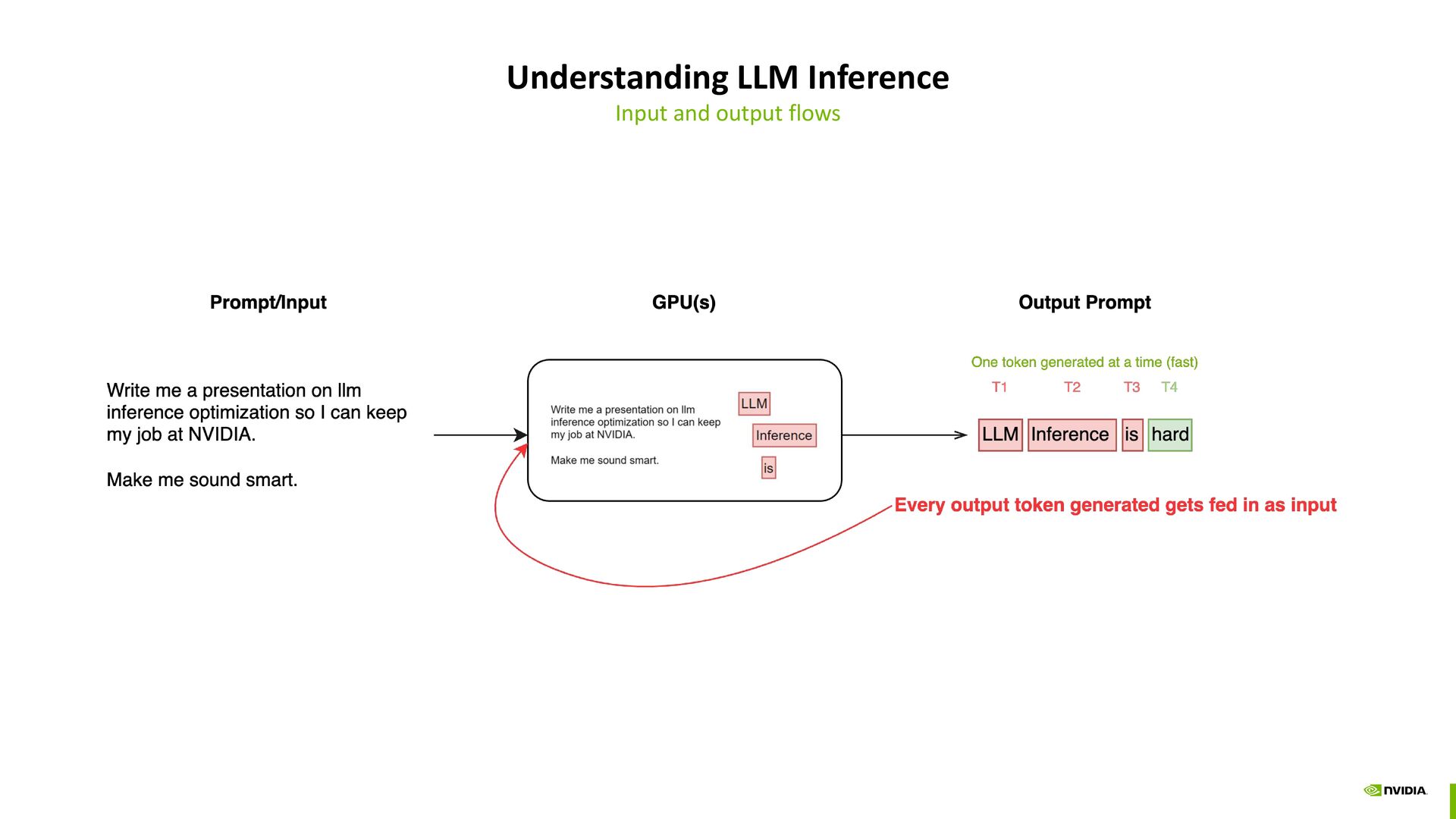
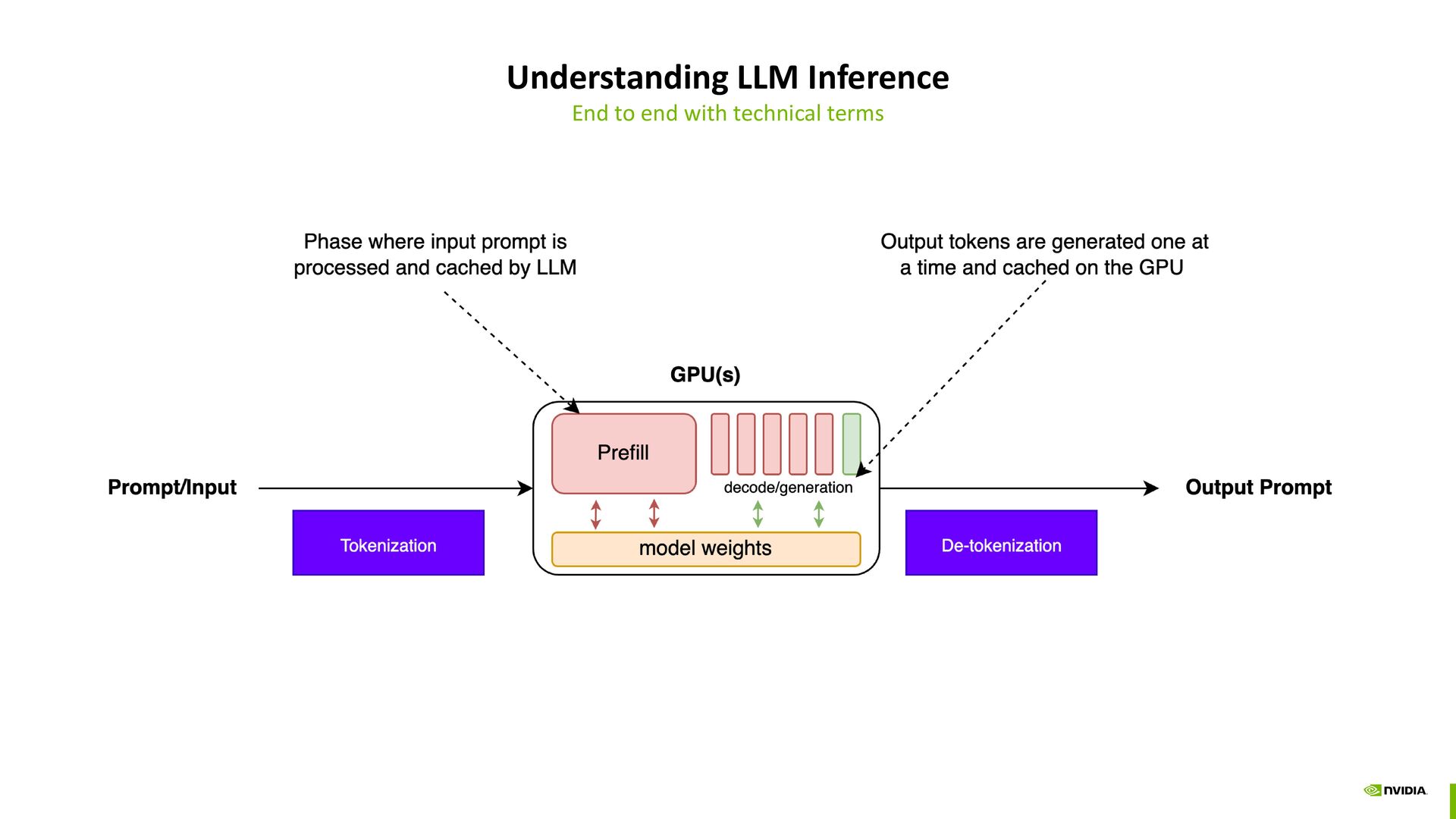
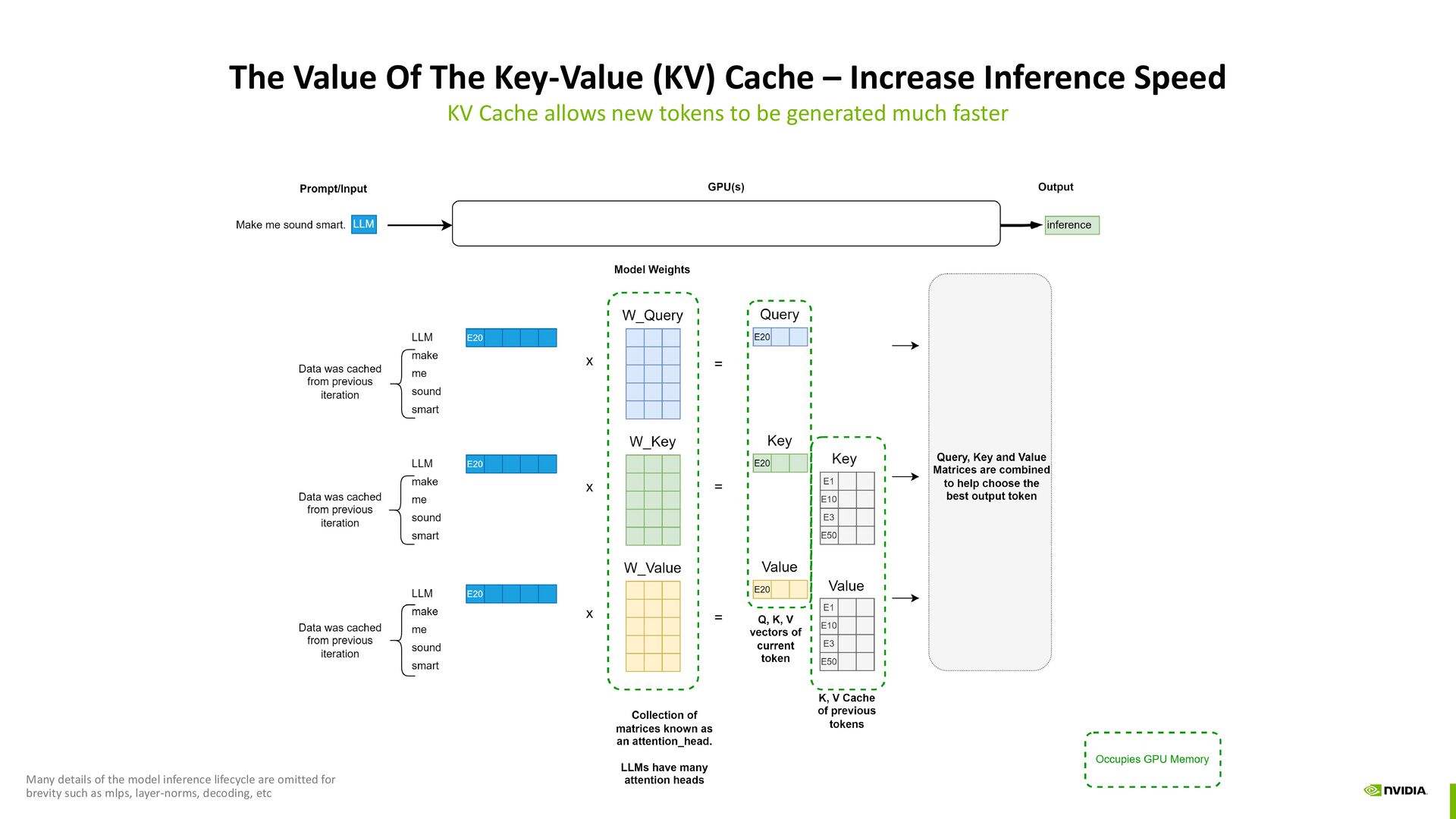
to token-ids -> token embeddings -> compute attention on the entire input sequence Many details of the model inference lifecycle are omitted for brevity such as mlps, layer-norms, decoding, etc
Speed KV Cache allows new tokens to be generated much faster Many details of