Share
Essa talk aborda alguns conceitos sobre Web Scraping e traz alguns exemplos de como podemos utilizar essa técnica com Python.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
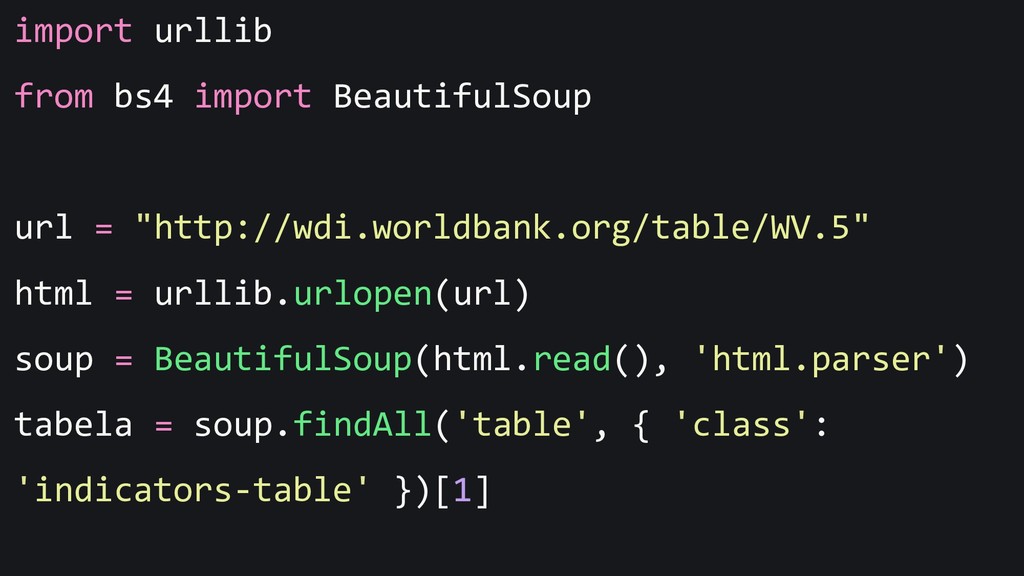{kind=link}
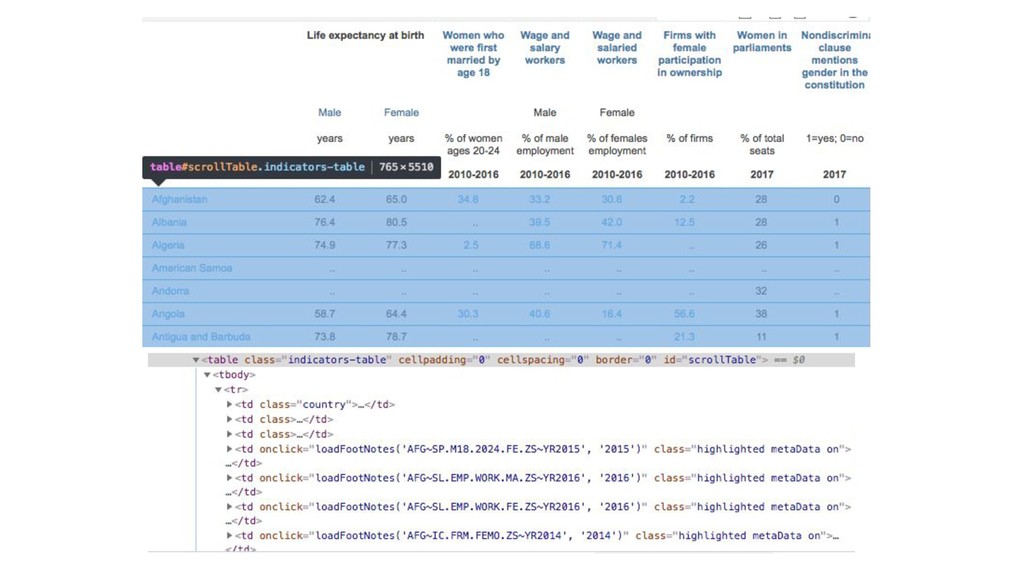{kind=link}
