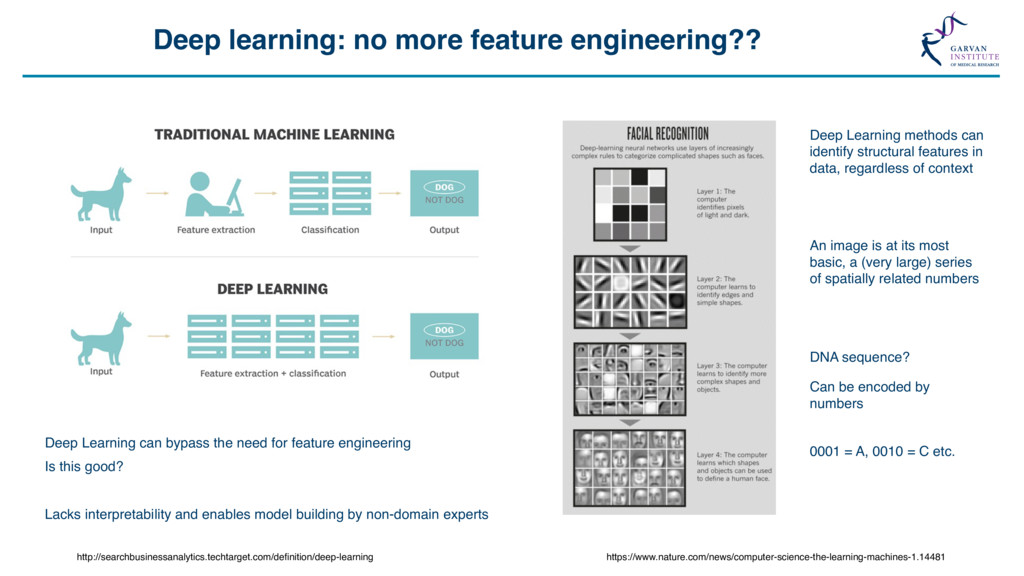
Grid Search “The Grid” Support Vector Machine (svmRadial) Hyperparameters C (cost) = 0.25, 0.5, 1, 2, 4 Sigma = 1, 1000 C sigma Accuracy 0.25 1 0.649 0.50 1 0.708 1.00 1 0.732 2.00 1 0.729 4.00 1 0.730 0.25 1000 0.649 0.50 1000 0.710 1.00 1000 0.730 2.00 1000 0.730 4.00 1000 0.727 Feature Selection *Some models include this automatically Feature number Feature 1 ORF length 2 Start Site 3 Stop Site 4 Sequence length 5 A-positional score 6 T-positional score 7 C-positional score 8 G-positional score 8 ORF frame 10 % GC 11 Random Value X … … 21 Random Value Y Model Accuracy with 21 Features Model Accuracy with 4 Features ~73% SVM model for lncRNA / protein coding transcript discrimination Methods • Recursive Feature