Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLM Reasoning Ability and HLE
Search
Satorien
September 27, 2025
55
0
Share
LLM Reasoning Ability and HLE
2025/9/27
GDGs Innovative Crosstalk 2025 DevFest UTokyo
にて15分の枠で登壇した際の発表資料
Satorien
September 27, 2025
Featured
See All Featured
Amusing Abliteration
ianozsvald
1
170
Claude Code のすすめ
schroneko
67
220k
The Invisible Side of Design
smashingmag
302
52k
Raft: Consensus for Rubyists
vanstee
141
7.4k
Facilitating Awesome Meetings
lara
57
6.9k
Practical Orchestrator
shlominoach
191
11k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2k
Become a Pro
speakerdeck
PRO
31
5.9k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
65
54k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
920
Embracing the Ebb and Flow
colly
88
5k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
120
Transcript
LLMの推論能力と人類最後の試験 東京大学大学院 佐藤諒平 2025/9/27 GDGs Innovative Crosstalk 2025 DevFest UTokyo
自己紹介:佐藤諒平 • 東京大学大学院 情報理工学系研究科 修士1年 • 人間の脳の複雑さやAIとの関係などに興味 • 研究 ◦ 脳の記憶モデルによるシミュレーション •
趣味 ◦ オリエンテーリング ▪ コンパスと地図だけ持って森を走る ▪ 実は東大は強豪校
LLMにおける推論(Reasoning)とは? “Reasoning models ... are LLMs trained with reinforcement learning
... Reasoning models think before they answer… Reasoning models excel in complex problem solving, coding, scientific reasoning, and multi-step planning for agentic workflows.” - OpenAI (引用元:https://platform.openai.com/docs/guides/reasoning) 要するに推論モデルは • 強化学習で実現 • 回答前に内部で考えを繰り返す • コードや計画立案などに対応
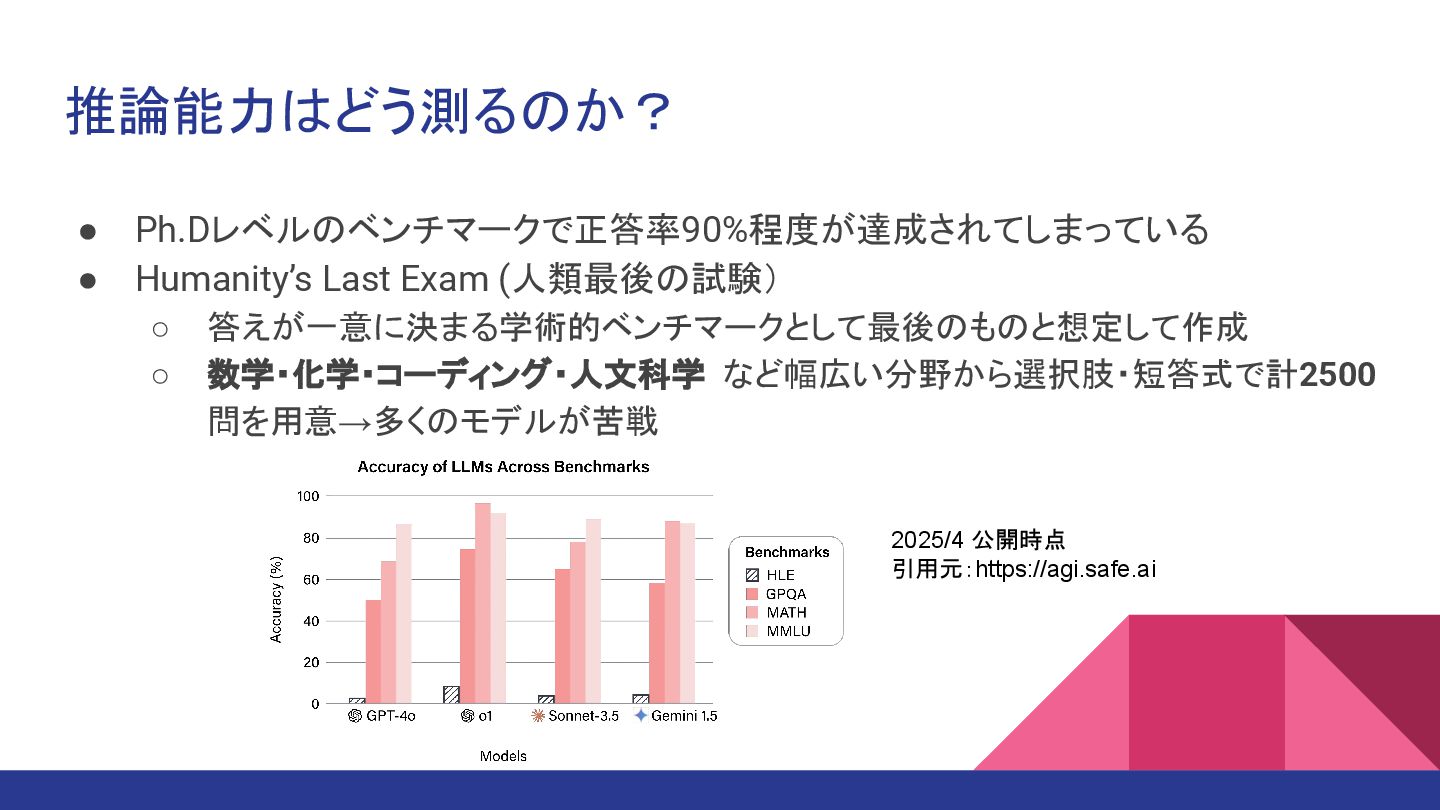
