Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層強化学習を用いたテトリスBotの作成の試行
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
thirofoo
May 05, 2024
980
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
深層強化学習を用いたテトリスBotの作成の試行
thirofoo
May 05, 2024
More Decks by thirofoo
See All by thirofoo
Meta Heuristics のすゝめ
thirofoo
0
84
Featured
See All Featured
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
430
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
680
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.7k
The Curious Case for Waylosing
cassininazir
1
440
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
440
GitHub's CSS Performance
jonrohan
1033
470k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.2k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
New Earth Scene 8
popppiees
3
2.4k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Transcript
深層強化学習を用いた テトリスBotの作成の試行 チームメンバー: monica_sor4chi through__TH 2kakerusei
概要 +深層強化学習に基づくモデルを作成し、テトリスをプレイす るエージェントを作成しました。 +開発の過程で得た知見に基づいて環境の修正やネットワーク 構成などを工夫し調査しました。
方針 +テトリスのゲーム環境を作成(Gym(nasium)互換) +学習エージェント作成 +強化学習ベースで実装 +報酬の条件、ハイパーパラメータを変えながら学習を回す +基本的にスコアを多く取得できるように(長生きするように)学習 させる
1. ゲーム環境 +Gym(nasium)にはテトリスの環境があるが、環境を変える際 に拡張できる情報に制約がある +https://gymnasium.farama.org/environments/atari/tetris +独自のCustomGymとしてテトリスを実装した +近代的なテトリスゲームとの相違点 +横入れなし +スピン系の技なし +両端の反発もなし
+全てハードドロップでミノを配置する (=学習を高速化させるため)
1.1 テトリス実装 + 右の動画のように可視化される + 標準出力を使ったCLI環境で動く実装 + ゲームスコア内訳 + ミノを配置できれば1点
+ 1ライン消すと100点 + 2ライン消すと300点 + 3ライン消すと500点 + 4ライン消すと800点 + ゲームオーバーは-1点 + src/tetris_gym内に実装されている
1.2 テトリス環境 +ゲームボードの状態や、ホールド以外に独自で状態を定義 +src/tetris_gym/tetris/tetris.pyのLine:133-155に記述 +実験によって取ってくる情報を変えている +特徴量エンジニアリングを行い、単純な2次元配列の情報よ りも説明的な変数を観測できるように工夫した
2. 学習エージェントについて
2.1 実装環境について +主に使用したライブラリ +Pytorch (NN構築、GPU環境の適応) +Gymnasium (OpenAI Gymの後継,強化学習用のエミュレート環境) +Numpy (ゲーム実装)
+プロジェクト管理・実行環境 +Rye +Ruff
2.2 内部実装について +以下の実装基本的に、src/tetris_project/ai/NN.pyに記述されている +20ゲーム(episodes)づつ学習の結果を表示・モデルを保存する +保存されたモデルを使って、シミュレーションも可能 +学習の途中でも可
2.3 学習手法 +ゲームオーバーするまでに得られるスコアを最大化するよう、 際限なく学習 +深層強化学習の更新方法を用いてTD学習を行い、盤面評価を 学習する。 +行動の決定はε-Greedy法 +実験によってパラメータ変更
2.3 学習手法 +Experience Replayを用いて、ミニバッチ学習を実施 +バッチ時のパラメータは実験によって変えている +後半の実験ではリプレイバッファの取り方を工夫している +実験・結果パートで説明
3 実験・結果
3.1.1 実験1 (初期モデル) 𝜖𝑠𝑡𝑎𝑟𝑡 = 1.0, 𝑑𝑖𝑠𝑐𝑜𝑢𝑡 = 0.9 𝜖𝑚𝑖𝑛
= 0.00001, 𝜖𝑑𝑒𝑐𝑎𝑦 = 0.995, 𝑙𝑟 = 0.001 NN: ・入力: 行動後の状態 ・出力: 場面の評価値 ・Dense(128)→Dense(64) ・活性化関数: ReLU, 出力層はリニア ・全結合 ・loss関数:HuberLoss
3.1.2 結果/考察 + (学習時間: 8時間,平均: 20Line,Episode: 3000) + ラインを消すことには成功していて、学習が進 んでいることがわかるが、ところどころ穴を
作っていて、だんだん上に迫り上がってしまっ ている
3.2.1 実験2 (特徴量と隠れ層を増やす) 𝜖𝑠𝑡𝑎𝑟𝑡 = 1.0, 𝑑𝑖𝑠𝑐𝑜𝑢𝑡 = 1.00 𝜖𝑚𝑖𝑛
= 0.001, 𝜖𝑑𝑒𝑐𝑎𝑦 = 0.995, 𝑙𝑟 = 0.001 NN: ・loss関数: MSE ・中間層(64)→ 中間層(64)→ 中間層(32) ・活性化関数: ReLU, 出力層はリニア ・全結合
3.2.1 実験2 (特徴量と隠れ層を増やす) 特徴量 ( Dellacherie's Algorithm *[1] ) 1.
