Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Animatediffの生成時間の壁を突破しようとして失敗した話
Search
mattya_monaca
September 23, 2023
830
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Animatediffの生成時間の壁を突破しようとして失敗した話
mattya_monaca
September 23, 2023
More Decks by mattya_monaca
See All by mattya_monaca
Wan2.5 Preview 発表資料
mattyamonaca
1
6.4k
画像生成AIを応用して 作画補助ツールを作成した話
mattyamonaca
1
2k
Featured
See All Featured
The Limits of Empathy - UXLibs8
cassininazir
1
470
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Mobile First: as difficult as doing things right
swwweet
225
10k
Claude Code のすすめ
schroneko
67
230k
Making Projects Easy
brettharned
120
6.7k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
HDC tutorial
michielstock
2
740
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
340
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Transcript
Animatediffの生成時間の壁を 突破しようとして失敗した話 発表者: 抹茶もなか
自己紹介 経歴 • 自然言語処理関係の研究室出身 • 機械学習エンジニア歴 約5年 • お絵描き歴 約3年
• 個人開発歴 約7年 最近の活動 • 画像生成ブームに乗じてOSS活動を開始 • お絵描き×AIでサービス作り • 動画生成にもお熱 ←今日話すのはここ 抹茶もなか @GianMattya mattyamonaca
皆さん、Animatediffは触っていますか?
Animatediffとは テキストを入力すると短時間の動画を生成してくれる技術 • 既存の動画生成と異なり、個人がチューニングしたモデルや LoRAにも対応している • VRAM12GB程度で生成が可能 • WebUI, ComfyUIにも対応
