Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Raft 文献調査
Search
koyamaso
February 04, 2021
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Raft 文献調査
koyamaso
February 04, 2021
More Decks by koyamaso
See All by koyamaso
9.4.3 耐障害性を持つ合意
koyamaso
0
33
5.4 リーダーレスレプリケーション
koyamaso
1
210
4.1.3 ThriftとProtocol Buffers
koyamaso
0
55
spack.yamlを書こう
koyamaso
0
95
主専攻実験S-3 メタヒューリスティクスと巡回セールスマン問題 最終発表
koyamaso
0
480
Featured
See All Featured
The Cost Of JavaScript in 2023
addyosmani
55
10k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
890
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Visualization
eitanlees
152
17k
Prompt Engineering for Job Search
mfonobong
0
370
Transcript
Raft 文献調査
参考文献 - https://raft.github.io/raft.pdf - https://github.com/ongardie/dissertation/blob/master/book.pdf まず上の論文を読んで雰囲気を掴んだ所で下の論文を読むと良さそうです 論文の著作権はCC BY 4.0で保護されています https://creativecommons.org/licenses/by/4.0/ 一部の図は論文から引用していますが、引用元は上記の論文だけで他の図は自作です
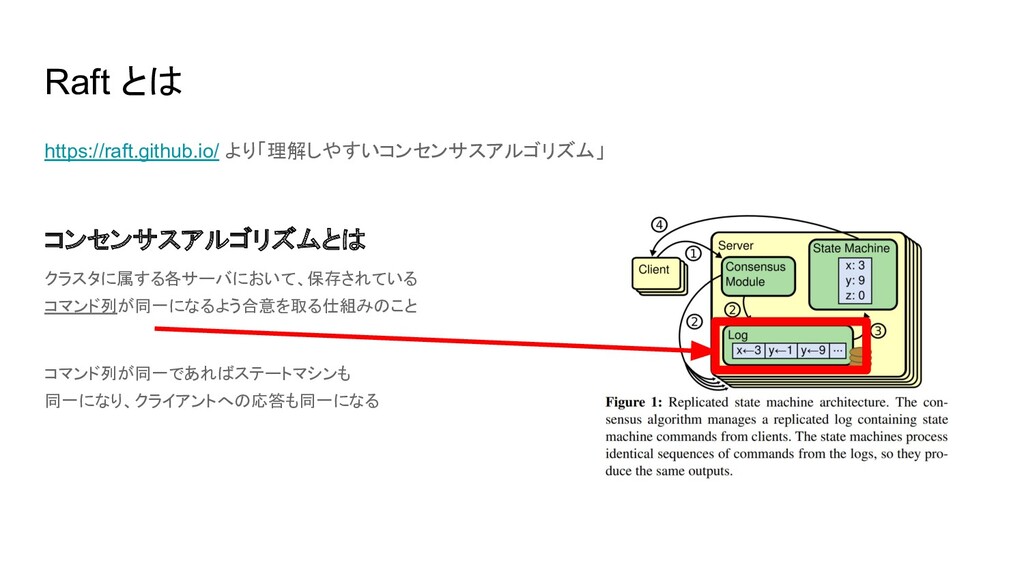
Raft とは https://raft.github.io/ より「理解しやすいコンセンサスアルゴリズム」 コンセンサスアルゴリズムとは クラスタに属する各サーバにおいて、保存されている コマンド列が同一になるよう合意を取る仕組みのこと コマンド列が同一であればステートマシンも 同一になり、クライアントへの応答も同一になる
Raft とは (2) 有名な実装Best 2 1. https://etcd.io/ - Goで実装されている -
