Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
スタートアップで初めての機械学習プロジェクトをリードするということ
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
crazysrot
October 28, 2025
Programming
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
スタートアップで初めての機械学習プロジェクトをリードするということ
https://recommendation-industry-talks.connpass.com/event/369310/
crazysrot
October 28, 2025
More Decks by crazysrot
See All by crazysrot
データエンジニア AI Agentを作ったらdbtのありがたみが増した
crazysrot
0
850
Other Decks in Programming
See All in Programming
IBM Bobを活用したレガシーアプリの最新化
oniak3ibm
PRO
1
180
不変条件と整合性境界—ビジネスが決める設計判断と実現パターン / Invariants and Consistency Boundaries
nrslib
13
3.6k
The ROI of Quarkus for Spring Boot Applications
hollycummins
0
100
AI時代の仕事技芸論 — ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ
kuranuki
1
640
その問い、本当に正しいですか?AI時代のエンジニアに必要な哲学と認知科学 / ai-philosophy-cognitive-science
minodriven
4
1.4k
[2026年度第1回ORセミナー] 計画最適化ベンチャーと競技プログラミング人材
terryu16
0
250
ローカルLLMを使ってB2Bサービスを作っていての学び
yaotti
0
150
3Dシーンの圧縮
fadis
1
680
Old Dog, New Tricks: The Java 25 Reinvention - JNation
bazlur_rahman
0
150
Why Laravel apps break—Mastering the fundamentals to keep them maintainable
kentaroutakeda
1
340
Spring Security 実践 ─ GraphQL APIで実務に役立つ 認証・認可 を学ぶ
wagyu
0
200
「エンジニアインターン、どうやって取った?」準備のリアルを語るLT会 Progate BAR
akiomatic
0
120
Featured
See All Featured
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
180
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
270
Game over? The fight for quality and originality in the time of robots
wayneb77
1
190
We Are The Robots
honzajavorek
0
240
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.3k
Accessibility Awareness
sabderemane
1
130
GitHub's CSS Performance
jonrohan
1033
470k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
610
KATA
mclloyd
PRO
35
15k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