推論能力はどう測るのか? • Ph.Dレベルのベンチマークで正答率90%程度が達成されてしまっている • Humanity’s Last Exam (人類最後の試験) ◦ 答えが一意に決まる学術的ベンチマークとして最後のものと想定して作成
◦ 数学・化学・コーディング・人文科学 など幅広い分野から選択肢・短答式で計2500 問を用意→多くのモデルが苦戦 2025/4 公開時点 引用元:https://agi.safe.ai
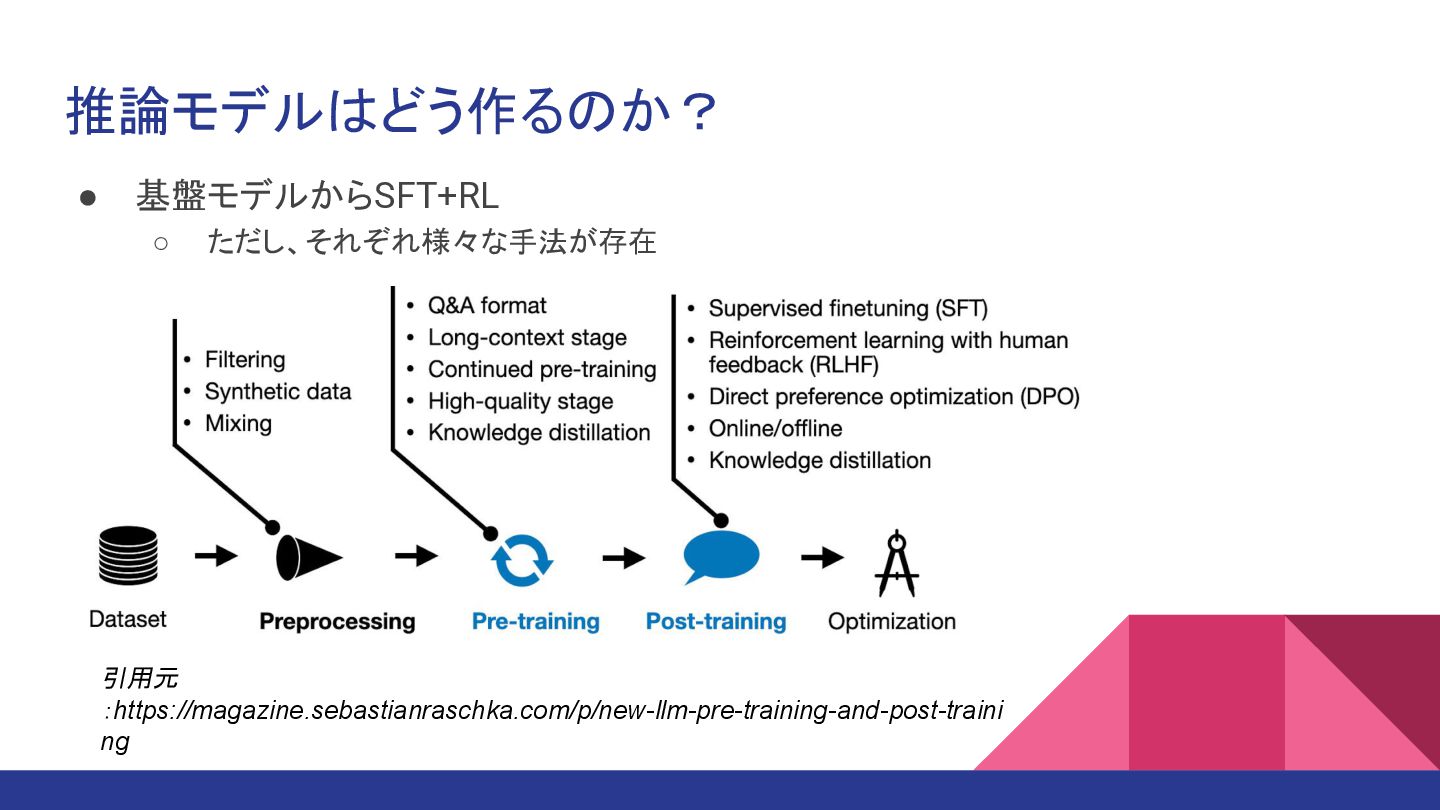
推論モデルはどう作るのか? • 基盤モデルからSFT+RL ◦ ただし、それぞれ様々な手法が存在 引用元 :https://magazine.sebastianraschka.com/p/new-llm-pre-training-and-post-traini ng
推論能力はどのようにして拡張されるのか? • 昨年、世間を賑わしたDeepSeek-R1の場合 ◦ 基盤モデルDeepSeek-V3 + SFT(CoT) + GRPO ▪
CoT(Chain of Thought)を活用するように鍛える→よく考えて答えを導く ▪ GRPO • 従来の強化学習手法よりも効率的に報酬を与える ◦ 従来(PPO):モデルの出力を報酬モデルが良い回答を選択 ◦ 新規(GRPO):モデルの出力の中で相対的に良いものを選択 ▪ モデルの既存知識を最大限活かす
最近の推論モデルはどこまで戦えているのか? • 全モデル(マルチモーダル含む) ◦ gpt-5-2025-08-07 ▪ 現行最高モデルでも 25% ▪ コード実行・検索ありなら44%