性能を向上させるために実装が工夫されている (=分かりづらい) - 代表的なユーザ: https://kubernetes.io/ 2. https://github.com/willemt/raft - Cで実装されている - シンプルな実装 - 代表的なユーザ: https://daos-stack.github.io/
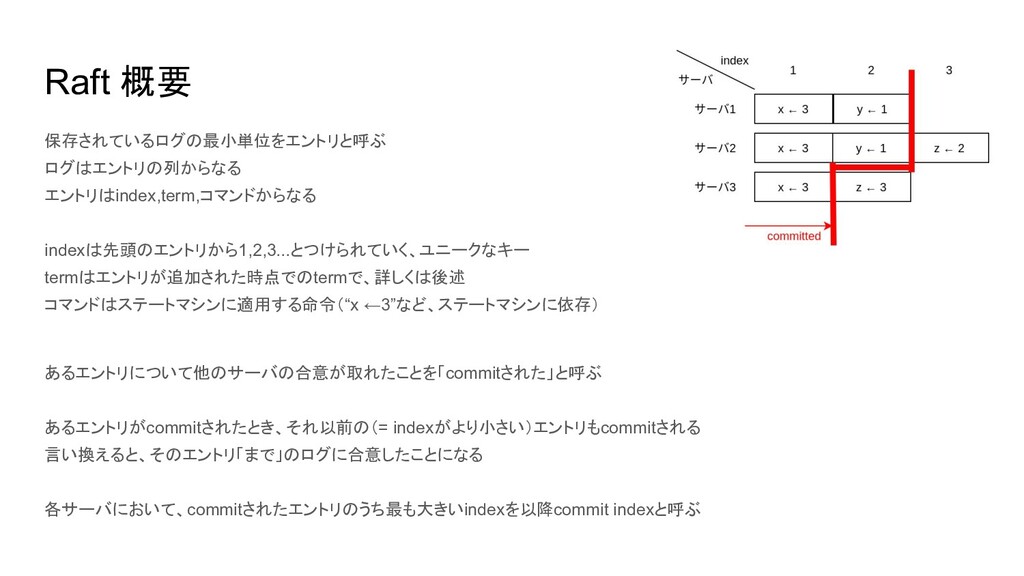
Raft 概要 保存されているログの最小単位をエントリと呼ぶ ログはエントリの列からなる エントリはindex,term,コマンドからなる indexは先頭のエントリから1,2,3...とつけられていく、ユニークなキー termはエントリが追加された時点でのtermで、詳しくは後述 コマンドはステートマシンに適用する命令(“x ←3”など、ステートマシンに依存) あるエントリについて他のサーバの合意が取れたことを「commitされた」と呼ぶ
あるエントリがcommitされたとき、それ以前の(= indexがより小さい)エントリもcommitされる 言い換えると、そのエントリ「まで」のログに合意したことになる 各サーバにおいて、commitされたエントリのうち最も大きいindexを以降commit indexと呼ぶ
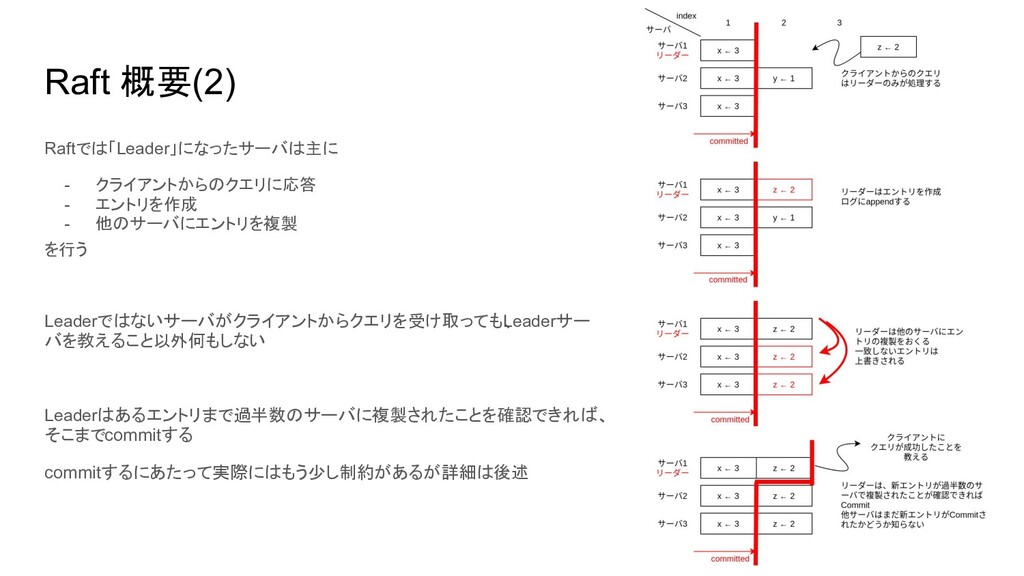
Raft 概要(2) Raftでは「Leader」になったサーバは主に - クライアントからのクエリに応答 - エントリを作成 - 他のサーバにエントリを複製 を行う
Leaderではないサーバがクライアントからクエリを受け取っても、 Leaderサー バを教えること以外何もしない Leaderはあるエントリまで過半数のサーバに複製されたことを確認できれば、 そこまでcommitする commitするにあたって実際にはもう少し制約があるが詳細は後述
Raft 概要(3) ここまでで説明していないこと - どのようにLeaderを選出するか - Leaderは今までcommitされた全てのエントリを保存していなければならない - でなければ、新しいエントリで commitされたエントリを上書きしてしまう可能性がある
- いつLeaderが死んでも次のリーダーが選出されなければならない - また、2台以上のLeaderが同時にいる状況を (なるべく)作らない - Leaderは各サーバにどのエントリを送るか - 極論エントリが追加されるたびに今までのログを全て送れば整合性はとれるが非効率 - 各サーバがどこまで Leaderのログと一致しているか、確かめる必要がある
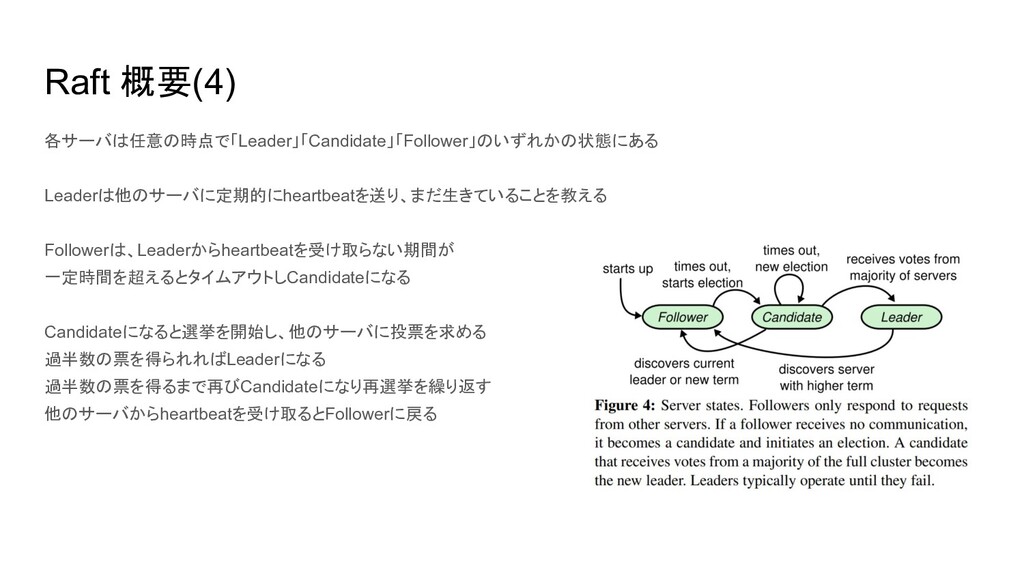
