Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
FableはすごいがローカルPCで動くLLMも活用していきたい.pdf
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
松尾淳平
June 15, 2026
580
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
FableはすごいがローカルPCで動くLLMも活用していきたい.pdf
松尾淳平
June 15, 2026
More Decks by 松尾淳平
See All by 松尾淳平
探して_入れて_作って_使う_Agent_Skills___LT.pdf
peintangos
2
210
Messaging API で AI エージェントの入口を作ってみた
peintangos
0
26
AIが盛んな時代に 技術記事を書き始めて起きた私の中での小さな変化
peintangos
0
550
Featured
See All Featured
Paper Plane
katiecoart
PRO
2
52k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Embracing the Ebb and Flow
colly
88
5.1k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
ラッコキーワード サービス紹介資料
rakko
1
4.1M
The Invisible Side of Design
smashingmag
301
52k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
New Earth Scene 8
popppiees
3
2.4k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Transcript
? 2026.06.12 LIGHTNING TALK Fableはすごいが、 ローカルPCで動くLLM も活用していきたい EDGE LLM —
LOCAL INFERENCE
01 ABOUT 自己紹介 EDGE LLM — LOCAL INFERENCE 松尾淳平 M20株式会社
Even G2 / R1 を買いました。 次に欲しいもの — DGX Spark とスタックチャン
02 NEWS 個人的な直近の2大発表 — その①: Google I/O EDGE LLM —
LOCAL INFERENCE Prompt API が Stable に Chrome 148 で Stable 到達・フラグ不要で本番利用OK に 2026.05.19 – 20
02 NEWS 個人的な直近の2大発表 — その②: WWDC EDGE LLM — LOCAL
INFERENCE macOS 27 に fm CLI 2026.06.08 – 12
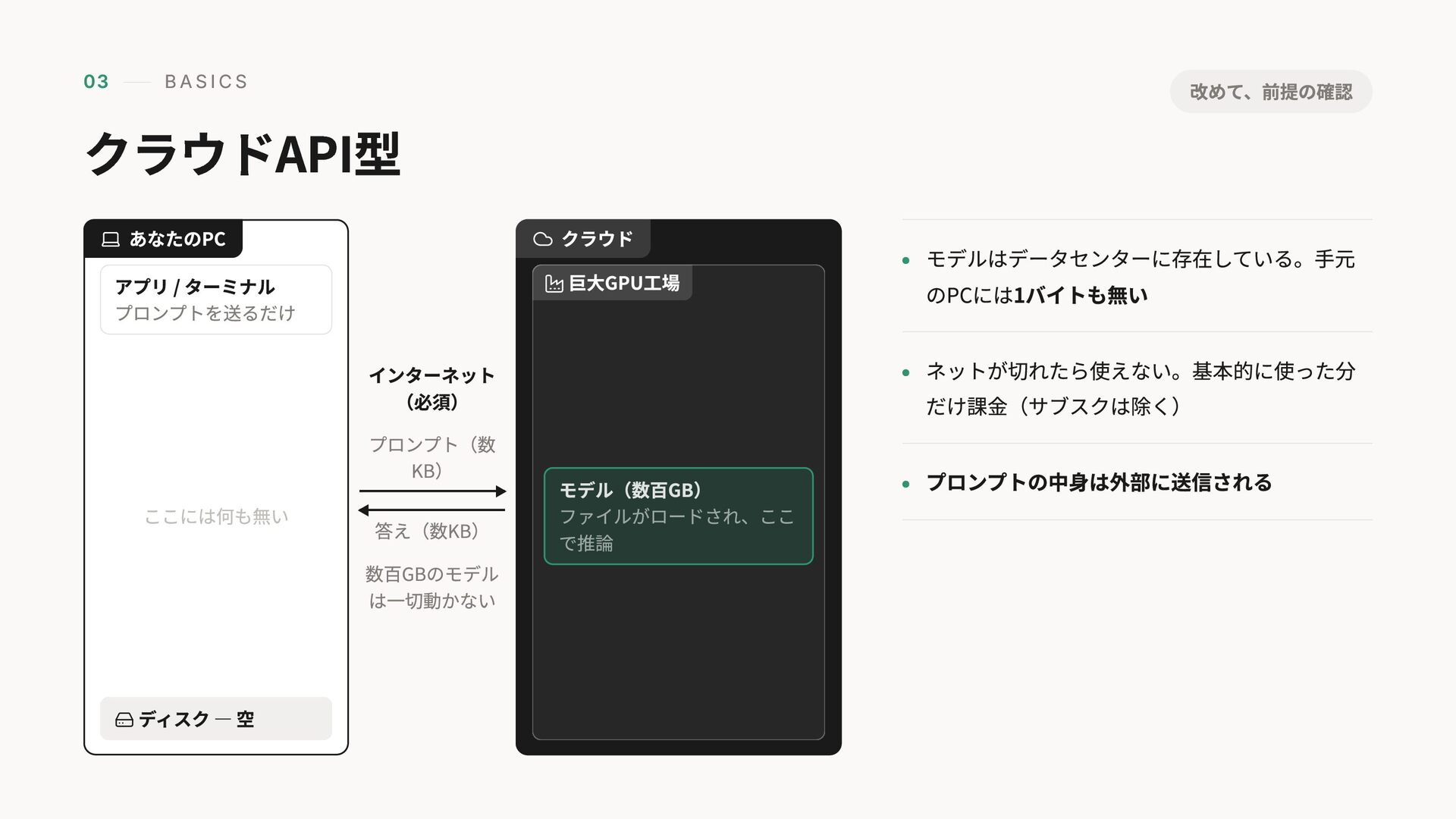