が、発表当初はあんまり話題になっていなかった (出展:「AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning 」URL; 2307.04725.pdf (arxiv.org))引用日:2023/09/23
Animatediff×ControlNetの衝撃 ControlNetと組み合わせることができるようになった!! • TDSさん(@TDS_95514874)がAnimatediffをControlNetで制御できる事を発見 • 動画の始点と終点に対応する画像を入力することで、 ContolNetによる制御が可能 • アニメーションの中割自動生成に使えるのではという事で一躍話題に 一方で、新たな課題も明確に
• ControlNetで出力される動画を制御できるようになったが、生成される動画が短い • 始点と終点を複数用意しつなげ合わせることはできるが、連続性 /一貫性に難がある
連続性/一貫性のある長時間動画を生成したい!
Animatediffの生成時間は何によって決まる? Batch×Channel×height×width×frameの5次元テンソルを入力とし訓練 • 画像生成モデルの入力データにフレームが追加 • 論文では16フレームで学習したと記載されている ➡学習時のフレーム数によって生成できる動画の時間が決定! じゃあ学習時の入力フレーム数を増やせば解決!…というわけにもいかない • 学習時のフレーム数を増やせば増やすほど必要な計算リソースが足りない
• フレーム数が増えるほど学習も困難になる • 例え学習が可能だったとしても、長時間のテキスト付データセットが足りない ➡学習以外の方法で、連続性/一貫性を保持する手法が必要
提案手法の説明に入る前に…
Motion Module frame 1 frame 2 frame 15 frame 16
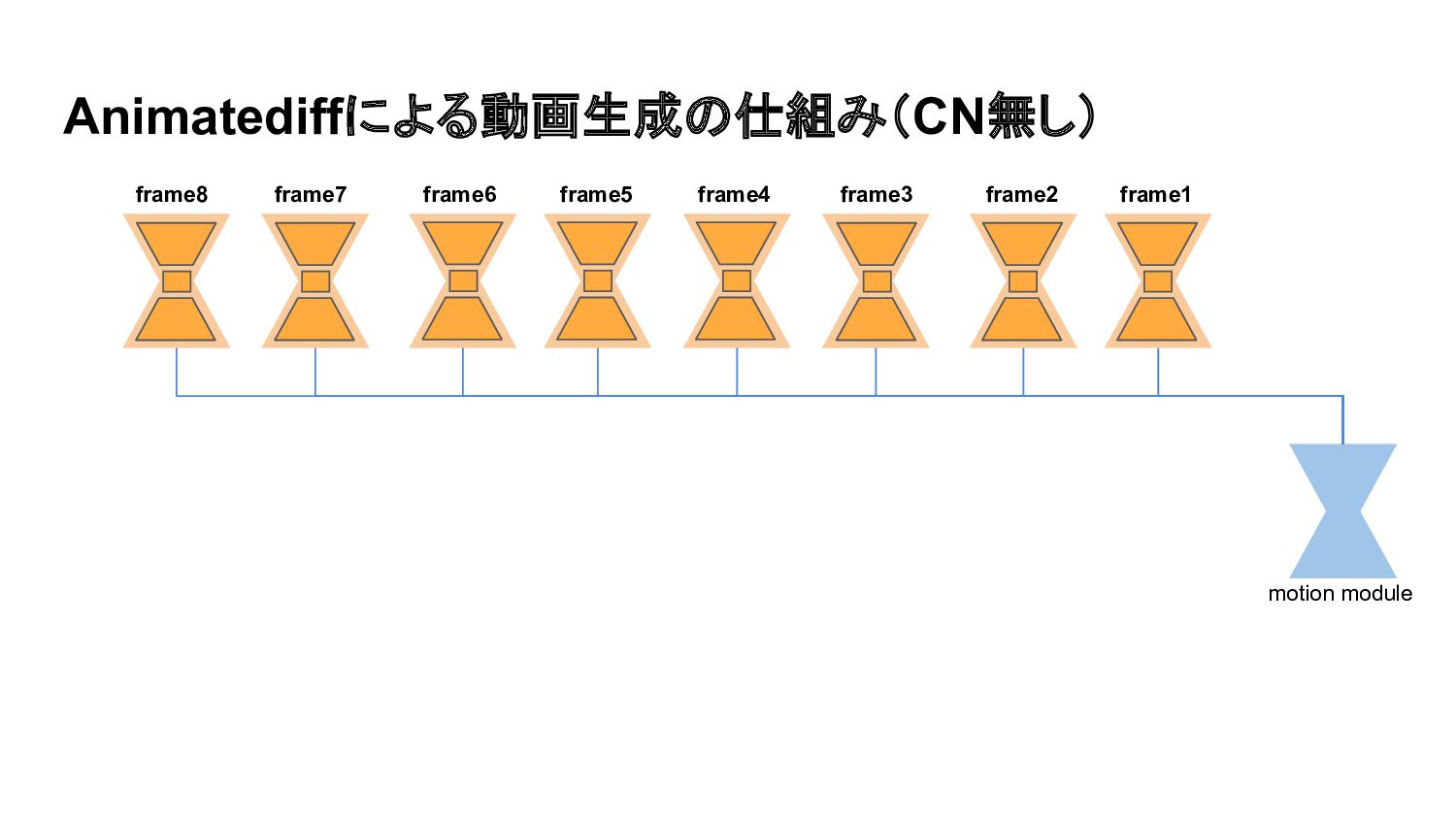
Animatediffによる動画生成の仕組み(CN無し) ×16 ・・・ VAE ×16 Motion Moduleは今何番目のフレームを生成しているかを認識できる
Animatediffによる動画生成の仕組み(CN無し) motion module frame8 frame7 frame6 frame5 frame4 frame3 frame2
frame1
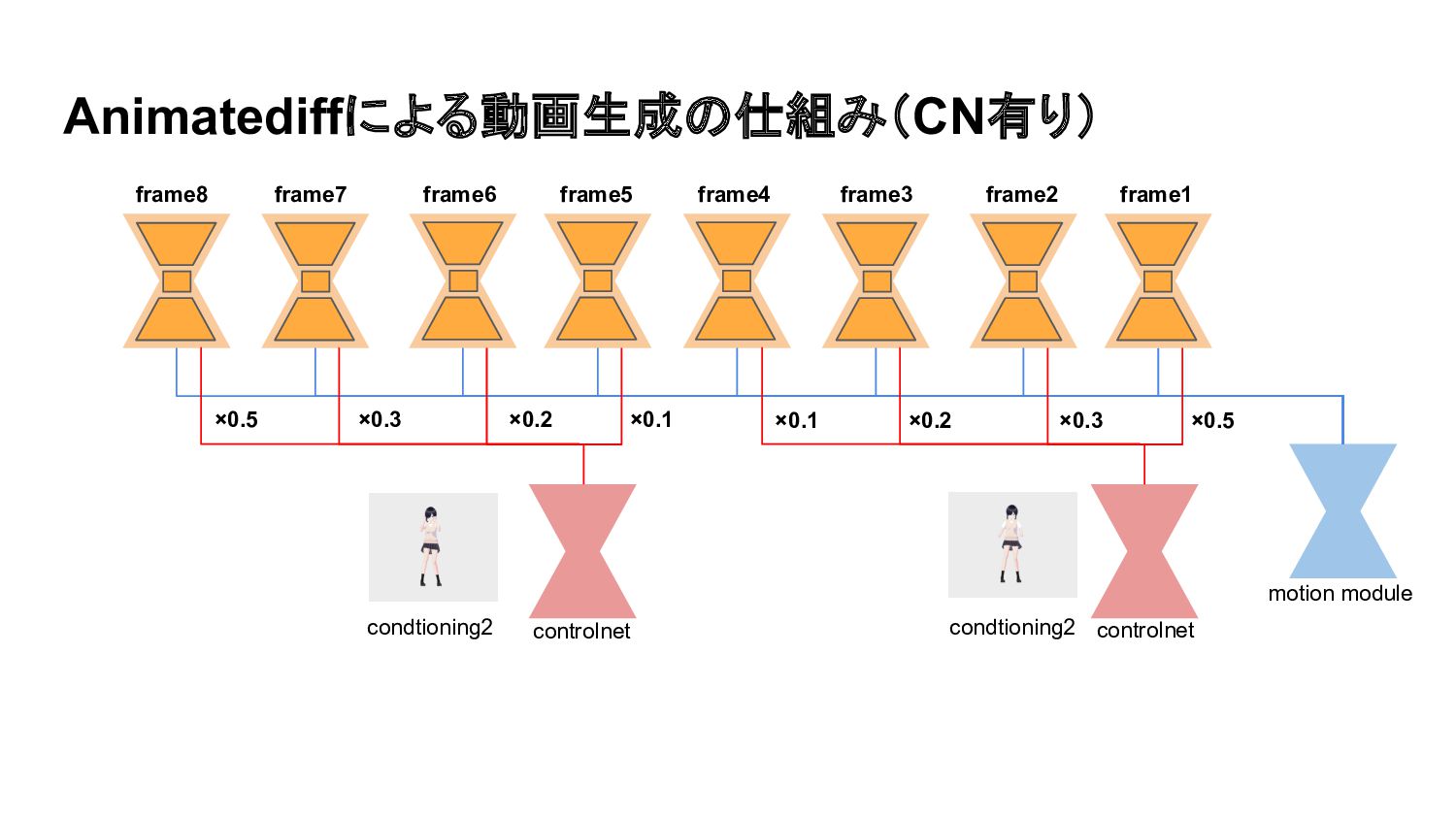
Animatediffによる動画生成の仕組み(CN有り) ×0.5 ×0.3 ×0.2 ×0.1 ×0.5 ×0.3 ×0.2 ×0.1 motion
module controlnet controlnet condtioning2 condtioning2 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1
以上を踏まえてどのように連続性/一貫性を担保するか
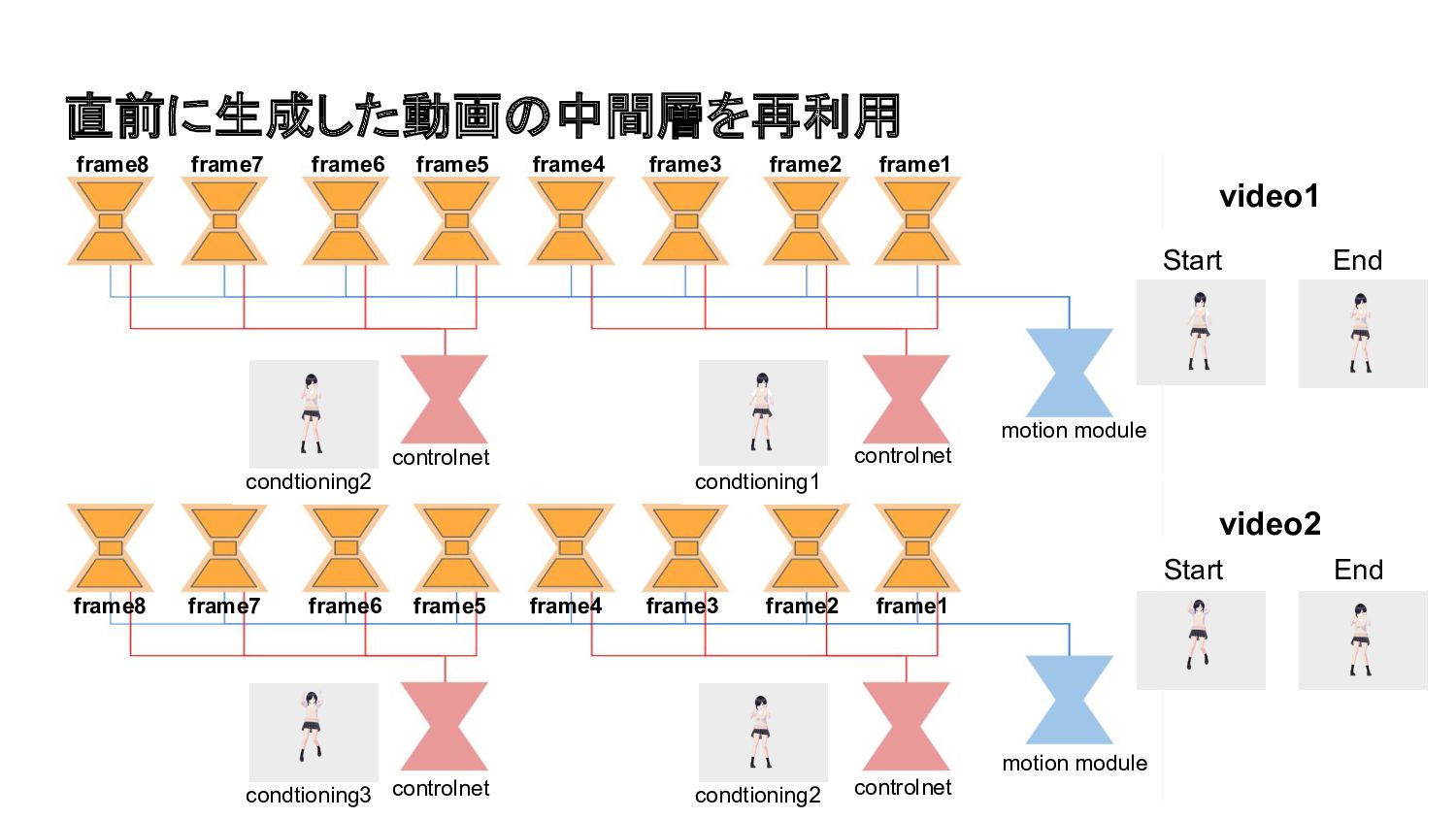
