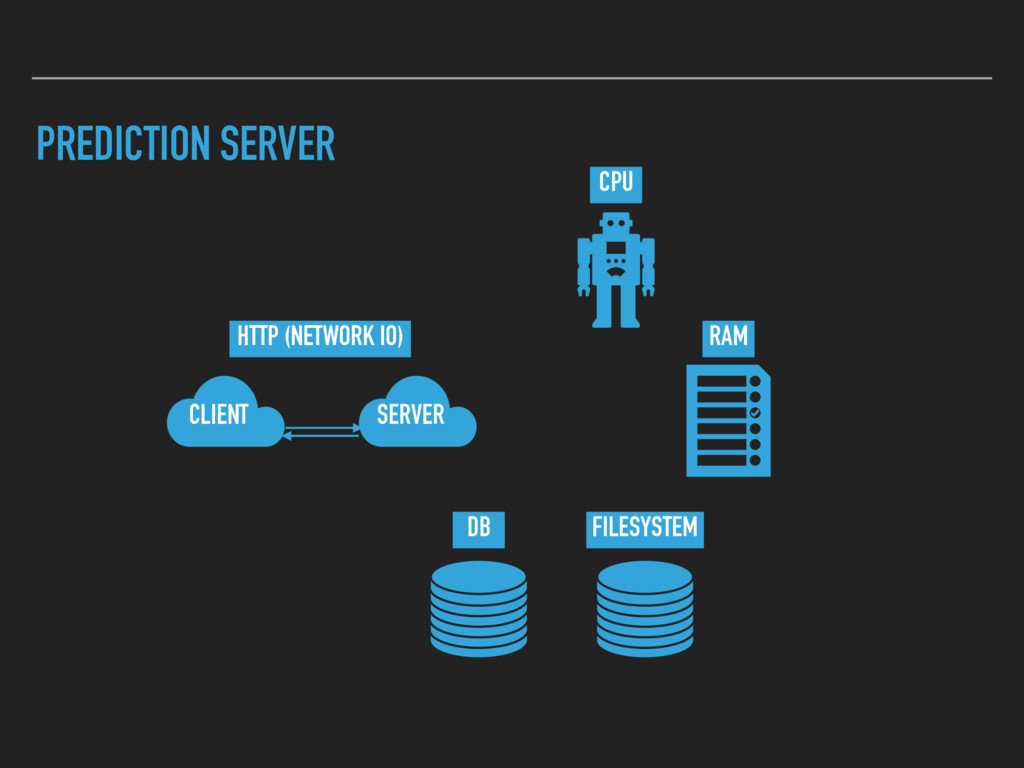
are slow and unreliable ▸ Deserializing model and load it to RAM is expensive ▸ model.predict(data) is CPU-bound operation ▸ model can be heavy 1Gb object.
▸ Custom routing (good UX) ▸ Gaps ▸ Complexity is growing (operations effort) ▸ Problem with utilization on opposite use case — can’t scale 1 model to N servers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}