Notes:
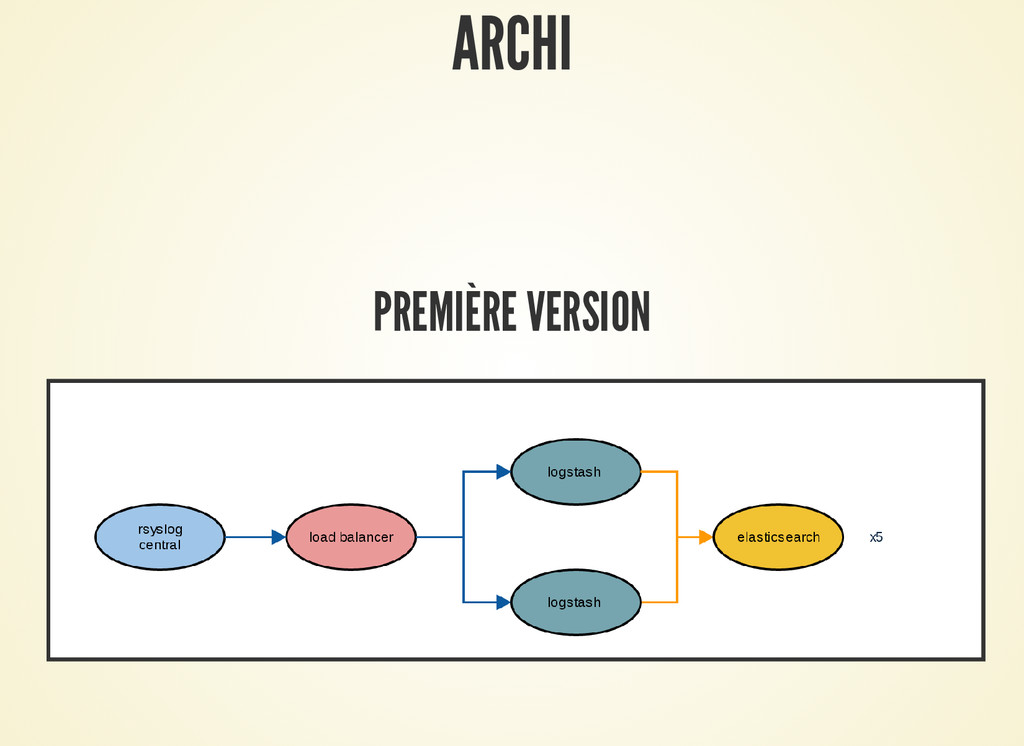
+ Archi :
- transport : syslog au dessus de tcp
- première version, logtash ne consomme plus les messages venant de
syslog si les filtres / sorties ne vont pas assez vite -> perte de
messages
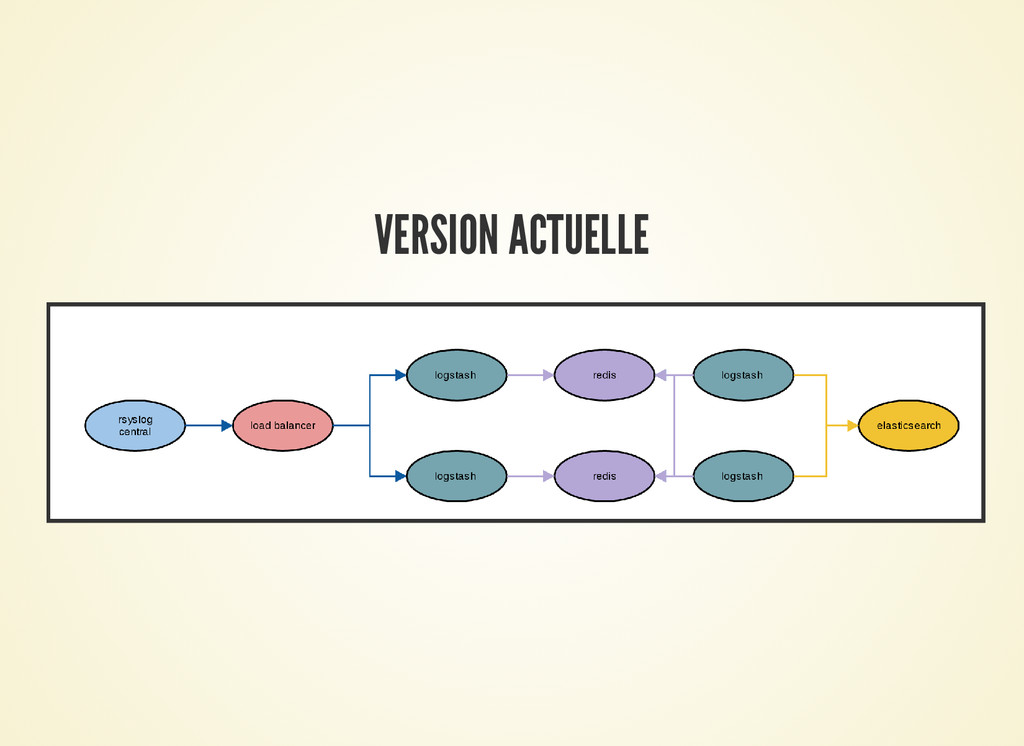
- seconde version: un étage simple (juste input / output) de logstash
qui mette en buffer les données dans redis.
+ Conso mémoire
- Agrégation simple (nombre de doc par jour) sur plusieurs jours -> la
requête ne finit pas : ralentissement, OutOfMemory
- Les field data consomment toute la heap