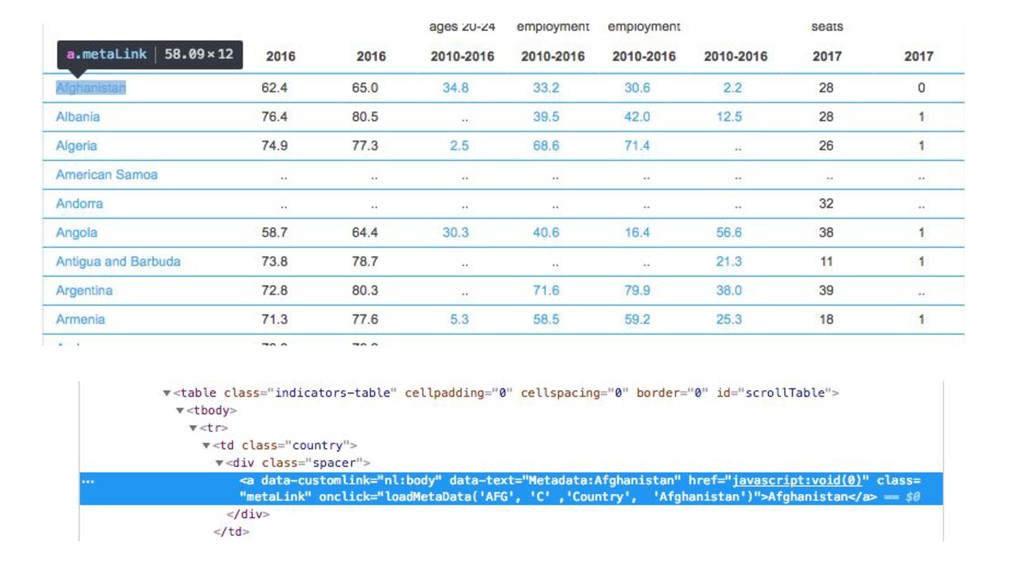{kind=link}
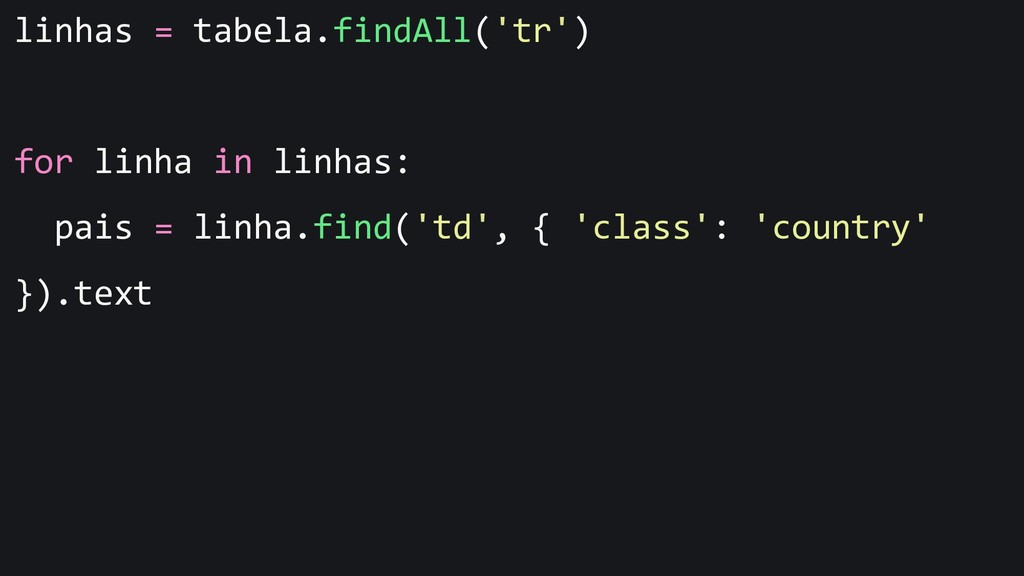{kind=link}
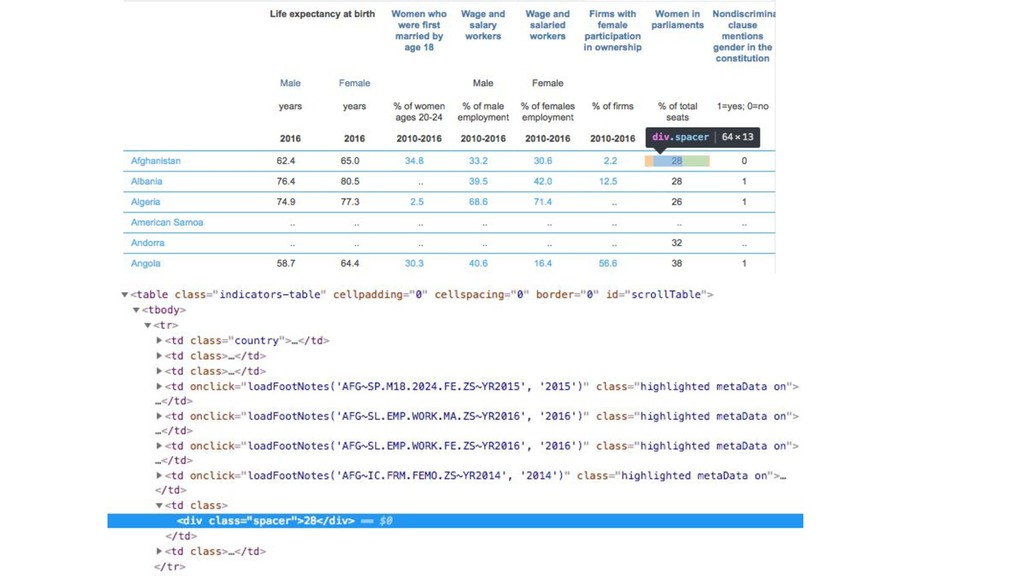{kind=link}
{kind=link}
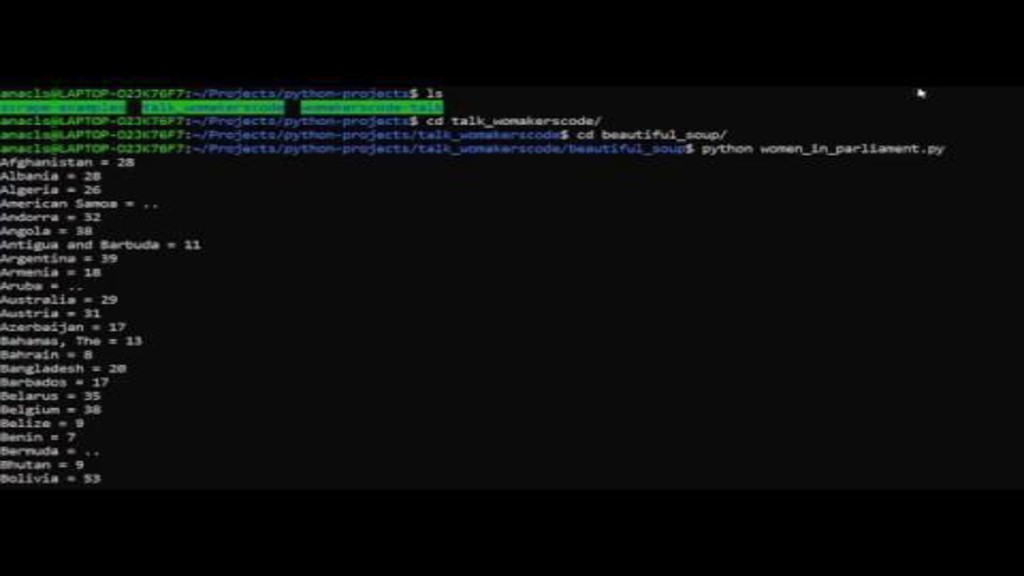{kind=link}
{kind=link}
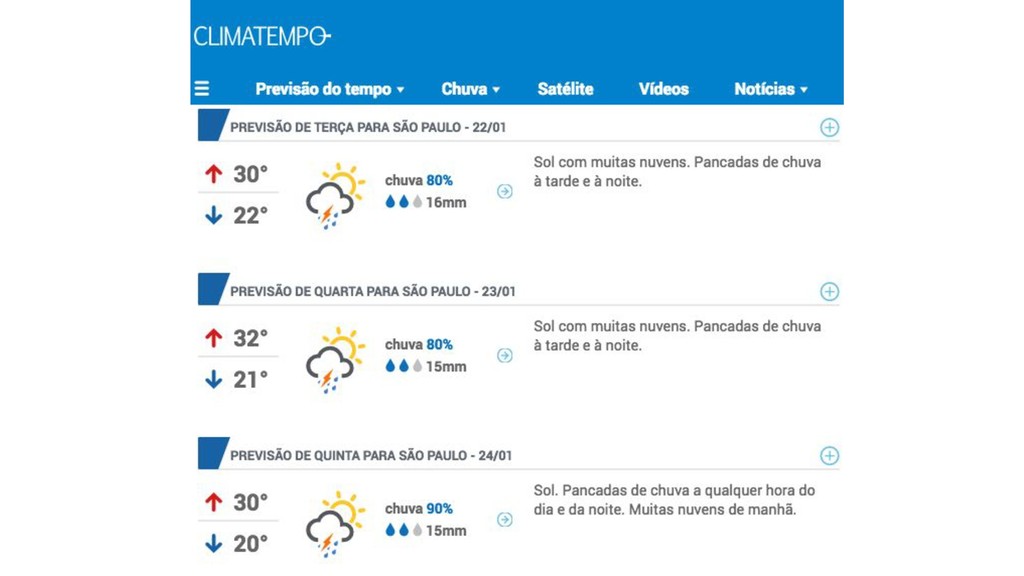{kind=link}
