Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データエンジニア AI Agentを作ったらdbtのありがたみが増した
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
crazysrot
March 02, 2026
850
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データエンジニア AI Agentを作ったらdbtのありがたみが増した
crazysrot
March 02, 2026
More Decks by crazysrot
See All by crazysrot
スタートアップで初めての機械学習プロジェクトをリードするということ
crazysrot
0
180
Featured
See All Featured
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Test your architecture with Archunit
thirion
1
2.3k
First, design no harm
axbom
PRO
2
1.2k
Designing for Timeless Needs
cassininazir
1
250
AI: The stuff that nobody shows you
jnunemaker
PRO
8
700
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
940
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
450
Transcript
データエンジニア AI Agentを作ったら dbtのありがたみが増した AI Agent実装で⾒えた「dbtエコシステム」の真価 古⽥ 裕規 株式会社ミツモア Tokyo
dbt Meetup #19 2026.02.25
⾃⼰紹介 株式会社ミツモア データグループマネージャ 経歴など 分析コンサルティング会社にてデータサイエンティストとして従事 DX推進、データ分析基盤構築、データ活⽤テーマの抽出、データ分析、AIシステ ム構築まで⼀気通貫した業務を推進 コンサルとフリーの活動含め、⼈材‧⾦融‧医療‧旅⾏‧マーケティング‧⾞ 業 界など幅広い経験あり
その後、2021年8⽉より1⼈⽬データ系正社員ポジションにてミツモア⼊社 現在は、データ基盤からAIまでを担当するグループのマネージャとしてデータの ⼈として活動しています crazysrot
会社について
会社紹介 株式会社ミツモア ミツモアのミッション Our Mission 日本のGDPを増やし 明日がもっといい日になる と思える社会に
会社紹介 株式会社ミツモア 我々は、3つのプロダクトを通して サービス産業の生産性向上を追い求めます。 日本人が使える、 世界基準でよいプロダクトを作る 生産性向上のために To Improve Productivity
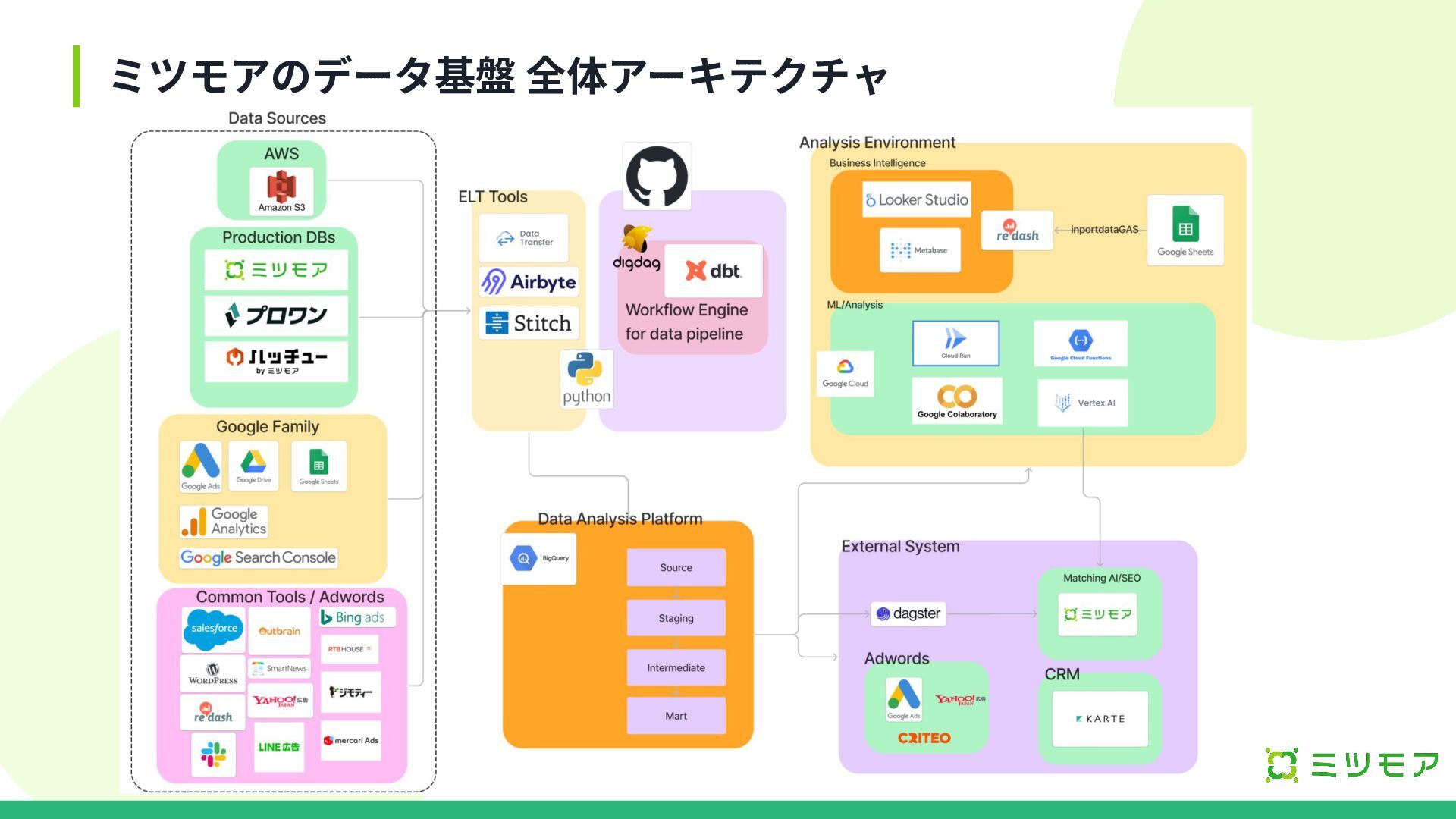
ミツモアのデータ基盤 全体アーキテクチャ
データ基盤と⽣成AIについて
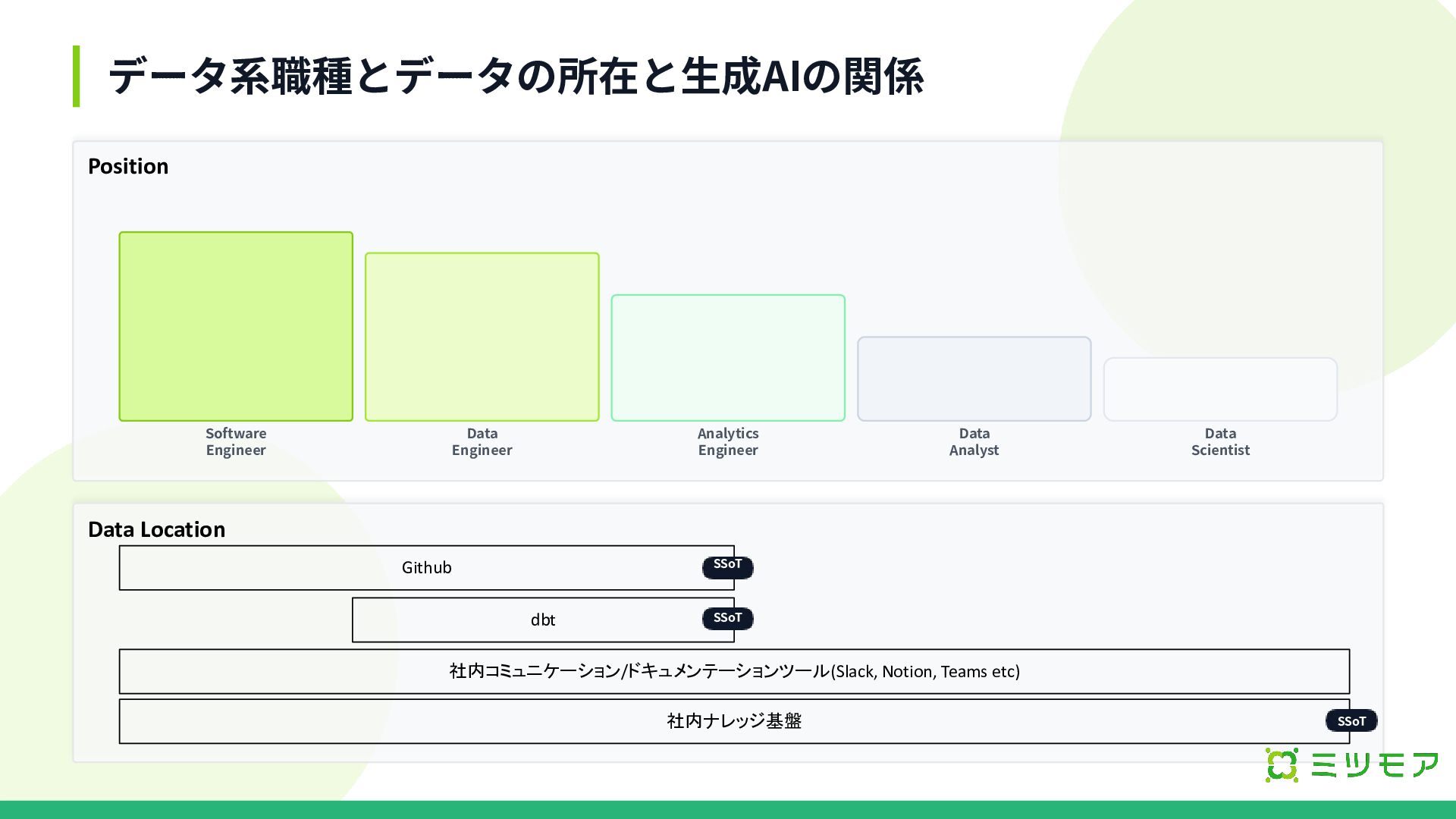
データ系職種とデータの所在と⽣成AIの関係 SSoT / 構造化レベル Software Engineer Data Engineer Analytics Engineer
Data Analyst Data Scientist Position Github dbt Data Location 社内コミュニケーション/ドキュメンテーションツール(Slack, Notion, Teams etc) SSoT SSoT 社内ナレッジ基盤 SSoT
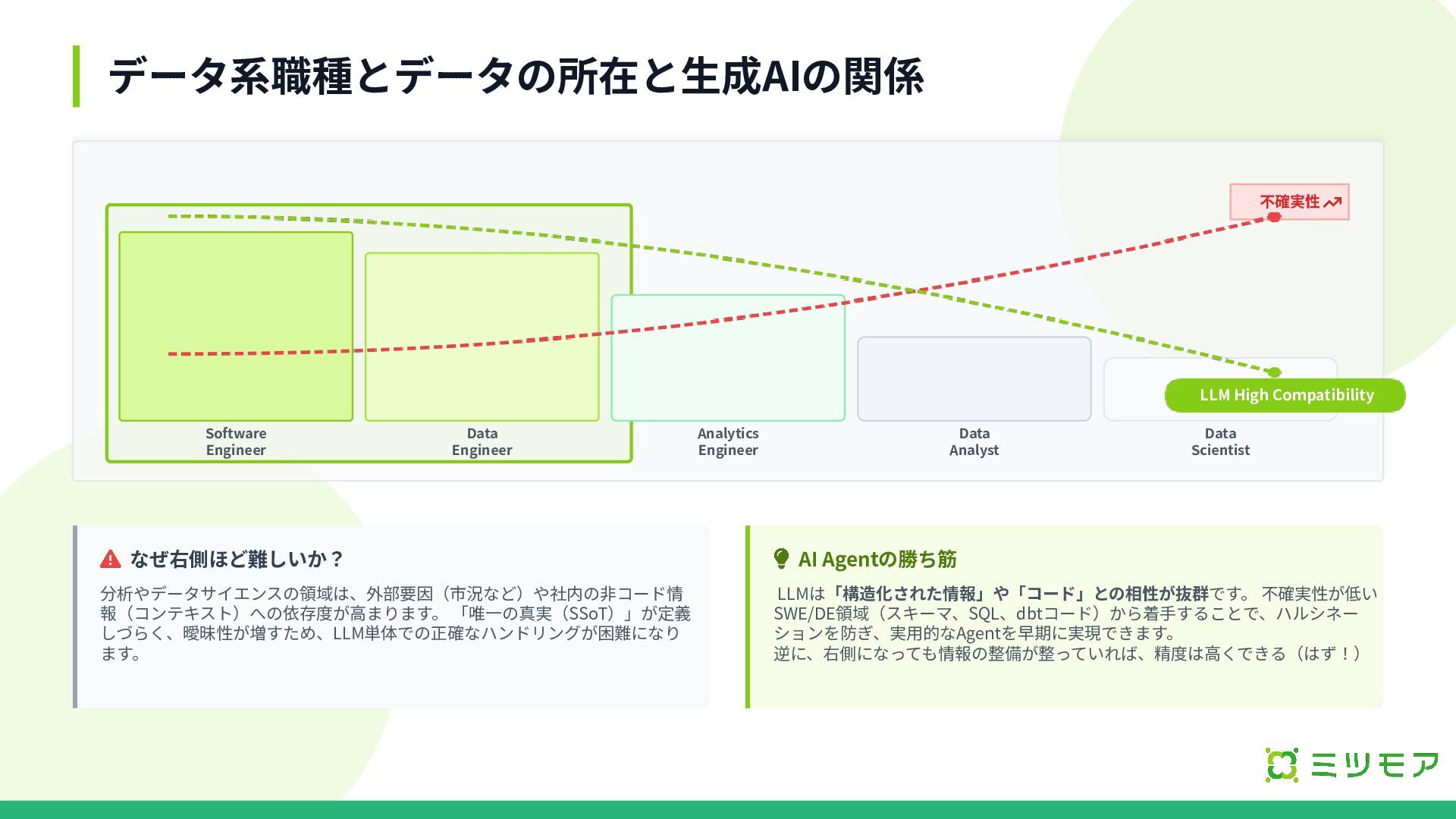