Transcript
スタートアップで初めての 機械学習プロジェクトをリードするということ 2025-10-23 Recommendation Industry Talks #8 Yuki Furuta
プロフィール詳細 分析コンサルティング会社にてデータサイエンティストとして従事した のち、2021年8⽉に1⼈⽬データ正社員ポジションにてミツモア⼊社 データ周り全般を担当するグループのマネージャ 趣味:息⼦とサッカー crazysrot
最近がんばっていること 分析業務すべてにAIをCopilotさせる取り組み 特にtext2sqlに特化した分析のAI Agentを内製 弊社Tech blogにて発信中!!
会社紹介 株式会社ミツモア ミツモアのミッション Our Mission 日本のGDPを増やし 明日がもっといい日になる と思える社会に
会社紹介 株式会社ミツモア 我々は、3つのプロダクトを通して サービス産業の生産性向上を追い求めます。 日本人が使える、 世界基準でよいプロダクトを作る 生産性向上のために To Improve Productivity
本発表に関連するプロダクト詳細 見積もりプラットフォーム くらしからビジネスまで、 600種類以上のサービスでプロが見つかる 日本で唯一の自動見積もりプラットフォーム
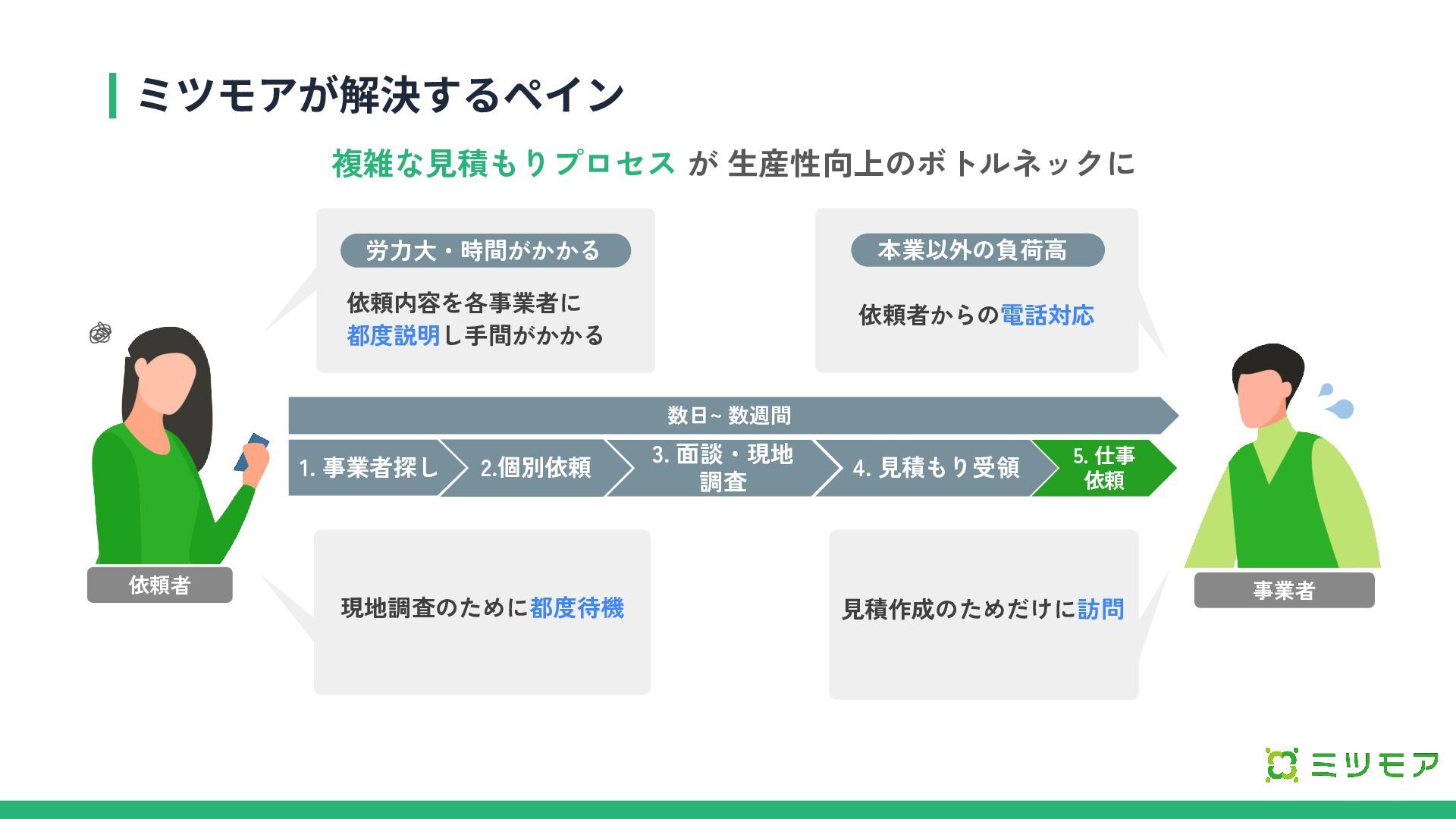
ミツモアが解決するペイン 依頼者からの電話対応 本業以外の負荷高 依頼内容を各事業者に 都度説明し手間がかかる 労力大・時間がかかる 1. 事業者探し 2.個別依頼 3.
面談・現地 調査 4. 見積もり受領 5. 仕事 依頼 数日~ 数週間 見積作成のためだけに訪問 現地調査のために都度待機 複雑な見積もりプロセス が 生産性向上のボトルネックに 依頼者 事業者
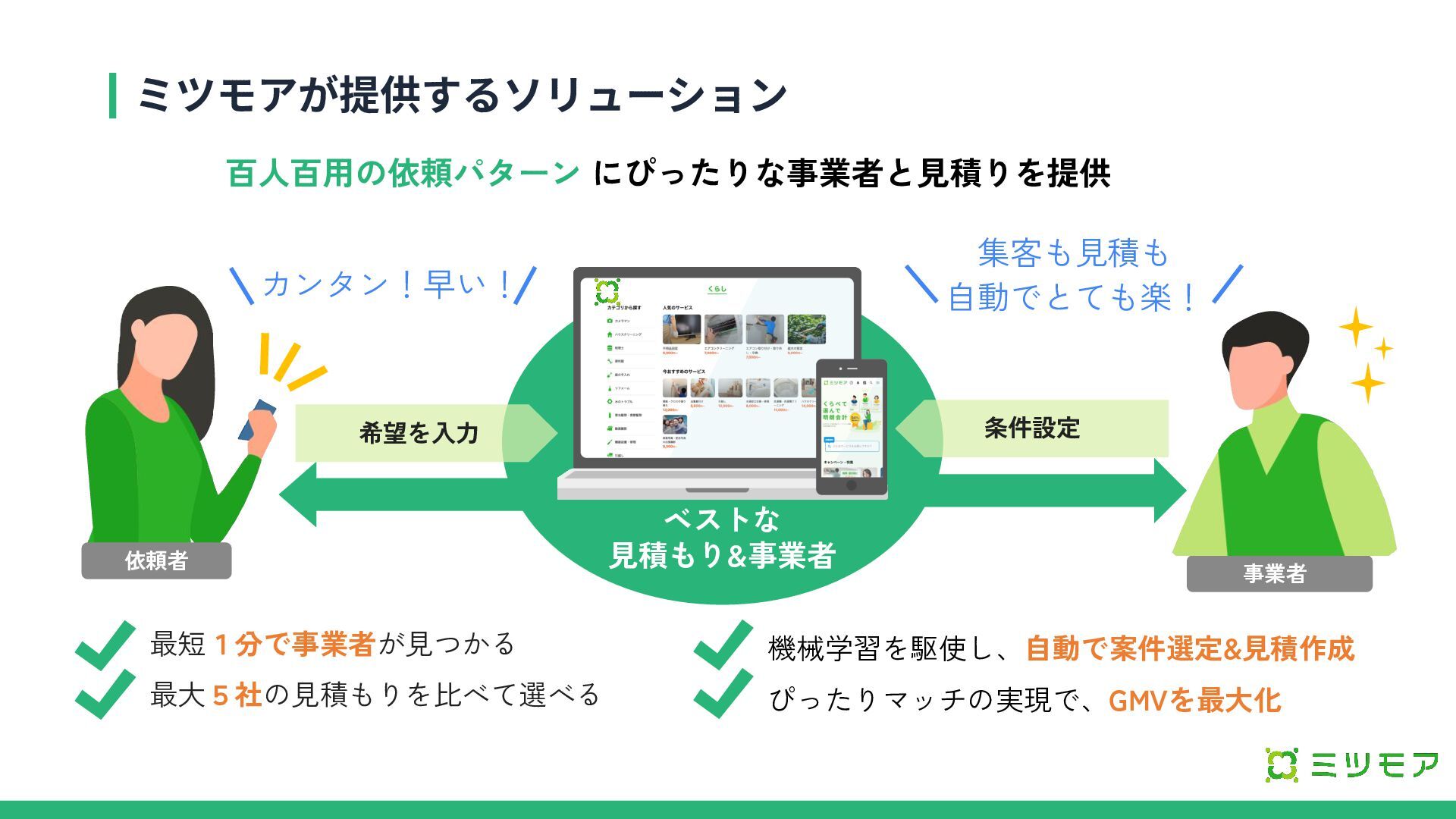
ミツモアが提供するソリューション ベストな 見積もり&事業者 条件設定 依頼者 事業者 カンタン!早い! 集客も見積も 自動でとても楽! 最短1分で事業者が見つかる