- Field data : structure utilisée par es pour calculer les
agrégations. Calculée et stockée en mémoire pour tout l'index lors du
premier appel.
- Le cache n'expire pas et n'est pas limité en taille par défaut
- Dans notre cas utilisation des "doc values": calcul et stockage des
"field data" au moment de l'indexation.
- Consomme plus d'espace disque et requête un peu plus lente -> mais
ou moins la requête termine maintenant.
+ Test
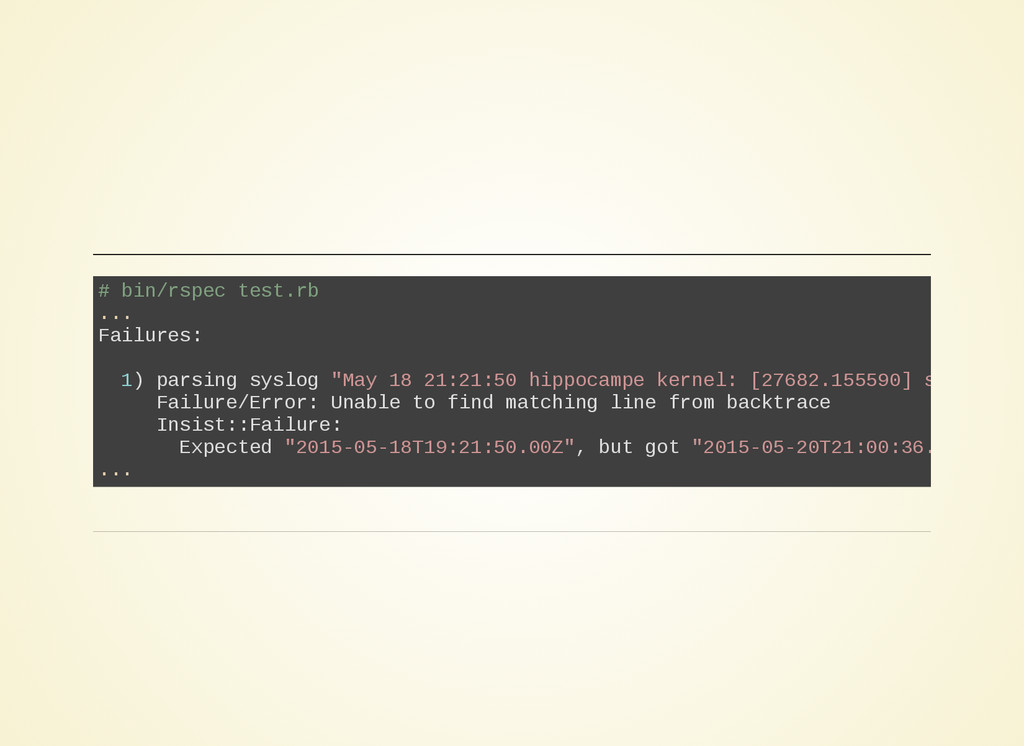
- A la main :
fastidieux -> conf de test, démarre logstash, copier/coller la ligne
de test, vérifier le résultat.
