machine learning.” Springer. Hastie, T., Tibshirani, R., & Friedman, J. ( ). “ e elements of statistical learning: Data mining, inference, and prediction.” Springer Verlag. Hünermund, P., Kaminski, J., & Schmitt, C. ( , May ). Causal machine learning and business decision making (SSRN). [SSRN]. Mohan, K., & Pearl, J. ( ). “Graphical models for processing missing data.” Journal of the American Statistical Association, , – . Neapolitan, R. E. ( ). “Probabilistic reasoning in expert systems: eory and algorithms.” Wiley. Richardson, T. S., & Robins, J. M. ( ). Single world intervention graphs (SWIGs): A uni cation of the counterfactual and graphical approaches to causality. Uhler, C., Raskutti, G., Bühlmann, P., & Yu, B. ( ). “Geometry of the faithfulness assumption in causal inference.” e Annals of Statistics, ( ), – . Zhang, J., & Spirtes, P. ( ). “Detection of Unfaithfulness and Robust Causal Inference.” Minds and Machines, ( ), – .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
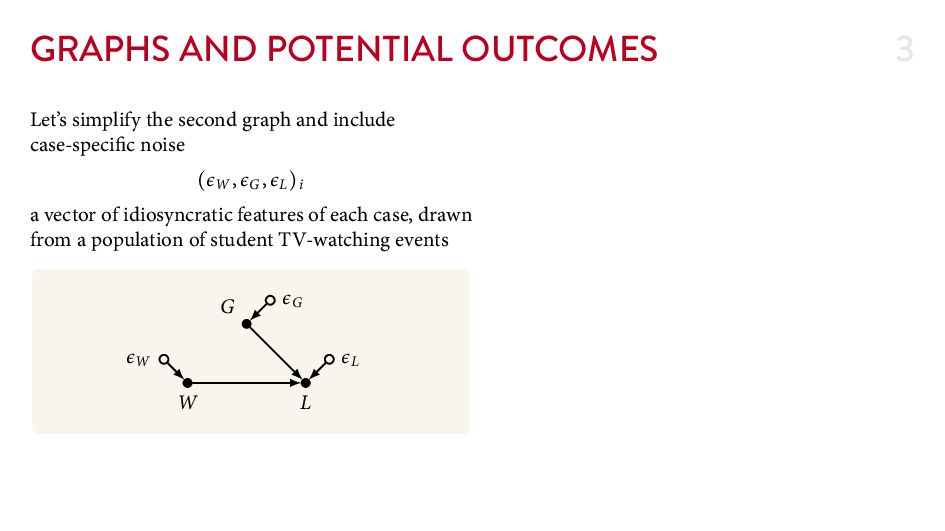{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
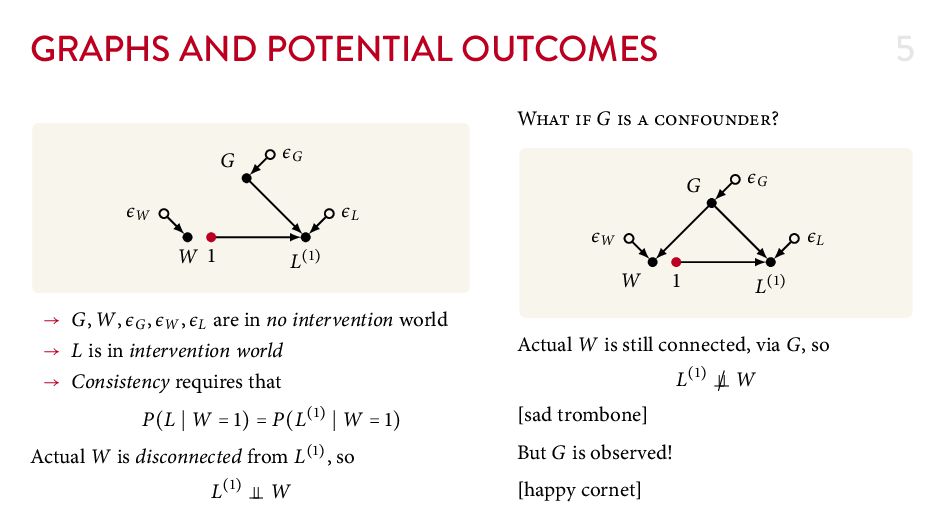{kind=link}
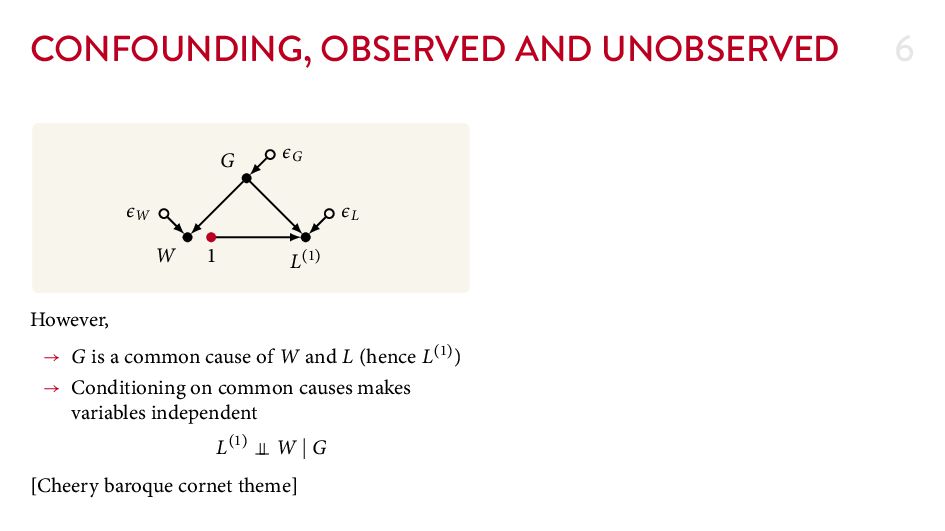{kind=link}
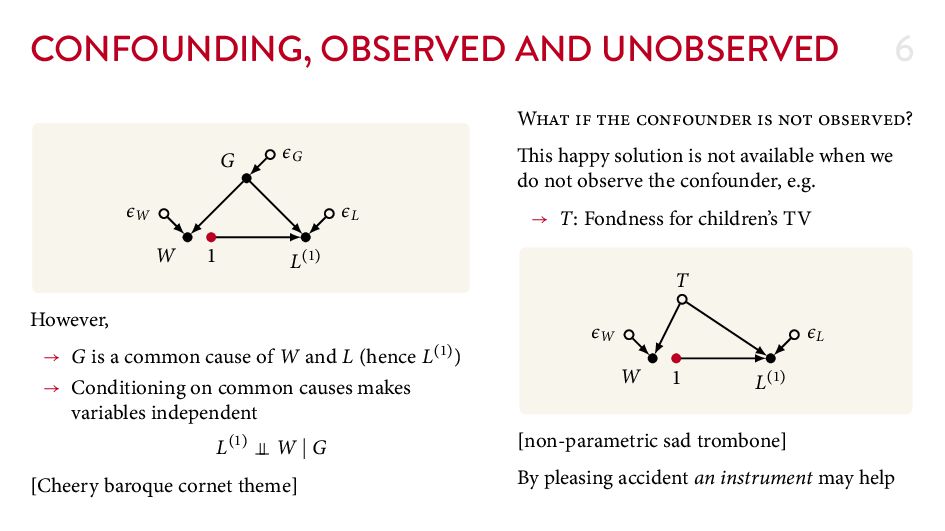{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}