データ系職種とデータの所在と⽣成AIの関係 なぜ右側ほど難しいか? 分析やデータサイエンスの領域は、外部要因(市況など)や社内の⾮コード情 報(コンテキスト)への依存度が⾼まります。 「唯⼀の真実(SSoT)」が定義 しづらく、曖昧性が増すため、LLM単体での正確なハンドリングが困難になり ます。 AI Agentの勝ち筋 LLMは「構造化された情報」や「コード」との相性が抜群です。
不確実性が低い SWE/DE領域(スキーマ、SQL、dbtコード)から着⼿することで、ハルシネー ションを防ぎ、実⽤的なAgentを早期に実現できます。 逆に、右側になっても情報の整備が整っていれば、精度は⾼くできる(はず!) 不確実性 SSoT / 構造化レベル Software Engineer Data Engineer Analytics Engineer Data Analyst Data Scientist LLM High Compatibility
AI Driven Analysis ロードマップ Lv.1 データチーム内において、業務を 遂行できている Lv.2 CursorなどのLLMサポートツール などを用いて、データチーム内で
業務の効率化が測れている Lv.3 CursorなどのLLMサポートツール などを用いて、データチーム外の 人間が業務の効率化を図れてい る Lv.4 汎用的なLLMサポートツールなど を用いて、データチーム外の一部 部門の人間が業務の効率化を測 れている Lv.5 汎用的なLLMサポートツールなど を用いて、全部門の人間が業務の 効率を測れている Layer Hierarchy Layer Applying AI データ連携ができている ・AI駆動開発による、データエンジニアリングのサポートが行えている ・AI駆動開発による、データエンジニアリングの領域の開発をビジネス側で行える データにアクセスしやすい text2sqlなどの生成AIにより、より正しい必要なデータを正しくすばやく判取できる 可視化しやすい Graphicalな可視化や簡単なものであったり特殊な可視化であっても裏でPythonなどが実行 基本的な可視化のパターンを網羅的に把握して持っている 意思決定に使われている 出力された結果を一覧表の状態を整理した上で今後どのような意思決定をするべきか正しく判断できたか出える AIの考察結果が果実かどうかな判断できる、分析力を持つ AIを活用して高度な分析がしやすい 機械学習などのより高度な分析をすることができる。