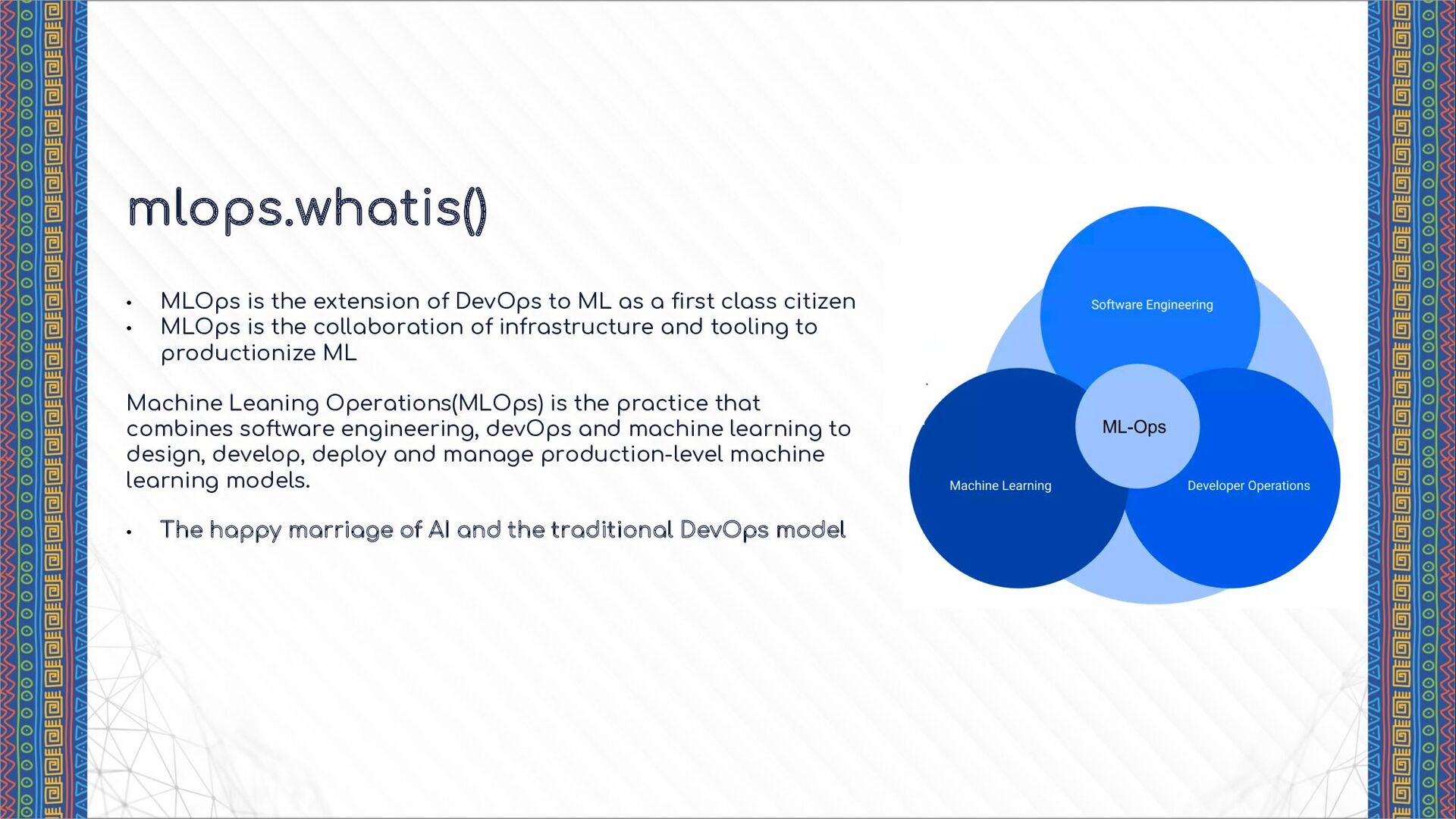
a first class citizen • MLOps is the collaboration of infrastructure and tooling to productionize ML Machine Leaning Operations(MLOps) is the practice that combines software engineering, devOps and machine learning to design, develop, deploy and manage production-level machine learning models. • The happy marriage of AI and the traditional DevOps model mlops.whatis()
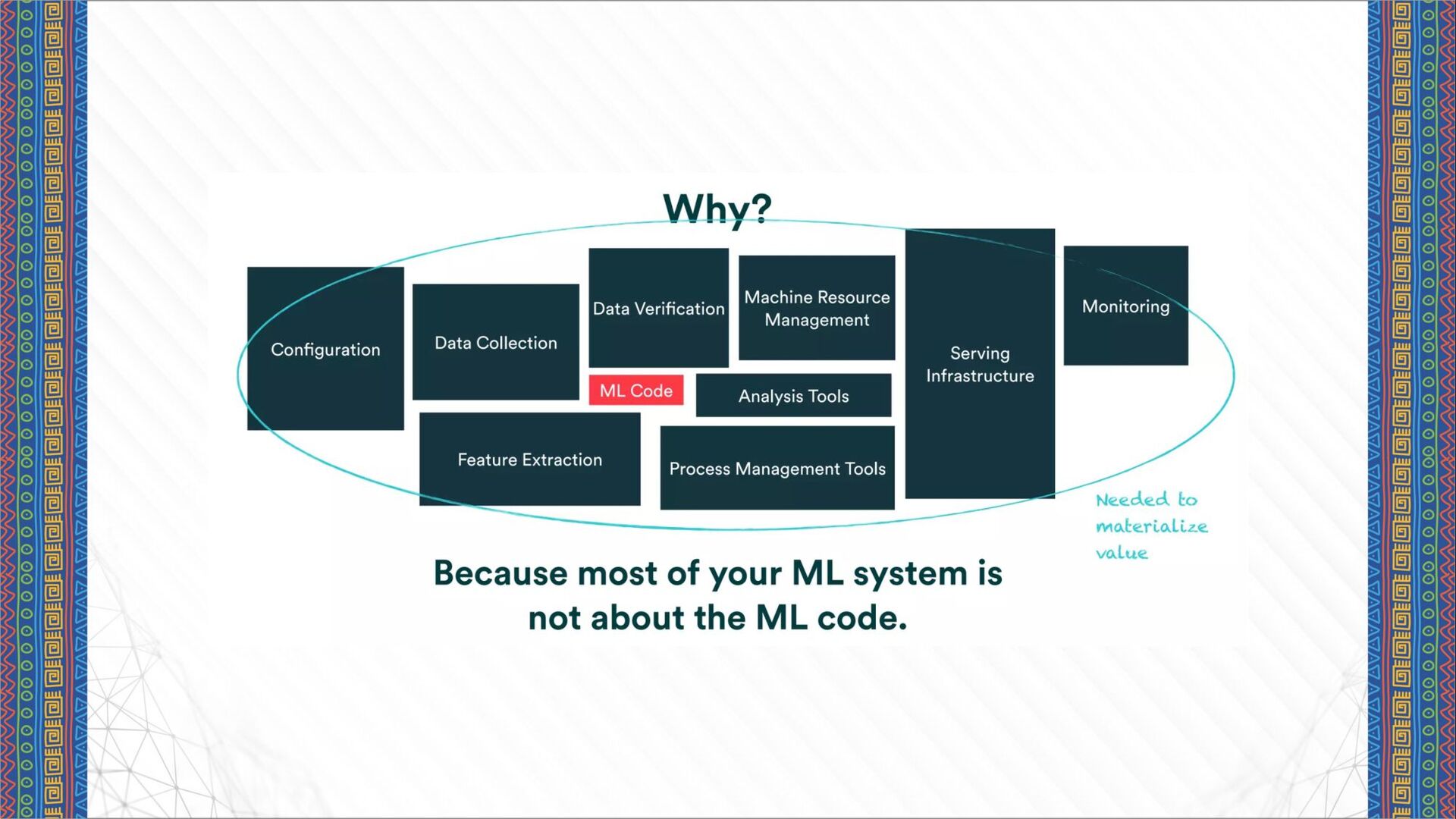