03 BASICS クラウドAPI型 インターネット (必須) プロンプト(数 KB) 答え(数KB) 数百GBのモデル は一切動かない
アプリ / ターミナル プロンプトを送るだけ ここには何も無い ディスク — 空 あなたのPC クラウド モデル(数百GB) ファイルがロードされ、ここ で推論 巨大GPU工場 モデルはデータセンターに存在している。手元 のPCには1バイトも無い ネットが切れたら使えない。基本的に使った分 だけ課金(サブスクは除く) プロンプトの中身は外部に送信される 改めて、前提の確認
04 HANDS-ON ① ブラウザ標準型 — Chrome Prompt API ネ ッ
ト 不 要 Chromeの持ち物フォルダに 4GB 全サイト共有・初回利用時に Google から自動DL あなたのPC Webページ = 注文の窓口 コード数行で注文。店の奥には手を出せない ▼ 注文 ▲ 答えが返る Chrome Gemini Nano が GPU / CPU で推論 要件: GPUは VRAM 4GB超、CPUは RAM 16GB+・4コア+ 店の奥 = Chrome本体 ✕ 出番なし クラウド 自分では何も用意しなくていい。配布も置き場 所も Google 持ち 何度呼んでもタダ・2回目以降はネット不要 初回のみ自動DL(構図は ② と同じ) 。空き容量 22GB が要件 引き換えに、モデルは選べない $ du -sh ~/Library/Application\ Suppor t/Google/Chrome/OptGuideOnDeviceModel 4.0G
04 HANDS-ON ① の実装 — JavaScript 2行 EDGE LLM —
LOCAL INFERENCE const session = await LanguageModel.create(); // Chrome 148+(Stable) const answer = await session.prompt('このエラーログを3行で要約して: ' + log); 同じタスク: ログを3行で要約
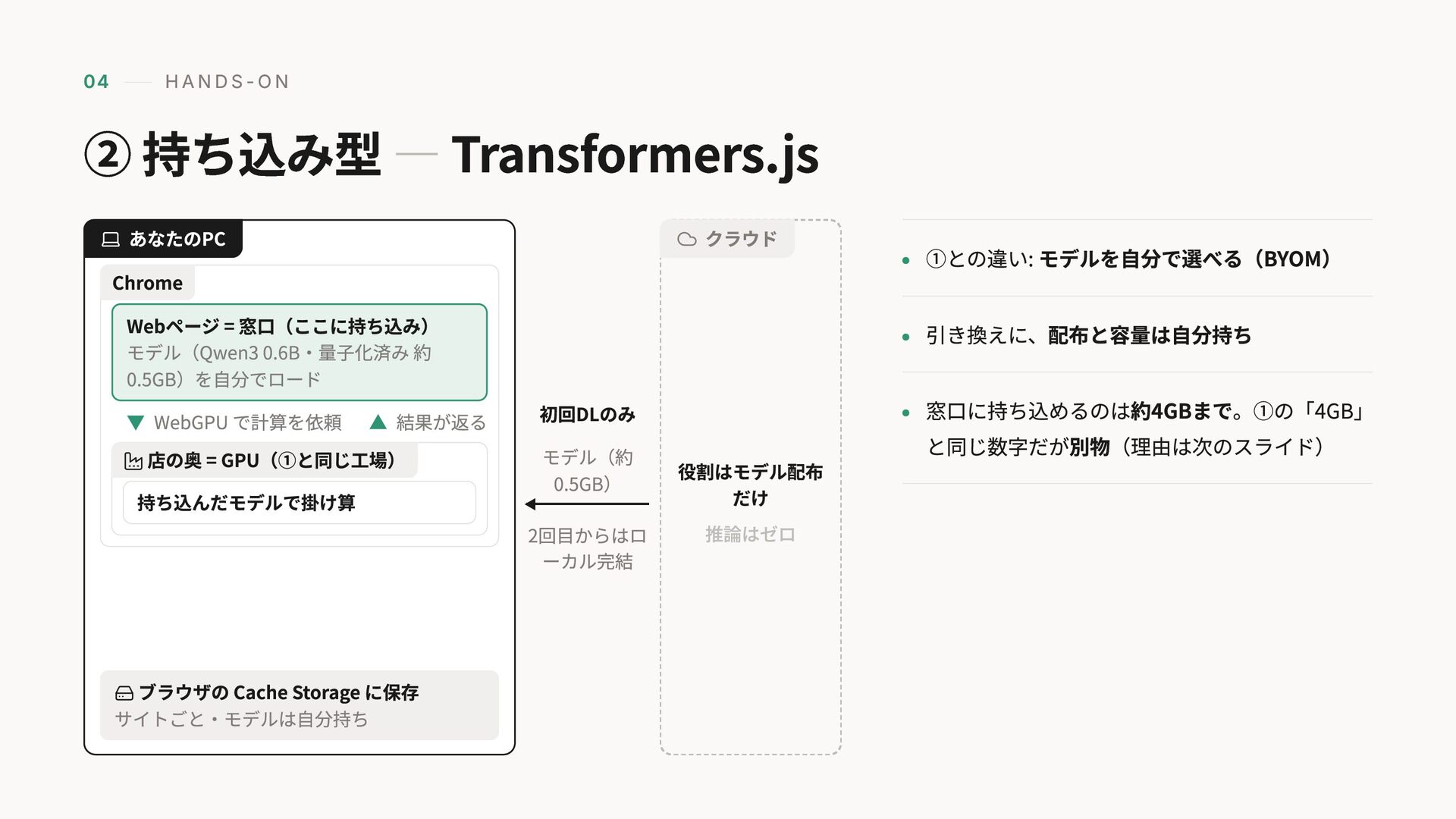
04 HANDS-ON ② 持ち込み型 — Transformers.js 初回DLのみ モデル(約 0.5GB) 2回目からはロ
ーカル完結 ブラウザの Cache Storage に保存 サイトごと・モデルは自分持ち あなたのPC Webページ = 窓口(ここに持ち込み) モデル(Qwen3 0.6B・量子化済み 約 0.5GB)を自分でロード ▼ WebGPU で計算を依頼 ▲ 結果が返る Chrome 持ち込んだモデルで掛け算 店の奥 = GPU(①と同じ工場) 役割はモデル配布 だけ 推論はゼロ クラウド ①との違い: モデルを自分で選べる(BYOM) 引き換えに、配布と容量は自分持ち 窓口に持ち込めるのは約4GBまで。①の「4GB」 と同じ数字だが別物(理由は次のスライド)
04 HANDS-ON ② の実装 — JavaScript 数行 EDGE LLM —