Raft 概要(4) 各サーバは任意の時点で「Leader」「Candidate」「Follower」のいずれかの状態にある Leaderは他のサーバに定期的にheartbeatを送り、まだ生きていることを教える Followerは、Leaderからheartbeatを受け取らない期間が 一定時間を超えるとタイムアウトしCandidateになる Candidateになると選挙を開始し、他のサーバに投票を求める 過半数の票を得られればLeaderになる 過半数の票を得るまで再びCandidateになり再選挙を繰り返す 他のサーバからheartbeatを受け取るとFollowerに戻る
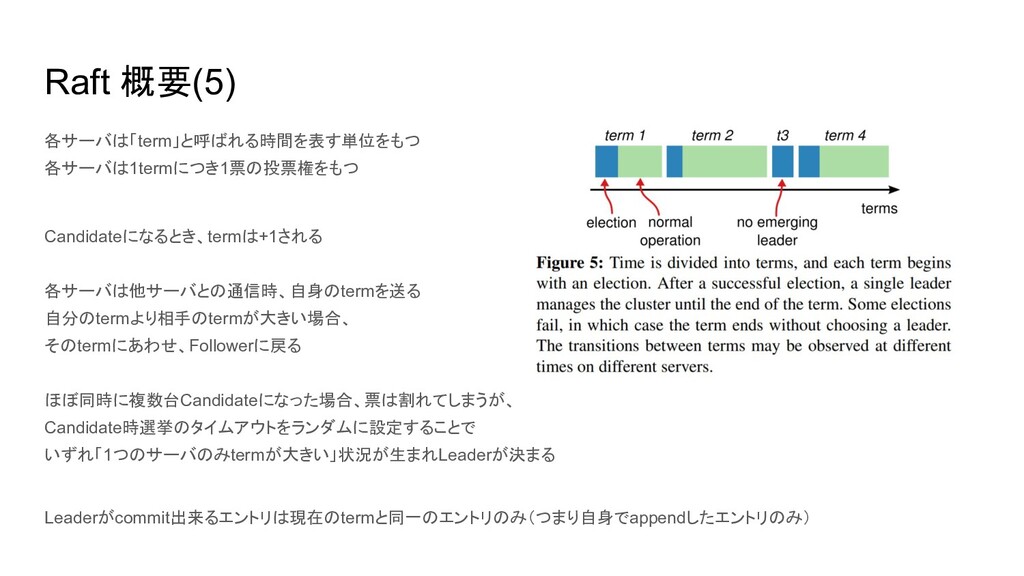
Raft 概要(5) 各サーバは「term」と呼ばれる時間を表す単位をもつ 各サーバは1termにつき1票の投票権をもつ Candidateになるとき、termは+1される 各サーバは他サーバとの通信時、自身のtermを送る 自分のtermより相手のtermが大きい場合、 そのtermにあわせ、Followerに戻る ほぼ同時に複数台Candidateになった場合、票は割れてしまうが、 Candidate時選挙のタイムアウトをランダムに設定することで
いずれ「1つのサーバのみtermが大きい」状況が生まれLeaderが決まる Leaderがcommit出来るエントリは現在のtermと同一のエントリのみ(つまり自身でappendしたエントリのみ)
Raftが保証する性質 - 各termにおいて選出されるLeaderは最大1つ - Leaderは自身のログに保存されたエントリを上書きしたり消したりせず、 appendのみ行う - 2つのログが同一のindexとtermをもつエントリを持っていた時、そのエントリまで同一 - エントリがterm
Tでcommitされたとき、term U (>T) のLeaderのログにそのエントリは含まれる - あるエントリをステートマシンに applyしたとき、同一indexで異なるエントリを他サーバは applyしない
Leader選出 ログa,bのどちらがより「進んでいる」か調べるには最後のエントリ Last(a),Last(b)を比べればよい 比較関数は以下のようにかける ここではあるエントリeのindex,termを取得する関数をindex(e),term(e)と表す - もしterm(Last(a)) != term(Last(b)) であるなら
term(Last(a)) < term(Last(b)) - もしterm(Last(a)) == term(Last(b))であるならindex(Last(a)) < index(Last(b)) 各サーバは以下の条件が満たされる相手にのみ投票する - 相手のtermが自分より大きい、または同じ termかつまだ今term中に投票していない - 相手のログが自分より進んでいる(同一含む)