{kind=link}
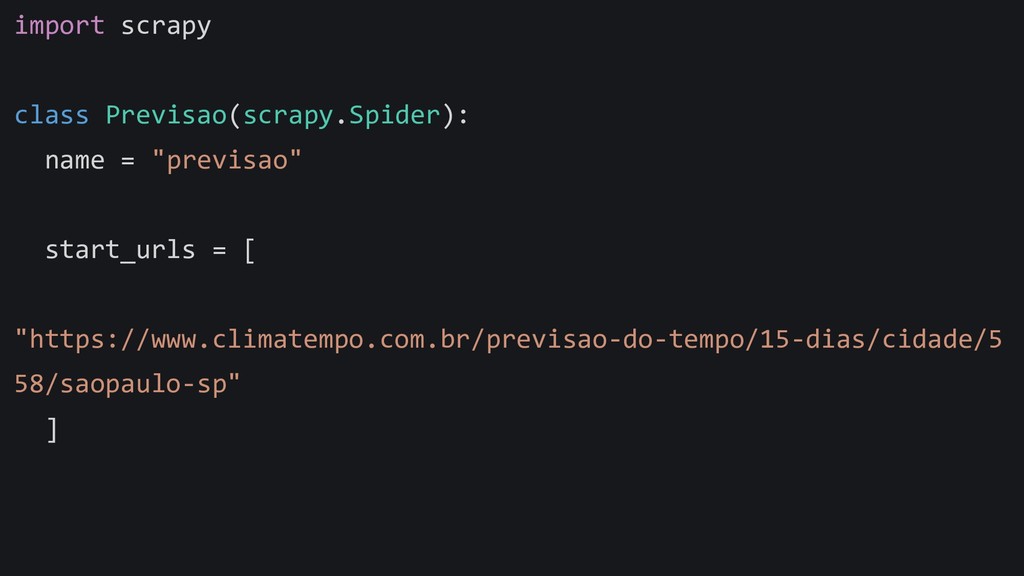{kind=link}
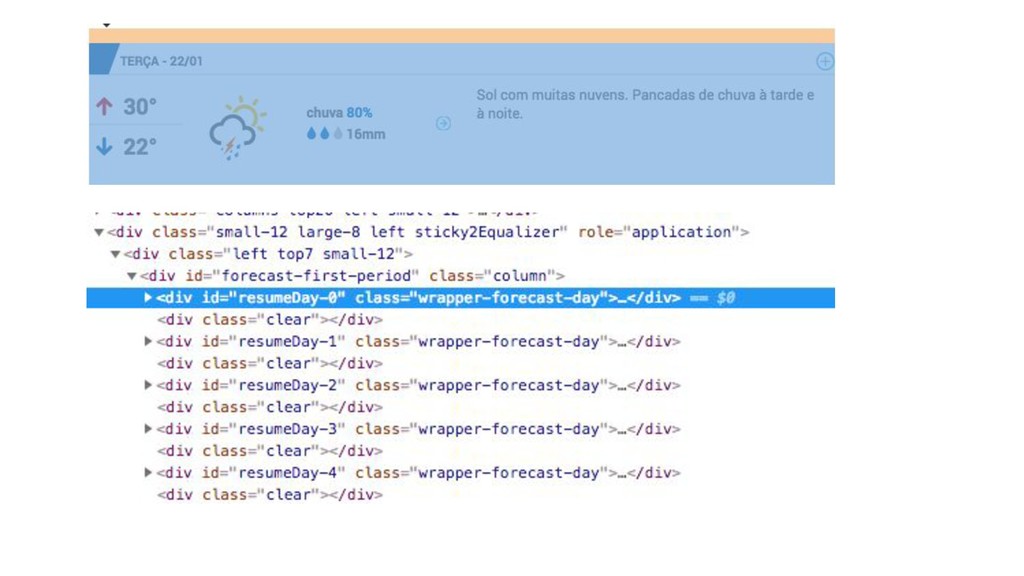{kind=link}
![def parse(self, response): dias = response.xpath('//div[contains(@id, "resumeDay")]')](https://files.speakerdeck.com/presentations/4d71dc9fd5e14cf8af4790c71fa47604/slide_36.jpg){kind=link}