report little or no impact with the use of AI. 40% of organizations with significant investments in Al report no benefits. FACT Only 22% of companies using ML have successfully deployed an ML model into production. 87% of data science projects never make it into production. The main challenges people face when developing ML capabilities are scale, version control, model reproducibility, and aligning stakeholders. Reality is: • Al is a source of opportunities and advantages • Implementing Al is a risk • Implementing Al correctly is difficult
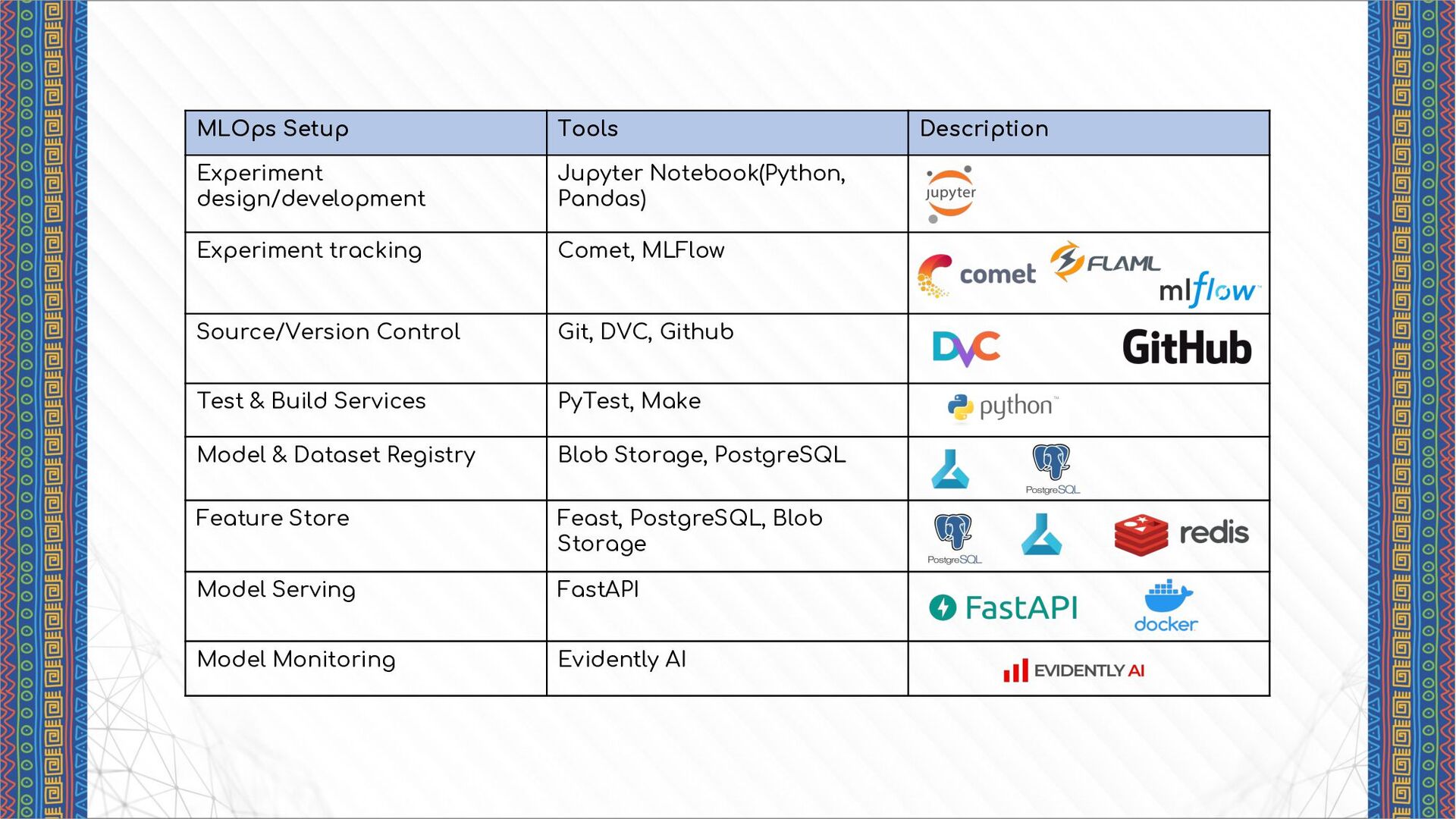
tracking Comet, MLFlow Source/Version Control Git, DVC, Github Test & Build Services PyTest, Make Model & Dataset Registry Blob Storage, PostgreSQL Feature Store Feast, PostgreSQL, Blob Storage Model Serving FastAPI Model Monitoring Evidently AI
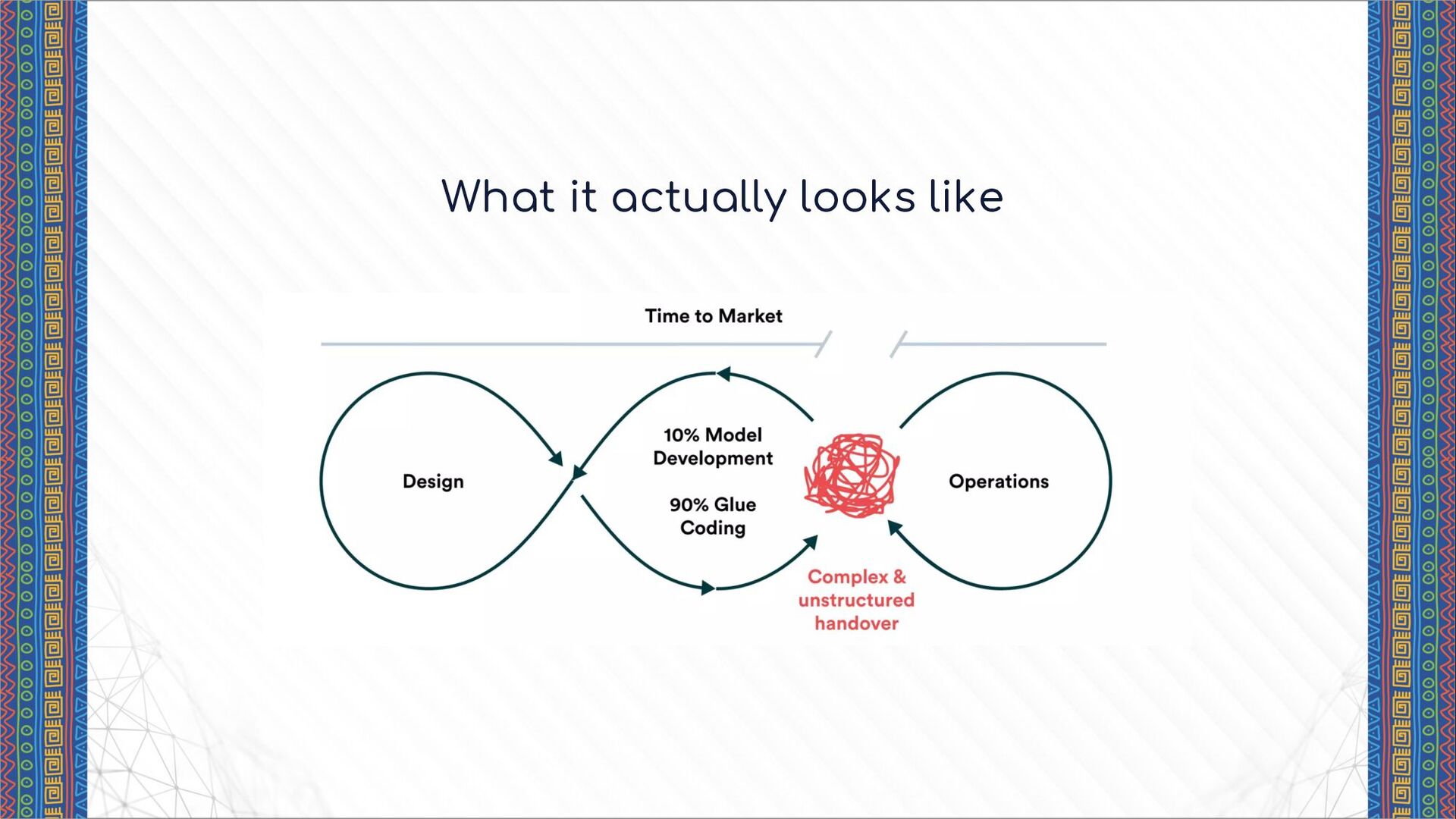
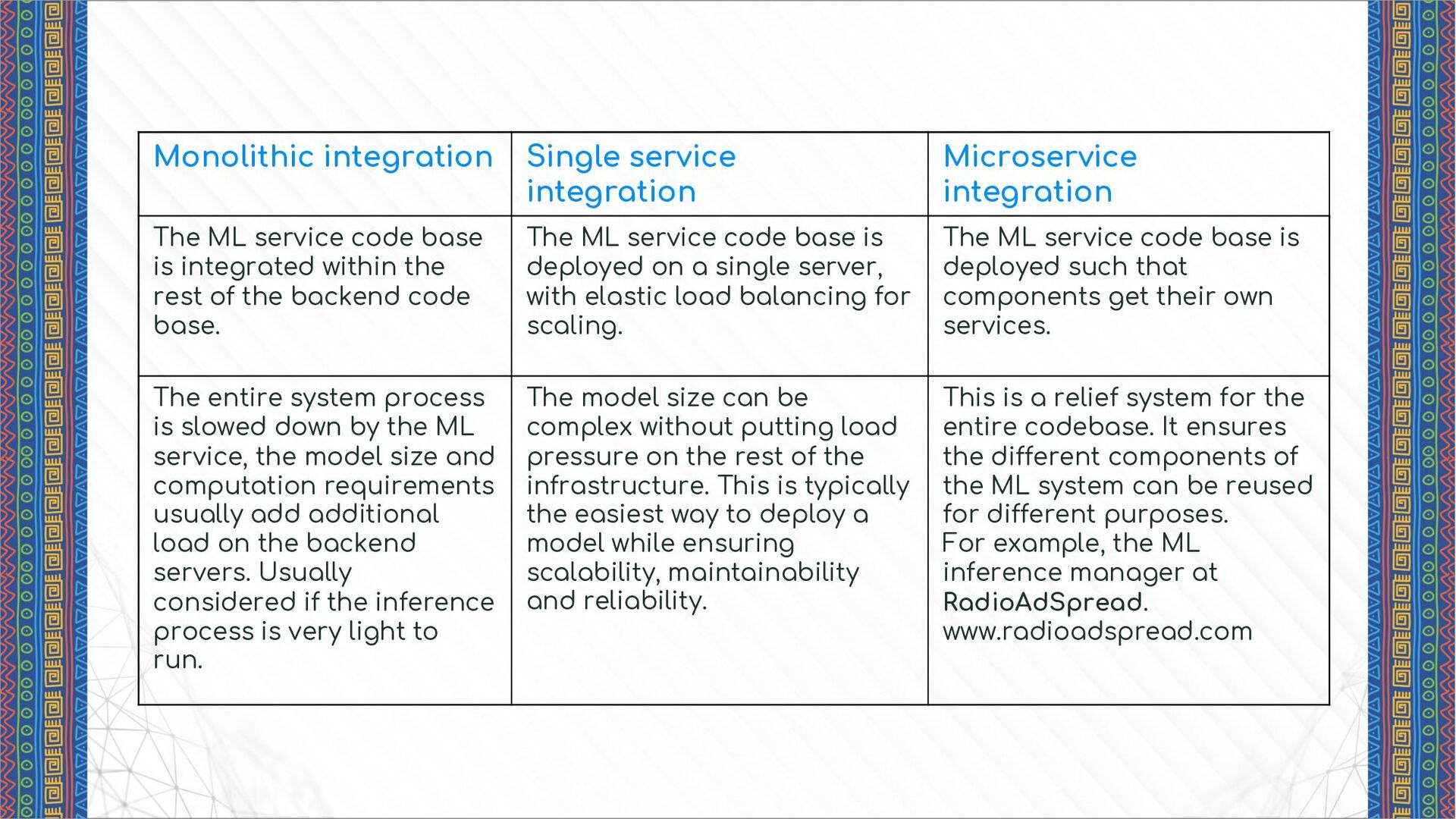
code base is integrated within the rest of the backend code base. The ML service code base is deployed on a single server, with elastic load balancing for scaling. The ML service code base is deployed such that components get their own services. The entire system process is slowed down by the ML service, the model size and computation requirements usually add additional load on the backend servers. Usually considered if the inference process is very light to run. The model size can be complex without putting load pressure on the rest of the infrastructure. This is typically the easiest way to deploy a model while ensuring scalability, maintainability and reliability. This is a relief system for the entire codebase. It ensures the different components of the ML system can be reused for different purposes. For example, the ML inference manager at RadioAdSpread. www.radioadspread.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}