Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Paper Introduction] Genie: Generative Interact...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Taisuke Takayama
June 13, 2025
230
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Paper Introduction] Genie: Generative Interactive Environments
2025/06/13
Paper introduction @TanichuLab
https://sites.google.com/view/tanichu-lab-ku/
Taisuke Takayama
June 13, 2025
Featured
See All Featured
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
170
Chasing Engaging Ingredients in Design
codingconduct
0
220
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
270
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
240
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
370
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Making the Leap to Tech Lead
cromwellryan
135
9.9k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
2
1.1k
Transcript
Genie: Generative Interactive Environments Symbol Emergence Systems Lab. Journal Club
Calendar June 13, 2025 Presenter: Taisuke Takayama
2 書誌情報 • タイトル: Genie: Generative Interactive Environments • 著者:
Jake Bruce (Google DeepMind), et al. • 採択状況: ICML 2024 (Best Paper Award) https://icml.cc/virtual/2024/oral/35508 https://proceedings.mlr.press/v235/bruce24a.html
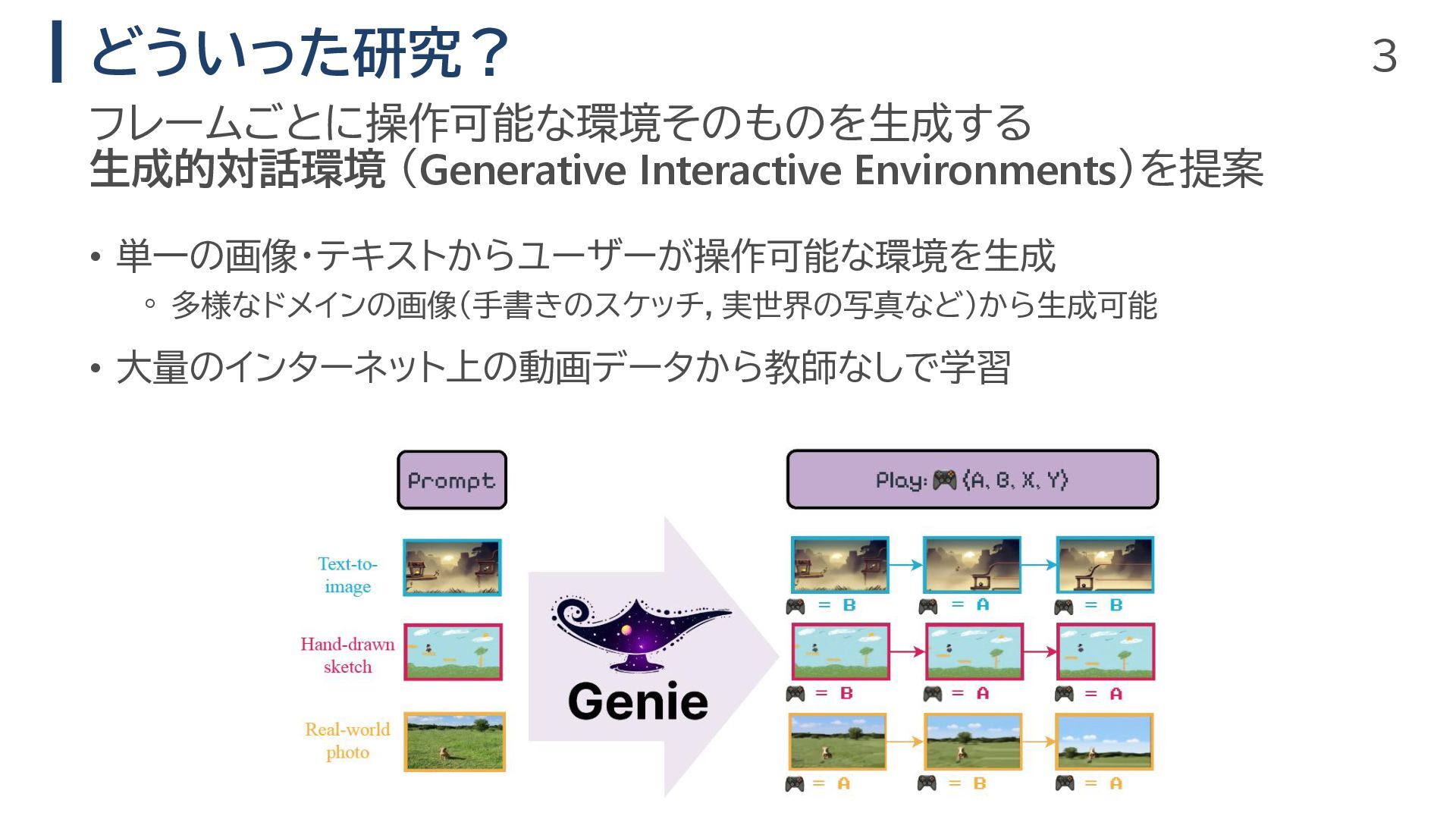
3 どういった研究? • 単一の画像・テキストからユーザーが操作可能な環境を生成 ◦ 多様なドメインの画像(手書きのスケッチ,実世界の写真など)から生成可能 • 大量のインターネット上の動画データから教師なしで学習 フレームごとに操作可能な環境そのものを生成する 生成的対話環境
(Generative Interactive Environments)を提案
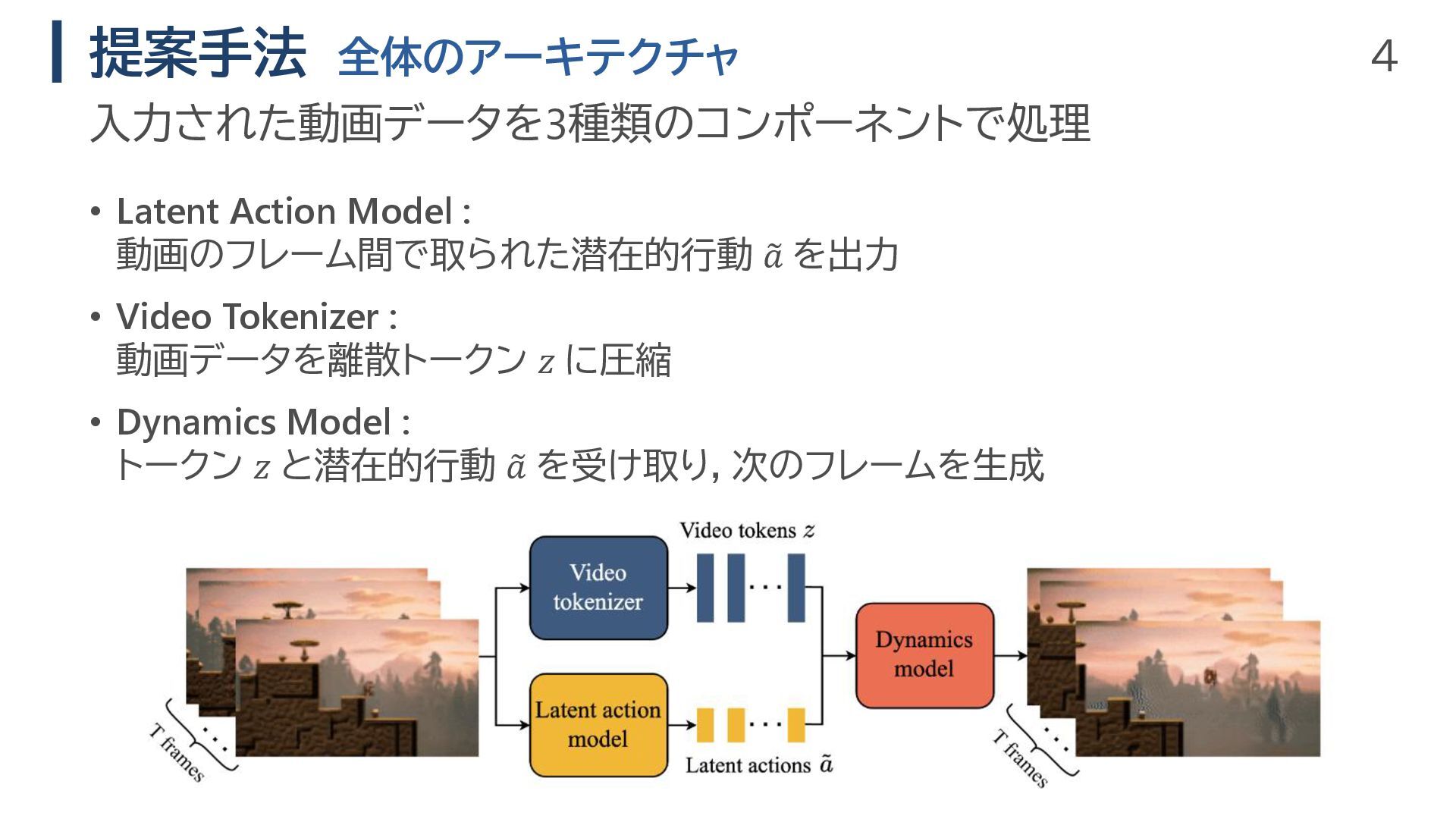