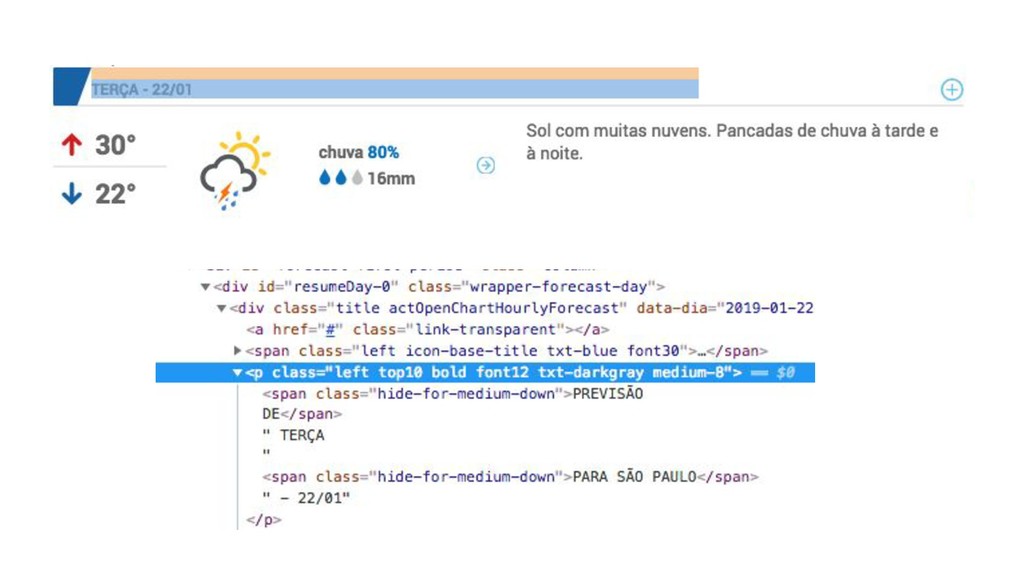{kind=link}
![def parse(self, response): dias = response.xpath('//div[contains(@id, "resumeDay")]') for dia in](https://files.speakerdeck.com/presentations/4d71dc9fd5e14cf8af4790c71fa47604/slide_38.jpg){kind=link}