Hole_count 2. Latest_clear_mino_count 3. Row_transitions 4. Column_transitions 5. Bumpiness 6. Eroded_piece_cells 7. Cumulative_well 8. Aggregate_height 9. Abobe_block_suqared_sum
3.2.1 実験2 (特徴量と隠れ層を増やす) 特徴量 ( Dellacherie's Algorithm *[1] ) 1.
上部にブロックがある空マスの総和 2. 直近でラインを消したミノの設置時の高さ 3. 行方向の空マス→ブロック、ブロック→空マスの遷移の数の総和 4. 列方向の空マス→ブロック、ブロック→空マスの遷移の数の総和 5. 隣り合う列の高さの差の総和 6. 直近で消したライン * ライン消しに貢献したミノのブロック数 7. 左右がブロックの空マスが k 連続の時の k の二乗和 8. 各列の高さの総和 9. 各空マスの上部にあるブロックの数の二乗和
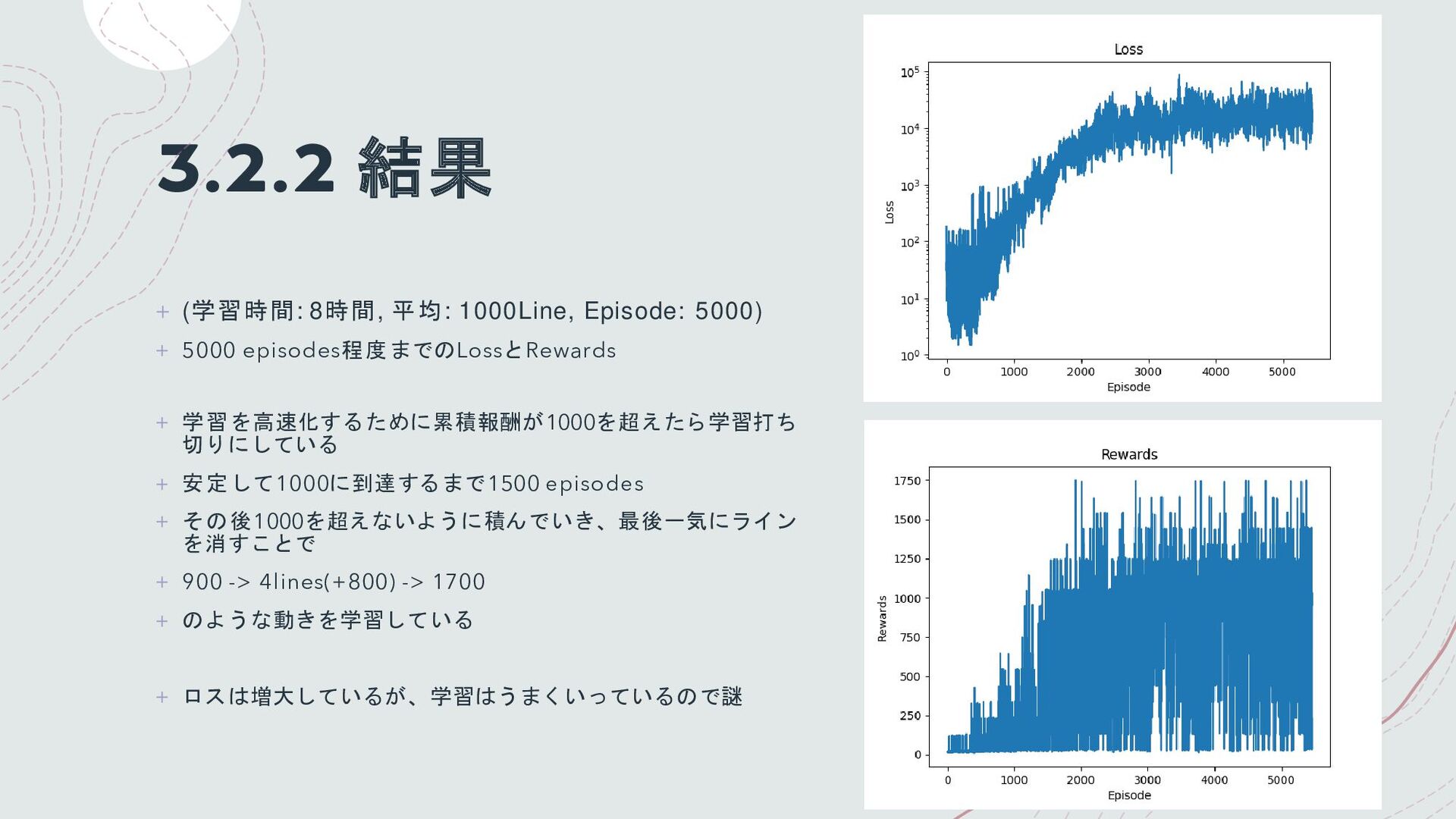
3.2.2 結果 + (学習時間: 8時間, 平均: 1000Line, Episode: 5000) +
5000 episodes程度までのLossとRewards + 学習を高速化するために累積報酬が1000を超えたら学習打ち 切りにしている + 安定して1000に到達するまで1500 episodes + その後1000を超えないように積んでいき、最後一気にライン を消すことで + 900 -> 4lines(+800) -> 1700 + のような動きを学習している + ロスは増大しているが、学習はうまくいっているので謎
3.2.3 結果/考察 + 生存時間が長くなって、消せるライン数も増 加したが、下段か上段のどちらかに偏って生 存するようになった。 + 特に下段で生存する右側の動画では、高く積 み上がった瞬間に操作精度が落ちてゲーム オーバーしまうことから、経験学習の偏りが
あるのではないかと考えられる。 + Experience Bufferを工夫してサンプルする ことで経験の偏りを緩和できないか。
3.3.1 実験3 (経験の偏りを緩和させる) + 実験2からパラメータ、NNの変更はなし + 追加で、Experience Bufferを設置したミノの位置が 盤面の上半分か下半分かで分け、均等に経験をサン プルするようにコードを修正
3.3.2 結果/考察 + 最初と比べると、下段~中段の穴の数が減り、うまく敷き 詰められているように見える + どちらか一方に寄って、片側に1-2マスほど残している + -> 得点が高いIミノやOミノなどを使った一気に2~4ライ