4 提案手法 全体のアーキテクチャ • Latent Action Model : 動画のフレーム間で取られた潜在的行動
𝑎 を出力 • Video Tokenizer : 動画データを離散トークン 𝑧 に圧縮 • Dynamics Model : トークン 𝑧 と潜在的行動 𝑎 を受け取り,次のフレームを生成 入力された動画データを3種類のコンポーネントで処理
5 提案手法 準備① VQ-VAE [van den Oord+ 2017] • Latent
Action Model, Video Tokenizer で利用 • 𝐾 本の埋め込みからなる VQ-codebook を用意し,エンコーダの出力を最も近い VQ-codebook 内の埋め込みに対応するインデックスに変換 • Posterior Collapse という,強い decoder を使うときに潜在変数が無視される 現象を回避 [van den Oord+ 2017] van den Oord, Aaron, et al. “Neural Discrete Representation Learning.” Advances in Neural Information Processing Systems, vol. 30, 2017. ベクトル量子化により,VAE の潜在変数を離散化
6 提案手法 準備② ST-transformer [Xu+ 2020] • 提案手法のコンポーネント全般で利用 • 空間的アテンション層は同一タイムステップの
𝐻 × 𝑊 × 1 個のトークンにアテンションを向ける • 時間的アテンション層は 𝑇 タイムステップに渡って 同じ場所の 1 × 1 × 𝑇 個のトークンにアテンション を向ける • 通常の ViT はフレーム数に対して2乗のオーダーで 計算コストが増大するが,ST-transformer を使うと フレーム数に対して線形のオーダーに抑えられる [Xu+ 2020] Xu, Mingxing, et al. “Spatial-Temporal Transformer Networks for Traffic Flow Forecasting.” arXiv [Eess.SP], 9 Jan. 2020, http://arxiv.org/abs/2001.02908. arXiv. 空間的アテンション層と時間的アテンション層を交互に配置し, 効率的にトークン間の時空間的な関連をとらえる
7 提案手法 準備③ MaskGIT [Chang+ 2022] • Dynamics Model で利用
• エンコーダ,デコーダ,VQ-codebook の学習後,画像トークンの分布の学習時に マスクされたトークンを予測するタスクを解くことで双方向的なコンテキストを 学習 [Chang+ 2022] Chang, Huiwen, et al. “MaskGIT: Masked Generative Image Transformer.” _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_, 2022, pp. 11315–11325. 画像トークン間の双方向的なコンテキストを利用できる transformer
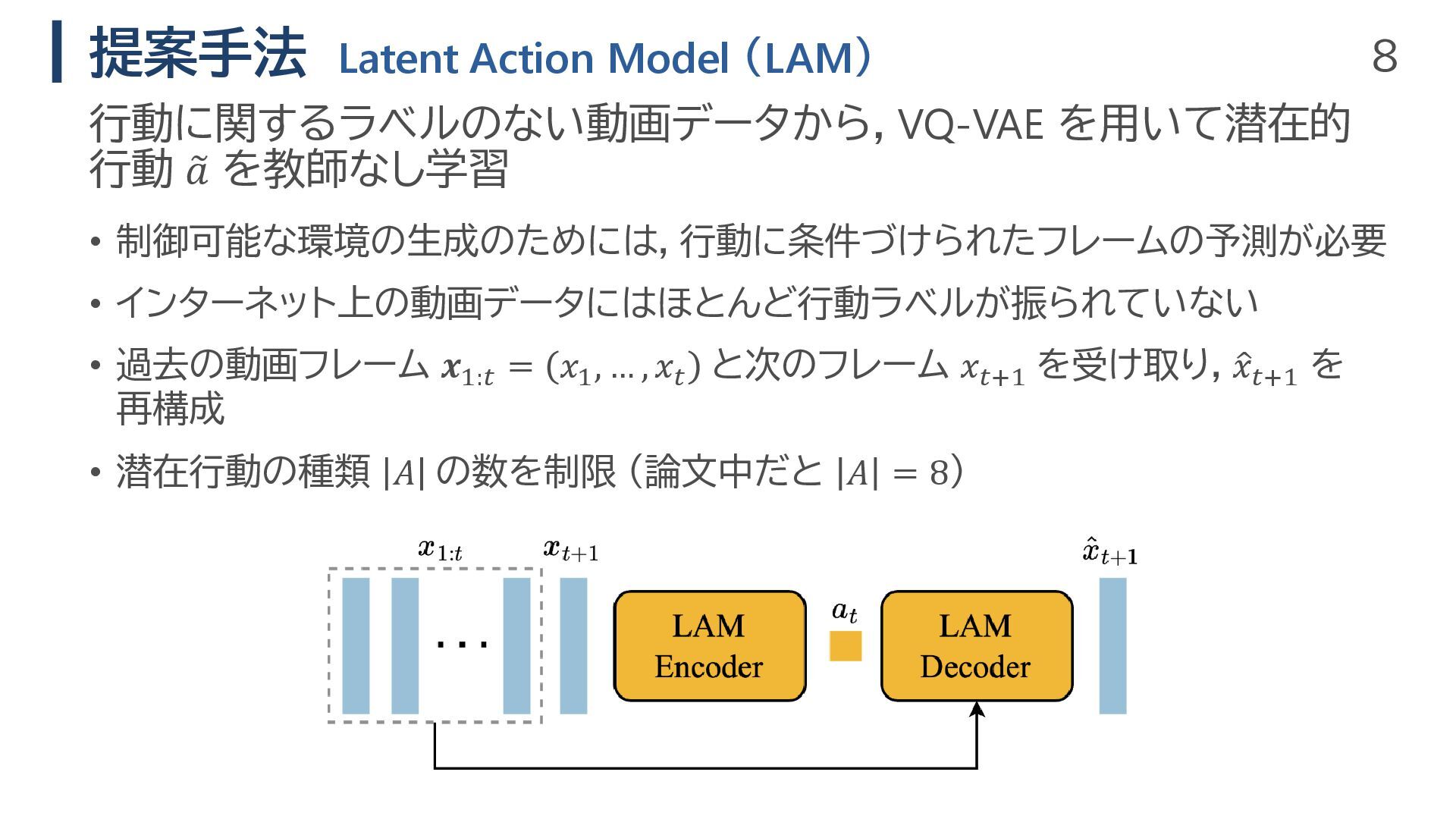
8 提案手法 Latent Action Model (LAM) • 制御可能な環境の生成のためには,行動に条件づけられたフレームの予測が必要 • インターネット上の動画データにはほとんど行動ラベルが振られていない