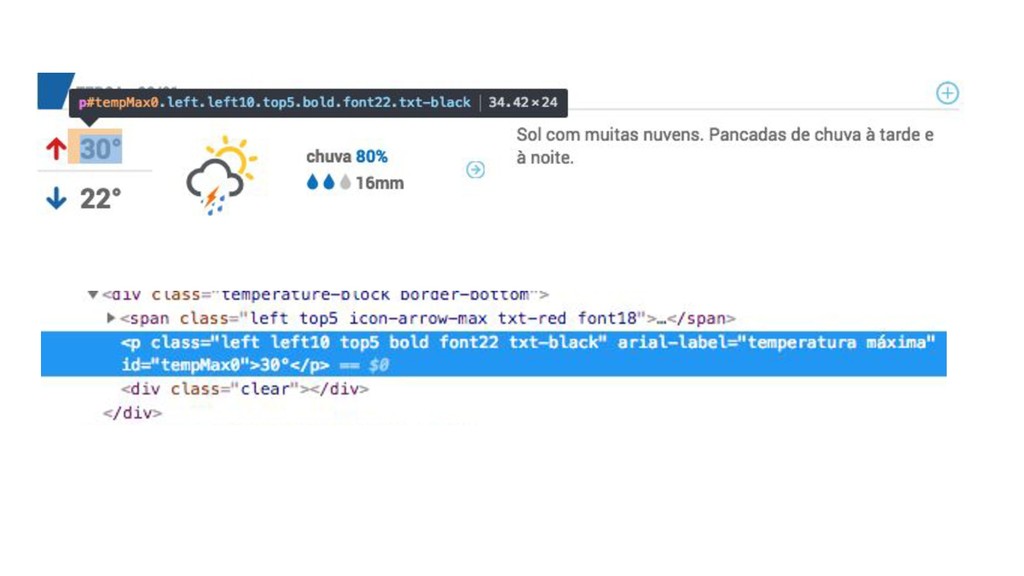{kind=link}
{kind=link}
![def parse(self, response): dias = response.xpath('//div[contains(@id, "resumeDay")]') for dia in](https://files.speakerdeck.com/presentations/4d71dc9fd5e14cf8af4790c71fa47604/slide_41.jpg){kind=link}
