Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
umamusume22
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
madoka223
May 21, 2021
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
umamusume22
madoka223
May 21, 2021
More Decks by madoka223
See All by madoka223
2025_10_1 LT会 私が発信中の記事やSNSなどを紹介!
mayo233
0
92
2025_10_1 LT会 私が発信中の記事やSNSなどを紹介!
mayo233
0
11
umamusume22
mayo233
0
590
Featured
See All Featured
4 Signs Your Business is Dying
shpigford
187
22k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Being A Developer After 40
akosma
91
590k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
How to Talk to Developers About Accessibility
jct
2
380
Code Reviewing Like a Champion
maltzj
528
40k
Transcript
2021/5/21 lidar_200 file:///Users/suzukamayo/Downloads/lidar_200 (2).html 1/3 pythonによる確率,統計の基礎を勉強した 北九州市⽴⼤学 国際環境⼯学部 情報メディア⼯学科4年 鈴⿅真
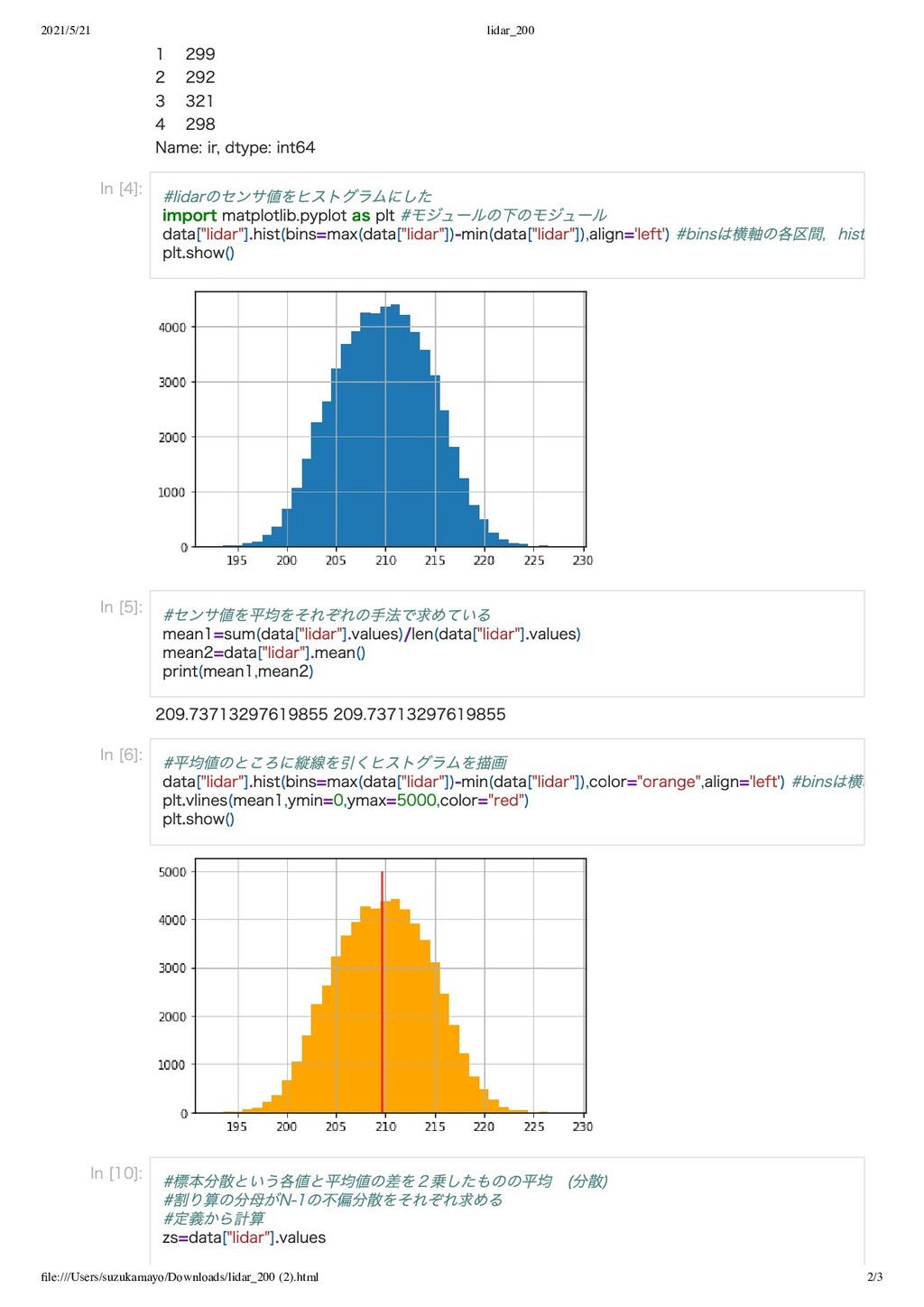
世 ⾃⼰紹介 出⾝:北九州市 好きな⾷べ物:チョコレート 好きなプログラミング⾔語: python サービスロボット の開発を⾏うチームに所属 ハッカソン出場経験有 ⼤学院に進学予定 ⼈⼯知能の研究開発職を志望 現在は⾞椅 ⼦が最短経路を歩む⾃動制御の研究を⾏っている data time ir lidar 0 20180122 95819 305 214 1 20180122 95822 299 211 2 20180122 95826 292 199 3 20180122 95829 321 208 4 20180122 95832 298 212 ... ... ... ... ... 58983 20180124 120023 313 208 58984 20180124 120026 297 200 58985 20180124 120030 323 204 58986 20180124 120033 326 207 58987 20180124 120036 321 208 58988 rows × 4 columns 0 305 GW 期間中は下記の本の勉強( 理論) ,⾞椅⼦⾃動制御の実験を⾏った ・lidar というセンサーから取得した値をヒストグラムにした ・値の変動であるノイズを数値化 In [2]: #lidarのセンサ値を採取した⽇付,時刻,光センサからのセンサ値,lidarからのセンサ値を表⽰ import pandas as pd data=pd.read_csv("/Users/suzukamayo/研究/理論/LNPR/data/sensor_data_200.txt",delimiter= header=None,names=("data","time","ir","lidar")) data Out[2]: In [12]: print(data["ir"][0:5]) #data["lidar"]から先頭の5個の値を出⼒している
2021/5/21 lidar_200 file:///Users/suzukamayo/Downloads/lidar_200 (2).html 2/3 1 299 2 292 3