最大5社の見積もりを比べて選べる 機械学習を駆使し、自動で案件選定&見積作成 ぴったりマッチの実現で、GMVを最大化 百人百用の依頼パターン にぴったりな事業者と見積りを提供 希望を入力
今⽇の話の概要 4年前にマッチングアルゴリズムに機械学習を導⼊した (ことが とてもエキセントリックだった)話
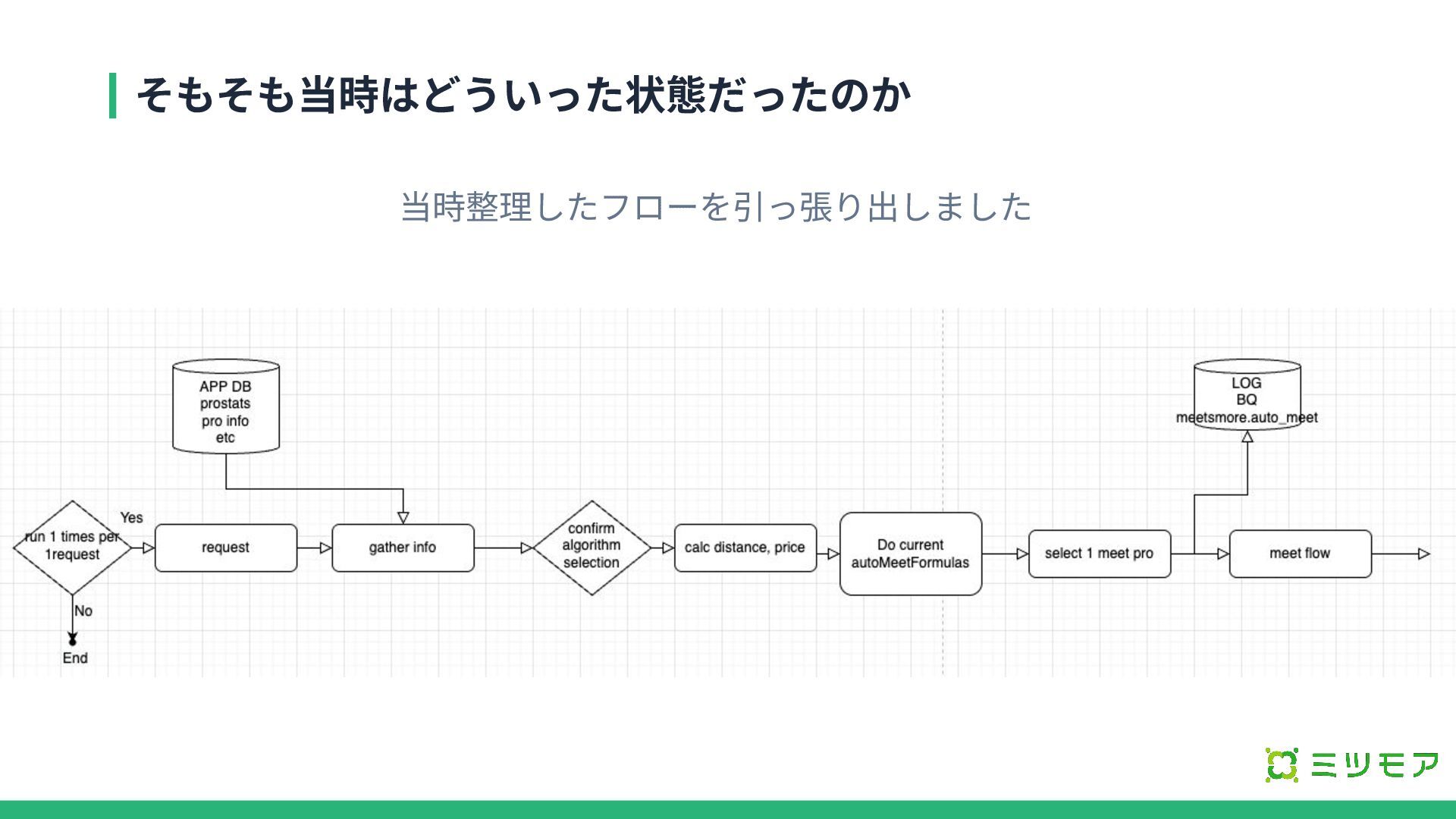
そもそも当時はどういった状態だったのか 当時整理したフローを引っ張り出しました
そもそも当時はどういった状態だったのか ルールベースの限界 データ基盤導⼊済み テスト環境 JavaScriptによる四則演算ベースの実装が拡張性に課題 BigQuery分析基盤は整っているがMLへの転⽤は未検証 事業の成⻑段階 PMF達成済みで売上‧データ増加フェーズに突⼊ ABテスト基盤は活⽤中 ロードマップ前の課題
精度向上の限界 経営層の期待と現実のギャップ 技術負債の蓄積
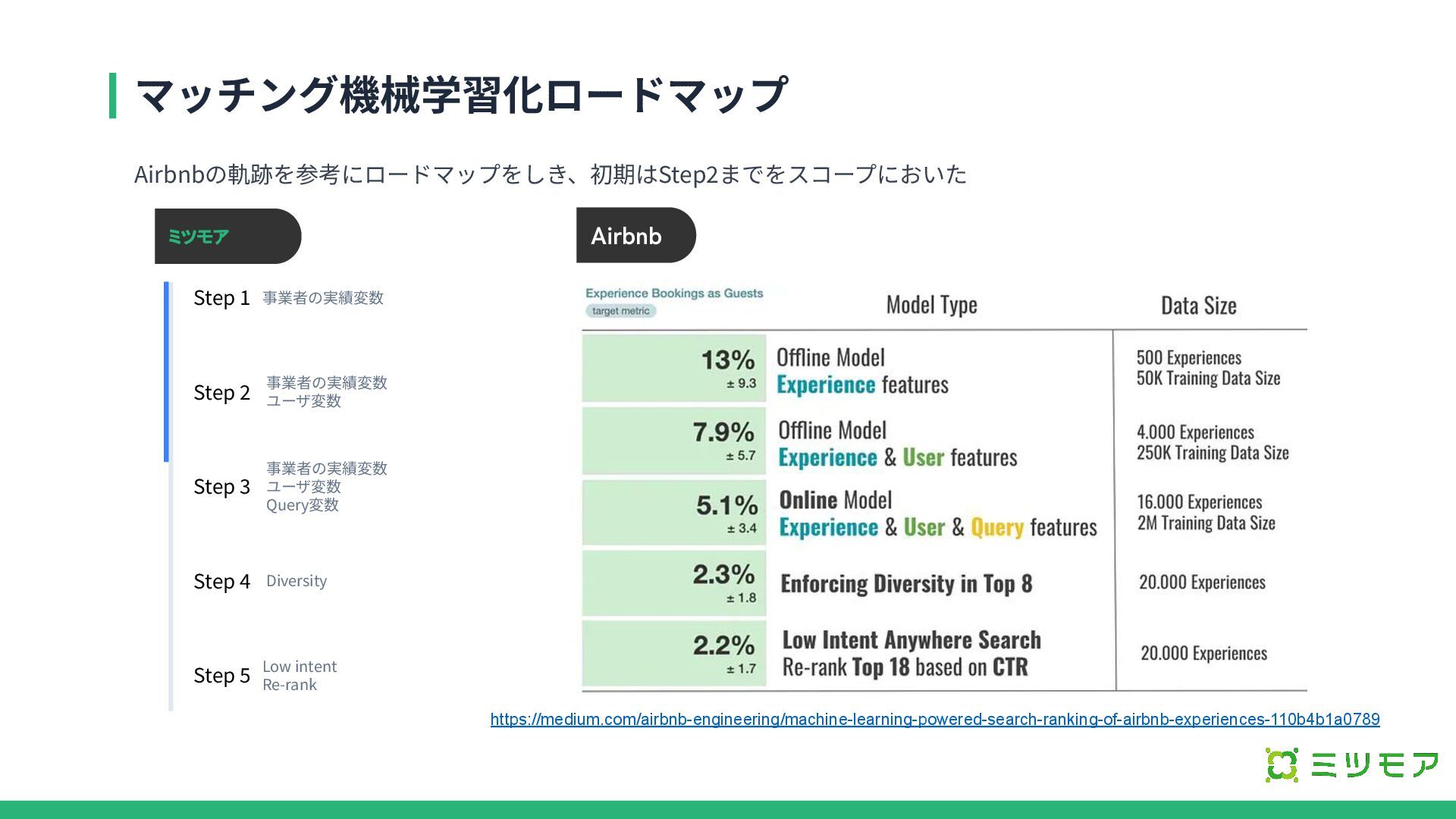
マッチング機械学習化ロードマップ Airbnbの軌跡を参考にロードマップをしき、初期はStep2までをスコープにおいた Step 1 Step 5 事業者の実績変数 Step 2 Step
3 Step 4 事業者の実績変数 ユーザ変数 事業者の実績変数 ユーザ変数 Query変数 Diversity Low intent Re-rank https://medium.com/airbnb-engineering/machine-learning-powered-search-ranking-of-airbnb-experiences-110b4b1a0789 Airbnb ミツモア
いざ出陣
発表者⼊社 @2021-08-24 ⼊社後は、しばらくほとんどが事業の可視化業務
Kick Off Meeting にて @2021-10-01 事前に⽤意した分析設計について答え合わせ 特徴量エンジニアリングのためのヒアリング 期限?????