Leader選出 (2) 前ページのLeader選出条件が満たされていれば Leaderは今までcommitされたエントリを全て含んでいることを背理法で証明出来る 1. termTにLeaderTがあるエントリをcommitし、termU(>T)に LeaderUがそのエントリを保存していないことを仮定 2. LeaderTはcommitに過半数のサーバに合意をとっており、 LeaderUはLeaderになるために過半数のサーバに合意をとって
いる よってLeaderTのcommitに参加しかつLeaderUの選出に参加し たサーバが少なくとも一台存在する(以降 voterと呼ぶ) 3. voterはLeaderUの選出に参加する前に LeaderTのcommitに参 加している LeaderUの選出に参加したvoterのtermはUになり、その後には LeaderTのcommitに参加できない FollowerはLeaderのエントリと衝突した時のみエントリを上書きするため、 voterはLeaderUの選出に参加するまで LeaderTのcommitしたエントリを 保存している 仮定よりvoterはLeaderUの選出に参加している。選出条件より LeaderU のログはvoterのログより進んでいる必要がある LeaderUの選出にあたり、最後のエントリの比較で 2通りが考えられ、どち らも矛盾を起こす voterとLeaderUの最後のエントリの termが等しい場合、最後のエントリの indexはvoterの方が小さいと投票されないことから、 voterのエントリはUに 全て含まれる。よって矛盾が起こる LeaderUの最後のエントリの termの方が大きい場合、それは Tよりも大きく なる。LeaderUの最後のエントリを追加した LeaderXは今までcommitされ たエントリを持っているので Uにも今までcommitされたエントリが複製さ れ、ここにTがcommitしたエントリも含まれる。よって矛盾が起こる(循環し ているがT<X<Uより6-1に収束する) 4. 5. 6-1. 6-2.
各サーバの状態 Persistent stateはストレージに保存する Volatile(揮発性) stateはサーバ開始/再開時に初期化される nextIndex[]: 各サーバに次にどのエントリを送るか 選挙後にリーダーの最後のエントリのindex+1に初期化され、 一致するまで-1していく matchIndex[]:
各サーバがどこまでリーダーのログと一致しているか 選挙後に0で初期化され、ログが一致すれば更新される このときnextIndex[]のデクリメントは止まり、 その後matchIndexとnextIndexは同じペースで進んでいく
