complex scenes, particularly in attributes and relations. • This study introduces a few number of structured scene graphs into VLMs, enhancing visual and textual comprehension. • The method improves VLM performance across multiple datasets, effectively addressing the initial scene understanding limitations. 2
compositional scene recognition • Especially recognizing attributes and relationships of objects, as well as the state of actions • Scene Graphs (SG) are effective for compositional recognition but have a high annotation cost • making them impractical to prepare on a large scale 4
recognition capabilities of pre-trained VLMs using a small amount of SGs • Method • They propose a fine-tuning method for pre-trained VLMs, named Scene Graphs for Vision-Language Models (SGVL), to leverage Scene Graphs for enhancing these models 5
This allows for effective training of the image-encoder in the task of predicting SG 10 image-encoder object relation projection object representation bounding box object name embedding relation representation bounding box relation name embedding
• This allows better learning of the graph prediction task • Although the Q,K,V and MLP are partitioned, the attention is performed over all tokens (patch and SG) 11
loss like CLIP 2. Matching object and relation loss following DETR (Carion et.al ECCV2020) • for allowing SG Tokens learn object/relations representation 12 Estimated probability of Teacher Label Loss Based on Bounding Box For image-text pairs, objective is just ℒ𝐶𝑜𝑛𝑡
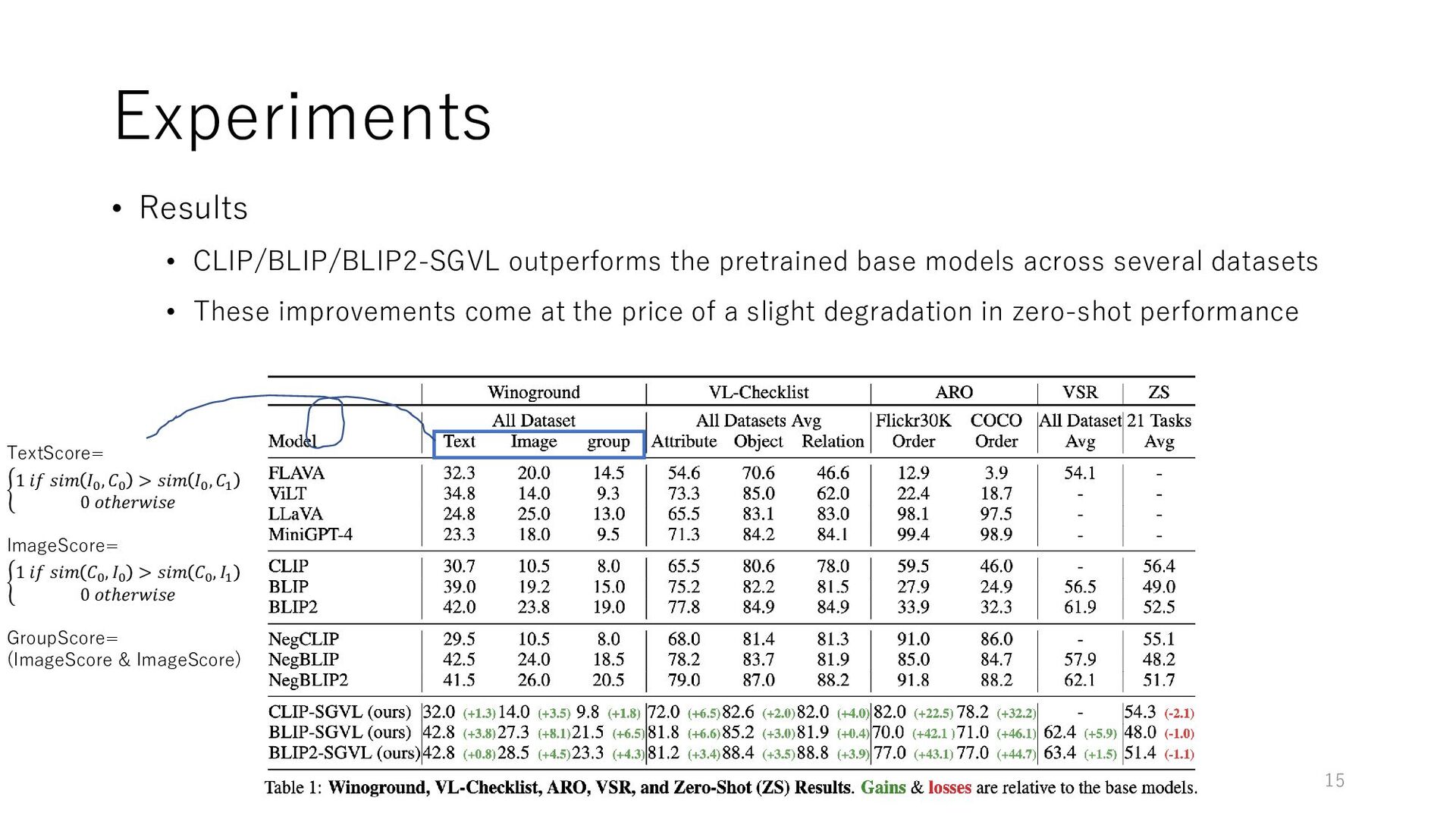
• pos-neg captions per 1 image (C pos, C neg, I) • Winoground (Thrush et.al CVPR2022) • 2 image-text pairs (C 0, I 0, C 1, I 1 ) swapping words • Attribution, Relation and Order (ARO) (Yuksekgonul et.al ICLR 2023) • Select the most suitable caption for an image from 5 captions, adjusting for changes in relationship, object, and attributes • Visual Spatial Reasoning (VSR) (Liu et.al TACL 2023) • estimate whether Image-text pair has spatial relationship each other • ZS (Various Zero-Shot Task) • 21 classification tasks from ELEVATER (Li et al., NeurIPS 2022) 14 Winoground sample VSR sample
Token are effective B) Adding Adaptive SG Token and partitioning image patch and SG token are effective C) SG Annotation needs to be dense for improving compositionality of VLM 17
complex scenes, particularly in attributes and relations. • This study introduces a few number of structured scene graphs into VLMs, enhancing visual and textual comprehension. • The method improves VLM performance across multiple datasets, effectively addressing the initial scene understanding limitations. 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}