321 4 298 Name: ir, dtype: int64 209.73713297619855 209.73713297619855 In [4]: #lidarのセンサ値をヒストグラムにした import matplotlib.pyplot as plt #モジュールの下のモジュール data["lidar"].hist(bins=max(data["lidar"])-min(data["lidar"]),align='left') #binsは横軸の各区間,hist plt.show() In [5]: #センサ値を平均をそれぞれの⼿法で求めている mean1=sum(data["lidar"].values)/len(data["lidar"].values) mean2=data["lidar"].mean() print(mean1,mean2) In [6]: #平均値のところに縦線を引くヒストグラムを描画 data["lidar"].hist(bins=max(data["lidar"])-min(data["lidar"]),color="orange",align='left') #binsは横軸 plt.vlines(mean1,ymin=0,ymax=5000,color="red") plt.show() In [10]: #標本分散という各値と平均値の差を2乗したものの平均 (分散) #割り算の分⺟がN-1の不偏分散をそれぞれ求める #定義から計算 zs=data["lidar"].values
2021/5/21 lidar_200 file:///Users/suzukamayo/Downloads/lidar_200 (2).html 3/3 23.407709770274106 23.40810659855441 23.4077097702742 23.408106598554504 23.4077097702742
23.408106598554504 4.838151482774605 4.83819249292072 4.838192492920729 まとめ 不偏分散といった統計学の基礎を勉強した ノイズといった値をグラフ化にすることができた 標準偏差を 求めるコードを書いて実⾏することで正しく計算可能なことがわかった ⾞椅⼦が障害物検知する⾃律⾛⾏シス テムが8割完成 おまけ 障害物を避けていく⾞椅⼦の動画をお⾒せします mean=sum(zs)/len(zs) diff_square=[(z-mean)**2 for z in zs] sampling_var=sum(diff_square)/(len(zs)) #標本分散 unbiased_var=sum(diff_square)/(len(zs)-1) #不偏分散 print(sampling_var) print(unbiased_var) #pandasを使⽤ pandas_sampling_var=data["lidar"].var(ddof=False) #標本分散 pandas_default_var=data["lidar"].var() #不偏分散 print(pandas_sampling_var) print(pandas_default_var) #numpyを使⽤ import numpy as np numpy_default_var=np.var(data["lidar"]) #デフォルト(標本分散) numpy_unbiased_var=np.var(data["lidar"], ddof=1) #(不偏分散) print(numpy_default_var) print(numpy_unbiased_var) In [11]: #標準偏差 つまり分散の正の平⽅根 import math #定義から計算 stddev1=math.sqrt(sampling_var) stddev2=math.sqrt(unbiased_var) #pandasを使⽤ pandas_stddev=data["lidar"].std() print(stddev1) print(stddev2) print(pandas_stddev)
{kind=link}
{kind=link}
{kind=link}