早すぎる期限の要望 MTGでの発⾔(うろ覚え): 役員クラス: 「これって今⽉とかにリリースできたりしないですかね?(ワクワク)」 発表者: 「えっと....」 (いままでならデータ⾒て、いろいろちゃんと確認して、バッファ乗っけて...) 発表者: 「1stのあと最速で動けるように並列でやってみます」 返事をすることができませんでした
(CTOに助けてもらいました) 役員クラス: 「1stリリースの後、確定申告シーズンに向けてすぐ次作って欲しいです!!」 迫る納期プレッシャー
スタートアップについて
"スタートアップの思想 Done is better than perfect 完璧を⽬指すよりも、まずは形にすることが⼤切
リリース重視のプロジェクト進⾏ ⾼速でリリースをして、まずコンセプトが問題ないかを確認 その後にブラッシュアップしていく思想の存在 MLプロジェクトは⼯数がかかることが多く、このような進め⽅は発表者の経験上皆無だった (最近だと⽣成AIの台頭により、MLの開発サイクルも⾼速化している?) 「Done is better than perfect」の精神
リリースまでの動き 爆速リリースとの戦い
やらないといけないことは盛りだくさん... インフラどうするか モデルはどう作るか 特徴量エンジニアリングどうするか ビジネスとの合意どうするか 推論データはどうやって作るか 組み込み開発どうするか テストどうするか 施策の効果検証どうするか etc
インフラについて Google Cloud のVertex AIを選択 理由:以前触れた経験があったため フルマネージドサービスで管理コストが低い SREチームと相談し、Rest APIでの検討も⾏ったがフルマネージドが最適と判断 最終的に迅速な導⼊を重視して決定
モデルはどう作るか Vertex AIの制約によりXGBoost⼀択 短期リリースを優先するための技術選定
特徴量エンジニアリング⽅針 EDAをしないという意思決定 データ探索よりも迅速なリリースを優先 とにかく時間がない スタートアップの⾼速リリースサイクルに合わせた開発⽅針 限られた知⾒で変数設計 発表者が⼊社から会社の全部⾨の事業数値を出すアナリストも兼務 ⼊社からわずかな時間で得られた知⾒のみを絞り出し変数設計を無理やり実⾏
ビジネスとの合意形成 全体的な合意 主要売上のサービスのみサンプル抽出 Before/Afterを隅々まで確認 細かい精度の確認は実施せず SHAPは出したが、ビジネス側との詳細な共有は限定的