そのために、分析基盤と分析プラットフォームと生成AIがシームレスにつながっている 1 2 3 4 5
AI Agent 内製事例
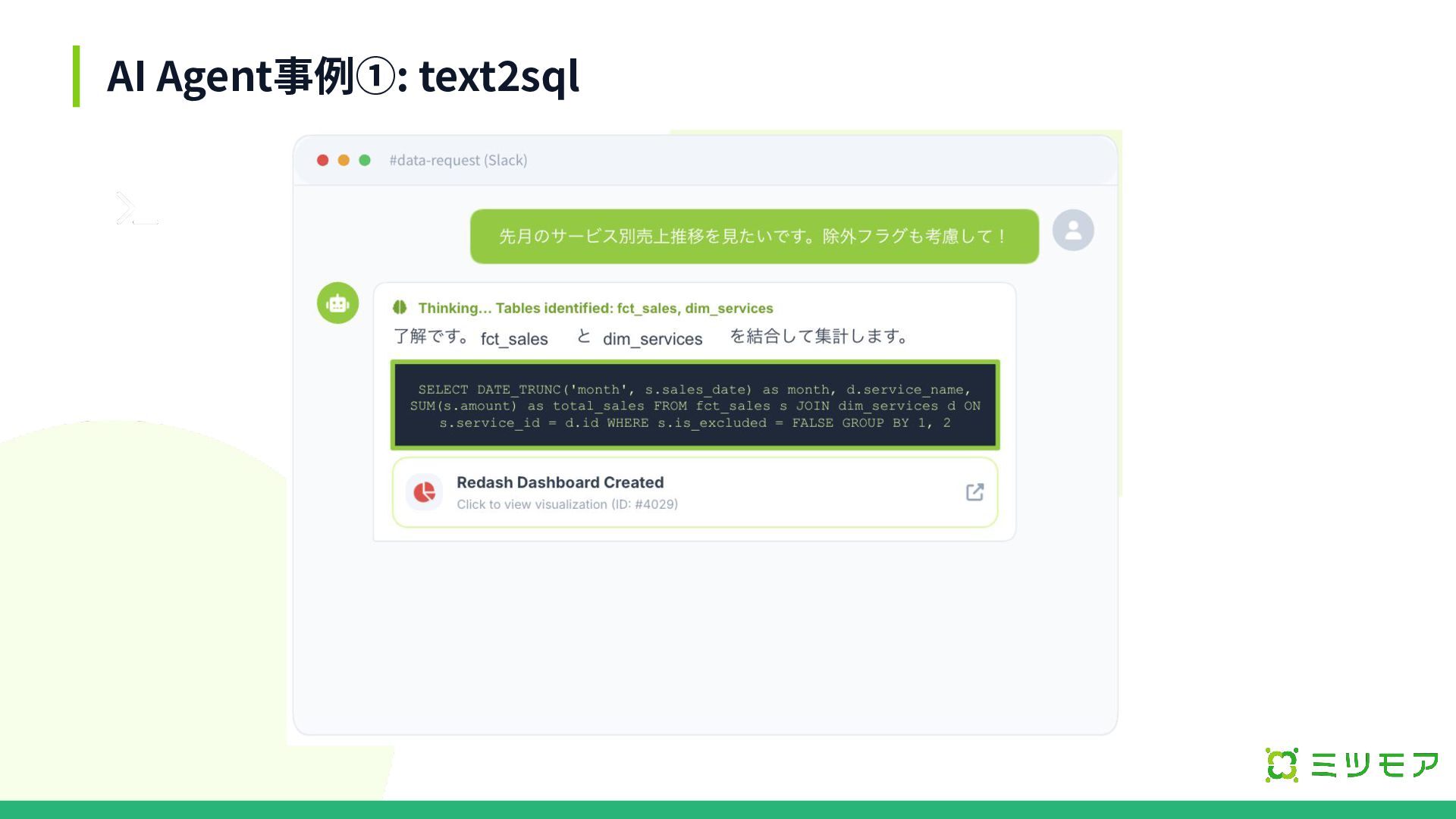
AI Agent事例①: text2sql #data-request (Slack) Thinking... Tables identified: fct_sales, dim_services
Redash Dashboard Created Click to view visualization ID #4029 了解です。 fct_sales と dim_services
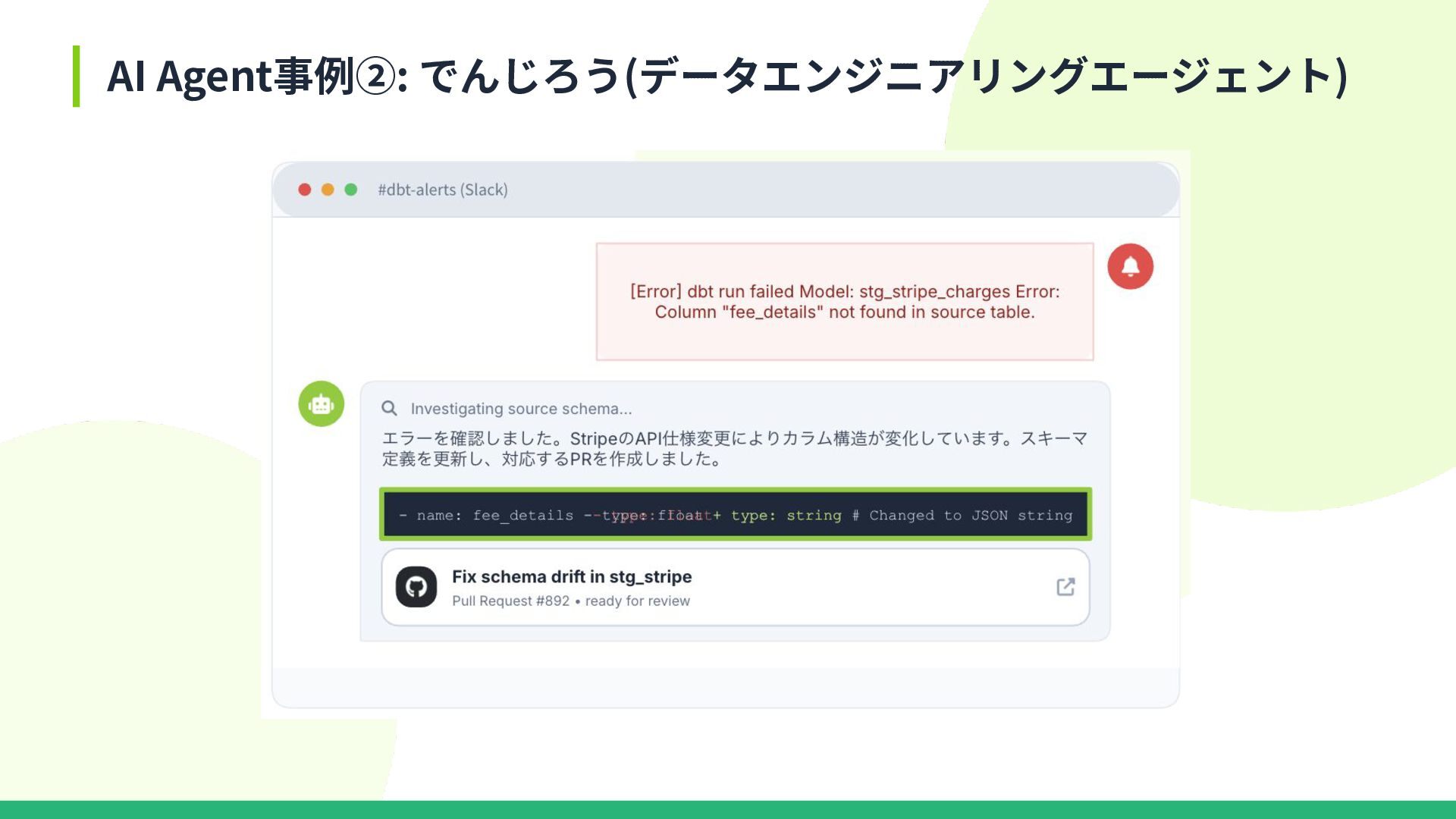
AI Agent事例②: でんじろう(データエンジニアリングエージェント)
AI Readyなデータ基盤整備
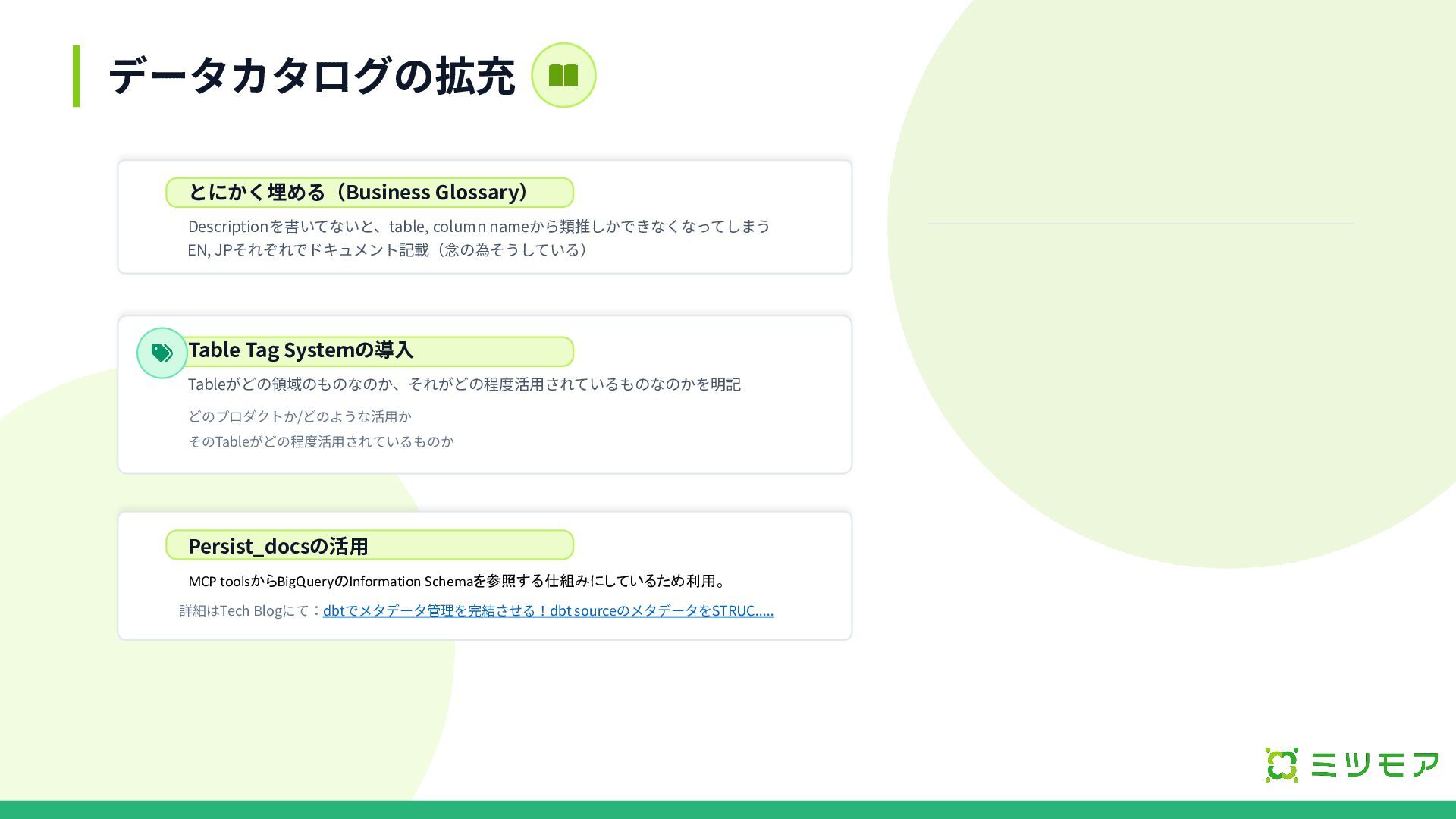
データカタログの拡充 とにかく埋める(Business Glossary) Descriptionを書いてないと、table, column nameから類推しかできなくなってしまう Tableがどの領域のものなのか、それがどの程度活⽤されているものなのかを明記 どのプロダクトか/どのような活⽤か そのTableがどの程度活⽤されているものか EN,
JPそれぞれでドキュメント記載(念の為そうしている) MCP toolsからBigQueryのInformation Schemaを参照する仕組みにしているため利用。 詳細はTech Blogにて:dbtでメタデータ管理を完結させる!dbt sourceのメタデータをSTRUC..... Table Tag Systemの導⼊ Persist_docsの活⽤
データカタログの拡充 - dbt docs記載例 ****************