• 過去の動画フレーム 𝒙1:𝑡 = 𝑥1 , … , 𝑥𝑡 と次のフレーム 𝑥𝑡+1 を受け取り,ො 𝑥𝑡+1 を 再構成 • 潜在行動の種類 𝐴 の数を制限 (論文中だと 𝐴 = 8) 行動に関するラベルのない動画データから,VQ-VAE を用いて潜在的 行動 𝑎 を教師なし学習
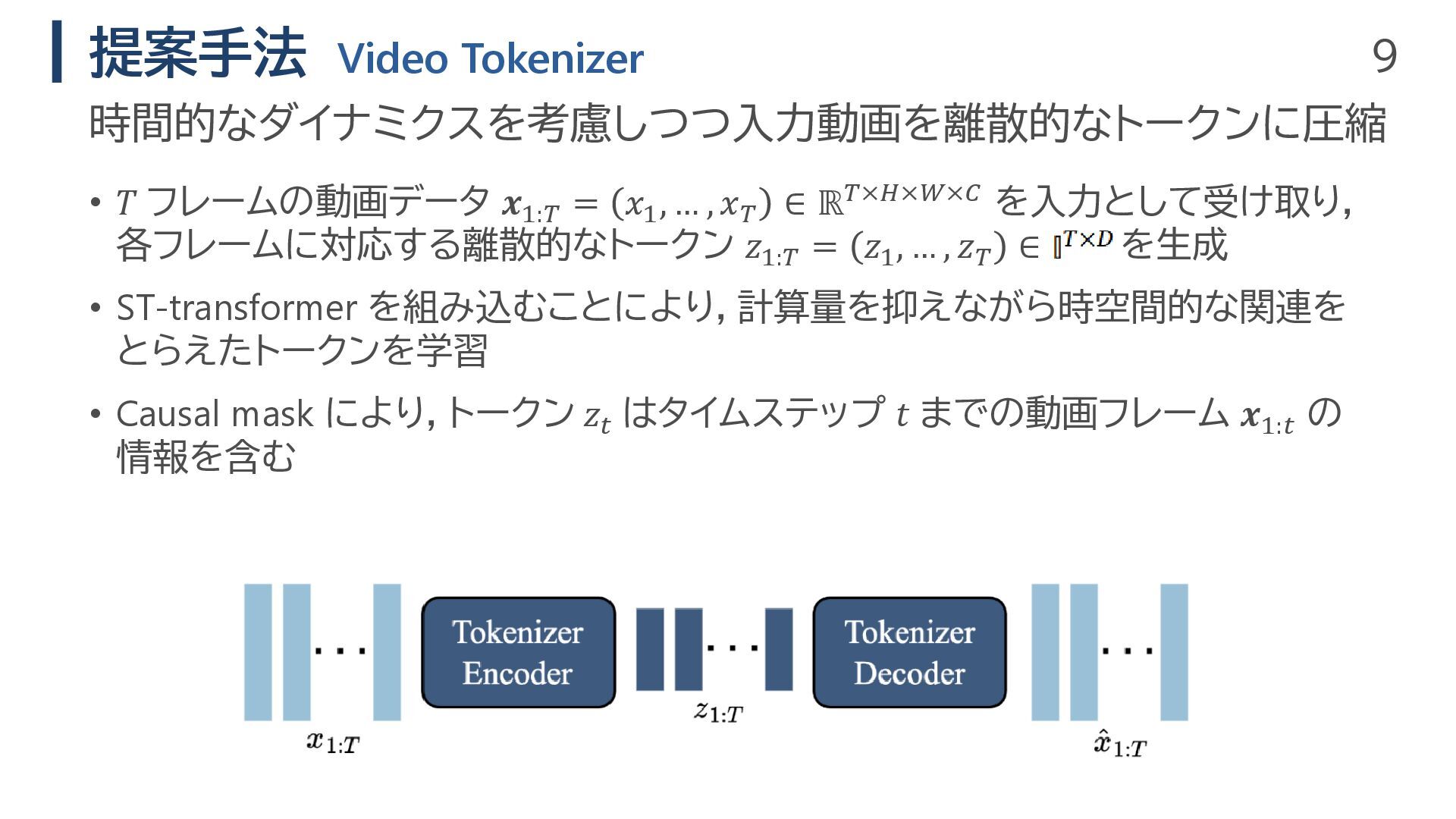
9 提案手法 Video Tokenizer • 𝑇 フレームの動画データ 𝒙1:𝑇 = 𝑥1
, … , 𝑥𝑇 ∈ ℝ𝑇×𝐻×𝑊×𝐶 を入力として受け取り, 各フレームに対応する離散的なトークン 𝑧1:𝑇 = 𝑧1 , … , 𝑧𝑇 ∈ を生成 • ST-transformer を組み込むことにより,計算量を抑えながら時空間的な関連を とらえたトークンを学習 • Causal mask により,トークン 𝑧𝑡 はタイムステップ 𝑡 までの動画フレーム 𝒙1:𝑡 の 情報を含む 時間的なダイナミクスを考慮しつつ入力動画を離散的なトークンに圧縮
10 提案手法 Dynamics Model 過去の動画フレームのトークンと潜在行動を統合し,新たな動画 フレームに対応するトークンを予測 • MaskGIT [Chang+ 2022]
transformer のデコーダを ST-transformer と 組み合わせて構成 • 動画トークン列 𝒛1:𝑇−1 と潜在行動列 𝒂1:𝑇−1 を受け取り,動画トークン列 𝒛2:𝑇 を予測 • 因果マスクによって 𝒛2:𝑇 を一度に出力できる [Chang+ 2022] Chang, Huiwen, et al. "Maskgit: Masked generative image transformer." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