推論データ作成 既存のBigQueryを活⽤しdbtにて事前バッチ処理を⾏なったデータセット作成 Hourlyで更新するデータパイプライン増築による対応 推論時に最⼤数時間のラグがある状態 現在も同じ⼿法を採⽤し続けている 事前処理済みデータにより推論機能の負荷を軽減
組み込み開発 マッチングのログ取得 リアルタイム変数の取得 BigQuery変数の取得 推論API周辺の実装 エラーハンドリング 新しい変数候補のログ取得 ABテスト可能な形で実装 その他いろいろ
テスト⽅針 考慮漏れが多発したテストフェーズ ほとんどが未計画で都度設計に追われました... エラーハンドリングの不⾜ 異常値の処理⽅法 データ不⾜時の挙動 エンジニアへの感謝 "ソフトウェアエンジニアってすごいな" プロダクション環境の品質を保つための細やかな配慮に感銘 急ピッチな開発の中でも
⾼品質を維持するために必須ですね
施策の効果検証⽅法 既存のABテスト仕組みを最⼤限活⽤ データ分析基盤からのインサイト抽出 サービス別の効果検証と改善サイクル確⽴ 40回以上のABテスト実施と効果測定 次期モデル開発のための詳細分析実施
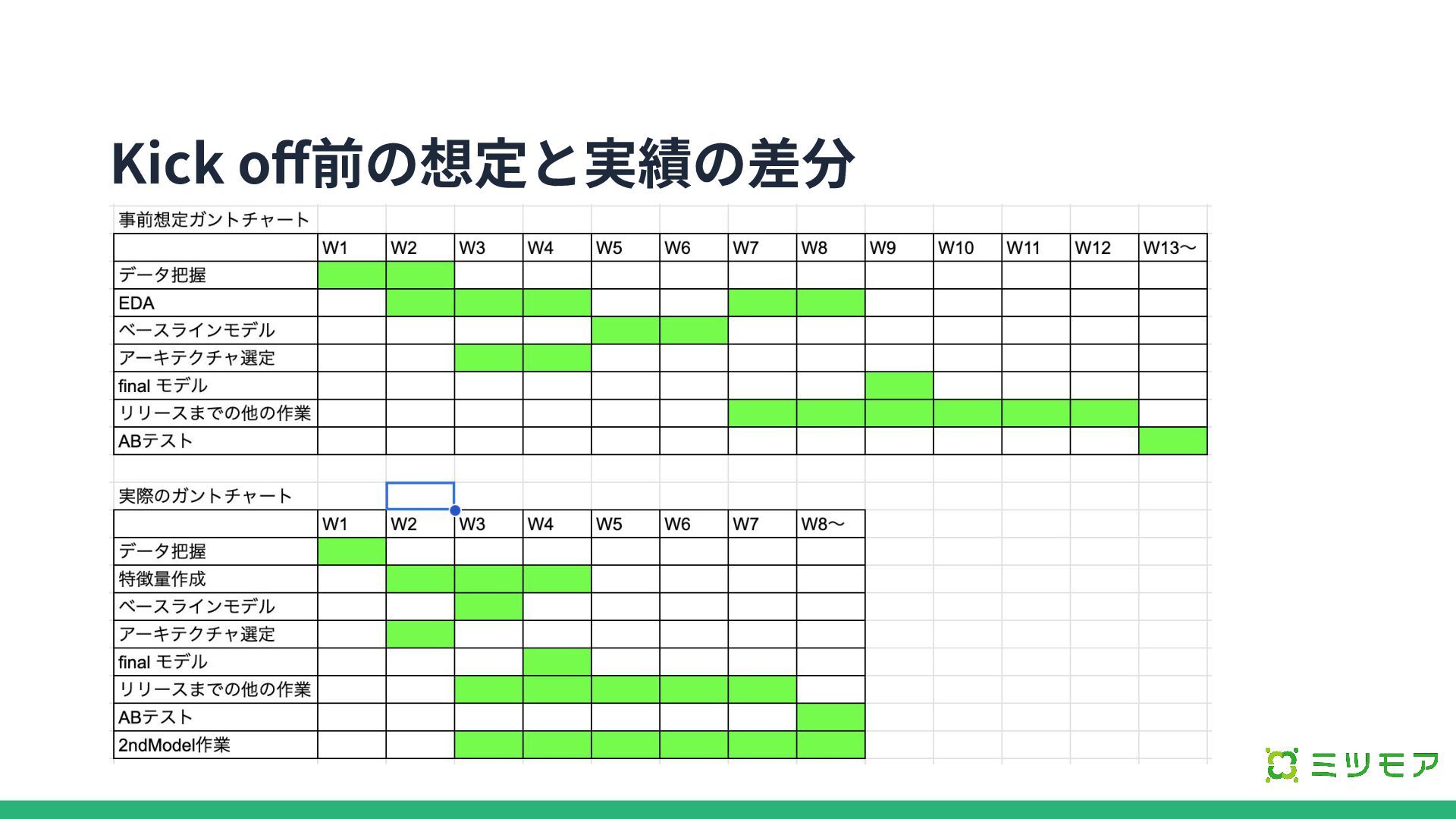
Kick off前の想定と実績の差分
最終的に作ったもの アルゴリズム:XGBoost 2値分類 VertexAIにてエンドポイントを提供 説明変数: 1st Model : 31 (6th
Model : 200弱) 事業者変数、依頼者変数 Code:Python Monitoring : Redash 機械学習置換率: 1st Model:10%台 (6th Model:50%超) ミッションを体現するコンセプトで設計 期待売上 = firstprice * predicted paid rate 現在取り⼊れている主要なビジネスロジック ‧外れ値対応 ‧リスクが⾼いマッチングの抑制 ‧サービス別特性 ‧⾮アクティブ事業者の抑制 Post Processing コンセプト 日本のGDPを増やし 明日がもっといい日になる と思える社会に Model
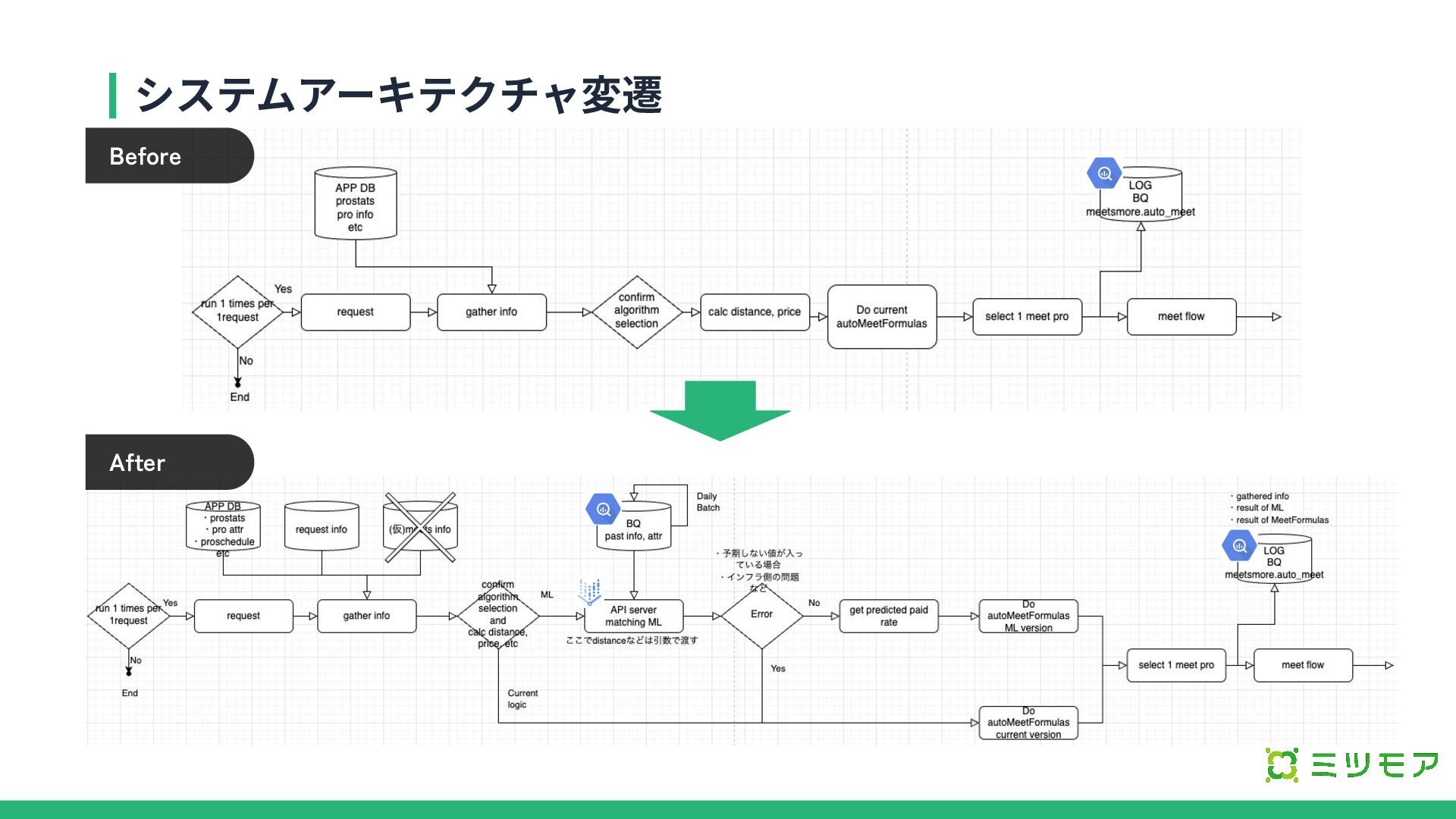
システムアーキテクチャ変遷 Before After
リリースして起きたこと 実際の運⽤で⾒えた課題と気づき
舞い上がり期 noteの記事に記載したように、成約率が急上昇☝☝☝ カナリーリリースで不⽤品回収サービスのみで実施
絶望期 ▶ 不⽤品回収サービスで顕著な成果が出たと勘違い 実際には初期段階の効果確認で事前に検知できていた課題があった データの検証不⾜による過剰な楽観視
