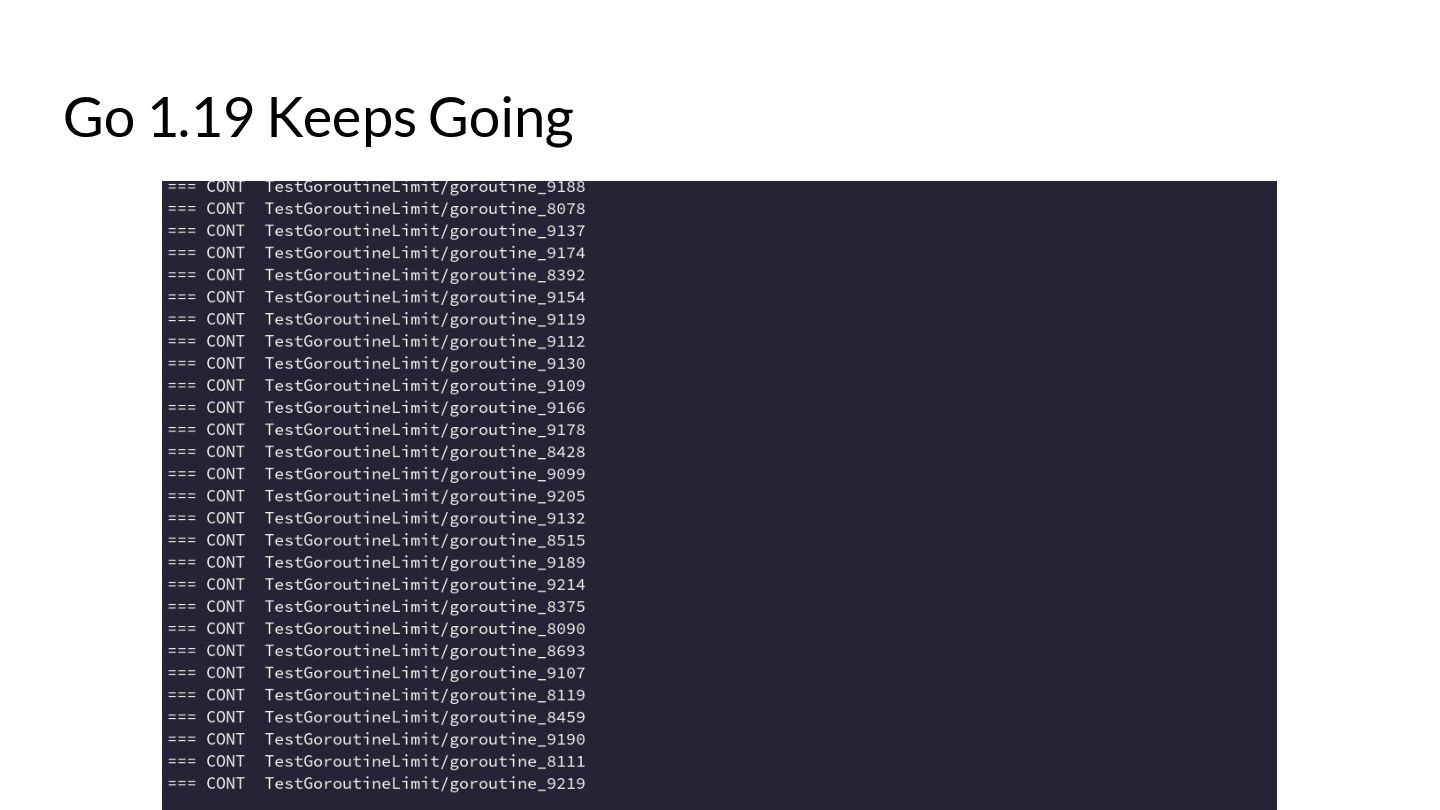{kind=link}
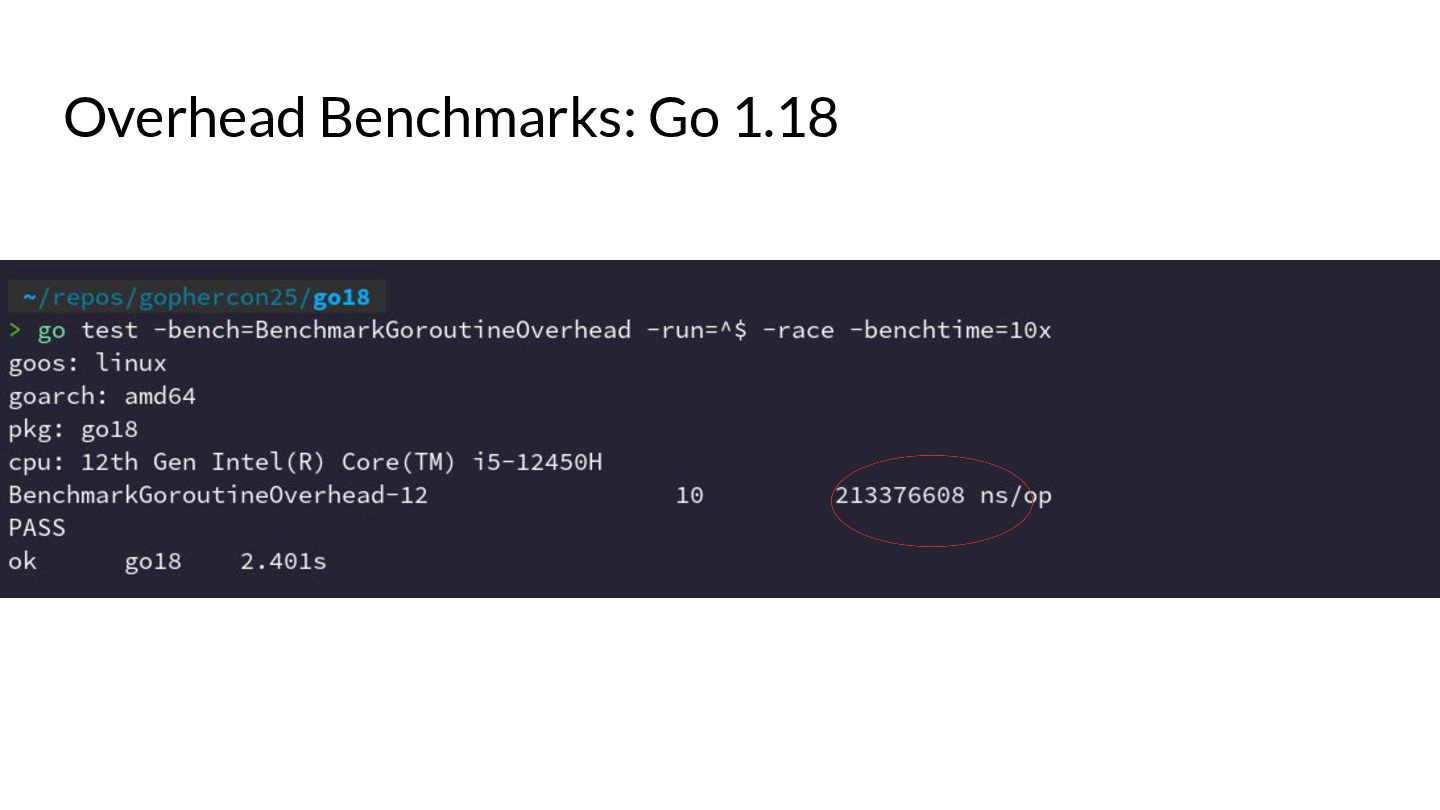{kind=link}
{kind=link}