データカタログの拡充 - dbt docs ルール記載例 dbt docs⾃体も⾃動⽣成 しているため、基本的にはルールを⾔語化してCLAUDE.md などに記載 ここで、TierやTagに対する記載⽅法などを明記しています
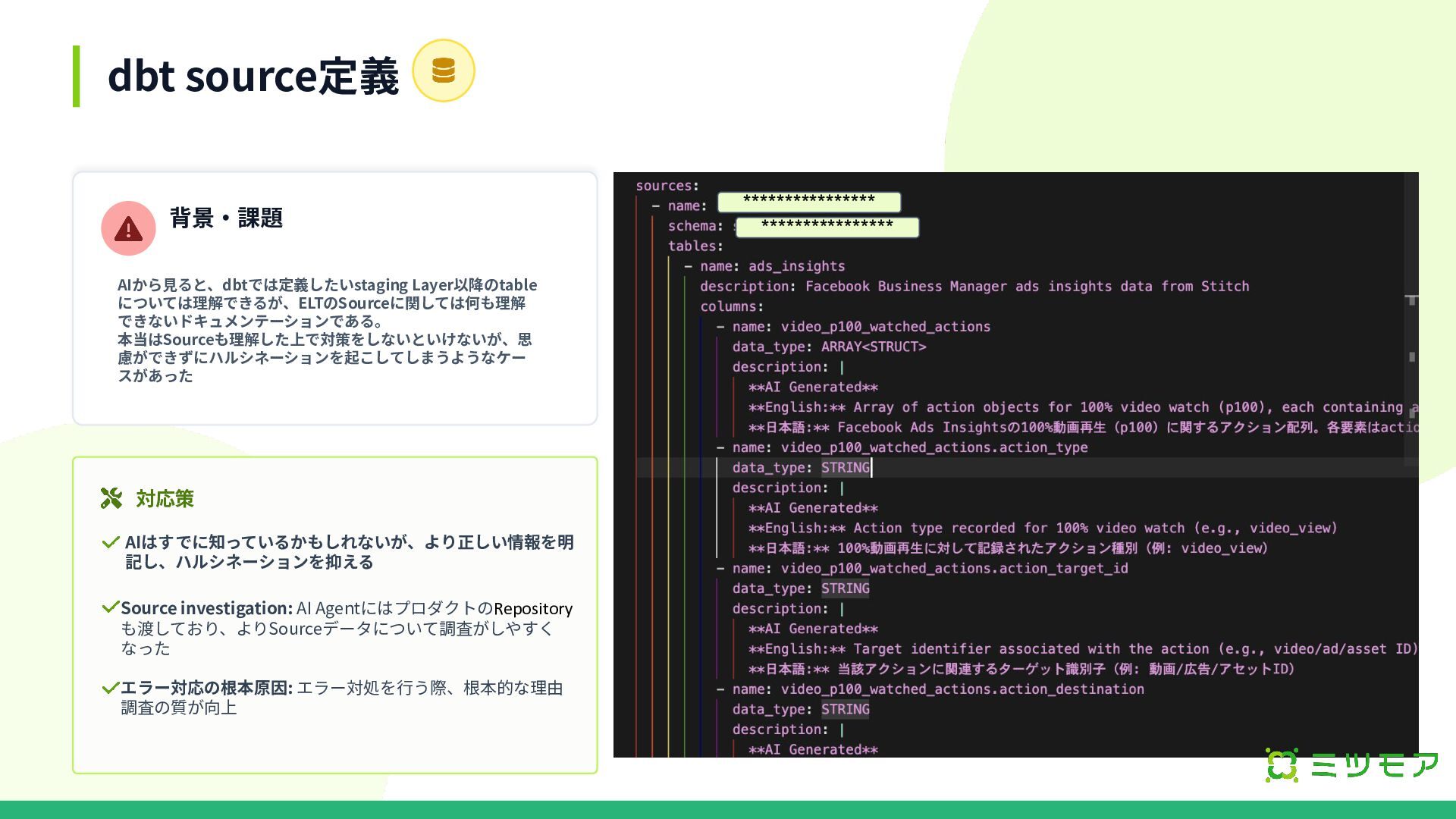
dbt source定義 背景‧課題 AIから⾒ると、dbtでは定義したいstaging Layer以降のtable については理解できるが、ELTのSourceに関しては何も理解 できないドキュメンテーションである。 本当はSourceも理解した上で対策をしないといけないが、思 慮ができずにハルシネーションを起こしてしまうようなケー スがあった
対応策 AIはすでに知っているかもしれないが、より正しい情報を明 記し、ハルシネーションを抑える Source investigation: AI AgentにはプロダクトのRepository も渡しており、よりSourceデータについて調査がしやすく なった エラー対応の根本原因: エラー対処を⾏う際、根本的な理由 調査の質が向上 **************** ****************
dbt exposuresの設定 開発の影響範囲を 把握したい Staging, Intermediate, martだけでなく Source table も
Lineageを登録 変更影響の⾃動通知 でんじろうがPR作成時にexposures を参照し、影響を受けるダッシュ ボードとオーナーを即座に特定‧通 知。 Agentの判断基準 「High Criticalityな下流を持つモデ ル」をAgentが認識し、軽率な⾃動修 正や破壊的変更を回避。 完全なリネージ SourceからBIまで⼀気通貫したリ ネージにより、障害時の原因特定時 間を⼤幅に短縮。 Action モデル変更がビジネスへ与える影響を不可視のま まにせず、で依存先を明⽰的に定義しました。 