AppendEntries RPC Leaderが他のサーバーにログを送るRPC 送るエントリがなくても定期的に送ることでheartbeatの役割を果たす indexとtermが等しければエントリは等しい性質が保たれているので LeaderはnextIndexの一つ前のエントリのindexとterm (prevLogIndexとprevLogTerm)を送る。 FollowerはprevLogIndexかつprevLogTermのエントリを もっていればentries[]を保存した後success=trueを返す またLeaderのcommit
index が自身のcommit indexより大きい場合 min(leaderCommit,index of last new entry)に更新する
RequestVote RPC Candidateになったサーバが投票を求めるRPC 各サーバは以下の条件が満たされる相手にのみ 投票する(再掲) - 相手のtermが自分より大きい、または同じ termかつ まだ今term中に投票していない -
相手のログが自分より進んでいる(同一含む)
リクエスト再送時の注意点 クライアントは以下のような時リクエストを再送する必要がある - リクエストを送った直後にサーバがクラッシュ - サーバがLeaderではない(leader hintがあればもらう、これによって線形時間で Leaderが分かる) このときサーバはリクエストが重複して実行されないようにする必要がある 論文には各クライアントに
idを振り、各リクエストにシリアルナンバーをつける方法が紹介されている
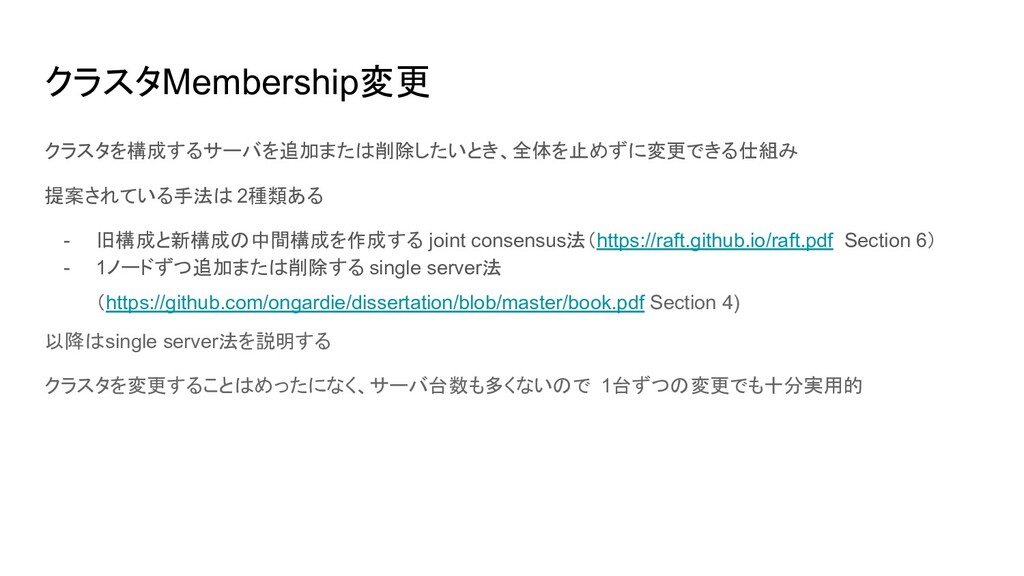
クラスタMembership変更 クラスタを構成するサーバを追加または削除したいとき、全体を止めずに変更できる仕組み 提案されている手法は 2種類ある - 旧構成と新構成の中間構成を作成する joint consensus法(https://raft.github.io/raft.pdf Section 6)
- 1ノードずつ追加または削除する single server法 (https://github.com/ongardie/dissertation/blob/master/book.pdf Section 4) 以降はsingle server法を説明する クラスタを変更することはめったになく、サーバ台数も多くないので 1台ずつの変更でも十分実用的