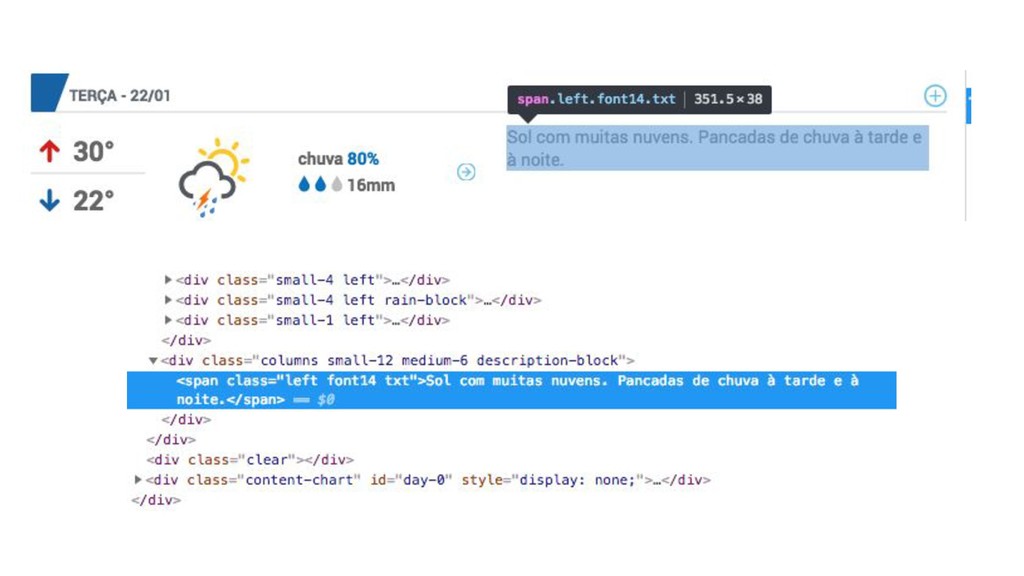{kind=link}
![def parse(self, response): dias = response.xpath('//div[contains(@id, "resumeDay")]') for dia in](https://files.speakerdeck.com/presentations/4d71dc9fd5e14cf8af4790c71fa47604/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}