Elimination • Genetic Algorithms • Random Feature Elimination ~83% Feature number Feature 1 ORF length 2 Start Site 3 Stop Site 4 Sequence length 5 A-positional score 6 T-positional score 7 C-positional score 8 G-positional score 8 ORF frame 10 % GC 11 Random Value X … … 21 Random Value Y
![Machine Learning in Genetics: Lessons Learned Beth Signal @BethSignal [email protected]](https://files.speakerdeck.com/presentations/83ca2632228a41d99b1efa350aa8a894/slide_0.jpg){kind=link}
{kind=link}
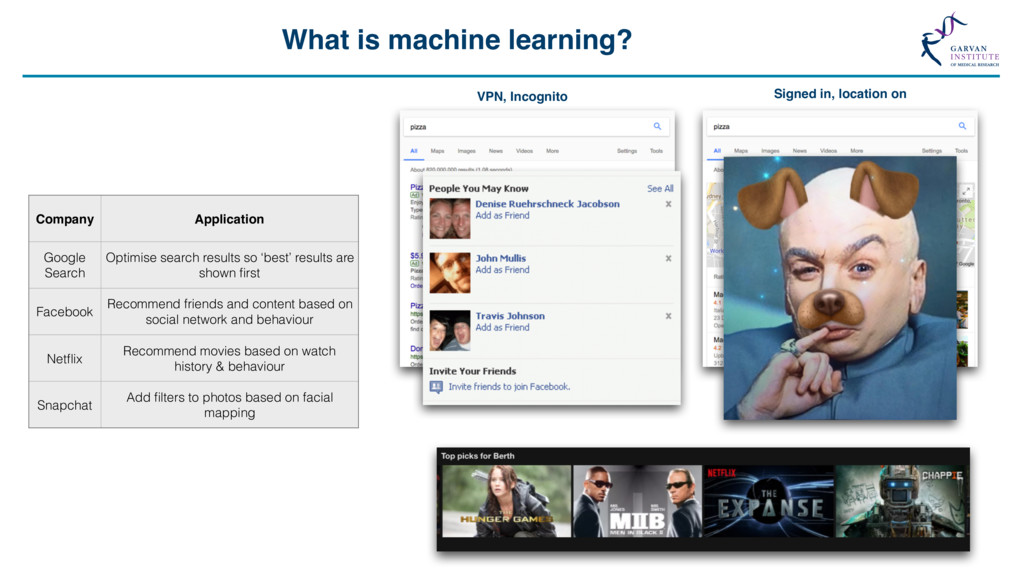{kind=link}
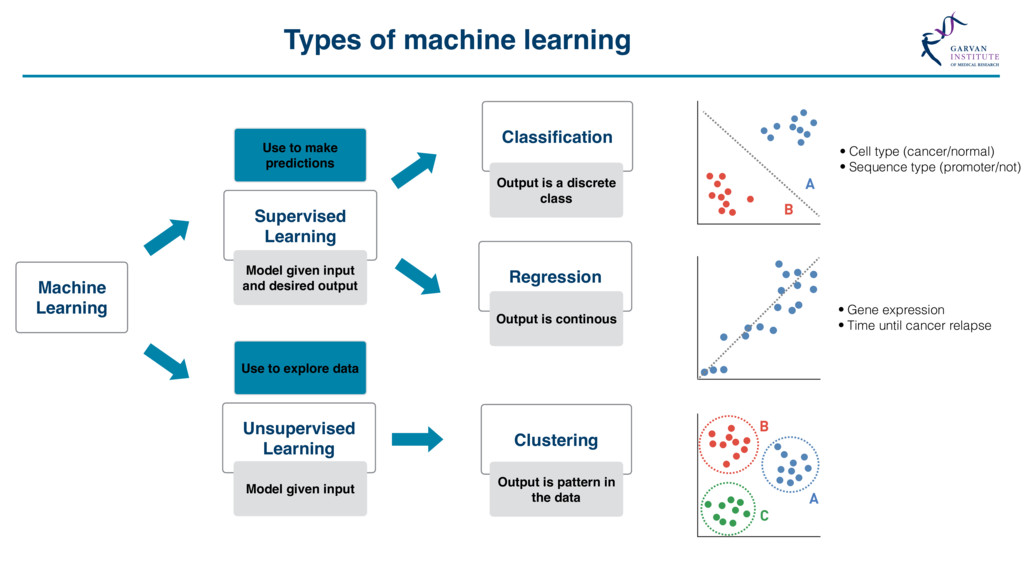{kind=link}
{kind=link}
{kind=link}
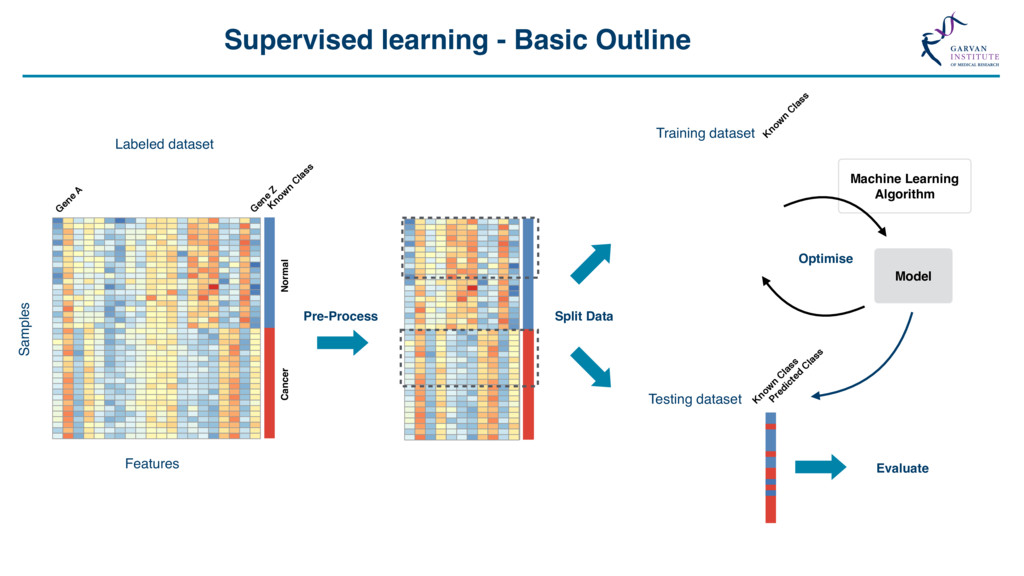{kind=link}
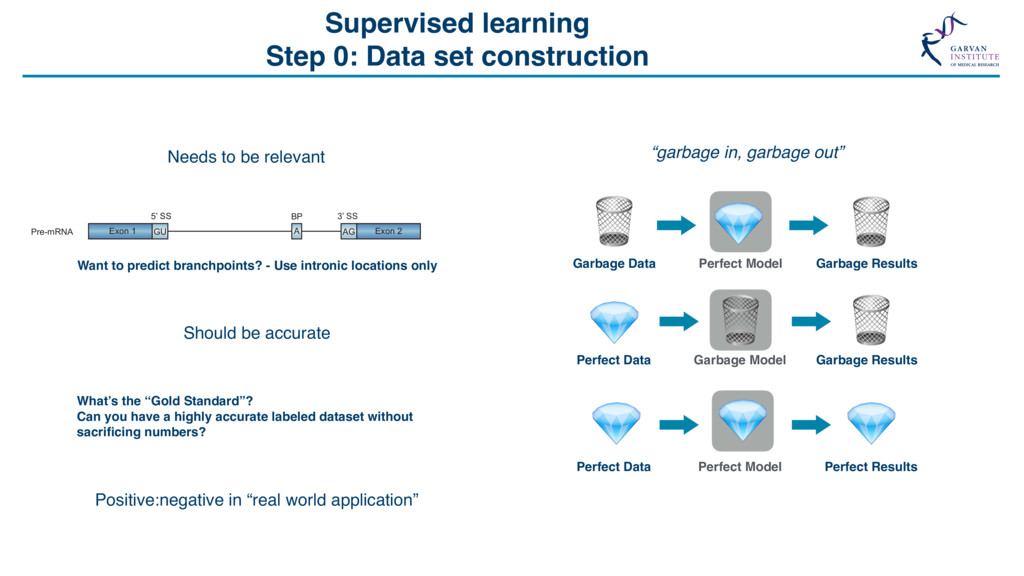{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}