資産の定義: 本当に⼤事なものだけ Redashダッシュボー ド、クエリ、Owner、Criticality(重要度)をYAML化 運⽤: 変更時の影響範囲をPR上で⾃動通知する仕組みを構 築 dbt exposuresのイケてないこと/活⽤で きてないこと 分類⽅法が少ない: dbt docs generate で⽣成された html で⾒づらい。タグやフォルダ構成で管理したり検索したり したい Maturity: 現在は優先度⾼いもののみ記載しているが、 もっと対応範囲を広げたい。そうした時に、Maturity が Medium, Lowの登録を増やすことで対応が可能なはず **************** **************** **************** **************** **************** ****************
PII / Security Policy 元々のPII計画 プロダクトに応じて事業部制の組織体制であることが背景で、将来のアクセス制限を⾒越して、BigQueryのdataset単位でアクセス管理を⾏う想定をしていた AI Use前提で⾒直した結果 ColumnベースでPII処置を施す
[全体俯瞰] AI Agentのためにやったこと データカタログの拡充 text2sqlで「このカラムの意味は?」と聞かれるたびにdescriptionを追記。Agentの学習データを 整備。 dbt exposuresの設定 でんじろうが修正する際、影響範囲を正確に知るためにBIとの依存関係を全てコード化。 PII
/ Security Policy Agentが誤って個⼈情報を出⼒しないよう、dbtタグでPIIを明⽰的に管理しマスキングを強制。 dbt source 定義 元データの変更検知(スキーマドリフト)を⾃動化するため、Source Freshnessとテストを強化。 Table Tag System Agentが「どのテーブルを使えばいい?」と迷わないよう、推奨テーブルをタグ付けして優先度を 提⽰。 dbt Unified Metadata SSoT