Post Processing迷⾛期 オフライン検証の限界 - Post processing時点で予期せぬ悪影響が発⽣し、⼤幅な調整が必要だった 理論と現実のギャップ - 理論的に正しい設計でも、実際の環境では想定外の動作をすることが判明 外れ値への対応
- 予測モデルの精度が低い外れ値に近い部分で、追加の制約設定が必要に 制約のバランス - 厳しすぎる制約は多様性‧コンセプトを失い、緩すぎると不適切なマッチングが発⽣
ABテスト祭り期 サービス別に効果検証を実施 計40回のABテストをサービス別などで実施 それぞれ勝ち負けのジャッジと事後分析を実施 分析は、2ndモデル以降で活⽤するため念⼊りに実施 改めてEDAを含む分析が⼤事だと実感 検証後17/40が勝ちでPoC⾃体は成功と判断し、改善フェーズに突⼊
脇⽬振らず期 1stモデルリリース後、すぐに次の開発フェーズへ 「スピード感あって楽しい!!!」 「1stモデルの良し悪しを噛み締める時間もなく、次の開発に移りました」 成功や失敗を過度に分析せず、常に前に進む⽂化がスタートアップの強み 改善サイクルが数週間単位で回るスピード感 スピード重視の開発サイクル
おさらい ここまでの流れを振り返りまとめる
主な学び 細かい調整や詳細な説得は不要 スピード重視の「Done is better than perfect」の思想 綿密な調査より実践投⼊して検証 PDCAが何よりも重要 Post
Processingは難しい 理論と実践のギャップ、外れ値処理の課題 ビジネス理解はとても重要 技術以上にドメイン知識が結果を左右する EDAはとても重要 時間がなくても省略せず、データを深く理解する必要性
スタートアップと巨⼤企業の差(主観) 特徴 スタートアップ 巨⼤企業 開発サイクル 検証⽅法 失敗の影響 プロセス 環境の特徴 改善サイクル
⾼速PDCA重視 "Done is better than perfect"思想 ABテスト重視 実環境での即時検証 ユーザー数が少なく影響が限定的 失敗から学習して素早く修正 EDAを最⼩限に抑える 実装優先のアプローチ カオスを受け⼊れる 曖昧さに対応できる柔軟性 数週間〜1ヶ⽉ 計画的かつ慎重なアプローチ 完成度と品質を重視 徹底的なオフライン検証 段階的な本番展開 ⼤規模ユーザーへの影響⼤ 失敗のコストが⾮常に⾼い 詳細なEDAと検証 体系的な分析プロセス 構造化された環境 明確な役割と責任 数ヶ⽉〜1年
その後 現在までの軌跡を紹介
