p); input [15:0] a; input [15:0] b; output [31:0] p; assign p = a*b; endmodule // mul module mul ( A, B, P ); input [15:0] A; input [15:0] B; output [31:0] P; wire N1, N2, N3, N4, N5, N6, N7, N8, N9, N10, N11, N12, N13, N14, N15, N16,N17, N18, N19, N20, N21, N22, N23, N24, N25, N26, N27, N28, N29, N30, N31, N32, N33, N34, N35, N36, N37, N38, N39, N40, N41, N42, N43, N44, INVXD U669 ( .A(N766), .YB(P[3]) ); OA21XB U670 ( .A0(N769), .A1(N768), .B(N767), .Y(P[2]) ); NAND2XB U671 ( .A(A[1]), .B(B[0]), .YB(N771) ); XOR2XB U672 ( .A(N771), .B(N770), .Y(P[1]) ); INVXD U673 ( .A(N773), .YB(N775) ); AO221XB U674 ( .A0(N775), .A1(N774), .B0(N773), .B1(B[15]), .C(N772), .Y(N784) ); ADDFXD U675 ( .A(N786), .B(N777), .CIN(N776), .COUT(N782), .SUM(N778) ); ADDFXD U676 ( .A(N780), .B(N779), .CIN(N778), .COUT(N781), .SUM(N659) ); XNOR2XB