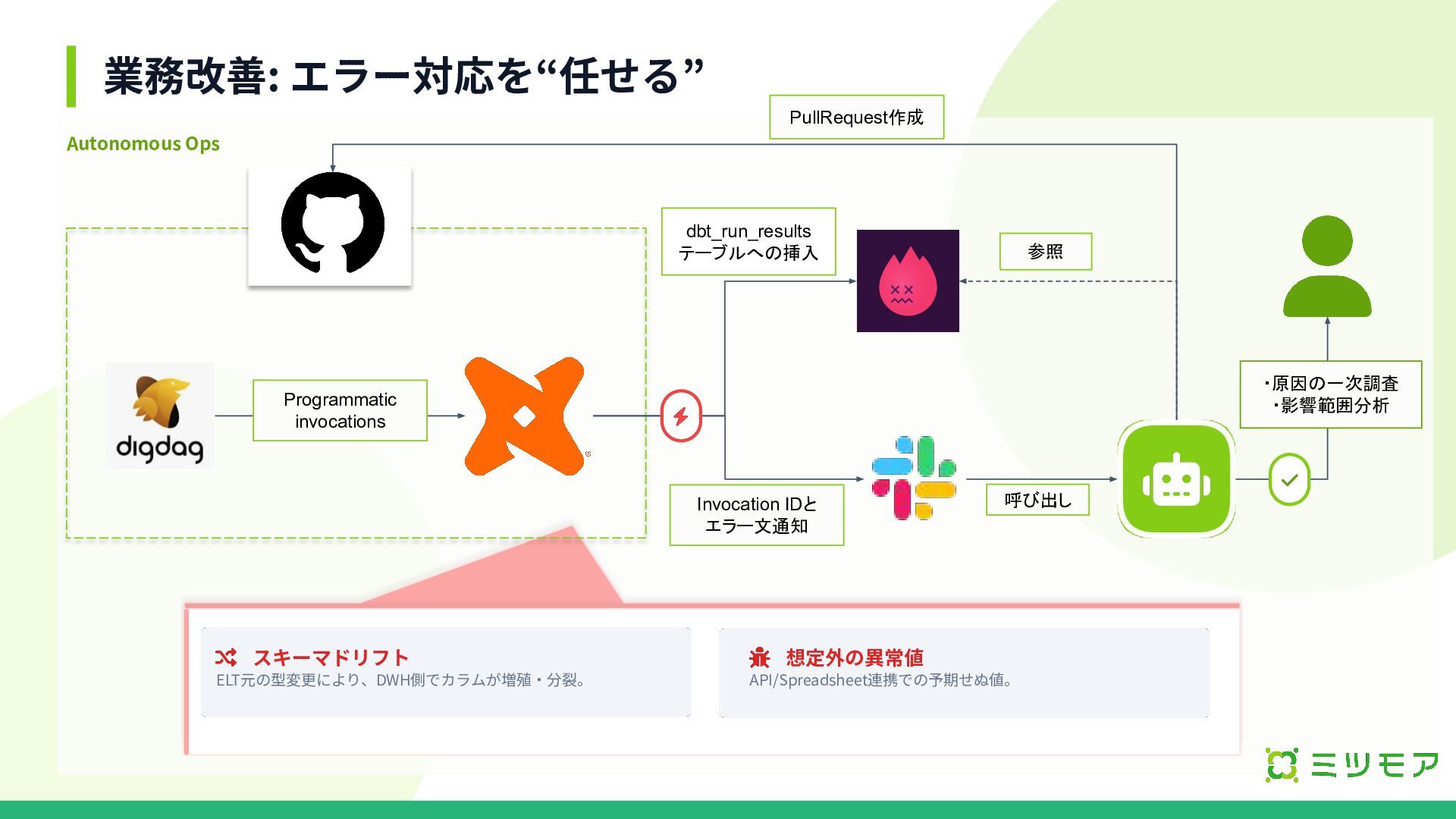
業務改善: エラー対応を“任せる” Programmatic invocations スキーマドリフト ELT元の型変更により、DWH側でカラムが増殖‧分裂。 想定外の異常値 API/Spreadsheet連携での予期せぬ値。 Invocation IDと
エラー文通知 呼び出し 参照 dbt_run_results テーブルへの挿入 PullRequest作成 ・原因の一次調査 ・影響範囲分析 Autonomous Ops
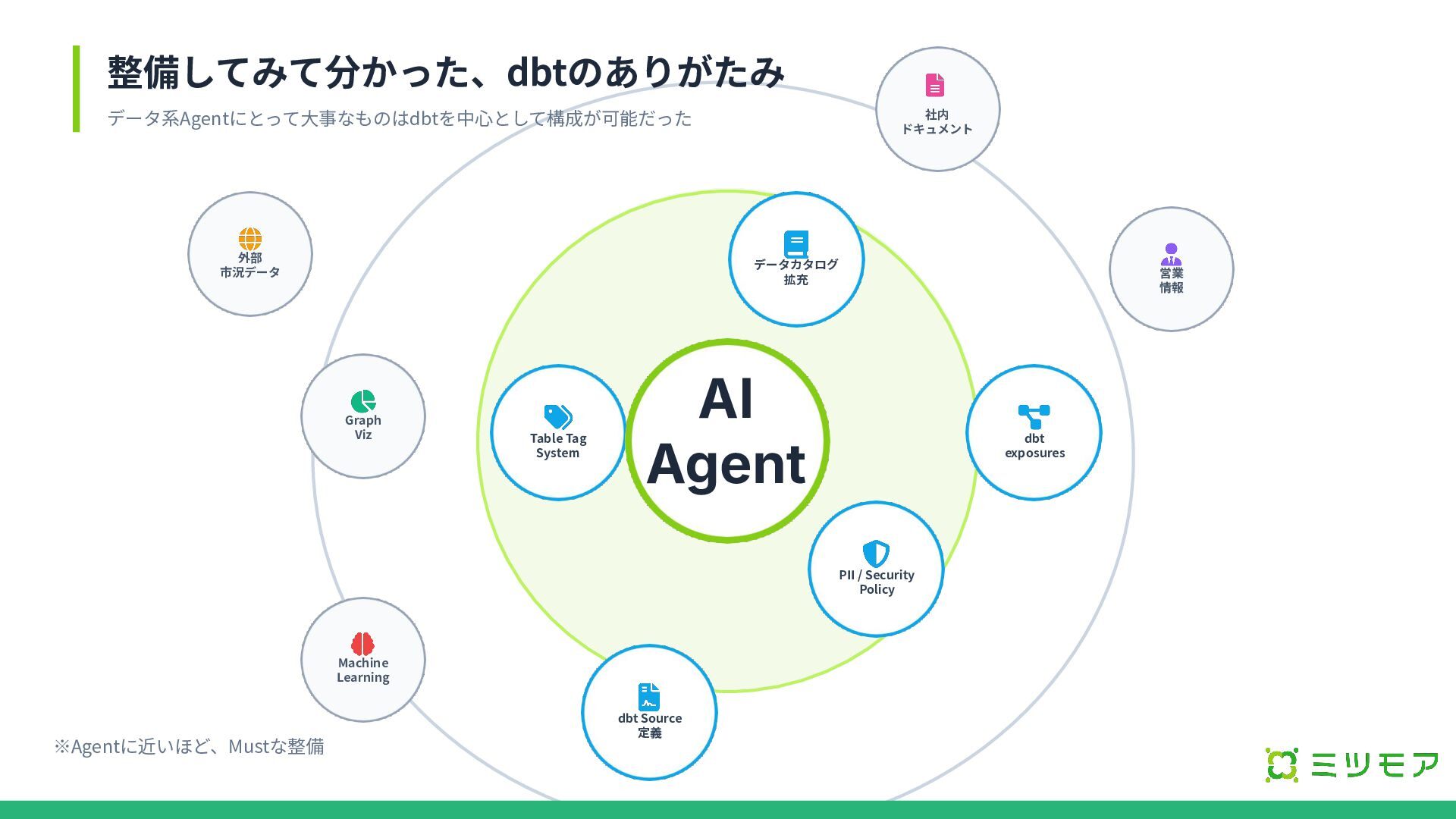
データカタログ 拡充 dbt exposures PII / Security Policy dbt Source
定義 Table Tag System 社内 ドキュメント 外部 市況データ 営業 情報 Machine Learning Graph Viz AI Agent 整備してみて分かった、dbtのありがたみ データ系Agentにとって⼤事なものはdbtを中⼼として構成が可能だった ※Agentに近いほど、Mustな整備
まとめ dbtが中核だったから成功した(と思っている) テーブルを指定せずに⾃然⾔語からSQLを⽣成できるような仕組みを作れたの は、dbtにメタデータが集約され、SSoTとして機能していたこと。整備なしで はAgentは作れなかった。 Agentがやりたくない仕事をしてくれる世界ができた 再帰的に発⽣する既知の対応業務や、⼤量に発⽣するエラーに対する1次対処 を⾏ってくれることで、データ基盤の品質向上とデータエンジニアが本質的な 業務へ向き合う時間の確保ができるようになった 整備のほとんどがdbtで完結し、ありがたみが増した
AI Agentを作ろうとした結果、「dbtによる基盤整備」の業務が⼤部分を占め た Agent時代こそ、堅牢なデータエンジニアリングが重要になる。 