the model inference lifecycle are omitted for brevity such as mlps, layer-norms, decoding, etc
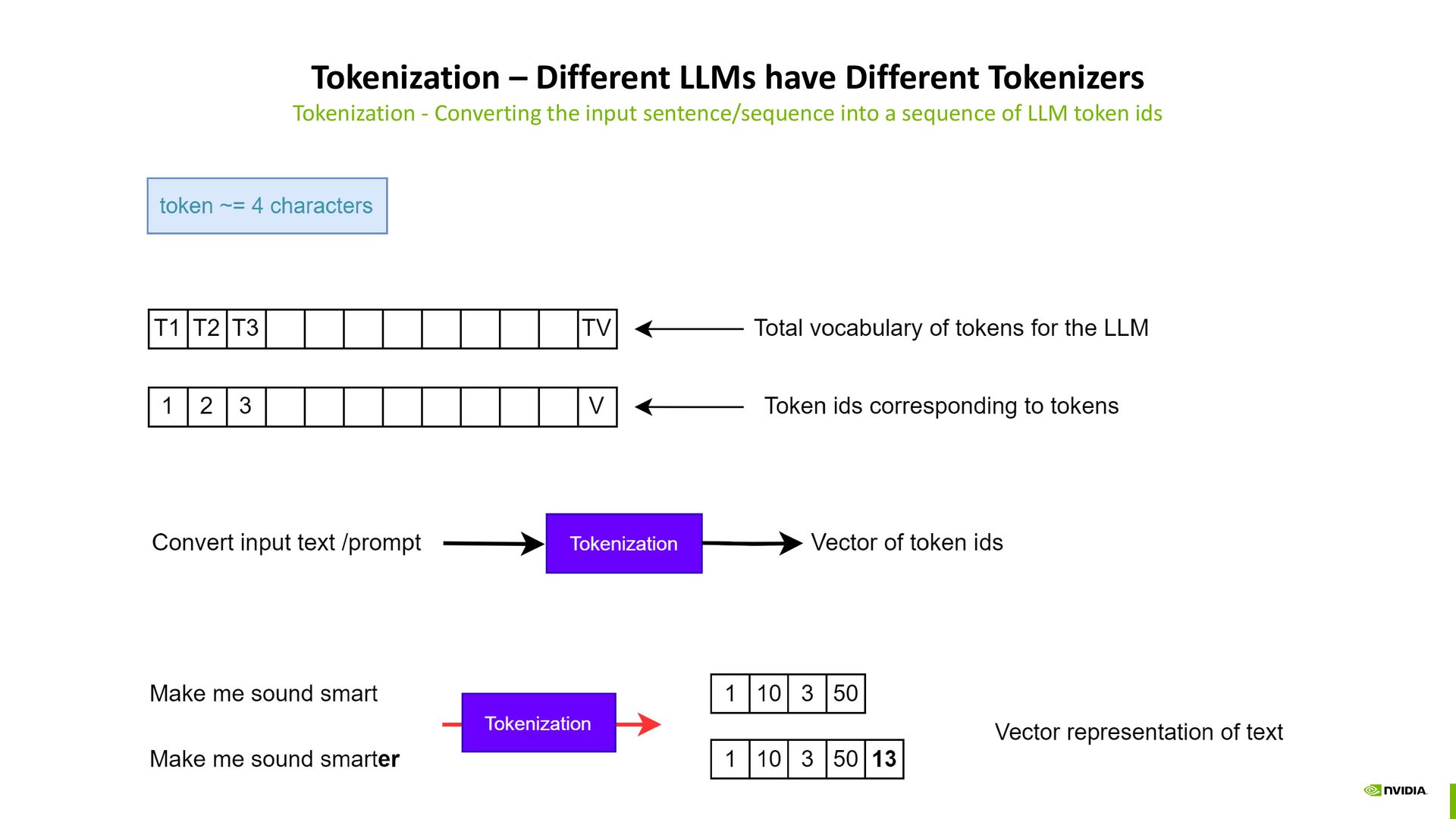
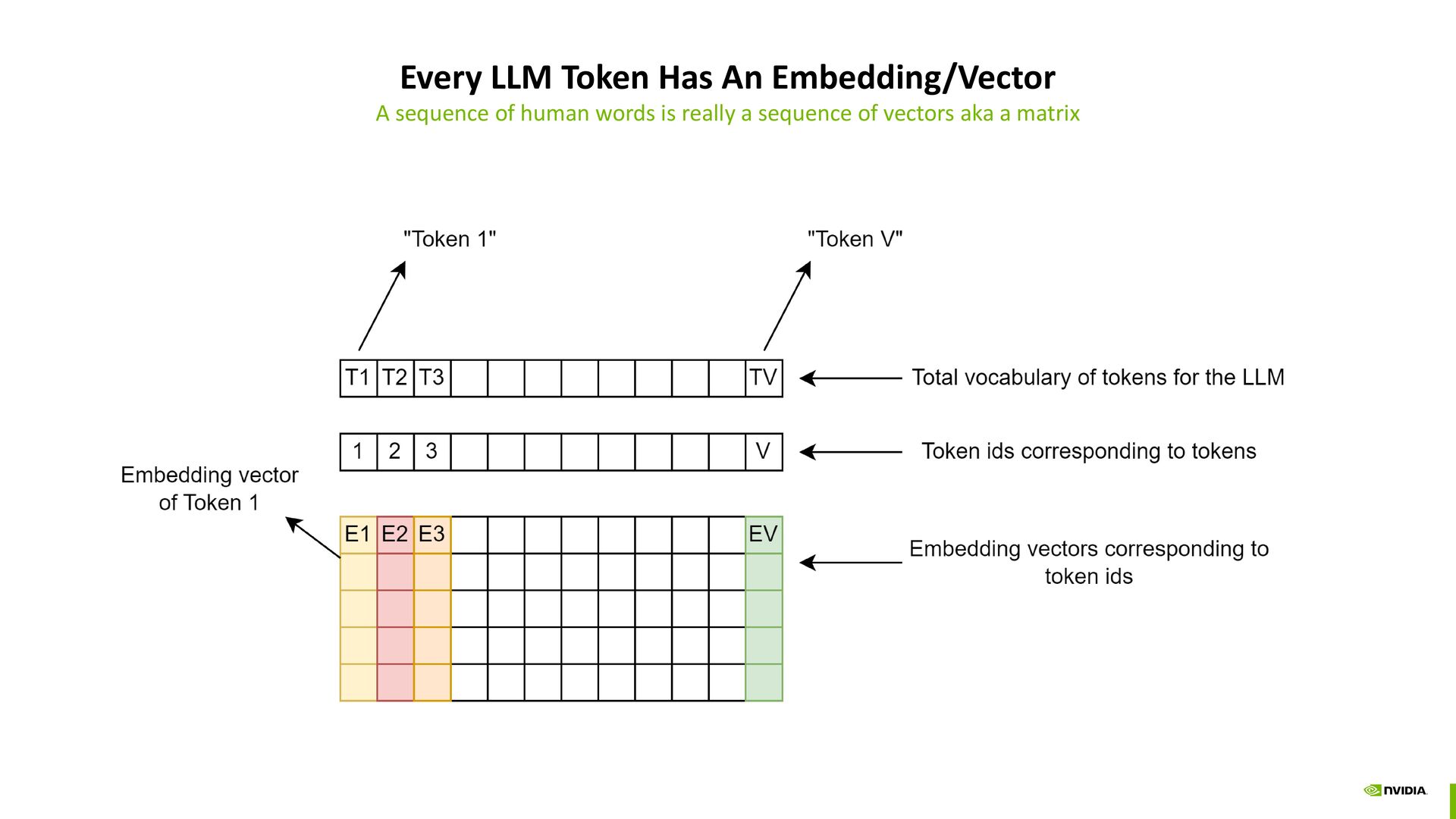
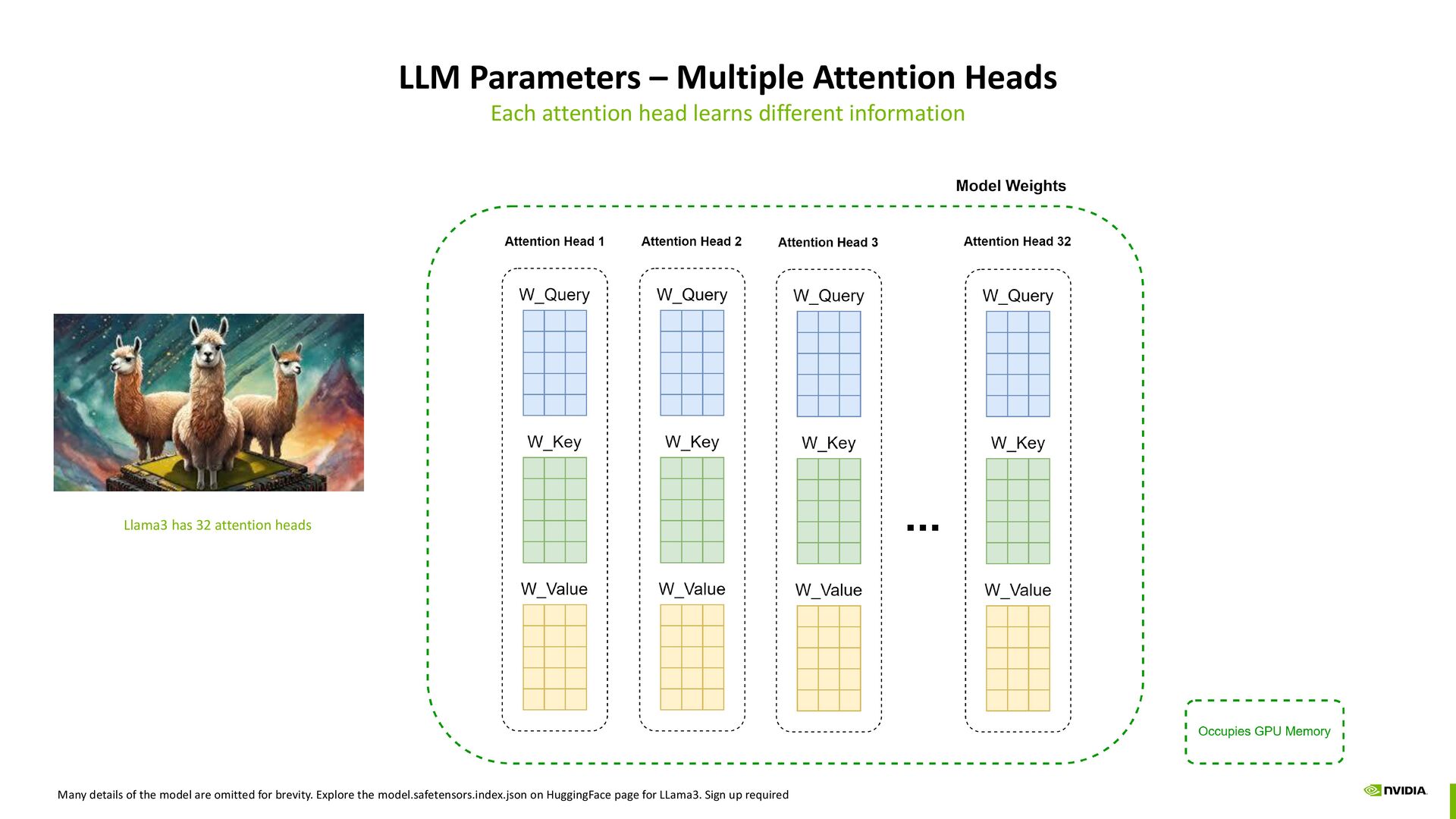
different information Llama3 has 32 attention heads Many details of the model are omitted for brevity. Explore the model.safetensors.index.json on HuggingFace page for LLama3. Sign up required