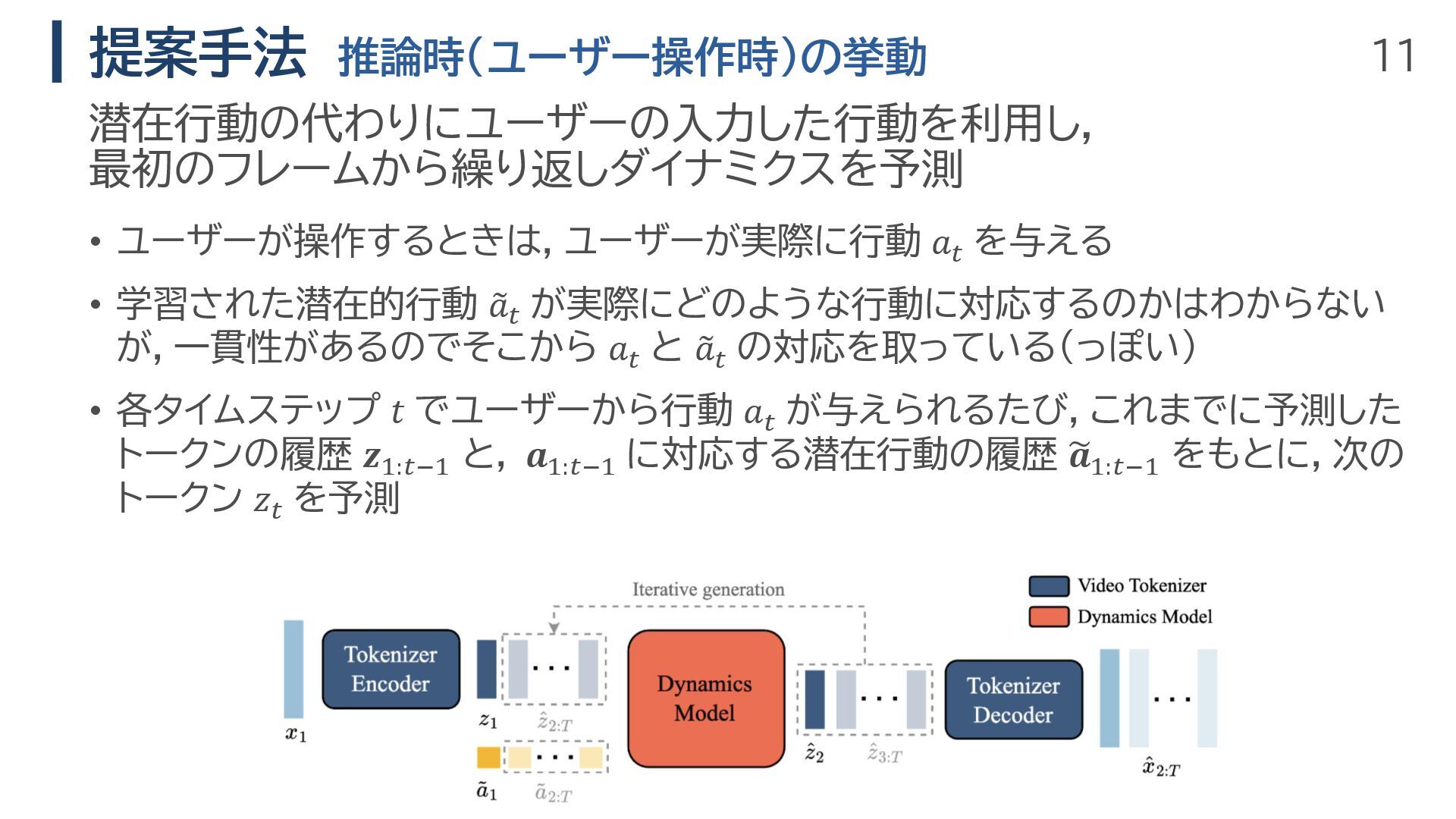
11 提案手法 推論時(ユーザー操作時)の挙動 • ユーザーが操作するときは,ユーザーが実際に行動 𝑎𝑡 を与える • 学習された潜在的行動
𝑎𝑡 が実際にどのような行動に対応するのかはわからない が,一貫性があるのでそこから 𝑎𝑡 と 𝑎𝑡 の対応を取っている(っぽい) • 各タイムステップ 𝑡 でユーザーから行動 𝑎𝑡 が与えられるたび,これまでに予測した トークンの履歴 𝒛1:𝑡−1 と, 𝒂1:𝑡−1 に対応する潜在行動の履歴 𝒂1:𝑡−1 をもとに,次の トークン 𝑧𝑡 を予測 潜在行動の代わりにユーザーの入力した行動を利用し, 最初のフレームから繰り返しダイナミクスを予測
12 実験 データセット • インターネット上で公開されている 2D ゲームのプレイ動画から収集した データセット(論文中では Platformers と呼称)を用いて学習
◦ 解像度 : 160 × 90 ◦ FPS: 10 • 680 万本の 16 秒動画クリップを含む大規模なデータセット • 同時に,ロボティクスデータセット(論文中では Robotics と呼称)も用いることで, 提案手法の一般性を検証 インターネット上の 2D ゲームのプレイ動画を用いて学習
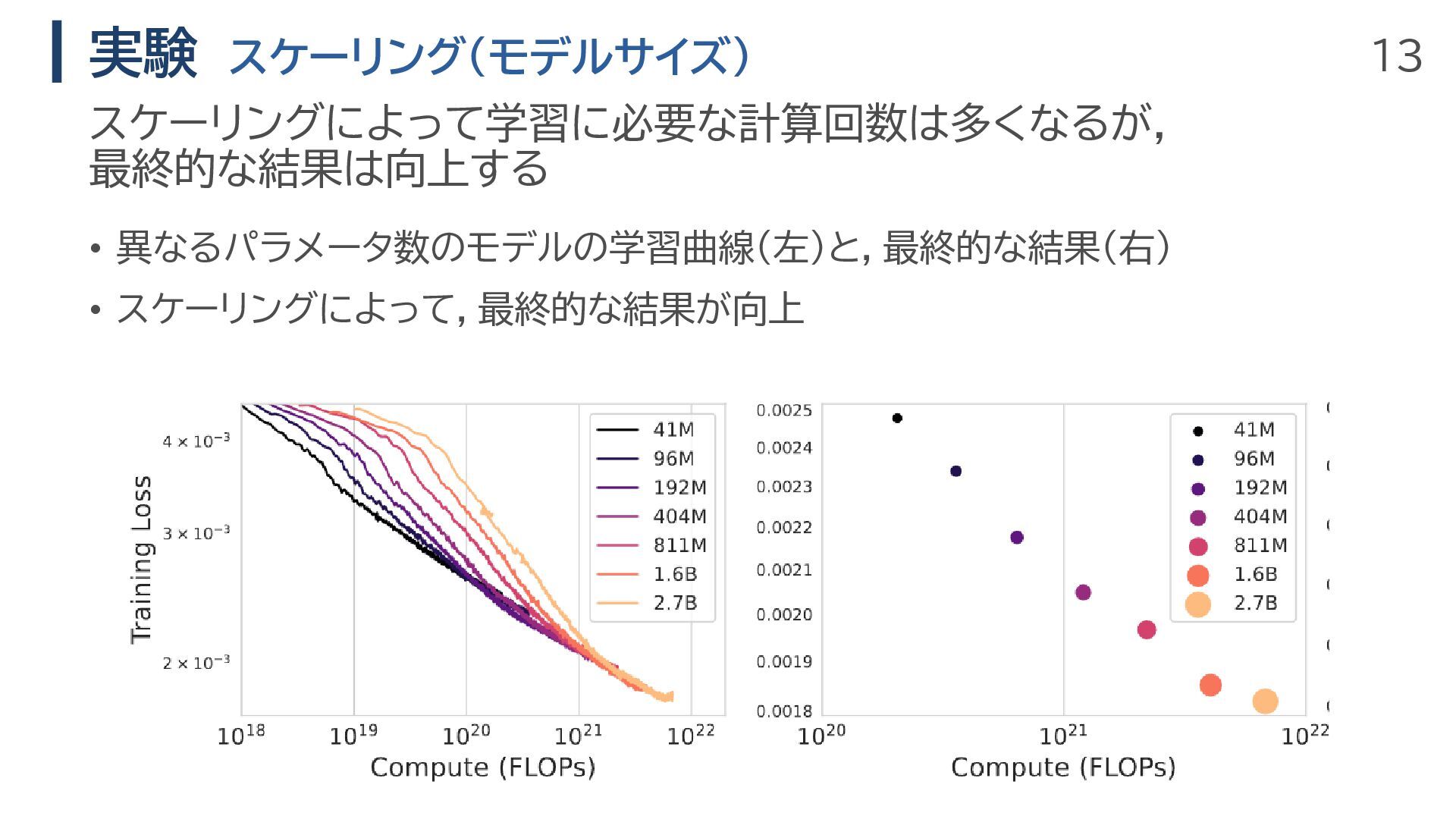
13 実験 スケーリング(モデルサイズ) • 異なるパラメータ数のモデルの学習曲線(左)と,最終的な結果(右) • スケーリングによって,最終的な結果が向上 スケーリングによって学習に必要な計算回数は多くなるが, 最終的な結果は向上する