▪ Grok 4も同等の精度 ◦ gemini-2.5-pro-preview-06-05 • オープンソースモデル(Textのみ) ◦ gpt-oss-120b ◦ Qwen3-235B-A22B-Thinking-2507 ◦ DeepSeek-R1-0528 引用元 :https://scale.com/leaderboard/humanitys_la st_exam
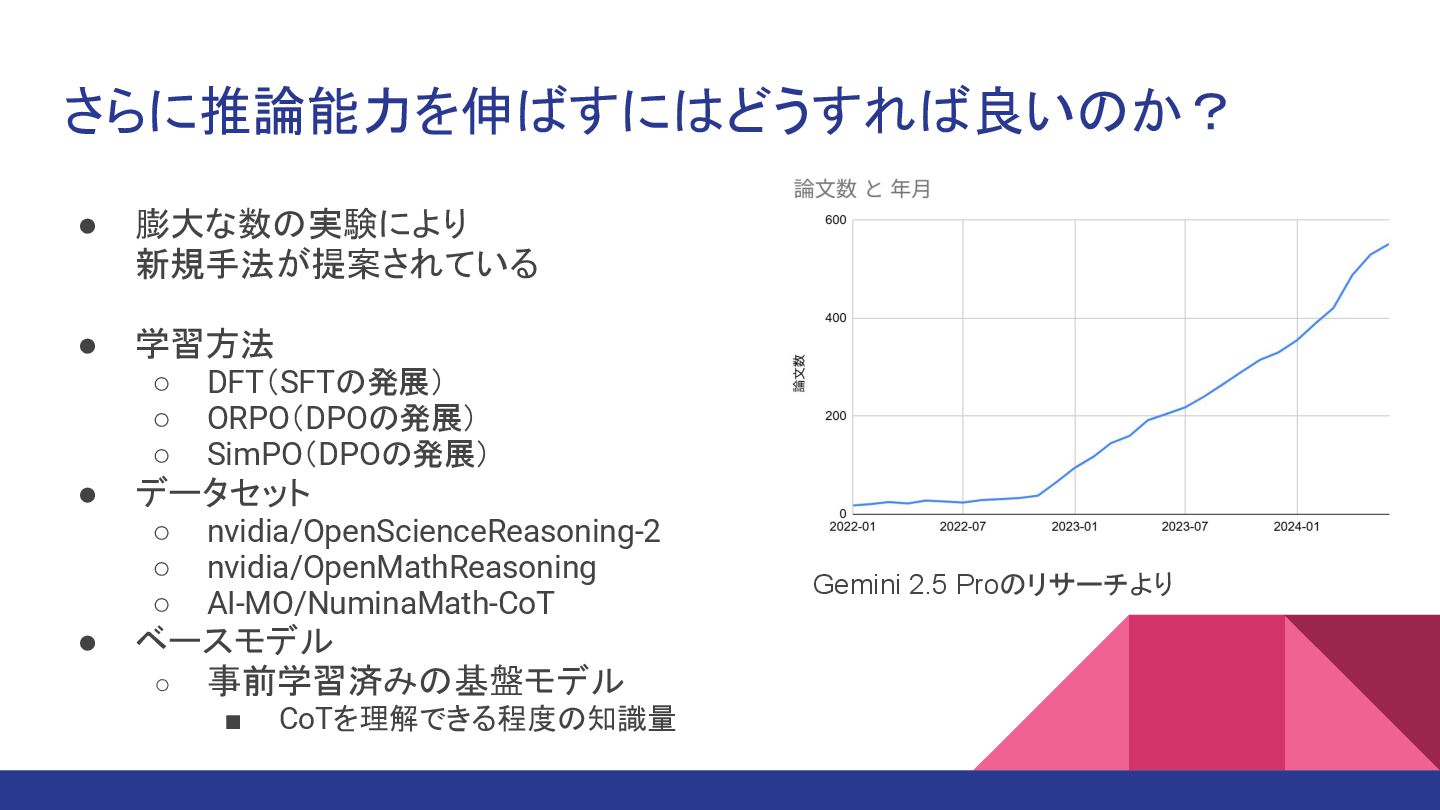
さらに推論能力を伸ばすにはどうすれば良いのか? • 膨大な数の実験により 新規手法が提案されている • 学習方法 ◦ DFT(SFTの発展) ◦ ORPO(DPOの発展)
◦ SimPO(DPOの発展) • データセット ◦ nvidia/OpenScienceReasoning-2 ◦ nvidia/OpenMathReasoning ◦ AI-MO/NuminaMath-CoT • ベースモデル ◦ 事前学習済みの基盤モデル ▪ CoTを理解できる程度の知識量 Gemini 2.5 Proのリサーチより
実際にやってみました • 東京大学松尾・岩澤研究室がNEDOのプロジェクトの一環で行う 「松尾研LLM開発プロジェクト(コンペティション)」に参加 ◦ 予選 13チーム 6週間 3ノード × H100(80GB) × 8
◦ 決勝 3チーム 3週間 8ノード × H100(80GB) × 8 ▪ 昨日モデル提出締め切り → 今回の発表内容含む多くの学びがあったので共有します ※本プロジェクトは、国⽴研究開発法⼈新エネルギー‧産業技術総合開発 機構(以下「NEDO」)の「⽇本語版医療特化型LLMの社会実装に向けた安 全性検証‧実証」における基盤モデルの開発プロジェクトの⼀環として⾏ われます。
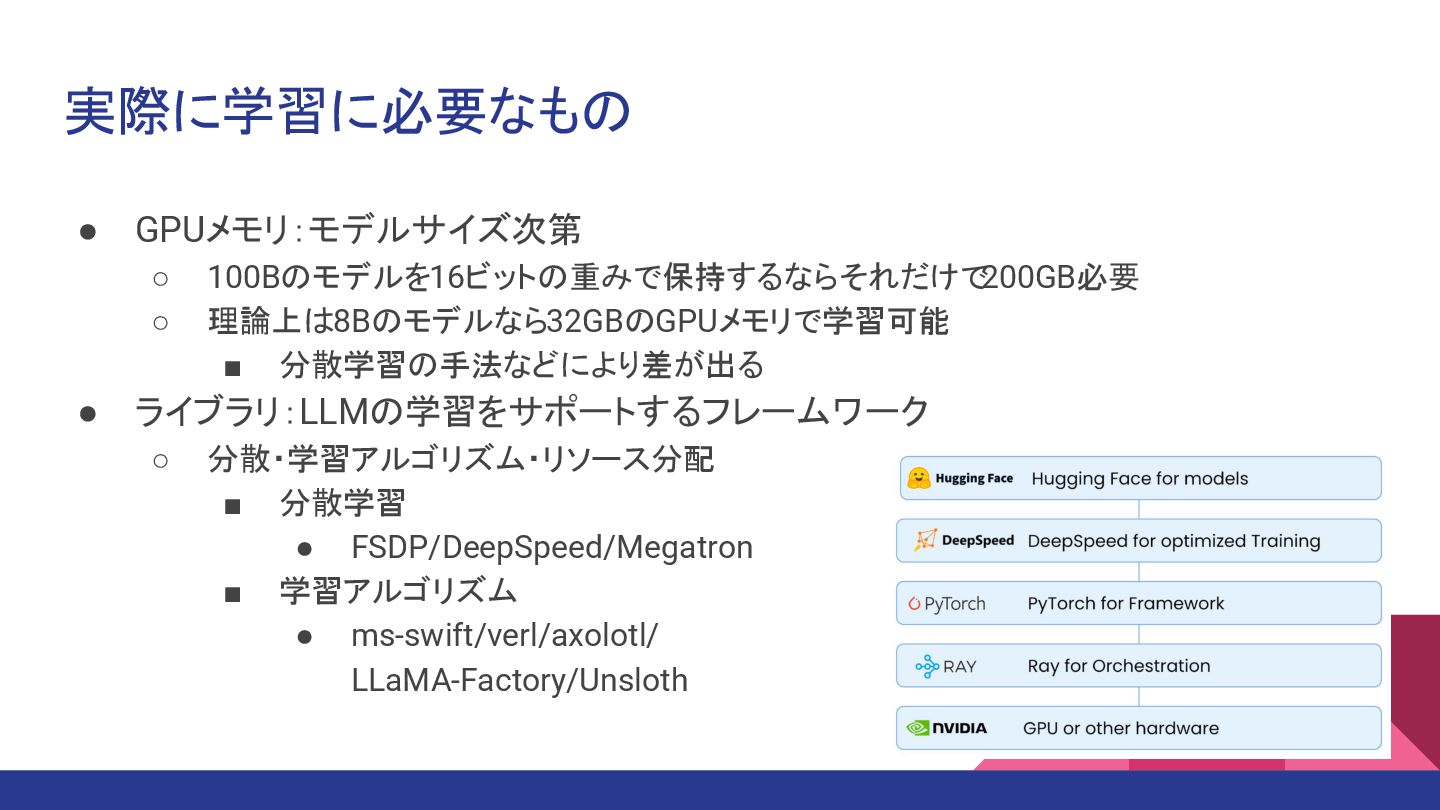