aller retour entre la conf de prod et la conf de test, on ne teste
que la ligne qu'on veut modifier -> risque d'en casser une
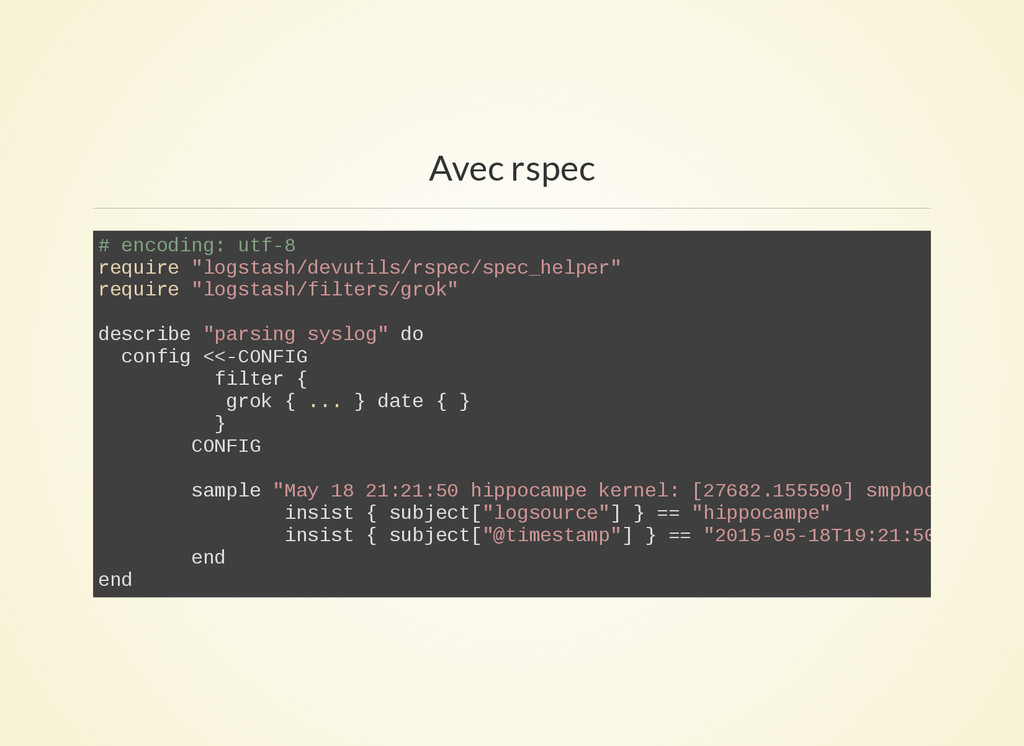
- Avec rspec:
un peu mieux mais la conf est toujours dans chaque fichier de test.
Toujours des aller retour avec la conf de prod
Les équipes doivent connaître rspec.