直前に生成した動画の中間層を再利用 Start End condtioning2 condtioning1 Start End condtioning3 condtioning2 controlnet
controlnet controlnet controlnet motion module motion module video1 video2 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1
直前に生成した動画の中間層を再利用 Start End condtioning2 condtioning1 Start End condtioning3 condtioning2 Conditioning2の影響を受ける
controlnet controlnet controlnet controlnet motion module motion module video1 video2 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1 Conditioning2の影響を受ける
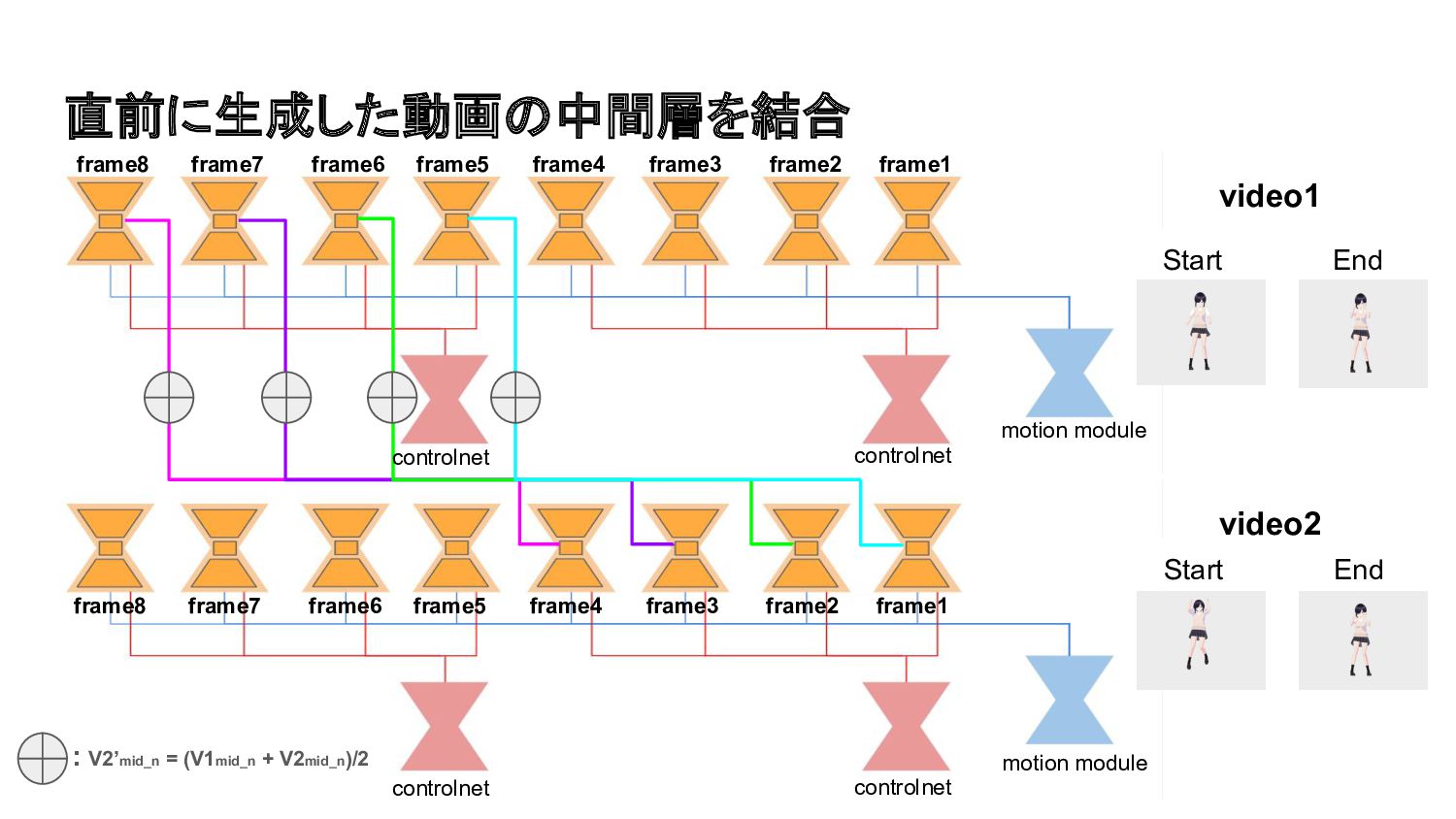
直前に生成した動画の中間層を結合 Start End Start End controlnet controlnet controlnet controlnet motion
