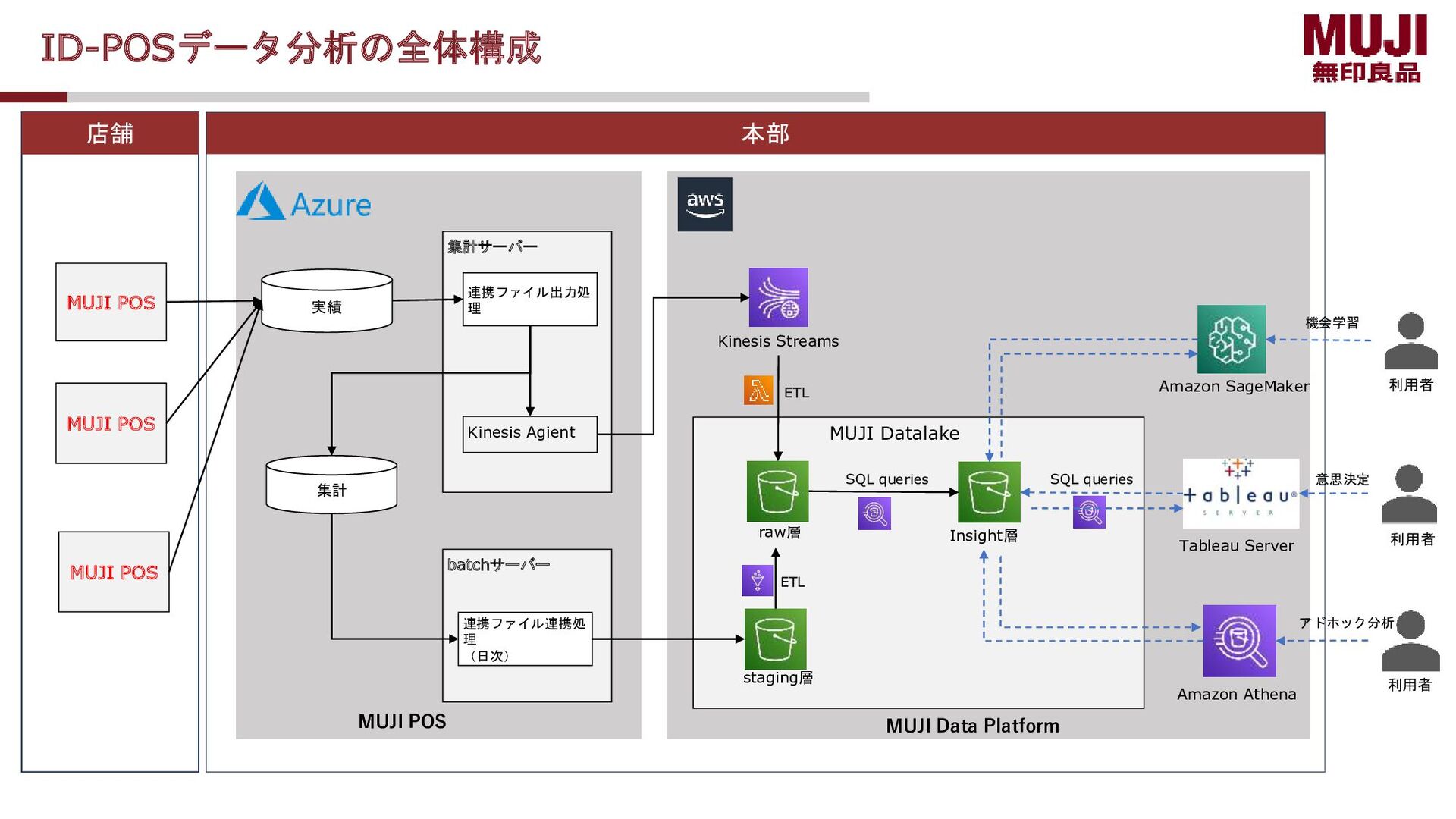
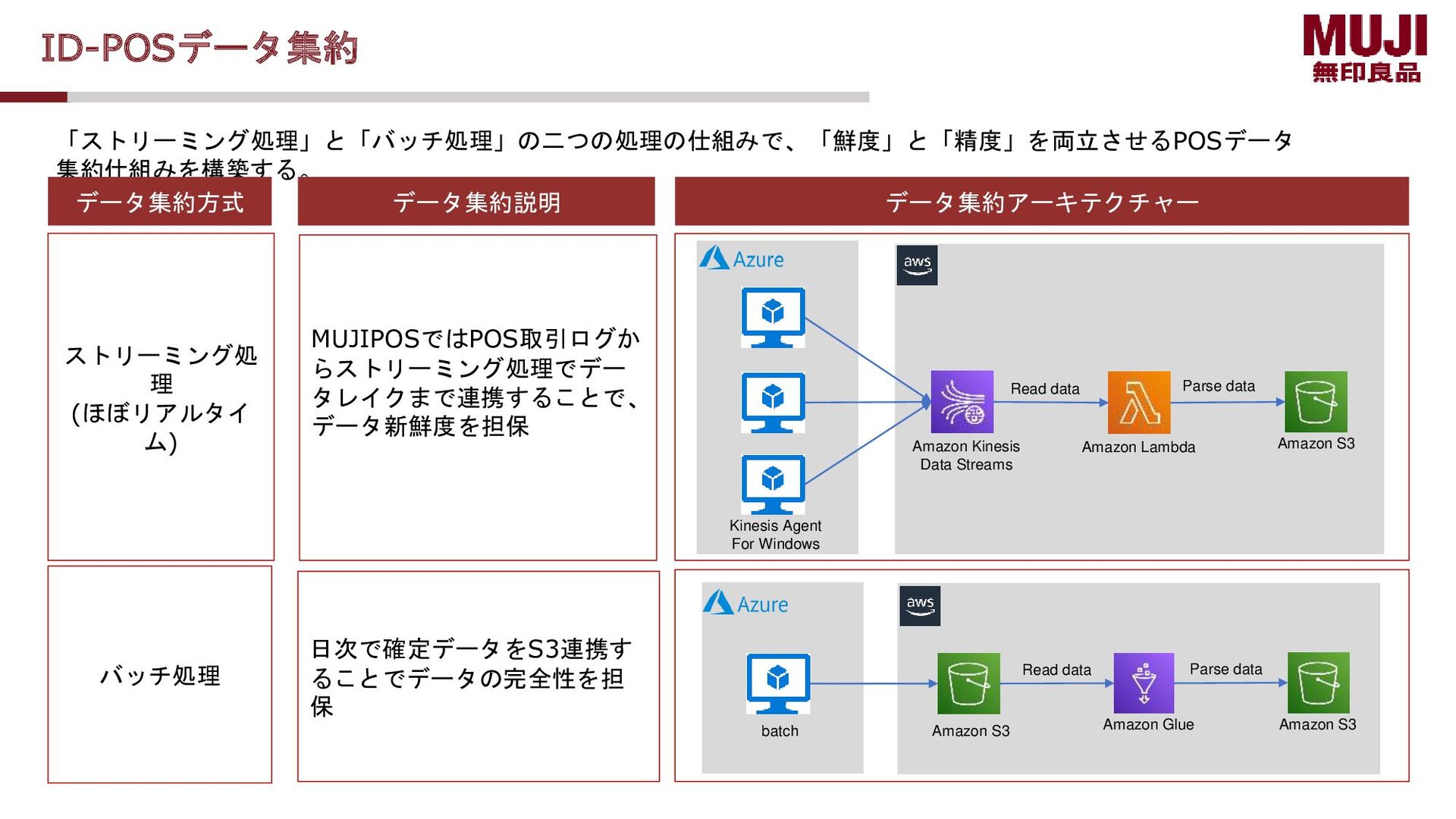
保 データ集約方式 データ集約説明 データ集約アーキテクチャー Amazon Lambda Amazon S3 Amazon Kinesis Data Streams Parse data Read data Kinesis Agent For Windows MUJIPOSではPOS取引ログか らストリーミング処理でデー タレイクまで連携することで、 データ新鮮度を担保 batch Amazon