{kind=link}
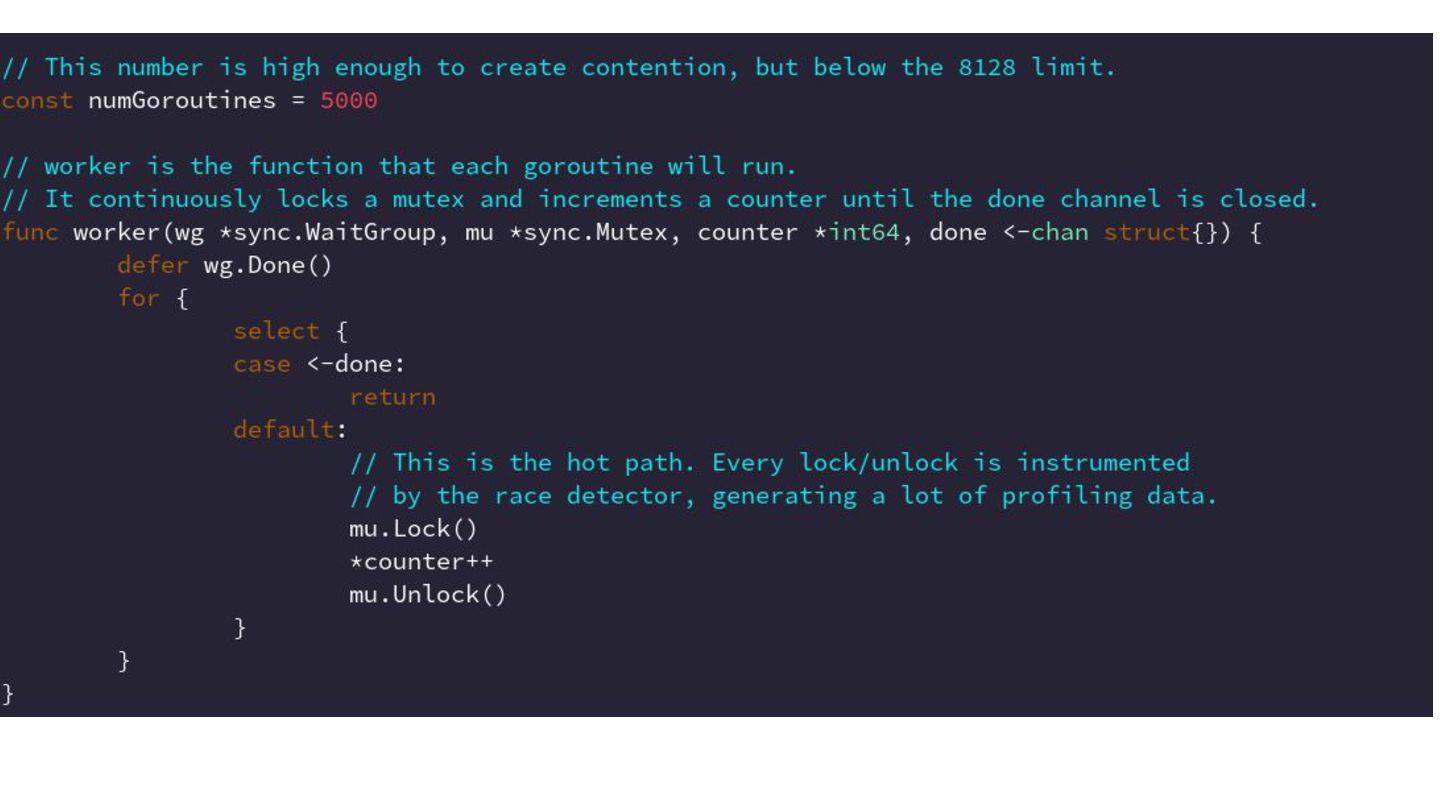{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}