より不確実な分析に挑戦 議事録や商談の⽂字、⾳声などのデータを代表とした⾮構造化データ の ‧dbtでメタデータ管理を完結させる!dbt sourceのメタデータをSTRUCT型カラムやポリシータグも含めBigQueryに 連携する⽅法 ‧Slackからの依頼でPR作成まで⾃律的に⾏うデータエンジニアリングAIエージェント「でんじろう」の設計 ‧dbt Programmatic Invocationsとデータエンジニアリングエージェントによるデータパイプライン運⽤⾃動化への道 ‧dbtのpost_hookとBigQuery UDFでデータパイプラインの異常検知をする仕組みづくり ‧AI Ready Data Analysis Platform(4/n) - AIエージェントとして覚醒した第⼆世代text2SQLツール ‧AI Ready Data Analysis Platform(3/n) - text2SQLツールの精度向上への取り組み table tag systemの導⼊ ‧AI Ready Data Analysis Platform(2/n) - text2SQL内製 1st Edition ‧AI Ready Data Analysis Platform(1/n) - データ分析Agentロードマップ MeetsMore Tech Blog engineering.meetsmore.com Next Steps 詳細はブログで
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[全体俯瞰] AI Agentのためにやったこと データカタログの拡充 text2sqlで「このカラムの意味は?」と聞かれるたびにdescriptionを追記。Agentの学習データを 整備。 dbt exposuresの設定 でんじろうが修正する際、影響範囲を正確に知るためにBIとの依存関係を全てコード化。 PII](https://files.speakerdeck.com/presentations/451c2c53c8204999b2976a2a6586c5d0/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}