model & asset data 3. attempts to download optimized TRT-LLM model from NGC NVIDIA LLM NIM Pull Sequence User executes “docker run” docker run [...]\ nvn.im/meta-llama/meta- llama-3-8b-instruct NIM container is pulled from NGC Model loaded with TRT-LLM runtime Container pulls HF model for serving with vLLM HF model loaded with vLLM runtime
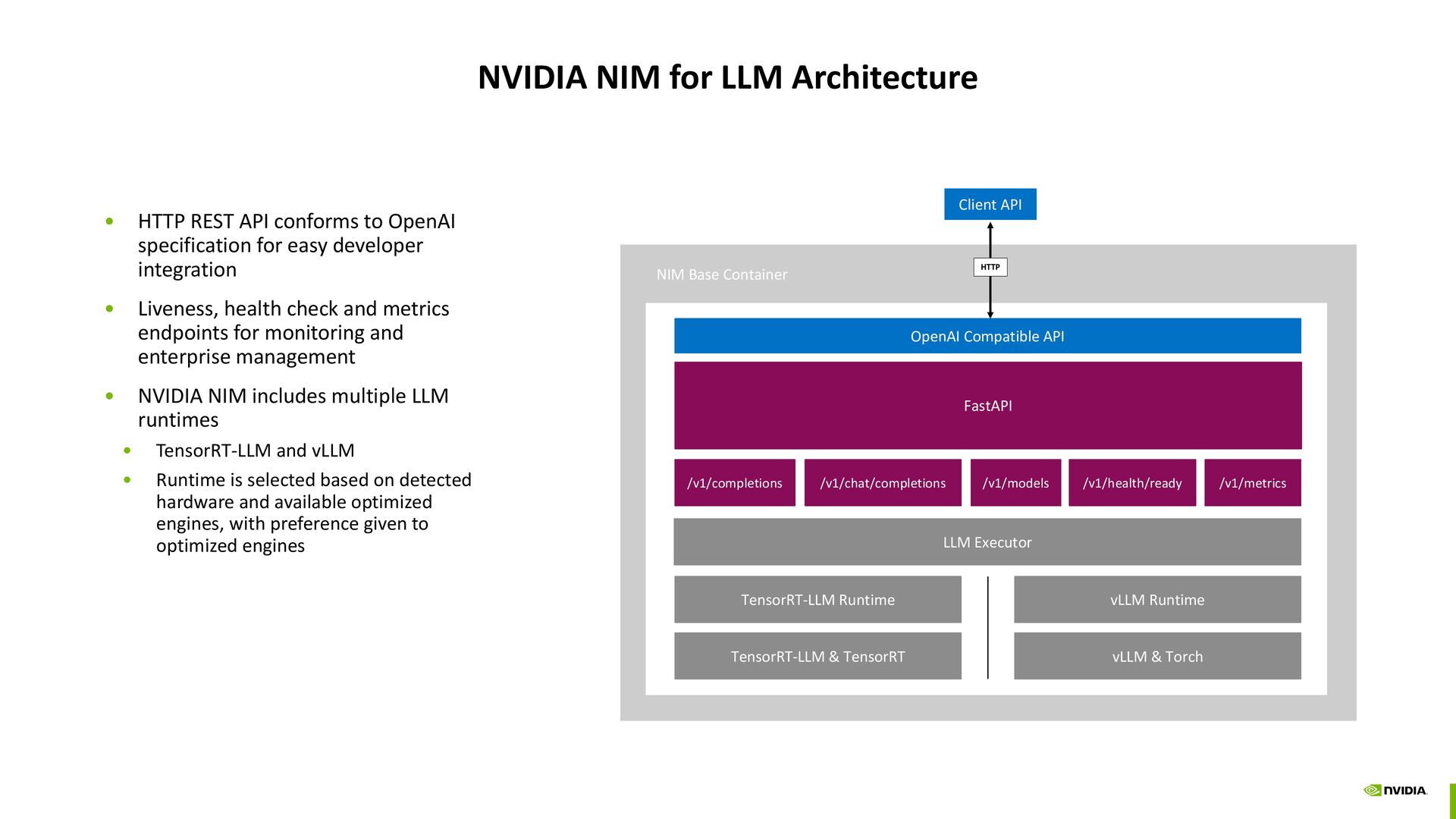