module motion module video1 video2 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1 : V2’mid_n = (V1mid_n + V2mid_n)/2
中間層を再利用せずvideo1, video2を単独で生成 video1 video2
中間層を再利用せずvideo1, video2を単独で生成 video1(5-8frame)
中間層を再利用せずvideo1, video2を単独で生成 video2(1-4frame)
中間層を再利用しvideo1, video2を合成して生成 video1 video2
中間層を再利用しvideo1, video2を合成して生成 video1(5-8frame)
中間層を再利用しvideo1, video2を合成して生成 video2(1-4frame)
(再掲)中間層を再利用せずvideo1, video2を単独で生成 video2(1-4frame)
とはいえ…
実用性という意味ではまだまだ遠く及ばず… ある程度連続性/一貫性が向上したものの、動画にすると違和感を感じる • 絵柄や等身、背景の変化のほか、動画が切り替わるタイミングで白飛びしやすい • 合成を行うと、合成元の要素が合成結果に不自然に残ってしまうことがある 微妙に想定と違う動作をしている • 生成した動画の後半と前半を混ぜているため、混ぜていない部分( Video2の5フレーム以降
等)は生成内容が変化しないと思っていたが、変化している video2
手間がかかってる割に効果が薄い
敗因 • モデルアーキテクチャに手を出す前にもっとやるべきことがあった ◦ そもそも動画生成のクオリティが低いのでプロンプト /モデル選定を詰めるべきだった ▪ 皆が生成している動画のクオリティが高すぎる ◦ IP
Adapterとの組み合わせや、 motion moduleの新Ver等、新技術の検証を先にやるべきだった ▪ 相変わらず1週間程度で環境が変わるので付いていくのがつらい • LT会のネタだからと奇をてらった事をやりすぎた ◦ (自分で設定したけど)発表順が最後だし何か凝ったことやらなきゃ …とか考えていた • LT会前に仕事が炎上して作業時間が全く取れなかった
今回の教訓 凝ったことし過ぎると失敗するので 王道かつ簡単な所から攻めていくべき!
というわけで、王道かつ簡単な内容に挑戦した人の発表を生 成AIなんでもLT会はお待ちしております (もちろん凝ったことやった人の発表も是非!)
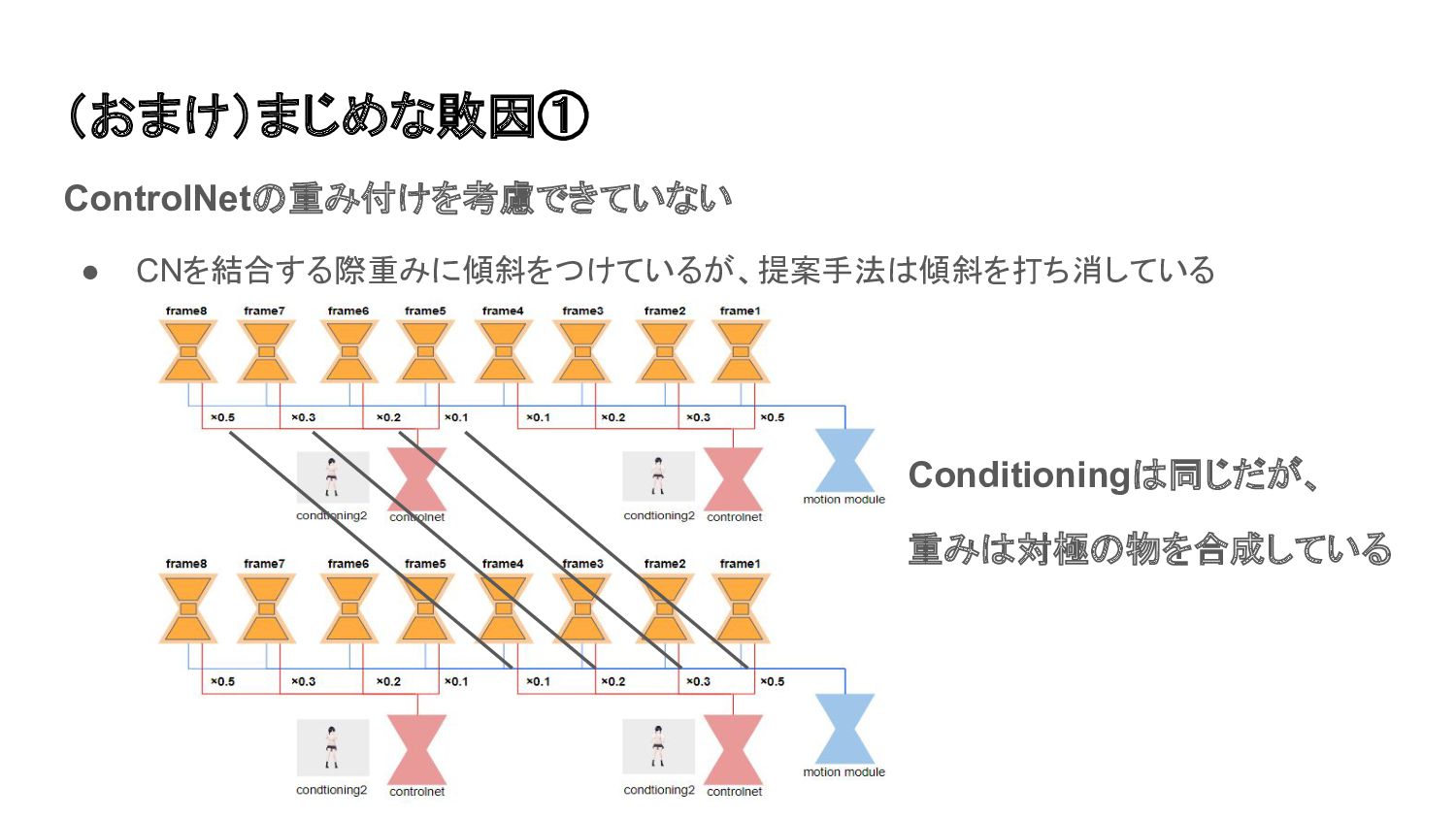
(おまけ)まじめな敗因① ControlNetの重み付けを考慮できていない • CNを結合する際重みに傾斜をつけているが、提案手法は傾斜を打ち消している Conditioningは同じだが、 重みは対極の物を合成している
