“Mostly harmless econometrics: An empiricist’s companion.” Princeton University Press. Aronow, P. M., & Samii, C. ( ). “Does regression produce representative estimates of causal e ects?” American Journal of Political Science, ( ), – . Chernozhukov, V., Chetverikov, D., Demirer, M., Du o, E., Hansen, C., & Newey, W. ( ). “Double / debiased / Neyman machine learning of treatment e ects.” American Economic Review, ( ), – . Hirano, K., Imbens, G. W., & Ridder, G. ( ). “E cient estimation of average treatment e ects using the estimated propensity score.” Econometrica, ( ), – . Hünermund, P., & Louw, B. ( , October ). On the nuisance of control variables in regression analysis (ArXiv No. . ). Jensen, N. M. ( ). “Democratic governance and multinational corporations: Political regimes and in ows of foreign direct investment.” International Organization, ( ), – . Keele, L., Stevenson, R. T., & Elwert, F. ( ). “ e causal interpretation of estimated associations in regression models.” Political Science Research and Methods, ( ), – .
{kind=link}
![REGRESSION BASICS 1 A regression function: E[log wage education] A](https://files.speakerdeck.com/presentations/fc2dda217d464c46a564a55442878c5d/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
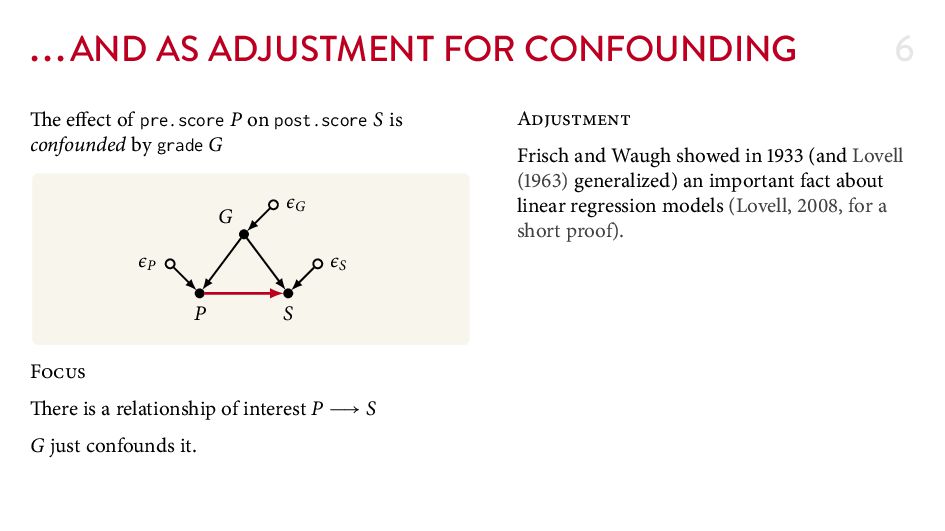{kind=link}
{kind=link}
{kind=link}
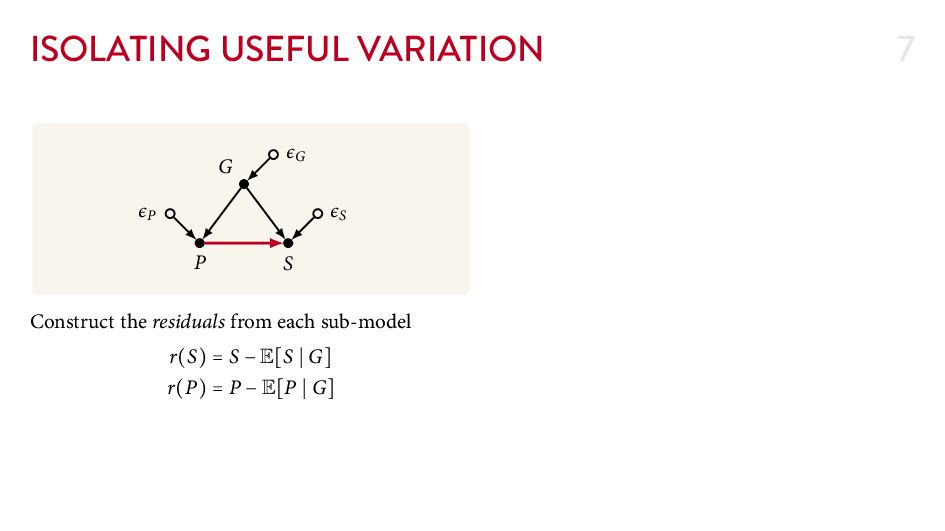{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