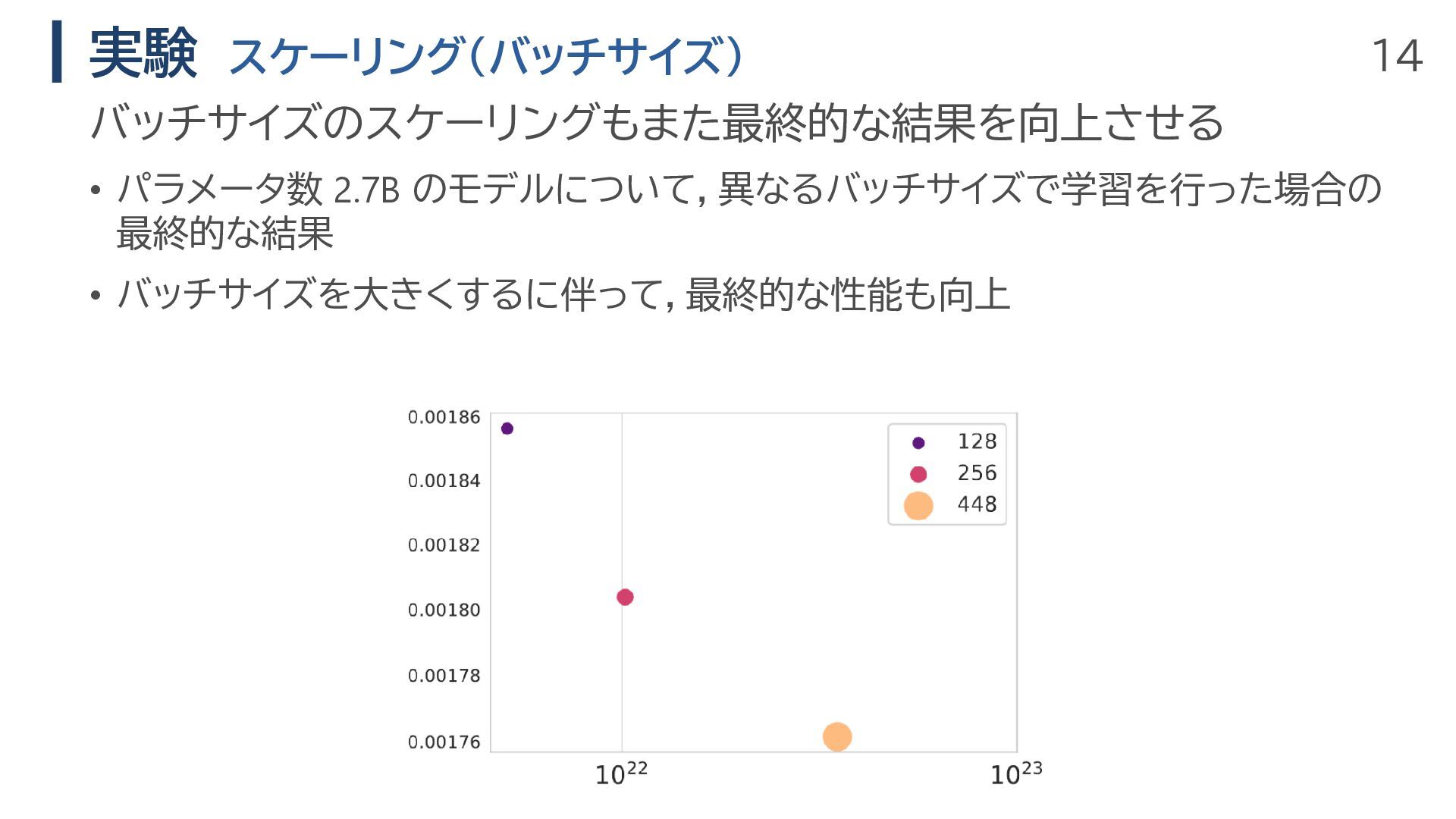
14 実験 スケーリング(バッチサイズ) • パラメータ数 2.7B のモデルについて,異なるバッチサイズで学習を行った場合の 最終的な結果 • バッチサイズを大きくするに伴って,最終的な性能も向上
バッチサイズのスケーリングもまた最終的な結果を向上させる
15 実験 対話環境の生成 • 入力テキストに text-to-image の変換を施した場合や,手描きスケッチを入力した 場合,実世界画像を入力した場合で対話環境の生成に成功 多様なプロンプトに対して操作可能な対話環境が生成
16 実験 Robotics データセットによる学習 Robotics データセットを用いた場合も,同様に対話環境を生成可能 • 同じモデルをロボット実験の動画 データを用いて学習 •
ロボットの操作にとどまらず,ロボット と周囲の物体の間の相互作用まで 再現 • ロボティクスのための基盤世界モデル の構築への応用が期待
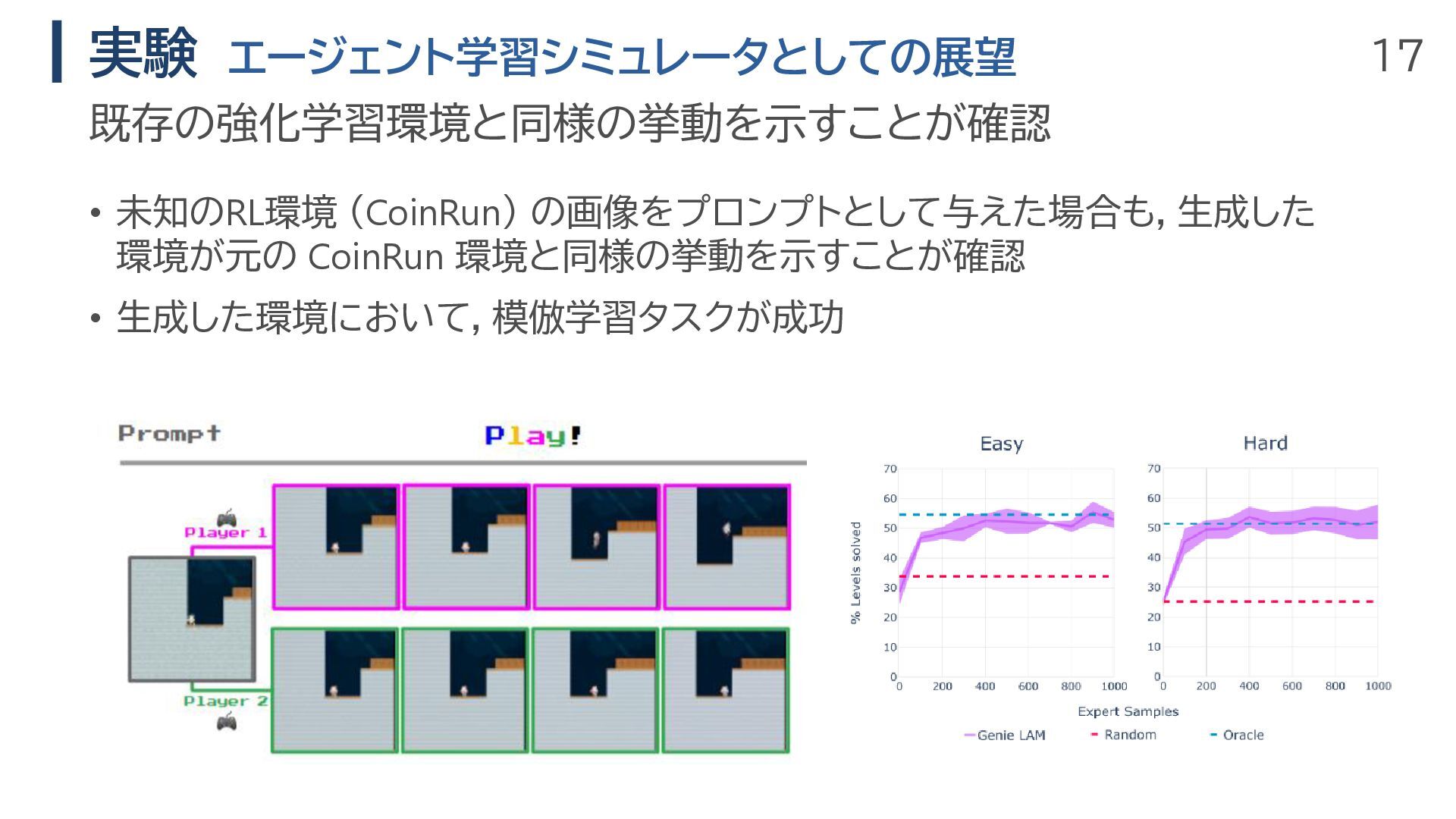
17 実験 エージェント学習シミュレータとしての展望 既存の強化学習環境と同様の挙動を示すことが確認 • 未知のRL環境 (CoinRun) の画像をプロンプトとして与えた場合も,生成した 環境が元の CoinRun
環境と同様の挙動を示すことが確認 • 生成した環境において,模倣学習タスクが成功
18 課題 • 非現実的なハルシネーションを起こすことがある • 扱えるフレーム数に限りがある(論文では16フレームと言及) • 動作が遅い(生成される環境は 1FPS)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 提案手法 準備① VQ-VAE [van den Oord+ 2017] • Latent](https://files.speakerdeck.com/presentations/f1a49d6379a946c5864ab798c3846e31/slide_4.jpg){kind=link}
![6 提案手法 準備② ST-transformer [Xu+ 2020] • 提案手法のコンポーネント全般で利用 • 空間的アテンション層は同一タイムステップの](https://files.speakerdeck.com/presentations/f1a49d6379a946c5864ab798c3846e31/slide_5.jpg){kind=link}
![7 提案手法 準備③ MaskGIT [Chang+ 2022] • Dynamics Model で利用](https://files.speakerdeck.com/presentations/f1a49d6379a946c5864ab798c3846e31/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
![10 提案手法 Dynamics Model 過去の動画フレームのトークンと潜在行動を統合し,新たな動画 フレームに対応するトークンを予測 • MaskGIT [Chang+ 2022]](https://files.speakerdeck.com/presentations/f1a49d6379a946c5864ab798c3846e31/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}