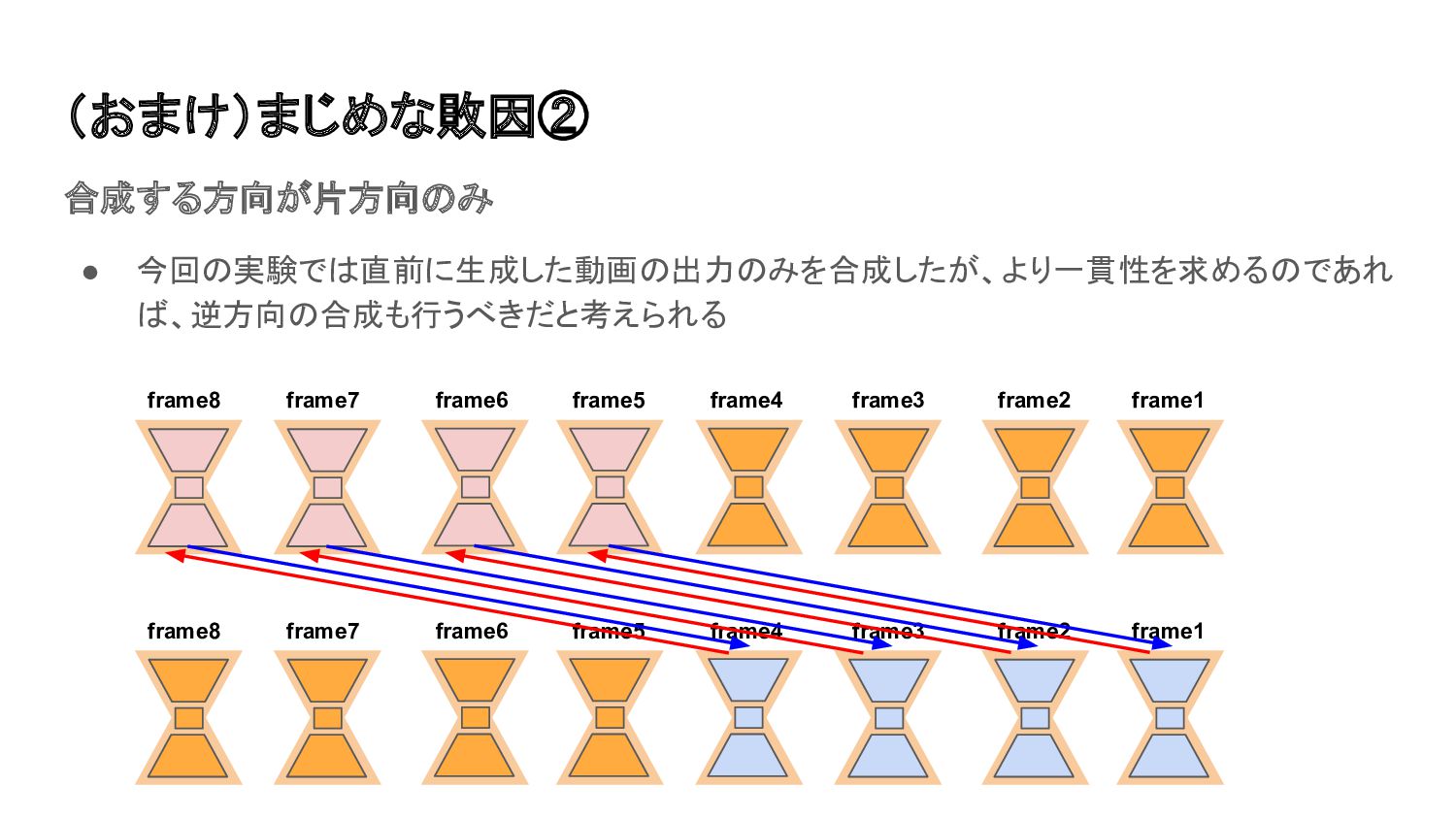
(おまけ)まじめな敗因② 合成する方向が片方向のみ • 今回の実験では直前に生成した動画の出力のみを合成したが、より一貫性を求めるのであれ ば、逆方向の合成も行うべきだと考えられる frame8 frame7 frame6 frame5 frame4
frame3 frame2 frame1 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1
(おまけ)まじめな敗因② 合成する方向が片方向のみ • 今回の実験では直前に生成した動画の出力のみを合成したが、より一貫性を求めるのであれ ば、逆方向の合成も行うべきだと考えられる frame8 frame7 frame6 frame5 frame4
frame3 frame2 frame1 frame8 frame7 frame6 frame5 frame4 frame3 frame2 frame1
宣伝 他にもAI×画像で色々挑戦中なので、ご興味ある方はTwitterとGithubのフォローをお願 いします! 抹茶もなか @GianMattya mattyamonaca AIアニメーション作成 高精度な背景切り抜き 一枚絵の自動レイヤー分け
ご清聴ありがとうございました!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}