ンを消す操作を期待してこのような行動をしている + -> 人間にも見られるプレイ方法を模倣できている + 上段だけでラインを消去することがほぼなくなっている + 止めなければ、半永久的にプレイし続けられる
4 まとめ +深層強化学習の更新方法を用いてTD学習、人間の動きを模倣 した論理的な行動をするテトリスエージェントが作成できた +Experience Bufferに区分を持たせることで経験の偏りを軽減 し、より性能が向上した +盤面の次元を特徴量で表現することで削減し、学習を高速 化・安定化させることができた
5 展望 +現在、行動後の状態から盤面評価の最大値を取る行動をする ような間接的なDQNを実装している。そのため、状態から直 接Q値を求めるようなDQNモデルも作成して評価したい +Prioritized Experience Replayという今回使ったExperience Bufferを分割する手法の派生があるようなのでそちらを試し たい
+今回は学習の高速化と安定化を図るためわざとFEによって盤 面情報の次元数を減らしたが、CNNを用いた盤面を直接 inputするような方針でも学習させたい
参考文献 [1] Isiam, El-Tetris – An Improvement on Pierre Dellacherie’s
Algorithm, 2011 June 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3.2.1 実験2 (特徴量と隠れ層を増やす) 特徴量 ( Dellacherie's Algorithm *[1] ) 1.](https://files.speakerdeck.com/presentations/712caed0a4844905a2dd69741dda05a1/slide_15.jpg){kind=link}
![3.2.1 実験2 (特徴量と隠れ層を増やす) 特徴量 ( Dellacherie's Algorithm *[1] ) 1.](https://files.speakerdeck.com/presentations/712caed0a4844905a2dd69741dda05a1/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 [1] Isiam, El-Tetris – An Improvement on Pierre Dellacherie’s](https://files.speakerdeck.com/presentations/712caed0a4844905a2dd69741dda05a1/slide_23.jpg){kind=link}