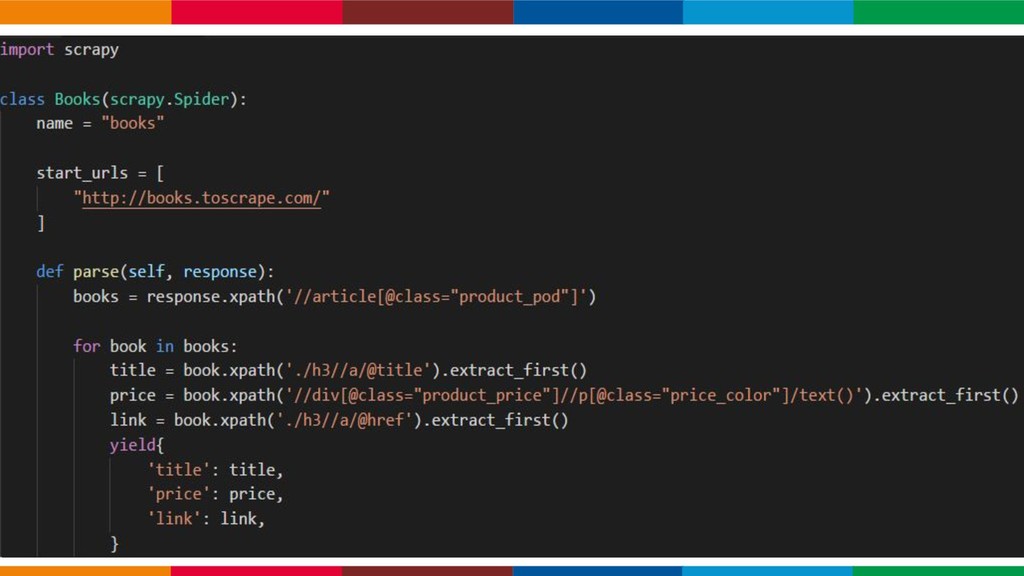
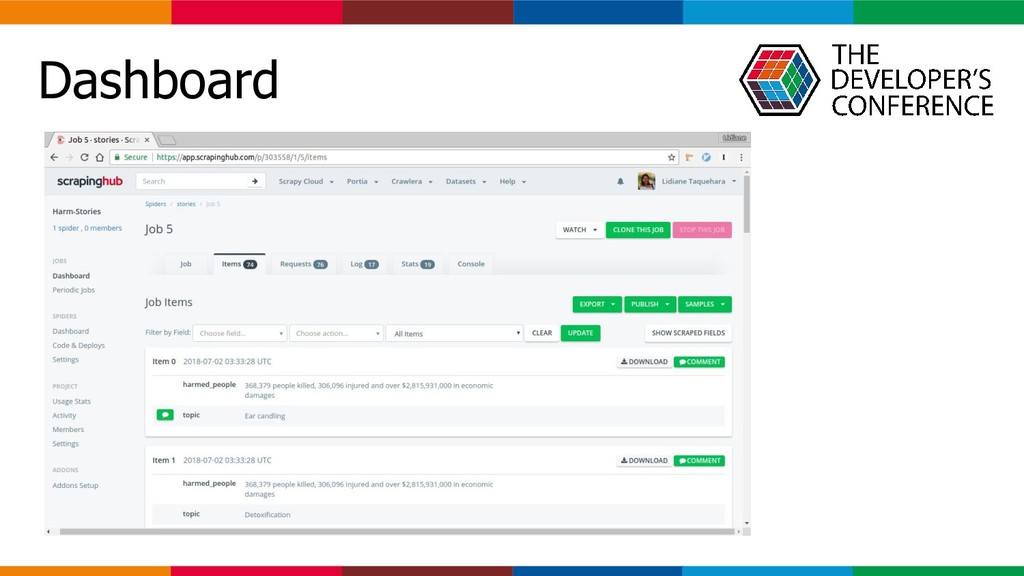
Scrapy é um framework escrito em Python voltado para web crawling e web scraping. Esta ferramenta facilita a construção de spiders capazes de automatizar a indexação de páginas da web e realizar a extração de conteúdo através da raspagem de dados. Scrapy Cloud é uma plataforma criada e mantida pela Scrapinghub voltada para a execução de web crawlers em nuvem. Ao subir o projeto para o scrapy cloud, é possível agendar, acompanhar e gerenciar a execução das spiders. No Love Mondays, utilizamos estas tecnologias para reunir vagas de emprego de diversas fontes. Então, ao buscar uma vaga, nosso usuário tem acesso a um volumoso banco de informações sem a necessidade de visitar diferentes sites.
Links úteis:
Exemplo Trilhas TDC: https://github.com/anacls/scrapy-study/blob/master/tdc_examples/scrapy_study/spiders/trilhas_tdc.py
ScrapingHub API Demo: https://github.com/lidimayra/scrapinghub-api-demo
Todos os exemplos utilizados na palestra: https://github.com/anacls/scrapy-study/tree/master/tdc_examples
Para saber mais (Scrapy):
Site oficial - https://scrapy.org
Github - https://github.com/scrapy/scrapy
Documentação - https://doc.scrapy.org/en/latest/intro/tutorial.html
Para saber mais (ScrapingHub):
Site oficial - https://scrapinghub.com/
Github - https://github.com/scrapinghub/
Blog - https://blog.scrapinghub.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}