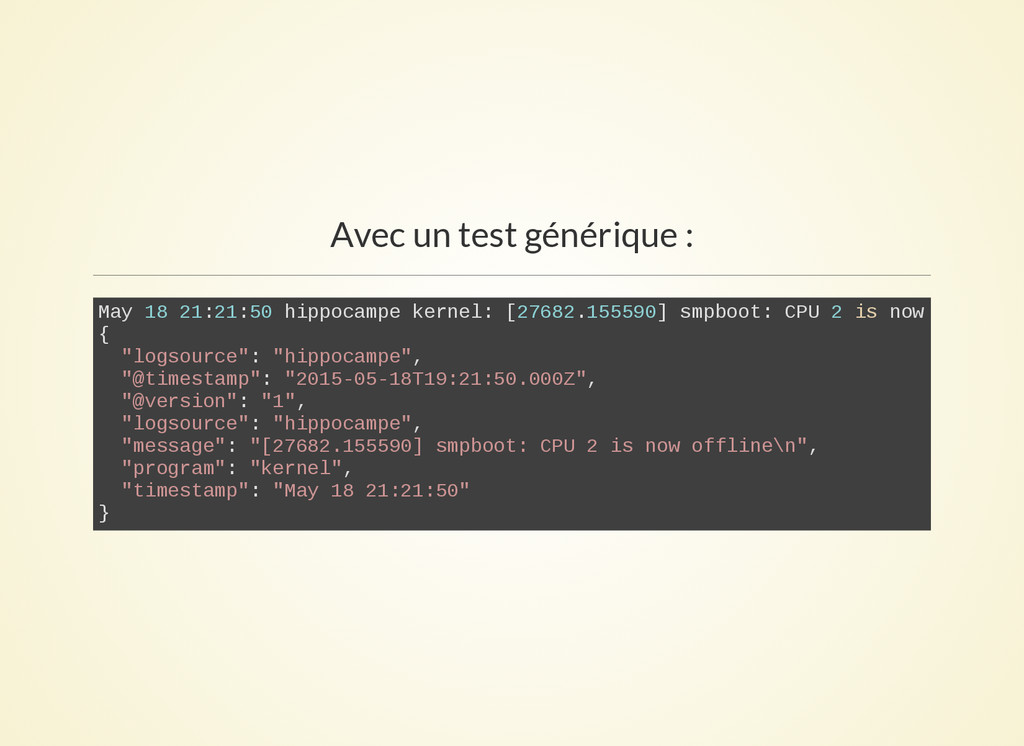
- Test générique :
il récupère la conf de prod et lance un jeu de fichiers de test.
Chaque fichier de test contient sur la première ligne la ligne à
tester et après un json correspondant à la ligne transformée.
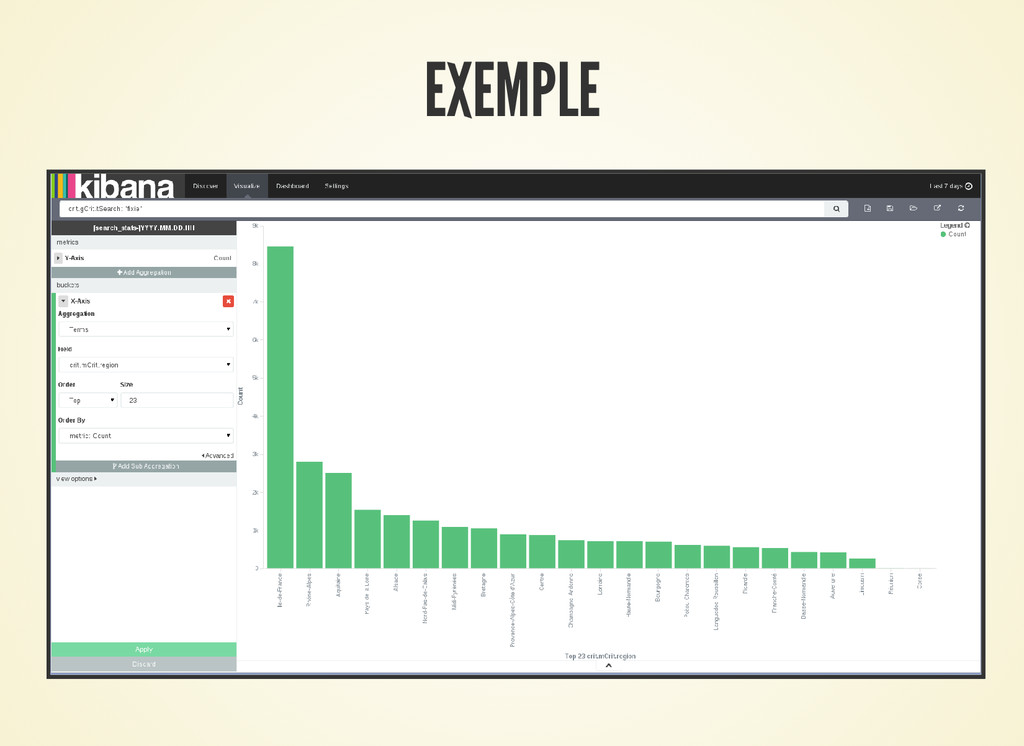
+ Agrégation :
- Requête : sélectionner tous les hits sur les url des numéros de téléphone
- Aggregation Term:
remonter les gens qui ont fait le plus de requêtes sur les numéros de
téléphone -> problème on remonte aussi les proxy des opérateurs