実際に学習に必要なもの • GPUメモリ:モデルサイズ次第 ◦ 100Bのモデルを16ビットの重みで保持するならそれだけで 200GB必要 ◦ 理論上は8Bのモデルなら32GBのGPUメモリで学習可能 ▪ 分散学習の手法などにより差が出る
• ライブラリ:LLMの学習をサポートするフレームワーク ◦ 分散・学習アルゴリズム・リソース分配 ▪ 分散学習 • FSDP/DeepSpeed/Megatron ▪ 学習アルゴリズム • ms-swift/verl/axolotl/ LLaMA-Factory/Unsloth
結果 内部評価としては辛差でオープンソースの SOTAを達成 ベース:18.26% => 開発モデル: 19.11% • 多くの学習手法で性能が大きく向上することはなかった ◦
すでに高性能の推論モデルをベースラインに据えたため大きな調整が失敗 ▪ 繊細なハイパラ調整によって精度向上の道筋が開ける ▪ ただ、大規模モデルのため試行錯誤に時間を要する ◦ 精度が良かった手法 ▪ オリジナルCoTデータセットでSFT/DPO
今後の推論モデルはどうなるのか? • 日々とてつもない勢いで新たな手法が提案されている ◦ 精度向上+モデルのコンパクト化が進む • 人間が答えを出せる問題のその先 ◦ 現状は既存の知識から推論しているだけ ◦
Open-endedの問題に対して専門的な答えを出していくと評価が難しい ▪ LLM-as-a-Judge • ユーザ視点での変化 ◦ より大規模な推論が可能になる ▪ より長いコード ▪ より大きなデータを要する問題
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}