U677 ( .A(N782), .B(N781), .YB(N783) ); XNOR2XB U678 ( .A(N784), .B(N783), .YB(N785) ); XOR2XB U679 ( .A(N786), .B(N785), .Y(P[31]) ); endmodule … 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
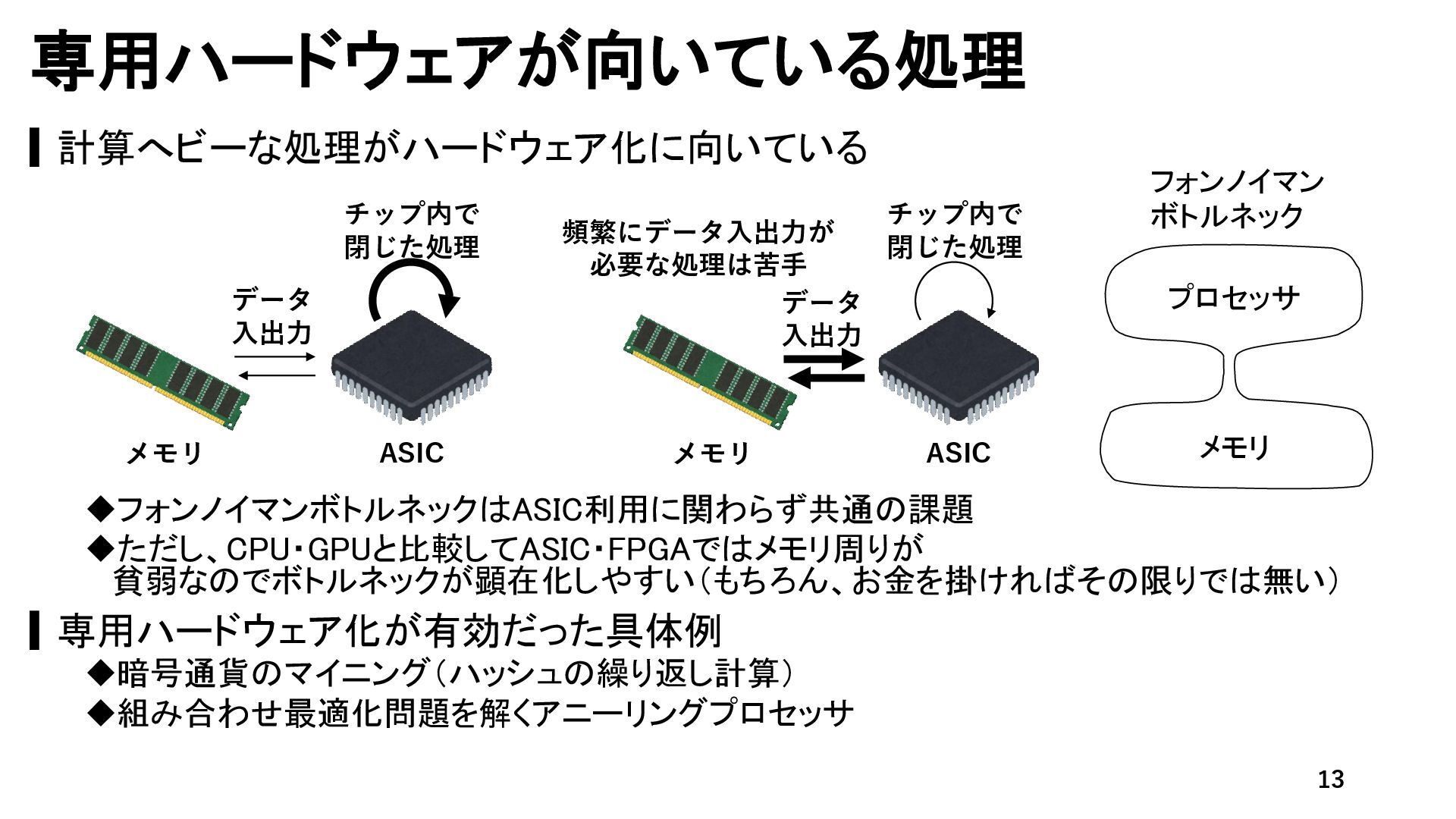{kind=link}
{kind=link}
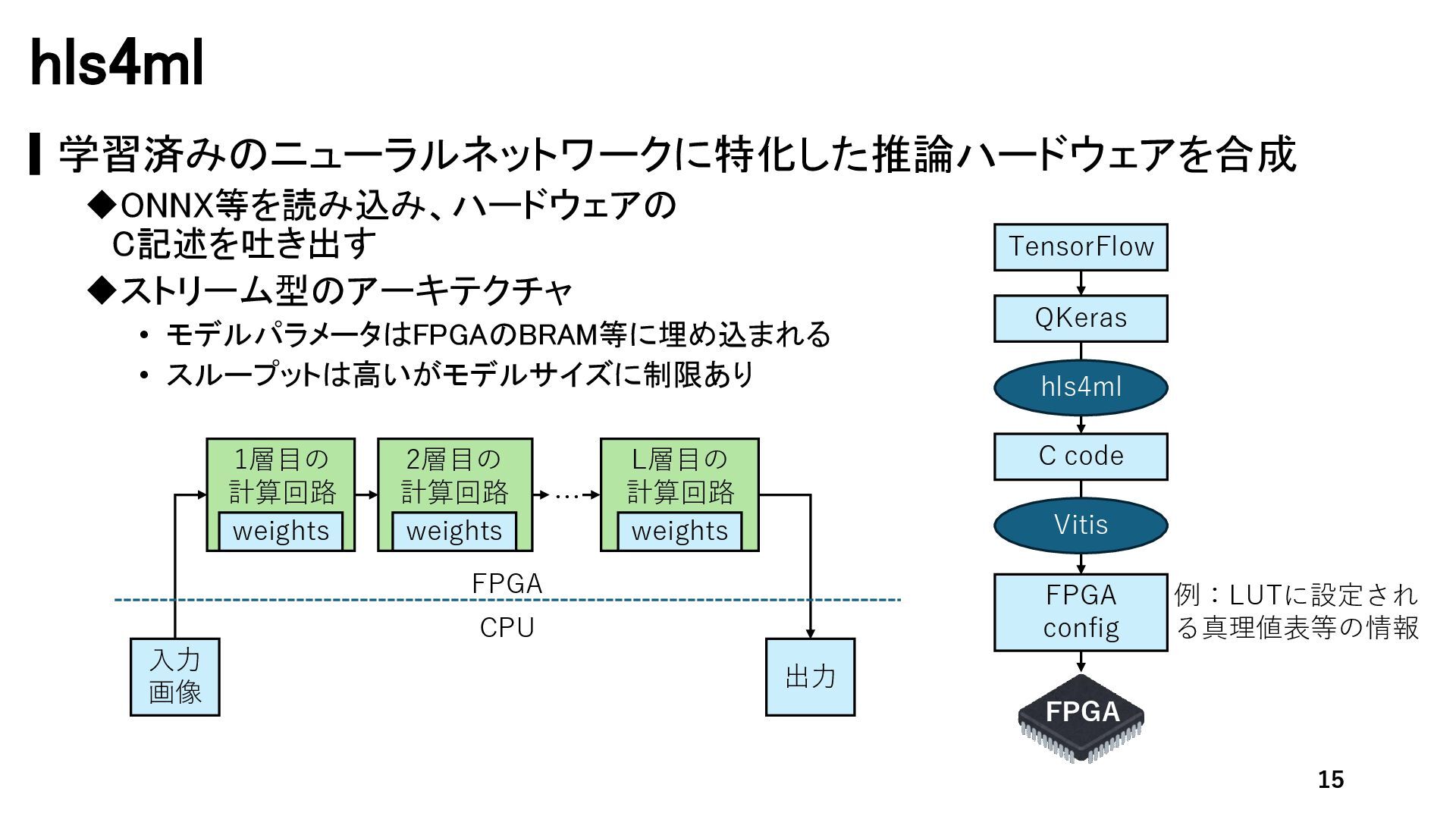{kind=link}
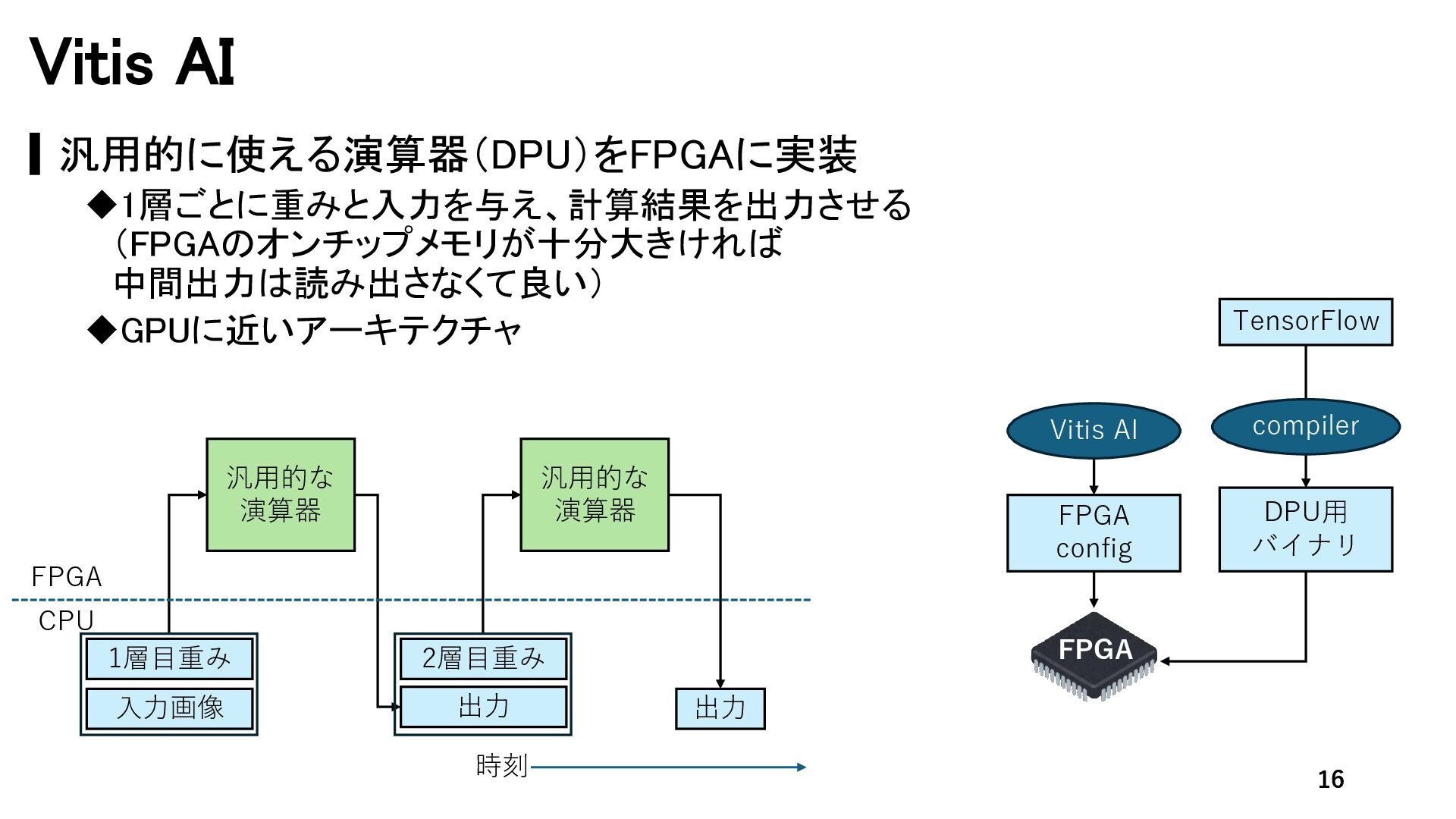{kind=link}