特別なエントリ クラスタ構成は特別なエントリで管理する Leaderはあるサーバを追加・削除するリクエストを受け取ったとき、特別なエントリのコマンドに - 以前の構成 - 次の構成 を記述してログにappendする。(クラスタの構成をステートマシンで管理する) このエントリの「次の構成」はcommitされるときではなく、appendされるときに適用される このようにすることで特別なエントリをcommitした時、過半数のサーバに「次の構成」はすでに適用されている
特別なエントリも通常のエントリ同様、commitされるまで他のエントリに上書きされる可能性がある この場合「以前の構成」に戻る必要があることに注意 またLeaderはまだcommitされていない特別なエントリを持っている場合、構成変更のリクエストを拒否する
構成変更時の注意点 旧構成の過半数+新構成の過半数が (旧構成∪新構成)の台数以下のとき、 どちらの合意にも参加している voterが存在しない 可能性が出てくる この時、同一termで複数のLeaderが選出されてしまう
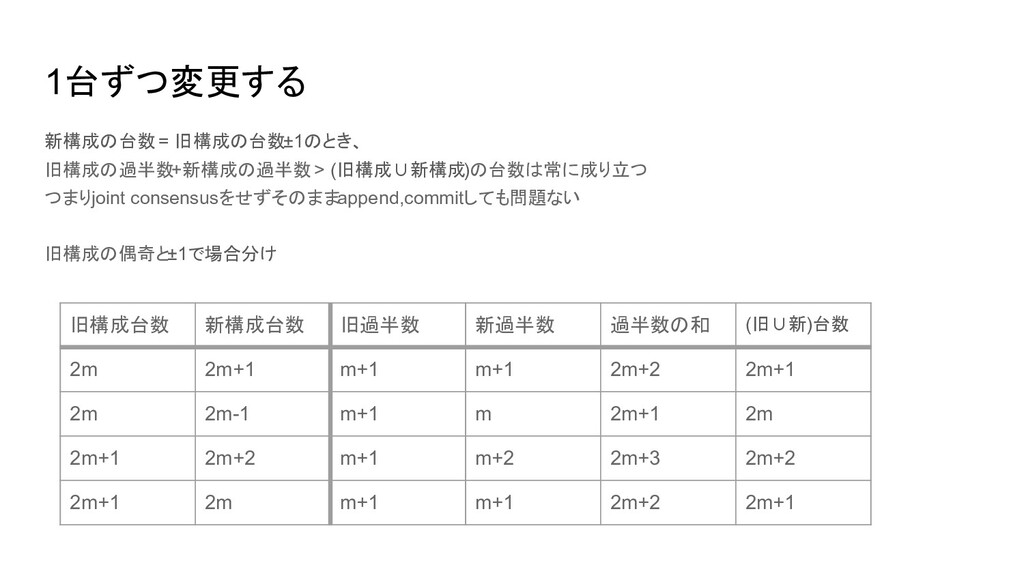
1台ずつ変更する 新構成の台数 = 旧構成の台数±1のとき、 旧構成の過半数+新構成の過半数 > (旧構成∪新構成)の台数は常に成り立つ つまりjoint consensusをせずそのままappend,commitしても問題ない 旧構成の偶奇と±1で場合分け
旧構成台数 新構成台数 旧過半数 新過半数 過半数の和 (旧∪新)台数 2m 2m+1 m+1 m+1 2m+2 2m+1 2m 2m-1 m+1 m 2m+1 2m 2m+1 2m+2 m+1 m+2 2m+3 2m+2 2m+1 2m m+1 m+1 2m+2 2m+1
1台のサーバから始める 1台ずつのクラスタMembership変更を実装した際、 初期のクラスタを構成するサーバ群の情報も(例外的な処理をすることなく)ログに含めたい 1つのサーバを選び以下のような特別なエントリを appendしcommitする(1台構成なのですぐcommit出来る) - index=1 - 前の構成={} -
次の構成={自身のサーバ名} 以降このクラスタに1台ずつ追加していく
Leadershipの移管 サーバのメンテナンスなどで、 Leaderをクラスタから削除したいときがある Followerがタイムアウトして選挙...をしている間、 クライアントからのクエリを受け取れない時間が発生するのを避けたい Leaderはログが十分に追いついているサーバを 1つ選び、そのサーバを強制的にタイムアウトさせる 新しいLeaderが選出され旧LeaderがFollowerになったあとで削除する