LOCAL INFERENCE import { pipeline } from '@huggingface/transformers'; const generate = await pipeline('text-generation', 'onnx-community/Qwen3-0.6B-ONNX', { device: 'webgpu' }); // ← モデルは自由(BYOM) const out = await generate('このエラーログを3行で要約して: ' + log); 同じタスク: ログを3行で要約
04 HANDS-ON 4GBの壁 — メモリが余っていても、使えない 結論 — ページが番号札で指せる範囲は 4GB だけ
4GB 番号札が届かない領域 PCに64GB積んでいても、ここはWebページから見えない 理由 番号札が 32bit → 2³² ≈ 42億枚 × 1バイト = 4GB だから、どうなる? ① Gemini Nano 壁の外(Chrome本体 = 店の奥)にいる → 4GBの影響なし ② Transformers.js 壁の中(ページの中)で動く → だから小型モデルを選ぶ ※ 64bit番号札(Memory64)は2025年に解禁済み。ただし遅くなるため、実用はまだ 32bit が主流
04 HANDS-ON ③ OS標準型 — fm CLI(macOS 27) ネ ッ
ト 不 要 ターミナル = 注文の窓口 $ echo ログ | fm respond "要約して" ▼ 注文 ▲ 答えが返る OS領域 Apple が配布・全アプリ共有 あなたのPC Apple のモデルが GPU / Neural Engine で推 論 モデルも計算も、ここで完結 店の奥 = macOS(Apple Intelligence) ✕ 出番なし クラウド ターミナルから1行。パイプにそのまま挟める Apple のモデルが OS領域に最初から住んでいる 全アプリ共有・Apple が配布 $ echo ログ | fm respond "要約して" このために macOS 27 ベータを入れました。
04 HANDS-ON ③ の実装 — コード0行、シェル1行 EDGE LLM — LOCAL
INFERENCE $ git log --oneline -20 | fm respond -i "作業内容を日本語3行で要約して" ※ macOS 27 Beta が必要 同じタスク: ログを3行で要約
05 OS LAYER ④ OS持ち込み型 — 代表例: Ollama 初回DLのみ モデル(数
GB) 2回目からはロ ーカル完結 ターミナル / アプリ = 注文の窓口 ▼ 注文 ▲ 答えが返る ~/.ollama/models 自分で管理 あなたのPC 持ち込んだモデルが GPU で推論 目安〜30B級・メモリ64GBをフル活用 店の奥 = Ollama(自分でインストール) 役割はモデル配布 だけ 推論はゼロ クラウド 自分でインストールするアプリ。ブラウザの外 なので制限なし 好きなモデルを目安〜30B級まで持ち込める (量子化すれば 70B 級も可・速度とのトレード) Mac が向く理由: ユニファイドメモリ — 職人 (CPU)と工場(GPU)が同じ64GBを共有 構図は ② と同じ「持ち込み」 。場所がブラウザの外 になっただけ。