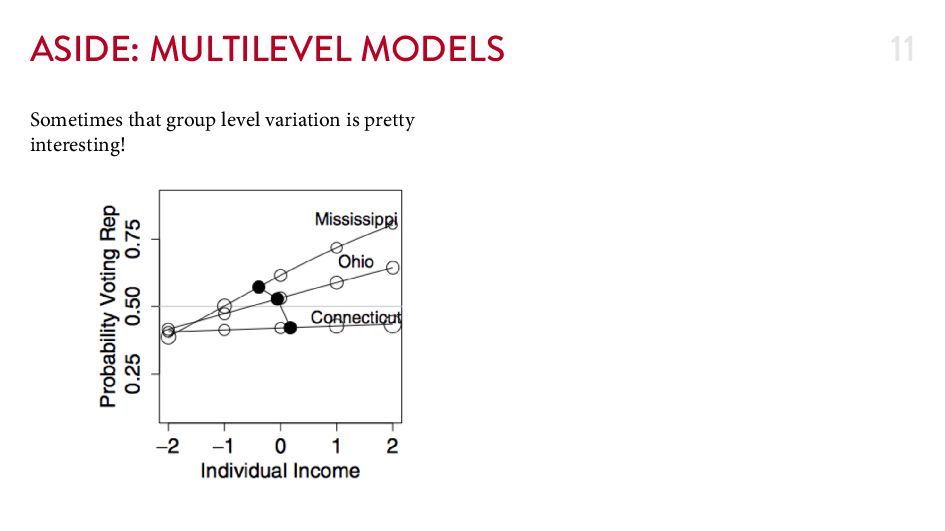{kind=link}
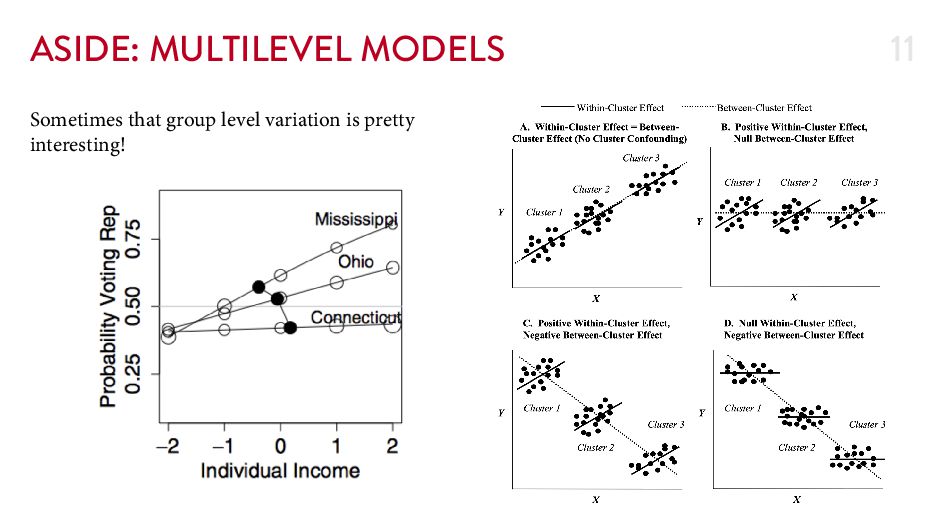{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
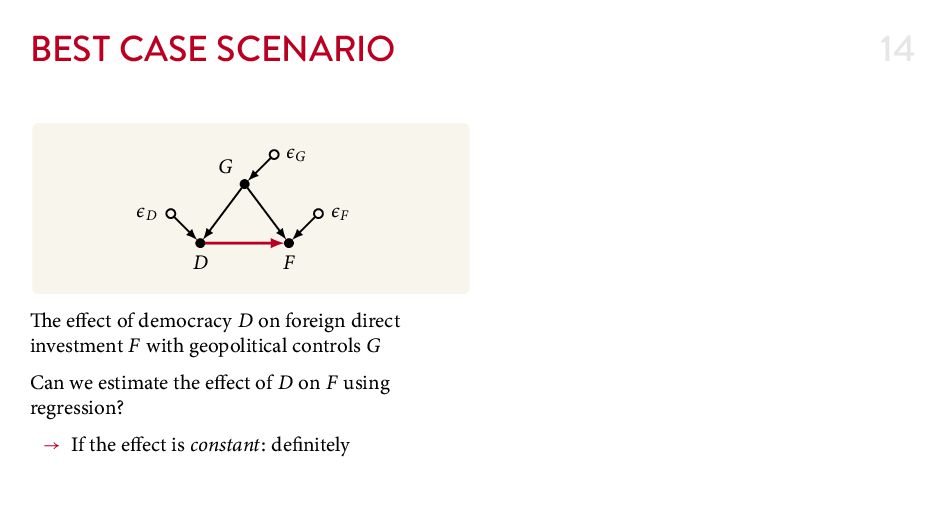{kind=link}
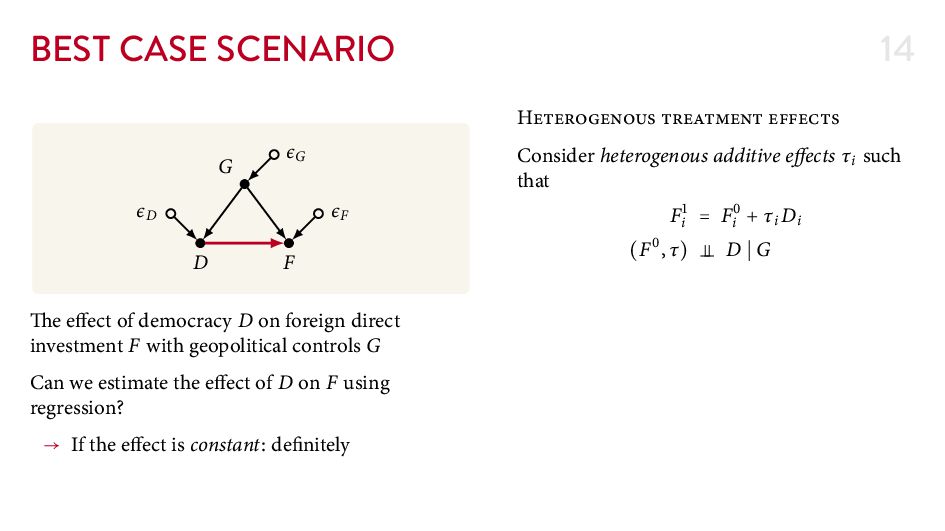{kind=link}
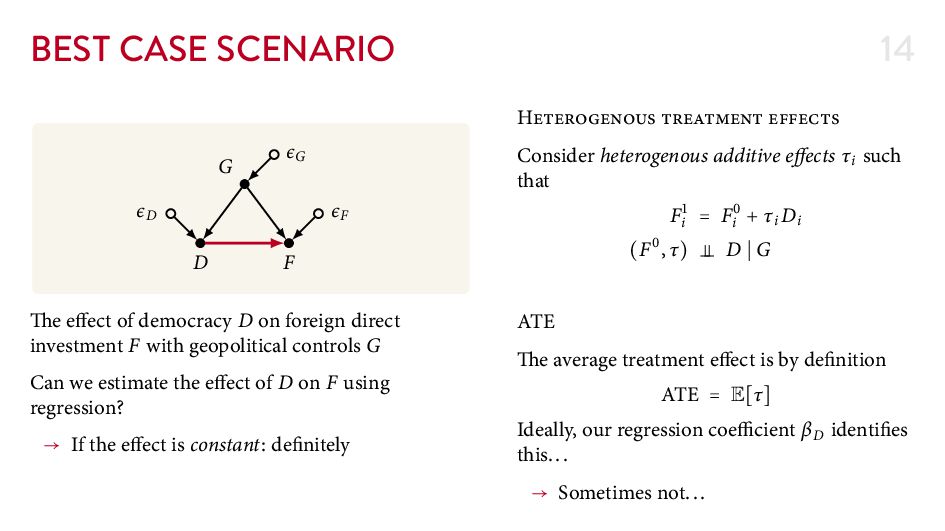{kind=link}
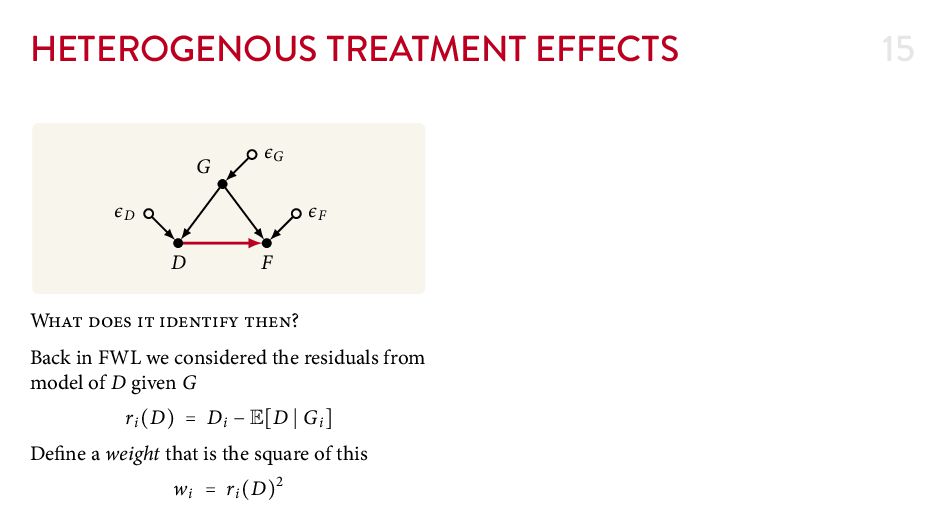{kind=link}
{kind=link}
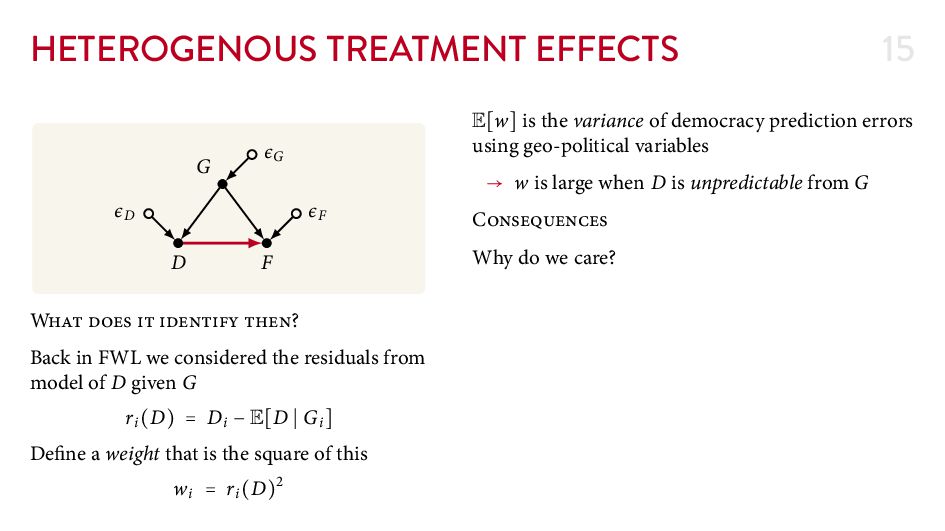{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}