to OpenAI specification for easy developer integration • Liveness, health check and metrics endpoints for monitoring and enterprise management • NVIDIA NIM includes multiple LLM runtimes • TensorRT-LLM and vLLM • Runtime is selected based on detected hardware and available optimized engines, with preference given to optimized engines NIM Base Container OpenAI Compatible API FastAPI /v1/completions /v1/chat/completions LLM Executor TensorRT-LLM Runtime TensorRT-LLM & TensorRT vLLM Runtime vLLM & Torch Client API /v1/models /v1/metrics /v1/health/ready HTTP
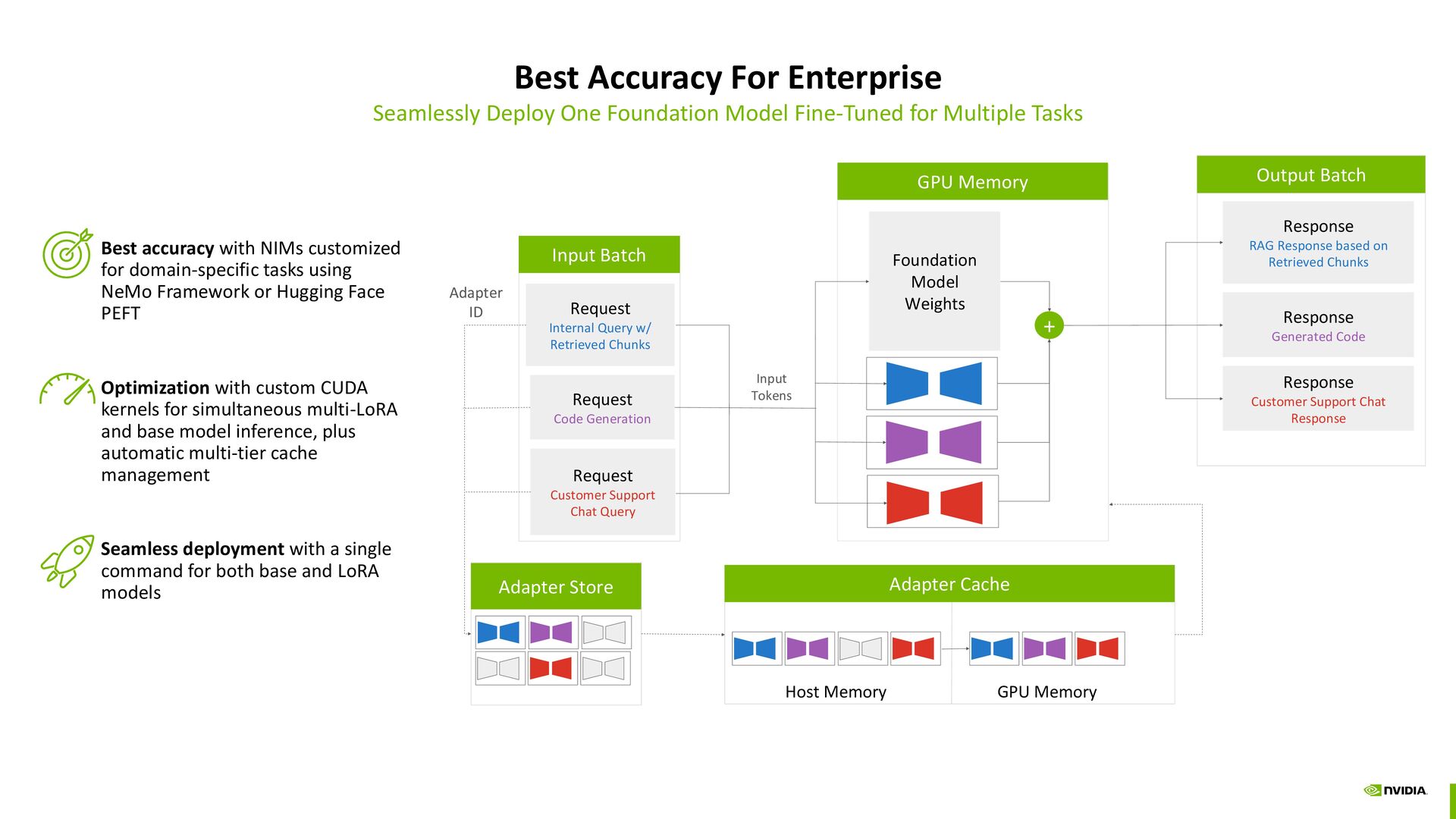
for Multiple Tasks Best accuracy with NIMs customized for domain-specific tasks using NeMo Framework or Hugging Face PEFT Optimization with custom CUDA kernels for simultaneous multi-LoRA and base model inference, plus automatic multi-tier cache management Seamless deployment with a single command for both base and LoRA models GPU Memory GPU Memory Input Batch Customization Cache Foundation Model Weights + Request Internal Query w/ Retrieved Chunks Request Code Generation Request Customer Support Chat Query Host Memory GPU Memory Response RAG Response based on Retrieved Chunks Response Generated Code Response Customer Support Chat Response Input Batch Output Batch Adapter Cache Adapter Store Input Tokens Adapter ID
Q&A Retrieval Pipeline Vector Database Data Optimized Inference Engines State-of-the-art, customizable models, fine-tuned for accuracy Flexible and modular deployment Accelerated vector search Production Ready Plan Event Prompt Retriever Microservice LLM NIM NeMo Retriever Embedding NIM NeMo Retriever Reranking NIM
for Download on build.nvidia.com NV-RerankQA-Mistral4B-v3 Text reranking for high accuracy question answering NV-Embed-QA-E5-v5 Embedding model for text question answering NV-EmbedQA-Mistral7B-v2 Multilingual text embedding model Snowflake-Arctic-Embed-l Optimized community model
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}