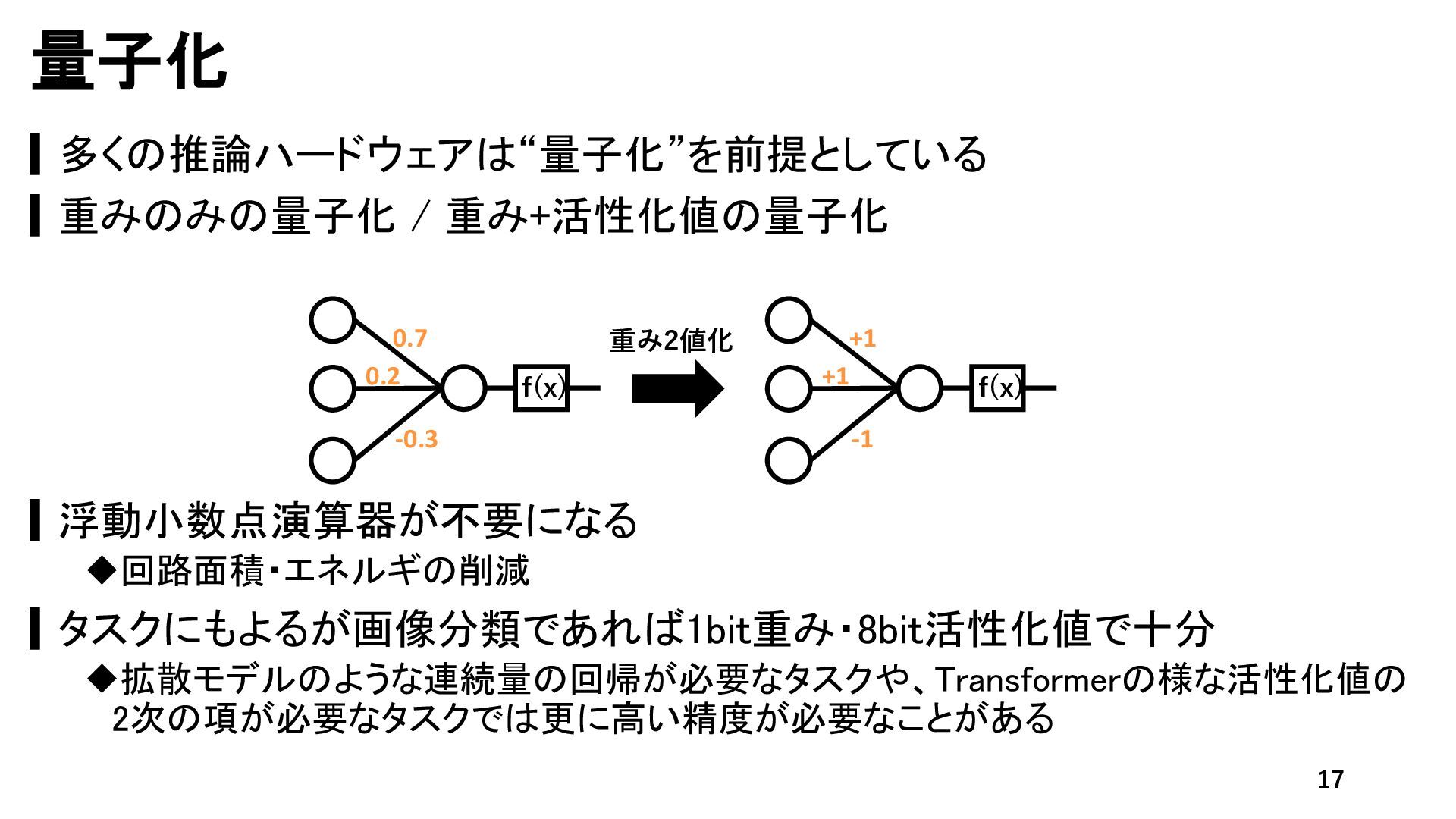{kind=link}
{kind=link}
{kind=link}
![他にも… ▍Incremental Quantization [Aojun Zhow et al., ICLR2017] ◆絶対値の大きな重みだけを選ん で量子化→再学習→残った重み](https://files.speakerdeck.com/presentations/0d4940e68c2344fbbefee2223bf0f89f/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![モジュールの書き方 ▍module で始まり、endmodule で終わる ▍回路の種類を表すモジュール名を付ける ▍通常、入出力信号がある module add32(a,b,s); input [31:0]](https://files.speakerdeck.com/presentations/0d4940e68c2344fbbefee2223bf0f89f/slide_32.jpg){kind=link}
![assign文(継続的代入文) ▍純粋な組合せ回路は、assign文で記述 ▍assign文(継続的代入文)は、左辺の信号と右辺の信号の間の普遍的な関係 を定義する、一種の宣言 module add32(a,b,s); input [31:0] a,b; output](https://files.speakerdeck.com/presentations/0d4940e68c2344fbbefee2223bf0f89f/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
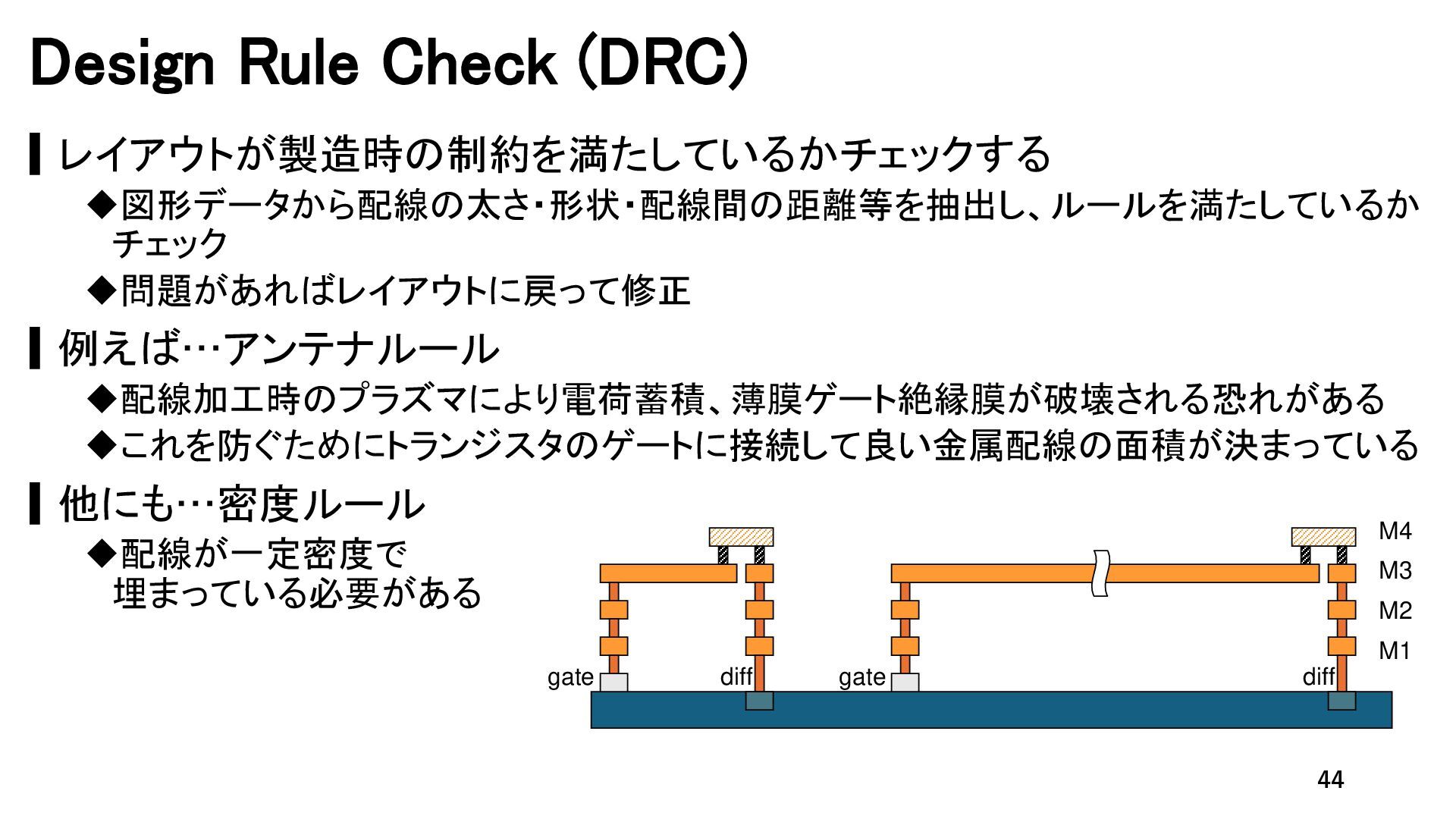{kind=link}