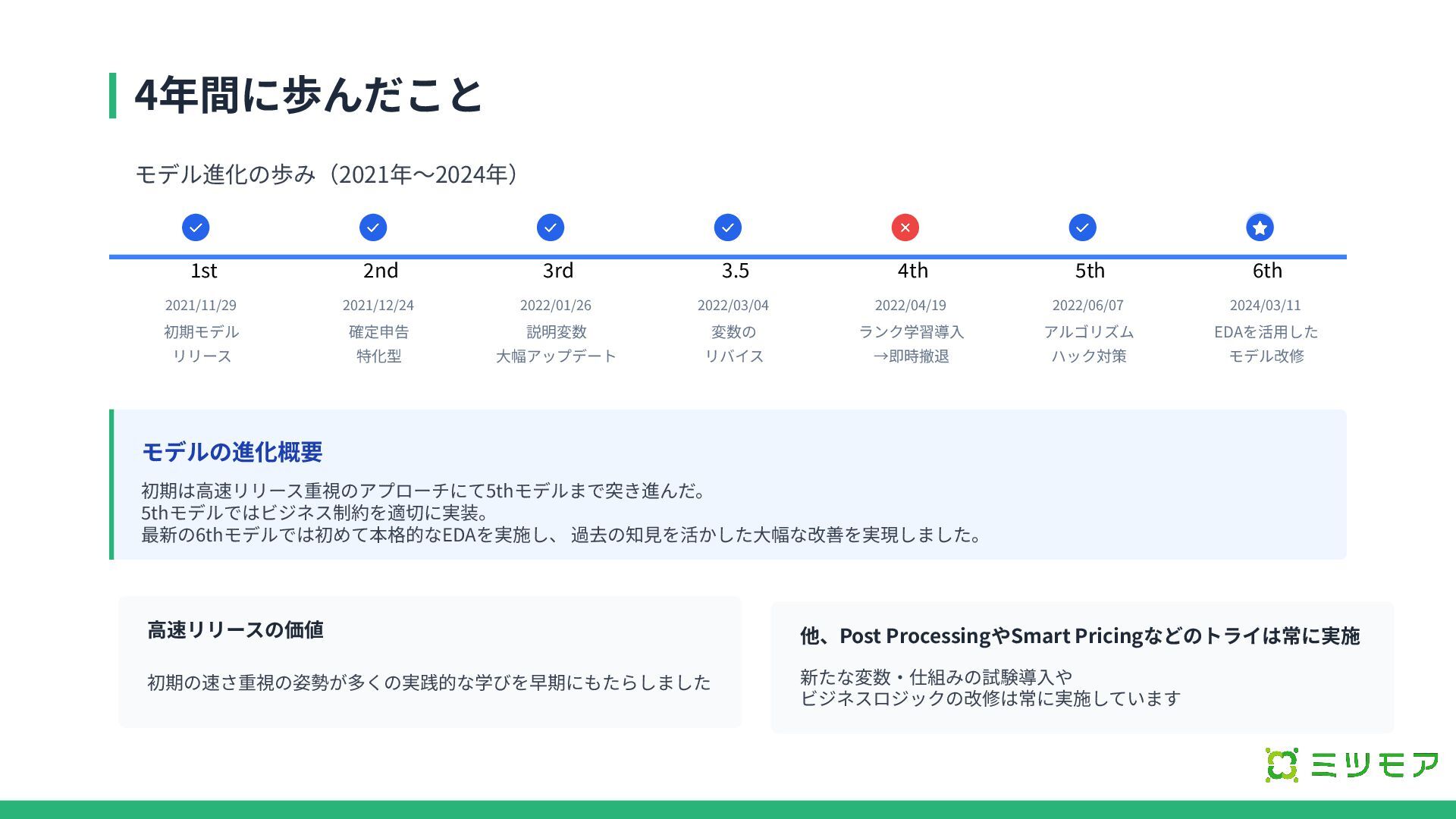
4年間に歩んだこと モデル進化の歩み(2021年〜2024年) モデルの進化概要 初期は⾼速リリース重視のアプローチにて5thモデルまで突き進んだ。 5thモデルではビジネス制約を適切に実装。 最新の6thモデルでは初めて本格的なEDAを実施し、 過去の知⾒を活かした⼤幅な改善を実現しました。 ⾼速リリースの価値 初期の速さ重視の姿勢が多くの実践的な学びを早期にもたらしました 1st
2nd 3.5 2021/11/29 初期モデル リリース 3rd 2021/12/24 2022/01/26 2022/03/04 確定申告 特化型 説明変数 ⼤幅アップデート 変数の リバイス 4th 5th 2022/04/19 2022/06/07 ランク学習導⼊ →即時撤退 6th 2024/03/11 アルゴリズム ハック対策 モデル改修 EDAを活⽤した 他、Post ProcessingやSmart Pricingなどのトライは常に実施 新たな変数‧仕組みの試験導⼊や ビジネスロジックの改修は常に実施しています
各モデル摘要 1st (2021年11⽉): 初のML導⼊。基本的な特徴量設計とXGBoostモデルの実装 2nd (2021年12⽉): 確定申告特化型。ユーザー体験が異なるため別モデルで検証 3rd (2022年1⽉): 説明変数の⼤幅アップデートによる精度向上
3.5 (2022年3⽉): 3rdモデルに劣化する変数があったためリバイス 4th (2022年3⽉): ランク学習導⼊も結果がとてつもなく悪く即時撤退 5th (2022年6⽉): アルゴリズムハックを防ぐ改善を実施。説明変数の数2倍弱 6th (2024年3⽉): EDAを初めてまともに実施して⼤幅に全体的に改修
今後やっていきたいこと
やりたいことはたくさんある Query Feature Engineering - 特徴量の追加と精緻化 Diversity - 多様性を考慮した推薦システム User
feature リベンジ - リピーターが増えてきたことにより、ユーザー特性の活⽤期待が⾼まる ビジネス制約の実装 - 集中の抑制など MLOps - モデル運⽤の⾃動化と効率化
We are hiring! データアナリスト データサイエンティスト データエンジニア データ系各職種にて募集中
最後に:今後も挑戦は続く ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}