téléphoniques
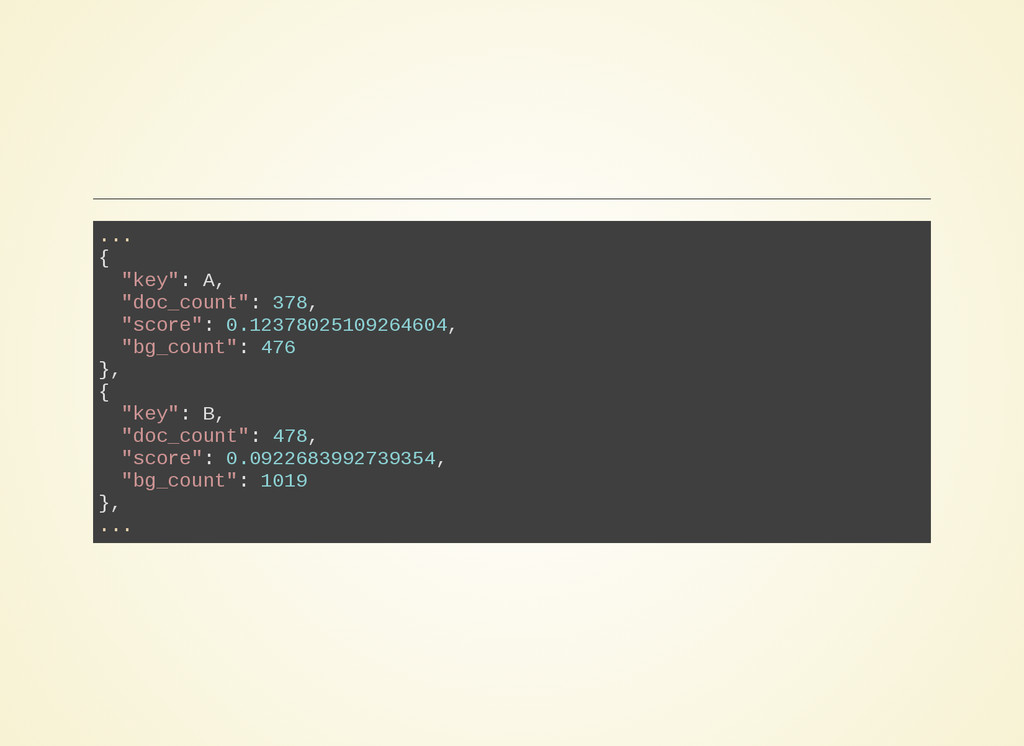
- Significant Term :
Remonter les anomalies
L'aggegration utilise 2 groupes de données :
- le premier : resultat de la requête
- le second : tout l'index
- elle remonte les termes qui apparaissent plus fréquemment dans le
premier groupe que dans le second
- dans notre cas les personnes qui consultent plus les numéros de
téléphone que les pages du site.
- key A : 378 requêtes sur le mobile, pour 476 requêtes en tout.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}