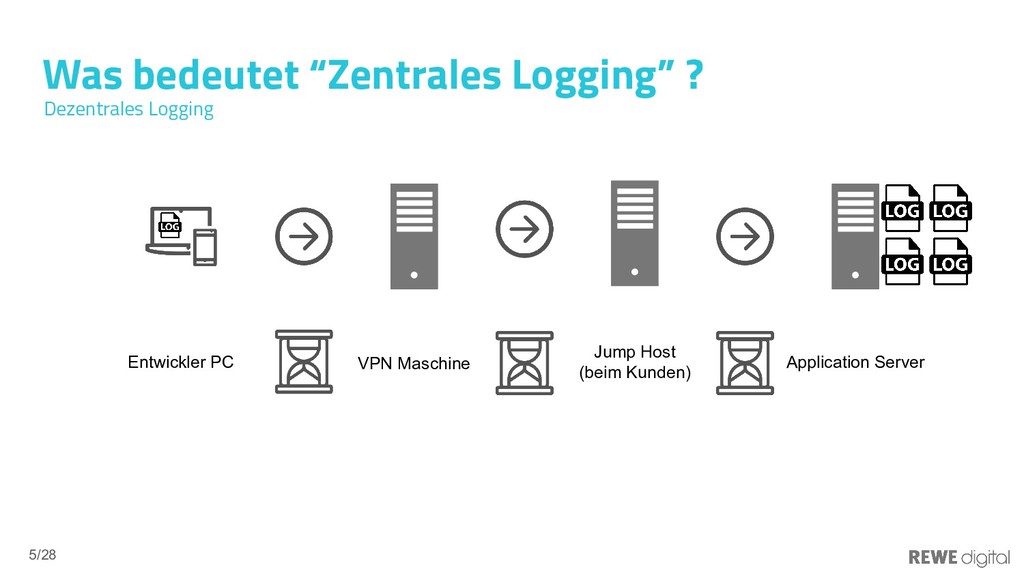
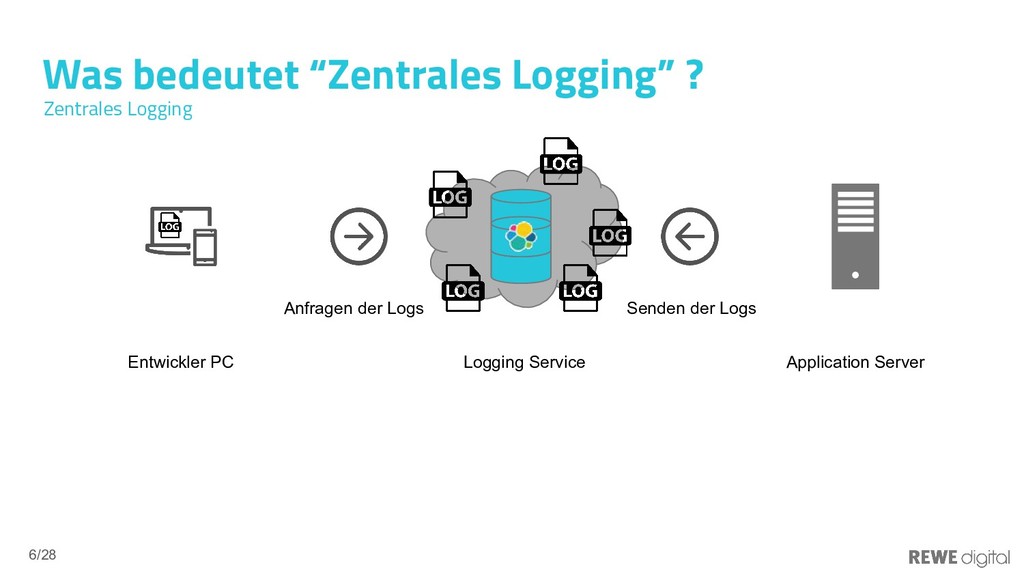
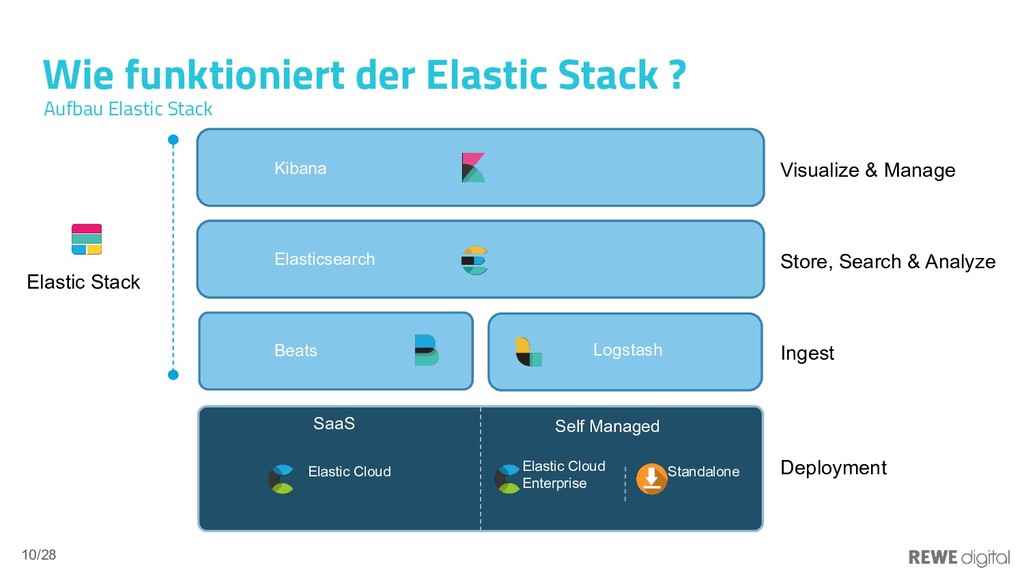
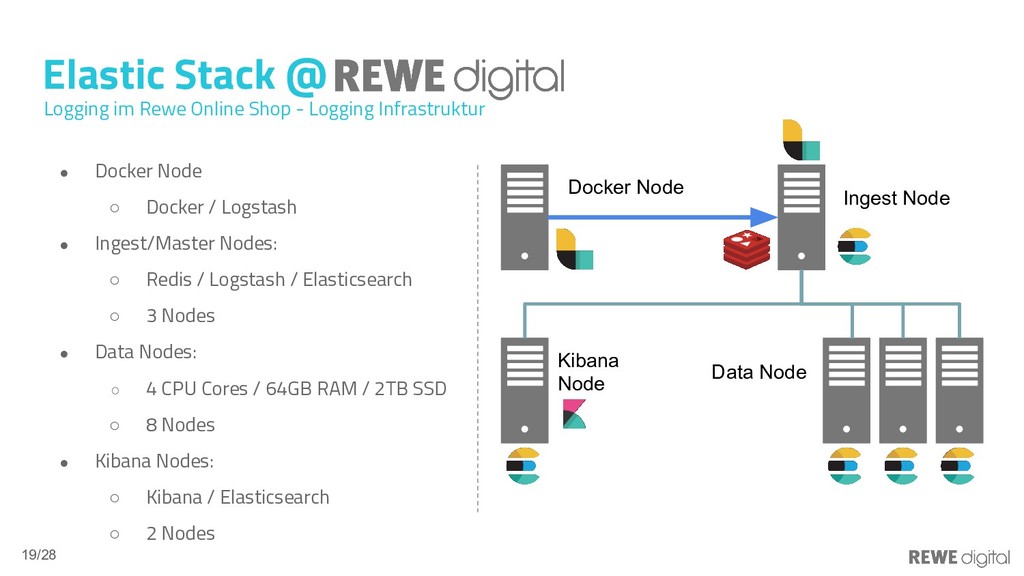
In der Welt der Microservices ist die Anzahl der Logs-produzierenden Prozesse sehr groß und liegt durchaus im Bereich von 100-1000 Prozessen. Eine manuelle Log-Verarbeitung ist hier so gut wie undenkbar. Doch auch monolithische Services laufen oftmals dezentral und das Analysieren der Produktions-Logs ist dann häufig auch mit viel Aufwand verbunden. Mithilfe eines zentralen Loggins lässt sich eine viel bessere Übersicht über den Gesamtzustand eines Systems gewinnen, da nicht jedes Log einzeln untersucht werden muss, sondern die Logs aggregiert und somit auch leicht automatisiert ausgewertet werden können. Elasticsearch bietet die Möglichkeit, große Mengen an Logs zu speichern und zu durchsuchen. Das Ökosystem um Elasticsearch unterstützt Entwickler, DevOps usw. dabei, die Logs schnell und einfach aufzubereiten, damit diese gut analysierbar sind. In diesem Vortrag werden die Vor- und Nachteile des zentralen Loggins dargelegt und gezeigt, wie sich Elasticsearch (bzw. der ELK-Stack) in Umgebungen einbinden lässt.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}