S3 Amazon S3 Amazon Glue Parse data Read data
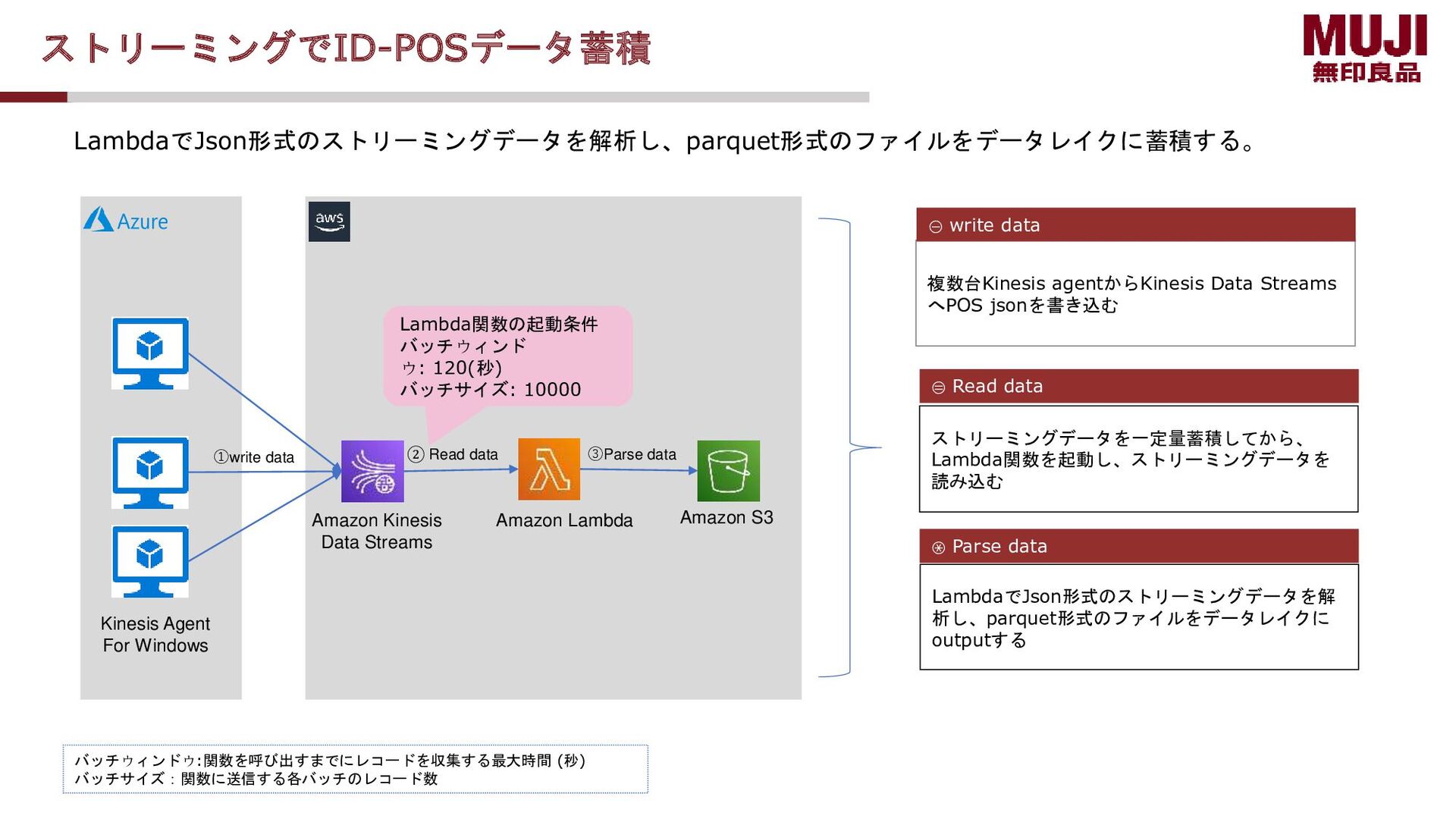
data ② Read data Kinesis Agent For Windows LambdaでJson形式のストリーミングデータを解析し、parquet形式のファイルをデータレイクに蓄積する。 ①write data 複数台Kinesis agentからKinesis Data Streams へPOS jsonを書き込む ① write data ② Read data LambdaでJson形式のストリーミングデータを解 析し、parquet形式のファイルをデータレイクに outputする ③ Parse data ストリーミングデータを一定量蓄積してから、 Lambda関数を起動し、ストリーミングデータを 読み込む Lambda関数の起動条件 バッチウィンド ウ: 120(秒) バッチサイズ: 10000 バッチウィンドウ:関数を呼び出すまでにレコードを収集する最大時間 (秒) バッチサイズ:関数に送信する各バッチのレコード数
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}