{kind=link}
{kind=link}
{kind=link}
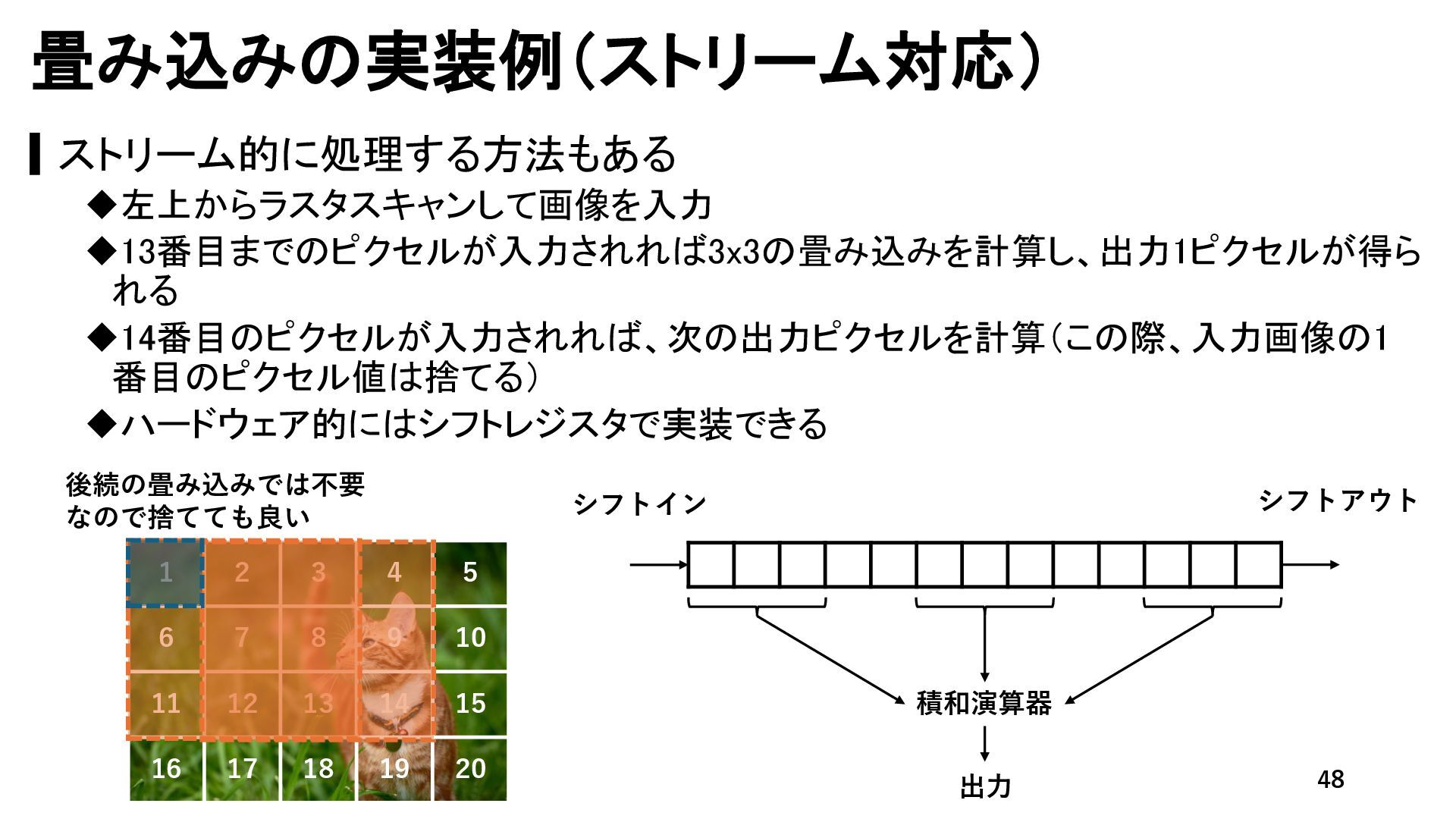{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![生成されたコードの一部 void conv2d( pixel_t input[H][W][C_IN], weight_t kernel[C_OUT][C_IN][K][K], acc_t output[H][W][C_OUT] )](https://files.speakerdeck.com/presentations/0d4940e68c2344fbbefee2223bf0f89f/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}