C群のCTR(過去のデータから30%とわかっている) 1 p2 = 0.31, # T群のCTR(1%ptの効果量を仮定) 2 sig.level = 0.05, # 有意水準α(真に差がない時に誤って帰無仮説を棄却してしまう割合) 3 power = 0.8) # 検出力β(真に差がある時に正しく差を検出できる割合) 4 Two-sample comparison of proportions power calculation n = 33274.15 p1 = 0.3 p2 = 0.31 sig.level = 0.05 power = 0.8 alternative = two.sided NOTE: n is number in *each* group
各日付に対して、impressionが発生するかどうかをサンプル 発生した場合 k 1, 2, … , k pi ∼ Beta(3.0, 7.0) is_impressioni ∼ Bernoulli(0.5) Ni ∼ Uniform(1, 100) Si ∼ Binomial(is_impressioni, pi)
K, Diane T, Ya X. A/Bテスト実践ガイド. アスキードワンゴ; 2021. Kohavi R, Longbotham R, Sommerfield D, Henne RM. Controlled experiments on the web: Survey and practical guide. Data Min Knowl Discov. 2009;18(1):140-181. doi: gota morishita. なぜAAテストにおけるp値は一様分布になるのか?. 2021. Deng A, Knoblich U, Lu J. Applying the delta method in metric analytics: A practical guide with novel ideas. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. KDD ’18. Association for Computing Machinery; 2018:233-242. doi: Taro T. 統計指標の信頼区間を評価する delta method とその応用(論文紹介). 2018. 中村. 検索エンジンのABテストで発生するユーザー内相関を突破する. 2021. 伊藤, 藤田. なぜあなたのA/Bテストはうまくいくのか?a/Bテストの分析で注 意すること. 2021. 伊藤寛武, 金子雄祐. Pythonで学ぶ効果検証入門. オーム社; 2024. 10.1007/s10618-008-0114-1 https://zenn.dev/morishita/articles/3c77d00b303c76 10.1145/3219819.3219919 https://engineering.linecorp.com/ja/blog/delta-method https://www.m3tech.blog/entry/search-ab https://developers.cyberagent.co.jp/blog/archives/33310/
A. All about sample-size calculations for a/b testing: Novel extensions & practical guide. In: Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. CIKM ’23. Association for Computing Machinery; 2023:3574-3583. doi: https://www.szdrblog.info/entry/2018/11/18/154952 10.1145/3583780.3614779
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![サンプルサイズ設計 有意水準0.05、検出力0.80の両側検定として設計 必要なimpression数は各群33275件 各群で必要なユーザー数を計算 過去のデータでは、1ユーザーあたりの平均impression数は353.5件らしい [必要impression数]/[平均impression数]=33275/353.5=95人 power.prop.test(p1 = 0.30, #](https://files.speakerdeck.com/presentations/10b462fb28004d9884bdffb3f69e0715/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
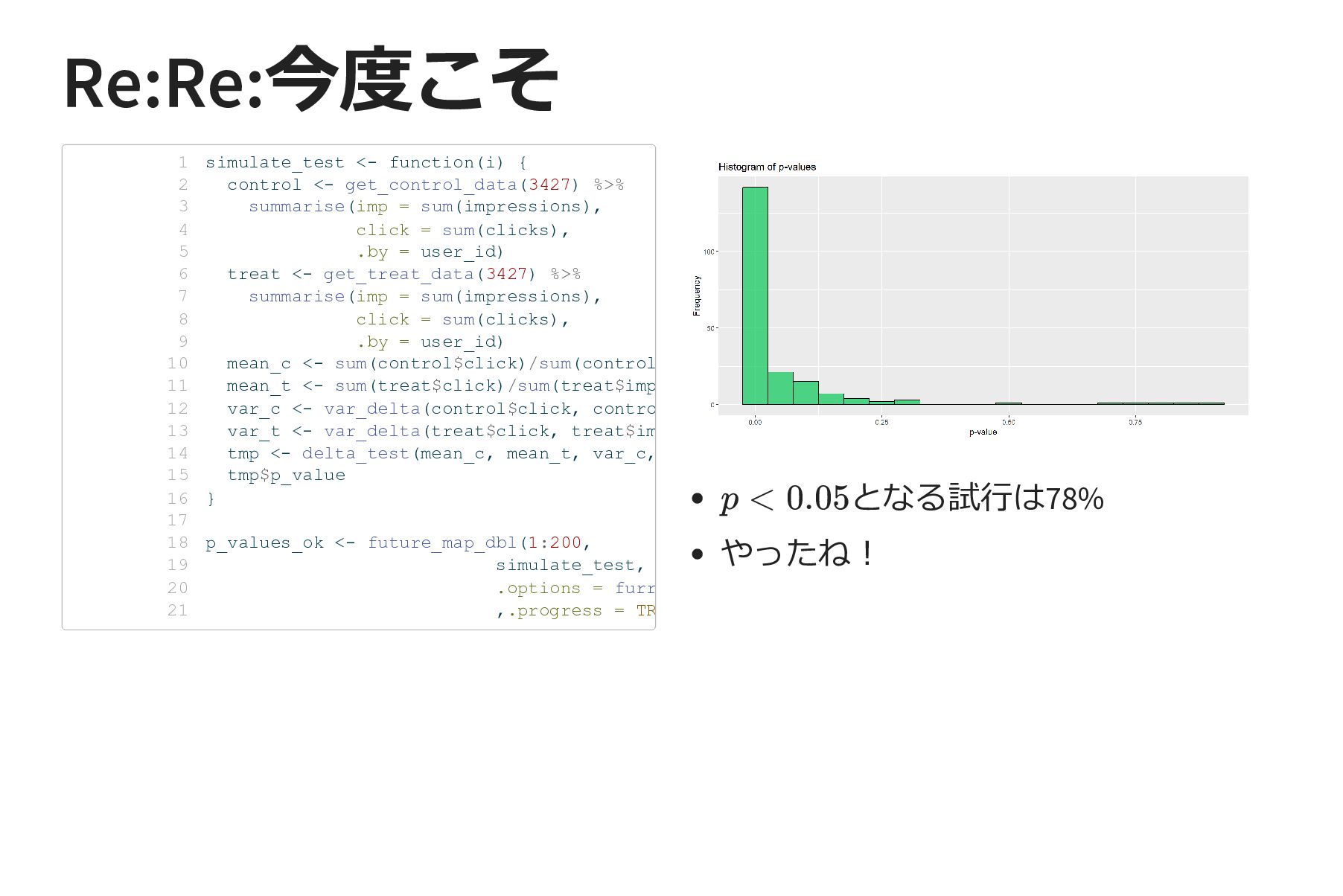{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}