05 OS LAYER ④ の実装 — こちらもシェル1行 EDGE LLM —
LOCAL INFERENCE $ ollama run qwen3 "このエラーログを3行で要約して: $(cat error.log)" どれも実装は数行。違うのはモデルの居場所だけ。 同じタスク: ログを3行で要約
軽いデモやります。 EDGE LLM — LOCAL INFERENCE
05 OS LAYER 4つの選択肢 — 2×2で整理する EDGE LLM — LOCAL
INFERENCE 配布済み標準モデル BYOM(自分で持ち込む) ブラウザ層 ① Chrome Prompt API Gemini Nano・Chrome本体 ② Transformers.js ページの中・上限4GB OS層 ③ fm CLI Apple のモデル・OS領域 ④ Ollama 目安〜30B級・自分で管理
06 RECAP まとめ 方式 動く環境 モデルのDL 賢さ 向いている場面 ① Chrome
Prompt API Chrome 148+(138+はフラ グ要) 自動(Chrome・ 4GB) 小型・固定 Webに無料のAI機能を足す ② Transformers.js WebGPU対応ブラウ ザ 自分で(0.5GB〜) 小型・自由 モデルを選びたいWebアプリ ③ fm CLI macOS 27 のみ OSに同梱 小型※PCC切替可 Macの自動化・パイプ処理 ④ Ollama OS問わず・メモリ 次第 自分で(数GB〜) メモリ次第・目 安〜30B 本気のローカル運用 クラウドAPI ネットがあればどこ でも なし — 手元に来ない フロンティア級 賢さが要る仕事 Webに足すなら ①②、Macの自動化なら ③、本気なら ④。 データを外に出せない仕事はローカルで — 賢さが要るところだけ、クラウドへ。
07 APPENDIX もう少し広げてみる EDGE LLM — LOCAL INFERENCE レイヤー 配布済み標準モデル
BYOM(自分で持ち込む) ブラウザ ① Prompt API(Gemini Nano) ② Transformers.js デスクトップOS ③ fm(macOS) / Phi Silica(Windows) ④ Ollama / Foundry Local(Windows) モバイルOS AICore + ML Kit(Android) / Foundation Models (iOS) MediaPipe LLM / MLC アプリ同梱 —(胴元がいない) llama.cpp / MLX をバイナリに埋め込み 専用筐体 / LAN — DGX Spark / Jetson / Mac Studio に ollama serve
ご清聴 ありがとうございました。 EDGE LLM — LOCAL INFERENCE
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}