サーバの混乱を防ぐ クラスタから削除されたサーバがそれを知らないままタイムアウトした場合、混乱が起こる 「自身が保存しているクラスタ情報に含まれないサーバからの通信を拒否」すればいいと考えるかもしれないが この仕組みを使うと、既存クラスタに自身を追加してもらう場合、その特別なエントリまで拒否してしまう そこで投票する際に制約を加える手法が提案されている LeaderからAppendEntries RPCを受け取った最後の時刻を s,RequestVote RPCを受け取った時刻をtとすると s+(タイムアウト時間)
> t のとき投票しない この制約はLeadership移管と競合するが、強制タイムアウトした新 Leader候補はRequestVote RPCに 特別なフラグをつけることによって解決できる
Log compaction あるサーバがLeader含む過半数のサーバのログから大きく遅れている場合、 Leaderがある地点までのエントリを適用したステートマシン自体をサーバに送り、一気に追いつく仕組み 実装できていないので説明できません 余談 etcdは「LeaderからみたFollowerのログの進み具合」を表す状態を定義している https://github.com/etcd-io/etcd/blob/master/raft/design.md
おしまい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![各サーバの状態 Persistent stateはストレージに保存する Volatile(揮発性) stateはサーバ開始/再開時に初期化される nextIndex[]: 各サーバに次にどのエントリを送るか 選挙後にリーダーの最後のエントリのindex+1に初期化され、 一致するまで-1していく matchIndex[]:](https://files.speakerdeck.com/presentations/4f956d3a62204789acdcbe7636a74af8/slide_12.jpg){kind=link}
![AppendEntries RPC Leaderが他のサーバーにログを送るRPC 送るエントリがなくても定期的に送ることでheartbeatの役割を果たす indexとtermが等しければエントリは等しい性質が保たれているので LeaderはnextIndexの一つ前のエントリのindexとterm (prevLogIndexとprevLogTerm)を送る。 FollowerはprevLogIndexかつprevLogTermのエントリを もっていればentries[]を保存した後success=trueを返す またLeaderのcommit](https://files.speakerdeck.com/presentations/4f956d3a62204789acdcbe7636a74af8/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}